О программе
Key Collector — это профессиональный инструмент для интернет-маркетологов, который служит для работы с семантическим ядром сайта.
Программа предоставляет инструменты для сбора и отбора наиболее эффективных фраз и организации структуры ядра.
Поддерживаются десятки различных источников данных. Также можно добавлять фразы вручную или импортировать из файлов.
Удобные инструменты для работы с данными облегчат выполнение рутинных операций и позволят найти и оценить параметры и скрытые взаимосвязи.
Инструменты кластеризации и работы с группами помогут сформировать удобную в работе древовидную структуру семантического ядра.
Сбор и отбор фраз
Программа поддерживает работу с десятками сервисов и позволяет получать данные более чем из 20 источников, включая популярные поисковые системы, системы аналитики и платные сервисы по подписке.
Собрав или загрузив из внешних источников или введя запросы ядра вручную, вы можете получить дополнительные параметры статистики и отобрать наиболее эффективные с точки зрения бюджета и поставленных целей варианты.
В анализе могут участвовать частоты, переходы, показы фраз пользователям поисковых систем, стоимость контекстной рекламы, подробные результаты поисковой выдачи, исторические или прогнозные данные по переходам на сайты, а также многие другие внутренние метрики поддерживаемых сервисов.
Сравнить и отобрать лучшие запросы помогут встроенные в Key Collector удобные инструменты по работе с фразами: фильтрация, сортировка, маркировка, автоматический и полуавтоматический анализ фраз и др.
Профессиональный инструмент для интернет-маркетинга
Программа поможет собрать и организовать семантическое ядро, избавит от рутины в процессах и подготовит отчеты по самым эффективным запросам.
Собирайте фразы
Собирайте данные автоматически. Поддерживаются более 30 источников данных и свыше 50 параметров статистики.
Анализируйте параметры
Пользуйтесь встроенными системами фильтрации и анализа данных для отбора лучших запросов. Не тратьте время на составление громоздких макросов, скриптов или сложных формул.
Организуйте структуру
Редактор структуры в сочетании с системой маркировки групп упрощает процесс создания сложной структуры проекта.
Удобная система фильтрации
Для работы с фразами программа оснащена мощной и удобной системой фильтрации данных: всего в несколько кликов можно сформировать запросы любой сложности и отобрать лучшие варианты.
Часто используемые комбинации можно сохранить в шаблоны или передать коллегам.
Редактор структуры ядра
Вместо ведения сотни отдельных файлов или листов воспользуйтесь преимуществами ведения структуры в Key Collector.
Программа поддерживает несколько видов отображения структуры ядра, включая дерево групп и редактор структуры.
Поддерживаются сортировка, фильтрация, закладки и многие другие операции.
Программа оснащена модулями автоматической и ручной кластеризации фраз, поиска неявных дублей, минус-слов и пр.
Используя эти инструменты, вы можете выявить сложные зависимости и признаки среди фраз семантического ядра.
Бессрочная лицензия
Лицензия предоставляется без абонентской платы с возможностью замены оборудования
Техническая поддержка
Пользователи программы имеют доступ к бесплатной технической поддержке через встроенную систему тикетов
Бесплатные обновления
Регулярные бесплатные обновления расширяют возможности программы и исправляют найденные неисправности
Комьюнити пользователей
Участвуйте в комьюнити пользователей программы и обменивайтесь опытом
Бессрочная лицензия на 1 ПК с возможностью замены оборудования
Возможны скидки 
Без абонентской платы Купить лицензию
![]()
“Key Collector 4 — это оптимальный инструмент в мире позапросной аналитики.”
Александр Ожгибесов
Генеральный директор Ожгибесов.НЕТ
Обновленная документация
Ознакомьтесь с подробной документацией и узнайте о скрытых возможностях и рекомендуемых практиках работы.
Инструкция по настройке и работе с Key Collector — обзор программы для сбора семантического ядра
Key Collector — что это и как с ним работать, а именно: как происходит настройка программы в 2020 году и сбор семантического ядра, как собрать частотность и увеличить семантику, что такое прокси и антикапча для кей коллектора, как его перенести на другой компьютер и какие бывают аналоги у сервиса? Ответы на все эти вопросы мы разберем в данной статье и попробуем понять: действительно ли это один из самых лучших инструментов для сбора семантики.
Key Collector — что это и какие функции выполняет
Кей Коллектор — это многофункциональная программа, применяемая для сбора семантического ядра, то есть получения информации, которая поможет в дальнейшей SEO-оптимизации сайта. Как правило, её используют SEO-шники, маркетологи, digital-стратеги или копирайтеры.
Ключевой опцией в Key Collector (KC) является возможность сбора точной частотности фраз. Вы сможете убирать ненужные запросы в различных словоформах с маленькой частотностью и оставлять слова или словосочетания, которые действительно запрашивают пользователи.
Благодаря данному сервису, работа по сбору семантики становится автоматическим процессом. Другими словами, в отличие от Вордстата, вам не придется вводить вручную символы операторов для SEO-детализации слов. С его помощью можно провести массовый парсинг запросов по выбранной тематике, отчистить дубли и создать собственный перечень «стоп-слов».
Стоп-слова — это перечень лишних фраз или слов, которые не схожи с темой продвигаемого материала или раздражают большинство целевых пользователей при прочтении текста по искомому запросу, следовательно, факт их присутствия в тексте является негативным аспектом для модераторов поисковых систем. Также их называют «мусорные» слова или «минус-слова».
К тому же программа интегрирована с такими сервисами как:
Мы перечислили основные сервисы, помимо них существует еще множество ресурсов с которыми взаимодействует данный парсер. Следовательно, особенность Кей Коллектора в том, что он является неким объединяющим звеном всех вышеперечисленных ресурсов, поскольку связывает весь их функционал в одну слаженную концепцию.
Возможности Кей Коллектора
Давайте разберем потенциал этого малыша на примере его базовых возможностей, чтобы вы смогли понять, что же входит в его основной функционал и определиться в том, насколько он вам будет полезен. С помощью данной утилиты вы сможете проводить:
Мы отобразили перечень основных функций Key Collector, для более детального ознакомления со всеми инструментами, рекомендуем вам попробовать воспользоваться данной программой самостоятельно. Если вы заинтересовались, давайте же теперь разберемся: где можно его прибрести и за какую стоимость.
Сколько стоит Key Collector и где купить программу
Во время сбора семантического ядра по данной статье, нам встретился такой запрос, как: «скачать бесплатно крякнутый Кей Коллектор». Однако всем пользователям, которые хотят сэкономить, мы рекомендуем этого не делать, по двум причинам:
Приобрести KC вы сможете на данном сайте. Если вы все же не хотите тратить средства на данный парсер — можете рассмотреть его бесплатный аналог: Slovoeb, как один из вариантов. Более подробная информация об этой программе написана в разделе: Аналоги.
Настройка Key Collector
Одним из важнейших процессов в работе с KC является его настройка, поскольку в дальнейшем от этого зависит достоверность сведений, которые вы будете получать.
Key Collector — что это, почему все используют
Key Collector — это программа для работы с ключевыми словами. Позволяет собирать слова со многих сервисов + быстро с ними работать. Если руками 10 000 запросов вы будете обрабатывать неделю, то я справлюсь за пол дня благодаря кей коллектору.

Кей коллектор настолько чудесен, что его стоимость в 1.7к мне кажется самой жуткой халявой, что я встречал за последнее время. Должна быть у каждого сеошника и спеца по контексту. Ускоряет и упрощает сбор семантического ядра (ключей) до безобразия.
В конце будет подробное видео от меня по сбору семантического ядра в нем
Key Collector умеет
Собирать ключи с разных сервисов, ускоряет сбор минус слов, быстро сегментирует, фильтрует ключи, собирает статистику, снимает позиции с поисковой выдачи.
Расскажу и покажу, как собрать семантическое ядро на примере ускорения работы с Яндекс Вордстат. Дам только базовые знания, чтоб не затягивать материал. Весь путь настройки Яндекс Директ (для гугла тоже подойдет) с помощью Key Collector есть в моем видеокурсе.
Настройки Key Collector
Что нужно сделать в Кей Коллекторе, чтобы работать с ним по Яндекс Директ:
 4. По стандарту интервалы и прочие радости во вкладке Yandex Wordstat настроены адекватно. Трогать ничего не надо.
4. По стандарту интервалы и прочие радости во вкладке Yandex Wordstat настроены адекватно. Трогать ничего не надо.
Интерфейс выглядит так:

В самом низу настройка регионов — на вордстат (сбор слов), на директ (сбор статистики по словам). Обязательно пропишите целевой регион.
Как собирать ключи в Кей Коллектор:
Вставляете ключи в нужный сервис, жмете «начать сбор», уходите пить чай и плевать в потолок. Ярлычок вордстата выделил.

Иногда может вылезать капча. Чтобы не вводить ее самому — идете в настройки и слева будет вкладка «Антикапча». Выбираете любой ресурс антикапчи, регистриуетесь, кладете на баланс, берете ключ API в личном кабинете и вставляете в настройки Key Collector. 5 баксов вам хватит на полгода постоянных настроек, а времени сэкономите уйму.
Собрал для примера 500 ключей, пора включить сбор статистики по разным частотностям через Yandex.Direct.

Про частотность «ключевое слово» второго столбца
Обратите внимание на мусорные ключи, которые имеют большую разницу между базовой частотой и закавыченной. Базовую частотность (без операторов) 1000, а закавыченную (второй столбец) в 0-1, например. Это несуществующий ключ, огрызок.

Что такое «павильоны в Оренбурге»? Цветов? Заказать? Купить? В таком виде ключ не вводят, а предложение по нему будет не точным.
Я удаляю ВЫБОРОЧНО ключи 30+ по базовой частоте и 0-1 по закавыченной (на первый столбец фильтр 30+, на второй столбец — меньше или равно 1). Естественно, вы это все просматриваете, ибо адекватные ключи попадаются.
Меньшие частотности не надо, ибо велик шанс, что более точного ключа у вас не будет.
Удаление неявных дублей в Key Collector
Вкладка «Данные» — «Удаление неявных дублей» — «Выполнить умную групповую отметку» и «Удалить отмченное».
Сбор минус слов в Key Collector
Пока статистика собирается, мы можем начать собирать минус слова и сразу же удалять их из таблицы.
Первое время смотрите, что удаляете!

Само окно стоп слов Кей Коллектор имеет два режима — применять при парсинге с вордстата (галочка + нажатие обведенной кнопки), либо можете почистить уже существующий список, нажав «Отметить фразы в таблице». Он выделит все вхождения.
Экспериментируйте с типом вхождения Зависимое — Независимое, полное, частичное, соответствие. Для личного удобства. Я работаю ТОЛЬКО с зависимостью от словоформы и полным вхождением!
Метод выделения по стандарту будет опасный — выбрав слово «а», вы выделите все слова, содержащие эту букву. Настраивается в окне стоп-слов.

Выделить галочкой плохие ключи, жмите правой кнопкой мыши, отправить фразы в стоп-слова, выделяете ненужные и жмите «Добавить в стоп-слова». После этого все вхождения будут выделены в таблице.

Но в самом начале, когда ключей дофига, надо пользоваться группировкой слов — вы мигом удалите треть ненужных ключей.
Вкладка «Данные» — «Анализ групп», а дальше по инструкции. Прошлись по голубым щиткам, добавили в стоп слова, закрыли анализ и удаляйте выделенные ключи из таблицы.
Просматривать ключи в Кей Коллектор удобнее всего, когда они упорядочены по алфавиту. Или вы можете отобрать себе ключи с частотностью от 10 (это для закавыченных кампаний, иначе будет грязно).
Сбор стоп-слов (минус-слов) в Key Collector через «Анализ групп».
Через «Данные — Анализ групп» можете выделить слова, содержащие «мобильные» в разных склонениях и отправить в отдельную группу (Кнопка переноса рядом с окном стоп-слов).
Удобнее всего собирать минус-слова в Кей Коллектор через Анализ Групп. Там есть кнопочка «синий щиток», который сразу выделает нужные минуса, остается только их отправить и выделить вхождения в таблице.
 С этой настроечкой (выделено зеленым) будут отмечаться вхождения в таблице по выбранным словам.
С этой настроечкой (выделено зеленым) будут отмечаться вхождения в таблице по выбранным словам.  После этого в таблице выделяются слова, которые нужно переместить в Корзину (или любую другую группу). Вас интересует перенос отмеченных слов (это про галочку. выделение кликом называется «выделенные»)
После этого в таблице выделяются слова, которые нужно переместить в Корзину (или любую другую группу). Вас интересует перенос отмеченных слов (это про галочку. выделение кликом называется «выделенные»)
 Вот и конец инструкции.
Вот и конец инструкции.
Составление семантического ядра в Key Collector

Пошаговое руководство как сделать семантическое ядро сайта в программе Key Collector. В статье приводим технологию сбора и парсинга семантического ядра, кластеризацию, анализ конкурентов и составление структуры сайта.
Содержание
Зачем нужен экспресс-метода сбора семантики
Что такое семантическое ядро, из чего оно состоит и зачем его делают — подробно рассмотрено в материале здесь.
Рассмотрим составление семантического ядра сайта на примере, как его сделать в Кей Коллекторе в режиме «Экспресс-метода». Маркетологи студии DIUS его делают в случаях:
Экспресс-метод составления семантического ядра в Key Collector отличается от полноценной разработки СЯ тем, что не производится дополнительных итераций по сбору фраз. Если при упрощенном методе оптимизатор по маскам собирает из вордстата фразы одним прогоном, то при рабочем проекте дополнительно производятся:
В результате количество полученных фраз на порядок превышает объем, созданный при экспресс-методе. Таким образом, проект прорабатывается гораздо глубже, учитывается больше факторов.
Подбор масок (маркеров)
Рассмотрим процесс составления семантики по направлению «рольставни», в продолжение темы, начатой здесь. В первую очередь необходимо подобрать маркеры. Для этого оптимизаторы DIUS используют популярный ресурс Википедия. Набираем в поисковике Яндекс «рольставни википедия» и читаем материал:


Выписываем разные названия:
Также интересны склонения слова:
Собираем фразы из Вордстат в Кей Коллекторе
Создаем новый проект в Кей Коллекторе и добавляем списком разные названия. А к словам в склонении добавляем вначале восклицательный знак:

Итого получилось 18 фраз, по которым производится сбор фраз из Wordstat (Что такое Яндекс.Вордстат и как им пользоваться). При сборе общей частоты регион выставляем выше целевого, если это Москва, то берем «Центр». Это позволяет собрать больше фраз. А уточненную или точную частоту собираем по целевому региону (подробнее про частотность здесь). В данном случае сбор фраз сделали без выбора региона.
Чистка фраз в Key Collector
Для этого во вкладке «Данные» запускаем инструмент «Анализ групп» и получаем группировку фраз по словам. В ней отмечаем нецелевые слова и кликом правой клавиши мыши на одном из них отправляем их в список «Стоп-слов». На будущее это пригодится, т.к. экспресс-ядро потом разворачивается в рабочий проект, который потом дополняется, и есть готовый список для минусов.
Стоит отметить, что в примере работу проводим по коммерческим запросам и информационные ключевики отправляем в корзину, а в рабочем проекте для них создается отдельная папка «Инфо». С ними также происходит работа по аналогии с дальнейшими этапами. Чем отличаются информационные запросы от коммерческих смотрите здесь, а также «Как продвигать сайт по информационным запросам».

Также в студии есть готовые списки слов по городам России и Подмосковья, которые добавляются в список «Стоп-слов», что ускоряет чистку. И еще предусмотрены списки слов для создания отдельной группы информационных запросов.
В результате чистки в «Корзину» отправлено 1367 запросов. Их не удаляют, т.к. в будущем эти фразы могут пригодится для работы, и при повторном сборе они не будут добавлены.
Сбор точной частоты
Рассмотрим, как собрать частотность в Кей Коллекторе. По оставшимся 2958 фразам определяем точную частоту при помощи инструмента «Сбор статистики Yandex.Direct». Выставляем целевой регион «Москва и область» и отмечаем следующие опции:

Все фразы, где точная частота равно 0, отправляем в корзину или в отдельную папку «0». Из 2958 оставленных фраз получилось 1598 нулевых. Оставшиеся слова сортируем по частоте:

И дополнительно проводим анализ групп или глазами пробегаемся по фразам, чтобы убрать нецелевые фразы, которые не увидели при первой чистке. Тут можно использовать следующий алгоритм:
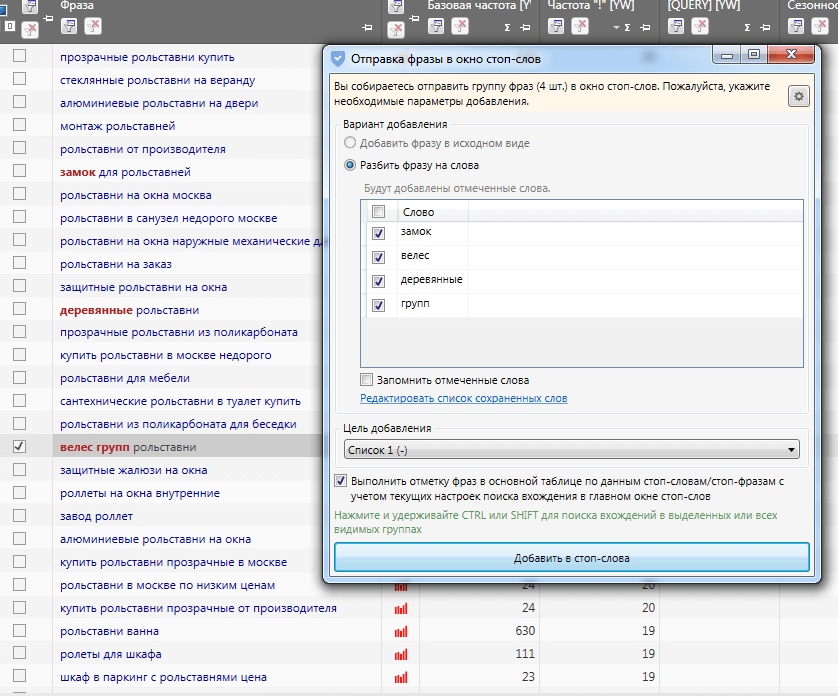
Жмем кнопку «Добавить в стоп-слова» и переносим их в папку «Корзина».
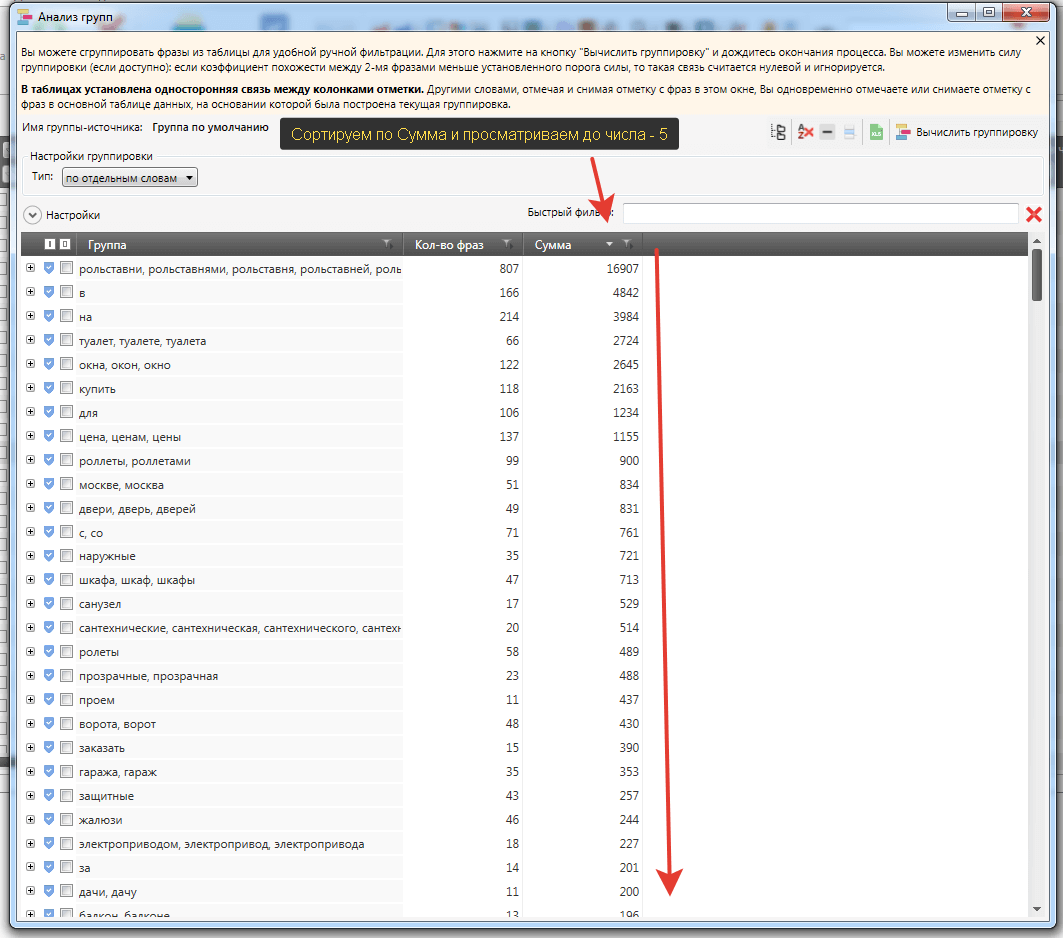
В результате чистки осталось 1035 фраз.
Сбор данных SERP

Включаем сбор данных по SERP:

Программа собирает данные ТОП-20 в Яндекс по каждой фразе. Параметры сбора этого инструмента выставляются в общих настройках:

В результате сбора в программе по каждой фразе с частотой «!» от 5 и выше будет список сайтов, которые находятся в ТОП-20. Кей Коллектор автоматически сведет данные на уровне доменов, чтобы можно было увидеть сайт и количество фраз, по которым он в ТОП.
Анализ конкурентов
После сбора данных СЕРП включаем инструмент «Поиск конкурентов»:

Получаем следующую сводку:

Указаны сайты и количество фраз по которым они в ТОП-20 (или ТОП-10, зависит от настроек). Нажимаем «Ctrl» и кликаем по этим сайтам – они откроются в браузере. Внимательно изучаем меню разделов «Рольставни», какие там есть подразделы:
При клике на каждый домен в общей группе отмечаются фразы, по которым сайт ранжируется в ТОП-20. Так, например, если выделить первые 5 сайтов от luxrol.ru до rusroll.ru, в группе будет отмечено 420 фраз из 1035, это фразы, по которым был осуществлен съем SERP. Для более детального анализ производится съем SERP по всем фразам.
Семантическое проектирование структуры сайта
Создаем табличку в Эксель или проект в МайндМап, в который выписываем разделы из меню сайтов с высокой видимостью, и создаем структуру:

Таким же образом можно сделать кластеризацию запросов в Key Collector:

Распределили слова по группам. Смотрим по «Анализ групп», что осталось:

Судя по группировкам, еще можно создать кластеры: в проем, с электроприводом, стеклянные, пластиковые и т.д. Это уже на усмотрение оптимизатора, т.к. сбор был не полный, а основные группы, генерирующие трафик, созданы на основе структур сайтов конкурентов.
Результат
В результате сбора фраз и анализа конкурентов за пару-тройку часов оптимизатор получает:
Кей Коллектор сокращает временные затраты на рутинные операции в разы, т.к. если это делать вручную – понадобилось бы несколько дней.



