Key-value для хранения метаданных в СХД. Тестируем выделенные базы данных

В этой статье мы продолжаем рассказывать о том, как можно хранить метаданные в СХД при помощи баз данных key-value.
На этот раз в центре нашего внимания выделенные БД: Aerospike и RocksDB. Описание значимости метаданных в СХД, а также результаты тестирования встроенных БД можно посмотреть тут.
Параметры тестирования key-value БД
Кратко напомним основные параметры, по которым мы проводили тестирование (подробности в предыдущей статье).
Основной workload — Mix50/50. Дополнительно оценивали: RR, Mix70/30 и Mix30/70.
Тестирование проводили в 3 этапа:
Измеряемые показатели
Тестовое окружение
Конфигурация:
| CPU: | 2x Intel Xeon E5-2620 v4 2.10GHz |
| RAM: | 16GB |
| Disk: | [2x] NVMe HGST SN100 1.5TB |
| OS: | CentOS Linux 7.2 kernel 3.11 |
| FS: | EXT4 |
Объем доступной RAM регулировался не физически, а программно — часть заполнялась искусственно скриптом на Python, а остаток был свободен для БД и кэшей.
Выделенные БД. Aerospike
Чем Aerospike отличается от движков, которые мы до этого тестировали?
Это означает, что при нашем количестве ключей индекс не поместится в памяти, которую мы выделяем. Надо уменьшить количество ключей. И наши данные это позволяют!

Рис. 1. Схема упаковки 1
Рис. 2. Схема упаковки 2
Итак, с помощью такой упаковки мы уменьшили количество ключей в 4 раза. Таким же образом можем уменьшить их количество в k раз. Тогда размер значения будет 16*k Б.
Тестирование. 17 млрд ключей
Чтобы индекс Aerospike на 17 млрд ключей (17 млрд сопоставлений lba->metadata) поместился в RAM, надо упаковать это всё в 64 раза.
В итоге получим 265 625 000 ключей (каждому из ключей будет соответствовать значение размером 1024Б, содержащее 64 экземпляра метаданных).
Тестировать будем с помощью YCSB. Он не выдаёт среднюю квадратическую задержку, поэтому её не будет на графиках.
Заполнение
Aerospike показал неплохой результат на заполнение. Ведёт себя очень стабильно.
Но заполнение проводилось в 16 потоков, а не в один, как было с движками. В один поток Aerospike выдавал около 20k IOPS. Скорее всего, дело в бенчмарке (т.е. в один поток бенчмарк просто не «выжимает» БД). Либо же Aerospike любит много потоков, а в один не готов выдавать большую пропускную способность.
Рис. 3. Производительность заполнения базы
Максимальная задержка также держалась на примерно одинаковом уровне на протяжении всего заполнения.
Рис. 4. Latency заполнения базы
Тесты
Здесь важно отметить, что на этих графиках нельзя напрямую сравнивать Aerospike и RocksDB, т.к тесты проводились в разных условиях и разными бенчмарками – Aerospike использовался «с упаковкой», а RocksDB — без.
Также стоит учесть, что 1 IO у Aerospike = извлечение 64 значений (экземпляров метаданных).
Результаты RocksDB здесь приведены в качестве опорных.
Рис. 5. Сравнение Aerospike и RocksDB.100% Read
Рис. 6. Сравнение Aerospike и RocksDB. Mix 70%/30%
Рис. 7. Сравнение Aerospike и RocksDB Mix 50%/50%
Рис. 8. Сравнение Aerospike и RocksDB Mix 30%/70%
В итоге запись на малом количестве потоков получилась медленнее, чем у RocksDB (при этом следует помнить, что в случае Aerospike за один раз записывается сразу 64 значения).
Но на большом количестве потоков Aerospike всё же выдаёт более высокие значения.
Рис. 9. Aerospike. Latency Read 100%
Тут мы, наконец-то, смогли получить приемлемый уровень задержки. Но только в тесте на чтение.
Рис. 10. Aerospike.Latency Mix 50%/50%
Теперь можно обновить список выводов:
Ниже мы расскажем о том, что с этим можно делать, и что нам дает хранение данных в прямой адресации.
Прямая адресация. 137 млрд ключей
Рассмотрим системы хранения объемом 512 ТВ. Метаданные такой системы хранения как раз помещаются на одну NVME и соответствуют 137 млрд ключей для key-value базы данных.
Рассмотрим простейшую реализацию прямой адресации. Для этого на одном узле создадим SPDK NVMf таргет, на другом узле возьмем локальную NVMe и этот NVMf таргет и объединим их в логический RAID1.
Такой подход позволит записывать метаданные и защищать их репликой на случай отказа.
При тестировании производительности в несколько потоков каждый поток будет писать в свою область и эти области не будут пересекаться.
Тестирование проводилось с помощью бенчмарка FIO в 8 потоков с глубиной очереди 32. В таблице ниже представлены результаты тестирования.
Таблица 1. Тестирование прямой адресации
| rand read 4k (IOPS) | rand write 4k (IOPS) | rand r/w 50/50 4K(IOPS) | rand r/w 70/30 4K(IOPS) | rand r/w 30/70 4K(IOPS) | |
|---|---|---|---|---|---|
| spdk | 760 — 770 K | 350 — 360 K | 400 — 410 K | 520 — 540 K | 410 — 450 K |
| lat (ms) avg/max | 0.3 / 5 | 0.4 / 23 | 0.3 / 19 | 0,5 / 21 | 1,2 / 28 |
Теперь протестируем Aerospike в аналогичной конфигурации, где 137 млрд ключей как раз также помещаются на одну NVMe и реплицируются на другую NVMe.
Тестируем с помощью «родного» бенчмарка Aerospike. Берем два бенчмарка – каждый на своем узле – и 256 потоков, чтобы выжать максимальную производительность.
Разбираемся в типах NoSQL СУБД
Авторизуйтесь
Разбираемся в типах NoSQL СУБД

В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
База данных типа «ключ-значение»
Отсутствие схемы в базах данных «ключ-значение», например, Riak, — это как раз то, что вам нужно для хранения данных. Ключ может быть синтетическим или автосгенерированным, а значение может быть представлено строкой, JSON, блобом (BLOB, Binary Large Object, большой двоичный объект) и т.д.
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
В модели «ключ-значение» нет ничего сложного, так как реализовать её проще простого. Не лучший способ, если вам нужно только обновить часть значения или сделать запрос к базе данных.
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:
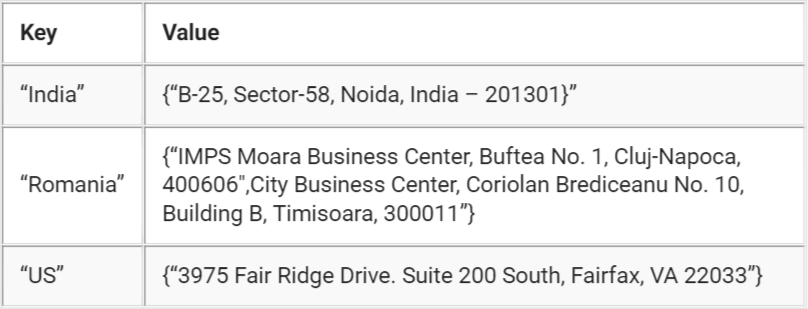
База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
И хотя базы данных типа «ключ-значение» могут пригодиться в определённых ситуациях, они не лишены недостатков. Первый заключается в том, что модель не предоставляет стандартные возможности баз данных вроде атомарности транзакций или согласованности данных при одновременном выполнении нескольких транзакций. Такие возможности должны предоставляться самим приложением.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Данные, представленные парами ключ-значение, сжимаются как хранилище документов схожим с хранилищем «ключ-значение» образом, с той лишь разницей, что хранимые значения (документы) имеют определённую структуру и кодировку данных. XML, JSON и BSON — некоторые из стандартных распространённых кодировок.
В следующем примере можно увидеть данные в виде «документа» который отображает названия определённых магазинов. Обратите внимание, что, хотя все три примера содержат местоположение, они отображают его по-разному:
Одним из ключевых различий между хранилищем «ключ-значение» и документоориентированным является то, что последний включает метаданные, связанные с хранимым содержимым, что даёт возможность делать запросы на основе содержимого. Например, в указанном примере можно попробовать найти все документы, в которых «City» равно «Noida», что вернёт все документы, связанные с магазинами в этом городе.
Apache CouchDB — пример документоориентированной СУБД. CouchDB использует JSON для хранения данных, JavaScript в качестве языка запросов с использованием MapReduce и HTTP для API. Данные и отношения не хранятся в таблицах так, как в традиционных реляционных базах данных, а по сути являются набором независимых документов.
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.

Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
На колонки можно ссылаться с помощью колоночного семейства.
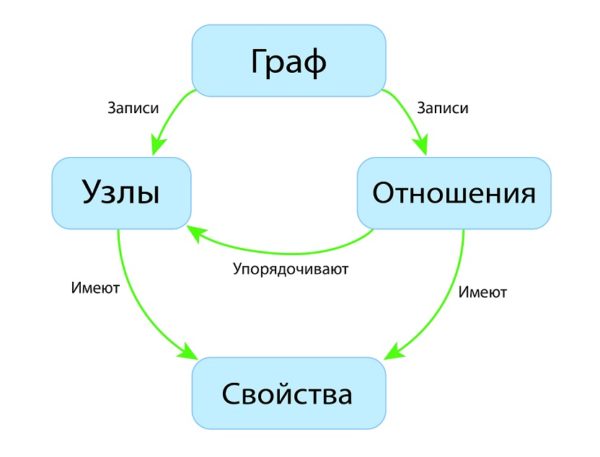
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
Контейнерная иерархия документоориентированной базы данных содержит данные без схемы, которые можно представить в виде дерева, которое является графом. Если обращаться к документам или их элементам в этом дереве, можно получить более выразительное представление данных, в котором можно легко ориентироваться с помощью Neo4j.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
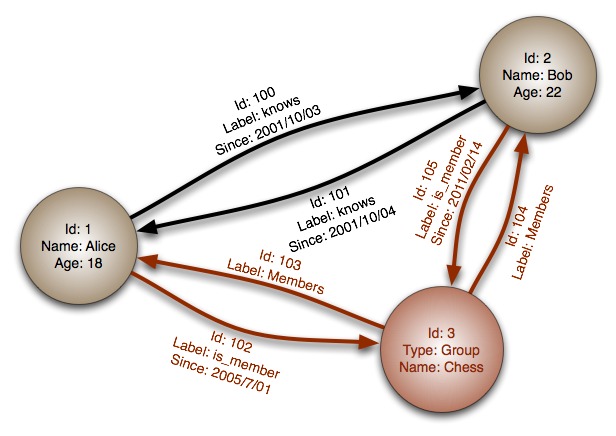
Помеченный, направленный, атрибутированный мультиграф: граф содержит узлы, которые помечены определёнными свойствами и которые имеют связи друг с другом, что представлено направленными рёбрами. Например, связь «Элис знает Боба» выражена ребром с некоторыми свойствами.
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Пример использования
Любой рейтинг «Рекомендовано вам», который можно увидеть на разных сайтах, зачастую составляется исходя из того, как другие пользователи оценили продукт. Графовые базы данных отлично подходят для такого случая.
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
InfoGrid предлагает два типа баз данных:
Хранилище key-value, или как наши приложения стали удобнее

Тот, кто разрабатывает на Voximplant, знает о концепции «приложений», которые связывают друг с другом облачные сценарии, телефонные номера, пользователей, правила и очереди звонков. Проще говоря, приложения – это краеугольный камень разработки на нашей платформе, входная точка в любое решение на основе Voximplant, так как именно с создания приложения все и начинается.
Раньше приложения «не помнили» ни действия, что выполняют сценарии, ни результаты вычислений, так что разработчики были вынуждены сохранять значения в сторонних сервисах или на своем бэкенде. Если вы когда-либо работали с local storage в браузере, то наша новая функциональность весьма похожа на это, т.к. позволяет приложениям запоминать пары «ключ-значение», которые уникальны для каждого приложения в вашем аккаунте. Работа хранилища стала возможна благодаря новому модулю ApplicationStorage – под катом вас ждет краткое руководство по его использованию, welcome!
Вам понадобятся
Настройки Voximplant
Сначала войдите в свой аккаунт: manage.voximplant.com/auth. В меню слева нажмите «Приложения», затем «Новое приложение» и создайте приложение с именем storage. Зайдите в новое приложение, переключитесь на вкладку «Сценарии», чтобы создать сценарий countingCalls с таким кодом:
Первая строка подключает модуль ApplicationStorage, остальная же логика помещена в обработчик события CallAlerting.
Сперва мы объявляем переменную, чтобы можно было сравнивать начальное значение со счетчиком звонков. Затем мы пытаемся получить значение ключа totalCalls из хранилища. Если такого ключи еще нет, то мы его создаем:
Далее необходимо увеличить значение ключа в хранилище:
Для каждого промиса необходимо явно указывать обработку отказа, как показано в листинге выше – иначе выполнение сценария будет остановлено, а в логах вы увидите ошибку. Подробности тут.
После работы с хранилищем сценарий отвечает на входящий звонок с помощью голосового синтеза и говорит, сколько раз вы звонили до этого. После этого сообщения сценарий завершает сессию.
После того, как вы сохранили сценарий, перейдите на вкладку «Роутинг» вашего приложения и нажмите «Новое правило». Назовите его startCounting, укажите сценарий countingCalls и оставьте маску по умолчанию (.*).
Последнее – создать пользователя. Для этого перейдите «Пользователи», нажмите «Создать пользователя», укажите имя (например, user1) и пароль, затем кликните «Создать». Эта пара логин-пароль понадобятся нам для аутентификации в вебфоне.
Проверяем
Откройте вебфон по ссылке phone.voximplant.com и залогиньтесь, используя имя аккаунта, название приложения и пару логин-пароль пользователя из приложения. После успешного входа введите любой набор символов в поле ввода и нажмите Call. Если все было сделано правильно, то вы услышите синтезированное приветствие!
Желаем вам отличной разработки на Voximplant и следите за новостями – их у нас будет еще много 😉
Key-value для хранения метаданных в СХД. Тестируем встраиваемые базы данных

7-8 ноября 2017 на конференции Highload++ исследователи лаборатории «Рэйдикс» представили доклад «Метаданные для кластера: гонка key-value-героев».
В этой статье мы представили основной материал доклада, касающийся тестирования баз данных key-value. «Зачем их тестировать производителю СХД?», — спрóсите вы. Задача возникла в связи с проблемой хранения метаданных. Такие «фичи», как дедупликация, тиринг, тонкое выделение ресурсов (thin provisioning), лог-структурированная запись, идут вразрез с механизмом прямой адресации – возникает необходимость хранить большое количество служебной информации.
Введение
Рис. 1. Метаданные
Например, при X=4KB, Y=16 байта. Получаем следующую таблицу:
Таблица 1. Соотношение объема хранения и метаданных
| Объем данных на узел | Количество ключей на узел | Объем метаданных |
|---|---|---|
| 512ТБ | 137 млрд | 3ТБ |
| 64ТБ | 17 млрд | 384ГБ |
| 4ТБ | 1 млрд | 22.3ГБ |
Объём метаданных достаточно большой, поэтому держать метаданные в RAM не представляется возможным (либо это экономически нецелесообразно). В связи с этим возникает вопрос хранения метаданных, причем с максимальной производительностью доступа.
Варианты хранения метаданных
Рис. 2. Принцип работы прямой адресации
На рисунке 2 pba1 — это физический сектор (512Б) накопителя, где мы храним метаданные, а lba1. lba32 (их 32, т.к. 512Б/16Б = 32) — адреса тех страниц, которым эти метаданные соответствуют, и эти адреса нам хранить не надо.
Анализ рабочей нагрузки в СХД
Исходя из нашего опыта рабочих нагрузок, определимся, какие требования по задержкам и пропускной способности нам нужны.
Рабочая нагрузка в медиаиндустрии:
Какие сложности возникают на старте?
Типы key-value БД
Существует два типа key-value баз данных:
Чем тестировать?
Первый вариант, который можно найти, — YCSB.
Рис. 3. Варианты тестирований
В итоге для движков выбираем ioarena, а для выделенных – YCSB.
Кроме workload’ов в ioarena нами была добавлена опция (-a), позволяющая указывать при запуске отдельно количество выполняемых операций на поток и отдельно количество ключей в БД.
Все изменения в коде ioarena можно найти на GitHub.
Параметры тестирования key-value БД
Основной workload, который нам интересен, – Mix50/50. Также мы решили посмотреть на RR, Mix70/30 и Mix30/70, чтобы понять, какие БД больше «любят» тот или иной workload.
Методика тестирования
Тестируем в 3 этапа:
Что измеряем?
Тестовое окружение
Конфигурация:
| CPU: | 2x Intel Xeon E5-2620 v4 2.10GHz |
| RAM: | 16GB |
| Disk: | [2x] NVMe HGST SN100 1.5TB |
| OS: | CentOS Linux 7.2 kernel 3.11 |
| FS: | EXT4 |
Здесь важно отметить, что такой малый объем RAM взят не случайно. Таким образом, база не сможет полностью поместиться в кэш на тестах с 1 млрд ключей.
Объем доступной RAM регулировался не физически, а программно — часть заполнялась искусственно скриптом на Python, а остаток был свободен для БД и кэшей.
В некоторых тестах было иное количество доступной памяти — об этом будет сказано отдельно.
NVMe в тестах использовался один.
Надёжность записи
Важный момент — режим надёжности записи данных на диск. От этого очень сильно зависит скорость записи и вероятность/объём потерь при сбоях.
В целом, можно выделить 3 режима:
В итоге для тестов был выбран режим lazy как наиболее сбалансированный. Об исключениях будет сказано отдельно.
Тестируем встраиваемые key-value БД
Для тестирования «движков» мы проводили два варианта тестирования: на 1 млрд ключей и на 17 млрд ключей.
Результаты тестов. 1 млрд ключей
Заполнение
Рис. 4.1. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Здесь все движки в стандартной конфигурации. Режим надёжности Lazy, кроме MDBX. У него слишком медленная запись в Lazy, поэтому для него был выбран режим Nosync, иначе заполнение продлится слишком долго. Однако видно, что с некоторого момента всё равно скорость записи падает примерно до уровня скорости Sync режима.
Что можно увидеть на этом графике?
Первое: с RocksDB что-то случается после 800 млн ключей. К сожалению, не были выяснены причины происходящего.
Рис. 4.2. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Второе: MDBX плохо перенёс момент, когда данных стало больше, чем доступно памяти.
Рис. 4.3. Зависимость текущей скорости (IOPS) от количества ключей (ось абсцисс — миллионы ключей).
Далее можно посмотреть на график максимальной задержки. Тут также видно, что у RocksDB начались вылеты после 800 млн ключей.
Рис. 5 Максимальная latency
Ниже находится график среднего квадратического значения задержки. Тут также видны те самые границы для RocksDB и MDBX.
Рис. 6.1. RMS Latency
Рис. 6.2. RMS Latency
Тесты
К сожалению, Sophia показала низкий результат во всех тестах. Скорее всего, она не «любит» много потоков (т.е. 32 и более).
WiredTiger сначала показывал очень низкую производительность — на уровне 30 IOPS. Оказалось, что у него есть важный параметр cache_size, который по умолчанию выставлен на 500МБ. После его установки на 8ГБ (или даже 4ГБ) всё становится намного лучше.
Ради интереса был проведён тест с тем же объёмом данных, но с объёмом доступной памяти > 100ГБ. В этом случае MDBX с отрывом уходит вперёд в тесте на чтение.
Рис. 7. 100% Read
При добавлении записи в workload получаем сильное падение MDBX (что ожидаемо, т.к. при заполнении скорость была низкой). WiredTiger подрос, а RocksDB снизил скорость.
Рис. 8. Mix 70%/30%
Рис. 9. Mix 50%/50%
Когда записи становится довольно много, WiredTiger начинает обгонять RocksDB на малом количестве потоков.
Рис. 10. Mix 30%/70%
Теперь можно посмотреть на графики задержек. Столбцы показывают минимальную и максимальную задержки, оранжевая полоска — средняя квадратическая задержка, а красная полоска — перцентиль 99.99.
Зелёная полоса — это примерно 2 мс. То есть мы хотим, чтобы перцентиль находился не выше зелёной полосы. В данном случае мы этого не получаем (шкала логарифмическая).
Рис. 11. Latency Read
Рис. 12. Latency 50%/50%
Результаты тестов. 17 млрд ключей
Заполнение
Тесты на 17млрд ключей были проведены только на RocksDB и WiredTiger, т.к. они были лидерами в тестах на 1 млрд ключей.
У WiredTiger начались странные выпады, но в целом он довольно неплохо себя показывает на заполнении, плюс не наблюдается деградации при увеличении объёма данных.
А вот RocksDB в итоге спустился ниже 100k IOPS. Таким образом, в тесте на 1 млрд ключей мы не видели всей картины, поэтому важно проводить тесты на объёмах, сравнимых с реальными!
Рис. 13. Производительность 17 млрд ключей
Пунктирной линией изображена средняя квадратическая задержка. Видно, что максимальная задержка у WiredTiger выше, а средняя квадратическая ниже, чем у RocksDB.
Рис. 14. Latency 17 млрд ключей
Тесты
С WiredTiger’ом случилась та же беда, что и в прошлый раз — он показывал около 30 IOPS на чтение, даже при cache_size=8GB. Было решено ещё увеличить значение параметра cache_size, но и это не помогло: даже при 96ГБ скорость не поднялась выше нескольких тысяч IOPS, хотя выделенная память даже не была заполнена.
При добавлении записи к workload’у WiredTiger традиционно поднимается.
Рис. 15. Производительность 100% Read
Рис. 16. Производительность 70%/30%
Рис. 17. Производительность 30%/70%
Рис. 18. Производительность 50%/50%
Рис. 19. Latency 100% Read
Рис. 20. Latency 50%/50%
Выводы
Из того, что сказано выше, можно сделать следующие выводы:
Для базы объемом в 1 млрд ключей:
Такова ситуация со встраиваемыми движками. В следующей статье мы расскажем о показателях выделенных баз данных key-value и сделаем выводы о бенчмарках.



