Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
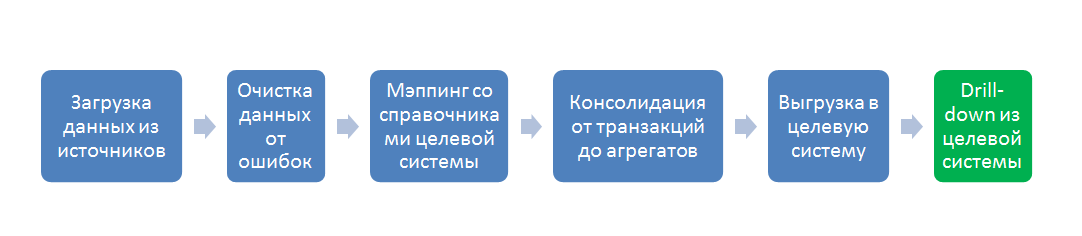
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
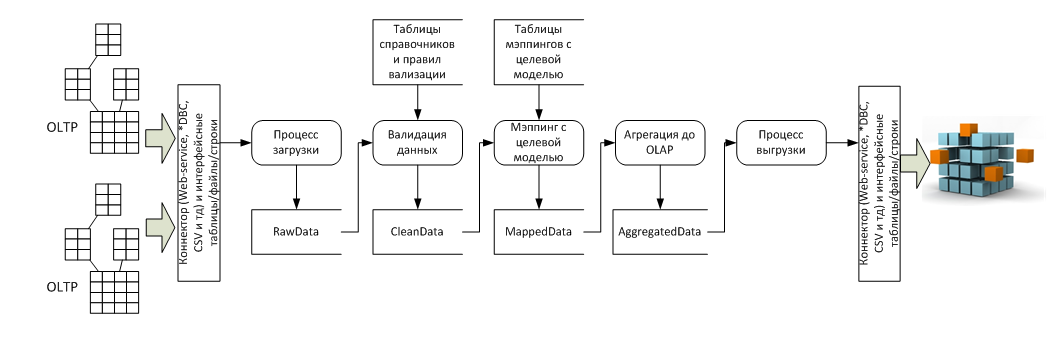
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
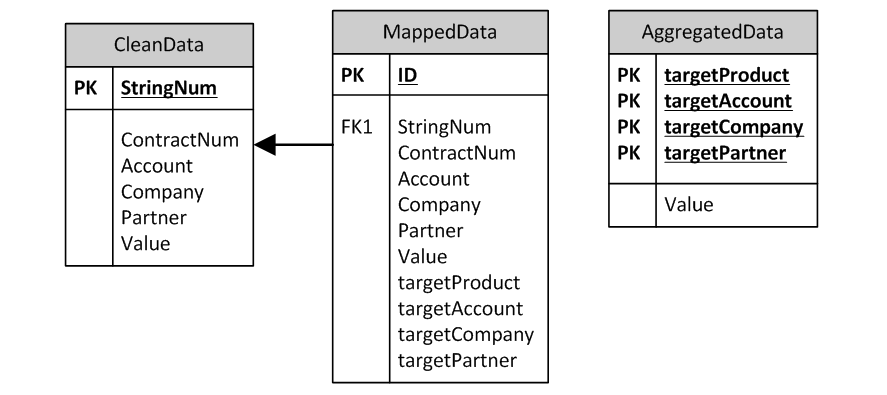
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Что такое ETL: как справиться с анализом big data
Крупные предприятия собирают, хранят и обрабатывают разные типы данных из множества источников, таких как системы начисления заработной платы, записи о продажах, системы инвентаризации и других. Эта информация извлекается, преобразуется и переносится в хранилища данных с помощью ETL-систем. Расскажем, что такое ETL, а также какие платные и общедоступные решения для работы с данными есть на рынке.
ETL — что это такое и зачем?
В переводе ETL (Extract, Transform, Load) — извлечение, преобразование и загрузка. То есть процесс, с помощью которого данные из нескольких систем объединяют в единое хранилище данных.
Представьте ритейлера с розничными и интернет-магазинами. Ему нужно анализировать тенденции продаж и онлайн, и офлайн. Но бэкэнд-системы для них, скорее всего, будут отдельными. Они могут иметь разные поля или форматы полей для сбора данных, использовать системы, которые не могут «общаться» друг с другом.
И вот тогда наступает момент для ETL.
ETL-система извлекает данные из обеих систем, преобразует их в соответствии с требованиями к формату хранилища данных, а затем загружает в это хранилище.
ETL — что это на практике, а не на примере?
Современные инструменты ETL собирают, преобразуют и хранят данные из миллионов транзакций в самых разных источниках данных и потоках. Эта возможность предоставляет множество новых возможностей: анализ исторических записей для оптимизации процесса продаж, корректировка цен и запасов в реальном времени, использование машинного обучения и искусственного интеллекта для создания прогнозных моделей, разработка новых потоков доходов, переход в облако и многое другое.
Облачная миграция. Процесс переноса данных и приложений в облако называют облачной миграцией. Она помогает сэкономить деньги, сделать приложения более масштабируемыми и защитить данные. ETL в таком случае используют для перемещения данных в облако.
Хранилище данных. Хранилище данных — база данных, куда передают данные из различных источников, чтобы их можно было совместно анализировать в коммерческих целях. Здесь ETL используют для перемещения данных в хранилище данных.
Машинное обучение. Машинное обучение — метод анализа данных, который автоматизирует построение аналитических моделей. ETL может использоваться для перемещения данных в одно хранилище для машинного обучения.
Интеграция маркетинговых данных. Маркетинговая интеграция включает в себя перемещение всех маркетинговых данных — о клиентах, продажах, из социальных сетей и веб-аналитики — в одно место, чтобы вы могли проанализировать их. ETL используют для объединения маркетинговых данных.
Интеграция данных IoT. То есть данных, собранных различными датчиками, в том числе встроенными в оборудование. ETL помогает перенести данные от разных IoT в одно место, чтобы вы могли сделать их подробный анализ.
Репликация базы данных — данные из исходных баз данных копируют в облачное хранилище. Это может быть одноразовая операция или постоянный процесс, когда ваши данные обновляются в облаке сразу же после обновления в исходной базе. ETL можно использовать для осуществления процесса репликации данных.
Бизнес-аналитика. Бизнес-аналитика — процесс анализа данных, позволяющий руководителям, менеджерам и другим заинтересованным сторонам принимать обоснованные бизнес-решения. ETL можно использовать для переноса нужных данных в одно место, чтобы их можно было использовать.
Популярные ETL-системы: обзор, но коротко
Cloud Big Data — PaaS-сервис для анализа больших данных (big data) на базе Apache Hadoop, Apache Spark, ClickHouse. Легко масштабируется, позволяет заменить дорогую и неэффективную локальную инфраструктуру обработки данных на мощную облачную инфраструктуру. Помогает обрабатывать структурированные и неструктурированные данные из разных источников, в том числе в режиме реального времени. Развернуть кластер интеграции и обработки данных в облаках можно за несколько минут, управление осуществляется через веб-интерфейс, командную строку или API.
IBM InfoSphere — инструмент ETL, часть пакета решений IBM Information Platforms и IBM InfoSphere. Доступен в различных версиях (Server Edition, Enterprise Edition и MVS Edition). Помогает в очистке, мониторинге, преобразовании и доставке данных, среди преимуществ: масштабируемость, возможность интеграции почти всех типов данных в режиме реального времени.
PowerCenter — набор продуктов ETL, включающий клиентские инструменты PowerCenter, сервер и репозиторий. Данные хранятся в хранилище, где к ним получают доступ клиентские инструменты и сервер. Инструмент обеспечивает поддержку всего жизненного цикла интеграции данных: от запуска первого проекта до успешного развертывания критически важных корпоративных приложений.
iWay Software предоставляет возможность интеграции приложений и данных для удобного использования в режиме реального времени. Клиенты используют их для управления структурированной и неструктурированной информацией. В комплект входят: iWay DataMigrator, iWay Service Manager и iWay Universal Adapter Framework.
Microsoft SQL Server — платформа управления реляционными базами данных и создания высокопроизводительных решений интеграции данных, включающая пакеты ETL для хранилищ данных.
OpenText — платформа интеграции, позволяющая извлекать, улучшать, преобразовывать, интегрировать и переносить данные и контент из одного или нескольких хранилищ в любое новое место назначения. Позволяет работать со структурированными и неструктурированными данными, локальными и облачными хранилищами.
Oracle GoldenGate — комплексный программный пакет для интеграции и репликации данных в режиме реального времени в разнородных IT-средах. Обладает упрощенной настройкой и управлением, поддерживает облачные среды.
Pervasive Data Integrator — программное решение для интеграции между корпоративными данными, сторонними приложениями и пользовательским программным обеспечением. Data Integrator поддерживает сценарии интеграции в реальном времени.
Pitney Bowes предлагает большой набор инструментов и решений, нацеленных на интеграцию данных. Например, Sagent Data Flow — гибкий механизм интеграции, который собирает данные из разнородных источников и предоставляет полный набор инструментов преобразования данных для повышения их коммерческой ценности.
SAP Business Objects — централизованная платформа для интеграции данных, качества данных, профилирования данных, обработки данных и отчетности. Предлагает бизнес-аналитику в реальном времени, приложения для визуализации и аналитики, интеграцию с офисными приложениями.
Sybase включает Sybase ETL Development и Sybase ETL Server. Sybase ETL Development — инструмент с графическим интерфейсом для создания и проектирования проектов и заданий по преобразованию данных. Sybase ETL Server — масштабируемый механизм, который подключается к источникам данных, извлекает и загружает данные в хранилища.
Open source ETL-средства
Большинство инструментов ETL с открытым исходным кодом помогают в управлении пакетной обработкой данных и автоматизации потоковой передачи информации из одной системы данных в другую. Эти рабочие процессы важны при создании хранилища данных для машинного обучения.
Некоторые из бесплатных и открытых инструментов ETL принадлежат поставщикам, которые в итоге хотят продать корпоративный продукт, другие обслуживаются и управляются сообществом разработчиков, стремящихся демократизировать процесс.
Open source ETL-инструменты интеграции данных:
Apache Airflow — платформа с удобным веб-интерфейсом, где можно создавать, планировать и отслеживать рабочие процессы. Позволяет пользователям объединять задачи, которые нужно выполнить в строго определенной последовательности по заданному расписанию. Пользовательский интерфейс поддерживает визуализацию рабочих процессов, что помогает отслеживать прогресс и видеть возникающие проблемы.
Apache Kafka — распределенная потоковая платформа, которая позволяет пользователям публиковать и подписываться на потоки записей, хранить потоки записей и обрабатывать их по мере появления. Kafka используют для создания конвейеров данных в реальном времени. Он работает как кластер на одном или нескольких серверах, отказоустойчив и масштабируем.
Apache NiFi — распределенная система для быстрой параллельной загрузки и обработки данных с большим числом плагинов для источников и преобразований, широкими возможностями работы с данными. Пользовательский веб-интерфейс NiFi позволяет переключаться между дизайном, управлением, обратной связью и мониторингом.
CloverETL (теперь CloverDX) был одним из первых инструментов ETL с открытым исходным кодом. Инфраструктура интеграции данных, основанная на Java, разработана для преобразования, отображения и манипулирования данными в различных форматах. CloverETL может использоваться автономно или встраиваться и подключаться к другим инструментам: RDBMS, JMS, SOAP, LDAP, S3, HTTP, FTP, ZIP и TAR. Хотя продукт больше не предлагается поставщиком, его можно безопасно загрузить с помощью SourceForge. CloverDX по-прежнему поддерживает CloverETL в соответствии со стандартным соглашением о поддержке.
Jaspersoft ETL — один из продуктов с открытым исходным кодом TIBCO Community Edition, позволяет пользователям извлекать данные из различных источников, преобразовывать их на основе определенных бизнес-правил и загружать в централизованное хранилище данных для отчетности и аналитики. Механизм интеграции данных инструмента основан на Talend. Community Edition прост в развертывании, позволяет создавать витрины данных для отчетности и аналитики.
Apatar — кроссплатформенный инструмент интеграции данных с открытым исходным кодом, который обеспечивает подключение к различным базам данных, приложениям, протоколам, файлам. Позволяет разработчикам, администраторам баз данных и бизнес-пользователям интегрировать информацию разного формата из различных источников данных. У инструмента интуитивно понятный пользовательский интерфейс, который не требует кодирования для настройки заданий интеграции данных. Инструмент поставляется с предварительно созданным набором инструментов интеграции и позволяет пользователям повторно использовать ранее созданные схемы сопоставления.
Итак, почему стоит отказаться от локальных ETL-решений?
Традиционные локальные ETL чаще всего поставляются в комплекте с головной болью. Например, создаются собственными силами, поэтому могут быстро устареть или не иметь сложных функций и возможностей. Они дороги и требуют времени на обслуживание, а также поддерживают только пакетную обработку данных и плохо масштабируются.
Локальные платформы ETL были важнейшим компонентом инфраструктуры предприятий на протяжении десятилетий. С появлением облачных технологий, SaaS и больших данных выросло число источников информации, что вызвало рост спроса на более мощную и сложную интеграцию данных.
Oracle Data Integration, Cloud, Spatial and Analytics
Oracle Data Integration, Cloud, Spatial and Analytics (GoldenGate, ODI, Cloud, Spatial, Exadata)
Введение в Oracle Data Integrator
Oracle занимается вопросами интеграции данных достаточно давно, но долгое время такая интеграция обеспечивалась только в однородной среде, т.е. среде баз данных Oracle. Однако, реальность такова, что в компаниях обычно существуют не только Oracle, но и другие конкурирующие базы данных: MSSQL, DB2 и т.д. Даже если это не так, то и сама компания Oracle имеет не одну базу данных — например, MySQL, Berkley, TimesTen.
Ориентируясь на свою базу данных, Oracle разработал отличный инструмент — Oracle Warehouse Builder. Ключевым элементом использования этого инструмента было формирование PL/SQL процедур, которые осуществляли преобразование. Процедуры управлялись через графический интерфейс. Инструмент был бесплатным. Все бы хорошо, но увлекшись Oracle Warehouse Builder, Streams и гетерогенными сервисами, Oracle проспал рынок выделенных инструментов ETL инструментов. Вот почему в 2007 была приобретена компания Sunopsis, один из лидеров ETL рынка.
Oracle Data Integrator, продукт компании Sunopsis, был выбран в качестве основного продукта для интеграции данных. Он обладает всеми необходимыми качествами — высокоскоростной, гибкий, гетерогенный. Его идеология совпадает с идеологией ранее разработанных продуктов Oracle, да и сам продукт отлично укладывается в линейку ETL-инструментов.
Поскольку многие компании вложились в Oracle Warehouse Builder, было принято решение не бросать его разработку, а произвести постепенное слияние продуктов. Об этом достаточно подробно написано в блоге Андрея Пивоварова.
Обобщая, можно сказать, что Oracle Data Integrator — основной и приоритетный продукт. Именно он будет развиваться быстрыми темпами, именно он будет использовать в других продуктах Oracle для интеграции данных.
E-LT и ETL. Меняется ли смысл от перестановки букв?
Об этих двух подходах написано много. Каждый из них имеет свои плюсы и минусы.
Подход ETL подразумевает порядок выгрузку данных в stage область, преобразование там этих данных, а затем загрузку данных в хранилище. Этот подход стар как мир и имеет большое количество инструментов, которые его поддерживают. Разработка концепции ETL подразумевала, что ни источники данных, ни хранилище данных неспособные самостоятельно преобразовать данные к нужному виду.
Подход E-LT также основан на том, что данные сначала загружаются stage область, но в отличие от предыдущего подхода хранилище данных и stage область совмещены. Т.е. мы имеем в хранилище сырые данные, которые затем могут быть трансформированы в любой нужный нам вид и сохранены в том же хранилище.
E-LT подход хорош тем, что в хранилище данных мы можем отследить, откуда появились данные, т.е. имеем как преобразованные (агрегированные, отобранные, трансформированные) данные, так и исходные. Кроме того, мы можем допускать пользователя к исходным данные с минимальной агрегацией, что дает нам возможность строить операционные витрины данных и операционный BI. Делается это за счет применения CDC технологий (GoldenGate, Streams, triggers). Подробнее о построении операционных BI можно посмотреть в моей презентации.
Если краткое, то отличие операционного BI от стратегического можно выразить следующей таблицей:

Если подвести итог, то у E-LT подхода есть следующие плюсы:
Наличие плюсов, подразумевает наличие минусов:
Однако, если вдуматься в эти подходы можно увидеть и много общего. Более того, эти подходы в чистом виде в реальности встречаются не так часто.
Приведем пример. Допустим, нам нужно в хранилище данных получать таблицу агрегатов из 100 строк — по 1 строке для каждого офиса. Имеет ли смысл тащить таблицу с исходными данными объемом 100 млн. строк в stage область? Я думаю, что нет.
Вот почему, многие разработчики ETL средств пытаются научить свои средства работать с базой данных более эффективно нежели просто вытаскивать сырые данные.
Подход компании Oracle был изначально направлен именно на использование возможностей базы данных. По сути с приобретением компании Sunopsis у Oracle появился инструмент TETLT, т.е. инструмент, который трансформирует данные в том месте, где это наиболее эффективно.
Архитектура ODI
Для того, чтобы эффективно использовать ODI необходимо понимать архитектуру комплекса.

При репликации данных в Oracle Data Integrator используются так называемые Knowledge Module — набор компонентов. Каждый компонент отвечает за свою задачу.

Комбинация этих модулей и позволяет задать процесс переноса данных в хранилище.
Заключение
Итак, инструмент Oracle Data Integrator — это ETL-инструмент, позволяющий декларативно определять процесс выгрузки, преобразования и загрузки данных в хранилище.
Продукт изначально был разработан так, чтобы максимально задействовать средства базы данных, поэтому, в частности, он дает возможность обойтись без выделенного центра для ETL-преобразования.
Для ODI разработан целый ряд knowledge-модулей, которые позволяют извлекать и загружать данные практически в любую базу данных и информационную систему.
В следующих постах я более подробно расскажу об использовании Oracle Data Inetegrator для построения ETL-решений.
What is ETL?
Extract, transform, and load (ETL) is the process data-driven organizations use to gather data from multiple sources and then bring it together to support discovery, reporting, analysis, and decision-making.
The data sources can be very diverse in type, format, volume, and reliability, so the data needs to be processed to be useful when brought together. The target data stores may be databases, data warehouses, or data lakes, depending on the goals and technical implementation.
The three distinct steps of ETL
Extract
During extraction, ETL identifies the data and copies it from its sources, so it can transport the data to the target datastore. The data can come from structured and unstructured sources, including documents, emails, business applications, databases, equipment, sensors, third parties, and more.
Transform
Because the extracted data is raw in its original form, it needs to be mapped and transformed to prepare it for the eventual datastore. In the transformation process, ETL validates, authenticates, deduplicates, and/or aggregates the data in ways that make the resulting data reliable and queryable.
Load
ETL moves the transformed data into the target datastore. This step can entail the initial loading of all the source data, or it can be the loading of incremental changes in the source data. You can load the data in real time or in scheduled batches.
ELT or ETL: What’s the difference?
The transformation step is by far the most complex in the ETL process. ETL and ELT, therefore, differ on two main points:
In a traditional data warehouse, data is first extracted from «source systems» (ERP systems, CRM systems, etc.). OLAP tools and SQL queries depend on standardizing the dimensions of datasets to obtain aggregated results. This means that the data must undergo a series of transformations.
Traditionally, these transformations have been done before the data was loaded into the target system, typically a relational data warehouse.
However, as the underlying data storage and processing technologies that underpin data warehousing evolve, it has become possible to effect transformations within the target system. Both ETL and ELT processes involve staging areas. In ETL, these areas are found in the tool, whether it is proprietary or custom. They sit between the source system (for example, a CRM system) and the target system (the data warehouse).
In contrast, with ELTs, the staging area is in the data warehouse, and the database engine that powers the DBMS does the transformations, as opposed to an ETL tool. Therefore, one of the immediate consequences of ELTs is that you lose the data preparation and cleansing functions that ETL tools provide to aid in the data transformation process.
ETL and enterprise data warehouses
Traditionally, tools for ETL primarily were used to deliver data to enterprise data warehouses supporting business intelligence (BI) applications. Such data warehouses are designed to represent a reliable source of truth about all that is happening in an enterprise across all activities. The data in these warehouses is carefully structured with strict schemas, metadata, and rules that govern the data validation.
The ETL tools for enterprise data warehouses must meet data integration requirements, such as high-volume, high-performance batch loads; event-driven, trickle-feed integration processes; programmable transformations; and orchestrations so they can deal with the most demanding transformations and workflows and have connectors for the most diverse data sources.
After loading the data, you have multiple strategies for keeping it synchronized between the source and target datastores. You can reload the full dataset periodically, schedule periodic updates of the latest data, or commit to maintain full synchronicity between the source and the target data warehouse. Such real-time integration is referred to as change data capture (CDC). For this advanced process, the ETL tools need to understand the transaction semantics of the source databases and correctly transmit these transactions to the target data warehouse.
ETL and data marts
Data marts are smaller and more focused target datastores than enterprise data warehouses. They can, for instance, focus on information about a single department or a single product line. Because of that, the users of ETL tools for data marts are often line-of-business (LOB) specialists, data analysts, and/or data scientists.
ETL tools for data marts must be usable by business personnel and data managers, rather than by programmers and IT staff. Therefore, these tools should have a visual workflow to make it easy to set up ETL pipelines.
ETL or ELT and data lakes
Data lakes follow a different pattern than data warehouses and data marts. Data lakes generally store their data in object storage or Hadoop Distributed File Systems (HDFS), and therefore they can store less-structured data without schema; and they support multiple tools for querying that unstructured data.
One additional pattern this allows is extract, load, and transform (ELT), in which data is stored “as-is” first, and will be transformed, analyzed, and processed after the data is captured in the data lake. This pattern offers several benefits.
ETL tools for data lakes include visual data integration tools, because they are effective for data scientists and data engineers. Additional tools that are often used in data lake architecture include the following:
ETL use cases
The ETL process is fundamental for many industries because of its ability to ingest data quickly and reliably into data lakes for data science and analytics, while creating high-quality models. ETL solutions also can load and transform transactional data at scale to create an organized view from large data volumes. This enables businesses to visualize and forecast industry trends. Several industries rely on ETL to enable actionable insights, quick decision-making, and greater efficiency.
Financial services
Financial services institutions gather large amounts of structured and unstructured data to glean insights into consumer behavior. These insights can analyze risk, optimize banks’ financial services, improve online platforms, and even supply ATMs with cash.
Oil and gas
Oil and gas industries use ETL solutions to generate predictions about usage, storage, and trends in specific geographical areas. ETL works to gather as much information as possible from all the sensors of an extraction site and process that information to make it easy to read.
Automotive
ETL solutions can enable dealerships and manufacturers to understand sales patterns, calibrate their marketing campaigns, replenish inventory, and follow up on customer leads.
Telecommunications
With the unprecedented volume and variety of data being produced today, telecommunications providers rely on ETL solutions to better manage and understand that data. Once this data is processed and analyzed, businesses can use it to improve advertising, social media, SEO, customer satisfaction, profitability, and more.
Healthcare
With the need to reduce costs while also improving care, the healthcare industry employs ETL solutions to manage patient records, gather insurance information, and meet evolving regulatory requirements.
Life sciences
Clinical labs rely on ETL solutions and artificial intelligence (AI) to process various types of data being produced by research institutions. For example, collaborating on vaccine development requires huge amounts of data to be collected, processed, and analyzed.
Public sector
With Internet of Things (IoT) capabilities emerging so quickly, smart cities are using ETL and the power of AI to optimize traffic, monitor water quality, improve parking, and more.
ETL Products and Solutions
Service Oriented Architecture (SOA) Suite
How can you decrease the complexity of application integration? With simplified cloud, mobile, on-premises, and IoT integration capabilities—all within a single platform—this solution can deliver faster time to integration and increased productivity, along with a lower total cost of ownership (TCO). Many enterprise applications, including, Oracle E-Business Suite, heavily use this product to orchestrate dataflows.
GoldenGate
Digital transformation often demands moving data from where it’s captured to where it’s needed, and GoldenGate is designed to simplify this process. Oracle GoldenGate is a high-speed data replication solution for real-time integration between heterogeneous databases located on-premises, in the cloud, or in an autonomous database. GoldenGate improves data availability without affecting system performance, providing real-time data access and operational reporting.
Cloud Streaming
Our Cloud Streaming solution provides a fully managed, scalable, and durable solution for ingesting and consuming high-volume data streams in real time. Use this service for messaging, application logs, operational telemetry, web clickstream data, or any other instance in which data is produced and processed continually and sequentially in a publish-subscribe messaging model. It is fully compatible with Spark and Kafka.



