Регресс Риджа и Лассо: полное руководство с Python Scikit-Learn
Дата публикации Sep 26, 2018
Поскольку я использую термин «линейный», сначала поясним, что линейные модели являются одним из самых простых способов прогнозирования результатов с использованием линейной функции входных функций.

В приведенном выше уравнении (1.1) мы показали линейную модель, основанную на n числах признаков. Учитывая только одну особенность, как вы, вероятно, уже поняли, чтош [0]будет склон иббудет представлять перехват. Линейная регрессия ищет оптимизациювеса такжебтакой, что минимизирует функцию стоимости. Функция стоимости может быть записана как

Хребет регрессии: В регрессии гребня функция стоимости изменяется путем добавления штрафа, эквивалентного квадрату величины коэффициентов.

Это эквивалентно высказыванию минимизации функции стоимости в уравнении 1.2 при условии, как показано ниже

Таким образом, регрессия гребня накладывает ограничение на коэффициенты(Ш).Наказывающий член (лямбда) упорядочивает коэффициенты так, что если коэффициенты принимают большие значения, функция оптимизации штрафуется. Такрегрессия гребня уменьшает коэффициенты и помогает уменьшить сложность модели и мультиколлинеарность.Возвращаясь к уравнению. 1.3 можно видеть, что при λ → 0 функция затрат становится аналогичной функции стоимости линейной регрессии (уравнение 1.2). ТакЧем ниже ограничение (низкое λ) на свойствах, модель будет напоминать модель линейной регрессии.Давайте рассмотрим пример с использованием данных Бостонского дома, а ниже приведен код, который я использовал для изображения линейной регрессии как ограничивающего случая регрессии Риджа.

Давайте разберемся с рисунком выше. По оси X мы строим индекс коэффициента и, для данных Бостона, имеется 13 объектов (для Python 0-й индекс относится к 1-му объекту). Для низкого значения α (0,01), когда коэффициенты менее ограничены, величины коэффициентов почти такие же, как у линейной регрессии. При более высоком значении α (100) мы видим, что для коэффициентов 3,4,5 величины значительно меньше по сравнению со случаем линейной регрессии. Это примерсокращениеКоэффициент коэффициента с использованием регрессионного хребта.
Лассо регрессия:Функция стоимости для регрессии Лассо (оператор наименьшей абсолютной усадки и выбора) может быть записана как



Код, который я использовал, чтобы сделать эти графики, как показано ниже
Давайте разберемся с сюжетом и кодом в кратком изложении.
До сих пор мы изучили основы регрессии Риджа и Лассо и увидели несколько примеров для понимания приложений. Теперь я попытаюсь объяснить, почему регрессия Лассо может привести к выбору объектов, а регрессия Риджа только уменьшает коэффициенты, близкие к нулю, но не к нулю. Приведенный ниже иллюстративный рисунок поможет нам лучше понять, где мы примем гипотетический набор данных только с двумя функциями. Используя ограничение для коэффициентов регрессии Риджа и Лассо (как показано выше в дополнениях 1 и 2), мы можем построить график ниже

Для двумерного пространства признаков области ограничения (см. Дополнения 1 и 2) построены для регрессии Лассо и Риджа с голубым и зеленым цветами. Эллиптические контуры являются функцией стоимости линейной регрессии (уравнение 1.2). Теперь, если у нас есть смягченные условия на коэффициенты, тогда ограниченные области могут стать больше, и в конечном итоге они попадут в центр эллипса. Это тот случай, когда регрессия Риджа и Лассо напоминает результаты линейной регрессии. Иначе,оба метода определяют коэффициенты путем нахождения первой точки, где эллиптические контуры попадают в область ограничений. Алмаз (Лассо) имеет углы на осях, в отличие от диска, и всякий раз, когда эллиптическая область достигает такой точки, одна из особенностей полностью исчезает!Для пространств пространственных объектов может быть много решений на оси с регрессией Лассо, и поэтому мы получаем только важные выбранные объекты.
Наконец, чтобы закончить эту медитацию, давайте подведем итог тому, что мы узнали до сих пор.
Для дальнейшего чтения я предлагаю «Элемент статистического обучения»; J. Friedman et.al., Springer, pages- 79-91, 2008.
Надеюсь, вам понравился пост и оставайтесь счастливыми! Ура!
Русские Блоги
L1, L2 + модель регрессии (Lasso, Ridge, Elasticnet)
Можно ли интегрировать процесс выбора функций с учебным процессом ученика.
Но если мы хотим изменить нежелательные характеристики 0?
Мы можем поставить

Но это проблема с НП. (NP-трудовые проблемы могут быть поняты как значение результата любого случая, но для расчета всех значений результата и статистически минимально и больше.)
И что я должен делать?
Два метода, меры 1:
L2 регуляризация
Мы начали быть полученным.

Здесь объясняет, как найти лучшее W

Из-за параллельного, мы можем иметь следующую формулу:

Отношения между λ C, большая, C меньше
Но значение λ должно быть очень конкретно

L1 регуляризация
Давайте поговорим о отношениях между L0 и L1.

Это процесс поиска: на самом деле, он очень похож на процесс L2. Он также вытягивается на двустороннюю параллельное положение, а затем найдет, что он будет натянут в угол.



Три типа регуляризации
(1) Специальная регуляризация драйвера цели: например, уменьшение эякуляции WQ2
(2) Для сглаживания (как можно меньше): например, L1 регулятор

Проблема регуляризации L1, может использовать проксимальный градиентный спуск, PGD, уменьшение оси координат, минимальный метод регрессии на углу; L2. Проблема регуляризации, снижение градиента может быть использовано (уменьшение градиента, снижение массовых градиентов)), Ньютон, бутон и т. Д. Отказ
PGD проксимальный градиентный падение
Потому что L1 неудобно в положении вершины. Чтобы решить эту проблему, вам необходимо использовать проксимальный градиентный раствор, проксимальный градиентный спуск.
Шаг 1: Запуск Тейлора проблемы f (x)



Координата оси снижение
2. Сохраняйте точки, отличные от других размеров, кроме xi, получите минимальное значение как независимая переменная
3. Измените размер, повторите 2
Каждое движение выполняется в направлении оси координат.
Метод минимального угла регрессии
1. Алгоритм выбора вперед (выделение Foward)
Вот хх как n m * 1 вектор x i 。
У X. k Вектор делают проекцию, проецируемая длина как х k Соответствующий коэффициент, не забудьте θ k 。
Шаг 2: Определить (остаточный) у ‘ =Y-X k *θ K
Если ты ‘ Проекция Все переменные завершены, или Y ‘равно 0, конечный алгоритм.
В противном случае, да после проекции ‘ Он установлен на новую цель Y, повторите первый шаг.
Иллюстрация рекомендуется следующим образом:

2. Алгоритм платного градиента (вперед по-ниди)
Рассчитайте остаточный у ‘ =Y-X k * W, затем найти наибольшее сходство одинаковой степени сходства на основе y ‘.

Как то выше направление X1 при ходьбе εx1 он перестанет расчета остатка, а затем определить сходство x1 или сходство с x2, затем продолжать идти.
3. Минимальная угловая регрессия (Ларс) алгоритм
Во-первых, также обнаружено, что не является исправлением переменной Y ближайшей к наиболее высокой степени корреляции, используя метод остаточного расчета, аналогичный алгоритму переднего градиента, для получения новой цели Y ‘, на этот раз не так, как Небольшой, как алгоритм плавного градиента и прогулка. Вместо этого это напрямую до XT, что делает корреляцию между XT и Y ‘и корреляцией XK и YYES. В это время остаток Y’ находится в горизонтальной линии XT и XK, в это время мы начали Прогуляйтесь по этому остаточному углу, пока связь между третью особенностью XP и Yyes не появились достаточно, то есть Xp к текущему корреляции остаточных yyes и θt, θk и yyes. Он также называет его в сборе функций приближения Y, а общая угловая ветвь набора аппроксимации используется в качестве нового направления приближения. С этой петлей до Yyyes недостаточно, или все переменные были взяты, алгоритм останавливается. В это время соответствующий коэффициент θ является конечным результатом.

L1 соответствует регрессии Лассо
L2 соответствует возврату хребта

Регулярный элемент L1 производит редкую модель L2 Regular для получения следующих эффектов:
1 Устранить ограничения на количество переменных в регулярном элементе L1 (т. Е. Резина)
2 Создание эффекта группировки (для атомов с сильным набором актуальности, L1 будет разрешено в соответствующей переменной *** ***)
3 Стабильный L1 обычный путь
Регулярный предмет после организации:


Его структура имеет следующие две функции: 1 В вершине есть странный выпуклый край (интенсивность выступов выступа (создание эффекта группировки) эластичной сети: 1 Регулярность упругости сети и выделение переменного выбора 2 может выполнять групповое выделение 3, когда P >> N, или тяжелые мультиплексные линейные чехлы, эффект является значительным 4, когда α находится близко к 0, эластичная сетка выполняет близко к лассо, но удаляет от чрезвычайно связанного разложения или странной производительности 5, когда α изменяется от 1 до 0, Редкое решение целевой функции 0 увеличивается от 0 до редкого раствора Лассо.
L1 L2 Резюме отличия:
L1 Регулярные параметры гипотезы являются распределение Лапласа, что обеспечивает реструктуру камеры модели, то есть некоторые параметры, равные 0, L1 регуляризация, является наиболее оптимальным эпитопным регуляризация L0 и может быть легко решена, чем L0, а также может достичь редкого Эффект,
L1 также известен как Лассо;


L2 регулярно, реки и озера, называемые хребтом, также известный как «Ring Repeate»
В реальном использовании, если функция имеет высокое измерение, используйте L1 Regular; если функция низкая и утолщение, L2 используется.
L2 не контролирует «номер» функции, но может предотвратить переполнение модели к функции; обратное состоит в том, что L1 состоит в том, чтобы контролировать функцию «номер» и поощряет модель, чтобы иметь большой вес на небольшом количестве особенностей.
1.1. Линейные модели ¶
Чтобы выполнить класификацию с помощью обобщенных линейных моделей, смотри раздел Логистическая регрессия
Обычный метод наименьших квадратов (Ordinary Least Squares, OLS) МНК
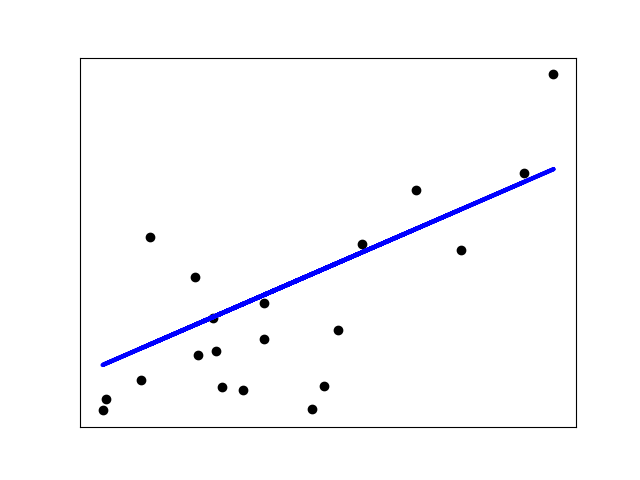
Оценки коэффициентов для обыкновенных наименьших квадратов полагаются на независимость функций. Когда функции коррелированы и столбцы матрицы плана имеют приблизительную линейную зависимость, матрица плана становится близкой к сингулярной, и в результате оценка методом наименьших квадратов становится очень чувствительной к случайным ошибкам в наблюдаемой цели, что приводит к большой дисперсии. Эта ситуация мультиколлинеарности может возникнуть, например, когда данные собираются без экспериментального плана.
1.1.1.2. Сложность обыкновенных наименьших квадратов
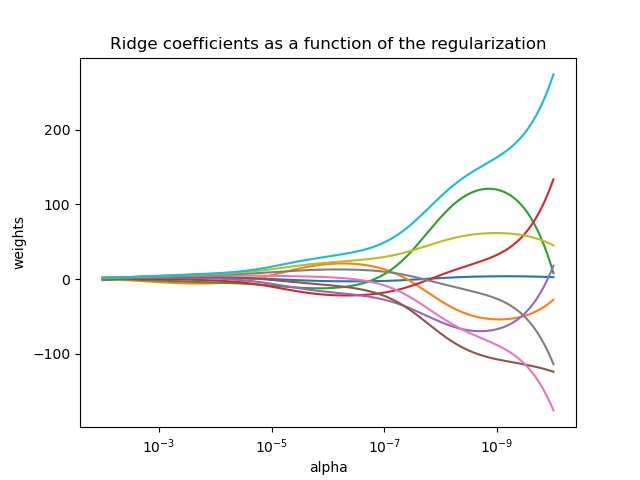
Как и в случае с другими линейными моделями, Ridge примет свой метод fit к массивам подбора X, y и сохранит коэффициенты линейной модели в своем члене coef_:
1.1.2.2. Классификация
У регрессора Ridge есть вариант классификатора: RidgeClassifier. Этот классификатор сначала преобразует двоичные цели в , а затем обрабатывает проблему как задачу регрессии, оптимизируя ту же цель, что и выше. Предсказанный класс соответствует знаку прогноза регрессора. Для мультиклассовой классификации проблема рассматривается как регрессия с несколькими выходами, и предсказанный класс соответствует выходу с наивысшим значением.
Может показаться сомнительным использование (штрафных) потерь по методу наименьших квадратов для соответствия классификационной модели вместо более традиционных логистических или шарнирных потерь. Однако на практике все эти модели могут приводить к одинаковым оценкам перекрестной проверки с точки зрения точности или точности / полноты, в то время как штрафные потери наименьших квадратов, используемые RidgeClassifier, позволяют совершенно разный выбор числовых решателей с различными профилями вычислительной производительности.
Этот классификатор иногда называют машинами опорных векторов наименьших квадратов с линейным ядром.
Этот метод имеет тот же порядок сложности, что и обычный метод наименьших квадратов.
1.1.2.4. Настройка параметра регуляризации: перекрестная проверка с исключением одного-одного
RidgeCV реализует регрессию гребня со встроенной перекрестной проверкой альфа-параметра. Объект работает так же, как GridSearchCV, за исключением того, что по умолчанию используется перекрестная проверка Leave-One-Out:
Указание значения атрибута cv вызовет использование перекрестной проверки с помощью GridSearchCV, например cv = 10 для 10-кратной перекрестной проверки, а не перекрестной проверки с оставлением одного значения.
“Notes on Regularized Least Squares”, Rifkin & Lippert (technical report, course slides).
1.1.3. Лассо
Лассо — это линейная модель, которая оценивает разреженные коэффициенты. Это полезно в некоторых контекстах из-за своей тенденции отдавать предпочтение решениям с меньшим количеством ненулевых коэффициентов, эффективно уменьшая количество функций, от которых зависит данное решение. По этой причине лассо и его варианты являются фундаментальными для области сжатого зондирования. При определенных условиях он может восстановить точный набор ненулевых коэффициентов (см. Компрессионное зондирование: реконструкция томографии с предварительным L1 (лассо)).
Реализация в классе Lasso использует координатный спуск в качестве алгоритма подбора коэффициентов. См. Другую реализацию в разделе «Регрессия наименьшего угла»:
Функция lasso_path полезна для задач нижнего уровня, поскольку она вычисляет коэффициенты по всему пути возможных значений.
Примечание. Выбор функций с лассо
В качестве регрессии LASSO дают редкие модели, таким образом, он может использоваться для выполнения выбора функций, как подробно описано в выборе функций на основе L1.
Следующие две ссылки объясняют итерации, используемые в соревете координатного спуска Scikit-Suart, а также вычисления пробелов двойственности, используемые для контроля конвергенции.
1.1.3.1. Настройка параметра регуляризации
Параметр alpha контролирует степень потенциальности предполагаемых коэффициентов.
1.1.3.1.1. Использование крос валидации
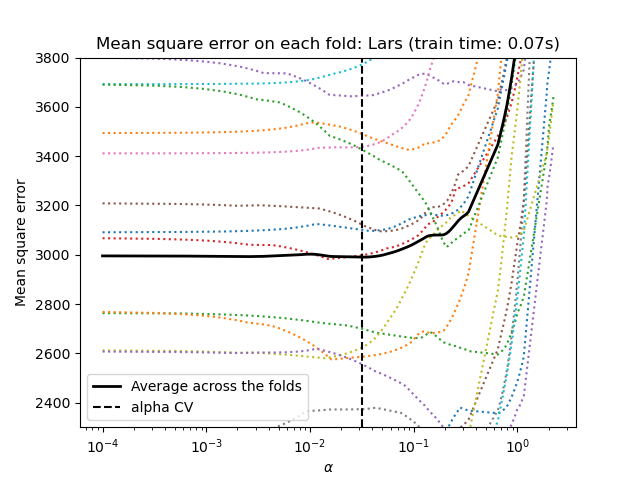
scikit-learn обнажает объекты, которые устанавливают параметр Lasso Alpha путем перекрестной проверки: lassocv и lassolarscv. Lassolarscv основан на алгоритме регрессии наименьших углов, объясненных ниже.
Для высокомерных наборов данных с множеством коллинеарных особенностей Lassocv чаще всего предпочтительнее. Тем не менее, Lassolarscv имеет преимущество в изучении более актуальных значений альфа-параметра, и если количество образцов очень мало по сравнению с количеством функций, он часто быстрее, чем Lassocv.

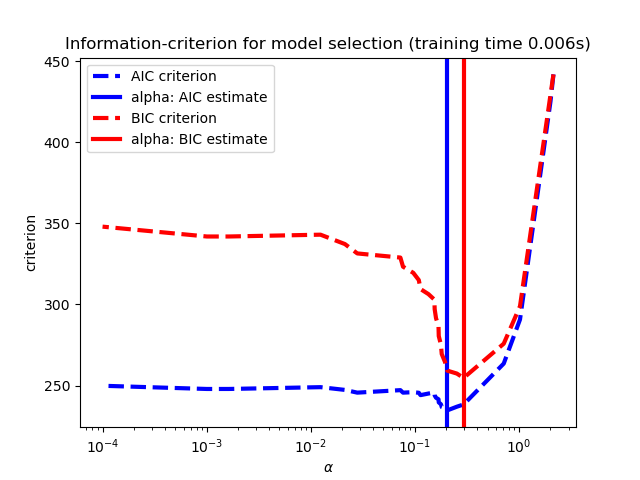
1.1.3.1.2. Выбор моделей на основе информационно-критериев
Альтернативно, оценщика Lassolarsic предлагает использовать информационный критерий (AIC AIC) и информационный критерий Bayes (BIC). Это вычислительная более дешевая альтернатива находить оптимальное значение альфа в качестве пути регуляризации, вычисляется только один раз вместо k + 1 раза при использовании кросс-проверки K-Fold. Однако такие критерии нуждаются в надлежащей оценке степеней свободы решения, получены для больших образцов (асимптотических результатов) и предполагают, что модель является правильной, то есть, что данные фактически генерируются этой моделью. Они также имеют тенденцию ломаться, когда проблема плохо обусловлена (больше особенностей, чем образцов).
1.1.3.1.3. Сравнение с параметром регуляризации SVM
Эквивалентность между альфам и параметром регуляризации SVM, C с помощью alpha = 1 / C или alpha = 1 / (n_samples * C), в зависимости от оценки и точной объективной функции, оптимизированной моделью.
1.1.4. Мультизадачное Лассо (Multi-Task Lasso)
Мультизадачное Лассо — это линейная модель, которая оценивает редкие коэффициенты для множественных проблем регрессии совместно: Y представляет собой 2D-массив, формы (N_SAMPLES, N_TASKS). Ограничение заключается в том, что выбранные функции одинаковы для всех проблем регрессии, также называемых задачами.
На следующем рисунке сравнивается расположение ненулевых записей в матрице коэффициента W, полученной с помощью простого лассо или многозадачно. Оценки Lasso выросли разбросанные нерешины, в то время как нестерос мультитаскиLasso являются полными столбцами.
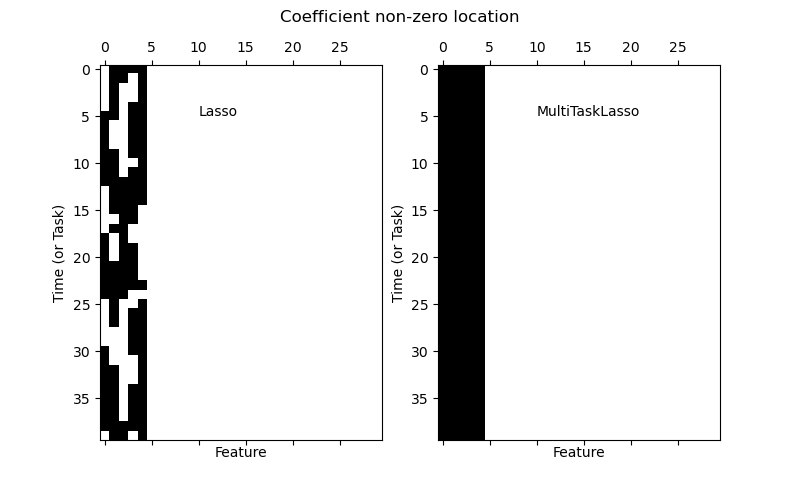
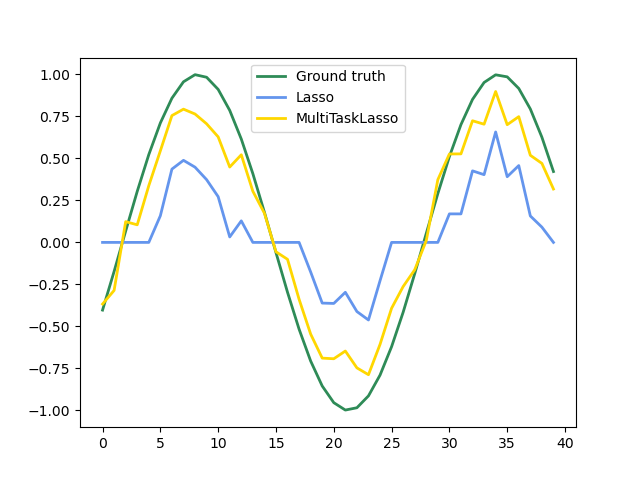
Установка модели серии Time, навязывая, что любая активная функция будет активна в любое время.
Реализация в классе MultiTaskLasso использует спуск координат в качестве алгоритма подбора коэффициентов.
1.1.5. Эластичная сетка
Эластичная сетка полезна, когда есть несколько функций, которые коррелируют друг с другом. Лассо, вероятно, выберет одно из них наугад, а эластичная сетка — и то, и другое.
Практическое преимущество компромисса между Lasso и Ridge заключается в том, что он позволяет Elastic-Net унаследовать часть стабильности Ridge при вращении.
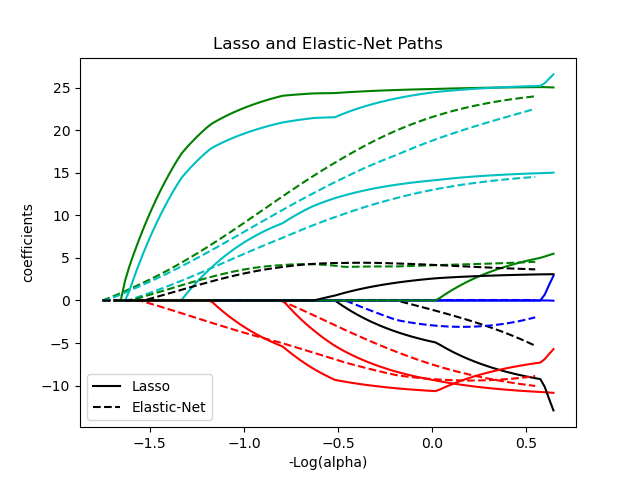
Класс ElasticNetCV можно использовать для установки параметров alpha ($\alpha$) и l1_ratio ($\rho$) путем перекрестной проверки.
Следующие две ссылки объясняют итерации, используемые в решателе координатного спуска scikit-learn, а также вычисление разрыва двойственности, используемое для управления сходимостью.
1.1.6. Многозадачная Elastic-Net
Реализация в классе MultiTaskElasticNet использует спуск координат в качестве алгоритма подбора коэффициентов.
Класс MultiTaskElasticNetCV можно использовать для установки параметров alpha ($\alpha$) и l1_ratio ($\rho$) путем перекрестной проверки.
1.1.7. Регрессия наименьшего угла
Регрессия наименьшего угла (LARS) — это алгоритм регрессии для многомерных данных, разработанный Брэдли Эфроном, Тревором Хасти, Иэном Джонстоном и Робертом Тибширани. LARS похож на пошаговую регрессию вперед. На каждом этапе он находит функцию, наиболее коррелирующую с целью. Когда есть несколько объектов, имеющих одинаковую корреляцию, вместо того, чтобы продолжать движение по одному и тому же объекту, он движется в одинаковом направлении между объектами.
К недостаткам метода LARS можно отнести:
1.1.8. ЛАРС Лассо
LassoLars представляет собой модель лассо, реализованную с использованием алгоритма LARS, и в отличие от реализации, основанной на координатном спуске, это дает точное решение, которое является кусочно-линейным как функция нормы его коэффициентов.
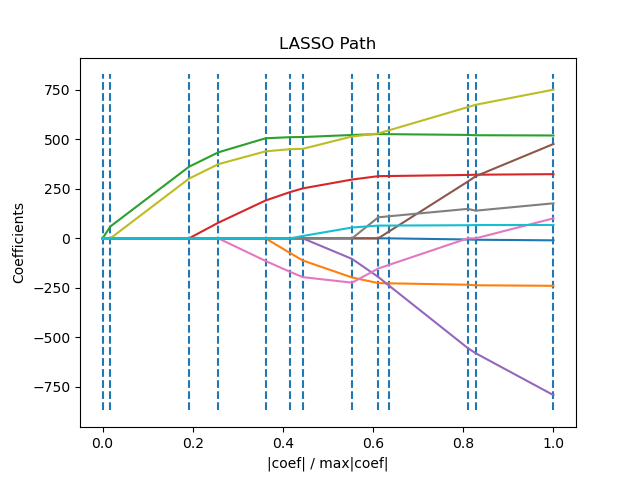
1.1.8.1. Математическая постановка
Алгоритм аналогичен пошаговой регрессии вперед, но вместо того, чтобы включать признаки на каждом шаге, оценочные коэффициенты увеличиваются в направлении, равносильном корреляциям каждого из них с остатком.
1.1.9. Ортогональное соответствие (OMP)
OrthogonalMatchingPursuit и orthogonal_mp реализует алгоритм OMP для аппроксимации соответствия линейной модели с ограничениями, наложенными на количество ненулевых коэффициентов (т. е.ℓ0 псевдонорма).
1.1.10. Байесовская регрессия
Для включения параметров регуляризации в процедуру оценки можно использовать методы байесовской регрессии: параметр регуляризации не устанавливается в жестком смысле, а настраивается на имеющиеся данные.
где α снова рассматривается как случайная величина, которая должна быть оценена на основе данных.
Преимущества байесовской регрессии:
К недостаткам байесовской регрессии можно отнести:
1.1.10.1. Регрессия Байесовского хребта
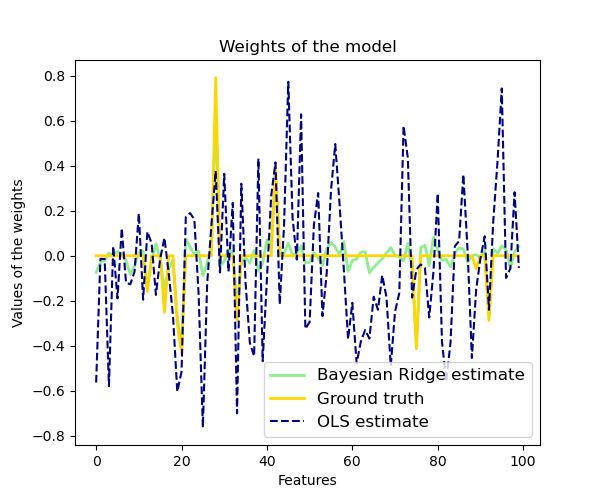
Регрессия Байесовского хребта используется для регрессии:
После установки модель может быть использована для прогнозирования новых значений:
Коэффициенты w модели доступны:
1.1.10.2. Автоматическое определение релевантности — ARD
Вместо этого распределение по w считается параллельным осям эллиптическим распределением Гаусса.
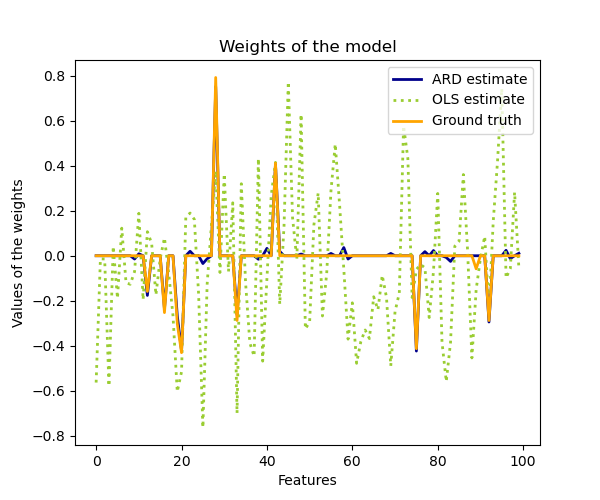
ARD также известен в литературе как машина разреженного байесовского обучения и векторов релевантности (рекомендации 3 и 4).
1.1.11. Логистическая регрессия
Логистическая регрессия, несмотря на свое название, представляет собой скорее линейную модель классификации, чем регрессию. Логистическая регрессия также известна в литературе как логит-регрессия, классификация максимальной энтропии (MaxEnt) или лог-линейный классификатор. В этой модели вероятности, описывающие возможные результаты одного испытания, моделируются с использованием логистической функции.
Регуляризация применяется по умолчанию, что характерно для машинного обучения, но не для статистики. Еще одно преимущество регуляризации состоит в том, что она улучшает численную стабильность. Никакая регуляризация не сводится к установке C на очень высокое значение.
В классе реализованы решатели LogisticRegression liblinear, newton-cg, lbfgs, sag и saga:
Решатель «sag» использует спуск градиента стохастического среднего (источник 6). Это быстрее, чем другие решатели для больших наборов данных, когда и количество выборок, и количество объектов велико.
В следующей таблице приведены штрафы, поддерживаемые каждым решателем:



