Когда Linux conntrack вам больше не товарищ

Отслеживание соединений (“conntrack”) является основной функцией сетевого стека ядра Linux. Она позволяет ядру отслеживать все логические сетевые соединения или потоки и тем самым идентифицировать все пакеты, которые составляют каждый поток, чтобы их можно было последовательно обрабатывать вместе.
Conntrack — это важная функция ядра, которая используется в некоторых основных случаях:
Кроме того, conntrack обычно повышает производительность системы (снижая потребление процессорного времени и время задержек пакетов), поскольку только первый пакет в потоке
должен пройти полную обработку стека сети, чтобы определить, что с ним делать. Смотрите пост «Сравнение режимов kube-proxy», чтобы увидеть пример того, как это работает.
Тем не менее, у conntrack есть свои ограничения.
Итак, где все пошло не так?
Таблица conntrack имеет настраиваемый максимальный размер, и, если она заполняется, соединения обычно начинают отклоняться или прерываться. Для обработки трафика большинства приложений в таблице достаточно свободного места, и это никогда не превратится в проблему. Тем не менее, есть несколько сценариев, при которых стоит задуматься об использовании таблицы conntrack:
Есть несколько нишевых типов приложений, попадающих в эти категории. Кроме того, если у вас много недоброжелателей, то заполнение таблицы conntrack вашего сервера множеством полуоткрытых соединений может использоваться в рамках атаки типа «отказ в обслуживании» (DOS). В обоих случаях conntrack может стать ограничивающим узким местом в вашей системе. В некоторых случаях настройки параметров таблицы conntrack может быть достаточно для удовлетворения ваших потребностей — путем увеличения размера или сокращения тайм-аутов conntrack (но если вы сделаете это неправильно, то столкнетесь с большими трудностями). Для других случаев будет необходимо обойти conntrack для агрессивного трафика.
Реальный пример
Приведем конкретный пример: один крупный SaaS провайдер с которым мы работали имел ряд memcached-серверов на хостах (не виртуальных машинах), каждый из которых обрабатывал 50К+ кратковременных соединений в секунду.
Они экспериментировали с конфигурацией conntrack, увеличивали размеры таблиц и сокращали время отслеживания, но конфигурация была ненадежной, значительно увеличилось потребление ОЗУ, что было проблемой(порядка ГБайтов!), а соединения были настолько короткими что conntrack не создавал своего обычного выигрыша в производительности (уменьшение потребления ЦП или задержек пакетов).
В качестве альтернативы они обратились к Calico. Сетевые политики Calico позволяют не использовать conntrack для определенного вида трафика (используя для политик опцию doNotTrack). Это обеспечило им необходимый уровень производительности плюс дополнительный уровень безопасности, предоставляемый Calico.
На что придется пойти, чтобы обойти conntrack?
Приступим к тестам
Мы проводили тест на одном pod’е с memcached-сервером и множеством pod’ов memcached-клиентов, запущенных на удаленных нодах, так что бы мы могли запускать очень большое количество соединений в секунду. Сервер с pod’ом memcached-сервера имел 8 ядер и 512k записей в conntrack таблице (стандартно настроенный размер таблицы для хоста).
Мы измеряли разницу в производительности между: без сетевой политики; с обычной Calico политикой; и Calico do-not-track политикой.
Для первого теста мы задали количество коннектов до 4.000 в секунду, поэтому мы могли сфокусироваться на разнице потребления CPU. Здесь не было существенных отличий между отсутствием политики и обычной политики, но do-not-track увеличила потребление CPU примерно на 20% :
Во втором тесте мы запустили столько соединений, сколько могли сгенерировать наши клиенты и измеряли максимальное количество соединений в секунду, которое мог отработать наш memcached-сервер. Как и ожидалось, в случае “без политик” и “обычная политика” оба достигли лимита conntrack в более чем 4,000 соединений в секунду (512k / 120s = 4,369 соединений/с). С do-not-track политикой наши клиенты отправляли 60,000 соединений в секунду без каких-либо проблем. Мы уверены, что могли бы увеличить это число, подключив большее количество клиентов, но чувствуем, что этих цифр уже достаточно, чтобы проиллюстрировать посыл этой статьи!
Заключение
Conntrack — это важная функция ядра. Он отлично выполняет свою работу. Зачастую его используют ключевые компоненты системы. Однако, в некоторых определенных сценариях, перегрузка из-за conntrack перевешивает обычные преимущества, которые он дает. В данном сценарии сетевые политики Calico могут быть использованы, чтобы выборочно отключать использование conntrack при этом повышая уровень сетевой безопасности. Для всего остального трафика conntrack продолжает быть вашим товарищем!
Мониторинг сетевого стека linux
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
С одной стороны большинство проблем с сетью возникают как раз на физическом и канальном уровнях, но с другой стороны приложения, работающие с сетью оперируют на уровне TCP сессий и не видят, что происходит на более низких уровнях.
Я расскажу, как достаточно простые метрики TCP/IP стека могут помочь разобраться с различными проблемами в распределенных системах.
Netlink
Почти все знают утилиту netstat в linux, она может показать все текущие TCP соединения и дополнительную информацию по ним. Но при большом количестве соединений netstat может работать достаточно долго и существенно нагрузить систему.
Есть более дешевый способ получить информацию о соединениях — утилита ss из проекта iproute2.
Ускорение достигается за счет использования протола netlink для запросов информации о соединениях у ядра. Наш агент использует netlink напрямую.
Считаем соединения
Disclaimer: для иллюстрации работы с метриками в разных срезах я буду показывать наш интерфейс (dsl) работы с метриками, но это можно сделать и на opensource хранилищах.
В первую очередь мы разделяем все соединения на входящие (inbound) и исходящие (outbound) по отношению к серверу.
Каждое TCP соединения в определенный момент времени находится в одном из состояний, разбивку по которым мы тоже сохраняем (это иногда может оказаться полезным):
По этому графику можно оценить общее количество входящих соединений, распределение соединений по состояниям.
Здесь так же видно резкое падение общего количества соединений незадолго до 11 Jun, попробуем посмотреть на соединения в разрезе listen портов:
На этом графике видно, что самое значительное падение было на порту 8014, посмотрим только 8014 (у нас в интерфейсе можно просто нажать на нужном элементе легенды):
Попробуем посмотреть, изменилось ли количество входящий соединений по всем серверам?
Выбираем серверы по маске “srv10*”:
Теперь мы видим, что количество соединений на порт 8014 не изменилось, попробуем найти на какой сервер они мигрировали:
Мы ограничили выборку только портом 8014 и сделали группировку не по порту, а по серверам.
Теперь понятно, что соединения с сервера srv101 перешли на srv102.
Разбивка по IP
Часто бывает необходимо посмотреть, сколько было соединений с различных IP адресов. Наш агент снимает количество TCP соединений не только с разбивкой по listen портам и состояниям, но и по удаленному IP, если данный IP находится в том же сегменте сети (для всех остальный адресов метрики суммируются и вместо IP мы показываем “
Рассмотрим тот же период времени, что и в предыдущих случаях:
Здесь видно, что соединений с 192.168.100.1 стало сильно меньше и в это же время появились соединения с 192.168.100.2.
Детализация рулит
На самом деле мы работали с одной метрикой, просто она была сильно детализирована, индентификатор каждого экземпляра выглядит примерно так:
Например, у одно из клиентов на нагруженном сервере-фронтенде снимается
700 экземпляров этой метрики
TCP backlog
По метрикам TCP соединений можно не только диагностировать работу сети, но и определять проблемы в работе сервисов.
Например, если какой-то сервис, обслуживающий клиентов по сети, не справляется с нагрузкой и перестает обрабатывать новые соединения, они ставятся в очередь (backlog).
На самом деле очереди две:
При достижении лимита accept queue ACK пакет удаленного хоста просто отбрасывается или отправляется RST (в зависимости от значения переменной sysctl net.ipv4.tcp_abort_on_overflow).
Наш агент снимает текущее и максимальное значение accept queue для всех listen сокетов на сервере.
Для этих метрик есть график и преднастроенный триггер, который уведомит, если backlog любого сервиса использован более чем на 90%:
Счетчики и ошибки протоколов
Однажды сайт одного из наших клиентов подвергся DDOS атаке, в мониторинге было видно только увеличение трафика на сетевом интерфейсе, но мы не показывали абсолютно никаких метрик по содержанию этого трафика.
В данный момент однозначного ответа на этот вопрос окметр дать по-прежнему не может, так как сниффинг мы только начали осваивать, но мы немного продвинулись в этом вопросе.
Попробуем что-то понять про эти выбросы входящего трафика:
Теперь мы видим, что это входящий UDP трафик, но здесь не видно первых из трех выбросов.
Дело в том, что счетчики пакетов по протоколам в linux увеличиваются только в случае успешной обработки пакета.
Попробуем посмотреть на ошибки:
А вот и наш первый пик — ошибки UDP:NoPorts (количество датаграмм, пришедших на UPD порты, которые никто не слушает)
Данный пример мы эмулировали с помощью iperf, и в первый заход не включили на сервер-приемщик пакетов на нужном порту.
TCP ретрансмиты
Отдельно мы показываем количество TCP ретрансмитов (повторных отправок TCP сегментов).
Само по себе наличие ретрансмитов не означает, что в вашей сети есть потери пакетов.
Повторная передача сегмента осуществляется, если передающий узел не получил от принимающего подтверждение (ACK) в течении определенного времени (RTO).
Данный таймаут расчитывается динамически на основе замеров времени передачи данных между конкретными хостами (RTT) для того, чтобы обеспечивать гарантированную передачу данных при сохранении минимальных задержек.
На практике количество ретрансмитов обычно коррелирует с нагрузкой на серверы и важно смотреть не на абсолютное значение, а на различные аномалии:
На данном графике мы видим 2 выброса ретрансмитов, в это же время процессы postgres утилизировали CPU данного сервера:
Cчетчики протоколов мы получаем из /proc/net/snmp.
Conntrack
Еще одна распространенная проблема — переполнение таблицы ip_conntrack в linux (используется iptables), в этом случае linux начинает просто отбрасывать пакеты.
Это видно по сообщению в dmesg:
Агент автоматически снимает текущий размер данной таблицы и лимит с серверов, использующих ip_conntrack.
В окметре так же есть автоматический триггер, который уведомит, если таблица ip_conntrack заполнена более чем на 90%:
На данном графике видно, что таблица переполнялась, лимит подняли и больше он не достигался.
Вместо заключения
Примеры наших стандартных графиков можно посмотреть в нашем демо-проекте.
Там же можно постмотреть графики Netstat.
Большие потоки трафика и Linux: прерывания, маршрутизатор и NAT-сервер
В нашей городской сети более 30 тысяч абонентов. Суммарный объем внешних каналов — более 3 гигабит. А советы, данные в упомянутой статье, мы проходили еще несколько лет назад. Таким образом, я хочу шире раскрыть тему и поделиться с читателями своими наработками в рамках затрагиваемого вопроса.
В заметке описываются нюансы настройки/тюнинга маршрутизатора и NAT-сервера под управлением Linux, а также приведены некоторые уточнения по поводу распределения прерываний.
Прерывания
Раскидывание прерываний сетевых карт по разным ядрам — это самое первое, с чем сталкивается сисадмин при возрастании нагрузки на linux-маршрутизатор. В упомянутой статье тема освещена достаточно подробно — поэтому надолго останавливаться на этом вопросе мы не будем.
Хочу только отметить:
Маршрутизатор
В первоначальной статье есть фраза «если сервер работает только маршрутизатором, то тюнинг TCP стека особого значения не имеет». Это утверждение в корне неверно. Конечно, на небольших потоках тюнинг не играет большой роли. Однако, если у вас большая сеть и соответствующая нагрузка — то тюнингом сетевого стека вам придется заняться.
Прежде всего, если по вашей сети «гуляют» гигабиты, то имеет смысл обратить свое внимание на MTU на ваших серверах и коммутаторах. В двух словах, MTU — это объем пакета, который можно передать по сети, не прибегая к его фрагментации. Т.е. сколько информации ваш один маршрутизатор может передать другому без фрагментирования. При значительном увеличении объемов передаваемых по сети данных, гораздо эффективнее передавать пакеты большего объема реже, — чем часто-часто пересылать мелкие пакеты данных.
Увеличиваем MTU на linux
/sbin/ifconfig eth0 mtu 9000
Увеличиваем MTU на коммутаторах
На коммутационном оборудовании обычно это будет называться jumbo-frame. В частности, для Cisco Catalyst 3750
3750(config)# system mtu jumbo 9000
3750(config)# exit
3750# reload
Заметьте: коммутатор затем надо перезагрузить. Кстати, mtu jumbo касаются только гигабитных линков, — 100-мбит такая команда не затрагивает.
Увеличиваем очередь передачи на linux
/sbin/ifconfig eth0 txqueuelen 10000
По умолчанию значение стоит 1000. Для гигабитных линков рекомендуется ставить 10000. В двух словах, это размер буфера передачи. Когда буфер наполняется до этого граничного значения, данные передаются в сеть.
Имейте ввиду, что если вы меняете размер MTU на интерфейсе какой-то железки — вы должны сделать то же самое и на интерфейсе её «соседа». Т.е., если вы увеличили MTU до 9000 на интерфейсе linux-роутера, то вы должны включить jumbo-frame на порту коммутатора, в который данный роутер включен. В противном случае сеть работать будет, но очень плохо: пакеты ходить по сети будут «через одного».
Итоги
В результате всех этих изменений, в сети возрастут «пинги» — но общая пропускная способность заметно возрастет, а нагрузка на активное оборудование снизится.
Сервер NAT
Операция NAT (Network Address Translation) является одной из самых дорогостоящих (в смысле, ресурсоёмких). Поэтому, если у вас большая сеть, без тюнинга NAT-сервера вам не обойтись.
Увеличение кол-ва отслеживаемых соединений
Для осуществления своей задачи, NAT-серверу необходимо «помнить» обо всех соединениях, которые через него проходят. Будь то «пинг» или чья-то «аська» — все эти сессии NAT-сервер «помнит» и отслеживает у себя в памяти в специальной таблице. Когда сессия закрывается, информация о ней из таблицы удаляется. Размер этой таблицы фиксирован. Именно поэтому если трафика через сервер идет достаточно много, а размера таблицы нехватает, — то NAT-сервер начинает «дропать» пакеты, рвать сессии, интернет начинает работать с жуткими перебоями, а на сам NAT-сервер бывает даже попасть по SSH становится просто невозможно.
Чтобы таких ужасов не происходило, необходимо адекватно увеличивать размер таблицы — в соответствии с проходящим через NAT трафиком:
Настоятельно НЕ рекомендуется ставить такое большое значение, если у вас на NAT-сервере меньше 1 гигабайта оперативной памяти.
Посмотреть текущее значение можно вот так:
Посмотреть, насколько уже заполнена таблица отслеживания соединений, можно вот так:
Увеличение размера hash-таблицы
Пропорционально должная быть увеличена и хэш-таблица, в которой хранятся списки conntrack-записей.
echo 65536 > /sys/module/nf_conntrack/parameters/hashsize
Правило простое: hashsize = nf_conntrack_max / 8
Уменьшение значений time-out
Как вы помниите, NAT-сервер отслеживает только «живые» сессии, которые через него проходят. Когда сессия закрывается — информация о ней удаляется, дабы таблица не переполнялась. Информация о сессиях удаляется так же по тайм-ауту. Т.е., если втечение долгого времени в рамках соединения обмена траифка нет — оно закрывается и информация о нем так же удаляется из памяти NAT-а.
Однако, по умолчанию значения тайм-аутов стоят достаточно большие. Поэтому, при больших потоках трафика даже если вы растянете nf_conntrack_max до предела — вы все равно рискуете быстро столкнуться с переполнением таблицы и разрывами соединений.
Чтобы такого не произошло, необходимо грамотно выставить тайм-ауты отслеживания соединений на NAT-сервере.
Текущие значения можно посмотреть, например, так:
В результате вы увидите что-то подобное:
net.netfilter.nf_conntrack_generic_timeout = 600
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_established = 432000
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close = 10
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 180
net.netfilter.nf_conntrack_icmp_timeout = 30
net.netfilter.nf_conntrack_events_retry_timeout = 15
Это значения тайм-аутов в секундах. Как вы видите, значение net.netfilter.nf_conntrack_generic_timeout равно 600 (10 минут). Т.е. NAT-сервер будет держать в памяти информацию о сессии до тех пор, пока по ней будет «пробегать» хоть что-то хотя бы раз в 10 минут.
На первый взгляд, ничего страшного — но на самом деле это очень и очень много.
Если вы посмотрите на net.netfilter.nf_conntrack_tcp_timeout_established — то вы увидите там значение 432000. Другими словами, простую TCP-сессию ваш NAT-сервер будет отслеживать до тех пор, пока по ней не пробегает какой-нибудь пакетик хотя бы раз в 5 дней(!).
Говоря еще более простым языком, за-DDOS’ить такой NAT-сервер становится проще простого: его NAT-таблица (параметр nf_conntrack_max) переполняется «на ура» простейшим флудом — вследствие чего он будет рвать соединения и в худшем варианте быстро превратится в черную дыру.
Значения тайм-аутов рекомендуется ставить в пределах 30-120 секунд. Этого вполне достаточно для нормальной работы абонентов, и этого вполне хватит для своевременной очистки NAT-таблицы, исключающей её переполнение.
И не забудьте вписать соответствующие изменения в /etc/rc.local и /etc/sysctl.conf
Итоги
После тюнинга вы получите вполне жизнеспособный и производительный NAT-сервер. Конечно же, это только «базовый» тюнинг — мы не касались, например, тюнинга ядра и т.п. вещей. Однако, в большинстве случаев даже таких простых действий будет достаточно для нормальной работы достаточно большой сети. Как я уже говорил, в нашей сети более 30 тыс. абонентов, трафик которых обрабатывают 4 NAT-сервера.
Блог о системном администрировании. Статьи о Linux, Windows, СХД NetApp и виртуализации.
 Доброго времени, читатели и гости моего блога. C этой статьи начну серию статей о подсистеме Netfilter/iptables в Linux. В данной статье приведу основные понятия работы netfilter в Linux. Для понимания данной темы, обязательно советую ознакомиться со статьями Основные понятия сетей, Настройка сети в Linux, диагностика и мониторинг и Настройка и управление сетевой подсистемой Linux (iproute2).
Доброго времени, читатели и гости моего блога. C этой статьи начну серию статей о подсистеме Netfilter/iptables в Linux. В данной статье приведу основные понятия работы netfilter в Linux. Для понимания данной темы, обязательно советую ознакомиться со статьями Основные понятия сетей, Настройка сети в Linux, диагностика и мониторинг и Настройка и управление сетевой подсистемой Linux (iproute2).
Введение и история
Архитектура Netfilter/iptables
Предварительные требования ( с )
Как уже говорилось выше, для работы Netfilter необходимо ядро версии 2.6 (ну или хотя бы 2.3.15). Кроме того, при сборке и настройке ядра необходимо наличие настроек CONFIG_NETFILTER, CONFIG_IP_NF_IPTABLES, CONFIG_IP_NF_FILTER (таблица filter), CONFIG_IP_NF_NAT (таблица nat), CONFIG_BRIDGE_NETFILTER, а также многочисленные дополнительные модули: CONFIG_IP_NF_CONNTRACK (отслеживание соединений), CONFIG_IP_NF_FTP (вспомогательный модуль для отслеживания FTP соединений), CONFIG_IP_NF_MATCH_* (дополнительные типы шаблонов соответствия пакетов: LIMIT, MAC, MARK, MULTIPORT, TOS, TCPMSS, STATE, UNCLEAN, OWNER), CONFIG_IP_NF_TARGET_* (дополнительные действия в правилах: REJECT, MASQUERADE, REDIRECT, LOG, TCPMSS), CONFIG_IP_NF_COMPAT_IPCHAINS для совместимости с ipchains, CONFIG_BRIDGE_NF_EBTABLES и CONFIG_BRIDGE_EBT_* для работы в режиме моста, прочие CONFIG_IP_NF_* и CONFIG_IP6_NF_*. Полезно также указать CONFIG_PACKET.
Схема работы
Для начального понимания архитектуры Netfilter/iptables отлично подойдет иллюстрация из википедии, которую я несколько модифицировал для большей прозрачности и понимания материала:
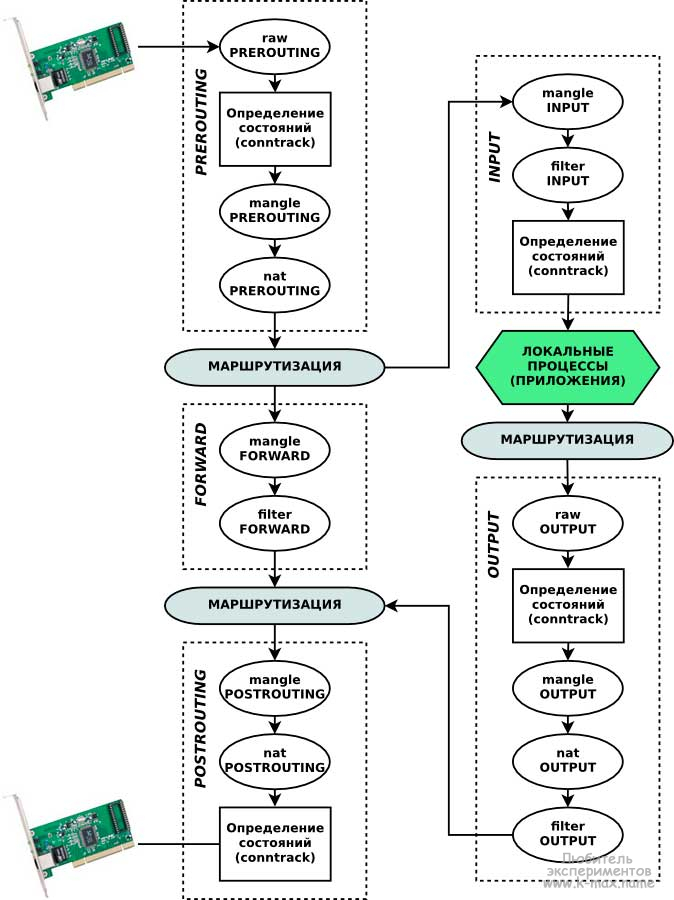
Ахтунг, ниже в трех абзацах изложена основная мысль статьи и принцип работы сетевого фильтра, поэтому желательно вчитаться как можно внимательнее!
Каждая цепочка, которую проходит пакет состоит из набора таблиц (table) (обозначены овалами). Таблицы в разных цепочках имеют одинаковое наименование, но тем не менее никак между собой не связаны. Например таблица nat в цепочке PREROUTING никак не связана с таблицей nat в цепочке POSTROUTING. Каждая таблица состоит из упорядоченного набора (списка) правил. Каждое правило содержит условие, которому должен соответствовать проходящий пакет и действия к пакету, подходящему данному условию.
Очень часто о таблицах и цепочках говорят в плоскости «таблицы содержат в себе наборы цепочек», но я считаю, что это неудобно и непонятно.
Цепочки netfilter:
Цепочки организованны в 4 таблицы:
Как я уже отметил, непосредственно для фильтрации пакетов используются таблицЫ filter. Поэтому в рамках данной темы важно понимать, что для пакетов, предназначенных данному узлу необходимо модифицировать таблицу filter цепочки INPUT, для проходящих пакетов — цепочки FORWARD, для пакетов, созданных данным узлом — OUTPUT.
Примеры прохождения цепочек
Последовательность обработки входящего пакета, предназначенного для локального процесса:
Последовательность обработки пакета, уходящего с нашего хоста:
Последовательность обработки проходящего пакета (начинается от п.2 первой процедуры):
Как видно, таблица nat и mangle может модифицировать получателя или отправителя сетевого пакета. Именно поэтому сетевой пакет несколько раз сверяется с таблицей маршрутизации.
Механизм определения состояний (conntrack)
Выше в тексте несколько раз указывалось понятие «определение состояний», оно заслуживает отдельной темы для обсуждения, но тем не менее я кратко затрону данный вопрос в текущем посте. В общем, механизм определения состояний (он же state machine, он же connection tracking, он же conntrack) является частью пакетного фильтра и позволяет определить определить к какому соединению/сеансу принадлежит пакет. Conntrack анализирует состояние всех пакетов, кроме тех, которые помечены как NOTRACK в таблице raw. На основе этого состояния определяется принадлежит пакет новому соединению (состояние NEW), уже установленному соединению (состояние ESTABLISHED), дополнительному к уже существующему (RELATED), либо к «другому» (неопределяемому) соединению (состояние INVALID). Состояние пакета определяется на основе анализа заголовков передаваемого TCP-пакета. Модуль conntrack позволяет реализовать межсетевой экран сеансового уровня (пятого уровня модели OSI). Для управления данным механизмом используется утилита conntrack, а так же параметр утилиты iptables: -m conntrack или -m state (устарел). Состояния текущих соединений conntrack хранит в ядре. Их можно просмотреть в файле /proc/net/nf_conntrack (или /proc/net/ip_conntrack).
Чтобы мысли не превратились в кашу, думаю данной краткой информации для понимания дальнейшего материала будет достаточно.
Управление правилами сетевой фильтрации Netfilter (использование команды iptables)
В общем случае формат команды следующий:
Ниже приведены команды и параметры утилиты iptables:
Критерии (параметры) отбора сетевых пакетов команды iptables
Критерии отбора сетевых пакетов негласно делятся на несколько групп: Общие критерии, Неявные критерии, Явные критерии. Общие критерии допустимо употреблять в любых правилах, они не зависят от типа протокола и не требуют подгрузки модулей расширения. Неявные критерии (я бы из назвал необщие), те критерии, которые подгружаются неявно и становятся доступны, например при указании общего критерия —protocol tcp|udp|icmp. Перед использованием Явных критериев, необходимо подключить дополнительное расширение (это своеобразные плагины для netfilter). Дополнительные расширения подгружаются с помощью параметра -m или —match. Так, например, если мы собираемся использовать критерии state, то мы должны явно указать это в строке правила: -m state левее используемого критерия. Отличие между явными и неявными необщими критериями заключается в том, что явные нужно подгружать явно, а неявные подгружаются автоматически.
Ниже в виде таблицы приведены часто используемые параметры отбора пакетов:
Состояние соединения. Доступные опции:
Действия над пакетами
Данный заголовок правильнее будет перефразировать в «Действия над пакетами, которые совпали с критериями отбора«. Итак, для совершения какого-либо действия над пакетами, необходимо задать ключ -j (—jump) и указать, какое конкретно действие совершить.
Действия над пакетами могут принимать следующие значения:
Кроме указанных действий, существуют и другие, с которыми можно ознакомиться в документации (возможно, в скором времени я дополню статью в ходе освоения темы). У некоторых действий есть дополнительные параметры.
В таблице ниже приведены примеры и описания дополнительных параметров:
На этом закончим теорию о сетевом фильтре netfilter/iptables. В следующей статье я приведу практические примеры для усвоения данной теории.
Резюме
В данной статье мы рассмотрели очень кратко основные понятия сетевого фильтра в Linux. Итак, подсистема netfilter/iptables является частью ядра Linux и используется для организации различных схем фильтрации и манипуляции с сетевыми пакетами. При этом, каждый пакет проходит от сетевого интерфейса, в который он прибыл и далее по определенному маршруту цепочек, в зависимости от того, предназначен он локальной системе или «нелокальной». Каждая цепочка состоит из набора таблиц, содержащих последовательный набор правил. Каждое правило состоит из определенного критерия/критериев отбора сетевого пакета и какого-то действия с пакетом, соответствующего данным критериям. В соответствии с заданными правилами над пакетом может быть совершено какое-либо действие (Например, передача следующей/другой цепочке, сброс пакета, модификация содержимого или заголовков и др.). Каждая цепочка и каждая таблица имеет свое назначение, функциональность и место в пути следования пакета. Например для фильтрации пакетов используется таблица filter, которая содержится в трех стандартных цепочках и может содержаться в цепочках, заданных пользователем. Завершается путь пакета либо в выходящем сетевом интерфейсе, либо доставкой локальному процессу/приложению.
Литература
Довольно много интересной информации на русском содержится тут:



