Kafka Connect¶
Kafka Connect – компонент Apache Kafka с открытым исходным кодом, является основой для подключения Kafka к внешним системам, таким как базы данных, хранилища key-value, поисковые индексы и файловые системы. С Kafka Connect можно использовать существующие реализации коннекторов для перемещения данных в сервис Kafka и из него:
Kafka Connect ориентирован на потоковую передачу данных из сервиса Kafka и в него, что упрощает написание высококачественных, надежных и высокопроизводительных плагинов. Это также позволяет фреймворку давать гарантии, которые трудно достичь с помощью других структур. Kafka Connect является неотъемлемым компонентом конвейера ETL в сочетании с сервисом Kafka и потоковой обработкой.
Kafka Connect может работать либо как автономный процесс для выполнения заданий на одной машине (например, сбор журналов), либо как распределенный, масштабируемый, отказоустойчивый сервис, поддерживающий всю структуру. Это позволяет сократить масштаб до разработки, тестирования и небольших продуктовых развертываний с низким барьером для входа и низкими эксплуатационными накладными расходами, а также увеличить масштаб поддержки конвейера данных большой организации.
Основные преимущества использования Kafka Connect:
Connectors & Tasks¶
Копирование данных между сервисом Kafka и сторонней системой осуществляется посредством создаваемых пользователями инстансов Kafka Connectors. Коннекторы бывают двух видов: SourceConnectors – импортируют данные из другой системы, и SinkConnectors – экспортируют данные в другую систему. Например, JDBCSourceConnector импортирует реляционную базу данных в Kafka, а HDFSSinkConnector экспортирует содержимое топика Kafka в файлы HDFS.
Реализации класса Connector не выполняют копирование данных самостоятельно: их конфигурация описывает набор данных для копирования, и Connector отвечает за разбиение этого задания на набор задач – Tasks, которые могут быть распределены между объектами Kafka Connect. Tasks также бывают двух видов: SourceTask и SinkTask. При необходимости реализация класса Connector может отслеживать изменения данных внешних систем и запрашивать реконфигурацию задачи.
С назначением данных, которые должны быть скопированы, каждая задача Task должна скопировать свое подмножество данных в сервис Kafka или из него. Данные, которые копирует коннектор, должны быть представлены как партиционированный поток, аналогично модели топика Kafka, где каждая партиция представляет собой упорядоченную последовательность записей со смещениями. Каждой задаче назначается подмножество партиций для обработки. Порой это сопоставление очевидно: каждый файл в наборе файлов журнала можно считать партицией, каждую строку в файле – записью, а смещения – просто позициии в файле. В иных случаях сопоставление с моделью требует больше усилий: коннектор JDBC может сопоставить каждую таблицу с партицией, но смещение менее ясно. Один из возможных вариантов сопоставления это использовать в качестве смещения последнюю запрашиваемую отметку времени при генерации запросов.

Рис. 149. Пример реализации Source Connector
Partitions & Records¶
Каждая партиция представляет собой упорядоченную последовательность записей ключ-значение, где и ключи, и значения могут иметь сложные структуры. Поддерживаются многие примитивные типы, а также массивы, структуры и вложенные структуры данных. Для большинства типов можно напрямую использовать стандартные типы Java, такие как java.lang.Integer, java.lang.Map и java.lang.Collection. Для структурированных записей следует использовать класс Struct.
На Рис.150. представлен партиционированный поток: модель данных, в которой коннекторы сопоставляют все системы source и sink. Каждая запись содержит ключи и значения (со схемами), идентификатор партиции и смещения в ней.

Рис. 150. Пример партиционированного потока
Для отслеживания структуры и совместимости записей в партициях схемы (Schemas) могут быть включены в каждую запись. Поскольку схемы обычно генерируются “на лету” на основе источника данных, класс SchemaBuilder включен, что делает их построение очень простым.
| Schemas: | Определение абстрактного типа данных. Типы данных могут быть примитивными типами (целочисленные типы, типы с плавающей запятой, логические, строки и байты) или сложными типами (типизированные массивы, карты с одной схемой ключей и схемами значений, а также структурами, которые имеют фиксированный набор имен полей, каждый из которых имеет схема связанных значений). Любой тип может быть указан как необязательный, что позволяет его опускать (в результате чего значения отсутствуют) и может указывать значение по умолчанию. |
|---|
Такой формат данных среды выполнения не предполагает какого-либо конкретного формата сериализации; это преобразование осуществляется с помощью Converter, которые обрабатывают формат времени выполнения org.apache.kafka.connect.data и сериализованные данные byte[].
| Converter: | Интерфейс конвертера обеспечивает поддержку перевода между форматом данных выполнения Kafka Connect и byte[]. Внутренне это включает промежуточный шаг к формату, используемому слоем сериализации (например, JsonNode, GenericRecord, Message). |
|---|
В дополнение к ключу и значению записи имеют идентификаторы партиций и смещения, которые используются фреймворком для периодической фиксации смещений обработанных данных. В случае сбоя обработка может возобновиться с последнего зафиксированного смещения, что позволяет избежать повторной обработки и дублирования событий.
Интеграция поддержки Apache Kafka Connect в Центрах событий Azure
Apache Kafka Connect — это платформа для подключения, импорта и экспорта данных в любую внешнюю систему или из нее, например MySQL, HDFS и файловую систему, через кластер Kafka. В этом руководстве описано использование платформы Kafka Connect с Центрами событий.
На использование платформы Apache Kafka Connect и ее соединителей не распространяется поддержка продуктов Microsoft Azure.
Предполагается, что динамическая конфигурация Apache Kafka Connect должна храниться в сжатых разделах с неограниченным сроком хранения. Центры событий Azure не реализуют сжатие на уровне брокера и всегда устанавливают ограничение на время хранения событий исходя из того, что являются механизмом потоковой передачи событий в реальном времени, а не долговременным хранилищем данных или конфигураций.
В то время как проект Apache Kafka позволяет сочетать эти роли, Azure считает, что такими данными лучше всего управлять в соответствующей базе данных или хранилище конфигураций.
Многие сценарии с участием Apache Kafka Connect будут работать должным образом, однако концептуальные различия между моделями хранения Apache Kafka и Центров событий Azure могут вести к ненадлежащей работе некоторых конфигураций.
В этом руководстве описана интеграция Kafka Connect с Центрами событий и развертывание соединителей FileStreamSource и FileStreamSink. Эта функция в настоящее время находится на стадии предварительной версии. Хотя эти соединители не предназначены для использования в рабочей среде, они показывают комплексный сценарий Kafka Connect, в котором Центры событий Azure действуют в качестве брокера Kafka.
Этот пример можно найти на сайте GitHub.
При работе с этим руководством вы выполните следующие задачи:
Предварительные требования
Для работы с этим пошаговым руководством выполните следующие предварительные требования:
Создание пространства имен Центров событий
Для отправки и получения данных из любой службы Центров событий требуется пространство имен Центров событий. См. раздел Создание концентратора событий для получения инструкций по созданию пространства имен и концентратора событий. Получите строку подключения Центров событий и полное доменное имя (FQDN) для последующего использования. Инструкции см. в статье Get an Event Hubs connection string (Получение строки подключения для Центров событий).
Клонирование примера проекта
Клонируйте репозиторий Центров событий Azure и перейдите к руководствам или вложенной папке подключения:
Настройка Kafka Connect для Центров событий
Минимальная перенастройка необходима при перенаправлении пропускной способности Kafka в Центры событий. Следующий пример connect-distributed.properties показывает, как настроить Connect для проверки подлинности и обмена данных с конечной точкой Kafka в Центрах событий:
Замените
Выполнение Kafka Connect
На этом этапе рабочая роль Kafka Connect запускается локально в распределенном режиме с помощью Центров событий для поддержания состояния кластера.
Kafka Connect использует API Kafka AdminClient для автоматического создания разделов с рекомендуемыми конфигурациями, включая сжатие. Быстрая проверка пространства имен на портале Azure показывает, что внутренние разделы рабочей роли Connect были созданы автоматически.
Внутренние разделы Kafka Connect должны использовать сжатия. Команда Центров событий не несет ответственности за исправление неправильных конфигураций в случае ненадлежащей настройки внутренних разделов Connect.
Создание соединителей
В этом разделе показано использование соединителей FileStreamSource и FileStreamSink.
Создайте каталог для файлов входных и выходных данных.
Создайте два файла. Один файл с начальными данными, которые читает соединитель FileStreamSource, и другой, в который соединитель FileStreamSink выполняет запись.
Создайте соединитель FileStreamSource. Обязательно замените фигурные скобки своим домашним каталогом.
Вы должны увидеть connect-quickstart Центра событий в экземпляре Центров событий после выполнения предыдущей команды.
Проверьте состояние соединителя источника.
Создайте соединитель FileStreamSink. Еще раз убедитесь, что вы заменили фигурные скобки своим путем к домашнему каталогу.
Проверьте состояние соединителя приемника.
Убедитесь, что данные реплицированы между файлами и что данные будут одинаковыми для обоих файлов.
Очистка
Дальнейшие действия
Дополнительные сведения о концентраторах событий для Kafka см. в следующих статьях:
Как синхронизировать сотни таблиц базы в Kafka, не написав ни одного продюсера

Привет, Хабр! Меня зовут Сергей Бевзенко, я ведущий разработчик Delivery Club в команде Discovery. Наша команда занимается навигацией пользователя по приложению Delivery Club: мы отвечаем за основную выдачу ресторанов, поиск и всё, что с этим связано.
Я расскажу про Kafka Connect: что это такое, какова общая концепция и как работать с этим фреймворком. Это будет полезно тем, кто использует Kafka, но не знаком с Kafka Connect. Если у вас огромный монолит и вы хотите перейти на событийную модель, но сталкиваетесь со сложностью написания продюсеров, то вы тоже найдёте здесь ответы на свои вопросы. В комментариях можем сравнить ваш опыт использования Kafka Connect с нашим и обсудить любые вопросы, которые с этим связаны.
Предпосылки
Delivery Club — не молодая компания. Она основана в сентябре 2009 года. Мы постоянно развиваемся и улучшаем наши сервисы, без этого рост невозможен.
У нас есть 10-летний Legacy-монолит. Он служит основой многих процессов. Да, новые сервисы мы, конечно же, пишем. Делаем это на Go, и иногда на PHP. Это два основных языка backend-разработки в Delivery Club. Также мы переходим на событийную модель с использованием шины событий: все изменения данных в системе — это события, попадающие в шину, и любой сервис может подписаться на них.
Какие это события?
В компании есть множество интеграции с различными ресторанами, магазинами, аптеками и т.д. Также у нас есть служба логистики, которая работает с курьерами, их маршрутами, заказами, распределением. Есть и отличный отдел R&D, который занимается различными исследованиями и околонаучной разработкой. И, конечно, есть другие отделы. У каждого направления множество сервисов, и все они генерируют огромное количество событий. В качестве шины для них мы используем Apache Kafka. Но десятилетний Legacy никуда не делся. Внутри него множество админок, которые являются источниками данных. Без крайней нужды трогать их не рекомендуется.
Сервис «Каталог»
Как один из этапов развития, перед нашей командой стояла задача — переписать основную выдачу приложения. За неё отвечал монолит, как и за бо̒льшую часть функциональности. И наступил момент, когда вносить какие-либо изменения в эту функциональность стало невероятно долго.
В нашем случае всё началось с небольшой задачи: отображать в основной выдаче дополнительные ярлыки у ресторанов, в которых есть какие-то акции. Решений было несколько, но большинство из них сильно повышало нагрузку на базу и увеличивало время ответа. Но, надо признаться, выдача и так была не особо быстрой.
Единственным оптимальным решением было написать на Go новый сервис, который помог бы решить все проблемы, имевшиеся в монолите. К тому же мы смогли сильно (в три раза) сократить время ответа.
Но наш монолит является мастером данных для основной выдачи, и новый сервис должен иметь к ним доступ.
Как писать продюсеры в условиях 10-летнего Legacy
В самой первой версии Catalog MVP мы ходили в реплику монолита, чтобы быстро запуститься (для нас важен Time to market). Но оставлять так мы не хотели, поэтому нужно было денормализовать данные из монолита. А для этого необходимо начать продьюсить данные.
Есть несколько подходов:
Kafka Connect
Как он используется
Чаще всего Kafka используют так:
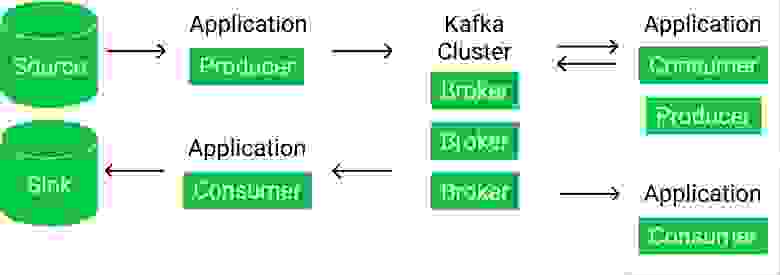
То есть нам приходится писать собственные консьюмеры и продюсеры и решать однообразные задачи при их разработке:
Source => Kafka (connect)
Kafka => Kafka (streams)
Kafka => Storage (connect)

Когда говорят, что Kafka Connect поставляется вместе с Kafka, это не какая-то скрытая функциональность Kafka-брокеров. Это именно отдельное приложение, которое имеет настройки подключения к Kafka и источнику/приёмнику. Работу с Kafka Connect мы рассмотрим ниже.
Но сначала нужно ввести три важных термина:
Преимущество distributed mode
Предположим, мы запустили четыре worker’а Kafka Connect и создали три connector’а с разным количеством task’ов.
Как я говорил выше, фреймворк используется для передачи данных из источника в Kafka либо из Kafka в приёмник. В соответствии с этим коннекторы делятся на два вида:
Коннекторов уже очень много написано. Например, на сайте confluent их сейчас 163, а на просторах интернета — ещё больше.
Вы можете написать свой коннектор на Java и Scala. Для этого нужно создать подключаемый jar-файл, реализовав простой интерфейс коннектора.
Как запустить Kafka Connect
Локально
Поставляется вместе с Kafka
Идём на сайт Kafka и скачиваем нужную нам версию: http://kafka.apache.org/downloads.
Рекомендую зайти в директорию kafka_2.12-2.6.0/config — там вы увидите настройки по умолчанию запуска и Kafka-брокера, и Kafka Connect.
Kafka Connect можно запускать в режиме standalone. Это удобно для локальной разработки и тестирования, но в боевых условиях рекомендуется использовать connect-distributed (причины были описаны выше).
Режим standalone чаще всего используется для локальной разработке и тестирования.
Чтобы запустить Kafka Connect, выполните команду:
Во многих Docker-образах используется этот же подход, поэтому вам достаточно переопределить CMD в Dockerfile, чтобы получить образ с Kafka Connect.
Конечно, есть и готовые образы. Я рекомендую использовать варианты от компании Confluent:
Запуск коннекторов
После того, как вы запустите Kafka Connect, вы можете запускать на нём свои коннекторы.
Для управления Kafka Connect используется REST API. Полную документацию по нему можно посмотреть на сайте. Я опишу лишь те методы, которые нам понадобятся для демонстрации работы Kafka Connect.
Запросим список классов коннекторов, которые добавлены в ваш Kafka Connect:
В ответ мы получим нечто подобное:
Запросим список запущенных коннекторов:
Получение информации о запущенном коннекторе
Конфигурация запущенного коннектора (config):
Состояние запущенного коннектора (status):
Создание коннектора
То есть необходимо методом POST отправить конфигурацию коннектора.
Обратите внимание, что имя коннектора должно быть уникальным в вашем кластере Kafka Connect. Но вы можете создавать несколько коннекторов одного класса с разными настройками.
Также у любого коннектора есть три обязательных параметра:
Настройка коннекторов
Причины выбора коннекторов
Как я рассказывал, мы выносили функциональность из нашего монолита. Сделали новый сервис «Каталог», который отвечает за основную выдачу ресторанов.
Но для этой функциональности были необходимы данные, мастером которых был монолит. Эти данные ещё не отправлялись в шину событий.
Для MVP Каталога решили использовать Shared Database. То есть наш новый сервис обращался в базу монолита.
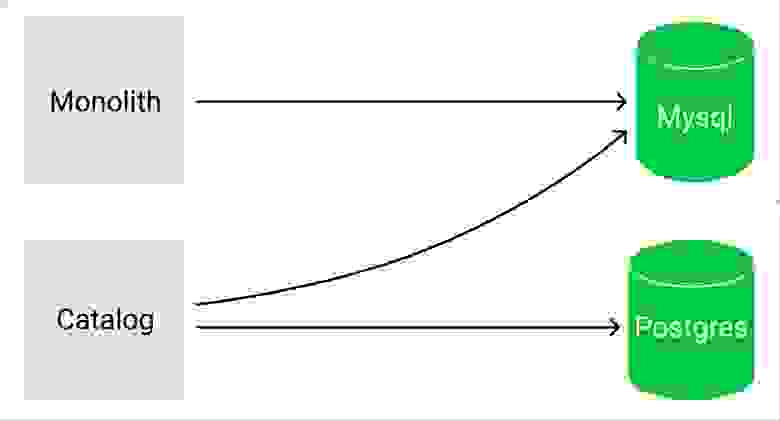
Таким образом мы сняли нагрузку с монолита, но нагрузка на старую базу осталась. После создания MVP нужно закрыть технический долг и отказаться от этого антипаттерна.

Две главные задачи, которые мы решали:
Jdbc и Debezium
Нам отлично подходит JdbcSinkConnector в качестве sink-коннектора. Он подписывается на топик Kafka и выполняет запросы на добавление, изменение и удаление данных в базе.
Но в качестве Source-коннектора он нам не подходит, так как делает SQL-запросы в базу по таймеру, а это создает ещё бо̒льшую нагрузку на базу-источник. Мы как раз хотим от этого уйти.

Помимо этого, у Debezium-коннектора есть ещё одно преимущество перед Jdbc. Так как Debezium отслеживает бинлог, он может определять моменты удаления записей в базе данных. У Jdbc нет такой возможности, так как он берёт текущее состояние базы и ничего не знает о предыдущем состоянии.
Debezium Connector

Все настройки коннектора можно посмотреть на сайте.
Давайте рассмотрим настройки коннектора и обсудим выбор некоторых параметров.
Подключения к базе данных:
Следует иметь в виду, что этот пользователь должен иметь права:
ID реплики, под которым будет зарегистрирован коннектор, и его имя сервера:
Список таблиц для синхронизации:
Имена базы и таблицы необходимо указывать через запятую.
Настройки создания snapshot’а:
Для чего нужен snapshot
Когда ваш коннектор Debezium MySQL запускается в первый раз, он выполняет начальный согласованный снимок вашей базы данных и сохраняет его в топик Kafka. Даже если вы будете отслеживать только несколько таблиц из базы, в database.history будет записана вся схема. Но можно не переживать из-за размера этого топика, он будет очень маленьким (менее 1 Мб).
Пропуск определений в снимке, которые по каким-то причинам не удалось распарсить:
Эту опцию мы включили, потому что сталкивались с такими ошибками, когда определения в бинлоге использовали неверный синтаксис. Сервер MySQL более-менее интерпретирует эти инструкции и потому не падает. Но анализатор SQL-запросов в DebeziumConnector ‘е с ними не справляется и падает с ошибкой. Чтобы не падать, а игнорировать нечитаемые запросы, необходимо включить эту опцию.
Точность типа данных time:
Эта настройка уменьшает точность типа данных time с микросекунд до миллисекунд.
Описанную конфигурацию уже можно использовать для production-окружения. А в документации есть полный перечень настроек с подробным описанием.
В целом, все трансформации рекомендуется использовать на стороне Sink-коннектора, а Source-коннекторы должны отправлять данные в топик Kafka без изменений.
Создание Debezium MySqlConnector :
При создании коннектора вы можете получить ошибку:
Connector configuration is invalid and contains the following 1 error(s):
Configuration is not defined: database.history.connector.id
Configuration is not defined: database.history.connector.class
Unable to connect: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
You can also find the above list of errors at the endpoint `/connector-plugins/
Эта ошибка говорит о том, что у вас указаны некорректные параметры подключения к MySQL. Проверьте ваши логин/пароль, а также убедитесь, что у пользователя есть права на репликацию (см. выше).
После создания коннектора можно проверить его состояние. Этот метод также используется в качестве метрики.
Мы увидим такой ответ:
После того, как мы запустили source connector, можно убедиться, что топики были созданы и можно прочитать из них данные. Для работы с Kafka будем использовать удобную утилиту kafkacat.
Какие топики были созданы нашим коннектором:
Чтение данных из топика monolyth_db.debezium.history :
Чтение данных из топика monolyth_db.table_name1 ($
В топиках вы увидите сообщения в формате avro (если вы использовали JsonSerializer для key, value серилизаторов). Вид и описание формата лучше прочитать в документации.
JdbcSinkConnector
В качестве Sink коннектора будем использовать JdbcSinkConnector.

Рассмотрим его конфигурацию
Создадим файл my-jdbc-sink-connector.json :
Тут, конечно, три обязательных для любого коннектора параметра:
Потом перечисление топиков, на которые будем подписываться:
JdbcConnector использует один топик для одной таблицы. Сопоставление топика и таблицы происходит по имени. Для коррекции используется route-трансформер. О трансформерах поговорим чуть ниже.
Ключ может быть составной. Например, для кросс-таблиц:
Следующие параметры очень красноречивые. Мы отключаем автоматическое создание и удаление таблиц, и разрешаем удалять данные:
Трансформеры
Последний блок настроек касается трансформеров.
Этот параметр указывает, какие трансформеры и в каком порядке выполнять. Они расположены в этой же конфигурации коннектора. Каждый трансформер имеет type (класс) и параметры.
Например, трансформер route отвечает за сопоставление имени топика и имени таблицы:
Он используется в Debezium MySqlConnector: отправляет данные в Kafka топики с именами
Второй важный трансформер unwrap:
Он преобразует формат Debezium в формат, с которым прекрасно работает JdbcSinkConnector.
Deploy
В каждой компании деплой происходит по-разному: где-то используют Jenkins, где-то — Gitlab CI или Bitbucket Pipelines, а кто-то пишет скрипты.
С Kafka Connect вы будете деплоить точно так же, как и в случае с другими сервисами в вашей компании.
Как я отмечал, Kafka Connect — это отдельное stateless-приложение. Оно не зависит от Kafka-брокера и даже от версии Kafka. Если у вас уже есть Kafka старой версии, можно использовать новую версию Kafka Connect. Я рекомендую это и сделать. Например, мы использовали последнюю на тот момент версию Kafka Connect 2.5.0 с Kafka-брокером 0.10.х.
Поэтому нет каких-то общих советов и нюансов, как деплоить сервисы. Расскажу, как это происходит у нас.
Deploy Kafka Connect в Delivery Club
Перед запуском в стейдж мы экспериментировали локально. Создавали свой Docker-образ на основе cp-kafka-connect, куда просто добавляли свои коннекторы.
Для стейджа было достаточно из этого образа собрать контейнер и выложить в Kubernetes, что мы и сделали.
Отмечу только, что 2 Гб памяти поду под Kafka Connect не хватает, и у нас поды по 4 Гб.
На проде у нас внедрение совпало с внедрением нового кластера Kafka-брокеров. Мы приняли специфическое решение поднимать Kafka Connect на тех же серверах, где будут находиться Kafka-брокеры. Для этого использовали rpm-пакет от Confluent.
Сами настройки конфигов мы храним в репозитории. У нас есть несколько скриптов, которые позволяют управлять коннекторами: создавать, останавливать, перезапускать их.
Но это уже отдельная история — как работать с Kafka Connect в проде, которая зависит от инфраструктуры компании.
Что нам дало использование Kafka Connect
Мы не стали писать множество продьюсеров в монолите для более чем 600 таблиц. По приблизительным подсчётам, это сэкономило нам более месяца работы пары разработчиков. И, конечно же, снизило возможность наделать множество ошибок в монолите. То есть мы избавились от потенциальных падений приложения.
Это позволило написать новый сервис выдачи ресторанов силами одной команды за один месяц.
Другие команды в компании тоже пользуются нашими топиками. Оценить выгоду очень сложно, но точно ясно: это позволило нам разрабатывать новую функциональность, не завязываясь на данные, источником которых является только монолит.
Мы сняли нагрузку с самой нагруженной нашей части — база данных монолита. Это примерно 150 RPS запросов к базе. И синхронизируем более 40 таблиц со скоростью 300 RPS.
Также мы разделил ответственность сервисов, что является первым шагов к разделению доменной области.
Резюме
Я очень рад, что вам удалось добраться до конца. В этой статье вы:



