Работа с БД с помощью JDBC
1. Утверждения (Statements)
Взаимодействовать с БД мы можем с помощью трёх интерфейсов, которые реализуются каждым драйвером:
2. Интерфейс Statement
После этого мы можем использовать наш экземпляр statement для выполнения SQL – запросов. Для этой цели интерфейс Statement имеет три метода, которые реализуются каждой конкретной реализацией JDBC драйвера:
Пример 1. Создание таблицы
3. Интерфейс ResultSet
Этот интерфейс представляет результирующий набор базы данных. Он обеспечивает приложению построчный доступ к результатам запросов в базе данных.
Во время обработки запроса ResultSet поддерживает указатель на текущую обрабатываемую строку. Приложение последовательно перемещается по результатам, пока они не будут все обработаны или не будет закрыт ResultSet.
Основные методы интерфейса ResultSet:
Пример 2. Использование интерфейса ResultSet
4. Пакетное выполнение запросов
Для выполнения набора из нескольких запросов на обновление данных в интерфейс Statement были добавлены методы:
Пакетное выполнение запросов уменьшает трафик между клиентом и СУБД и может привести к существенному повышению производительности.
Пример 3. Пакетное выполнение запросов
5. Интерфейс PreparedStatement
Особенностью SQL-выражений в PreparedStatement является то, что они могут иметь параметры. Параметризованное выражение содержит знаки вопроса в своем тексте. Например:
Перед выполнением запроса значение каждого вопросительного знака явно устанавливается методами setXxx(), например:
Использование PreparedStatement приводит к более быстрому выполнению запросов при их многократном вызове с различными параметрами.
Пример 4. Использование интерфейса PreparedStatement
Пример 5. Использование интерфейса PreparedStatement
6. Использование properties файлов
Пример 6. Содержимое database.properties файла
Пример 7. Использование ResourceBundle для чтения данных для аутентификации
7. Data access object (DAO)
В программном обеспечении data access object (DAO) — это объект, который предоставляет абстрактный интерфейс к какому-либо типу базы данных или механизму хранения. DAO может использоваться для разных видов доступа к БД (JDBC, JPA).
Какой класс или интерфейс позволяет отсылать запросы в бд
Мы приступаем к одному из очень важных разделов программирования на Java — работа с базами данных. Данные являются наверно наиглавнейшей составляющей программирования и вопрос их хранения крайне актуален. Не буду больше говорить о важности этого вопроса — тут можно писать много-много-много разных интересных слов.
Сервер баз данных
Сама идея сервера баз данных и СУБД в виде отдельной программы появилось по совершенно очевидным причинам. Базы данных мгновенно стали МНОГОПОЛЬЗОВАТЕЛЬСКИМИ. Данные нужны всем и возможность одновременного доступа к ним является очевидной. Проблема базы данных в виде обычного файла заключается в том, что к этому файлу будет обращаться сарзу много программ, каждая из которых захочет внести изменения или получить данные. Организовать такой доступ на уровне файловой системы — по сути, невыполнимая задача.
Во-первых — файл должен быть доступен всем пользователям, что требует перекачку данных по сети и хранение этого файла где-то на сетевом диске. Большие объемы данных по сети (пусть даже с высокой скоростью) — кроме слова “отвратительно” у меня ничего не приходит на ум.
Во-вторых — попытка одновременной записи в файл несколькими программами обречена на провал. Для организации такого доступа обычной файловой системы явно не достаточно.
В-третьих — организация прав доступа к тем или иным данным тоже становится непосильной задачей.
В-четвертых — надо “разруливать” конфликты при одновременном доступе к одним и тем же данным.
После небольшого анализа, кроме этих вопросов, можно увидеть еще немалое количество проблем, которые надо решить при мультипользовательском доступе к данным.
В итоге было принято (и реализовано) вполне здравое решение — написать специальную программу, которая имеет несколько названий — Система Управления Базами Данных (СУБД), сервер баз данных и т.д. Я буду называть ее СУБД.
Суть и цель этой программы — организовать централизованный доступ к данным. Т.е. все запросы на получение или изменение данных от клиентских приложений (клинетов) посылаются (обычно по сети и по протоколу TCP/IP) именно в эту программу. И уже эта программа будет заниматься всеми вышеупомянутыми проблемами:
В итоге мы получаем достаточно ясную архитектуру — есть СУБД, которая сосредоточена на работе с данными и есть клиенты, которые могут посылать запросы к СУБД.
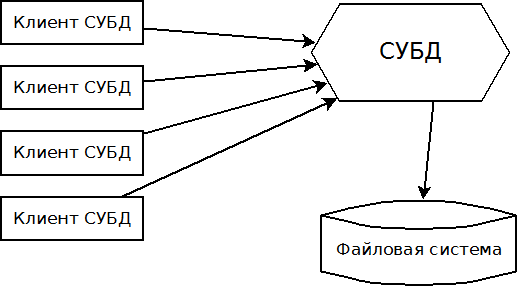
При работе с СУБД клиенты должны решить достаточно четкие задачи:
SQL базы данных
JDBC — Java Database Connectivity — архитектура
Если попробовать определить JDBC простыми словами, то JDBC представляет собой описание интерфейсов и некоторых классов, которые позволяют работать с базами данных из Java. Еще раз: JDBC — это набор интерфейсов (и классов), которые позволяют работать с базами данных.
И вот с этого момента я попробую написать более сложное и в тоже время более четкое описание архитектуры JDBC. Главным принципом архитектуры является унифицированный (универсальный, стандартный) способ общения с разными базами данных. Т.е. с точки зрения приложения на Java общение с Oracle или PostgreSQL не должно отличаться. По возможности совсем не должно отличаться.
Сами SQL-запросы могут отличаться за счет разного набора функций для дат, строк и других. Но это уже строка запроса другая, а алгоритм и набор команд для доставки запроса на SQL-сервер и получение данных от SQL-сервера отличаться не должны.
Думаю, что вы уже догадались — типичный полиморфизм через интерфейсы. Именно на этом и строится архитектура JDBC. Смотрим рисунок.
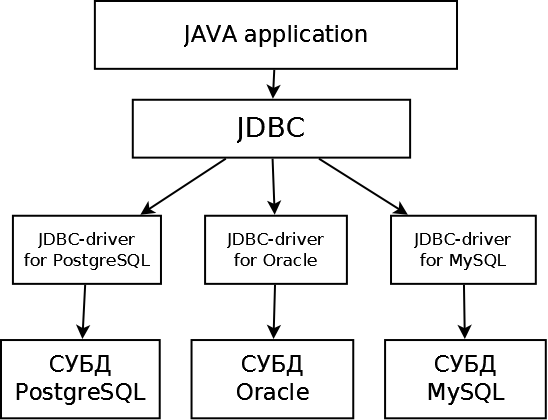
Как следует из рисунка, приложение работает с абстракцией JDBC в виде набора интерфейсов. А вот реализация для каждого типа СУБД используется своя. Эта реализация называется “JDBC-драйвер”. Для каждого типа СУБД используется свой JDBC-драйвер — для Oracle свой, для MySQL — свой. Как приложение выбирает, какой надо использовать, мы увидим чуть позже.
Что важно понять сейчас — система JDBC позволяет загрузить JDBC-драйвер для конкретной СУБД и единообразно использовать компоненты этого драйвера за счет того, что мы к этим компонентам обращаемся не напрямую, а через интерфейсы.
Т.е. наше приложение в принципе не различает, обращается оно к Oracle или PostgreSQL — все обращения идут через стандартные интерфейсы, за которыми “прячется” реализация.
Пока я предлагаю отметить несколько важных интерфейсов, которые мы будем рассматривать позже, но мне бы хотелось, чтобы у вас этот список уже был, чтобы вы могли по мере прочтения отмечать — “да, вот он важный интерфейс/класс и я теперь знаю, куда он встраивается”. Вот они:
Теперь давайте рассмотрим несложный пример и поймем, как работает JDBC.
JDBC — пример соединения и простого вызова
Попробуем посмотреть на несложном примере, как используется JDBC-драйвер. В нем же мы познакомимся с некоторыми важными интерфейсами и классами.
Предварительно нам необходимо загрузить JDBC-драйвер для PostgreSQL. На данный момент это можно сделать со страницы PostgreSQL JDBC Download
Если вы не нашли эту страницу, то просто наберите в поисковике “PostgreSQL JDBC download” и в первых же строках найдете нужную страницу.
Т.к. я пишу эти статьи для JDK 1.7 и 1.8, то я выбрал строку “JDBC41 Postgresql Driver, Version 9.4-1208” — может через пару-тройку лет это будет уже не так.
Если вы выполнили SQL-скрипт из раздела Установка PostgreSQL, который создавал таблицу JC_CONTACT и вставил туда пару строк, то эта программа позволит вам “вытащить” эти данные и показать их на экране. Это конечно же очень простая программа, но на ней мы сможем посмотреть очень важные моменты. Итак, вот код:
Для запуска этой програмы необходимо подключить JDBC-драйвер для PostgreSQL. Прочитайте раздел Что такое JAR-файлы для того, чтобы подключить нужный JAR с JDBC-драйвером к проекту в NetBeans.
Для запуска нашей программы из командной строки достаточно собрать этот код (причем здесь не надо подключать JAR на этапе компиляции — только на момент запуска).
Итак, команда для сборки:
И теперь команда для запуска:
Для запуска проекта в NetBeans предлагаю вам самостоятельно разобраться, как подключить JAR-файл — пример этого указан в статье Что такое JAR-файлы
Начнем разбор нашей программы с самого начала. Итак, в чем же заключается набор вызовов для создания соединения с базой
Вызов Class.forName() мы уже встречали, когда разговаривали о рефлексии. Если вы этого не сделали — обязательно прочитайте, иначе многое будет непонятно. Так вот наш вызов загружает один из ключевых классов JDBC, который реализует очень важный интерфейс java.sql.Driver. Почему этот класс так важен, мы разберем чуть ниже.
Следующим важным вызовом явлется DriverManager.getConnection(url, login, password);.
Думаю, что параметры login и password достаточно оччевидны — это логин и пароль для подключения к СУБД. А вот первый параметр — url надо рассмотреть подробно.
Параметр url является строкой и я люблю его разбивать на две части. Первая часть jdbc:postgresql: позволяет идентифицировать, к какому типу СУБД вы подключаетесь — Oracle, MySQL, PostgreSQL, IBM DB2, MS SQL Server. В нашем случае тип базы данных — PostgreSQL.
Вторая часть — //localhost:5432/contactdb — определяет конкретный экземпляр выбранной базы данных. Т.е. если первая часть url указывает, что мы хотим работать с PostgreSQL, то вторая часть указывает на каком хосте и на каком порту (опять вспоминаем основы TCP/IP) работает конкретный экземпляр PostgreSQL. Еще раз — первая часть поределяет только тип, вторая часть — параметры оединения с конкретным экземпляром СУБД.
Как вы можете видеть, вторая часть включает помимо IP-адреса и порта (localhost:3306) включает имя базы данных, с которой вы будете соединяться.
Собеседование по Java EE — SQL, JDBC (вопросы и ответы)
Вопросы и ответы для собеседования о применении SQL, JDBC в Java разработке.
к списку вопросов раздела JEE
Вопросы
1. ANSI SQL
2. Основные элементы баз данных – таблицы, процедуры, функции, констрейнты и т.д..
3. Как вы понимаете null в базах данных?
4. Агрегатные функции, как они работают с null. Не забудьте о group by и having
5. Каким образом лучше добавлять большое количество записей в таблицу?
6. Что такое первая нормальная форма и процесс нормализации? Какие бывают нормальные формы?
7. В чем смысл индекса СУБД, как они устроены, как хранятся? Как бы вы реализовали тот же функционал?
8. Что такое JDBC API и когда его используют?
9. Что такое JDBC Driver и какие различные типы драйверов JDBC вы знаете?
10. Как JDBC API помогает достичь слабой связи между Java программой и JDBC Drivers API?
11. Что такое JDBC Connection? Покажите шаги для подключения программы к базе данных.
12. Как используется JDBC DriverManager class?
13. Как получить информацию о сервере базы данных из java программы?
14. Что такое JDBC Statement?
15. Какие различия между execute, executeQuery, executeUpdate?
16. Что такое JDBC PreparedStatement?
17. Как установить NULL значения в JDBC PreparedStatement?
18. Как используется метод getGeneratedKeys() в Statement?
19. Какие преимущества в использовании PreparedStatement над Statement?
20. Какие есть ограничения PreparedStatement и как их преодолеть?
21. Что такое JDBC ResultSet?
22. Какие существуют различные типы JDBC ResultSet?
23. Как используются методы setFetchSize() и SetMaxRows() в Statement?
24. Как вызвать Stored Procedures используя JDBC API?
25. Что такое JDBC Batch Processing и какие его преимущества?
26. Что такое JDBC Transaction Management и зачем он нужен?
27. Как откатить JDBC транзакцию?
28. Что такое JDBC Savepoint и как он используется?
29. Расскажите о JDBC DataSource. Какие преимущества он дает?
30. Как создать JDBC пул соединений используя JDBC DataSource и JNDI в Apache Tomcat Server?
31. Расскажите про Apache DBCP API.
32. Какие вы знаете уровни изоляции соединений в JDBC?
33. Что вы знаете о JDBC RowSet? Какие существуют различные типы RowSet?
34. В чем разница между ResultSet и RowSet?
35. Приведите пример наиболее распространенных исключений в JDBC.
36. Расскажите о типах данных CLOB и BLOB в JDBC.
37. Что вы знаете о «грязном чтении» (dirty read) в JDBC? Какой уровень изоляции предотвращает этот тип чтения?
38. Какие есть две фазы commit?
39. Приведите пример различных типов блокировки в JDBC.
40. Как вы понимаете DDL и DML выражения?
41. Какая разница между java.util.Date и java.sql.Date?
42. Как вставить изображение или необработанные данные в базу данных?
43. Что вы можете рассказать о фантомном чтении? Какой уровень изоляции его предотвращает?
44. Что такое SQL Warning? Как возвратить SQL предупреждения в JDBC программе?
45. Как запустить Oracle Stored Procedure с объектами базы данных IN/OUT?
46. Приведите пример возникновения java.sql.SQLException: No suitable driver found.
47. Best Practices в JDBC.
Ответы
1. ANSI SQL
SQL (structured query language — «язык структурированных запросов») — формальный непроцедурный язык программирования, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных, управляемой соответствующей системой управления базами данных (СУБД). SQL основывается на исчислении кортежей. Стандарт SQL определяется с помощью кода ANSI.
*Вопрос «расскажите о SQL» очень широкий и не вписывается в рамки этой статьи. К прочтению любая информация из интернета, например:
SQL : ОБЗОР: http://www.sql.ru/docs/sql/u_sql/ch2.shtml
Wiki: https://ru.wikipedia.org/wiki/SQL
2. Основные элементы баз данных – таблицы, процедуры, функции, констрейнты и т.д.
Поле — это минимальный элемент базы данных, содержащий один неделимый квант информации. Каждое поле характеризуется именем и типом хранящихся в нем данных.
Запись — это совокупность нескольких разнородных полей, описывающая некоторую сущность предметной области.
Таблица базы данных — это набор однородных записей.
Хранимая процедура — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам. В хранимых процедурах могут выполняться стандартные операции с базами данных (как DDL, так и DML). Кроме того, в хранимых процедурах возможны циклы и ветвления, то есть в них могут использоваться инструкции управления процессом исполнения.
JDBC: запросы к базе данных
Запрос к базе данных означает поиск по ее данным. Вы отправляете операторы SQL в базу данных. Для этого сначала нужно открыть соединение с базой данных. Когда у вас есть открытое соединение, вам нужно создать объект Statement, например:
После того, как вы создали Statement, вы можете использовать его для выполнения SQL-запросов, например так:
Когда вы выполняете SQL-запрос, вы получаете ResultSet. ResultSet содержит результат вашего запроса SQL. Результат возвращается в строках со столбцами данных. Вы перебираете строки ResultSet следующим образом:
Метод ResultSet.next() перемещается к следующей строке в ResultSet, если строк больше нет. Если строк больше, возвращается true. Если строк больше не было, он вернет false.
Вам нужно вызвать next() хотя бы один раз, прежде чем вы сможете прочитать какие-либо данные. Перед первым вызовом next() ResultSet располагается перед первой строкой.
Вы можете получить данные столбца для текущей строки, вызвав некоторые методы getXXX(), где XXX – это примитивный тип данных. Например:
Имя столбца для получения значения передается в качестве параметра любому из этих вызовов метода getXXX().
Вместо этого вы также можете передать индекс столбца, например так:
Чтобы это работало, вам нужно знать, какой индекс имеет данный столбец в ResultSet. Вы можете получить индекс данного столбца, вызвав метод ResultSet.findColumn(), например:
При итерации большого количества строк ссылка на столбцы по их индексу может быть быстрее, чем по их имени.
Когда вы закончите итерацию ResultSet, вам нужно закрыть и ResultSet, и объект Statement, который его создал(если вы закончили с ним, то есть). Вы делаете это, вызывая их методы close(), например так:
Конечно, вы должны вызывать эти методы внутри блока finally, чтобы убедиться, что они вызываются, даже если во время итерации ResultSet происходит исключение.
Полный пример
Вот полный пример кода запроса:
И вот снова пример с добавленными блоками try-finally. Обратите внимание, я пропустил блоки catch, чтобы сделать пример короче.
Какой класс или интерфейс позволяет отсылать запросы в бд
JDBC основан на концепции драйверов, которые позволяют получать соединение с базой данных по специально описанному URL. При загрузке драйвер регистрирует себя в системе и в дальнейшем автоматически вызывается, когда программа требует URL, содержащий протокол, за который этот драйвер отвечает.
В чем заключаются преимущества использования JDBC?
Преимуществами JDBC считают:
Что из себя представляет JDBC URL?
JDBC URL состоит из:
Пример JDBC URL для подключения к MySQL базе данных «Test» расположенной по адресу localhost и ожидающей соединений по порту 3306: jdbc:mysql://localhost:3306/Test
Из каких частей стоит JDBC?
JDBC состоит из двух частей:
JDBC превращает вызовы уровня API в «родные» команды того или иного сервера баз данных.
Перечислите основные классы и интерфейсы JDBC.
Перечислите основные типы данных используемые в JDBC. Как они связаны с типами Java?
| JDBC Type | Java Object Type |
|---|---|
| CHAR | String |
| VARCHAR | String |
| LONGVARCHAR | String |
| NUMERIC | java.math.BigDecimal |
| DECIMAL | java.math.BigDecimal |
| BIT | Boolean |
| TINYINT | Integer |
| SMALLINT | Integer |
| INTEGER | Integer |
| BIGINT | Long |
| REAL | Float |
| FLOAT | Double |
| DOUBLE | Double |
| BINARY | byte[] |
| VARBINARY | byte[] |
| LONGVARBINARY | byte[] |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
| CLOB | Clob |
| BLOB | Blob |
| ARRAY | Array |
| STRUCT | Struct |
| REF | Ref |
| DISTINCT | сопоставление базового типа |
| JAVA_OBJECT | базовый класс Java |
Опишите основные этапы работы с базой данных при использовании JDBC.
Как зарегистрировать драйвер JDBC?
Регистрацию драйвера можно осуществить несколькими способами:
Class.forName(«полное имя класса драйвера») ;
Как установить соединение с базой данных?
В качестве параметра может передаваться:
Какие уровни изоляции транзакций поддерживаются в JDBC?
Уровень изолированности транзакций — значение, определяющее уровень, при котором в транзакции допускаются несогласованные данные, то есть степень изолированности одной транзакции от другой. Более высокий уровень изолированности повышает точность данных, но при этом может снижаться количество параллельно выполняемых транзакций. С другой стороны, более низкий уровень изолированности позволяет выполнять больше параллельных транзакций, но снижает точность данных.
Во время использования транзакций, для обеспечения целостности данных, СУБД использует блокировки, чтобы заблокировать доступ других обращений к данным, участвующим в транзакции. Такие блокировки необходимы, чтобы предотвратить:
«грязное» чтение (dirty read) — чтение данных, добавленных или изменённых транзакцией, которая впоследствии не подтвердится (откатится);
неповторяющееся чтение (non-repeatable read) — при повторном чтении в рамках одной транзакции ранее прочитанные данные оказываются изменёнными;
фантомное чтение (phantom reads) — ситуация, когда при повторном чтении в рамках одной транзакции одна и та же выборка дает разные множества строк.
Уровни изоляции транзакций определены в виде констант интерфейса java.sql.Connection :
TRANSACTION_NONE – драйвер не поддерживает транзакции;
TRANSACTION_READ_UNCOMMITTED – позволяет транзакциям видеть несохраненные изменения данных: разрешает грязное, непроверяющееся и фантомное чтения;
TRANSACTION_READ_COMMITTED – любое изменение, сделанное в транзакции, не видно вне неё, пока она не сохранена: предотвращает грязное чтение, но разрешает непроверяющееся и фантомное;
TRANSACTION_REPEATABLE_READ – запрещает грязное и непроверяющееся, фантомное чтение разрешено;
TRANSACTION_SERIALIZABLE – грязное, непроверяющееся и фантомное чтения запрещены.
NB! Сервер базы данных может не поддерживать все уровни изоляции. Интерфейс java.sql.DatabaseMetaData предоставляет информацию об уровнях изолированности транзакций, которые поддерживаются данной СУБД.
При помощи чего формируются запросы к базе данных?
Для выполнения запросов к базе данных в Java используются три интерфейса:
Объекты-носители интерфейсов создаются при помощи методов объекта java.sql.Connection :
Чем отличается Statement от PreparedStatement?
Перед выполнением СУБД разбирает каждый запрос, оптимизирует его и создает «план» (query plan) его выполнения. Если один и тот же запрос выполняется несколько раз, то СУБД в состоянии кэшировать план его выполнения и не производить этапов разборки и оптимизации повторно. Благодаря этому запрос выполняется быстрее.
Суммируя: PreparedStatement выгодно отличается от Statement тем, что при повторном использовании с одним или несколькими наборами параметров позволяет получить преимущества заранее прекомпилированного и кэшированного запроса, помогая при этом избежать SQL Injection.
Как осуществляется запрос к базе данных и обработка результатов?
Выполнение запросов осуществляется при помощи вызова методов объекта, реализующего интерфейс java.sql.Statement :
Как вызвать хранимую процедуру?
Выбор объекта зависит от характеристик хранимой процедуры:
Если неизвестно, как была определена хранимая процедура, для получения информации о хранимой процедуре (например, имен и типов параметров) можно использовать методы java.sql.DatabaseMetaData позволяющие получить информацию о структуре источника данных.
Пример вызова хранимой процедуры с входными и выходными параметрами:
Как закрыть соединение с базой данных?
Соединение с базой данной закрывается вызовом метода close() у соответствующего объекта java.sql.Connection или посредством использования механизма try-with-resources при создании такого объекта, появившегося в Java 7.
NB! Предварительно необходимо закрыть все запросы созданные этим соединением.



