Кластеризация: расскажи мне, что ты покупаешь, и я скажу кто ты
Задача Datawiz.io: провести кластеризацию клиентов программы лояльности в ритейле.
Кластеризация — это метод поиска закономерностей, предназначенный для разбиения совокупности объектов на однородные группы (кластеры) или поиска существующих структур в данных.
Целью кластеризации является получение новых знаний. Это как “найти клад в собственном подвале”.
Для чего это нужно компаниям? Чтобы лучше узнать своих клиентов. Чтобы найти индивидуальный подход к каждому клиенту, а не работать со всеми одинаково.
Несмотря на то, что многие компании используют программы лояльности и обладают колоссальными данными, их аналитики сначала определяют персону покупателя, а уже потом анализируют ее поведение.
Решение: Machine Learning позволяет пойти от обратного, от личных предпочтений — к персоне. Мы в Datawiz.io используем кластеризацию как метод группирования клиентов по данным о их поведении – покупках, банковских транзакциях, кредитных историях.
Для кластеризации массива данных (чеки, данные по программах лояльности) мы используем алгоритм K-means. Он хорошо масштабируется и оптимизируется под Hadoop.
Также как альтернативу можно использовать алгоритм Affinity Propagation. Конечно, у него есть ряд существенных минусов: он медленный и плохо масштабируется. Но в частных случаях, при желании и наличии свободного времени, можно использовать его для кластеризации на коротких промежутках времени.
1. Clean Datа.
Прежде, чем формировать матрицу — в обязательном порядке чистим информацию. Убираем то, что не влияет на поведение покупателей и является информационным шумом. Для ритейлеров, например, можно исключить рекламную продукцию, выданные дисконтные карты, скретч-карты, тару и пакеты, покупаемые на кассе. После того как данные очищены приступаем к формированию матрицы.
2. Формируем матрицу с входными данными.
Важно: Результаты кластеризации очень зависят от периода времени, по которому она проводится. Если выберем кроткий период — увидим текущие тренды.
Например, проведя кластеризацию перед Новым годом, увидим кластеры, которые не видны на длительном промежутке времени. (Скажем, кластер “Любители “Оливье” и “Селедки под шубой”). Кластеризация за длительный период позволит увидеть картину в целом, то есть клиентов со стабильным поведением (“лайфстайл”). “Студенты”, “Домохозяйки”, “Пенсионеры” и т.д.
Например, ритейлер хочет провести кластеризацию по программе лояльности за полгода.
У магазина есть чеки Васи, который за полгода купил 1 хлеб, 2 молока и 1 батон; и чеки Оли — она купила 3 хлеба, 5 молока и 2 батона за полгода и т.д.
Значит матрица для этого ритейлера будет выглядеть так: 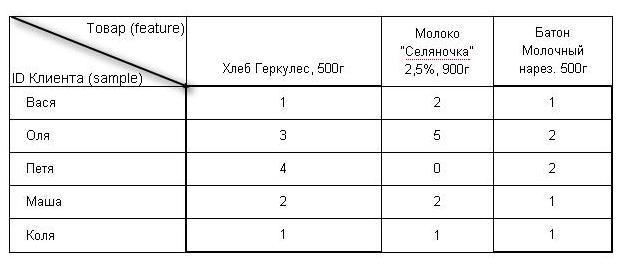
Для ритейлера в среднем, features = 15 тыс. SKU, а samples = 60 тыс. клиентов.
Возьмем каждого отдельно клиента, например Васю со всеми его чеками за полгода. В зависимости от количества вхождений всех товаров по всех его чеках, разместим Васю (и других) на графике, где:
количество осей = количеству товаров (features),
количество точек = количеству клиентов (samples), участвующих в программе лояльности.
Наглядное (и очень схематичное:) изображение: 
Но выглядеть результат кластеризации алгоритмом k-means будет так: 
Также можно проводить кластеризацию по разных уровнях категоризации товаров (feature reduction), тогда матрица будет выглядеть так: 
После того, как матрица сформирована, можно переходить к выбору количества кластеров.
3. Выбираем оптимальное количество кластеров.
Количество кластеров мы выбираем экспериментальным путем, исходя из собственного опыта. Малое количество кластеров будет малоэффективно и не информативно, потому что в таком случае мы получаем один-два “мегакластера”, куда будет входить 98% клиентов и несколько бесполезных маленьких кластеров.
При большом количестве кластеров получится слишком много маленьких групп. К тому же никто не хочет анализировать 5000 отдельных мелких кластеров. Для каждого отдельного случая должен быть свой индивидуальный подход.
Для длительных периодов и большого количества кластеров используем K-means.
4. Проводим кластеризацию.
Выбираем алгоритм K-means (или Affinity Propagation), используем Python библиотеку scikit-learn, на вход даем получившуюся матрицу, запускаем кластеризацию.
5. Анализируем результаты кластеризации.
Результатом работы алгоритма является маркировка всех клиентов программы лояльности, в зависимости от их поведения/покупки. Клиенты с одинаковыми поведенческими характеристиками попадают в один кластер.
Если вы проводите кластеризацию за весь период работы, то в ней участвуют все клиенты программы лояльности. Если за определенный период (год, месяц), то в кластеризации участвуют только те клиенты, которые совершили покупки в заданный период.
Итак, мы провели кластеризацию по программе лояльности для ритейлера за полгода, с количеством кластеров 75. Рассмотрим, как распределились по кластерам покупатели, и какие товары предпочитают в тех или иных кластерах: 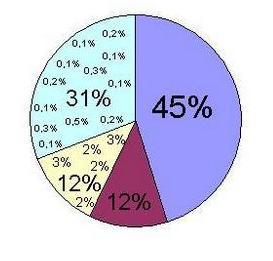
— В “Кластер 1” попало 45% клиентов за этот период. Лидерами продаж по товарам здесь стали: масло, бананы, яйца, молоко, батон, сметана.
— В “Кластере 2” оказалось 12% клиентов. Здесь популярнее остальных уже несколько видов хлеба и сметаны, бананы и непродовольственные товары.
— Пять последующих кластеров уже не такие большие, в каждый из них входят лишь по 2-3% клиентов. (В общей сложности в эти кластеры попали 12% клиентов за выбранный период). Здесь предпочтения клиентов весьма интересны, например: молочные продукты+фрукты, печенье+йогурты\сырки, йогурты\десерты+хлопья, курица+пиво+корм для кошек.
— Оставшиеся 31% покупателей рассеяны по 68 кластерам. в которые входят 0,1-2% клиентов. Также кластер может быть очень маленьким и состоять из 1-2 человек. Чем может быть интересен такой кластер? Читайте в кейсах в конце статьи.
При кластеризации алгоритм выявляет нестандартное поведение клиента. Выявить такое поведение поможет анализ отдельных “фич”(характеристик и особенностей) каждого отдельного кластера.
6. Анализируем характеристики каждого кластера.
7. Проводим персонализированную рассылку по каждому кластеру.
Используя кластеризацию клиентов, можно получить четкую систему рекомендаций для персонала — какой товар, какому клиенту и в какое время предлагать.
Зная, что и какой группе людей предлагать, компании смогут избежать метода “ковровой бомбардировки” при sms или e-mail рассылке. Предлагая клиентам только нужные им товары (не забывая про сопутствующие), можно добиться гораздо большего отклика и конверсии в покупку.
Рассмотрим несколько кейсов от Datawiz.io.
Повышение эффективности промо-рассылок с помощью кластеризации.
В результате кластеризации клиентов одной из сети магазинов мы получили 75 кластеров. Для примера рассмотрим три из них: “молодая семья”, “студент” и “пенсионер”.
— Клиенты кластера “молодая семья” были наиболее восприимчивы к предложениям по покупке подгузников, детского питания, фруктов и молока;
— “студентам” предложили скидки на продукты группы фастфуд и пиво;
— а “пенсионерам” на крупы и овощи.
В следствии такой рассылки конверсия в покупку увеличилась на 14,5 %.
Продвижение нового продукта.
Вариант 1. Чтобы узнать кому будет интересен новый продукт, мы сделали рассылку по всех клиентах программы лояльности. По результатах отклика узнали персону покупателя, которой необходимо маркетировать новый продукт. Далее, отследили нужных нам покупателей в кластерах. Провели рассылку уже только по интересующих нас кластерах.
Вариант 2. Компания не захотела проводить рассылку по всех клиентах, так как база весьма обширна. Поэтому мы создали гипотезу, каким кластерам клиентов этот продукт интересен. Из всех интересующих нас кластеров мы взяли рандомно по 1% клиентов и провели по ним тестовую рассылку. С теми кластерами, которые показали наивысшую конверсию в покупку после тестовой рассылки, и работали в дальнейшем, предлагая новый продукт всему кластеру.
Нестандартное поведение клиента.
Мы провели кластеризацию для магазина одной из сети. Алгоритм выдал кластер, в котором было всего 2 клиента. Но внимание привлекла сумма оборота по этому кластеру за небольшой период. Казалось бы, ну покупают люди много разнообразных продуктов и товаров.
Еще одной интересной деталью было то, что много чеков проводились с разницей в несколько минут. Когда же отследили этих клиентов в базе программы лояльности, оказалось, что владельцами двух дисконтных карт были сотрудники магазина.
Вопрос: может сотрудники таким образом склоняли клиентов к покупке? или зарабатывали себе дисконтные баллы? или продавали товар по полной стоимости, а разницу присваивали, то есть, мошенничали?
Кластерные системы

Parking.ru как облачный провайдер имеет опыт оказания не только услуг с «обычной» надежностью, но и услуг хостинга высокой доступности, построенных на кластеризованной дублированной инфраструктуре.
Имея весомый опыт в построении таких инфраструктурных проектов, мы решили предложить его не только избранным клиентам (которые уже много лет используют эти услуги), а сделать стандартизированное предложение для всех желающих.
Parking.ru запустил целый ряд кластерных решений построенных на надежной дублированной инфраструктуре и имеющих в основе самые разные решения: от виртуальных машин до группы физических серверов. Отдельного внимания заслуживает предложение по ГЕО кластеризации в двух разных ЦОД, объединенных дублированными каналами связи.
Если рассматривать вкратце, то в рамках предложения существуют следующие типовые схемы кластеров:
Кластеры высокой доступности (High Availability cluster)
Создаются для обеспечения высокой доступности сервиса, предоставляемого кластером. Избыточное число узлов, входящих в кластер, гарантирует предоставление сервиса в случае отказа одного или нескольких серверов. Минимальное количество узлов — два, но может быть и больше.
Обычно High Availability кластер строится для Microsoft SQL server’ов, который поддерживает базы данных интернет проектов. High Availability кластер возможно построить и для Exchange систем.
Существует ещё одна разновидность High Availability SQL кластера — «зеркалирование БД» или database mirroring. Этот вид кластера не требует выделенного дискового хранилища, но для автоматического переключения в случае аварии нужен ещё один SQL сервер — следящий/witness. Такой кластер идеально подходит для WEB приложений и требует меньше затрат на создание.
Балансировка нагрузки (Network Load Balancing, NLB)
Принцип действия NLB-кластеров — распределение приходящих запросов на несколько физических или виртуальных узлов серверов. Первоначальная цель такого кластера — производительность, однако, они используются также для повышения надёжности, поскольку выход из строя одного узла приведет просто к равномерному увеличению загрузки остальных узлов. Совокупность узлов кластера часто называют кластерной фермой. Минимальное количество узлов в ферме — два. Максимальное — 32.
При размещении высоконагруженных web-проектов в режиме NLB строится ферма web-серверов на IIS 7.х
Кластеры на виртуальных машинах
Наиболее доступным и масштабируемым решением является построение кластера на основе виртуальных машин на платформе Hyper-V.
В качестве web-боксов NLB-кластера используются виртуальные машины с установленными на них Windows Web Server 2008 (IIS7.х, пользовательское приложение).
В качестве кластера баз данных используется две виртуальные машины необходимой мощности на Windows Server 2008 Standard Edition и SQL Server 2008 Standard Edition.
Отказоустойчивое единое хранилище данных на основе Storage System от NetApp или HP.
Для обеспечения бОльшей надежности все узлы кластера располагаются на различных физических серверах\узлах кластера.
Масштабируемость решения достигается путем увеличения мощности используемых виртуальных машин (вплоть до 100% мощности физического сервера), а также за счет добавления новых узлов в NLB-кластер.
С использованием средств онлайновой миграции со временем возможен перенос узлов кластера на новые, более современные физические сервера без потери работоспособности и без простоя любого узла.
Данный кластер является лучшим решением в соотношении цена/качество и рекомендуется как для критичных для бизнеса приложений, так и для относительно нагруженных web-проектов (
до 30000-50000 посетителей ежедневно).
Кластеры на физических серверах
Web-проекты с нагрузкой выше 50000 посетителей, проекты со специальными требования по безопасности требуют построения кластерных решений на выделенных серверах без потерь мощностей физических серверов на виртуализацию.
Схема построения таких кластеров аналогична схеме построения кластеров на виртуальных машинах, только в качестве узлов используются выделенные физические серверы.
Геокластеры
При построении локальных кластеров единой точкой отказа системы является сама инфраструктура ЦОД. Parking.ru предлагает уникальное решение на российском рынке — построение географически распределенного кластера, узлы которого располагаются в разных ЦОДах Parking.ru.
Каждый из узлов кластера имеет независимый выход в интернет, но при этом из сети данных кластер выглядят как единый сервер с единым адресом и контентом.
Обзор вариантов реализации отказоустойчивых кластеров: Stratus, VMware, VMmanager Cloud

Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности.
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.
Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности — vSphere от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый — Kemari, продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй — Micro Checkpointing, основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.
В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.
В упрощённой форме алгоритм такой:
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:
Отличительные черты кластера:
Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.
К использованию VMmanager Cloud компания пришла из следующих соображений:
В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки — не обойтись без кластера непрерывной доступности.
Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости — избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать — резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя.
Если вы решили, что для ваших задач больше подходит схема высокой доступности и выбрали VMmanager Cloud как инструмент для её реализации, к вашим услугам инструкция по установке и документация, которая поможет подробно ознакомиться с системой. Желаем вам бесперебойной работы!
P. S. Если у вас в организации есть аппаратные CA-серверы — напишите, пожалуйста, в комментариях кто вы и для чего вы их используете. Нам действительно интересно услышать для каких проектов использование такого оборудование экономически целесообразно 🙂
В чем сила, кластер?
Кластер – это не ассоциация или формальное объединение компаний. Хотя разные сети, объединения однозначно работают на кластер и в большинстве ситуаций не мешают. Хотя…важно отслеживать, чтобы такие ассоциации не обязывали стать участником, потому что компании малого бизнеса, например, не всегда будут стремиться куда-то вступить. Главное для кластера – чтобы люди и компании приходили в него, выбирали эту территорию или экосистему в этот период своего развития, на какое-то время оставались тут.
В традиционном понимании кластер – это территория, на которой на расстоянии 2-3 часа езды друг от друга расположено много компаний разного размера (малый, средний, крупный бизнес, стартапы), университеты, технопарки, инкубаторы, разные научно-исследовательские и другие организации, НКО, СМИ, работающих по определенной теме. Концентрация обычно составляет 130 и больше участников (даже в аэрокосмосе и авиации). Именно такой количественный размах «имеет значение» и переходит в качественный – таким образом в одном месте появляется много правильных людей по теме специализации кластера и в результате формируется разнообразие – кластеру нужны люди, которые думают и действуют по-разному. Одна корпорация или компания формируют определенный образ мышления, привычки, модели, а кластер позволяет за них выходить.
Именно поэтому кластер может и должен ежегодно (подчеркну, ежегодно) подтверждать, что он работает: в нем появляются решения по оптимизации и совершенно новым продуктам прежде всего для данной территории, сервисам и даже новые компании, стартапы, проекты, в том числе инновационные для отрасли и мира вообще.
Сильный кластер всегда основан на науке. Что происходит в таком кластере? В идеале в нем разрабатывают научно-производственные решения, которые производство оценивает, как рабочие и внедряет. Например, компания заказывает исследование и разработку решения в университете, и активно сотрудничает с ним в этом процессе. Сейчас это не всегда получаются – не всегда бизнес доверяет университетам. Хороший пример, где получается получить результат – Политехнический университет в Санкт-Петербурге, где умеют работать с обратным инжинирингом.
Понятные, правильные, традиционно самые сильные в мире – это научно-производственные или научно-сервисные кластеры, в которых есть и хорошее образование по специализации. Это касается, например, активно развиваемого Московского международного медицинского кластера.
Все сильные кластеры создают инновации. Это обязательное (без исключений) условие работы кластера. Сейчас этим словом подчеркивают, что инновации должны быть или уже есть в кластере, что к этому надо стремиться, иначе без инноваций территория, город проиграют.
Поэтому понятно и логично стремление Москвы к созданию платформы Инновационного кластера: необходимо и очертить весь потенциал, и объяснить, и представить горожанам и заявить стране\миру, то есть агрегировать инновации во всех имеющихся направлениях, развить новые.
Участникам кластеров нужны витрина и площадка для общения людей из разных отраслей, в том числе для более эффективного продвижения продукции за границей и создания кросс-отраслевых решений. Идея правильная – только слово «суперкластер» запутает людей. Я за то, чтобы найти другое слово, а использовать механизмы развития кластеров.
Кластеры же помогают конкурировать в 21 веке. И в первую очередь – конкурировать за людей! Впервые за историю человечества многие люди могут выбрать «правильный» стиль и место для жизни и работы, где они будут не только жить сами, но и перевезут свои проекты и амбиции. Модель «где родился, там и пригодился» стала слишком тесная. Поэтому все страны мира активно вкладываются в развитие кластеров, объясняя гражданам, что стоит за кластером, который «маркирует» ту или иную локацию определенным образом.
Что значит «объяснять себя» для каждого из нас? Мы (большинство из нас, а не только ограниченная группа специалистов, которые напрямую занимается кластерами) не можем точно объяснить – что сильного, инновационного, классного есть в городе/ регионе. Грубо говоря, а по какому вопросу надо сюда обращаться или что здесь хорошо развивать.
А вот, например, Кремниевая долина вкладывается в свою идентификацию, постоянно конкретизирует и объясняет, что в ней сильного, отстраивается от Сан-Франциско, где другие сильные кластеры, подтверждает, что она продолжает оставаться Меккой для CIT отрасли.



