В чем разница между пространством пользователя и пространством ядра?
Используется ли пространство ядра, когда ядро выполняется от имени пользовательской программы, т.е. системного вызова? Или это адресное пространство для всех потоков ядра (например, планировщика)?
Если это первый, чем это означает, что обычная пользовательская программа не может иметь более 3 ГБ памяти (если деление составляет 3 ГБ + 1 ГБ)? Кроме того, в таком случае, как ядро может использовать High Memory, потому что на какой адрес виртуальной памяти будут отображаться страницы из верхней памяти, поскольку логически будет отображаться 1 ГБ пространства ядра?
Используется ли пространство ядра, когда ядро выполняется от имени пользовательской программы, т.е. системного вызова? Или это адресное пространство для всех потоков ядра (например, планировщика)?
Прежде чем мы пойдем дальше, мы должны заявить о памяти.
Получение памяти разделено на две отдельные области:
Если это первый, чем это означает, что обычная пользовательская программа не может иметь более 3 ГБ памяти (если деление составляет 3 ГБ + 1 ГБ)? Кроме того, в таком случае, как ядро может использовать High Memory, потому что на какой адрес виртуальной памяти будут отображаться страницы из верхней памяти, поскольку логически будет отображаться 1 ГБ пространства ядра?
Для ответа на этот вопрос, пожалуйста, обратитесь к отличному ответу от wag здесь
Схема распределения памяти процесса
Виртуальные и реальные адреса
Каждый процесс в многозадачной ОС выполняется в собственной области памяти. Эта область представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер, равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц. Ядро создает и заполняет таблицы, а процессор обращается к ним когда нужно выполнить «перевод» адреса. Каждый процесс работает со своим набором таблиц.
Концепция виртуальной адресации распространяется на все выполняемые программы, включая и само ядро. По этой причине для ядра резервируется часть виртуального адресного пространства (т.н. kernel space). При попытке обращения к этим страницам из кода в пользовательском режиме (user mode) кода генерируется page fault. В Linux kernel space всегда присутствует в памяти процесса, и разные процессы отображают kernel space в одну и ту же область физической памяти. Таким образом, код и данные ядра всегда доступны, если нужно обработать прерывание или системный вызов.
Память запущенной программы (процесса) разделена на ряд непрерывных блоков (сегментов). Кроме Kernel Space существуют следующие сегменты:

Сегмент кода
В нем находится исполняемый код программы. Содержимое сегмента доступно для чтения/исполнения. Благодаря тому, что этот сегмент защищен от записи, программа не может испортить свой собственный код во время выполнения.
Сегмент инициализированных данных
Содержит глобальные переменные, которые инициализированы программистом. Размер этого сегмента зависит от объема помещенных в него данных, определяется на этапе компиляции программы и не изменяется во время ее выполнения.
Сегмент неинициализированных данных
Или сегмент BSS (сокращение от Block Started by Symbol; название историческое и мы не будем углубляться в причины его появления). Начинается сразу после окончания сегмента инициализированных данных. Содержит глобальные и статические переменные, которые не были явным образом инициализированы в исходном коде, и которые будут при запуске программы инициализированы нулями.
Данные в сегменты кода и инициализированных данных загружаются прямо из исполняемого файла (то есть эти области памяти являются копией исполняемого файла). Хранить же нули, которыми заполняется BSS, в исполняемом файле не имеет смысла. Поэтому в файле хранится только количество переменных и их тип. При загрузке программы в память, в последней будет зарезервирована область под требуемое количество нулей.
Область памяти, используемая для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. кадра стека. Когда функция возвращает управление, кадр стека уничтожается. Данные в стеке обрабатываются в соответствии с принципом «последним пришел — первым обслужен» (LIFO). Поэтому, для отслеживания содержимого стека достаточно знать лишь положение указателя на вершину стека. Добавление данных в стек и их удаление – операция быстрая. Кроме того, многократное использование одних и тех же областей стека приводит к тому, что они помещаются в кеш процессора, что еще более ускоряет доступ к ним.
Подобно стеку, куча используется для выделения памяти во время выполнения программы. Но в отличие от стека, память, выделенная в куче, сохраняется и после того, как функция, вызвавшая выделение этой памяти, завершит работу. Язык С предоставляет программисту целый ряд средств управления памятью в куче. Например, функция malloc() выделяет память, а free() освобождает ее.
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения размера кучи. Управление памятью в куче – непростая задача, для решения которой используются сложные алгоритмы. Куча также подвержена фрагментированию.
Куча и стек «растут» по направлению друг к другу.
Параметры командной строки и переменные окружения
Хранятся в самых верхних адресах доступной памяти процесса.
Пример
Выведем адреса переменных, заданных в каждом из сегментов памяти и отсортируем их по мере убывания адресов
В результате получим:
Инструменты
Утилита size показывает размер разделов и общий размер для объектных файлов или архивов. Так, для memsegments.o получим:
Таким образом мы можем определить размеры сегментов Text, Data и BSS. В колонках «dec» и «hex» приведен суммарный размер указанных сегментов в десятичном и 16-ричном форматах соответственно.
Поскольку стек им куча формируются во время выполнения программы, size не может показать их размер.
Для просмотра стека и кучи нужно остановить выполнение программы, не завершая ее работы. Например, добавить в нее ожидание пользовательского ввода
а затем выполнить в терминале
В итоге вы увидите стек, кучу и не только их.
Не рассмотрено
Приведенная схема описывает распределение памяти процесса в первом приближении, игнорируя некоторые детали. В частности, между стеком и кучей располагается сегмент, предназначенный для memory mapping. Желающие познакомится с этими деталями могут посмотреть статью Густаво Дуарте.
Читайте также
Комментарии
Дмитрий Храмов
Компьютерное моделирование и все, что с ним связано: сбор данных, их анализ, разработка математических моделей, софт для моделирования, визуализации и оформления публикаций. Ну и за жизнь немного.
Архитектура контейнеров, часть 1. Почему важно понимать разницу между пространством пользователя и пространством ядра

Вам поручили спроектировать инфраструктуру на основе контейнеров? И вы, скорее всего, понимаете, какую пользу могут принести контейнеры разработчикам, архитекторам и командам эксплуатации. Вы уже что-то читали о них и с нетерпением ждете возможности более подробно изучить эту технологию. Однако перед погружением в обсуждение архитектуры и развертывание контейнеров в продакшн-окружении необходимо знать три важные вещи:
Все приложения, включая контейнерные, используют ядро базовой ОС.
Ядро предоставляет приложениям API через системные вызовы (system calls).
Важны версии этого API, так как это «клей», который обеспечивает детерминированное взаимодействие между пространством пользователя (user space) и пространством ядра (kernel space).
Иногда контейнеры рассматриваются как виртуальные машины, но важно отметить, что, в отличие от виртуальных машин, ядро является единственным слоем абстракции между программами и ресурсами, к которым необходим доступ. Давайте посмотрим почему.
Все процессы выполняют системные вызовы (system calls):
А поскольку контейнеры тоже являются процессами, они также выполняют системные вызовы:
Итак, у нас есть понимание, что такое процесс, и что контейнеры — это тоже процессы. Но что насчет файлов и программ, находящихся внутри контейнера? Эти файлы и программы находятся в так называемом пользовательском пространстве (user space). При старте контейнера в память загружается программа из образа контейнера. Но программе, запущенной в контейнере, по-прежнему необходимо выполнять системные вызовы в пространстве ядра (kernel space). Важна возможность детерминированного взаимодействия пользовательского пространства и пространства ядра.
Пользовательское пространство
Под пользовательским пространством понимается весь код операционной системы, который находится вне ядра. Большинство Unix-подобных операционных систем (включая Linux) поставляются с разнообразными предустановленными утилитами, средствами разработки и графическими инструментами — это все приложения пространства пользователя.
Приложения могут быть написаны на C, Java, Python, Ruby и других языках программирования. В мире контейнеров эти программы обычно поставляются в формате образа контейнера, такого как Docker. Когда вы запускаете в контейнере образ Red Hat Enterprise Linux 7 из Red Hat Registry, то используете предварительно настроенное минимальное пользовательское пространство Red Hat Enterprise Linux 7, содержащее такие утилиты, как bash, awk, grep и yum (для возможности установки дополнительного программного обеспечения).
Все пользовательские приложения (и контейнеризированные и нет) при работе используют различные данные, но где эти данные хранятся? Какие-то данные поступают из регистров процессора и внешних устройств, но чаще они хранятся в памяти и на диске. Приложения получают доступ к данным, выполняя специальные запросы к ядру — системные вызовы. Например, такие как выделение памяти (для переменных) или открытие файла. В памяти и файлах часто хранится конфиденциальная информация, принадлежащая разным пользователям, поэтому доступ к ним должен запрашиваться у ядра с помощью системных вызовов.
Пространство ядра
Обычные программы пользовательского пространства для выполнения работы постоянно выполняют системные вызовы, например:
Некоторые программы, выполняемые в пользовательском пространстве, почти напрямую отображаются на системные вызовы, например:
Типичная программа получает доступ к ресурсам ядра через несколько слоев абстракции, как показано на следующем рисунке:
Обратите внимание, что по информации из man какие-то системные вызовы (также известные как интерфейсы) были убраны, а какие-то добавлены. Линус Торвальдс и другие уделяют большое внимание тому, чтобы поведение системных вызовов было понятным и стабильным. В Red Hat Enterprise Linux 7 (ядро 3.10) доступно 382 системных вызова. Время от времени добавляются новые, а некоторые объявляются устаревшими. Это следует учитывать при рассмотрении жизненного цикла вашей контейнерной инфраструктуры и приложений, которые будут в ней работать.
Заключение
Есть несколько важных моментов, которые нужно знать про пользовательское пространство и пространство ядра:
Приложения содержат бизнес-логику, но используют системные вызовы.
После компиляции программы набор используемых системных вызовов встраивается в бинарный файл (в языках более высокого уровня это интерпретатор или JVM).
Контейнеры не абстрагируют (не отменяют) необходимость того, чтобы пользовательское пространство и пространство ядра использовали одинаковый набор системных вызовов.
В мире контейнеров пользовательское пространство упаковывается (bundle) и развертывается на различных хостах от ноутбуков до продуктивных серверов.
В ближайшие годы могут появиться проблемы.
Со временем будет сложно гарантировать, что контейнер, созданный сегодня, будет работать завтра. Представьте, что наступил 2024 год (возможно, наконец-то появятся настоящие ховерборды), а у вас все еще работает контейнеризованное приложение в проде для которого требуется пользовательское пространство Red Hat Enterprise Linux 7. Как безопасно обновить хост с контейнерами и инфраструктуру? Будет ли контейнеризированное приложение одинаково хорошо работать на новых хостах, доступных на рынке?
Во второй части этой серии (оригинал на англ. Architecting Containers Part 2: Why the User Space Matters) мы рассмотрим, как взаимосвязь между пространством пользователя и пространством ядра влияет на архитектурные решения и что можно сделать, чтобы минимизировать проблемы.
Перевод материала подготовлен в рамках курса «Administrator Linux. Professional». Всех желающих приглашаем на открытый урок «Использование VPN туннелей в Linux».
В ходе этого вебинара:
— узнаем, что такое VPN;
— познакомимся с основными видами VPN и сравним их;
— разберем варианты конфигурации OpenVPN, попробуем понять разницу между ними;
— познакомимся с WireGuard, сравним его производительность с OpenVPN.
Организация памяти процесса

Управление памятью – центральный аспект в работе операционных систем. Он оказывает основополагающее влияние на сферу программирования и системного администрирования. В нескольких последующих постах я коснусь вопросов, связанных с работой памяти. Упор будет сделан на практические аспекты, однако и детали внутреннего устройства игнорировать не будем. Рассматриваемые концепции являются достаточно общими, но проиллюстрированы в основном на примере Linux и Windows, выполняющихся на x86-32 компьютере. Первый пост описывает организацию памяти пользовательских процессов.
Каждый процесс в многозадачной ОС выполняется в собственной “песочнице”. Эта песочница представляет собой виртуальное адресное пространство, которое в 32-битном защищенном режиме всегда имеет размер равный 4 гигабайтам. Соответствие между виртуальным пространством и физической памятью описывается с помощью таблицы страниц (page table). Ядро создает и заполняет таблицы, а процессор обращается к ним при необходимости осуществить трансляцию адреса. Каждый процесс работает со своим набором таблиц. Есть один важный момент — концепция виртуальной адресации распространяется на все выполняемое ПО, включая и само ядро. По этой причине для него резервируется часть виртуального адресного пространства (т.н. kernel space).
Это конечно не значит, что ядро занимает все это пространство, просто данный диапазон адресов может быть использован для мэппирования любой части физического адресного пространства по выбору ядра. Страницы памяти, соответствующие kernel space, помечены в таблицах страниц как доступные исключительно для привилегированного кода (кольцо 2 или более привилегированное). При попытке обращения к этим страницам из user mode кода генерируется page fault. В случае с Linux, kernel space всегда присутствует в памяти процесса, и разные процессы мэппируют kernel space в одну и ту же область физической памяти. Таким образом, код и данные ядра всегда доступны при необходимости обработать прерывание или системный вызов. В противоположность, оперативная память, замэппированная в user mode space, меняется при каждом переключении контекста.

Синим цветом на рисунке отмечены области виртуального адресного пространства, которым в соответствие поставлены участки физической памяти; белым цветом — еще не использованные области. Как видно, Firefox использовал большую часть своего виртуального адресного пространства. Все мы знаем о легендарной прожорливости этой программы в отношении оперативной памяти. Синие полосы на рисунке — это сегменты памяти программы, такие как куча (heap), стек и так далее. Обратите внимание, что в данном случае под сегментами мы подразумеваем просто непрерывные адресные диапазоны. Это не те сегменты, о которых мы говорим при описании сегментации в Intel процессорах. Так или иначе, вот стандартная схема организации памяти процесса в Linux:
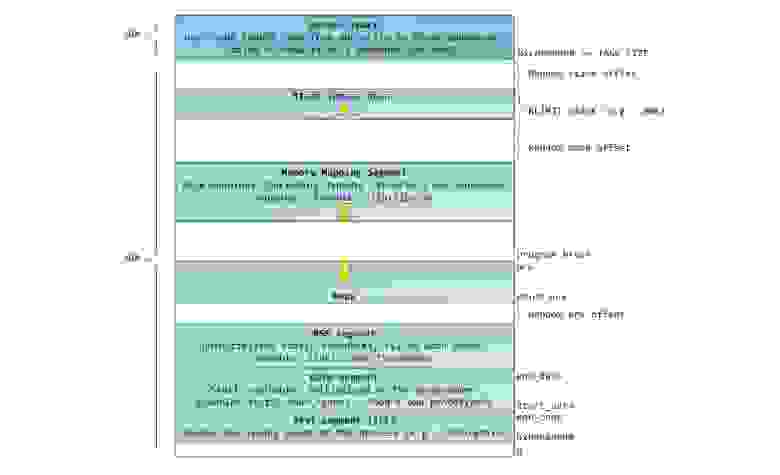
Давным давно, когда компьютерная техника находилась в совсем еще младенческом возрасте, начальные виртуальные адреса сегментов были совершенно одинаковыми почти для всех процессов, выполняемых машиной. Из-за этого значительно упрощалось удаленное эксплуатирование уязвимостей. Эксплойту часто необходимо обращаться к памяти по абсолютным адресам, например по некоторому адресу в стеке, по адресу библиотечной функции, и тому подобное. Хакер, рассчитывающий осуществить удаленную атаку, должен выбирать адреса для обращения в слепую в расчете на то, что размещение сегментов программы в памяти на разных машинах будет идентичным. И когда оно действительно идентичное, случается, что людей хакают. По этой причине, приобрел популярность механизм рандомизации расположения сегментов в адресном пространстве процесса. Linux рандомизирует расположение стека, сегмента для memory mapping, и кучи – их стартовый адрес вычисляется путем добавления смещения. К сожалению, 32-битное пространство не очень-то большое, и эффективность рандомизации в известной степени нивелируется.
В верхней части user mode space расположен стековый сегмент. Большинство языков программирования используют его для хранения локальных переменных и аргументов, переданных в функцию. Вызов функции или метода приводит к помещению в стек т.н. стекового фрейма. Когда функция возвращает управление, стековый фрейм уничтожается. Стек устроен достаточно просто — данные обрабатываются в соответствии с принципом «последним пришёл — первым обслужен» (LIFO). По этой причине, для отслеживания содержания стека не нужно сложных управляющих структур – достаточно всего лишь указателя на верхушку стека. Добавление данных в стек и их удаление – быстрая и четко определенная операция. Более того, многократное использование одних и тех же областей стекового сегмента приводит к тому, что они, как правило, находятся в кеше процессора, что еще более ускоряет доступ. Каждый тред в рамках процесса работает с собственным стеком.
Возможна ситуация, когда пространство, отведенное под стековый сегмент, не может вместить в себя добавляемые данные. В результате, будет сгенерирован page fault, который в Linux обрабатывается функцией expand_stack(). Она, в свою очередь, вызовет другую функцию — acct_stack_growth(), которая отвечает за проверку возможности увеличить стековый сегмент. Если размер стекового сегмента меньше значения константы RLIMIT_STACK (обычно 8 МБ), то он наращивается, и программа продолжает выполняться как ни в чем не бывало. Это стандартный механизм, посредством которого размер стекового сегмента увеличивается в соответствии с потребностями. Однако, если достигнут максимально разрещённый размер стекового сегмента, то происходит переполнение стека (stack overflow), и программе посылается сигнал Segmentation Fault. Стековый сегмент может увеличиваться при необходимости, но никогда не уменьшается, даже если сама стековая структура, содержащаяся в нем, становиться меньше. Подобно федеральному бюджету, стековый сегмент может только расти.
Динамическое наращивание стека – единственная ситуация, когда обращение к «немэппированной» области памяти, может быть расценено как валидная операция. Любое другое обращение приводит к генерации page fault, за которым следует Segmentation Fault. Некоторые используемые области помечены как read-only, и обращение к ним также приводит к Segmentation Fault.
Под стеком располагается сегмент для memory mapping. Ядро использует этот сегмент для мэппирования (отображания в память) содержимого файлов. Любое приложение может воспользоваться данным функционалом посредством системного вызовома mmap() (ссылка на описание реализации вызова mmap) или CreateFileMapping() / MapViewOfFile() в Windows. Отображение файлов в память – удобный и высокопроизводительный метод файлового ввода / вывода, и он используется, например, для загрузки динамических библиотек. Существует возможность осуществить анонимное отображение в память (anonymous memory mapping), в результате чего получим область, в которую не отображен никакой файл, и которая вместо этого используется для размещения разного рода данных, с которыми работает программа. Если в Linux запросить выделение большого блока памяти с помощью malloc(), то вместо того, чтобы выделить память в куче, стандартная библиотека C задействует механизм анонимного отображения. Слово «большой», в данном случае, означает величину в байтах большую, чем значение константы MMAP_THRESHOLD. По умолчанию, это величина равна 128 кБ, и может контролироваться через вызов mallopt().
Кстати о куче. Она идет следующей в нашем описании адресного пространства процесса. Подобно стеку, куча используется для выделения памяти во время выполнения программы. В отличие от стека, память, выделенная в куче, сохранится после того, как функция, вызвавшая выделение этой памяти, завершится. Большинство языков предоставляют средства управления памятью в куче. Таким образом, ядро и среда выполнения языка совместно осуществляют динамическое выделение дополнительной памяти. В языке C, интерфейсом для работы с кучей является семейство функций malloc(), в то время как в языках с поддержкой garbage collection, вроде C#, основной интерфейс – это оператор new.
Если текущий размер кучи позволяет выделить запрошенный объем памяти, то выделение может быть осуществлено средствами одной лишь среды выполнения, без привлечения ядра. В противном случае, функция malloc() задействует системный вызов brk() для необходимого увеличения кучи (ссылка на описание реализации вызова brk). Управление памятью в куче – нетривиальная задача, для решения которой используются сложные алгоритмы. Данные алгоритмы стремятся достичь высокой скорости и эффективности в условиях непредсказуемых и хаотичных пэттернов выделения памяти в наших программах. Время, затрачиваемое на каждый запрос по выделению памяти в куче, может разительно отличаться. Для решения данной проблемы, системы реального времени используют специализированные аллокаторы памяти. Куча также подвержена фрагментированию, что, к примеру, изображено на рисунке:

Наконец, мы добрались до сегментов, расположенных в нижней части адресного пространства процесса: BSS, сегмент данных (data segment) и сегмент кода (text segment). BSS и data сегмент хранят данные, соответствующий static переменным в исходном коде на C. Разница в том, что в BSS хранятся данные, соответствующие неинициализированным переменным, чьи значения явно не указаны в исходном коде (в действительности, там хранятся объекты, при создании которых в декларации переменной либо явно указано нулевое значение, либо значение изначально не указано, и в линкуемых файлах нет таких же common символов, с ненулевым значением. – прим. перевод.). Для сегмента BSS используется анонимное отображение в память, т.е. никакой файл в этот сегмент не мэппируется. Если в исходном файле на C использовать int cntActiveUsers, то место под соответствующий объект будет выделено в BSS.
В отличии от BSS, data cегмент хранит объекты, которым в исходном коде соответствуют декларации static переменных, инициализированных ненулевым значением. Этот сегмент памяти не является анонимным — в него мэппируется часть образа программы. Таким образом, если мы используем static int cntWorkerBees = 10, то место под соответствующий объект будет выделено в data сегменте, и оно будет хранить значение 10. Хотя в data сегмент отображается файл, это т.н. «приватный мэппинг» (private memory mapping). Это значит, что изменения данных в этом сегменте не повлияют на содержание соответствующего файла. Так и должно быть, иначе присвоения значений глобальным переменным привели бы к изменению содержания файла, хранящегося на диске. В данном случае это совсем не нужно!
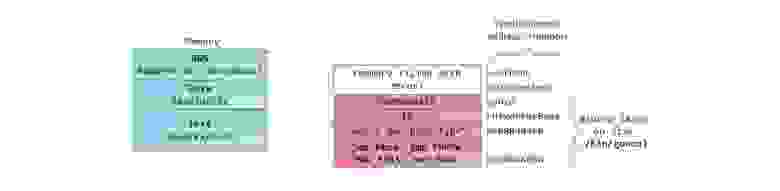
Мы можем посмотреть, как используются области памяти процесса, прочитав содержимое файла /proc/pid_of_process/maps. Обратите внимание, что содержимое самого сегмента может состоять из различных областей. Например, каждой мэппируемой в memory mapping сегмент динамической библиотеке отводится своя область, и в ней можно выделить области для BSS и data сегментов библиотеки. В следующем посте поясним, что конкретно подразумевается под словом “область”. Учтите, что иногда люди говорят “data сегмент”, подразумевая под этим data + BSS + heap.
Можно использовать утилиты nm и objdump для просмотра содержимого бинарных исполняемых образов: символов, их адресов, сегментов и т.д. Наконец, то, что описано в этом посте – это так называемая “гибкая” организация памяти процесса (flexible memory layout), которая вот уже несколько лет используется в Linux по умолчанию. Данная схема предполагает, что у нас определено значение константы RLIMIT_STACK. Когда это не так, Linux использует т.н. классическую организации, которая изображена на рисунке:

Ну вот и все. На этом наш разговор об организации памяти процесса завершен. В следующем посте рассмотрим как ядро отслеживает размеры описанных областей памяти. Также коснемся вопроса мэппирования, какое отношение к этому имеет чтение и запись файлов, и что означают цифры, описывающие использование памяти.



