Русский – MSI B85M-G43 User Manual
Page 164

Параметр будет настроен автоматически с помощью BIOS.
Определяет состояние простоя системы и значительно
сокращает энергопотребление процессором.
[Disabled] Выключение функции.
C1E Support [Disabled]
Включение или выключение функции C1E для энергосбережения в состоянии
остановки. Этот элемент появляется при включении “Intel C-State”.
Включение функции C1E для снижения частоты и напряжения
процессора для энергосбережения в состоянии остановки.
Package C State limit [Auto]
Данный параметр позволяет выбрать режим C-state для энергосбережения
при простое системы. Этот элемент появляется при включении “Intel C-State”.
Параметр будет настроен автоматически с помощью BIOS.
Уровни энергосбережения от высокого к низкому (C7s, C7, C6,
Не ограничивать C-state процессора.
LakeTiny Feature [Disabled]
Включение или выключение технологии Intel Lake Tiny с iRST для SSD. Этот
элемент появляется, когда установленный процессор поддерживает данную
функцию и при включении “Intel C-State”.
Повышение динамической нагрузки IO скорректированной
производительности для ускорения скорости SSD.
Внимание: Следующие пункты появляются при включении “Intel Turbo Boost”.
Long Duration Power Limit (W) [Auto]
Настроить предельную мощность TDP на длительный срок для CPU в режиме
Long Duration Maintained (s) [Auto]
Настроить максимальное время работы процессора с ограничением
мощности при Long Duration Power Limit.
Short Duration Power Limit (W) [Auto]
Настроить предельную мощность TDP на короткий срок для процессора в
режиме Turbo Boost.
CPU Current limit (A) [Auto]
Устанавливает текущий максимальный предел тока в режиме Turbo
Boost. Когда текущий ток превышает указанный предел, процессор будет
автоматически снижать частоты ядра для уменьшения тока.
1/2/3/4-Core Ratio Limit [Auto]
Эти пункты появляются, только если процессор поддерживает данную
функцию. Эти элементы позволяют устанавливать процессорные
множители в различных ядрах в режиме turbo boost. Пункты доступны, когда
установленный процессор поддерживает эту функцию.
Обзор и тестирование твердотельного накопителя Silicon Power Slim S55 240GB с интерфейсом SATA 6 Гбит/с
Тестовый стенд
В качестве соперников в тестах быстродействия для Silicon Power Slim S55 240GB выступили два запоминающих устройства: GoodRAM C100 Series 120GB, построенный на базе контроллера Phison PS3108-S8, а также ADATA SX900 256GB, который является типичным накопителем, в основе которого лежит платформа SandForce SF-2281. Конечно, такой выбор найдет немало противников, которые могут ссылаться на присутствие на рынке более современных и производительных решений, но, к сожалению, выбор конкурентов оказался очень ограниченным, что и обусловило перечень участников сегодняшнего тестирования, сводные характеристики которых приведены в следующей таблице:
Результаты тестирования
Для оценки скорости работы запоминающих устройств использовалась утилита AS SSD Benchmark. Прежде всего, были измерены скорости чтения при различных типах нагрузки.
В подтесте последовательного чтения оба накопителя на контроллере Phison показали одинаковые результаты, тогда как ADATA SX900 256GB немного отстал от своих соперников. При случайном чтении блоков размером 4К новичок занял второе место, уступив только GoodRAM C100 Series 120GB, тогда как SSD на платформе SandForce второго поколения продемонстрировал на 25% меньшую скорость работы. При формировании очереди глубиной в 64 запроса файла 4К в лидерах оказался накопитель на базе контроллера SF-2281, чуть худшие результаты у SSD GoodRAM, а Silicon Power Slim S55 240GB занял последнее место, но зато показал наименьшее время доступа при чтении. Очевидно, разница в результатах двух SSD, основанных на эталонном дизайне Phison, объясняется отличными версиями прошивки.
При выполнении операций последовательной записи и по части времени доступа Silicon Power Slim S55 240GB показал наилучшие результаты, за ним с заметным отставанием расположился накопитель GoodRAM, а самым медленным оказался SSD ADATA. Во время случайной записи блоков размером 4К ситуация прямо противоположная: лучше других выступил ADATA SX900 256GB, тогда как оба накопителя на базе Phison PS3108-S8 демонстрируют примерно равные результаты, что вызвано, скорее всего, конструктивными особенностями платформы, не лучшим образом оптимизированной для записи мелких файлов.
С помощью подпрограммы, входящей в состав AS SSD Benchmark также были измерены скорости копирования различных наборов файлов в пределах одного логического диска.
При выполнении тестовой трассы ISO, которая эмулирует перенос папки с образами оптических дисков, лучшие результаты показал GoodRAM C100 Series 120GB, а второе место с минимальным отставанием занял Silicon Power Slim S55 240GB, тогда как самую низкую скорость работы продемонстрировало запоминающее устройства ADATA. В подтесте копирования папки с установленными играми все три участника показали близкое быстродействие, а при перемещении директории с программами победил твердотельный накопитель на платформе SandForce, который даже в состоянии устоявшейся производительности демонстрирует отличную скорость записи мелких файлов.
Общий балл в подтесте Storage из комплексного тестового пакета PCMark 7 позволяет сравнить скорость работы накопителей при выполнении типичных повседневных задач. Здесь мы видим, что новичок продемонстрировал самые скромные показатели быстродействия.
При детальном анализе результатов, Silicon Power Slim S55 240GB проиграл почти во всех тестовых сценариях, за исключением импорта цифровых изображений, где уровень его быстродействия идентичен конкурентам.
Напоследок было проведена оценка в новейшем тестовом пакете PCMark 8, который также дает возможность оценить интегральный показатель производительности в прикладных программах.
Средний балл у всех трех участников практически одинаковый, но показатели средней пропускной способности все расставляют по своим местам. Лучше всех выступило запоминающее устройство GoodRAM, чуть худшие результаты у SSD ADATA, а наш новичок занял последнее место, причем, отставание от лидера составило почти 15%.
Выводы
Сегодня мы с вами познакомились с еще одним неплохим твердотельным накопителем Silicon Power Slim S55 240GB. Как в «синтетике», так и в большинстве тестовых сценариях, эмулирующих нагрузку от реальных приложений, новичок показал неплохое быстродействие, хотя SSD GoodRAM на такой же платформе Phison эталонного дизайна в отдельных случаях работал быстрее. Одной из самых сильных сторон запоминающего устройства Silicon Power, безусловно, является его невысокая стоимость, за которую можно простить и скромный комплект поставки, и небогатую программную поддержку со стороны вендора. В то же время, конкурентами накопителя выступают как продукты на базе SandForce второго поколения или альтернативных контроллерах JMicron, так и популярные модели Crucial на платформе Marvell, поэтому для повышения рыночной привлекательности вендору можно порекомендовать проводить еще более агрессивную ценовую политику. Таким образом, накопитель рекомендован к приобретению экономными пользователями, тогда как энтузиасты могут обратить свое внимание на другие модели.
Быстрый градиентный бустинг с CatBoost
Привет, хабровчане! Подготовили перевод статьи для будущих учеников базового курса Machine Learning.

В градиентном бустинге прогнозы делаются на основе ансамбля слабых обучающих алгоритмов. В отличие от случайного леса, который создает дерево решений для каждой выборки, в градиентном бустинге деревья создаются последовательно. Предыдущие деревья в модели не изменяются. Результаты предыдущего дерева используются для улучшения последующего. В этой статье мы подробнее познакомимся с библиотекой градиентного бустинга под названием CatBoost.
Источник
CatBoost — это библиотека градиентного бустинга, созданная Яндексом. Она использует небрежные (oblivious) деревья решений, чтобы вырастить сбалансированное дерево. Одни и те же функции используются для создания левых и правых разделений (split) на каждом уровне дерева.
Источник
По сравнению с классическими деревьями, небрежные деревья более эффективны при реализации на процессоре и просты в обучении.
Работа с категориальными признаками
Наиболее распространенными способами обработки категориальных данных в машинном обучении является one-hot кодирование и кодирование лейблов. CatBoost позволяет использовать категориальные признаки без необходимости их предварительно обрабатывать.
При использовании CatBoost мы не должны пользоваться one-hot кодированием, поскольку это влияет на скорость обучения и на качество прогнозов. Вместо этого мы просто задаем категориальные признаки с помощью параметра cat_features.
Преимущества использования CatBoost
Есть несколько причин подумать об использовании CatBoost:
Параметры обучения
Давайте рассмотрим общие параметры в CatBoost:
Пример с регрессией
CatBoost в своей реализации использует стандарт scikit-learn. Давайте посмотрим, как мы можем использовать его для регрессии.
Первый шаг, как всегда, импортировать регрессор и создать его экземпляр.
При обучении модели CatBoost также позволяет нам визуализировать его, установив plot=true:
Также мы можем выполнять кроссвалидацию и визуализировать процесс:
Аналогично вы можете выполнить grid search и визуализировать его:
Также мы можем использовать CatBoost для построения дерева. Вот график первого дерева. Как вы видите из дерева, листья разделяются при одном и том же условии, например, 297, значение > 0.5.
CatBoost дает нам словарь со всеми параметрами модели. Мы можем вывести их, как словарь.
В этой статье мы рассмотрели преимущества и ограничения CatBoost, а также ее основные параметры обучения. Затем мы реализовали простую регрессию с помощью scikit-learn. Надеюсь, вы получили достаточно информации об этой библиотеке, чтобы самостоятельно продолжить ее исследование.
📊 Построение и отбор признаков. Часть 1: feature engineering

Alex Maszański

Что такое признаки (features) и для чего они нужны?
Признаки могут быть следующих видов:
Стоит отметить, что для задач машинного обучения нужны только те «фичи», которые на самом деле влияют на итоговый результат. Определить и сгенерировать такие признаки вам поможет эта статья.
Что такое построение признаков?
Например, в базе данных интернет-магазина есть таблица «Покупатели», содержащая одну строку для каждого посетившего сайт клиента.

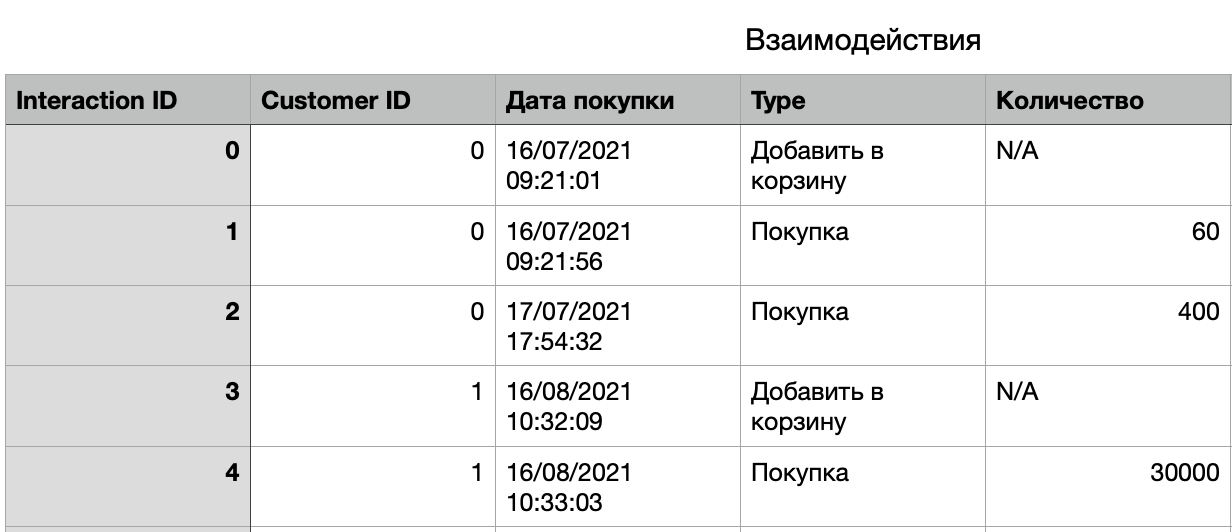
Чтобы повысить предсказательную способность, нам необходимо воспользоваться данными в таблице взаимодействий. Отбор признаков делает это возможным. Мы можем рассчитать статистику для каждого клиента, используя все значения в таблице «Взаимодействия» с идентификатором этого клиента. Вот несколько потенциально полезных признаков, или же «фич», которые помогут нам в решении задачи:
Следует обратить внимание, что данный процесс уникален для каждого случая использования и набора данных.
Этот тип инжиниринга признаков необходим для эффективного использования алгоритмов машинного обучения и построения прогностических моделей.
Построение признаков на табличных данных
Удаление пропущенных значений
Отсутствующие значения – одна из наиболее распространенных проблем, с которыми вы можете столкнуться при попытке подготовить данные. Этот фактор очень сильно влияет на производительность моделей машинного обучения.
Самое простое решение для пропущенных значений – отбросить строки или весь столбец. Оптимального порога для отбрасывания не существует, но вы можете использовать 70% в качестве значения и отбросить строки со столбцами, в которых отсутствуют значения, превышающие этот порог.
Заполнение пропущенных значений
В качестве другого примера: у вас есть столбец, который показывает количество посещений клиентов за последний месяц. Тут отсутствующие значения могут быть заменены на 0.
За исключением вышеперечисленного, лучший способ заполнения пропущенных значений – использовать медианы столбцов. Поскольку средние значения столбцов чувствительны к значениям выбросов, медианы в этом отношении будут более устойчивыми.
Замена пропущенных значений максимальными
Замена отсутствующих значений на максимальное значение в столбце будет хорошим вариантом для работы только в случае, когда мы разбираемся с категориальными признаками. В других ситуациях настоятельно рекомендуется использовать предыдущий метод.
Обнаружение выбросов
Другой математический метод обнаружения выбросов – использование процентилей. Вы принимаете определенный процент значения сверху или снизу за выброс.
Ключевым моментом здесь является повторная установка процентного значения, и это зависит от распределения ваших данных, как упоминалось ранее.
Ограничение выбросов
С другой стороны, ограничение может повлиять на распределение данных и качество модели, поэтому лучше придерживаться золотой середины.
Логарифмическое преобразование
Важное примечание: данные, которые вы применяете, должны иметь только положительные значения, иначе вы получите ошибку.
Быстрое кодирование (One-Hot encoding)
Этот метод распределяет значения в столбце по нескольким столбцам флагов и присваивает им 0 или 1. Бинарные значения выражают связь между сгруппированным и закодированным столбцом. Этот метод изменяет ваши категориальные данные, которые сложно понять алгоритмам, в числовой формат. Группировка происходит без потери какой-либо информации, например:
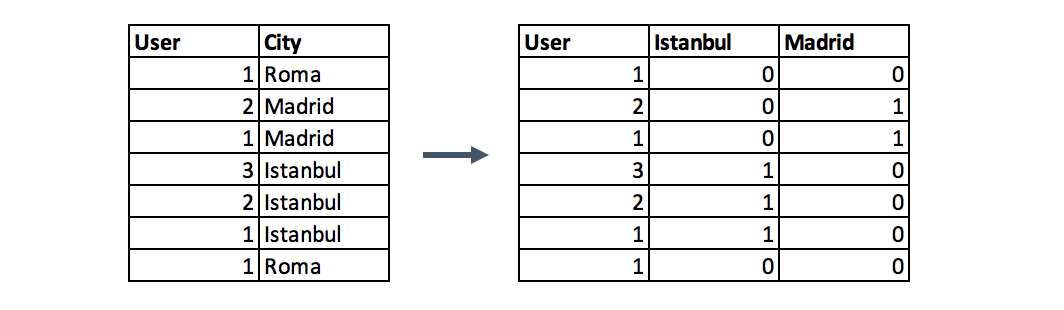
Приведенная ниже функция отражает использование метода быстрого кодирования с вашими данными.
Масштабирование признаков
В большинстве случаев числовые характеристики набора данных не имеют определенного диапазона и отличаются друг от друга.
Например, столбцы возраста и месячной зарплаты будут иметь совершенно разный диапазон.
Как сравнить эти два столбца, если это необходимо в нашей задаче? Масштабирование решает эту проблему, так как после данной операции элементы становятся идентичными по диапазону.
Существует два распространенных способа масштабирования:
В данном случае все значения будут находиться в диапазоне от 0 до 1. Дискретные бинарные значения определяются как 0 и 1.
Масштабирует значения с учетом стандартного отклонения. Если стандартное отклонение функций другое, их диапазон также будет отличаться друг от друга. Это снижает влияние выбросов в элементах. В следующей формуле стандартизации среднее значение показано как μ, а стандартное отклонение показано как σ.
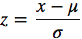
Работа с текстом
Перед тем как работать с текстом, его необходимо разбить на токены – отдельные слова. Однако делая это слишком просто, мы можем потерять часть смысла. Например, «Великие Луки» это не два токена, а один.
В коде алгоритм выглядит гораздо проще, чем на словах:
Работа с изображениями
Чтобы адаптировать ее под свою задачу, работающие в области науки о данных инженеры практикуют fine tuning (тонкую настройку). Ликвидируются последние слои нейросети, вместо них добавляются новые, подобранные под нашу конкретную задачу, и сеть дообучается на новых данных.
Пример подобного шаблона:
Заключение
На практике процесс построения фич может быть самым разнообразным: решение проблемы пропущенных значений, обнаружение выбросов, превращение текста в вектор (с помощью продвинутой обработки естественного языка, которая отображает слова в векторное пространство) – лишь некоторые примеры из этой области.
Feature engineering: шесть шагов для создания успешной модели машинного обучения
Исследования в области машинного обучения приводят к созданию новых алгоритмов и методик. Даже такой метод, как feature engineering, существующий уже несколько десятилетий, постоянно обновляется. Команды разработчиков должны постоянно учиться и прокачивать свои навыки, генерируя новые подходы в машинном обучении. «Хайтек» перевел и дополнил статью VentureBeat, чтобы рассказать о современных методиках в feature engineering и дать советы разработчикам по созданию моделей с добавленной стоимостью.
Читайте «Хайтек» в
Метод feature engineering так же стар, как и data science. Но почему-то он становится все более забытым. Высокий спрос на машинное обучение вызвал ажиотаж среди ученых-исследователей. Сегодня у них огромный опыт создания инструментов и алгоритмов. Но у них недостаточно отраслевых знаний, требуемых для feature engineering. Исследователи пытаются компенсировать это инструментами и алгоритмами. Однако алгоритмы теперь являются лишь товаром и сами по себе не генерируют корпоративное IP-портфолио (портфель интеллектуальных прав, принадлежащих компании — «Хайтек»).

Feature engineering (с англ. «создание показателей, признаков») — техника решения задач машинного обучения, позволяющая увеличить качество разрабатываемых алгоритмов. Предусматривает превращение данных, специфических для предметной области, в понятные для модели векторы. Чтобы эффективно решить задачу с feature engineering, необходимо быть экспертом в конкретной области и понимать, что влияет на конкретную целевую переменную. Поэтому многие разработчики называют feature engineering искусством, требующим решения большого количества задач и наработки опыта.
Сегодня такие стартапы, как ContextRelevant и SparkBeyond, разрабатывают новые инструменты, которые упростят для пользователей процесс создания и отбора показателей (feature selection).
Обобщенные данные тоже становятся товаром, а облачные сервисы машинного обучения (MLaaS), такие, как Amazon ML и Google AutoML, теперь позволяют даже менее опытным членам команды запускать модели данных и получать их прогнозы в течение нескольких минут. Но в результате этого набирают обороты те компании, которые развивают организационную компетенцию в сборе или изготовлении собственных данных, создаваемых при feature engineering. Простого сбора данных и построения моделей уже недостаточно.
Корпорации многому учатся у победителей соревнований по моделированию, таких как KDD Cup и Heritage Provider Network Health Prize. Своими успехами они обязаны именно грамотному подходу к методу feature engineering.

Ян Лекун, Facebook: прогностические модели мира — решающее достижение в ИИ
Методы feature engineering
Для техники feature engineering ученые разработали ряд методов.
Контекстная трансформация. Он включает в себя преобразование отдельных функций из исходного набора в более контекстуально значимую информацию для каждой конкретной модели.
Например, при использовании категориальной функции в качестве «неизвестного» может быть специальная информация в контексте ситуации. Но внутри модели это выглядит, как просто другое значение категории. В этом случае можно ввести новую двоичную функцию has_value, чтобы отделить «неизвестное» от всех других опций. Например, функция color позволит ввести has_color для какого-то неизвестного цвета.
Команды машинного обучения часто используют биннинг для разбивания отдельных функций на несколько для лучшего понимания. Например, разделение функции «возраст» на «молодой» для 60 лет.
Биннинг, или балансировка данных — метод предварительной обработки, используемый для уменьшения влияния незначительных ошибок наблюдения. Исходные значения данных, которые попадают в небольшой интервал, заменяются значением, представляющим этот интервал, часто центральным значением. Это форма квантования.
Некоторые другие примеры преобразований:
Многофункциональная арифметика. Другой подход к feature engineering заключается в применении арифметических формул к набору существующих точек данных. Такие формулы создают производные, основанные на взаимодействии между функциями и их отношениях друг к другу.
Построение с многофункциональной арифметикой — очень выгодно, но оно требует полного понимания предмета и целей модели.
Примеры использования формул:

Джианкарло Суччи: «Попытка спроектировать программу без багов — утопия»



