Sber.DS — платформа, которая позволяет создавать и внедрять модели даже без кода
Идеи и встречи о том, какие ещё процессы можно автоматизировать, возникают в бизнесе разного масштаба ежедневно. Но помимо того, что много времени может уходить на создание модели, нужно потратить его на её оценку и проверку того, что получаемый результат не является случайным. После внедрения любую модель необходимо поставить на мониторинг и периодически проверять.
И это всё этапы, которые нужно пройти в любой компании, не зависимо от её размера. Если мы говорим о масштабе и legacy Сбербанка, количество тонких настроек возрастает в разы. К концу 2019 года в Сбере использовалось уже более 2000 моделей. Недостаточно просто разработать модель, необходимо интегрироваться с промышленными системами, разработать витрины данных для построения моделей, обеспечить контроль её работы на кластере.
Наша команда разрабатывает платформу Sber.DS. Она позволяет решать задачи машинного обучения, ускоряет процесс проверки гипотез, в принципе упрощает процесс разработки и валидации моделей, а также контролирует результат работы модели в ПРОМ.
Чтобы не обмануть ваших ожиданий, хочу заранее сказать, что этот пост — вводный, и под катом для начала рассказано о том, что в принципе под капотом платформы Sber.DS. Историю о жизненном цикле модели от создания до внедрения мы расскажем отдельно.
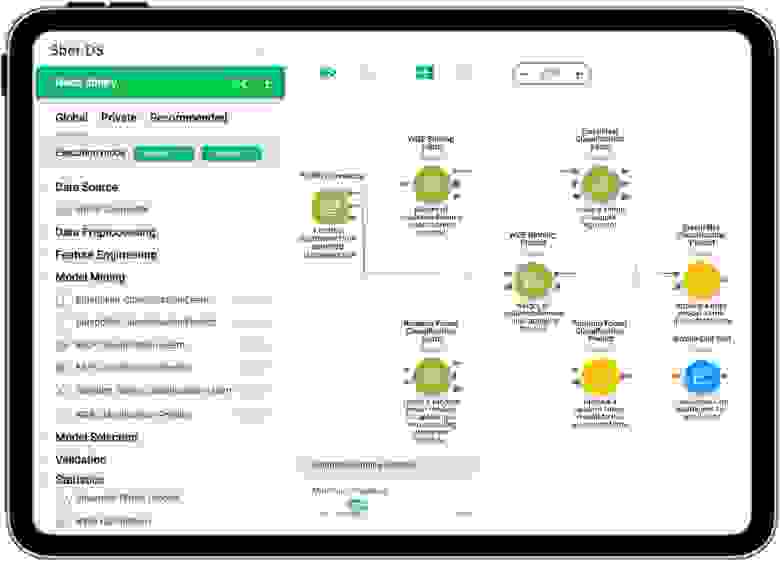
Sber.DS состоит из нескольких компонентов, ключевыми из которых являются библиотека, система разработки и система исполнения моделей.

Библиотека контролирует жизненный цикл модели с момента появления идеи её разработать до внедрения в ПРОМ, постановки на мониторинг и вывода из эксплуатации. Многие возможности библиотеки продиктованы правилами регулятора, например, отчетность и хранение обучающих и валидационных выборок. По факту это реестр всех наших моделей.
Система разработки предназначена для визуальной разработки моделей и валидационных методик. Разработанные модели проходят первичную валидацию и поставляются в систему исполнения для выполнения своих бизнес функций. Также в системе исполнения модель может быть поставлена на монитор с целью периодического запуска валидационных методик для контроля ее работы.
В системе есть несколько типов узлов. Одни предназначены для подключения к различным источникам данных, другие — для трансформации исходных данных и их обогащения (разметки). Есть множество узлов для построения различных моделей и узлов для их валидации. Разработчик может загружать данные из любых источников, преобразовывать, фильтровать, визуализировать промежуточные данные, разбивать их на части.
Также платформа содержит уже готовые модули, которые можно перетаскивать на проектную область. Все действия производятся с использованием визуализированного интерфейса. Фактически можно решить задачу без единой строчки кода.
Если встроенных возможностей не хватает, то система предоставляет возможность для быстрого создания своих собственных модулей. Мы сделали режим интегрированной разработки на основе Jupyter Kernel Gateway для тех, кто создает новые модули «с нуля».
Архитектура Sber.DS построена на микросервисах. Есть много мнений о том, что такое микросервисы. Некоторые считают, что достаточно разделить монолитный код на части, но при этом они все равно ходят в одну и ту же базу данных. У нас микросервис должен общаться с другим микросервисом только по REST API. Никаких обходных путей доступа к базе данных напрямую.
Мы стараемся, чтобы сервисы не становились очень большими и неповоротливыми: один экземпляр не должен потреблять больше 4-8 гигабайт оперативной памяти и обязан обеспечивать возможность горизонтального масштабирования запросов запуском новых экземпляров. Каждый сервис общается с другими только по REST API (Open API). Команда, ответственная за сервис, обязана сохранять обратную совместимость API до последнего клиента, который им пользуется.
Ядро приложения написано на Java с использованием Spring Framework. Решение изначально проектировалось для быстрого развертывания в облачной инфраструктуре, поэтому приложение построено с использованием системы контейнеризации Red Hat OpenShift (Kubernetes). Платформа постоянно развивается, как в части наращивания бизнес функционала (добавляются новые коннекторы, AutoML), так и в части технологической эффективности.
Одна из «фишек» нашей платформы состоит в том, что мы можем запускать код, разработанный в визуальном интерфейсе, на любой системе исполнения моделей Сбербанка. Сейчас их уже две: одна на Hadoop, другая — на OpenShift (Docker). Мы на этом не останавливаемся и создаем интеграционные модули для запуска кода на любой инфраструктуре, в том числе on-premise и в облаке. В части возможностей эффективного встраивания в экосистему Сбербанка, мы также планируем поддержать работу с имеющимися средами исполнения. В перспективе – решение может быть гибко встроено «из коробки» в любой ландшафт любой организации.
Те, кто когда-нибудь пробовал поддерживать решение, запускающее Python на Hadoop в ПРОМ, знают, что мало подготовить и доставить пользовательский environment питона на каждую датаноду. Огромное количество C/C++ библиотек для машинного обучения, которые используют Python модули, не позволят вам отдыхать спокойно. Надо не забывать обновлять пакеты при добавлении новых библиотек или серверов, сохраняя обратную совместимость с уже внедренным кодом моделей.
Есть несколько подходов к тому, как это делать. Например, заранее подготовить несколько часто используемых библиотек и внедрить их в ПРОМ. В дистрибутиве Hadoop от Cloudera для этого обычно используют parcel. Также сейчас в Hadoop появляется возможность запуска docker-контейнеров. В некоторых простых случаях можно доставить код вместе с пакетом python.eggs.
Банк очень серьезно подходит к безопасности запуска стороннего кода, поэтому мы по максимуму используем новые возможности ядра Linux, где процессу, запущенному в изоляционном окружении Linux namespace, можно ограничить, например, доступ к сети и локальному диску, что значительно снижает возможности вредоносного кода. Области данных каждого департамента защищены и доступны только владельцам этих данных. Платформа гарантирует, что данные из одной области могут попасть в другую область, только через процесс публикации данных с контролем на всех этапах от доступа к источникам до приземления данных в целевую витрину.
В этом году мы планируем завершить MVP запуска моделей, написанных на Python/R/Java на Hadoop. Мы поставили для себя амбициозную задачу научиться запускать любой пользовательский environment на Hadoop, чтобы ни в чем не ограничивать пользователей нашей платформы.
Кроме того, как оказалось, многие DS-специалисты отлично знают математику и статистику, делают классные модели, но не очень хорошо разбираются в трансформациях больших данных, и им требуется помощь наших data-инженеров для подготовки обучающих выборок. Мы решили помочь коллегам и создать удобные модули для типовой трансформации и подготовки фич для моделей на Spark-движке. Это позволит больше времени уделять разработке моделей и не ждать, пока дата-инженеры подготовят новый dataset.
У нас работают люди со знаниями в разных областях: Linux и DevOps, Hadoop и Spark, Java и Spring, Scala и Akka, OpenShift и Kubernetes. В следующей раз мы расскажем о библиотеке моделей, о том, как модель проходит по жизненному циклу внутри компании, как происходит валидация и внедрение.
Код без тестов — легаси
Если вы работаете в IT, то о легаси вы слышите часто — обычно с множеством негативных коннотаций. Понятно, что это не «хороший код», но какой? Может старый, может не поддерживаемый или не обновляемый, а может просто чужой? Есть ли «полноценное» определение «легаси», на которое можно ссылаться? А когда разберемся — что нам делать с легаси? Попробуем разобраться. Спойлер: выводы неочевидны.
Автор — Николас Карло, веб-разработчик в Busbud (Монреаль, Канада). Специализируется на легаси. В свободное время организует митап Software Crafters и помогает с конференциями SoCraTes Canada и The Legacy of SoCraTes.
Данная статья была скомпилирована (и отредактирована) из двух статей Николаса: «What is Legacy Code? Is it code without tests?» и «The key points of Working Effectively with Legacy Code». Показалось логичным рассказать о том, что такое легаси, а потом — как с ним работать.
Что такое «легаси»?
Возможно, если вы задавались этим вопросом, то встречали определение от Майкла Физерса. Майкл выпустил книгу «Working Effectively with Legacy Code» в 2004 году, но она до сих пор актуальна. Комикс это отлично иллюстрирует.
В своей книге Майкл пишет своё определение:
«Для меня легаси — это просто код без тестов».
Почему Физерс так считает? Потому что по его многолетнему опыту без тестов обычно трудно узнать всё, что код умеет. Если тестов нет, то для понимания, что код делает, вам нужно внимательно его прочитать, воспроизвести программу в своей голове и представить все возможные сценарии. Потом вы поменяете код и нужно снова представить все сценарии. Или проверить их вручную, но всегда есть шанс что-то сломать.
Это хорошее определение: чаще всего тесты отсутствуют, так что это хорошее начало. Но это ещё не всё — есть нюансы.
Код с тестами также может быть легаси. Если вы читаете тесты, но не можете понять, что должен делать код — они отстой. Плохие тесты только мешают: тестируемый код так же трудно отрефакторить, как если бы у него не было тестов, а может даже и сложнее!
Тестов может и не быть, но код всё ещё легко можно отрефакторить. Возможно, вы поддерживаете небольшую кодовую базу без тестов, которую легко понять и рефакторить. Хотя, по моему опыту, это аномалия. Эту кодовую базу можно было бы проверить, но отсутствие автоматизированных тестов всё же не позволяет квалифицировать его как легаси.
Перейдём к моему определению легаси.
Легаси — это ценный код, который вы боитесь менять.
Например, мы ищем первопричину ошибки или выясняете, куда вставить свою функцию. Мы хотим поменять код, но это трудно, потому что непонятно как не нарушить существующее поведение. Готово — у нас легаси!
Мы переоцениваем сложность незнакомого кода. Поэтому мы думаем, что код, который писали не мы — устаревший. Это работает и с нашими прошлыми проектами, когда мы не можем понять, что закладывали и имели в виду, когда писали эту мешанину на экране.
Хорошие тесты помогают легко менять незнакомый код. А плохие тесты не помогают. Отсюда и определение Физерса.
С легаси помогает время. Парадоксально: обычно время превращает любой код в легаси, но чтобы его понять нам также помогает время. Если вы начали работать над легаси и это трудно — подождите. Да, большая часть кода ужасна, но вы привыкнете и лучше поймете его причуды и особенности.
Легаси не виновато в том, что оно такое. Большая часть кода ужасна, потому что это результат работы многих людей в течение долгого времени с противоречивыми требованиями и под давлением дедлайнов. Это Рецепт Устаревшего Кода™. Когда мало времени и недостаточно знаний — рождаются костыли (ну вы знаете). В конце концов, мы достигнем состояния, когда каждое движение приводит к ошибке, а реализация любой функции занимает целую вечность.
А теперь один из важнейших нюансов.
Легаси — это код, который мы изо всех сил пытаемся понять, чтобы поменять.
Легаси — это личная точка зрения. Устаревший код может стать проблемой для каждого разработчика команды. Какой-то код может показаться сложным, потому что мы его ещё не поняли, а какой-то понимаем, но всё равно чувствуем себя некомфортно, когда рефакторим. Но субъективное ощущение «легаси» зависит от нашего понимания кода, и наших чувств по поводу его изменения. Часто люди этого не понимают.
В итоге мы получаем, что легаси это:
который мы пытаемся понять, чтобы отрефакторить;
Как же эффективно работать с легаси?
Легаси — код, который мы пытаемся понять, чтобы отрефакторить. Задача рефакторинга в том, чтобы сохранить существующее поведение кода. Как без тестов мы будем уверены, что ничего не сломали? Нам нужна обратная связь. Автоматизированная обратная связь — ещё лучше.
Добавить тесты, а затем внести изменения
Логично, что если добавить тесты, они помогут его «прощупать» и он перестанет быть устаревшим. Поэтому первое, что нужно сделать — написать тесты. Только тогда мы будем в безопасности, чтобы рефакторить код.
Но чтобы запустить тесты, мы должны поменять код. Возникает парадокс легаси. Мы обречены? Нет. Поменяем как можно меньше кода для тестов:
Определим точки изменения — «швы».
Первые два пункта самые сложные, а как только доберёмся до тестов, мы знаем, что делать.
Найти «швы» для разрыва зависимостей
Обычно когда мы добавляем тесты к легаси возникает «проблема зависимостей»: код, который мы хотим протестировать, не может работать, потому что ему нужно что-то сложное для тестирования. Иногда это соединение с базой данных, иногда вызов на сторонний сервер, а иногда — параметр, который сложно создать. А чаще всё и сразу.
Чтобы протестировать код, нужно разбить эти зависимости в тестах. Для этого необходимо выявить «швы».
«Шов» — место, где можно изменить поведение программы, не меняя код.
«Швы» бывают разные. Если это объектно-ориентированный ЯП, то обычно это объект, например, в JavaScript.
Допустим, метод connect() вызывает проблемы, когда мы пытаемся поместить код в тесты. Получается, что весь класс — это «шов», который можно поменять. Можно расширить этот класс в тестах, чтобы предотвратить его подключение к реальной БД.
Есть и другие виды швов. Если язык позволяет изменять поведение кода без изменения исходного кода, у нас есть точка входа в написание тестов. Кстати о тестах…
Напишем unit-тесты
Дискуссии о лучших практиках тестирования обычно перерастают в холивары. Применять принцип пирамиды тестов, и писать максимум unit-тестов? Или использовать «Кубок тестирования» и писать в основном интеграционные?
Почему советы такие противоречивые? Потому что у них нет единого определения того, что такое «unit». Одни люди говорят об «интеграционных тестах» и тестируют всю библиотеку, а другие тестируют каждый класс по отдельности.
Чтобы избежать путаницы, Майкл даёт четкое определение того, что такое НЕ unit-тест:
он не работает быстро (
Похожие и интересные статьи:
О том, над чем в целом мы тут работаем: монолит, монолит, опять монолит.
Кратко об истории Open Source — просто развлечься (да и статья хорошая).
Больше новостей про разработку в Додо Пицце я пишу в канале Dodo Pizza Mobile. Также подписывайтесь на чат Dodo Engineering, если хотите обсудить эту и другие наши статьи и подходы, а также на канал Dodo Engineering, где мы постим всё, что с нами интересного происходит.
А если хочешь присоединиться к нам в Dodo Engineering, то будем рады — сейчас у нас открыты вакансии iOS-разработчиков (а ещё для Android, frontend, SRE и других).
Сбербанк запускает единое рабочее место операторов собственной разработки
Содержание
На платформе Единой фронтальной системы (ЕФС) разрабатываются фронтальные процессы для системы «Сбербанк Онлайн» (мобильное приложение и веб-версия), а также для сотрудников отделений, специалистов по прямым продажам первого уровня. Программа по разработке этой системы является одной из ключевых и стратегических для Сбербанка.
2020: Запуск единого рабочего места операторов на базе ЕФС
26 февраля 2020 года «Сбербанк» сообщил TAdviser о запуске тиража собственной разработки — единого рабочего места (ЕРМ) операторов первых линий, обслуживающих корпоративных клиентов. Запуск ЕРМ планируется на 1 марта 2020 года.

Опытная эксплуатация разработки показала, что благодаря ей экономится 17–20 секунд (примерно 6%) среднего времени обработки контакта. В месяц это 2900 часов.
На 26 февраля 2020 года идут подготовительные работы по организации тиража и обучению операторов — пользователей ЕРМ. Увеличение численности операторов будет происходить планомерно.
Единое рабочее место (ЕРМ) операторов первых линий ЦКР («Центра корпоративных решений») для направлений «операционная поддержка УСО» и «техническая поддержка ДБО» разрабатывается на базе банковской платформы «Единая фронтальная система» (ЕФС) с использованием модульного подхода, позволяющего легко подключить (в зависимости от потребности и готовности) дополнительные инструменты или сервисы. На февраль 2020 года ЕРМ состоит из следующих модулей: идентификации клиентов, аутентификации, CTI-панели, карточки клиента, истории вопросов, интеллектуального помощника, базы знаний, регистрации обращений, уведомлений, поиска в CRM.
ЕРМ содержит консолидированную из девяти систем-источников информацию: «CRM Корпоративный», ЕКС, СББОЛ, Way4, СНУИЛ, БФС (геообъекты), ФП «Выплаты», ФП ЗД (зарплатные договора). Это позволяет сократить количество программных окон на рабочем столе оператора.


2018: Результаты разработки за год
В 2018 году были усовершенствованы архитектура ЕФС, процессы разработки и вывода функционала в промышленную среду, сообщил Сбербанк в отчете о своей деятельности за 2 квартал 2019 года. Также была внедрена возможность многоверсионности, благодаря которой технологические сервисы и клиентский функционал могут развиваться независимо и итерационно в собственных релизных циклах.

В рамках разработки ЕФС в 2018 году Сбербанк реализовал функционал дистанционного банковского обслуживания по документарным операциям (аккредитивы, инкассо) через «Сбербанк Бизнес Онлайн», который позволяет клиенту направлять заявления/запросы/письма в банк в электронном виде, отслеживать их статусы онлайн и видеть реестр своих сделок.
Этот сервис позволяет сократить время обслуживания клиентов по аккредитивам и инкассо и повысить удовлетворенность клиентов, заявляют в Сбербанке.
Еще одним ключевым событием в области ЕФС Сбербанк называет начало этапа массового тиража системы на всех клиентов в трех каналах дистанционного банковского обслуживания в 2018 году.
2017: Новая версия ЕФС
В 2017 году была разработана новая версия платформы ЕФС 7.0 с более высоким уровнем надежности и производительности за счет поддержки режима развертывания в многоблочной архитектуре и режима Stand-In, обеспечивающего повышение отказоустойчивости и бесшовное обновление функциональных подсистем платформы. Также было начато массовое внедрение нового целевого процесса разработки ЕФС с использованием «инструментальных средств разработки. В Сбербанке поясняют, что это позволит одной команде реализовывать решения для всех каналов, максимально переиспользовать уже реализованные объекты и сервисы, уменьшить число ошибок за счет авто-генерации типовых функциональных блоков, а также сократить время обучения новых сотрудников.
Ожидаемый эффект от внедрения целевого процесса разработки ЕФС – сокращение объема ручной разработки в два раза.
Практики DevOps были внедрены для всех приложений ЕФС. Использование DevOps сокращает время на обновление приложений и позволяет избежать ошибок ручной установки параметров. Покрытие кода автоматическими модульными тестами достигло 80%, что привело к снижению количества ошибок на этапе тестирования в два раза, заявляет Сбербанк.
Кроме этого, в 2017 году банк определил стандарт качества платформы ЕФС. Его выполнение контролируется по 12 метрикам. Использование стандарта вдвое сократило количество ошибок на этапе тестирования и позволило добиться того, что 50% ошибок устраняются в течение 8 часов.
Определены разработчики Единой фронтальной системы Сбербанка
Максимальная цена первого лота составляла 297 млн рублей, «Техносерв Консалтинг» предложила выполнить работы за 178,2 млн рублей.
Второй лот был оценен в 198 млн рублей. Сумма, за которую согласилась выполнить работу AT Consulting, составила 131,5 млн рублей.

Генеральным подрядчиком Сбербанка по созданию Единой фронтальной системы является компания «Сбербанк-Технологии».
К участию в закупке были приглашены компании, имеющие опыт реализации не менее трех проектов по разработке фронтальных систем в период с 2013 г. (при этом пользовательская аудитория проекта должна составлять не менее 10 000 пользователей). Участники конкурса должны иметь не менее 40 разработчиков со знаниями языка программирования Java, 20 системных аналитиков, 20 разработчиков со знанием языка программирования JavaScript, css, html и 5 архитекторов. Специалисты проектной команды участника должны обладать сертификатами Java Senior Specialist (не менее 10 специалистов) и Oracle Professional (не менее 1).
Отдельно в документации оговаривались максимальные ставки специалистов:
| № п/п | Роль в проекте | Стоимость оплаты чел./дня специалистов, руб. без НДС | Стоимость оплаты чел./дня специалистов, руб. с НДС |
| 1 | Главный разработчик | не более 18 980,00 | не более 22 396,40 |
| 2 | Ведущий аналитик/разработчик | не более 14 440,00 | не более 17 039,20 |
| 3 | Ведущий аналитик/Бизнес-аналитик | не более 14 440,00 | не более 17 039,20 |
| 4 | Аналитик/разработчик | не более 10 690,00 | не более 12 614,20 |
| 5 | Ведущий разработчик (Java Script) | не более 10 690,00 | не более 12 614,20 |
Общая оценка заявки участников зависела на 50% от предложенной стоимости выполнения работ и на 50% от качества выполнения тестового задания.
Задачи системы
В системе работают сотрудники отделений и колл-центра банка, клиенты мобильных приложений и интернет-банка (юр. и физлица), партнеры по продаже продуктов банка. Эта система предназначена и для управление банкоматами и терминалами самообслуживания.
Внедрение системы позволит обеспечить единый клиентский опыт за счет создания единой базы клиентов для всех каналов обслуживания. Начать взаимодействие можно будет через колл-центр банка, а продолжить, например, в интернет-банке или в отделении с того момента, на котором операция была прервана.
Еще одна задача ЕФС – ускорить вывод на рынок новых продуктов банка. В нынешних условиях, когда за управление интернет- и мобильным банком, процессингом, банкоматами, терминалами отвечают разные приложения, обновление услуг и продуктов Сбербанка (например, изменение ставки по вкладу) по всей стране может занимать несколько недель. Цель – сократить сроки до одного дня.
Также, как ожидается, ЕФС позволит сократить время проведения операций, упростить интерфейс сотрудников отделений, ускорить адаптацию к работе новичков, снизить количество ошибок.
Руководство программы ЕФС
В конце 2018 года руководителем программы «Единая фронтальная система» стал Алексей Поддубный. По информации TAdviser, он был назначен на эту должность после того, как из Сбербанка ушла Елена Батурова, которая ранее руководила проектом ЕФС, а также Вадим Шаробаев, который под ее руководством отвечал за этот проект в Сбертехе. Подробнее здесь.



