Обзор компонентов управления памятью в SQL Server
Материал посвящен описанию использования подсистемы памяти в MS SQL server. Данный обзор дает только общее представление о структуре управления. Следует помнить, что продукты компании Microsoft поставляются с закрытыми кодами и детальные сведения отсутствуют в общедоступных источниках (насколько удалось выяснить нам, если Вам удалось большее – сообщите, пожалуйста). Общий обзор необходим для понимания описываемых далее возможных проблем SQL server и используемых средств тестирования и измерения производительности.
Memory manager
Состав Memory Manager
Сведения о составе этого компонента весьма ограничены, однако можно выделить следующие составные части ММ: memory nodes, memory clerks (клерки памяти), memory caches (кэши) и memory objects (объекты). Подробнее можно прочитать здесь и здесь.
Также ММ предоставляет несколько счетчиков, которые позволяют оценить использование оперативной памяти в SQL. Подробнее можно прочитать здесь и здесь.
Обобщенно состав ММ представлен на Рисунке 1.1
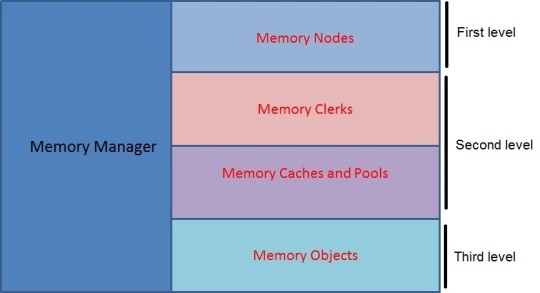
Рисунок 1.1 Компоненты Memory Manager
Объекты ММ используются для распределения памяти внутри экземпляра SQL Server. Memory nodes обеспечивают интерфейс к ОС и реализацию выделения памяти на нижнем уровне. Внутри SQL Server только Memory clerks имеют доступ к интерфейсу. Memory nodes для распределения памяти. Каждый компонент SQL Sever, который потребляет существенный объем памяти должен создать собственный клерк и распределять память именно через его интерфейс.
Реализация управлению памятью меняется от версии к версии SQL, однако основные функциональные компоненты сохраняются. На рисунке 2.2 приведены отличия в реализации ММ в SQL2008 и SQL2012 дополнительные сведения можно найти здесь.
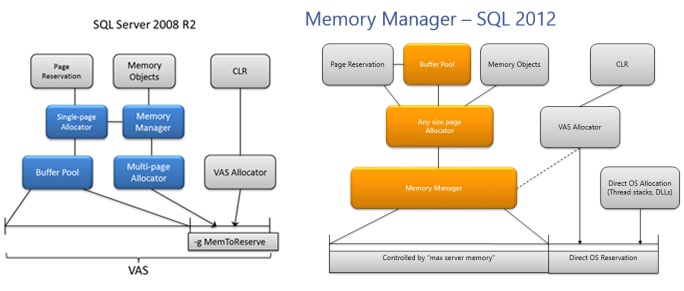
Рисунок 1.2 Изменения в структуре Memory Manager для SQL2008 и SQL 2012
Из рисунков видно, что полностью исчезло разделение page allocator. Эти компоненты были заменены одним Any-size page allocator.
Memory Nodes
Memory Nodes является внутренним объектом SQLOS. Представляет собой логический объект памяти, которая соответствует процессору в случае SMP-реализации или группе процессоров в случае NUMA-реализации. Подробнее можно посмотреть здесь.
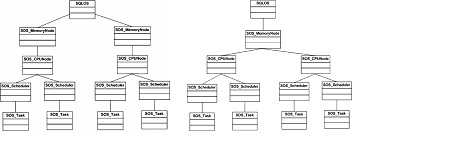
Рисунок 1.3 Иерархия SQLOS в случае реализации SMP (А — рисунок) и NUMA (Б- рисунок)
Memory node абсолютно прозрачна для потребителей памяти. Главная задача этого компонента состоит в определении области выделения памяти. Memory node состоит из нескольких распределителей памяти (memory allocators). На рисунке 2.4 представлены потребители памяти, использующие memory node. Подробнее можно посмотреть здесь и здесь.
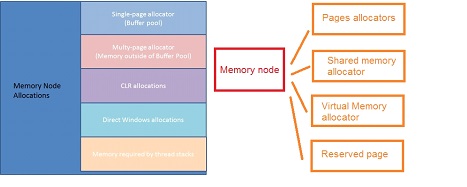
Рисунок 1.4 Memory nodes
Memory allocators являются процедурами, которые определяют тип Windows API используемой для выделения памяти. Аллокаторы содержат программный код используемый для выделения памяти, например, для страниц или использования shared memory.
Memory clerks
Memory nodes обеспечивают интерфейс к ОС и реализацию выделения памяти на уровне Windows. Внутри SQL Server только Memory clerks имеют доступ к интерфейсу Memory nodes для распределения памяти. Каждый компонент SQL Sever, который потребляет существенный объем памяти, должен создать собственный клерк и далее распределять ресурсы именно через его интерфейс.
Таким образом, клерки выполняют следующие функции в рамках Memory manager:
• Отражают использование памяти конкретными компонентами сервера
• Получают уведомления о смене состояний памяти и изменяют её размер согласно обстоятельствам.
• Используют Memory nodes для выделения памяти компонентам сервера.
Выделяют четыре категории клерков. Список категорий приведен в таблице 1. Подробнее можно посмотреть здесь.
Memory Caches
Под понятием «кэш» понимается механизм кэширования различных типов данных с учетом стоимости хранения объектов. Кэш обеспечивает: контроль времени хранения, видимость и анализ статистики обращения к кэшированным данным. Кэшированные данные могут быть использованы одновременно несколькими потребителями. Кроме кэшей SQL Server использует пулы памяти. Пулы в отличии от кэшей используются для хранения однородных данных без дополнительного контроля. Используется несколько механизмов кэширования и них основные:
• Cache Store
• User Store
• Object Store
Только Object Store является пулом, Cache и User Store являются кэшами. Механизмы Cache и User Store весьма похожи, однако если параметры Cache Store контролируются целиком SQLOS, то для User Store разработчики могут использовать собственные алгоритмы управления. В документации также используются понятия Cache Store и User Store со значением “обособленные области памяти”. Каждому Cache Store сопоставлено хранилище hash table. Возможно использование не одной, а нескольких таблиц hash tables. Hash table – это структура в памяти, которая содержит массив указателей на страницы буфера. Хэширование – это методика, которая единообразно отображает значение ключа в соответствующий hash bucket.
Подробнее можно прочитать здесь (про хэш) и здесь и здесь и здесь.
Cache Store используются, например, для хранения кэша планов выполнения, кэша xml, кэша полнотекстового поиска, Procedure Cache, System Rowset Cache. В User Store хранятся в частности кэш метаданных пользовательских и системных баз, токены безопасности, данные схем. Полный список можно найти в динамическом представлении dm_os_memory_cache_counters.
Buffer pool (buffer cache) а также buffer pool extension
Buffer pool (второе название buffer cache) – это область в памяти, которая используется для кэширования страниц, данных таблиц и их индексов, размер страниц 8Кб. Использования Buffer pool уменьшает ввод/вывод в файл базы данных и таким образом увеличивает производительность сервера. При этом Buffer Cach является основным потребителем памяти в SQL Server.

Рисунок 1.5 Компоненты системы управления буфером
В SQL Server 2014 buffer pool может быть расширен в энергонезависимую память, например, на диск SSD. Такое расширение называется Buffer Pool Extension. Подробнее можно прочитать здесь здесь.
Подробнее об управлении буферным кэшем можно прочитать здесь, здесь и здесь.
Буферный кэш имеет собственный клерк памяти и распределят память через page allocator. Для буферного кэша используется клерк памяти типа Generic и называется memoryclerk_sqlbufferpool.
До SQL 2012 Buffer Cache использовал только Single Page Allocator (распределяющий отдельные страницы 8Кб). Если компоненту сервера было необходимо выделить буфер большего, чем 8Кб размера использовался Multi Page Allocator (см. рис. 2.4) и соответственно эта память располагалась за пределами Buffer Pool. C SQL2012 Single и Multi Page allocators были объединены в Any-size page allocator. На рис. 2.2 можно увидеть эти изменения.
Max server memory и min server memory
Хотя управление буферным кэшем происходит автоматически внутри SQL Server, однако администраторы могут регулировать максимальный и минимальный размер распределяемой памяти для этого буфера.
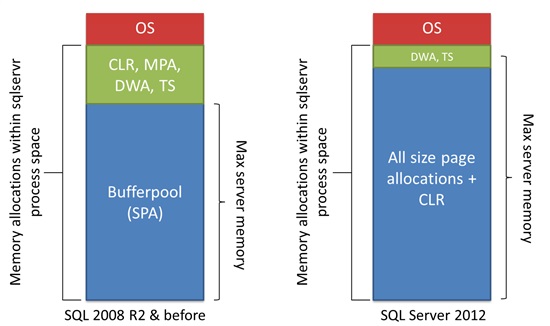
Рисунок 1.6 Изменения в диапазоне памяти резервируемой параметром Max server memory
Как уже упоминалось в SQL 2012 произошли изменения memory manager. В результате таких изменений параметр max server memory регулирует не только память buffer pool, но вообще всё распределение памяти (кроме Direct Memory Allocations производимых с помощью VirtualAlloc).
Параметр min server memory обозначает границу, ниже которой Buffer Pool не будет по требованию освобождать занятую память. При первоначальной загрузке пул не занимает память, указанную в min server memory. Используется минимально необходимый объем, который вычисляется автоматически. Размер пула при необходимости в дальнейшем увеличивается.
Подробнее можно прочитать здесь и здесь.
Stolen pages
Stolen pages — это страницы буферного кэша, которые используются для различных целей в сервере. Например, для процедурного кэша, операций сортировки (т.е. рабочей памяти запроса — workplace memory). Также эти страницы необходимы для хранения таких структур данных, которые требуют распределение памяти менее 8Кб, например, блокировки, контекст транзакций и информации о соединении.
Подробнее можно посмотреть в следующих источниках:
Object Store
Object Store представляет собой пул памяти. Он используется для хранения однородных типов данных без дополнительного контроля стоимости хранения. Эти данные могут быть легко очищены в случае нехватки памяти. По своей структуре пулы являются клерками памяти (т.е. являются одним из его видов). Дополнительно можно посмотреть здесь и здесь.
Memory Objects (MO)
Memory Objects представляют собой кучу памяти, которая использует интерфейс клерков памяти чтобы получить доступ к page allocator для выделения страниц. Memory Objects не используют интерфейсы виртуальной или общей памяти, этот элемент использует только механизм распределения страниц. Многие компоненты SQL Server обращаются напрямую к MO, минуя клерки памяти. МО предоставляют возможность распределить диапазоны памяти произвольного размера.
Memory Broker (МВ)
Memory broker (брокер памяти) является компонентом SQLOS. Брокер памяти отвечает за распределение памяти между различными компонентами SQL Server в соответствии с их запросами. Более подробно можно прочитать на сайте производителя.
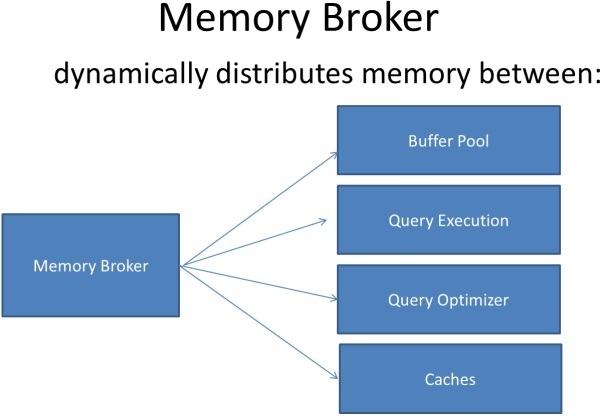
Рисунок 1.7 Распределение памяти Memory Broker
Описание механизма: МВ отслеживает запросы памяти от компонентов SQL и сопоставляет с текущими показатели её использования. Основываясь на полученной информации, брокер вычисляет «оптимальный» размер памяти, которая может быть распределена между компонентами. Брокер уведомляет компоненты о своих вычислениях, после этого каждый компонент использует эти сведения для дальнейшего использования памяти.
Расширение буферного пула
Преимущества расширения буферного пула
Главное назначение базы данных SQL Server — хранение и поиск данных, поэтому интенсивное использование операций дискового ввода-вывода — это основное свойство компонента Database Engine. Так как дисковые операции ввода-вывода могут потреблять много ресурсов и требовать относительно длительного времени для выполнения, в SQL Server особое внимание уделено рациональному использованию операций ввода-вывода. Буферный пул служит основным источником размещения памяти SQL Server. Управление буфером — это ключевой компонент в достижении этой рациональности. Компонент управления буферами состоит из двух механизмов: диспетчера буферов для доступа к страницам баз данных и их обновления и буферного пула для сокращения операций файлового ввода-вывода базы данных.
Страницы данных и индексов считываются с диска в буферный пул, а измененные страницы (так называемые «грязные страницы») записываются обратно на диск. Нехватка памяти в контрольных точках сервера и базы данных приводит к тому, что активные «грязные» страницы удаляются из буферного кэша, записываются на механические диски и считываются обратно в кэш. Эти операции ввода-вывода обычно представляют небольшие произвольные операции чтения и записи с объемом данных от 4 до 16 КБ. Работа в режиме небольших произвольных операций ввода-вывода предполагает частые операции поиска, конкурирующие за перемещение головки диска, что увеличивает задержку ввода-вывода и сокращает общую пропускную способность ввода-вывода системы.
Типичный подход к устранению этих «узких мест» заключается в добавлении дополнительных модулей DRAM или высокопроизводительных шпинделей SAS. Хотя эти варианты работают, у них есть существенные недостатки: модули DRAM дороже, чем диски хранения данных, а установка шпинделей увеличивает капитальные расходы при покупке оборудовании и эксплуатационные расходы из-за повышения энергопотребления и вероятности сбоя компонента.
Компонент расширения буферного пула расширяет кэш буферного пула с помощью памяти энергонезависимого хранилища (обычно на основе SSD-дисков). В результате этого расширения в буферном пуле становится возможным разместить рабочее множество данных большего объема, что обеспечивает подкачку операций ввода-вывода между ОЗУ и SSD-дисками. Это эффективно перераспределяет нагрузку небольших случайных операций ввода-вывода с механических дисков на SSD-диски. Благодаря более низкой задержке и улучшенной производительности случайных операций ввода-вывода SSD-дисков расширение буферного пула значительно повышает пропускную способность ввода-вывода.
В следующем списке приведены преимущества расширения буферного пула.
Повышенная пропускная способность произвольных операций ввода-вывода
Уменьшенная задержки ввода-вывода
Повышенная пропускная способность транзакций
Улучшенная производительность операций чтения с использованием крупного гибридного буферного пула
Архитектура кэширования, которая может использовать современные и будущие недорогие диски
Основные понятия
Следующие термины относятся к компоненту расширения буферного пула.
Твердотельный накопитель (SSD)
Твердотельные накопители постоянно хранят данные в оперативной памяти (ОЗУ). Дополнительные сведения см. в этом определении.
Буфер
В SQL Serverбуфер — это 8-килобайтовая страница в памяти такого же размера, что и страница данных или индекса. Буферный кэш делится на 8-килобайтовые страницы. Страница остается в буферном кэше, пока диспетчеру буферов требуется область буфера для чтения дополнительных данных. Данные записываются обратно на диск, только если они были изменены. Эти измененные страницы в памяти называют «грязными». Страница чиста, когда она эквивалентна ее образу в базе данных на диске. Данные в буферном кэше могут измениться несколько раз, прежде чем будут сохранены обратно на диске.
Буферный пул
Также называют буферным кэшем. Буферный пул — это глобальный ресурс, который совместно используется всеми базами данных для кэшированных страниц данных. Минимальный и максимальный размер кэша буферного пула задается во время запуска или динамической настройки SQL Server с процедуры sp_configure. Этот размер определяет максимальное число страниц, которые могут кэшироваться в буферном пуле в любое время в запущенном экземпляре.
Максимальный объем памяти, который может зафиксировать расширение буферного пула, может ограничиваться другими запущенными на компьютере приложениями, если они вызывают значительную нехватку памяти.
Контрольная точка
Контрольная точка создает известную надежную точку, с которой Компонент Database Engine может начать применение изменений, содержащихся в журнале, во время восстановления после непредвиденного отключения или аварии. Новая контрольная точка записывает «грязные» страницы вместе со сведениями журнала транзакций из памяти на диск, а также сведения о журнале транзакций. Дополнительные сведения см. в разделе Контрольные точки базы данных (SQL Server).
Сведения
SSD-хранилище используется как расширение подсистемы памяти вместо дисковой подсистемы хранилища. Это означает, что файл расширения буферного пула позволяет диспетчеру буферного пула использовать DRAM и NAND-Flash для реализации буферного пула намного большего размера из изменяемых страниц в энергонезависимой ОЗУ на основе SSD. Это создает многоуровневую иерархию кэширования, где на 1-м уровне (L1) DRAM, а на 2-м уровне (L2) файл расширения буферного пула на SSD-дисках. В кэш L2 записываются только чистые страницы, что позволяет обеспечить безопасность данных. Диспетчер буферов обеспечивает перемещение чистых страниц между кэшами L1 и L2.

Если расширение буферного пула включено, оно определяет размер и путь к файлу кэширования буферного пула на SSD-диске. Этот файл представляет собой смежный экстент хранилища на SSD-дисках, которое настраивается статически во время запуска экземпляра SQL Server. Параметры файла конфигурации можно изменить, только если расширение буферного пула отключено. Если расширение буферного пула отключено, все связанные параметры конфигурации удаляются из реестра. Файл расширения буферного пула удаляется после завершения работы экземпляра SQL Server.
Ограничения емкости
Выпуск SQL Server Enterprise допускает максимальный размер расширения буферного пула, который в 32 раза превышает значение max_server_memory.
Выпуск SQL Server Standard допускает максимальный размер расширения буферного пула, который в 4 раза превышает значение max_server_memory.
Рекомендации
Рекомендуется следовать приведенным ниже правилам.
Включив расширение буферного пула первый раз, перезапустите экземпляр SQL Server, чтобы обеспечить максимальную производительность.
Настройте расширение буферного пула так, чтобы соотношение между объемом физической памяти (max_server_memory) и объемом расширения буферного пула не превышало 1:16. Более низкое значение в диапазоне от 1:4 до 1:8 может быть оптимальными. Сведения о настройке параметра max_server_memory см. в разделе Параметры конфигурации сервера «Server Memory».
Тщательно протестируйте расширение буферного пула перед реализацией в рабочей среде. После внедрения в рабочую среду не следует изменять конфигурацию в файле или отключать функцию. Эти действия могут отрицательно повлиять на производительность сервера, поскольку размер буферного пула значительно снижается, когда эта функция отключена. При отключении память, используемая для поддержки функции, не возвращается в кучу, пока не произойдет перезагрузка экземпляра SQL Server. Однако, если функцию снова включить, память будет использоваться повторно без перезапуска экземпляра.
Возврат сведений о расширении буферного пула
Можно использовать следующие динамические административные представления для отображения конфигурации расширения буферного пула и получения сведений о страницах данных в расширении.
Счетчики производительности доступны в объекте диспетчера буферов SQL Server для трассировки страниц данных в файле расширения буферного пула. Дополнительные сведения см. в разделе Счетчики производительности расширения буферного пула.
Русские Блоги
Основы DB2: табличные пространства и буферные пулы
Эта статья помогает новым администраторам баз данных DB2 понять важность табличных пространств и буферных пулов и показывает, как их правильная разработка и настройка могут повысить производительность базы данных.
Эта статья написана для IBM DB2 Universal Database ™ для Linux, UNIX® и Windows®
Для администратора баз данных, который является новичком в DB2, или будущих администраторов баз данных, выбор дизайна и производительности для новой базы данных может привести к путанице. В этой статье мы обсудим две области, в которых администраторы баз данных делают важный выбор: табличные пространства и буферные пулы. Проектирование и настройка табличных пространств и буферных пулов может оказать глубокое влияние на производительность сервера DB2, поэтому мы сосредоточимся на этих действиях.
В нашем примере мы будем использовать DB2 V8.1 Enterprise Server Edition. Большинство примеров также применимы к низкоуровневой версии. Мы сообщим вам, если пример применим только к V8.1.
в Раздел 1 Мы начнем с определения типа табличного пространства и объясним, как DB2 хранит данные в табличных пространствах. Мы представим параметры конфигурации и проведем вас через процесс создания и управления табличными пространствами. Далее мы сосредоточимся на Буферный бассейн Объяснить, что такое буферный пул и как его создавать и использовать. в Раздел 2 Мы объединим эти два аспекта и обсудим, как организовать пулы буферов и табличные пространства для оптимальной производительности.


Табличные пространства могут управляться двумя различными способами:
Система управляемого пространства (SMS) Табличные пространства SMS управляются операционной системой. Контейнеры определяются как обычные файлы операционной системы и доступны через вызовы операционной системы. Это означает, что все обычные функции операционной системы будут обрабатывать следующее: операционная система будет буферизовать ввод-вывод, выделять пространство в соответствии с соглашениями операционной системы, автоматически расширять табличное пространство, если это необходимо. Однако контейнеры не могут быть удалены из табличного пространства SMS и ограничены добавлением новых контейнеров в многораздельную базу данных. Все три табличных пространства по умолчанию, описанные в предыдущем разделе, представляют собой SMS. База данных управляемого пространства (DMS) Табличные пространства DMS управляются DB2. Контейнеры могут быть определены как файлы (им будут выделены все заданные размеры при создании табличного пространства) или как устройства. DB2 может управлять столько операций ввода-вывода, сколько позволяет метод распределения и операционная система. Вы можете расширить контейнер, используя команду altER TABLESPACE. Вы также можете освободить неиспользованную часть контейнера DMS (начиная с V8).
Вот пример, показывающий, как увеличить размер контейнера (эта функция поддерживается как в V7, так и в V8):
Обратите внимание, что только V8 поддерживает меньшее изменение размера исходного контейнера.
При создании базы данных создаются три табличных пространства (SYSCATSPACE, TEMPSPACE1 и USERSPACE1). Используя командное окно DB2 или командную строку UNIX, создайте базу данных с именем testdb, подключитесь к базе данных и перечислите табличные пространства:
следующий Листинг 1 Вывод команды LIST TABLESPACES показан.
Листинг 1Вывод команды LIST TABLESPACES
Три табличных пространства, показанные выше, автоматически создаются командой CREATE DATABASE. Вы можете переопределить создание табличного пространства по умолчанию, включив описание табличного пространства в эту команду, но при создании базы данных вы должны создать табличное пространство каталога и хотя бы одно обычное табличное пространство и хотя бы одно системное временное табличное пространство. Вы можете создать больше табличных пространств всех типов (кроме табличных пространств каталога), используя команду CREATE DATABASE или более позднюю, используя команду CREATE TABLESPACE.
Каждое табличное пространство имеет один или несколько контейнеров. Еще раз, вы можете думать о контейнере как о дочернем элементе, а о табличном пространстве как о его родительском. Каждый контейнер может принадлежать только одному табличному пространству, но табличное пространство может иметь много контейнеров. Контейнеры могут быть добавлены или удалены из табличных пространств DMS, а размер контейнеров может быть изменен. Вы можете добавить контейнер только в табличное пространство SMS в многораздельной базе данных в разделе. Раздел еще не выделил контейнер для табличного пространства до его добавления. Когда добавляется новый контейнер, запускается операция автоматического перебалансирования для распределения данных по всем контейнерам. Операция перебалансировки не препятствует одновременному доступу к базе данных.
Вы можете указать много параметров для табличных пространств при их создании или указать их позже, когда используете оператор altER TABLESPACE.
Размер страницы Определяет размер страницы, используемый табличным пространством. Поддерживаемые размеры: 4K, 8K, 16K и 32K. Размер страницы ограничивает длину строки и количество столбцов таблицы, которые можно поместить в табличное пространство, в соответствии со следующей таблицей:
Таблица 1. Значение размера страницы
Размер страницы
Предел размера строки
Количество столбцов
Максимальная вместимость
8 KB
8 101
1 012
128 GB
16 KB
16 293
1 012
256 GB
32 KB
32 677
1 012
512 GB
Табличные пространства могут содержать до 16384 страниц, поэтому выбор большего размера страницы может увеличить емкость табличного пространства.
Следующий оператор создает обычное табличное пространство. Все настройки обсуждаются для иллюстрации.
При указании параметра SHOW DETAIL в команде LIST TABLESPACES отображается дополнительная информация:
Перечисление 2 Выводится табличное пространство USERSPACE1. По умолчанию перечислены три табличных пространства, созданные при создании базы данных.
Перечисление 2Вывод команды LlST TABLESPACES SHOW DETAIL
Чтобы составить список контейнеров, нам нужно использовать идентификатор табличного пространства из вышеприведенного вывода:
Перечисление 3.LIST TABLESPACE CONTAINERS Вывод команды
Эта команда выведет список всех контейнеров в указанном табличном пространстве. Указанный выше путь указывает на то место, где физически расположен контейнер.
Буферный пул связан с одной базой данных и может использоваться несколькими табличными пространствами. При рассмотрении вопроса об использовании пула буферов для одного или нескольких табличных пространств необходимо убедиться, что размер страницы табличного пространства и размер страницы пула буферов одинаковы для всех табличных пространств, «обслуживаемых» буферным пулом. Табличное пространство может использовать только один буферный пул.
При создании базы данных создается пул буферов по умолчанию IBMDEFAULTBP, который используется всеми табличными пространствами. Вы можете использовать оператор CREATE BUFFERPOOL, чтобы добавить больше буферных пулов. Размер пула буферов по умолчанию равен размеру, указанному параметром конфигурации базы данных BUFFPAGE, но его можно изменить, указав ключевое слово SIZE в команде CREATE BUFFERPOOL. Достаточный размер буферного пула является ключом к хорошей производительности базы данных, потому что он уменьшает наиболее трудоемкую операцию дискового ввода-вывода. Большие буферные пулы также влияют на оптимизацию запросов, так как в памяти можно выполнять больше работы.
Блочный пул буферов
V8 позволяет вам выделить часть пула буферов (до 98%) для операций предварительной выборки на основе блоков. Блочный ввод / вывод может повысить эффективность операций предварительной выборки, считывая блок в смежную область памяти вместо того, чтобы распространять его на отдельные страницы. Размер блока каждого пула буферов должен быть одинаковым и контролироваться параметром BLOCKSIZE. Значение равно размеру блока в страницах, от 2 до 256, и по умолчанию равно 32.
Расширенная память
DB2 не использует расширенную память для буферов. Однако расширенную память можно использовать для кэширования страниц памяти, что ускоряет перемещение страниц из памяти.
Ниже приведен пример оператора CREATE BUFFERPOOL:
Буферный пул выделяется для USERSPACE3 в примере CREATE TABLESPACE выше, и он создается до создания табличного пространства. Обратите внимание, что размер страницы как пула буферов, так и табличного пространства равен 8 КБ, что одинаково. Если вы создаете табличное пространство после создания пула буферов, вы можете опустить синтаксис BUFFER POOL BP3 в операторе CREATE TABLESPACE. Вместо этого вы можете использовать команду altER TABLESPACE, чтобы добавить пул буферов в существующее табличное пространство:
Запросите системное представление SYSCAT.BUFFERPOOLS, чтобы получить информацию о пуле буферов:
Чтобы узнать, какой буферный пул выделен для табличного пространства, выполните этот запрос:
BUFFERPOOLID можно найти в предыдущем запросе, который позволяет увидеть, с каким пулом буферов связано каждое табличное пространство.
Теперь, когда мы описали, что такое табличные пространства и буферные пулы и как их создавать, давайте рассмотрим примеры того, как организовать их визуально в базе данных.
Рисунок 1. Табличные пространства и буферные пулы
База данных имеет 5 табличных пространств: табличное пространство каталога, два обычных табличных пространства, длинное табличное пространство и системное временное табличное пространство. Пользовательское временное табличное пространство не было создано. Есть еще 8 контейнеров.
В этом сценарии пул буферов может быть выделен следующим образом:
Назначьте BP1 (4K) для SYSCATSPACE и USERSPACE2
Назначьте BP2 (8K) на USERSPACE1
Назначьте BP3 (32K) для LARGESPACE и SYSTEMP1
В общем, при разработке способов размещения табличных пространств и контейнеров на физических устройствах цель состоит в том, чтобы максимально увеличить параллелизм ввода-вывода и использование буфера. Достижение этой цели требует полного понимания дизайна базы данных и приложений. Только тогда вы сможете определить, приведут ли проблемы, такие как разделение двух таблиц к разным устройствам, к параллельному вводу-выводу, или таблицы должны быть созданы в отдельных табличных пространствах, чтобы их можно было полностью буферизовать.
Проектирование физического макета новой базы данных следует начинать с организации, которая спроектировала табличное пространство:
Это итеративный процесс, и проект должен быть проверен с помощью стресс-тестов и тестов. Очевидно, что для достижения наилучшего дизайна может потребоваться много усилий, и проект может оказаться оптимальным только в том случае, если производительность базы данных должна быть наилучшей. В общем:
В целом, чтобы снизить сложность управления и поддержки более простого проектирования базы данных, целесообразно немного снизить производительность. У DB2 очень развитая логика управления ресурсами, которая часто дает очень хорошую производительность без тщательного проектирования.
Табличные пространства каталога и системные временные табличные пространства обычно должны выделяться как SMS. Нет необходимости иметь несколько временных табличных пространств с одинаковым размером страницы, обычно достаточно только одного временного табличного пространства с наибольшим размером страницы.
Остается нерешенным вопрос, стоит ли разбивать пользовательские данные на несколько табличных пространств. Одним из соображений является использование страницы. Строки не могут быть разбиты на разные страницы, поэтому таблицы с длинными строками должны иметь соответствующий размер страницы. Однако на странице не может быть более 255 строк, поэтому таблицы с более короткими строками не могут использовать всю страницу целиком. Например, поместив таблицу с длиной строки 12 байт в табличное пространство с размером страницы 32 КБ, он может использовать только приблизительно 10% каждой страницы (т. Е. (255 строк * 12 байт + 91 байт служебных данных) / Размер страницы 32 КБ =
Если таблица большая, это всего лишь соображение, поэтому потраченное впустую пространство очень велико. Это также делает ввод-вывод и кэширование менее эффективными, потому что на каждой странице очень мало полезного контента. Если вы можете поместить таблицы в табличное пространство с меньшими страницами и воспользоваться преимуществами страниц большего размера, наиболее распространенный метод доступа определит, какой из них лучше. Если обычно к большому количеству строк обращаются последовательно (таблица может быть кластеризована), больший размер страницы более эффективен. Если доступ к строкам осуществляется случайным образом, меньший размер страницы позволяет DB2 лучше использовать буфер, поскольку в одной и той же области хранения может храниться больше страниц.
PREFETCHSIZE указывает количество страниц, которые будут считаны из табличного пространства при выполнении предварительной выборки данных. Операции предварительной выборки (обычно сканирование больших таблиц) используются, когда менеджер баз данных определяет, что последовательный ввод-вывод является подходящим, и определяет, что операции предварительной выборки могут помочь повысить производительность. Рекомендуется явно установить значение PREFETCHSIZE, кратное произведению значения EXTENTSIZE табличного пространства и количества контейнеров табличного пространства. Например, если EXTENTSIZE равен 32, а в табличном пространстве 4 контейнера, идеальный PREFETCHSIZE должен быть 128, 256 и т. Д. Если для одной или нескольких часто используемых таблиц требуются значения для этого набора параметров, которые отличаются от тех, которые наиболее применимы к производительности других таблиц в табличном пространстве, размещение этих таблиц в отдельных табличных пространствах может повысить общую производительность.
Если предварительная выборка является важным фактором в табличных пространствах, рассмотрите возможность выделения некоторых буферов для ввода-вывода на основе блоков. Размер блока должен быть равен PREFETCHSIZE.
Наиболее важной причиной использования нескольких пользовательских табличных пространств является управление использованием буфера. Табличное пространство может быть связано только с одним буферным пулом, а буферный пул может использоваться для нескольких табличных пространств.
Наличие нескольких пулов буферов хранит данные в буферах. Например, предположим, что в базе данных есть много небольших таблиц, которые часто используются. Все эти таблицы обычно расположены в буфере, поэтому доступ к ним очень быстрый. Теперь давайте предположим, что существует запрос к очень большой таблице, которая использует тот же пул буферов и должна прочитать больше страниц, чем общий размер буфера. Страницы из этих часто используемых небольших таблиц будут потеряны при выполнении запроса, что потребует повторного чтения данных, когда они понадобятся снова.
Как только таблицы распределены по нескольким табличным пространствам, их физическое хранилище должно быть определено. Табличное пространство может храниться в нескольких контейнерах, и это может быть SMS или DMS. SMS проще в управлении и может быть хорошим выбором для табличных пространств, которые содержат много разных небольших таблиц, таких как табличные пространства каталога, особенно те, которые содержат таблицы больших объектов. Чтобы уменьшить накладные расходы на расширение контейнера SMS по одной странице за раз, вы должны запуститьdb2empfaCommand. Это устанавливает значение параметра конфигурации базы данных MULTIPAGE_ALLOC в YES.
DMS, как правило, имеет лучшую производительность и обеспечивает гибкое хранение данных индекса и большого объекта отдельно. Обычно несколько контейнеров для табличного пространства следует хранить отдельно на отдельных физических томах. Это может улучшить параллельность некоторых операций ввода-вывода. При наличии нескольких пользовательских табличных пространств и нескольких устройств следует учитывать логику приложения, чтобы рабочая нагрузка могла быть как можно более равномерно распределена между этими устройствами.
Устройства RAID имеют свои особые соображения. EXTENTSIZE должен быть равен или кратен размеру полосы RAID. PREFETCHSIZE должен быть равен размеру полосы RAID, умноженному на количество параллельных устройств RAID (или кратному этому продукту). Это значение должно быть кратным EXTENTSIZE. DB2 предоставляет собственные переменные реестра, которые позволяют улучшить вашу конкретную среду. Вы можете включить параллелизм ввода-вывода в контейнере, выполнив эту команду:
Другая переменная реестра, DB2_STRIPED_CONTAINERS = ON, может изменить размер тега контейнера от одной страницы до полного экстента, тем самым делая экстент табличного пространства совместимым с полосой RAID.
Если платформы разные, то эта проблема становится более сложной. Даже при переходе между UNIX и Windows производительность уже оптимальна в одной системе, но не обязательно в другой. Если база данных скопирована для производства, процесс настройки должен быть повторен. Если вам нужно перенести базу данных на zSeries ™, некоторые из обсуждаемых здесь вопросов не применимы, и вам следует обратиться к соответствующим руководствам и Redbooks. В системах iSeries физическая настройка и настройка выполняются вместе вне среды базы данных, и вам следует обратиться к руководству по системному администрированию iSeries ™.



