Боковая панель
НАЧАЛО РАБОТЫ
МОДЕЛИ
ПРЕДОБРАБОТКА
ПРИМЕРЫ
Sequential model: руководство
Модель Sequential представляет собой линейный стек слоев.
Вы может создать модель Sequential, передав список слоев конструктору модели:
| from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential([Dense(32, input_shape=(784,)), Activation(‘relu’), Dense(10), Activation(‘softmax’),]) |
| model = Sequential() model.add(Dense(32, input_dim=784)) model.add(Activation(‘relu’)) |
Указание размерности входных данных
Ваша модель должна знать, какую размерность данных ожидать на входе. В связи с этим, первый слой модели Sequential (и только первый, поскольку последующие слои производят автоматический расчет размерности) должен получать информацию о размерности входных данных. Есть несколько способов сделать это:
Таким образом, следующие примеры эквивалентны:
| model = Sequential() model.add(Dense(32, input_shape=(784,))) |
| model = Sequential() model.add(Dense(32, input_dim=784)) |
Компиляция
Перед обучением модели необходимо настроить сам процесс. Это выполняется с помощью метода compile(). Он получает три аргумента:
# Задача бинарной классификации
model.compile(optimizer=’rmsprop’, loss=’binary_crossentropy’, metrics=[‘accuracy’])
# Среднеквадратичная ошибка регрессии
model.compile(optimizer=’rmsprop’, loss=’mse’)
# Пользовательская метрика
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer=’rmsprop’, loss=’binary_crossentropy’, metrics=[‘accuracy’, mean_pred])
Обучение
Модели Keras обучаются на Numpy-массивах, содержащих набор исходных данных и метки. Для обучения обычно используется функция fit(). Документация по этой функции здесь.
# Модель с одномерными входными данными и бинарной классификацией
model.add(Dense(32, activation=’relu’, input_dim=100))
# Генерируем случайные данные
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Обучаем модель, перебирая данные в пакетах по 32 примера
model.fit(data, labels, epochs=10, batch_size=32)
# Модель с одномерными входными данными и 10 классами
model.add(Dense(32, activation=’relu’, input_dim=100))
# Генерируем случайные данные
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Преобразуем метки в OHE (one-hot encoding)
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Обучаем модель, перебирая данные в пакетах по 32 примера
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
Примеры
Вот несколько примеров, с которых можно начать!
В папке примеров вы также найдете варианты решения задач с реальными наборами данных:
Многослойный персептрон (MLP) для мультиклассовой классификаци (softmax):
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# Генерируем случайные данные
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(
np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(
np.random.randint(10, size=(100, 1)), num_classes=10)
# Dense(64) — это полносвязный слой с 64 скрытыми нейронами.
# в первом слое вы должны указать размерность входных данных:
# здесь, это векторы длинной 20.
model.add(Dense(64, activation=’relu’, input_dim=20))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
score = model.evaluate(x_test, y_test, batch_size=128)
MLP для бинарной классификации:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Генерируем случайные данные
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model.add(Dense(64, input_dim=20, activation=’relu’))
score = model.evaluate(x_test, y_test, batch_size=128)
VGG-подобная сверточная сеть:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Генерируем случайные данные
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(
np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(
np.random.randint(10, size=(20, 1)), num_classes=10)
# применим здесь сверточный слой с 32 нейронами и ядром свертки (3, 3)
model.add(Conv2D(32, (3, 3), activation=’relu’,
input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(Conv2D(64, (3, 3), activation=’relu’))
model.add(Conv2D(64, (3, 3), activation=’relu’))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
Классификация последовательностей с помощью LSTM:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
Классификация последовательностей с помощью одномерной свертки:
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model.add(Conv1D(64, 3, activation=’relu’,
input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation=’relu’))
model.add(Conv1D(128, 3, activation=’relu’))
model.add(Conv1D(128, 3, activation=’relu’))
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
Классификация последовательностей с помощью LSTM с памятью:
В этой модели мы накладываем 3 слоя LSTM друг на друга, делая модель способной изучать временные представления более высокого уровня.
Первые два слоя возвращают свои полные выходные последовательности, но последний слой возвращает только последний шаг своей выходной последовательности. Таким образом отбрасывается временное измерение (то есть входная последовательность преобразуется в один вектор).
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# ожидаемая размерность входных данных:
# (batch_size, timesteps, data_dim)
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim)))
# возвращает последовательность векторов длинной 32
model.add(LSTM(32, return_sequences=True))
# возвращает последовательность векторов длинной 32
model.add(LSTM(32)) # возвращает одиночный векторов длинной 32
# Генерируем случайные данные
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Генерируем случайные проверочные данные
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
LSTM с передачей состояния
Рекуррентная модель с состоянием — это модель, для которой внутренней состояние, полученное после обработки очередного пакета данных, повторно используется в качестве начальных состояний для выборок следующей серии. Это позволяет обрабатывать более длинные последовательности.
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
# ожидаемая размерность входных данных:
# (batch_size, timesteps, data_dim)
# Обратите внимание, что мы должны указать полную размерность входных
# данных batch_input_shape, так как это сеть с состоянием
# i-тый пример в k-ом пакете является продолжением
# i-того примера в k-1-ом пакете
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
# Генерируем случайные данные
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# Генерируем случайные проверочные данные
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
batch_size=batch_size, epochs=5, shuffle=False,
Как начать работу с Keras

Если вы только недавно открыли для себя нейронные сети и собираетесь их изучать, то вы на правильном пути. Многие новички начинают погружаться в машинное обучение через Keras – открытую нейросетевую библиотеку, написанную на языке Python.
В сегодняшней статье мы рассмотрим, что представляет собой Keras, а также поговорим о таком понятии, как Deep Learning.
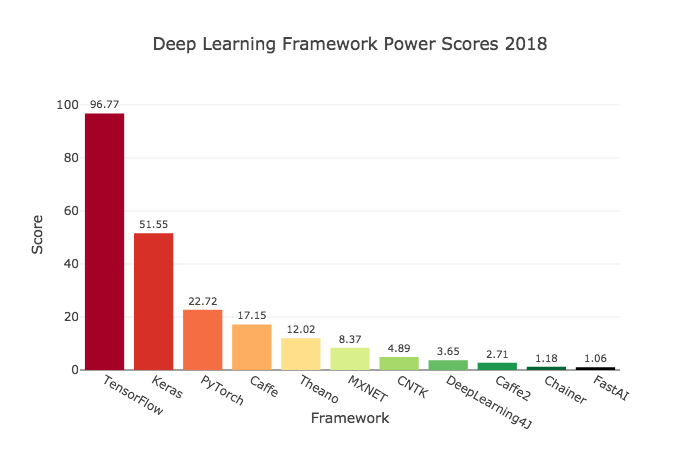
Что такое Keras
Keras – это библиотека для Python, позволяющая легко и быстро создавать нейронные сети. Она совместима с TensorFlow, Theano, Microsoft Cognitive Toolkit и MXNet. Первые две платформы наиболее используемы для разработки алгоритмов глубокого обучения, но довольно сложны в освоении. Keras же, напротив, представляет собой отличный вариант для тех, кто только начинает изучение нейронных сетей.
Создатель библиотеки Франсуа Шолле, инженер Google, разработал Keras для того, чтобы максимально упростить процесс создания нейронных сетей. Упор был на расширяемости, модульности и минимализме с поддержкой Python.
Разработка Keras позволила компании Google внести большой вклад в глубокое обучение и искусственный интеллект. Связано это в первую очередь с тем, что библиотека содержит современные алгоритмы, которые ранее были недоступны.
Из особенностей принято выделять следующие факторы:
Что такое глубокое обучение
Глубокое обучение (от англ. Deep learning) – это совокупность методов машинного обучения, позволяющая обучать модель и предсказывать результат по набору входных данных. Технология основана на искусственных нейронных сетях. Они получают алгоритмы обучения и объемы данных, которые постоянно растут для повышения эффективности обучения. Чем больше данных – тем эффективнее процесс.
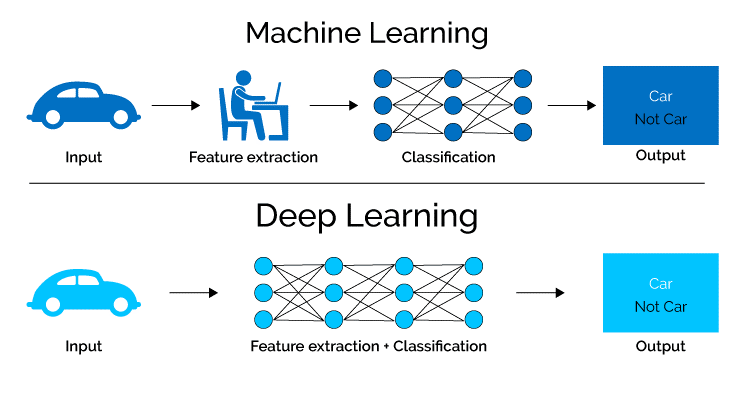
Обучение называется глубоким, потому что со временем нейронная сеть покрывает все большее количество уровней. Подобный процесс состоит из двух фаз – обучения и формирования выводов. Первый рассматривается как способ маркировки больших объемов данных и определение их характеристик, которые в последующем сравниваются и запоминаются системой. Это необходимо для того, чтобы сделать правильные выводы, когда система повторно сталкивается с подобными данными.
Этапы глубокого обучения:
Когда происходит формирование выводов, система делает некоторые заключения, после чего маркирует неизученные данные, исходя из полученной ранее информации.
Появление глубокого обучения привело к значительным достижениям в области компьютерного зрения. Благодаря этому мы можем классифицировать изображения, находить в них объекты и отмечать их заголовками. Для этого глубокие нейронные сети со многими скрытыми слоями могут последовательно изучать более сложные функции из исходного входного изображения:
Эти типы глубоких нейронных сетей называются свёрточными нейронными сетями. Они представляют собой многослойные нейронные сети, которые предполагают, что входные данные являются изображениями.
Модели глубокого обучения в Keras
В основе Keras лежат модели, основной тип которых – последовательность, представляющая собой линейный стек слоев.
Суть в следующем: создается последовательность и к ней добавляются слои в том порядке, в котором нужно выполнить вычисления. После определения компилируется модель, использующая базовую платформу для оптимизации вычислений.
Далее модель должна соответствовать данным – это можно сделать по одной партии данных за один раз или запустив весь режим обучения модели. Когда обучение будет завершено, модель можно использовать для прогнозирования новых данных.
Также есть еще один тип моделей – это класс Model, используемый с функциональным API.
Как установить Keras
В установке нет ничего сложного, главное – чтобы был установлен один из движков. Рекомендую попробовать TensorFlow. Подробнее на нем останавливаться не будем, его инсталляция отлично описана на официальном сайте.
Также вам могут потребоваться следующие компоненты:
После этого можно переходить к установке Keras, сделать это можно с помощью одной команды:
Альтернативная команда – установка из репозитория GitHub. Для начала потребуется сделать клон:
Затем перейдите в папку, где находится библиотека и воспользуйтесь командой:
Работа с Keras на примере
Рассмотрим работу Keras с движком TensorFlow на примере базовых операций: загрузки набора данных, построения модели, добавления параметров, компиляции, тренировки и оценки. С их помощью мы создадим собственный классификатор рукописных цифр на основе набора данных MNIST.
Шаг 1: Используем набор помеченных данных
В Keras много помеченных наборов данных, которые можно импортировать. В нашем случае нам потребуется MNIST, загрузить который можно следующим образом:
Шаг 2: Загружаем необходимые слои
Keras включает в себя большое количество слоев и параметров: функции потерь, оптимизаторы, метрики оценки и прочее. Они используются для создания, настройки, тренировки и оценки нейронных сетей.
Нам потребуются следующие слои:
Также для классификатора используем свёрточную нейронную сеть:
Шаг 3: Используем метод предварительной обработки данных
Будем использовать метод Keras.np_utils.to_categorical() для унитарной кодировки y_train и y_test. Выглядит он следующим образом:
Шаг 4: Используем метод add()
Для добавления импортированных слоев воспользуемся методом add():
Шаг 5: Используем метод compile()
Данный метод предназначен для процесса обучения:
Шаг 6: Используем метод fit()
Тренировку выполним с помощью метода fit():
Выглядит тренировка следующим образом:
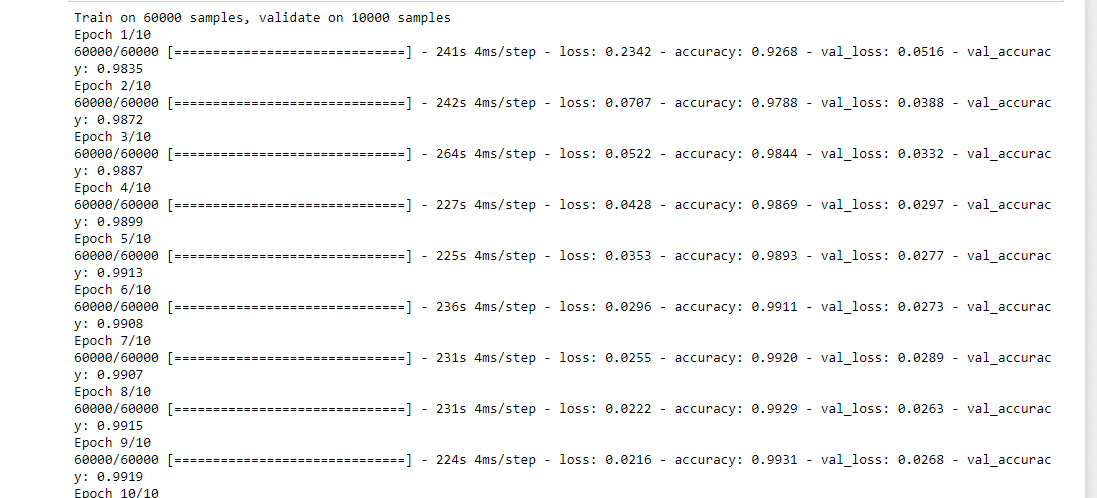
Шаг 7: Оцениваем модель
Следующий этап после тренировки – проверка результатов на новых данных либо с помощью методов predict_classes() или evaluate(). Возьмем в качестве примера изображение:
Первым делом конвертируем его в нужный нам формат набора – MNIS. Затем попробуем распознать:
Шаг 8: Сохраняем модель
Как я уже говорил ранее, Keras является модульным – таким образом, мы можем сохранить модель и использовать ее в последующем:
Вот такими несложными действиями у нас получилось создать классификатор рукописных цифр – в этом и есть прелесть Keras. Это отличное решение для тех, кто только-только начинает вникать в нейронные сети и хочет поближе познакомиться с глубоким обучением.
Боковая панель
НАЧАЛО РАБОТЫ
МОДЕЛИ
ПРЕДОБРАБОТКА
ПРИМЕРЫ
Sequential
API модели Sequential
Для начала прочтите это руководство по модели Keras Sequential.
Методы последовательной модели
compile
| compile(optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None) |
Настраивает модель Keras Sequential для обучения.
Исключения
fit
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False)
Обучает модель Keras Sequential для фиксированного количества эпох (итераций на наборе данных).
Аргументы
validation_data: Данные, по которым оцениваются потери и любые показатели модели в конце каждой эпохи. Модель не будет обучена работе с этими данными. данные validation_data будут переопределять данные validation_split. данные validation_data могут быть: — кортеж (x_val, y_val) нулевых массивов или тензоры — кортеж (x_val, y_val, val_sample_weights) нулевых массивов — набор данных или итератор набора данных.
Для первых двух случаев необходимо указать batch_size. В последнем случае должны быть предоставлены validation_steps.
shuffle: Булевы (чтобы перетасовать тренировочные данные перед каждой эпохой) или str (для «batch»). «Batch» — это специальная опция для работы с ограничениями данных HDF5; он тасуется в кусках пакетного размера. Не имеет эффекта, когда steps_per_epoch не None.
Объект History. Его атрибут History.history представляет собой запись обучающих значений потерь и метрик в последующие эпохи, а также значений потерь проверки и метрик проверки (если применимо).
Исключения
evaluate
evaluate(x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
Возвращает значение потерь и метрики для модели Keras Sequential в тестовом режиме.
Вычисление производится партиями.
Аргументы
Исключеия
Возврат
Скалярные тестовые потери (если модель имеет один выход и не имеет метрик) или список скаляров (если модель имеет несколько выходов и/или метрик). Атрибут model.metrics_names даст вам метки отображения для скалярных выходов.
predict
predict(x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
Генерирует предсказания для входных сэмплов.
Вычисление производится партиями.
Аргументы
Возврат
Numpy массив(ы) предсказаний.
train_on_batch
train_on_batch(x, y, sample_weight=None, class_weight=None, reset_metrics=True)
Выполняет обновление одного градиента на одном пакете данных.
Аргументы
Возврат
Скалярные потери при обучении (если модель имеет один выход и не имеет метрик) или список скаляров (если модель имеет несколько выходов и/или метрик). Атрибут model.metrics_names даст вам метки отображения для скалярных выходов.
test_on_batch
test_on_batch(x, y, sample_weight=None, reset_metrics=True)
Тестируем модель Keras Sequential на одной партии образцов.
Аргументы
Возврат
Скалярные тестовые потери (если модель имеет один выход и не имеет метрик) или список скаляров (если модель имеет несколько выходов и/или метрик). Атрибут model.metrics_names даст вам метки отображения для скалярных выходов.
predict_on_batch
Возвращает прогнозы для одной партии образцов.
Аргументы
Возврат
Numpy массив(ы) предсказаний.
fit_generator
fit_generator(generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, validation_freq=1, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=True, initial_epoch=0)
Поставляет модель Keras Sequential на основе данных, сгенерированных пакетно по пакетам генератором Python (или экземпляром Sequence).
Генератор работает параллельно с моделью, для большей эффективности. Например, это позволяет выполнять увеличение данных на изображениях на CPU в реальном времени параллельно с обучением модели на GPU.
Использование keras.utils.Sequence гарантирует упорядочение и однократное использование каждого входа в эпоху при использовании use_multiprocessing=True.
Returns
A History object. Its History.history attribute is a record of training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable).
Пример
def generate_arrays_from_file(path):
while True:
with open(path) as f:
for line in f:
# создавать Numpy массивы входных данных
# и метки, из каждой строки в файле.
x1, x2, y = process_line(line)
evaluate_generator
evaluate_generator(generator, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=0)
Оценивает модель Keras Sequential на генераторе данных.
Генератор должен возвращать данные того же типа, что и test_on_batch.
Аргументы
generator: Генератор, выдающий кортежи (входы, цели) или (входы, цели, sample_weights) или экземпляр объекта Sequence (keras.utils.Sequence), чтобы избежать дублирования данных при использовании многопроцессорной обработки.
steps: Общее количество шагов (партий образцов) для выхода из генератора до остановки. Необязательно для Sequence: если не указано, будет использоваться len(generator) в качестве нескольких шагов.
callbacks: Список экземпляров keras.callbacks.callback. List of callbacks to apply during training (Список обратных вызовов, применяемых во время тренировки). См. callbacks.
max_queue_size: максимальный размер очереди генератора.
workers: Целостный. Максимальное количество процессов для раскрутки при использовании многопоточности на основе процессов. Если не указано, то по умолчанию рабочие будут равны 1. Если 0, то генератор будет выполняться в главном потоке.
use_multiprocessing: если значение True, использовать многопоточность на основе процессов. Обратите внимание, что поскольку эта реализация основана на многопроцессорной обработке, не следует передавать генератору непикируемые аргументы, так как они не могут быть легко переданы дочерним процессам.
verbose: verbosity mode, 0 или 1.
Возврат.
Скалярные тестовые потери (если модель имеет один выход и не имеет метрик) или список скаляров (если модель имеет несколько выходов и/или метрик). Атрибут model.metrics_names даст вам метки отображения для скалярных выходов.
Исключения
predict_generator
predict_generator(generator, steps=None, callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=0)
Генерирует предсказания для входных образцов из генератора данных.
Генератор должен возвращать данные того же вида, что и принятый в predict_on_batch.
Аргументы
Возврат
Numpy массив(ы) предсказаний.
Исключения
get_layer
get_layer(name=None, index=None)
Восстанавливает слой на основе его имени (уникального) или индекса.
Если указаны и name, и index, то приоритет будет отдан индексу.
Индексы основываются на порядке обхода горизонтального графика (снизу вверх).
Аргументы
Возврат
Исключения



