Зачем процессорам нужен кэш и чем отличаются уровни L1, L2, L3

Во всех центральных процессорах любого компьютера, будь то дешёвый ноутбук или сервер за миллионы долларов, есть устройство под названием «кэш». И с очень большой вероятностью он обладает несколькими уровнями.
Наверно, он важен, иначе зачем бы его устанавливать? Но что же делает кэш, и для чего ему разные уровни? И что означает «12-канальный ассоциативный кэш» (12-way set associative)?
Что такое кэш?
TL;DR: это небольшая, но очень быстрая память, расположенная в непосредственной близости от логических блоков центрального процессора.
Однако мы, разумеется, можем узнать о кэше гораздо больше…
Давайте начнём с воображаемой волшебной системы хранения: она бесконечно быстра, может одновременно обрабатывать бесконечное количество операций передачи данных и всегда обеспечивает надёжное и безопасное хранение данных. Конечно же, ничего подобного и близко не существует, однако если бы это было так, то структура процессора была бы гораздо проще.
Процессорам бы тогда требовались только логические блоки для сложения, умножения и т.п, а также система управления передачей данных, ведь наша теоретическая система хранения способна мгновенно передавать и получать все необходимые числа; ни одному из логических блоков не приходится простаивать в ожидании передачи данных.
Но, как мы знаем, такой волшебной технологии хранения не существует. Вместо неё у нас есть жёсткие диски или твердотельные накопители, и даже самые лучшие из них далеки от возможностей обработки, необходимых для современного процессора.

Великий Т’Фон хранения данных
Причина этого заключается в том, что современные процессоры невероятно быстры — им требуется всего один тактовый цикл для сложения двух 64-битных целочисленных значений; если процессор работает с частотой 4 ГГЦ, то это составляет всего 0,00000000025 секунды, или четверть наносекунды.
В то же время, вращающемуся жёсткому диску требуются тысячи наносекунд только для нахождения данных на дисках, не говоря уже об их передаче, а твердотельным накопителям — десятки или сотни наносекунд.
Очевидно, что такие приводы невозможно встроить внутрь процессоров, поэтому между ними будет присутствовать физическое разделение. Поэтому ещё добавляется время на перемещение данных, что усугубляет ситуацию.
Увы, но это Великий А’Туин хранения данных
Именно поэтому нам нужна ещё одна система хранения данных, расположенная между процессором и основным накопителем. Она должна быть быстрее накопителя, способна одновременно управлять множеством операций передачи данных и находиться намного ближе к процессору.
Ну, у нас уже есть такая система, и она называется ОЗУ (RAM); она присутствует в каждом компьютере и выполняет именно эту задачу.
Почти все такие хранилища имеют тип DRAM (dynamic random access memory); они способны передавать данные гораздо быстрее, чем любой накопитель.
Однако, несмотря на свою огромную скорость, DRAM не способна хранить такие объёмы данных.
Одни из самых крупных чипов памяти DDR4, разработанных Micron, хранят 32 Гбит, или 4 ГБ данных; самые крупные жёсткие диски хранят в 4 000 раз больше.
Итак, хоть мы и повысили скорость нашей сети данных, нам потребуются дополнительные системы (аппаратные и программные), чтобы разобраться, какие данные должны храниться в ограниченном объёме DRAM, готовые к обработке процессором.
DRAM могут изготавливаться в корпусе чипа (это называется встроенной (embedded) DRAM). Однако процессоры довольно малы, поэтому в них не удастся поместить много памяти.

10 МБ DRAM слева от графического процессора Xbox 360. Источник: CPU Grave Yard
Подавляющее большинство DRAM расположено в непосредственной близости от процессора, подключено к материнской плате и всегда является самым близким к процессору компонентом. Тем не менее, эта память всё равно недостаточно быстра…
DRAM требуется примерно 100 наносекунд для нахождения данных, но, по крайней мере, она способна передавать миллиарды битов в секунду. Похоже, нам нужна ещё одна ступень памяти, которую можно разместить между блоками процессора и DRAM.
На сцене появляется оставшаяся ступень: SRAM (static random access memory). DRAM использует микроскопические конденсаторы для хранения данных в виде электрического заряда, а SRAM для той же задачи применяет транзисторы, которые работают с той же скоростью, что и логические блоки процессора (примерно в 10 раз быстрее, чем DRAM).
Разумеется, у SRAM есть недостаток, и он опять-таки связан с пространством.
Память на основе транзисторов занимает гораздо больше места, чем DRAM: в том же размере, что чип DDR4 на 4 ГБ, можно получить меньше 100 МБ SRAM. Но поскольку она производится по тому же технологическому процессу, что и CPU, память SRAM можно встроить прямо внутрь процессора, максимально близко к логическим блокам.
С каждой дополнительной ступенью мы увеличивали скорость перемещаемых данных ценой хранимого объёма. Мы можем продолжить и добавлять новые ступени,, которые будут быстрее, но меньше.
И так мы добрались до более строгого определения понятия кэша: это набор блоков SRAM, расположенных внутри процессора; они обеспечивают максимальную занятость процессора благодаря передаче и сохранению данных с очень высокими скоростями. Вас устраивает такое определение? Отлично, потому что дальше всё будет намного сложнее!
Кэш: многоуровневая парковка
Как мы говорили выше, кэш необходим, потому что у нас нет волшебной системы хранения, способной справиться с потреблением данных логических блоков процессора. Современные центральные и графические процессоры содержат множество блоков SRAM, внутри упорядоченных в иерархию — последовательность кэшей, имеющих следующую структуру:
На приведённом выше изображении процессор (CPU) обозначен прямоугольником с пунктирной границей. Слева расположены ALU (arithmetic logic units, арифметико-логические устройства); это структуры, выполняющие математические операции. Хотя строго говоря, они не являются кэшем, ближайший к ALU уровень памяти — это регистры (они упорядочены в регистровый файл).
Каждый из них хранит одно число, например, 64-битное целое число; само значение может быть элементом каких-нибудь данных, кодом определённой инструкции или адресом памяти каких-то других данных.
Регистровый файл в десктопных процессорах довольно мал, например, в каждом из ядер Intel Core i9-9900K есть по два банка таких файлов, а тот, который предназначен для целых чисел, содержит всего 180 64-битных целых чисел. Другой регистровый файл для векторов (небольших массивов чисел) содержит 168 256-битных элементов. То есть общий регистровый файл каждого ядра чуть меньше 7 КБ. Для сравнения: регистровый файл потоковых мультипроцессоров (так в GPU называются аналоги ядер CPU) Nvidia GeForce RTX 2080 Ti имеет размер 256 КБ.
Регистры, как и кэш, являются SRAM, но их скорость не превышает скорость обслуживаемых ими ALU; они передают данные за один тактовый цикл. Но они не предназначены для хранения больших объёмов данных (только одного элемента), поэтому рядом с ними всегда есть более крупные блоки памяти: это кэш первого уровня (Level 1).

Одно ядро процессора Intel Skylake. Источник: Wikichip
На изображении выше представлен увеличенный снимок одного из ядер десктопного процессора Intel Skylake.
ALU и регистровые файлы расположены слева и обведены зелёной рамкой. В верхней части фотографии белым обозначен кэш данных первого уровня (Level 1 Data cache). Он не содержит много информации, всего 32 КБ, но как и регистры, он расположен очень близко к логическим блокам и работает на одной скорости с ними.
Ещё одним белым прямоугольником справа показан кэш инструкций первого уровня (Level 1 Instruction cache), тоже имеющий размер 32 КБ. Как понятно из названия, в нём хранятся различные команды, готовые к разбиению на более мелкие микрооперации (обычно обозначаемые μops), которые должны выполнять ALU. Для них тоже существует кэш, который можно классифицировать как Level 0, потому что он меньше (содержит всего 1 500 операций) и ближе, чем кэши L1.
Вы можете задаться вопросом: почему эти блоки SRAM настолько малы? Почему они не имеют размер в мегабайт? Вместе кэши данных и инструкций занимают почти такую же площадь на чипе, что основные логические блоки, поэтому их увеличение приведёт к повышению общей площади кристалла.
Но основная причина их размера в несколько килобайт заключается в том, что при увеличении ёмкости памяти повышается время, необходимое для поиска и получения данных. Кэшу L1 нужно быть очень быстрым, поэтому необходимо достичь компромисса между размером и скоростью — в лучшем случае для получения данных из этого кэша требуется около 5 тактовых циклов (для значений с плавающей запятой больше).

Кэш L2 процессора Skylake: 256 КБ SRAM
Но если бы это был единственный кэш внутри процессора, то его производительность наткнулась бы на неожиданное препятствие. Именно поэтому в ядра встраивается еще один уровень памяти: кэш Level 2. Это обобщённый блок хранения, содержащий инструкции и данные.
Он всегда больше, чем Level 1: в процессорах AMD Zen 2 он занимает до 512 КБ, чтобы кэши нижнего уровня обеспечивались достаточным объёмом данных. Однако большой размер требует жертв — для поиска и передачи данных из этого кэша требуется примерно в два раза больше времени по сравнению с Level 1.
Во времена первого Intel Pentium кэш Level 2 был отдельным чипом, или устанавливаемым на отдельной небольшой плате (как ОЗУ DIMM), или встроенным в основную материнскую плату. Постепенно он перебрался в корпус самого процессора, и, наконец, полностью интегрировался в кристалл чипа; это произошло в эпоху таких процессоров, как Pentium III и AMD K6-III.
За этим достижением вскоре последовал ещё один уровень кэша, необходимый для поддержки более низких уровней, и появился он как раз вовремя — в эпоху расцвета многоядерных чипов.

Чип Intel Kaby Lake. Источник: Wikichip
На этом изображении чипа Intel Kaby Lake в левой части показаны четыре ядра (интегрированный GPU занимает почти половину кристалла и находится справа). Каждое ядро имеет свой «личный» набор кэшей Level 1 и 2 (выделены белыми и жёлтым прямоугольниками), но у них также есть и третий комплект блоков SRAM.
Кэш третьего уровня (Level 3), хоть и расположен непосредственно рядом с одним ядром, является полностью общим для всех остальных — каждое ядро свободно может получать доступ к содержимому кэша L3 другого ядра. Он намного больше (от 2 до 32 МБ), но и намного медленнее, в среднем более 30 циклов, особенно когда ядру нужно использовать данные, находящиеся в блоке кэша, расположенного на большом расстоянии.
Ниже показано одно ядро архитектуры AMD Zen 2: кэши Level 1 данных и инструкций по 32 КБ (в белых прямоугольниках), кэш Level 2 на 512 КБ (в жёлтых прямоугольниках) и огромный блок кэша L3 на 4 МБ (в красном прямоугольнике).

Увеличенный снимок одного ядра процессора AMD Zen 2. Источник: Fritzchens Fritz
Но постойте: как 32 КБ могут занимать больше физического пространства чем 512 КБ? Если Level 1 хранит так мало данных, почему он непропорционально велик по сравнению с кэшами L2 и L3?
Не только числа
Кэш повышает производительность, ускоряя передачу данных в логические блоки и храня поблизости копию часто используемых инструкций и данных. Хранящаяся в кэше информация разделена на две части: сами данные и место, где они изначально располагаются в системной памяти/накопителе — такой адрес называется тег кэша (cache tag).
Когда процессор выполняет операцию, которой нужно считать или записать данные из/в память, то он начинает с проверки тегов в кэше Level 1. Если нужные данные там есть (произошло кэш-попадание (cache hit)), то доступ к этим данным выполняется почти сразу же. Промах кэша (cache miss) возникает, если требуемый тег не найден на самом нижнем уровне кэша.
В кэше L1 создаётся новый тег, а за дело берётся остальная часть архитектуры процессора выполняющая поиск в других уровнях кэша (при необходимости вплоть до основного накопителя) данных для этого тега. Но чтобы освободить пространство в кэше L1 под этот новый тег, что-то обязательно нужно перебросить в L2.
Это приводит к почти постоянному перемешиванию данных, выполняемому всего за несколько тактовых циклов. Единственный способ добиться этого — создание сложной структуры вокруг SRAM для обработки управления данными. Иными словами, если бы ядро процессора состояло всего из одного ALU, то кэш L1 был бы гораздо проще, но поскольку их десятки (и многие из них жонглируют двумя потоками инструкций), то для перемещения данных кэшу требуется множество соединений.
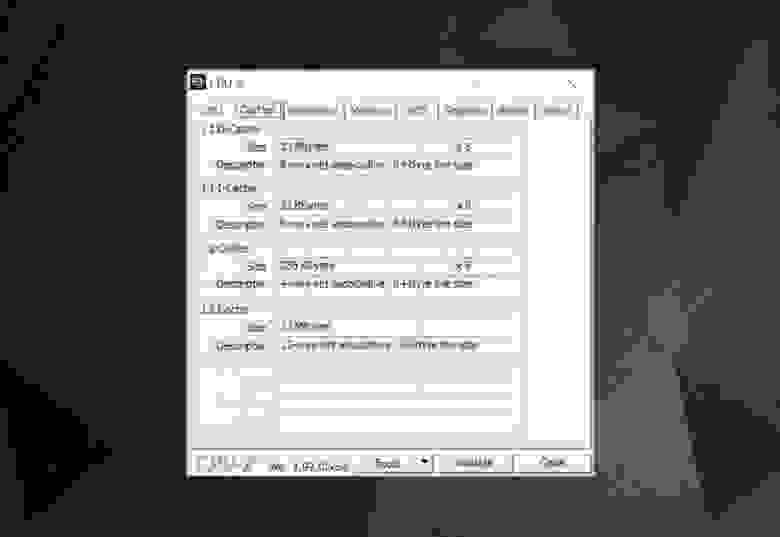
Для изучения информации кэша в процессоре вашего компьютера можно использовать бесплатные программы, например CPU-Z. Но что означает вся эта информация? Важным элементом является метка set associative (множественно-ассоциативный) — она указывает на правила, применяемые для копирования блоков данных из системной памяти в кэш.
Представленная выше информация кэша относится к Intel Core i7-9700K. Каждый из его кэшей Level 1 разделён на 64 небольших блока, называемые sets, и каждый из этих блоков ещё разбит на строки кэша (cache lines) (размером 64 байта). «Set associative» означает, что блок данных из системы привязывается к строкам кэша в одном конкретном сете, и не может свободно привязываться к какому-то другому месту.
«8-way» означает, что один блок может быть связан с 8 строками кэша в сете. Чем выше уровень ассоциативности (т.е. чем больше «way»), тем больше шансов на кэш-попадание во время поиска процессором данных и тем меньше потери, вызываемые промахами кэша. Недостатки такой системы заключаются в повышении сложности и энергопотребления, а также понижении производительности, потому что для каждого блока данных нужно обрабатывать больше строк кэша.

Инклюзивный кэш L1+L2, victim cache L3, политики write-back, есть даже ECC. Источник: Fritzchens Fritz
Ещё один аспект сложности кэша связан с тем, как хранятся данные между разными уровнями. Правила задаются в inclusion policy (политике инклюзивности). Например, процессоры Intel Core имеют полностью инклюзивные кэши L1+L3. Это означает, что одни данные в Level 1, например, могут присутствовать в Level 3. Может показаться, что это пустая трата ценного пространства кэша, однако преимущество заключается в том, что если процессор совершает промах при поиске тега в нижнем уровне, ему не потребуется обыскивать верхний уровень для нахождения данных.
В тех же самых процессорах кэш L2 неинклюзивен: все хранящиеся там данные не копируются ни на какой другой уровень. Это экономит место, но приводит к тому, что системе памяти чипа нужно искать ненайденный тег в L3 (который всегда намного больше). Victim caches (кэши-жертвы) имеют похожий принцип, но они используются для хранения информации, переносимой с более низких уровней. Например, процессоры AMD Zen 2 используют victim cache L3, который просто хранит данные из L2.
Существуют и другие политики для кэша, например, при которых данные записываются и в кэш, и основную системную память. Они называются политиками записи (write policies); большинство современных процессоров использует кэши write-back — это означает, что когда данные записываются на уровень кэшей, происходит задержка перед записью их копии в системную память. Чаще всего эта пауза длится в течение того времени, пока данные остаются в кэше — ОЗУ получает эту информацию только при «выталкивании» из кэша.

Графический процессор Nvidia GA100, имеющий 20 МБ кэша L1 и 40 МБ кэша L2
Для проектировщиков процессоров выбор объёма, типа и политики кэшей является вопросом уравновешивания стремления к повышению мощности процессора с увеличением его сложности и занимаемым чипом пространством. Если бы можно было создать 1000-канальные ассоциативные кэши Level 1 на 20 МБ такими, чтобы они при этом не занимали площадь Манхэттена (и не потребляли столько же энергии), то у нас у всех бы были компьютеры с такими чипами!
Самый нижний уровень кэшей в современных процессорах за последнее десятилетие практически не изменился. Однако кэш Level 3 продолжает расти в размерах. Если бы десять лет назад у вас было 999 долларов на Intel i7-980X, то вы могли бы получить кэш размером 12 МБ. Сегодня за половину этой суммы можно приобрести 64 МБ.
Подведём итог: кэш — это абсолютно необходимое и потрясающее устройство. Мы не рассматривали другие типы кэшей в CPU и GPU (например, буферы ассоциативной трансляции или кэши текстур), но поскольку все они имеют такую же простую структуру и расположение уровней, разобраться в них будет несложно.
Был ли у вас компьютер с кэшем L2 на материнской плате? Как насчёт слотовых Pentium II и Celeron (например, 300a) на дочерних платах? Помните свой первый процессор с общим L3?
На правах рекламы
Наша компания предлагает в аренду серверы с процессорами от Intel и AMD. В последнем случае — это эпичные серверы! VDS с AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
BIOS M3A32-MVP Deluxe
В данной статье я собрал информацию о некоторых настройках BIOS материнской платы M3A32-MVP Deluxe. А точнее о тех из них, которые интересны при разгоне. Все, что сказано ниже не является абсолютной истиной и было собрано из различных источников, в большинстве своем англоязычных. Поэтому выношу этот материал на обсуждение. Тем более, что сам хотел бы узнать побольше о некоторых опциях. Личное мнение от использования тех или иных настроек я записывал под знаком *. Вот подходящая ветка на оверах, где можно и нужно обсудить данный материал. Осталось добавить, что на данной МП я разгонял Athlon 64 x2 4400+ Brisbane, поэтому, возможно список опций неполный по сравнению с использованием Phenom-ов.
Jumper Free Configuration
AI Overclocking [Manual]
Установка значения Manual открывает Вашему взору следующие опции:
FSB Frequency [200-600 MHz]
Значение, которое наряду с множителем задает устанавливает частоту процессора. Например, 200 FSB x 11 = 2.2 Ггц.
PCIE Frequency [100-150 MHz]
Рекомендуется устанавливать не более 115-118 МГц, при этом можно добиться небольшого увеличения производительности в 3D-приложениях. Установка значений превышающие данные может вызвать проблемы в работе южного и северного мостов и, как следствие, проблемы в работе периферии и жестких дисков, но кого этим испугаешь 😉
Processor Frequency Multiplier [x4 — x11,5]
В режиме AI Overclocking Auto BIOS устанавливает заданную по умолчанию частоту CPU. В режиме Manual можно задать множитель из приведенного интервала.
Processor Voltage [0,8-1,6875 v]
Устанавливается с шагом 0,0125v.
* Минимальное напряжение на котором процессор (вышеназванный Athlon) завелся и даже прошел 30 мин. тест стабильности ОССТ 2.0.0 было 1,025v. В CPU-Z 1.44 значение напряжения сильно занижено по сравнению с выставленным в BIOS (разница 0,017v). SpeedFan напряжение показывает такое же как и в BIOS с округлением до 2-го знака. В Everest тоже. Видимо брешет CPU-Z. Значения более 1,6v подсвечиваются красным и увеличение с 1,6 вплоть до 1,6875v прироста в разгоне и стабильности не приносит.
CPU-NB HT Link Speed [200-1000MHz]
Частота HT для Phenom-ов от 200 до 2200МНz
CPU VDDA Voltage [2,5-2,8v]
* Толкового объяснения в русскоязычном интернете не нашел. По поиску нашел на одном из англоязычных форумов объяснение, что этот параметр устанавливает схему регулирования центрального процессора и манипуляциями с ним можно добиться стабильности при разгоне. Проверил, действительно, на комп на пределе разгона (проц Athlon 64 x2 Brisbane 4400+ @ 3300Гц 1,6v) при значении данной опции 2,5v грузился через раз, а при установке ее в 2,8v он у меня прошел SuperPi32M, правда, ОССТ не выдержал. При этом, помогло именно значение 2,8v, с 2,6 и 2,7 была та же картина, что и с 2,5.
DDR Voltage [1,8-2,5v]
* устанавливается с шагом 0,02v. Значения 2,2v и выше подсвечиваются красным.
NorthBridge Voltage [Manual]
Данная установка открывает следующие опции:
Hyper Transport Voltage [1,2-1,5v]
Выставляет напряжение на шине Hyper Transport.
* При разгоне ставил 1,3v.
Southbridge Voltage [1,2-1,4v]
* При разгоне выставил 1,3v.
Auto Xpress [Auto, Enabled, Disabled]
Про эту опцию можно сказать следующее:
Уже в случае с AMD 790X, впрочем, перечень характеристик пополняется за счет Auto Xpress (автоматическое увеличение рабочей частоты шины PCI Express при установке видеокарт AMD на платы с чипсетом AMD; использование специальных режимов работы с DDR2 памятью), GPU-Plex, Quad PCIE Blocks и CrossFireX. Последняя технология особо интересна тем, что отныне в режиме CrossFire могут быть объединены три или даже четыре графических адаптера AMD. Перечень CrossFireX-совместимых видеокарт на данный момент состоит из решений AMD поколения Radeon HD 3800. При производстве новых чипсетов компании был использован 65 нм техпроцесс. Энергопотребление данных наборов системной логики составляет 10-12 Вт (TDP).
Будучи объединенными вместе, все вышеперечисленные компоненты (процессоры Phenom, чипсеты AMD 7, адаптеры Radeon HD 3800 и технология CrossFireX) составляют новую платформу для «энтузиастов» под названием AMD «Spider».
CPU Tweak [Enabled, Disabled]
В BIOS от Asus так называется TLB-патч для процессоров Phenom.
Bank Interleaving [Auto, Disabled]
Включение этого режима позволяет работать с банками по очереди, то есть получать данные из одного в то время, когда другие заняты. Причем выбор значения 2-Way позволяет чередовать пару банков, а 4-Way – четыре банка (они есть у большинства микросхем DIMM-модулей), а это, конечно, выгоднее.
* В тесте памяти Everest с данной опцией Disabled результат снижается на
2,5% по сравнению с Auto.
Channel Interleaving
* У меня эта опция была в BIOS версии 0801, с которой она и продавалась. После прошивки до последней версии 1102 я ее не обнаружил.
DCT Unganged Mode [Enabled, Disabled]
При установке Disabled чипсет должен работать с памятью частотой до 800МГц. Enabled позволяет включить делитель для памяти 1066МГц. Это можно сделать при установке процессоров Phenom.
Read Delay [0,5-4 memory CLKs]
Это поле определяет задержку от включения DQS ресивера до начала чтения первых данных с клавиатуры, получаемых FIFO.
000b = 0.5 Memory Clocks
001b = 1 Memory Clock
010b = 1.5 Memory Clocks
011b = 2 Memory Clocks
100b = 2.5 Memory Clocks
101b = 3 Memory Clock
110b = 3.5 Memory Clocks
111b = 4 Memory Clocks
Прямая корреляция w/memory’s время ожидания. Чем ниже установка, тем ниже время ожидания.
* Со значением 0,5 комп не стартовал, сброс CMOS. С 1 стартует, но пишет что-то вроде ошибки при проверке DRAM. Нормальный запуск при 1,5. В бенчмарке памяти и кэша Everest прирост по сравнению с настройками по умолчанию: по Read — 1,9%; по Copy — 0,5%; по Latency — уменьшение времени доступа на 2,8 ns. По Write изменений нет.
Memory Clock Tristate C3/ALTVID [Enabled, Disabled]
Позволяет частоте памяти DDR быть в трех состояниях (tristated), когда включен дополнительный режим VID. Этот бит не имеет никакого эффекта если установлен бит DisNbClkRamp (Function 3, Offset 88h).
Power Down Enable [Enabled, Disabled]
Если данный режим активирован, то после ввода включения режима Sleep Mode, главному внутреннему тактовому генератору запрещено передавать сигнал на чип устройства. При этом большая часть связанной схемы может отключена от питания для сохранения энергии.
DCQ Bypass Maximu [0x-14x]
Управляющий контроллер обычно позволяет производить за проход другие операции по порядку, чтобы оптимизировать пропускную способность DRAM. Это поле определяет максимальное количество раз, которое самый старый запрос доступа к памяти в очереди контроллера DRAM может быть отложен перед выполнением, и самый старый запрос доступа к памяти будет выполнен вместо другого.
0000b = Никогда не откладывается; самый старый запрос никогда не откладывается.
0001b = самый старый запрос может быть отложен не больше, чем 1 раз.
1111b = самый старый запрос может быть отложен не больше, чем 15 раз.
* оптимальное значение для быстродействия 4. При этом в тесте памяти Everest наибольшая скорость копирования. На чтение, запись и латентность это значение почти не влияет.
DRAM Timing Configuration
Memory Clock Mode [Auto, Limit, Manual]
Установка в Manual открывает следующую опцию:
Memory Clock Value [400, 533, 667, 800]
Позволяет установить делитель для памяти.
PLL1 Spread Spectrum [Enabled, Disabled]
PLL2 Spread Spectrum [Enabled, Disabled]
Опция Spread Spectrum позволяет сгладить пики и уменьшить интерференцию, а также уменьшить взаимное электромагнитное влияние различных компонентов системной платы друг на друга за счет изменения их частоты в некоторых пределах. Рекомендуется отключить для стабильности системы.
PCI Express Configuration
GFX Dual Slot Configuration [Enabled]
GFX2 Dual Slot Configuration [Disabled]
Peer-to-Peer among GFX/GFX2 [Disabled]
Данные опции определяют сколько и в каком режиме будет работать видеоадаптеров, размещенных в слотах. С такими значениями — будут задействованы платы, подсоединенные к верхним синему и черному слотам в равном состоянии для получения запросов и команд.
GPP Slots Power Limit, W [25]
Ограничение мощности слотов GPP
Port #02 и #12 Features
Gen2 High Speed Mode [Disabled, Software Swith, Autonomus Switch]
* Software Switch, Autonomus Switch — включение данных значений дает небольшой прирост в 3DMark06, по сравнению с Disabled. Между собой у них разницы не заметил.
Link Width [Auto, x1Mode, x2, x4, x8, x16]
режим работы слота.
Slot Power Limit, W [175]
максимальная потребляемая мощность, которая может быть подана через слот (0-250).
Port #11
Настройки синего нижнего слота.
NB-SB Port Features
NB-SB Link ASPM [Disabled, L1]
NP NB-SB VC1 Traffic Support [Disabled, Enabled]
виртуальный канал 1) помогает с асинхронным режимом управлять потоком данных и голоса по IP.
Hyper Transport Configuration
HT Link Tristate [Disabled, CAD/CTL, CAD/CTL/CLK]
Включите вариант с тремя состояниями, чтобы уменьшить потребляемую мощность. По умолчанию нет линий в трех состояниях. Также CAD/CTL или CAD/CTL/CLK линии могут быть в трех состояниях.
UnitID Clumping [Disabled, UnitID 2/3, UnitID B/C, UnitID 2/3&B/C]
Включите для поддержки UnitID clumping, чтобы увеличить число отдельных запросов, поддерживаемых одиночным устройством. Это возможно включит для PCI-Express GFX линии в некоторых конфигурациях. Clumping можно включить, только когда используется более низкий мост номера в пределах каждого ядра PCI-Express GFX.
* Точных указаний нет. Вроде как работает вместе с Isochronous Flow-Control Mode и нужно ставить значение UnitID 2/3&B/C.
2X LCLK Mode
Ничего (опция будет удалена в следующей версии).



