Blue Ocean for Jenkins Pipelines
Continuous delivery pipelines should be easy
That’s why we’ve built Blue Ocean; the continuous delivery tool for teams just like yours.
It’s a way to use Jenkins that even your boss’s boss can understand. 🉠🙌
Continuous Delivery for every team
Blue Ocean puts Continuous Delivery in reach of any team without sacrificing the power and sophistication of Jenkins.
Visual Pipeline Editor
Create your first Continuous Delivery pipeline from start to finish.
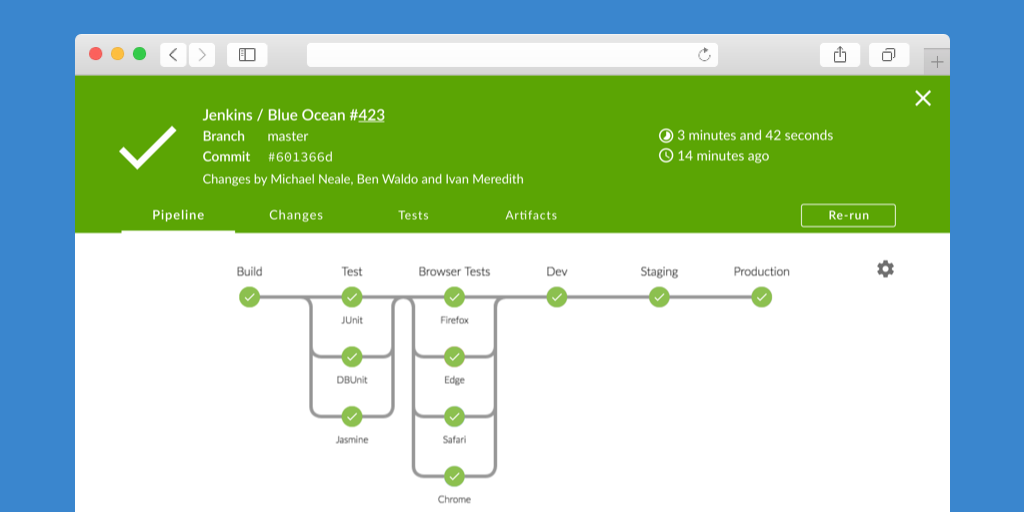
Pipeline visualization
Visually represent pipelines so that even your boss’s boss can understand.
Diagnosis
Diagnose problems instantly and say
good-riddance to endlessly scanning through logs.
GitHub & Git
Run the pipeline for every feature branch and pull request.
Personalization
Customize your dashboard so that you only see pipelines that matter to you.
100% Open Source
Blue Ocean is 100% free and open source software. Yup, you heard right — free!
I’ve just been testing @jenkinsci with the new UI/UX. Awesome! Very good job! Creating pipelines is now dead simple. pic.twitter.com/dSFlauhpxd
@i386 blue ocean is life рџ‘ЊрџЏ» you have made work fun again
Continuous Delivery shouldn’t be hard
Blue Ocean focuses on the needs of regular developers just like you.
We do all the hard work making things simple so you can get back to building your next big thing.
Introducing Blue Ocean: a new user experience for Jenkins
In recent years developers have become rapidly attracted to tools that are not only functional but are designed to fit into their workflow seamlessly and are a joy to use. This shift represents a higher standard of design and user experience that Jenkins needs to rise to meet.
We are excited to share and invite the community to join us on a project we’ve been thinking about over the last few months called Blue Ocean.
Blue Ocean is a project that rethinks the user experience of Jenkins, modelling and presenting the process of software delivery by surfacing information that’s important to development teams with as few clicks as possible, while still staying true to the extensibility that is core to Jenkins.
While this project is in the alpha stage of development, the intent is that Jenkins users can install Blue Ocean side-by-side with the Jenkins Classic UI via a plugin.
Not all the features listed on this blog are complete but we will be hard at work over the next few months preparing Blue Ocean for general use. We intend to provide regular updates on this blog as progress is made.
Blue Ocean is open source today and we invite you to give us feedback and to contribute to the project.
Blue Ocean will provide development teams:
New modern user experience
The UI aims to improve clarity, reduce clutter and navigational depth to make the user experience very concise. A modern visual design gives developers much needed relief throughout their daily usage and screens respond instantly to changes on the server making manual page refreshes a thing of the past.
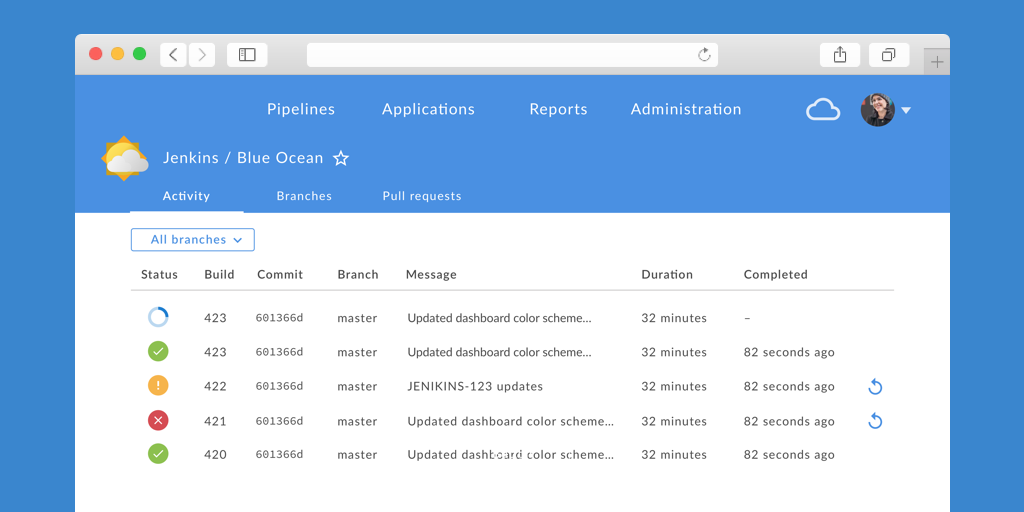
Advanced Pipeline visualisations with built-in failure diagnosis
Pipelines are visualised on screen along with the steps and logs to allow simplified comprehension of the continuous delivery pipeline – from the simple to the most sophisticated scenarios.
Scrolling through 10,000 line log files is a thing of the past. Blue Ocean breaks down your log per step and calls out where your build failed.
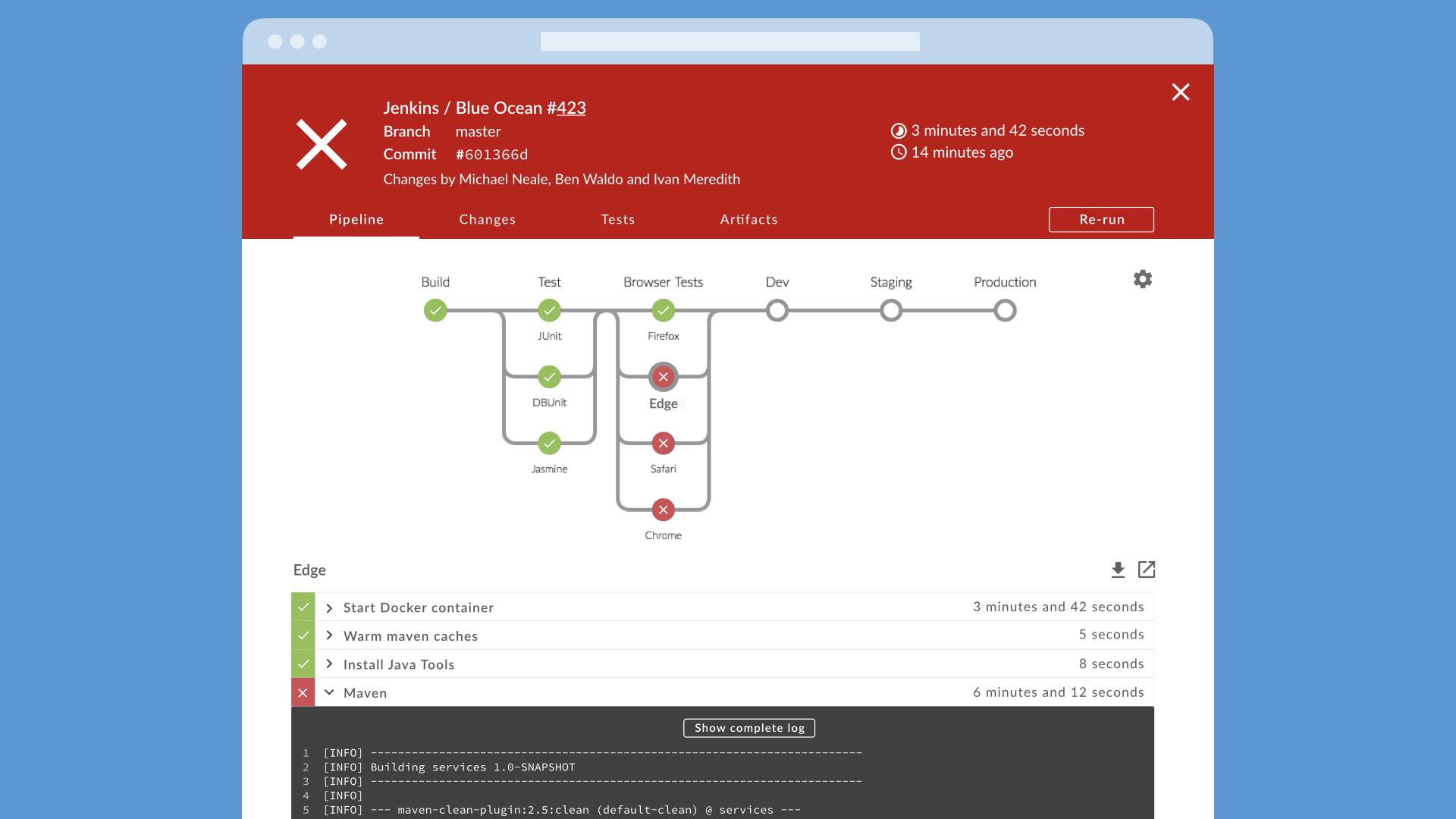
Branch and Pull Request awareness
Modern pipelines make use of multiple Git branches, and Blue Ocean is designed with this in mind. Drop a Jenkinsfile into your Git repository that defines your pipeline and Jenkins will automatically discover and start automating any В Branches and validating Pull Requests.
Jenkins will report the status of your pipeline right inside Github or Bitbucket on all your commits, branches or pull requests.
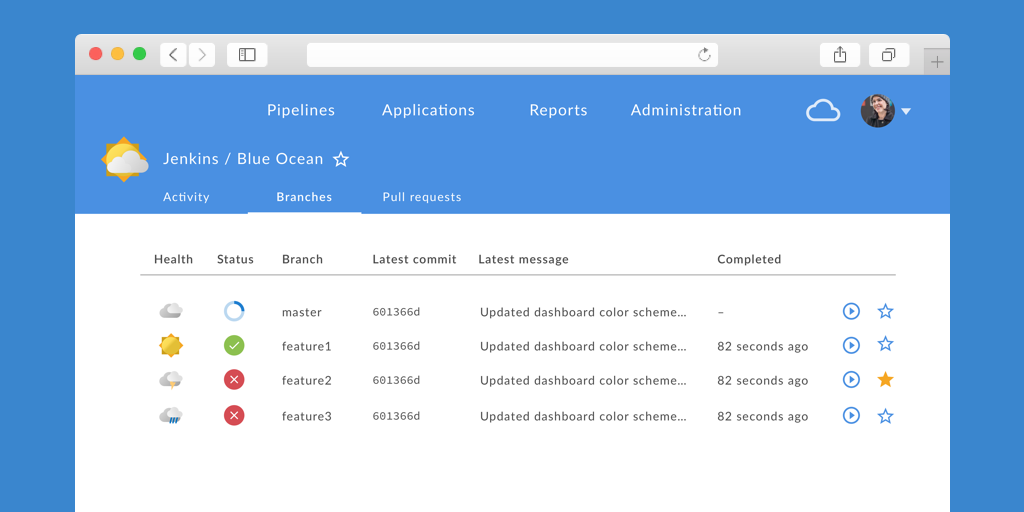
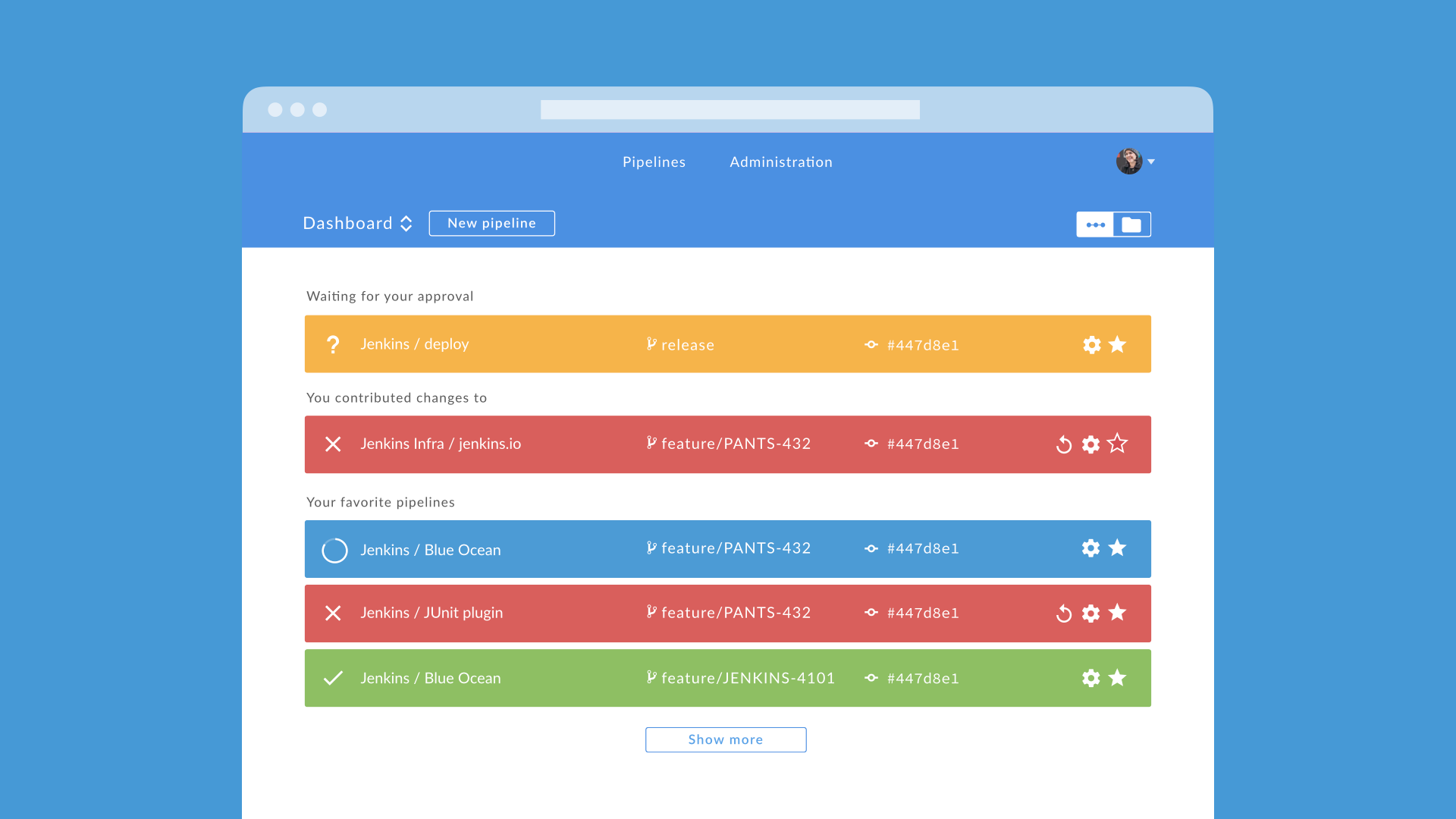
Personalised View
Favourite any pipelines, branches or pull requests and see them appear on your personalised dashboard. Intelligence is being built into the dashboard. Jobs that need your attention, say a Pipeline waiting for approval or a failing job that you have recently changed, appear on the top of the dashboard.
You can read more about Blue Ocean and its goals on the project page and developers should watch the Developers list for more information.
For Jenkins developers and plugin authors:
Jenkins Design “Language”
The Jenkins Design Language (JDL) is a set of standardised React components and a style guide that help developers create plugins that retain the look and feel of Blue Ocean in an effortless way. We will be publishing more on the JDL, including the style guide and developer documentation, over the next few weeks.
Modern JavaScript toolchain
The Jenkins plugin tool chain has been extended so that developers can use ES6, React, NPM in their plugins without endless yak-shaving. Jenkins js-modules are already in use in Jenkins today, and this builds on this, using the same tooling.
Client side Extension points
Client Side plugins use Jenkins plugin infrastructure. The Blue Ocean libraries built on ES6 and React.js provide an extensible client side component model that looks familiar to developers who have built Jenkins plugins before. Client side extension points can help isolate failure, so one bad plugin doesn’t take a whole page down.
Server Sent Events
Server Sent Events (SSE) allow plugin developers to tap into changes of state on the server and make their UI update in real time (watch this for a demo).
To make Blue Ocean a success, we’re asking for help and support from Jenkins developers and plugin authors. Please join in our Blue Ocean discussions on the Jenkins Developer mailing list and the #jenkins-ux IRC channel on Freenode!
Blue Ocean
This chapter covers all aspects of Blue Ocean’s functionality, including how to:
use the Pipeline Editor to modify Pipelines as code, which are committed to source control.
This chapter is intended for Jenkins users of all skill levels, but beginners may need to refer to some sections of the Pipeline chapter to understand some topics covered in this Blue Ocean chapter.
For an overview of content in the Jenkins User Handbook, see User Handbook overview.
What is Blue Ocean?
Blue Ocean rethinks the user experience of Jenkins. Designed from the ground up for Jenkins Pipeline, but still compatible with freestyle jobs, Blue Ocean reduces clutter and increases clarity for every member of the team. Blue Ocean’s main features include:
Sophisticated visualizations of continuous delivery (CD) Pipelines, allowing for fast and intuitive comprehension of your Pipeline’s status.
Personalization to suit the role-based needs of each member of the team.
Pinpoint precision when intervention is needed and/or issues arise. Blue Ocean shows where in the pipeline attention is needed, facilitating exception handling and increasing productivity.
Native integration for branch and pull requests, enables maximum developer productivity when collaborating on code with others in GitHub and Bitbucket.
Frequently asked questions
Why does Blue Ocean exist?
Developer tools companies like Heroku, Atlassian, and Github have raised the bar for what is considered good developer experience, and developers are increasingly expecting exceptional design. In recent years, developers have become more rapidly attracted to tools that are not only functional but are designed to fit into their workflow seamlessly and are a joy to use. This shift represents a higher standard of design and user experience. Jenkins needs to rise to meet this higher standard.
Creating and visualising CD pipelines is something valuable for many Jenkins users and this is demonstrated in the 5+ plugins that the Jenkins community has created to meet their needs. This indicates a need to revisit how Jenkins currently expresses these concepts and consider delivery pipelines as a central theme to the Jenkins user experience.
It is not just CD concepts but the tools that developers use every day – Github, Bitbucket, Slack, HipChat, Puppet, or Docker. It is about more than Jenkins – it is the developer workflow surrounding Jenkins that spans multiple tools.
New teams have little time to learn how to assemble their own Jenkins experience – they want to improve their time to market by shipping better software faster. Assembling that ideal Jenkins experience is something we can work together as a community of Jenkins users and contributors to define. As time progresses, developers’ expectations of good user experience changes and the mission of Blue Ocean enables the Jenkins project to respond.
The Jenkins community has poured its sweat and tears into building the most technically capable and extensible software automation tool in existence. Not doing anything to revolutionize the Jenkins developer experience today is just inviting someone else – in closed source – to do it.
Where is the name from?
The name Blue Ocean comes from the book Blue Ocean Strategy where instead of looking at strategic problems within a contested space, you look at problems in the larger uncontested space. To put this more simply, consider this quote from ice hockey legend Wayne Gretzky: «skate to where the puck is going to be, not where it has been».
Does Blue Ocean support freestyle jobs?
Blue Ocean aims to deliver a great experience around Pipeline and be compatible with any freestyle jobs you already have configured on your Jenkins instance. However, you will not benefit from any of the features built for Pipelines – for example, Pipeline visualization.
As Blue Ocean is designed to be extensible, it is possible for the Jenkins community to extend Blue Ocean to support other job types in the future.
What does this mean for the Jenkins classic UI?
The intention is that as Blue Ocean matures, there will be fewer reasons for users to go back to the existing «classic UI». Read more about the classic UI in Getting started with Pipeline.
For example, early versions of Blue Ocean are mainly targeted at Pipeline jobs. You might be able to see your existing non-pipeline jobs in Blue Ocean but it might not be possible to configure them from the Blue Ocean UI for some time. This means users will have to jump back to the classic UI to configure items/projects/jobs other than Pipeline ones.
There are likely going to be more examples of this, which is why the classic UI will remain important in the long term.
What does this mean for my plugins?
Extensions are delivered by plugins as usual. However, plugin developers will need to include some additional JavaScript to hook into Blue Ocean’s extension points and contribute to the Blue Ocean user experience.
Учимся разворачивать микросервисы. Часть 4. Jenkins

Это четвертая и заключительная часть серии статей «Учимся разворачивать микросервисы», и сегодня мы настроим Jenkins и создадим пайплайн для микросервисов нашего учебного проекта. Jenkins будет получать файл конфигурации из отдельного репозитория, собирать и тестировать проект в Docker-контейнере, а затем собирать Docker-образ приложения и пушить его в реестр. Последней операцией Jenkins будет обновлять кластер, взаимодействуя с Helm (более подробно о нем в прошлой части).
Ключевые слова: Java 11, Spring Boot, Docker, image optimization
Ключевые слова: Kubernetes, GKE, resource management, autoscaling, secrets
Ключевые слова: Helm 3, chart deployment
Настройка Jenkins и пайплайна для автоматической доставки кода в кластер
Ключевые слова: Jenkins configuration, plugins, separate configs repository
Jenkins — это сервер непрерывной интеграции, написанный на Java. Он является чрезвычайно расширяемой системой из-за внушительной экосистемы разнообразных плагинов. Настройка пайплайна осуществляется в декларативном или императивном стиле на языке Groovy, а сам файл конфигурации (Jenkinsfile) располагается в системе контроля версий вместе с исходным кодом. Это удобно для небольших проектов, однако, часто более практично хранить конфигурации всех сервисов в отдельном репозитории.
Код проекта доступен на GitHub по ссылке.
Установка и настройка Jenkins
Установка
Существует несколько способов установить Jenkins:
War-архив с программой можно запустить из командной строки или же в контейнере сервлетов (№ Apache Tomcat). Этот вариант мы не будем рассматривать, так как он не обеспечивает достаточной изолированности системы.
Устранить этот недостаток можно, установив Jenkins в Docker. Из коробки Jenkins поддерживает использование докера в пайплайнах, что позволяет дополнительно изолировать билды друг от друга. Запуск докера в докере — плохая идея (здесь можно почитать почему), поэтому необходимо установить дополнительный контейнер ‘docker:dind’, который будет запускать новые контейнеры параллельно контейнеру Jenkins’а.
Также возможно развернуть Jenkins в кластере Kubernetes. В этом случае и Jenkins, и дочерние контейнеры будет работать как отдельные поды. Любой билд будет полностью выполняться в собственном контейнере, что максимально изолирует выполнения друг от друга. Из недостатков этот способ имеет довольно специфичную конфигурацию. Из приятных бонусов Jenkins в Google Kubernetes Engine может быть развернут одним кликом.
Хоть третий способ и кажется наиболее продвинутым, мы выберем прямолинейный путь и развернем Jenkins в Docker напрямую. Это упростит настройку, а также избавит нас от нюансов работы со stateful приложениями в Kubernetes. Хорошая статья для любопытствующих про Jenkins в Kubernetes.
Так как проект учебный, то мы установим Jenkins на локальной машине. В реальной обстановке можно посмотреть в сторону, например, Google Compute Engine. В дополнение замечу, что изначально я пробовал использовать Jenkins на Raspberry Pi, но из-за разной архитектуры «малинки» и машин кластера они не могут использовать одни и те же Docker-образы. Это делает невозможным применение Raspberry Pi для подобных вещей.
После установки Jenkins открываем http://localhost:8080/ и следуем инструкциям. Настроить Jenkins можно через UI, либо программно. Последний подход иногда называют «инфраструктура как код» (IaC). Он подразумевает описание конфигурации сервера с помощью хуков — скриптов на Groovy. Оставим этот способ настройки за рамками данной статьи. Для интересующихся ссылка.
Плагины
Для нашего проекта нам понадобится установить два плагина: Remote File Plugin и Kubernetes CLI. Remote File Plugin позволяет хранить Jenkinsfile в отдельном репозитории, а Kubernetes CLI предоставит доступ к kubectl внутри нашего пайплайна.
Установка Helm
Глобальные переменные среды
Так как у нас два сервиса, то мы создадим два пайплайна. Некоторые данные у них будут совпадать, поэтому логично вынести их в одно место. Это можно сделать, задав глобальные переменные среды, которые будут установлены перед выполнением любого билда на сервере Jenkins. Отмечу, что не стоит с помощью этого механизма передавать пароли — для этого существуют секреты.
Секреты
| Имя секрета | Тип | Описание |
|---|---|---|
| github-creds | username with password | Логин/пароль от git-репозиториев |
| dockerhub-creds | username with password | Логин/пароль от реестра Docker-образов |
| kubernetes-creds | secret text | Токен сервисного аккаунта нашего кластера |
В предыдущей части в файле NOTES.txt нашего чарта мы описали последовательность команд для получения токена сервисного аккаунта. Вывести эти команды для кластера можно, запросив статус Helm-инсталляции ( helm status msvc-project ).
Конфигурация пайплайна
Как уже было упомянуто ранее, пайплайны описываются на Groovy, и могут быть написаны в декларативном и императивном стилях. Мы будем придерживаться декларативного подхода.
В Jenkins процесс выполнения пайплайна (билд) поделен на ряд шагов (stage). Каждый шаг выполняется определенным агентом (agent).
Наши пайплайны будут состоять из следующих шагов:
Структура файла конфигурации
Файл конфигурации будет иметь следующую структуру:
Агенты в Jenkins подчиняются типичным правилам «наследования» — если в шаге не определен агент, то будет использован агент родительского шага. Тег pipeline может рассматриваться как корневой шаг для всех остальных. Корневой шаг мы используем для объявления переменных среды и опций, которые по тому же правилу наследования будут иметь силу для всех вложенных шагов. Поэтому для тега pipeline установлен агент ‘none’. Использование этого агента подразумевает, что вложенные шаги обязаны переопределить этот агент для выполнения каких-либо полезных действий.
Агент в шагах Push Images и Trigger Kubernetes равен ‘any’. Это значит, что шаг может быть выполнен на любом доступном агенте. В простейшем случае это означает выполнение в контейнере Jenkins’а. Также эти шаги будут выполнены только для коммитов в мастер-ветку ( when < branch 'master' >).
Далее мы более пристально посмотрим на каждый из шагов, а также на блоки options и environment.
Опции
Блок опций может быть использован для настройки выполнения пайплайна или же отдельного шага. Мы используем следующие опции:
skipStagesAfterUnstable заставит Jenkins сразу прервать билд, eсли тесты были провалены. Поведение по умолчанию предусматривает установку статуса билда в UNSTABLE и продолжение выполнения. Это позволяет в сложных случаях более гибко обрабатывать подобные ситуации.
skipDefaultCheckout отключает автоматический чекаут репозитория проекта. Дефолтно Jenkins делает force чекаут репозитория для каждого шага с собственным агентом (в нашем случае Prepare Checkout, Push images и Trigger Kubernetes). То есть по сути затирает все изменения. Это может быть полезно при использовании пайплайна с несколькими различными образами. Однако нам нажно получить исходники с репозитория только единожды — на шаге Build. Применив опцию skipDefaultCheckout, мы получаем возможность произвести чекаут вручную. Также стоит заметить, что Jenkins будет автоматически переносить артефакты между шагами. Так, например, скомпилированные исходники из шага Build будут полностью доступны в шаге Test.
Переменные среды
Переменные среды могут быть также объявлены как для всего пайплайна, так и для отдельного шага. Их можно использовать, чтобы вынести какие-то редкоизменяемый свойства. В этом блоке мы определим имя файла докера и имена создаваемых Docker-образов.
В предыдущих статьях при работе с кластером мы всегда использовали наиболее свежие latest образы, но напомню, что это не лучший вариант из-за проблем при откатах к предыдущим версиям. Поэтому мы предполагаем, что в начальный момент времени кластер создается из самых свежих образов, а потом уже будет обновляться на конкретную версию. Тег IMAGE_TAG будет зависеть только от номера билда, который можно получить из предустановленной глобальной переменной среды BUILD_NUMBER. Таким образом наши версии будут составлять монотонную последовательность при условии того, что пайплайн не будет пересоздаваться (это приведет к сбросу номера билда). При неуспешных билдах BUILD_NUMBER также будет инкрементирован, следовательно последовательность версий образов может содержать «пробелы». Основное преимущество такого подхода к версионированию — его простота и удобство восприятия человеком. В качестве альтернативы можно подумать об использовании метки времени, чексуммы коммита или даже внешних сервисов.
Компиляция, тестирование, сборка
Чисто технически фазы компиляции, тестирования и сборки возможно объединить в один шаг, но для лучшей наглядности мы опишем их как отдельные шаги. С помощью плагинов Maven можно с легкостью добавлять дополнительные фазы, такие как статический анализ кода или интеграционное тестирование.
В фазе тестирования командой junit ‘**/target/surefire-reports/TEST-*.xml’ мы указываем Jenkins’у на файл с результатами тестов. Это позволит их отобразить прямо в веб-интерфейсе.
На последнем шаге мы генерируем jar-архив с нашим приложением.
Создание и отправка Docker-образа в реестр
На следующем шаге мы должны собрать Docker-образы и запушить их в реестр. Мы будем делать это средствами Jenkins, но в качестве альтернативы можно реализовать это и с помощью Maven-плагина.
Для начала нам надо доработать докер-файлы наших сервисов, которые мы разработали в первой статье цикла. Эти докер-файлы собирали приложение из исходников прямо в процессе создания образа. Сейчас же у нас имеется протестированный архив, следовательно один из шагов создания образа уже выполнен средствами Jenkins. Мы назовем этот новый файл Dockerfile-packaged.
Докер-файл для микросервиса шлюза аналогичен.
В конце шага происходит удаление установленных локально образов.
Обновление кластера Kubernetes
Финальным шагом осталось сообщить Kubernetes, что в реестре появился новый образ, и необходимо запустить процедуру обновления подов одного из микросервисов.
Итоговый Jenkinsfile
Jenkinsfile для микросервиса шлюза полностью аналогичен.
Подключение пайплайна
В Jenkins существует несколько видов пайплайнов. В данном проекте мы используем Multibranch pipeline. Как и следует из названия, билд будет запускаться для любого коммита в произвольной ветке.
Branch sources. Выбираем GitHub, в графе ‘Credentials’ выбираем секрет с логином/паролем от аккаунта и указываем URL репозитория с исходным кодом микросервиса.
Build Configuration. В Mode выбираем ‘by Remote File Plugin’, основное поле — Repository URL, в котором надо указать адрес репозитория с Jenkinsfile, а также Script Path с путем к этому файлу.
Scan Repository Triggers. В этом разделе настроим период, с которым Jenkins будет проверять, появились ли какие-то изменения в отслеживаемом репозитории. Недостаток этого подхода в том, что Jenkins будет генерировать трафик, даже когда в репозитории ничего не менялось. Более грамотный подход — настроить веб-хуки. При этом хранилище исходного кода само будет инициировать запуск билда. Очевидно, что сделать это можно, только если Jenkins доступен по сети для хранилища исходных кодов (они должны быть либо в одной сети, либо Jenkins должен иметь публичный IP-адрес). Подключение веб-хуков оставим за рамками данной статьи.
Запуск
После того как наш пайплайн настроен, можно его запустить. Наиболее удобно это сделать из меню Blue Ocean (Open Blue Ocean). Первый запуск может занять продолжительное время, так как потребуется время на загрузку Maven-зависимостей. После выполнения билда можно подключиться к кластеру и убедиться в том, что тег образа микросервиса был изменен ( helm get values msvc-project ).
В дальнейшем Jenkins будет отслеживать изменения в репозитории микросервиса и запускать билд автоматически.
Заключение
Jenkins — очень гибкая система, позволяющая реализовывать процесс непрерывной интеграции и развертывания любой сложности. В этой статье мы только коснулись этого инструмента, создав простенький пайплайн для микросервисов нашего проекта. В будущем этот пайплайн можно значительно дорабатывать и улучшать, например, добавив уведомления, дополнительные шаги, веб-хуки и многое-многое другое.
Jenkins Pipeline. Что это и как использовать в тестировании
Меня зовут Александр Михайлов, я работаю в команде интеграционного тестирования компании ЮMoney.
Наша команда занимается приемочным тестированием. Оно включает в себя прогон и разбор автотестов на критичные бизнес-процессы в тестовой среде, приближенной по конфигурации к продакшену. Еще мы пишем фреймворк, заглушки, сервисы для тестирования — в целом, создаем экосистему для автоматизации тестирования и обучаем ручных тестировщиков автоматизации.
Надеюсь, что эта статья будет интересна как новичкам, так и тем, кто съел собаку в автоматизации тестирования. Мы рассмотрим базовый синтаксис Jenkins Pipeline, разберемся, как создать джобу на основе пайплайна, а также я расскажу про опыт внедрения неочевидной функциональности в CI — запуска и дожатия автотестов по условию.
Запуск автотестов на Jenkins — инструкция
Не новость, что автотесты эффективнее всего проводить после каждого изменения системы. Запускать их можно локально, но мы рекомендуем делать это только при отладке автотестов. Больший профит автотесты принесут при запуске на CI. В качестве CI-сервера у нас в компании используется Jenkins, в качестве тестового фреймворка — JUnit, а для отчетов — Allure Report.
Чтобы запускать тесты на Jenkins, нужно создать и сконфигурировать джобу.
Для этого достаточно выполнить несколько несложных шагов.
1) Нажать «Создать», выбрать задачу со свободной конфигурацией и назвать ее, например, TestJob.
Естественно, для этого у вас должны быть права в Jenkins. Если их нет, нужно обратиться к администратору Jenkins.
2) Указать репозиторий, откуда будет выкачиваться код проекта: URL, credentials и branch, с которого все будет собираться.
3) Добавить нужные параметры, в этом примере — количество потоков (threadsCount) и список тестов для запуска (testList).
Значение “*Test” для JUnit означает «Запустить все тесты».
4) Добавить команду для запуска тестов.
Наш вариант запускается на Gradle: мы указываем таску теста и передаем параметры в тесты.
Можно выполнить шаг сборки «Выполнить команду shell», либо через Gradle Plugin использовать шаг «Invoke Gradle Script».
5) Нужно добавить Allure-report (должен быть установлен https://plugins.jenkins.io/allure-jenkins-plugin/) в «Послесборочные операции», указав путь к артефактам Allure после прогона (по умолчанию allure-result).
Создав джобу и прогнав с ее помощью тестов, мы можем получить такой результат.
На скрине — реальный прогон. По таймлайну видно, как тесты разделяются по потокам и где были падения.
Несложно заметить, что тесты у нас падают.
Почему падают тесты
Падения могут случаться по разным причинам. В нашем случае на это влияют:
ограниченные ресурсы тестового стенда,
большое число микросервисов (
140); если при запуске интеграционных тестов какой-то один микросервис подтормаживает, тесты начинают валиться,
большое число интеграционных тестов (>3000 E2E),
врожденная нестабильность UI-тестов.
Что такое дожим
Дожим — это перезапуск автотестов в рамках одного прогона. При успешном прохождении автотеста можно считать его пройденным, не учитывая предыдущие падения в прогоне.
«Дожимать? Опасно же!»
Возразите вы и будете полностью правы. Безусловно, дожим автотестов может спровоцировать пропуск дефекта на продакшн. Баг может быть плавающим — при повторном запуске успешно просочиться и попасть на продакшн.
Но мы проанализировали статистику падений автотестов за длительный период и увидели, что большинство падений было связано с нестабильной тестовой средой, тестовыми данными. Поэтому мы взяли на себя риск и стали дожимать тесты. Прошло уже больше года, и не было ни одного дефекта, пропущенного на продакшн по этой причине. Зато стабильность тестов повысилась ощутимо.
Как решать задачу с дожимами
Мы пробовали разные решения: использовали модификацию поведения JUnit 4, JUnit 5, писали обертки на Kotlin. И, к сожалению, каждый раз реализация завязывалась на фичах языка или фреймворка.
Если процесс запускался с помощью JUnit 4 или JUnit 5, возможность перезапустить тесты была только сразу при падении. Тест упал, перезапустили его несколько раз подряд — и если сбоил какой-то микросервис из-за нагрузки, либо настройки тестовой среды были некорректные, то тест все три раза падал.
Это сильно удлиняло прогон, особенно когда проблема была в настройке тестовой среды, что приводило к провалу множества тестов.
Мы взглянули на проблему шире, решили убрать зависимость от тестового фреймворка или языка и реализовали перезапуск на более высоком уровне — на уровне CI. И сделали это с помощью Jenkins Pipeline.
Для этого подходил следующий алгоритм: получаем список упавших тестов и проверяем условия перезапуска. Если упавших тестов нет, завершаем прогон. Если есть, решаем, запускать их повторно или нет. Например, можно реализовать логику, чтобы не перезапускались тесты, если их упало больше какого-то критического числа. Или перед запуском можно сделать проверку доступности тестируемого сервиса.
Что такое Jenkins Pipeline
Jenkins Pipeline — набор плагинов, позволяющий определить жизненный цикл сборки и доставки приложения как код. Он представляет собой Groovy-скрипт с использованием Jenkins Pipeline DSL и хранится стандартно в системе контроля версий.
Существует два способа описания пайплайнов — скриптовый и декларативный.
Они оба имеют структуру, но в скриптовом она вольная — достаточно указать, на каком слейве запускаться (node), и стадию сборки (stage), а также написать Groovy-код для запуска атомарных степов.
Декларативный пайплайн определен более жестко, и, соответственно, его структура читается лучше.
Рассмотрим подробнее декларативный пайплайн.
В структуре должна быть определена директива pipeline.
Также нужно определить, на каком агенте (agent) будет запущена сборка.
Дальше идет определение stages, которые будут содержаться в пайплайне, и обязательно должен быть конкретный стейдж с названием stage(“name”). Если имени нет, тест упадет в runtime с ошибкой «Добавьте имя стейджа».
Обязательно должна быть директива steps, в которой уже содержатся атомарные шаги сборки. Например, вы можете вывести в консоль «Hello».
Мне нравится декларативный вид пайплайна тем, что он позволяет определить действия после каждого стейджа или, например, после всей сборки. Я рекомендую использовать его при описании пайплайнов на верхнем уровне.
Если сборка и стейдж завершились успешно, можно сохранить артефакты или почистить workspace после сборки. Если же при таких условиях использовался бы скриптовый пайплайн, пришлось бы за этим «флоу» следить самостоятельно, добавляя обработку исключений, условия и т.д.
При написании своего первого пайплайна я, естественно, использовал официальный мануал — там подробное описание синтаксиса и степов.
Сначала я даже растерялся и не знал, с чего начать — настолько там много информации. Если вы первый раз сталкиваетесь с написанием пайплайна, начать лучше со знакомства с генераторами фрагментов пайплайна из UI-интерфейса.
Если к URL вашего веб-интерфейса Jenkins добавить ендпойнт /pipelines-syntax, откроется страница, в которой есть ссылки на документацию и два сниппет-генератора, позволяющие генерировать пайплайн даже без знания его синтаксиса:
Declarative sections generator
Генераторы фрагментов — помощники в мире Jenkins
Для создания пайплайна сначала нужно декларативно его описать, а затем наполнить степами. Давайте посмотрим, как вспомогательные инструменты нам в этом помогут.
Declarative sections generator (JENKINS-URL/directive-generator) — генератор фрагментов для декларативного описания пайплайна.
Для добавления стадии нужно написать ее имя и указать, что будет внутри (steps). После нажатия кнопки «Сгенерировать» будет выведен код, который можно добавлять в пайплайн.
Также нам нужны шаги, в которых будут выполняться различные действия — например, запуск джобы Jenkins с тестами.
Snippet Generator (JENKINS-URL/pipeline-syntax) — поможет сгенерировать фрагменты шагов.
В Sample Step выбрать build: Build a job.
(Дальше функционал подсказывает) — необходимо определить параметры, которые будут переданы в джобу (для примера задано branch, project).
Нажать кнопку «Generate» — в результате сформируется готовый рабочий код.
Изменим параметры джобы на те, которые определили при ее создании.
Snippet Generator удобен тем, что подсвечивает шаги в зависимости от установленных плагинов. Если у вас есть, например, Allure-report, то плагин сразу покажет наличие расширения и поможет сгенерировать код, который будет работать.
Вставим сгенерированный код степа в пайплайн на следующем шаге.
Запуск тестов с помощью Pipeline — инструкция
Итак, давайте с помощью Declarative sections generator создадим пайплайн. В нем нужно указать директивы: pipeline, agent (агент, на котором будет запускаться пайплайн), а также stages и steps (вставка ранее сгенерированного кода).
Так получится пайплайн, который запустит джобу, созданную на предыдущем шаге через UI.
Напомню, что в параметры для запуска тестов мы передавали количество потоков и список тестов. Теперь к этому добавляем параметр runId (идентификатор прогона тестов) — он понадобится позднее для перезапуска конкретного сьюта тестов.
Чтобы запустить пайплайн, нужно создать проект.
Для этого нужно нажать на кнопку «Создать проект» и выбрать не джобу со свободной конфигурацией, а джобу Pipeline — осталось указать ей имя.
Добавить параметры runId, threadsCount, testList.
Склонировать из Git.
Пайплайн можно описать непосредственно как код и вставить в поле, но для версионирования нужно затягивать пайплайн из Git. Обязательно указываем путь до скрипта с пайплайном.
Готово, джобу можно запускать.
Хотим добавить немного дожатий
На этом этапе у нас уже готова джоба для запуска проекта с автотестами. Но хочу напомнить, что наша задача — не просто запускать тесты, а добавить им стабильности, исключив падения из-за внешних факторов. Для достижения этого результата было принято решение дожать автотесты.
Для реализации нужно:
вынести шаг запуска тестов в библиотечную функцию (shared steps),
получить упавшие тесты из прогона,
добавить условия перезапуска.
Теперь немного подробнее про каждый из этих шагов.
Многократное использование шагов — Shared Steps
В процессе написания пайплайнов я столкнулся с проблемой постоянного дублирования кода (часто используемых степов). Этого хотелось избежать.
Решение нашлось не сразу. Оказывается, для многократного использования кода в Jenkins есть встроенный механизм — shared libraries, который позволяет описать методы один раз и затем применять их во всех пайплайнах.
Существуют два варианта подключения этой библиотеки.
Написанный проект/код подключить через UI Jenkins. Для этого требуются отдельные права на добавление shared libraries или привлечение девопс-специалистов (что не всегда удобно).
Хранить код в отдельном проекте или в проекте с пайплайнами. При использовании этот код подключается как динамическая библиотека и выкачивается каждый раз при запуске пайплайна.
Мы используем второй вариант — размещаем shared steps в проекте с пайплайнами.
Для этого в проекте нужно:
в ней создать файл с названием метода, который планируется запускать — например, gradlew.groovy,
стандартно определить имя метода (должен называться call), то есть написать «def call» и определить входящие параметры,
в теле метода можно написать произвольный Groovy-код и/или Pipeline-степы.
Вынесение запуска тестов в shared steps в /var
Выносим startTests.groovy в /var.
Во-первых, нужно вынести запуск тестов в отдельный метод. Выглядит это так — создаем файл, называем метод def call, берем кусок кода, который был в пайплайне, и выносим его в этот step.
Структура проекта будет выглядеть так.
Подключение shared steps как внешней библиотеки.
Дальше нужно добавить вынесенные шаги в пайплайн. При динамической подгрузке библиотек (во время запуска пайплайна) эти шаги выкачиваются из репозитория и подключаются на лету.
Сделать это можно с помощью сниппет-генератора — выбираем степ library и указываем ветку, в которую все будет собираться и репозиторий. Дальше нажимаем кнопку «Сгенерировать» и вставляем получившийся пайплайн.
Теперь после подключения shared steps вместо шага запуска тестов build нужно вставить startTest. Не забудьте, что имя метода должно совпадать с именем файла.
Теперь наш пайплайн выглядит так.
Первый шаг реализован, теперь можно многократно запускать тесты в разных местах. Переходим к 2 шагу.
Получение упавших тестов из прогона
Теперь нам нужны упавшие тесты. Каким образом их извлечь?
Установить в Jenkins плагин JUnit Test Result Report и использовать его API.
Взять результаты прогона JUnit (обычно в формате XML), распарсить и извлечь нужные данные.
Запросить список упавших тестов из нужного места.
В нашем случае таким местом является собственный написанный сервис — Reporter. Во время прогона тестов результат по каждому из них отправляется именно туда. В конце прогона делаем http-запрос и получаем упавшие тесты.
Добавление условий перезапуска
На этом шаге следует добавить getFailedTests.groovy в /var. Представим, что у вас есть такой сервис — Reporter. Нужно назвать файл getFailedTests, сделать запрос httpRequest в этот сервис и распарсить его.
Отлично, второй шаг выполнен. Осталось добавить ту самую изюминку — условия перезапуска. Но сначала посмотрим, что получается.
Есть запуск тестов и получение результатов прогона. Теперь нужно добавить те самые условия, которые будут говорить: «Если все хорошо, завершай прогон. Если плохо, давай перезапускать».
Условия перезапуска
Какие условия для перезапуска можно реализовать?
Приведу часть условий, которые используем мы.
1) Если нет упавших тестов, прогон завершается.
2) Как я уже писал выше, на тестовой среде ресурсы ограничены, и бывает такое, что ТС захлебывается в большом количестве параллельных тестов. Чтобы на дожатии избежать падений тестов по этой причине, понижаем число потоков на повторном запуске. Именно для этого при создании джобы и в самом пайплайне мы добавили параметр threadsCount.
Если и после уменьшения потоков тесты не дожимаются (количество упавших тестов на предыдущем прогоне равно числу упавших тестов на текущем), тогда считаем, что дело не во влиянии ТС на тесты. Останавливаем прогон для анализа причин падений — и тем самым предотвращаем последующий холостой запуск.
3) Третья и самая простая проверка состоит в том, что если падает большое количество тестов, то дожимать долго. Скорее всего, причина падений какая-то глобальная, и ее нужно изучать.
Для себя мы определили: если тестов > 40, дожимать не автоматически не будем, потому что 40 наших E2E могут проходить порядка 15 минут.
Последние два условия — так называемые fail fast. Они позволяют при глобальных проблемах на тестовом стенде не делать прогоны, которые не приведут к дожиму тестов, но будут занимать ресурсы тестового стенда.
Итоговый pipeline
Итак, все 3 шага реализованы — итоговый пайплайн выглядит так.
Визуализация с Blue Ocean
Как все это выглядит при прогоне в Jenkins? У нас, к примеру, для визуализации в Jenkins установлен плагин Blue Ocean.
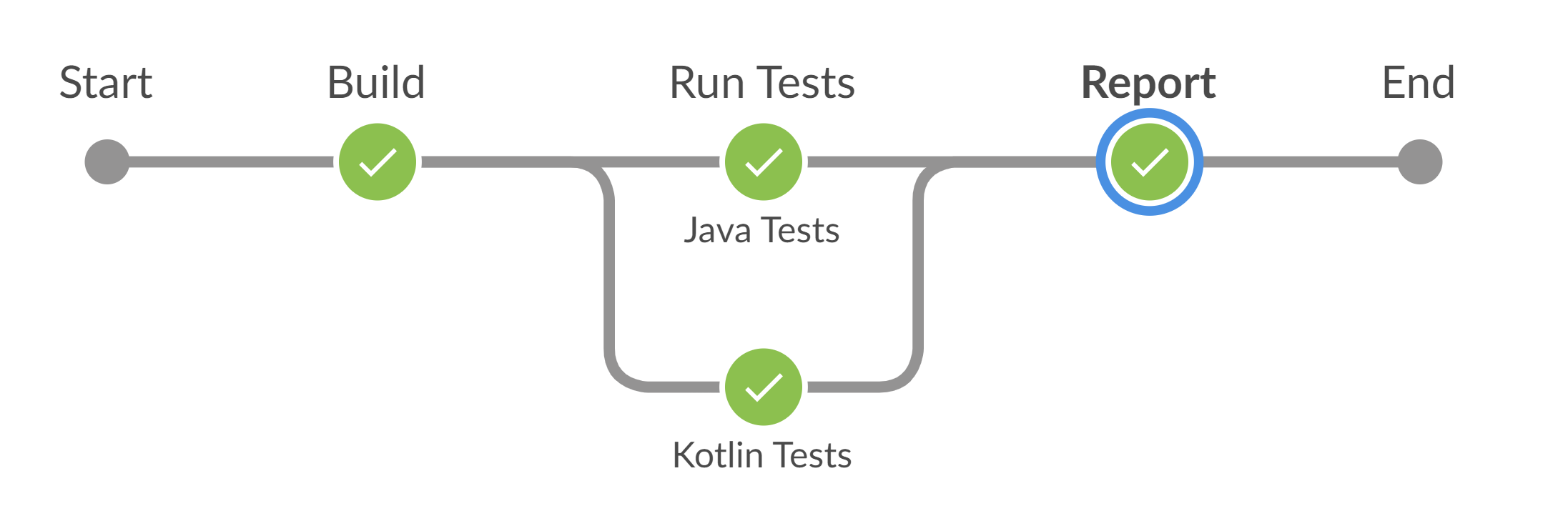
На картинке ниже можно увидеть, что:
запустился метод testwith_rerun,
прошел первый запуск,
прошла проверка упавших тестов,
запустился второй прогон,
после успешной проверки джоба завершилась.

Вот так выглядит визуализация нашего настоящего прогона.
В реальном примере две ветки: мы параллельно запускаем два проекта с тестами (на Java и Kotlin). Можно заметить, что тесты одного проекта прошли с первого раза, а вот тесты другого пришлось дожимать еще раз. Таким образом визуализация помогает найти этап, на котором падают тесты.
А так выглядит реальный timeline приемки релиза.
После первого прогона отправили дожимать упавшие тесты. Во второй раз упавших тестов намного меньше, дожимаем в третий раз — и вуаля, успешный build.
Мы перенесли логику перезапусков упавших тестов из тестового проекта на уровень выше — на CI. Таким образом сделали механизм перезапуска универсальным, более гибким и независимым от стека, на котором написаны автотесты.
Раньше наши тесты дожимались безусловно, по несколько раз, с неизменным количеством параллельных потоков. При перегрузке тестового стенда, некорректных настройках тестового окружения либо каких-то других проблемах — красные тесты перезапускались фиксированное число раз без шансов дожаться. В худшем случае прогоны могли длиться часами. Добавив условия fail fast, мы сократили это время.
При падении тестов инженер, ответственный за приемку, в некоторых ситуациях вручную стартовал джобу перезапуска, выполняя прогон с меньшим числом потоков. На это тоже уходило время. Добавив в условия пайплайна уменьшение числа потоков на перезапуске, мы сократили и это время.
Какой профит мы получили:
уменьшили time-to-market тестируемых изменений,
сократили длительность аренды тестового стенда под приемочное тестирование,
увеличили пропускную способность очереди приемочного тестирования,
не завязаны на тестовый фреймворк («под капотом» может быть что угодно — дожатия будут работать),
поделились знаниями об использовании Jenkins Pipeline.
Примеры кода выложены на GitHub. Если будут вопросы, задавайте — обязательно отвечу.
А еще в нашей компании принято награждать ачивкой за какое-то достижение. Статья получилось достаточно подробной и многословной, а потому вас, дочитавших до конца этот лонгрид, хотелось бы поощрить.
Помимо +100 к опыту и знаниям Jenkins вы получаете ачивку «Ю Academic»! 🙂



