Грабли на пути к keep-alive
Увеличение активности обмена данными между микросервисами зачастую является проблемой в архитектуре современных IT решений. Выжать максимум и выжить любой ценой — серьёзный вызов для любой разработки. Поэтому поиск оптимальных решений — это не прекращающийся процесс. В статье кратко изложены проблемы, которые могут возникнуть при высоконагруженном использовании http запросов и пути их обхода.
Эта история начинается с ошибки. Как-то мы проводили нагрузочное тестирование, основным элементом которого было выполнение большого количества коротких http запросов. Клиент, написаный под netcore 2.2, начиная с какого-то момента, выдавал System.Net.Sockets.SocketException: Address already in use. Достаточно быстро выяснилось, что на клиенте не успевали освобождаться порты, и в какой-то момент система получала отказ в открытии нового. Теперь, если перейти к коду, проблема была в использовании старого подхода с классом HttpWebRequest и конструкции:
Казалось бы, мы высвобождаем ресурс, и порт должен быть освобожден своевременно. Однако netstat сигнализировал о быстром росте количества портов в состоянии TIME_WAIT. Это состояние означает ожидание закрытия соединения (и возможно получение потерянных данных). Как следствие порт может находится в нем 1-2 минуты. Данная проблема рассмотрена довольно подробно во многих статьях (Проблемы с очередью TIME_WAIT, История о TIME_WAIT). Все же это означает, что dotnet «честно» пытается закрыть соединение, а дальнейшее происходит уже по вине настроек таймаута в системе.
Почему так происходит и как с этим бороться
Не буду рассказывать про keep-alive. Об этом можно почитать самостоятельно. Целью статьи является попытка обойти грабли, заботливо разложенные на пути разработчика. Согласно msdn, свойство KeepAlive класса HttpWebRequest по умолчанию равно true. То есть все это время HttpWebRequest «обманывал» сервер, предлагая ему поддержать соединение, после чего сам же его разрывал. Если быть точнее, HttpWebRequest с настройками по умолчанию не отправлял заголовок «Connection: keep-alive», просто этот режим подразумевается в стандарте HTTP/1.1. Первое, что следовало попробовать, это принудительно отключить KeepAlive. Если установить HttpWebRequest.KeepAlive = false, то в запросе появляется заголовок «Connection: close». Надо признать, что на тестовом стенде это полностью решило проблему. В качестве сервера был настроен nginx со статической страницей.
Тестировался следующий код:
Однако при попытке запустится на серверном железе, при больших нагрузках (свыше 1000 запросов в секунду) этот код вновь начал выдавать те же ошибки. Только теперь порты находились в состоянии CLOSE_WAIT, LAST_ACK. Это пред-финальные состояния закрытия соединения, когда клиент ждет подтверждение от инициатора закрытия. Такое поведение сигнализирует о том, что клиент начинает «захлебываться» вновь открываемыми соединениями.
Закрывать нельзя, переиспользовать
Действительно, чтобы добиться максимальной производительности, соединение нужно переиспользовать. Для этого необходимо включить режим keep-alive и взять класс HttpClient. Как именно он работает и как лучше его использовать стоит почитать здесь и здесь.
Другой вопрос заключается в том, как убедится, что соединения переиспользуются? Существование одного keep-alive соединения регулируется двумя основными параметрами на сервере nginx:
Если просматривать соединения в netstat или wireshark, то при больших нагрузках открытые порты на клиенте также будут стремительно меняться. Только выставив keepalive_requests в большие значения (> 1000) можно увидеть, что все работает как надо.
Вывод
Если вы не используете http запросы в высоконагруженном режиме, то вам подойдет любой вариант. Вряд ли вы успеете исчерпать все порты. Если же в вашем приложении переиспользовать соединения смысла нет, например вы редко повторно обращаетесь к серверу, то стоит сознательно отключать keep-alive. Также keep-alive стоит использовать правильно и с осторожностью при большом потоке запросов, регулируя время жизни соединения в зависимости от частоты повторных обращений к серверу.
И напоследок немного тестовых сравнений производительности:
Сервер nginx настроен с параметрами:
Ошибки и решение проблем с Базой Данных
На что влияет ошибка Базы Данных и почему появляется?
При ошибке базы данных TRASSIR не может записать новые события и узнать что-нибудь про старые. Вы не сможете посмотреть инциденты за прошлый день в экспертном режиме POS или проверить, какие номера машин въехали на территорию на прошлой неделе. Хотя новые события могут появляться в интерфейсе TRASSIR, они не попадут в базу данных и будут утеряны.
База данных запускается и работает отдельной службой независимо от работы TRASSIR. В Настройки сервера → База Данных на регистраторе вводятся настройки подключения TRASSIR к базе данных. Поэтому есть три основных причины возникновения ошибки базы данных:
В качестве базы данных TRASSIR использует СУБД PostgeSQL.
Особенности Базы Данных на разных платформах
TRASSIR OS
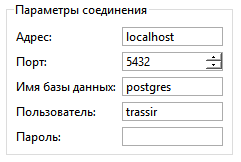
Пароль вводить не требуется.
Windows
Как правило, база данных находится на той же машине, что и сервер TRASSIR
Чтобы проверить, запущена ли у вас служба PostgreSQL:
Известные ошибки и пути их решения
fe_sendauth: no password supplied

PgConnection disconnected
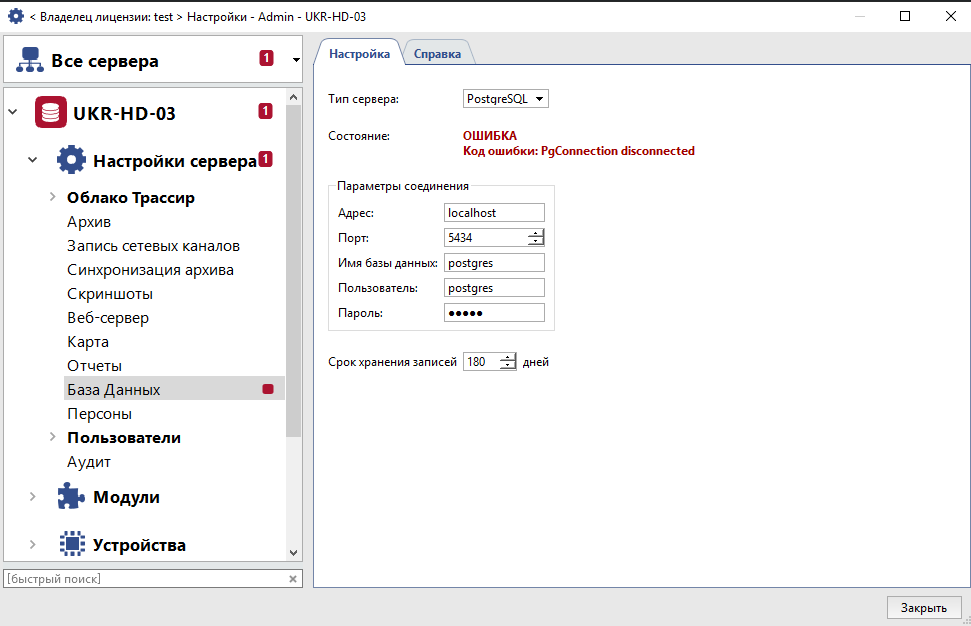
Причина: Неверно указан Адрес или Порт.
Пароль вводить не требуется.
Иероглифы-postgres или другие понятные буквы-Иероглифы
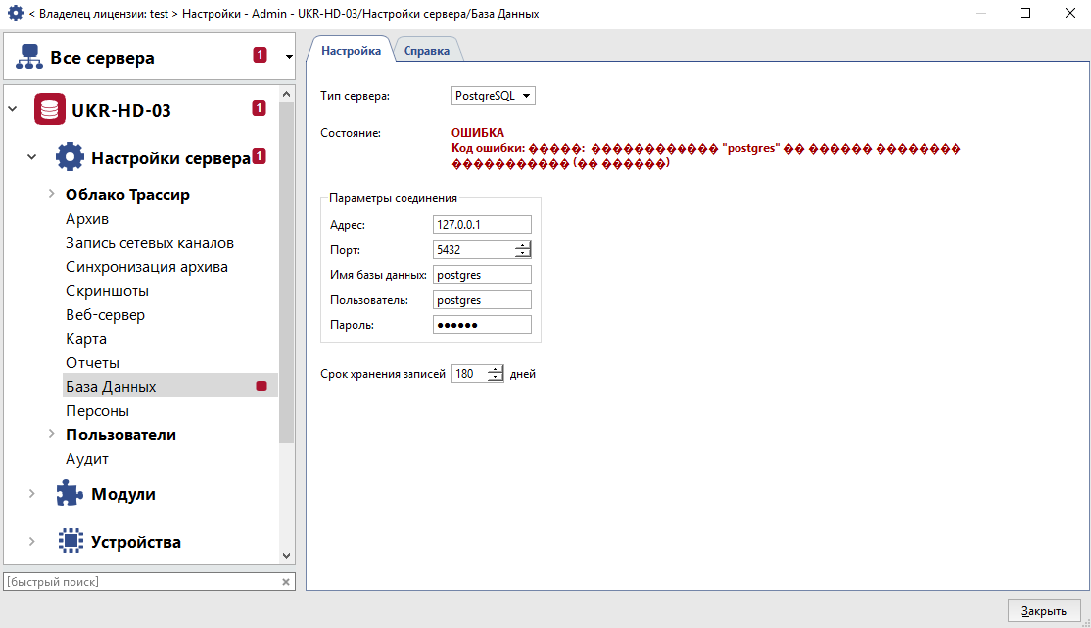
Пароль вводить не требуется.
Не удалось подключиться к серверу. В соединении отказано. Он действительно работает по адресу.

Пароль вводить не требуется.
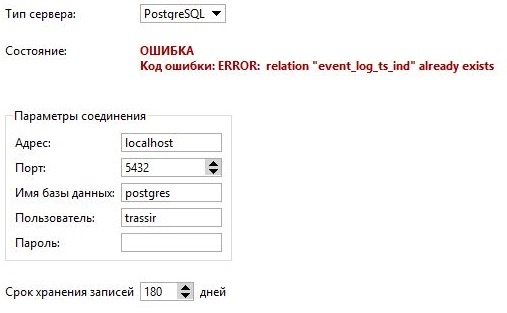
Причина: После обновления, замены лицензии или при некоторых сбоях TRASSIR не с первого раза внёс данные в базу.
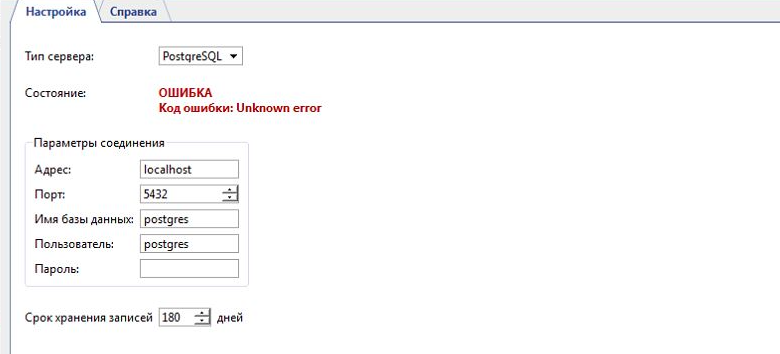
Unknown error
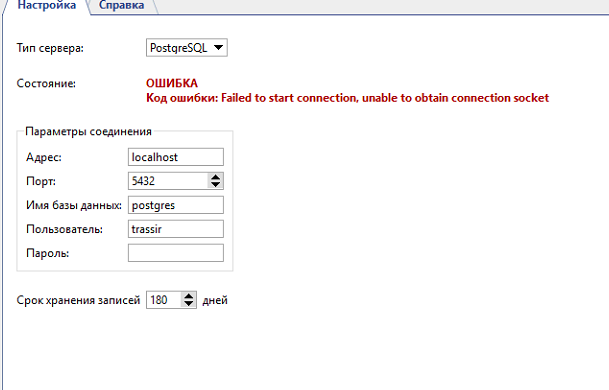
Failed to start connection, unable to obtain connection socket
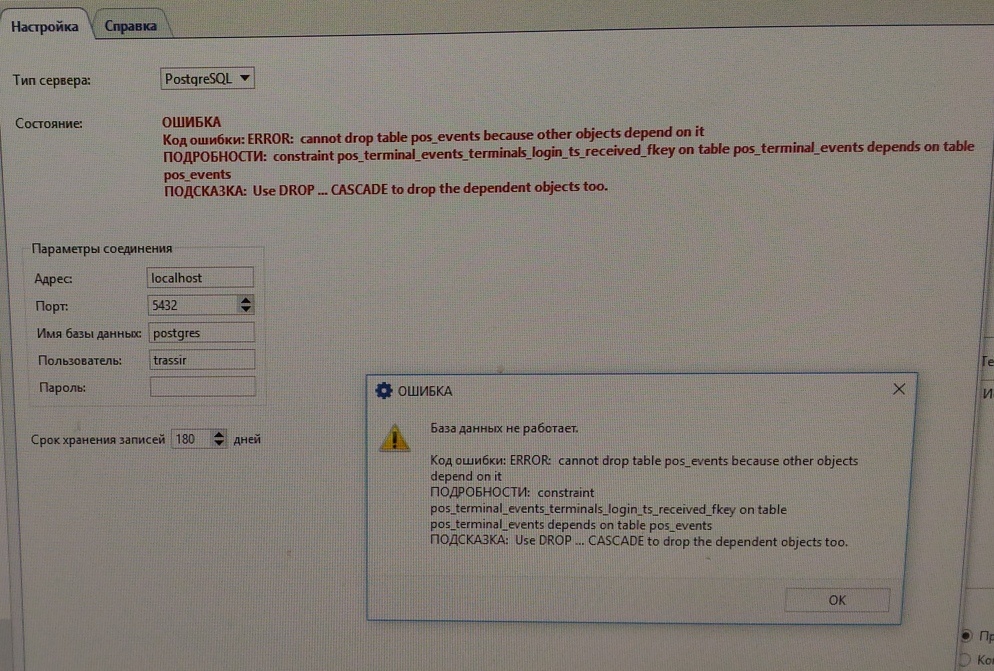
cannot drop table pos_events/pos_incidents.
Причина: Сломана база данных
Случайно поменяли настройки подключения к базе данных, как можно вернуть обратно?
Пароль вводить не требуется.
В остальных случаях можно восстановить настройки из ранее созданного бэкапа
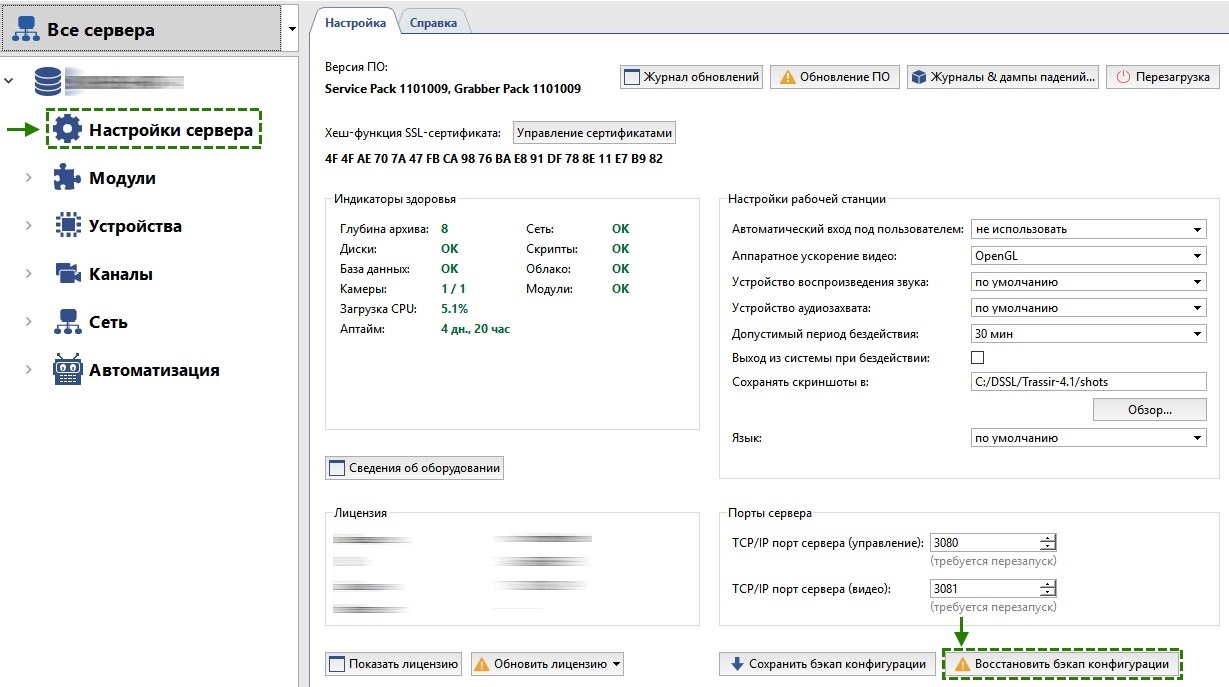
Так как настройки восстанавливаются все без исключения, вы можете потерять, например, подключения к камерам, созданные после бэкапа. Поэтому перед восстановлением бэкапа рекомендуется вручную сохранить текущие настройки: в Настройки сервера нажмите Сохранить бэкап конфигурации → В файл.
Из файла: В Настройки сервера нажмите Восстановить бэкап конфигурации → Из файла.
Из облака: Если сервер был добавлен в облако, то бэкап его настроек может автоматически сохраняться в облаке. Для восстановления из облачного бэкапа в Настройки сервера нажмите кнопку Восстановить бэкап конфигурации → Облако и выберите наиболее подходящий вам по дате бэкап.
Если был утерян пароль для базы данных, работающей на Windows, можно временно настроить вход без пароля.
С помощью инструкции из нашего руководства найдите файл настройки pg_hba.conf и сделайте его резервную копию. В файле замените md5 на trust. Сохраните файл, найдите службу PostgreSQL в списке служб, нажмите на неё правой кнопкой и выберите Перезапустить. После перезапуска к базе данных можно будет подключиться без пароля. Этот способ рекомендуется только для сохранения данных из базы с последующей переустановкой PostgreSQL.
Пересоздание базы данных
В некоторых случаях возможно сохранить данные из повреждённой базы и загрузить их в новую базу.
TRASSIR OS: Воспользуйтесь скриптами из статьи Backup PSSQL.
Большинство способов необратимо удаляет текущую базу данных вместе со всеми записанными в ней событиями.
TRASSIR OS
Если регистратор хранит базу данных на архивных дисках, нужно только удалить старую базу данных. TRASSIR самостоятельно создаст новую базу данных. Для удаления воспользуйтесь одним из способов:
Используйте скрипт удаления базы данных на диске регистратора Remove BD on TRASSIR OS
Удалите базу данных вручную
Убедитесь, что вы выбрали нужную папку и только её. В соседних папках находится архив.
Сломанная база данных не пропадёт с предыдущего диска. Если в будущем ПО TRASSIR начнёт использовать этот диск для хранения базы данных, ошибка снова появится.
Если служба PostgreSQL работает, известны логин и пароль для подключения и проблема только в самой базе данных, то достаточно создать другую базу данных в уже работающей службе и настроить работу TRASSIR с новой базой данных.
Русские Блоги
Что такое HTTP Keep-Alive? Как это работает?
HTTP Keep-Alive
В первые дни http каждый http-запрос требовал открыть соединение через сокет tpc, а затем отключить соединение tcp после его однократного использования.
Использование keep-alive может улучшить это состояние, то есть можно непрерывно отправлять несколько данных без отключения по TCP-соединению. Используя механизм keep-alive, количество соединений TCP-соединений может быть уменьшено, что также означает, что состояние соединения TIME_WAIT может быть уменьшено, что повышает производительность и повышает пропускную способность сервера httpd (меньшее количество соединений tcp означает меньшее количество вызовов ядра системы, сокетов Принять () и закрыть () вызовы).
Тем не менее,keep-aliveЭто не бесплатный обед. Длинные TCP-соединения могут легко привести к неэффективному использованию системных ресурсов. Неправильно настроенная поддержка активности может иногда стоить дороже, чем повторное использование соединений. Поэтому важно правильно установить время ожидания активности.
keepalvie timeout
Демон Httpd обычно предоставляет параметр установки времени ожидания активности. Например, keepinlive_timeout для nginx и KeepAliveTimeout для Apache. Это значение времени keepalive_timout означает, что TCP-соединение, сгенерированное http, должно удерживать секунду keepalive_timeout после передачи последнего ответа, прежде чем оно начнет закрывать соединение.
Когда демон httpd заканчивает отправку ответа, он должен немедленно предпринять попытку закрыть соответствующее TCP-соединение. После установки keepalive_timeout демон httpd захочет сказать: «Подождите немного и посмотрите, запросил ли браузер его». Это время keepalive_timeout. Если демон не получает запрос http от браузера в течение этого времени ожидания, соединение http закрывается.
Напишите скрипт ниже для удобного тестирования:
1. Когда время keepalive_timeout равно 0, то есть когда Keep-Alive не включен, жизненный цикл TCP-соединения:
Можно видеть, что без сохранения alive_timeout время, необходимое ресурсу сокета от установления к реальному выпуску, составляет: установление соединения TCP + передача запроса HTTP + выполнение сценария PHP + передача ответа HTTP + закрытие соединения TCP + 2MSL. (Примечание. Время здесь можно использовать только в качестве эталона. Конкретное время в основном определяется пропускной способностью сети и размером ответа.)
2. Когда время keepalive_timeout больше 0, то есть, когда Keep-Alive включен, жизненный цикл TCP-соединения. Для анализа мы установили keepalive_timeout равным 300 с
3. Когда время keepalive_timeout больше 0 и несколько HTTP-ответов отправляются по одному и тому же TCP-соединению. Здесь для анализа мы установили keepalive_timeout равным 180 с.
С помощью этого теста мы хотим выяснить, запускает ли keepalive_timeout таймер с конца первого ответа или заканчивается последний таймер. Результаты теста подтвердили последнее: здесь мы отправляли запрос каждые 120 секунд и отправляли 3 запроса через TCP-соединение.
http keep-alive и tcp keep-alive
То есть, только когда значение nginx keepalive_timeout установлено выше, чем tcp_keepalive_time и последний HTTP-ответ, переданный из этого tcp-соединения, после истечения времени tcp_keepalive_time операционная система отправит пакет обнаружения, чтобы решить, следует ли сбрасывать TCP-соединение. Обычно это не тот случай, если вам не нужно это делать.
keep-alive и TIME_WAIT
Использование http keep-alvie может уменьшить количество серверов TIME_WAIT (поскольку демон httpd сервера активно закрывает соединение). Причина очень проста: по сравнению с включением поддержки активности установлено меньше соединений TCP и, естественно, закрыто меньше соединений TCP.
в конце концов
Я хочу использовать схематическое изображение, чтобы проиллюстрировать разницу между использованием keepalive. Кроме того, http keepalive является результатом сотрудничества между клиентским браузером и демоном httpd сервера, поэтому мы подготовили отдельную статью, чтобы представить использование keepalive в разных ситуациях в разных браузерах.
Преодоление разрыва удаленного соединения при отсутствии действий пользователя
При работе с GUI и терминальными приложениями нередко случается, что пользователь, работая в режиме удаленного доступа (как правило, через Интернет), покинув компьютер минут на 15, по возвращении обнаруживает, что программа зависла. На любое действие она отвечает ошибкой, содержащей примерно такие фразы: «Потеряна связь с сервером», «[WINSOCK] virtual circuit reset by host» и т.п. Наблюдается такое и при выполнении «долгоиграющих» методов (запросов к серверу), в которых не предусмотрен вывод прогресс-бара или какая-либо интерактивность.
Данная проблема характерна не только для GUI и терминальных решений на базе СУБД Caché и Ensemble компании InterSystems, а вообще для любого клиент-серверного взаимодействия по протоколу TCP/IP. Обычно она решается на прикладном уровне путём периодического обмена пустыми сообщениями специального вида, предназначенными лишь для того, чтобы просигнализировать о том, что приложение «живо».
Ниже о том, как можно решать эту проблему без программирования.
Источник проблемы
Источник проблемы лежит в природе протокола TCP/IP. Как правило, источник сеанса TCP/IP и его приемник находятся в различных сетях, и на пути сеанса встречается несколько маршрутизаторов. Хотя бы один из них обычно выполняет NAT-преобразование адресов. Ресурсы маршрутизатора всегда ограничены, поэтому некоторые из них выполняют очистку NAT-таблиц от «мёртвых» сеансов. Сеанс считается «мёртвым», если по нему не передавались пакеты в течение некоторого заданного интервала времени (назовем его интервал очистки). Таким образом, «молчаливый» сеанс может быть принят за «мёртвый» и вычищен из NAT-таблицы. При этом ни источник, ни приемник об этом не уведомляются («не царское дело»), и оба они остаются в уверенности, что сеанс ещё «жив» (в чем легко убедиться командой netstat, выполнив ее на клиенте или на сервере в момент возникновения ошибки, но до нажатия на ОК). Когда пользователь, получивший сообщение об ошибке, нажмет на ОК, о разрыве сеанса узнает клиент; серверный же процесс завершится, когда «умерший» сеанс распознает ОС.
Экспериментально установлено, что интервал очистки у многих маршутизаторов (по крайней мере, с прошитым Linux 2.4/iptables) составляет около 10 минут. Постараемся заставить наш TCP-сеанс автоматически поддерживать себя в активном состоянии, даже когда не передается никаких пакетов с данными.
Предлагаемое решение
На уровне ОС обнаружением разорванных TCP-соединений управляют следующие параметры ядра, управляющие работой механизма tcp_keepalive [1]:
• tcp_keepalive_time — интервал времени с момента отправки последнего пакета с данными; по истечении этого срока соединение помечается как требующее проверки; после начала проверки параметр не используется;
• tcp_keepalive_intvl — интервал между проверочными пакетами (отправка которых начинается по истечении tcp_keepalive_time);
• tcp_keepalive_probes — количество неподтвержденных проверочных пакетов; по исчерпании этого счетчика соединение считается разорванным.
Надо сказать, что механизм tcp_keepalive имеет двойное назначение: он может использоваться как для искусственного поддержания активности соединения, так и для выявления разорванных (так называемых «полуоткрытых») соединений. В данной статье обсуждается в основном первое применение, о втором применении, возможно, речь пойдёт в следующей статье на эту тему.
Для того чтобы механизм tcp_keepalive был задействован для TCP-соединений, необходимы два условия:
• поддержка на уровне ОС; к счастью, и в Windows, и в Linux она имеется;
• на одном из концов соединения сокет должен быть открыт с параметром SO_KEEPALIVE. Как оказалось, сервисы Caché открывают сокеты с этим параметром, а сервис OpenSSH несложно заставить поступать аналогично.
Наибольший интерес для нас представляет первый параметр (tcp_keepalive_time), так как именно от него зависит, насколько часто будет выполняться проверка неактивных (с точки зрения отсутствия трафика) соединений. Его значение по умолчанию — и в Windows, и в Linux — равно двум часам (7200 с). Типичное же время бездействия, после которого наступает разрыв, составляет около 10 минут. Поэтому предлагается установить значение параметра в 5 минут, что позволит искусственно поддерживать активность TCP-сеансов, не перегружая сеть избыточным трафиком (5 минут — это не 5 секунд).
Установка параметров tcp_keepalive на сервере Windows
Вы должны обладать правами Администратора к серверу. В разделе реестра
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
создайте параметр DWORD с именем KeepAliveTime и значением 300000 (десятичным). Параметр задаётся в миллисекундах, поэтому предлагаемое значение — это 5 минут. После чего остановите Caché и перезагрузите сервер.
Что касается двух других параметров tcp_keepalive, то их умолчания в Windows таковы:
KeepAliveInterval
Key: Tcpip\Parameters
Value Type: REG_DWORD—time in milliseconds
Valid Range: 0–0xFFFFFFFE
Default: 1000 (1 секунда)
KeepAliveProbes
Такого параметра (устанавливающего количество неподтвержденных проверочных пакетов), в реестре не существует. Согласно [2], в Windows 2000 / XP / 2003 в этом качестве используется значение параметра TcpMaxDataRetransmission (умолчание — 5), а в более поздних версиях [3] — фиксированное значение, равное 10. Поэтому, если менять только значение первого параметра (с 7200 на 300), сохраняя умолчание для второго, сервер Windows 2008 будет узнавать о разрыве TCP-соединения через 1*10 + 300 = 310 секунд.
Установка параметров tcp_keepalive на сервере Linux
Изменить значения параметров можно «на ходу», не перезагружая сервер. Зайдите как root и выполните:
Чтобы сделать изменение долговечным по отношению к возможным перезагрузкам сервера, проще всего отредактировать файл параметров ядра /etc/sysctl.conf, добавив в него строку (лучше две):
Обратите внимание, что в отличие от Windows, значение параметра задается в секундах.
Что касается остальных двух параметров tcp_keepalive, то их умолчания в Linux таковы:
Если менять только значение первого параметра (с 7200 на 300), сохраняя умолчания для остальных двух, сервер Linux будет узнавать о разрыве соединения только через 75*9 + 300 = 975 секунд.
Установка параметра TCPKeepAlive в конфигурации СУБД Caché
Начиная с версии 2008.2, в Caché для платформ Windows и Linux появилась возможность задавать tcp_keepalive_time на уровне сокета, что удобно, так как позволяет избежать изменения настроек операционной системы. Однако «в чистом виде» эта возможность, в основном, представляет интерес лишь для независимых разработчиков сокет-серверов. К счастью, она была дополнена параметром конфигурации TCPKeepAlive=n в секции [SQL], доступным для редактирования со страницы Портала управления системой: Конфигурация > Общие Настройки SQL. Значение по умолчанию — 300 секунд (то, что доктор прописал). Действие параметра распространяется не только на SQL, но и, как нетрудно догадаться, на любые соединения с Caché, обслуживаемые сервисом %Service_Bindings. К ним относится, в частности, и объектный доступ через CacheActiveX.Factory, поэтому если ваше приложение может использовать этот протокол в качестве транспорта, не стоит упускать такую возможность.
Установка параметров KeepAlive в конфигурации сервера OpenSSH
Если вы используете SSH [4] (для работы в режиме командной оболочки или как транспорт для вашего GUI-приложения), то… скорее всего, проделанной настройки ядра будет достаточно, поскольку сервис OpenSSH (по крайней мере, в версии 5.x) по-умолчанию открывает сокет с параметром SO_KEEPALIVE.
На всякий случай стоит проверить конфигурационный файл /etc/ssh/sshd_config. Найдите в нем строку
Если нашли, то делать ничего не надо, так как значения параметров по умолчанию предоставляются в закомментированном виде.
Протокол SSH v.2 имеет альтернативные средства контроля активности сеансов, например, с помощью настройки параметров сервиса OpenSSH ClientAliveInterval и ClientAliveCountMax.
При использовании этих параметров, в отличие от TCPKeepAlive, запросы KeepAlive отправляются через защищённый SSH канал и не могут быть подменены. Приходится признать, что альтернативные средства являются более безопасными, нежели традиционный механизм TCPKeepAlive, для которого существует опасность анализа KeepAlive-пакетов и организации DoS-атак [5].
Устанавливает время ожидания в секундах, по истечении которого, если не поступает информация со стороны клиента, sshd отправляет ему запрос отклика через защищённый канал. По умолчанию используется 0, что означает, что клиенту не будет направлен такой запрос.
Устанавливает количество запросов клиенту, которые могут быть отправлены sshd без получения на них отклика. Если предел достигнут, sshd разъединяется с клиентом и завершает сеанс. Значение по умолчанию: 3. Если вы установите значение параметра ClientAliveInterval равным 60, оставив ClientAliveCountMax без изменений, то не отвечающие ssh-клиенты будут отключены примерно через 180 секунд. При этом следует отключить механизм TCP KeepAlive, установив
Всегда ли это работает?
Существуют категории сетевых проблем, в которых описанный подход может быть малоэффективен.
Одна из них имеет место, когда из-за низкого качества сетевого обслуживания связь может физически пропадать в течение коротких промежутков времени. Если сеанс бездействует, а связь временно пропадает и восстанавливается до того, как клиент или сервер попытаются что-то друг другу послать, то никто из них ничего «не замечает», и TCP-сеанс сохраняется. В случае периодических проверок TCPKeepAlive возрастает вероятность обращения сервера к клиенту в моменты временного исчезновения связи, что может вести к принудительным разрывам TCP-соединения. В такой ситуации можно попробовать увеличить на сервере KeepAliveInterval до 60-75 секунд (вспомнив, что в Windows умолчание — 1 секунда) при максимальном количестве повторов равным 10, в надежде, что за 10 минут любая временная сетевая проблема самоустранится. Правда, если повторные передачи будут длиться слишком долго, и окажется, что
KeepAliveTime + (KeepAliveInterval * кол-во_повторов) > 10 минут
то TCP-сеанс, несмотря на все предпринятые усилия, может быть принят за «мёртвый» и вычищен из NAT-таблицы.
Другая категория проблем связана с недостаточной пропускной способности используемых маршрутизаторов и/или каналов связи, когда при перегрузке могут теряться любые пакеты, в том числе и KeepAlive. В случае маршрутизаторов такие проблемы иногда решаются сменой прошивки (мне, например, это помогло победить Acorp ADSL XXXX), или, в худшем случае, заменой его на более производительную модель. В случае «слишком узких» каналов связи не остаётся ничего другого, кроме как их расширять.
Заключение
Предложенный подход позволяет искусственно поддерживать активность сеансов TCP/IP, по которым в текущий момент не передается никаких данных, исключительно на системном уровне, не внося каких-либо изменений в прикладной код. На сегодня он проверен и успешно используется в Caché for UNIX (Red Hat Enterprise Linux 5 for x86-64) 2010.1.4 (Build 803), Caché for Windows (x86-64) 2010.1.4 (Build 803), а также в более поздних версиях.
Следует признать, что он эффективно работает, если сетевое соединение физически устойчиво, и кроме разрыва неактивных сеансов других сетевых проблем у вас нет.
При развёртывании приложения в агрессивной среде (удалённый доступ, распределённые системы и т.д.), подумайте о реализации KeepAlive не на уровне TCP, а на уровне защищённого протокола более высокого уровня; хорошим кандидатом здесь оказывается SSH.



