Технологии современных процессоров Intel
Введение
В этой статье будут рассмотрены лишь самые основные технологии, применяющиеся в процессорах Intel, которые сильнее всего влияют на их производительность и об использовании которых хорошо известно. Надо отметить, что здесь не будут рассмотрены чипы до 2009 года, так как те чипы на данный момент устарели и ценность представляют лишь самые мощные решения того времени.
Все мы знаем, что в разных линейках процессоров применяются разные технологии, также это зависит от позиционирования модели и ее цены. Посмотреть наличие основных технологий в линейках процессоров Intel можно в этой статье. Там нет про серверные чипы, но будьте уверены, что они достаточно технологичны. А если интересно узнать про интегрированную графику от Intel, то у нас для этого есть отдельная статья. Про технологии AMD можно прочесть по ссылке.
Вы спросите: «А как узнать о наличии тех или иных технологий в моем процессоре?». Для этого нужно зайти сюда и найти нужный вам процессор. После этого ищите вот эти поля.
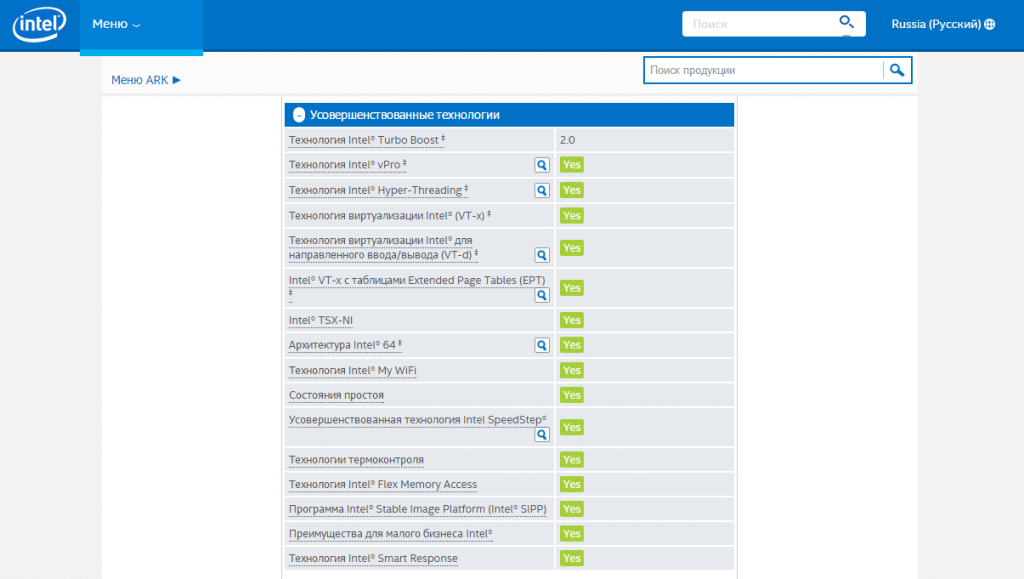
Turbo Boost
Эта технология позволяет автоматически увеличить тактовую частоту процессора свыше номинальной (саморазгон), что позволяет увеличить производительность чипа на некоторое время.
В основном это используется для повышения производительности в однопоточных приложениях или плохо оптимизированных под многпоточность, где производительность одного ядра важнее их количества. В таком случае нагрузка снимается в других ядер и освобожденная мощность уходит на некоторую часто ядер. В другом случае эта технология просто позволяет на время поднять производительность чипа за счет повышения тактовой частоты.

Значение этого саморазгона зависит от множества факторов:
Технология Turbo Boost 1.0 применялась в процессорах Nehalem и Westmere. Далее стала применяться чуть усовершенствованная версия Turbo Boost 2.0. Все отличия выглядят так.
| Признак | 1.0 версия | 2.0 версия |
|---|---|---|
| Шаг множителя | 133 Мгц | 100 Мгц |
| TDP | не превышает | на короткое время превышает |
Также стоит отметить более плавное повышение величины разгона с уменьшением числа активных ядер у 2.0 версии. Вторая версия в первые несколько секунд после долгого простоя повышает тактовую частоту выше, чем она должна быть для нормального TDP, но из-за немгновенного прогрева чипа это не критично. Затем же разгон скидывается до не превышающего TDP уровня. Похожий алгоритм можно увидеть в NVIDA GPU Boost 2.0, про которую можно посмотреть тут.
Особенно большим Turbo Boost может быть у мобильных процессоров, например в Intel Core M.
Интересный факт: у модели Intel Core m7-6Y75 максимальный Turbo Boost составляет c 1,2 Ггц до 3,1 Ггц!
Hyper-Threading
Или по-другому гиперпоточность. Из-за этой технологии операционная система определяет одно физическое ядро, как два логических и в соответствии с этим отдает команды. Так получается, что одно ядро работает в 2 потока. Гиперпоточность позволяет таким образом загрузить блоки процессора находящиеся в простое и увеличить его эффективность.
Надо отметить, что два логических ядра проигрывают двум физическим, что хорошо демонстрирует превосходство Core i5 (4 ядра без HT) над Core i3 (2 ядра с HT). Но одно физическое ядро c Hyper-Threading будет производительнее, чем без него, и это видно на примере Core i7 (4 ядра c HT) и Core i5 (4 ядра без HT).
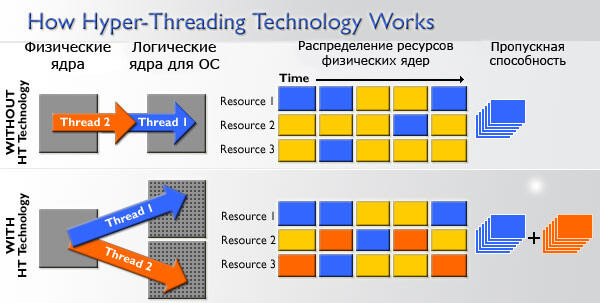
Особенно хорошо эта технология будет помогать в приложениях, умеющих хорошо распараллеливать процессы на различные потоки.
Burst
Эта технология применяется в мобильных процессорах Intel Atom (про то, как выбрать мобильный процессор можете прочесть по ссылке), а также в версиях Celeron/Pentium для мобильных устройств. Эта технология очень схожа с Turbo Boost. Она также повышает таковую выше номинальной, если выполняются некоторые условия.
Здесь также есть две версии этой технологии. Только во второй обмен мощностью может быть и с дисплеем, и c графическим чипом, и с системой обработки изображения с камеры, а не только с процессорными ядрами.

SpeedStep
Это такая технология энергосбережения, призванная динамически менять тактовую частоту и напряжение питания в зависимости от нагрузки. Ведь зачем процессору работать на полную, если нагрузки никакой нет? Энергопотребление процессора приблизительно прямо пропорционально зависит от его частоты. Это значит, что снизив частоту в 2 раза, мы снизим в 2 раза и энергопотребление. Также снизится и тепловыделение и, следовательно шум от кулера. А от напряжения энергопотребление зависит во второй степени. Это уже значит, что снизив напряжение питания в 2 раза, мы снизим энергопотребление в 4 раза! Но, к сожалению менять напряжение так сильно нельзя и даже слабое изменение питания может сделать работу невозможной. В основном это снижение происходит в состоянии очень низкой загрузки при помощи функции Enhanced Halt State (или C1E). Так что львиная доля экономится за счет снижения тактовой частоты.
У этой технологии есть несколько версий: SpeedStep, SpeedStep II и SpeedStep III, но мы не будем заострять на этом внимание, будет достаточно и описания. Можно лишь упомянуть, что представлена она была в далеком 2001 в процессоре Mobile Pentium III.
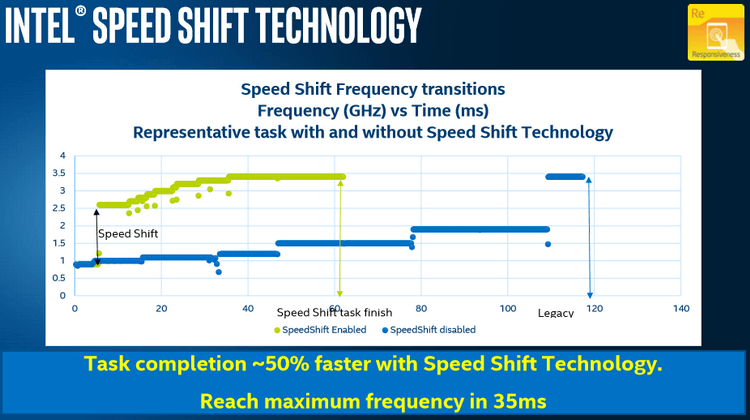
Speed Shift
Эта технология является продолжением развития SpeedStep. Она работает эффективнее и быстрее реагирует на повышение нагрузки. Это значит, что она процессор быстрее достигает нужной тактовой частоты и быстрее справляется с задачей. Speed Shift может работать только в процессорах, начиная с поколения Skylake, так как реализована аппаратно. Также она должна поддерживаться операционной системой и на данный момент с этим уже справляется Windows 10.
Также более усовершенствованная версия данной технологии была представлена в Intel Kaby Lake.
Intel Quick Sync Video

Это технология Intel, предназначенная для аппаратного ускорения кодирования и декодирования видео. В этом случае в графическом ядре есть специальная интегральная схема, предназначенная для этого. Благодаря этого эта технология справляется со своей задачей лучше, чем видеокарты – и быстрее, и более энергоэффективно, ведь в видеокарте нет блоков, предназначенных специально для этой функции. Но, как и в случае с другими технологиями для аппаратного кодирования/декодирования видео, качество обработки хуже, чем в случае выполнения этой задачей при помощи процессора.
Существует две версии этой технологии. Первая было представлена вместе с микроархитектурой Sandy Bridge в 2011 году. Вторая версия увидела свет в в 2012 году при выходе Ivy Bridge. Вторая версия движка имела несколько изменений, например улучшенный медиасемплер, позволивших ей заметно улучшить скорость работы, качество видео, а также получить поддержку высоких разрешений. Существенный недостаток технологии выходит из того, что она встроена в графическое ядро процессора – ее функционирование невозможно, когда в компьютере основной является дискретный видеоадаптер.
Extreme Memory Profile (XMP)
Эта технология позволяет пользовать заранее сделанными профилями разгона оперативной памяти. Это может пригодиться, если вы не хотите рисковать. Так вы просто берете нужный вам профиль и не беспокоитесь о его работоспособности. Профиль выбирается в BIOS. Для этого оперативная память должна быть сертифицированной.
InTru3D
Это такой стандарт для 3D-контента, разработанный Intel и DreamWorks. И, что вполне логично, этот стандарт хорошо функционирует на современных процессорах Intel. Подробнее можно посмотреть здесь.
High Definition Audio
Это такой набор требований, предъявляемый к интегрированным в процессор аудиокодекам, который призван улучшить качество цифрового звука. Это касается как увеличения числа каналов, так и и разрядности с частотой дискретизации.
Intel vPro
Эта технология позволяет получать доступ к ПК дистанционно. Вкратце, эта технология позволяет IT-специалистам получить доступ к ПК для устранения неполадок в них и защиты. Она работает на базе ядра и на ее функционирование не влияют состояние питания и операционной системы.
Она базируется на двух других технологиях Intel:
Не будем подробно рассказывать о средствах реализации этих технологий. Об этом вы можете подробнее прочесть здесь.
Intel Authenticate
Эта технология реализована на базе Intel vPro 6-го поколения, и представляет собой многофакторную аутентификацию корпоративного класса, что позволяет улучшить защиту личных данных. Здесь используются несколько разных факторов для проверки личности. Можно и PIN-код, и телефон и отпечаток пальца. Методы проверки выбирает само предприятие в зависимости от условий. Эта технология использует все ключи и связанные с ними сертификаты, шифрует их, сопоставляет и хранит в памяти аппаратной части, что держит их в безопасности от основной массы атак.
Intel Smart Cache
Это технология по использованию общей L2/L3-памяти (кэш-память второго/третьего уровня), что позволяет снизить энергопотребление и повысить производительность. Стоит отметь, что при динамическом отключении ядер другие ядра получают больше кэша.
Заключение
Здесь не были затронуты все технологии Intel. Здесь лишь были оговорены наиболее известные и больше всего влияющие на производительность. Также были затронуты технологии для корпоративного сегмента, но, довольно, вскользь. Если возникли какие-то вопросы, то сначала советуем вам заглянуть в раздел «Введение», где написаны границы применимости данной статьи. Надеемся, что эта статья помогла вам в выборе процессора от Intel и вы разобрались в том, что дают процессору различные технологии.
Intel smart cache что это
реклама
Прежде всего, приведём содержание слайда, повествующего о технологии Smart Cache, впервые применяемой в процессорах Intel. Как известно, оба ядра в процессоре Yonah будут использовать общий разделяемый кэш второго уровня объёмом 2 Мб. Именно применяемые в этом кэше технологии и объединены под вывеской «Smart Cache».
Как уже сообщалось, данные из кэша будут доступны в полном объёме даже в том случае, если одно из ядер будет отключено. Если учесть, что в целях экономии электроэнергии одно из ядер будет регулярно «засыпать» или отключаться, «бесперебойный» режим работы кэша очень важен. Проходящий через общую шину трафик данных тоже сокращается за счёт возможности обращения обоих ядер к одной порции данных.
Улучшенные механизмы предварительной выборки и более глубокие буферы записи тоже приводят к повышению производительности кэша. Механизм управления разделяемой шиной при этом оптимизирует потоки при работе в одноядерном и двухъядерном режимах. Наконец, специальный буфер адаптирует пропускную способность к режиму работы процессора: при активности двух ядер пропускная способность шины удваивается.
В целом, кэш процессора Yonah используется более эффективно и интеллектуально, оптимизация алгоритма работы кэша и шины позволяют повысить производительность и «скорость реакции», а также снизить затраты энергии.
Приводят коллеги с скриншот процессора Yonah, работающего на частоте 1.46 ГГц. Большой информативностью скриншот CPU-Z версии 1.29 не отличается. Мы видим, что присутствуют два ядра, в режиме простоя они работают на частоте 1.0 ГГц, предусмотрена поддержка расширений SSE3. Собственно говоря, и точное название ядра утилита пока воспроизвести не в силах. Заметим, что серийные процессоры Yonah будут работать на частотах от 1.67 до 2.13 ГГц и поддерживать 667 МГц, так что демонстрируемый образец не отражает всех возможностей будущих решений этого семейства.
Как влияет объем кэш-памяти на производительность в играх? Intel Skylake: 3 MB vs 8 MB Cache
Приветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?

Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop.ua 2-ядерный процессор Intel Core i3-6100 с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный Intel Core i7-6700K, у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.


Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.

Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта MSI GeForce GTX 1070 GAMING X 8G и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.

Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.

Arma 3 имеет хорошо выраженную процессорозависимость, а значит больший объем кэш-памяти должен сыграть свою позитивную роль даже при ультравысоких настройках графики. Тем более что нагрузка на видеокарту в обоих случаях достигала максимум 60%.

Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.

Завершает мини-серию живых геймплеев Evolve Stage 2. Здесь мы наверняка увидели бы разницу между системами, поскольку в обоих случаях видеокарта загружена ориентировочно на половину. Поэтому субъективно кажется, что уровень FPS в случае Core i7 выше, но однозначно сказать нельзя, поскольку сцены не идентичные.

Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе – до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.

Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.

Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.




Интересная ситуация получилась и с Rainbow Six Siege: на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.
Секрет высокой производительности Intel Core 2 Duo: микроархитектура Core
Процессор Conroe, выход которого планируется в самом ближайшем будущем, можно отнести, пожалуй, к числу самых ожидаемых новинок этого года. В настоящее время Conroe, который станет первым десктопным носителем новой микроархитектуры Core, разработанной израильской командой инженеров Intel (авторству которой принадлежит и весьма успешный Pentium M), представляется панацеей чуть ли не от всех бед, нажитых Intel в течение последних шести лет. Теперь уже даже у самых ярых сторонников Intel не вызывает сомнений тот факт, что микроархитектура NetBurst, впервые представленная в конце 2000 года, не оправдала возложенных на неё ожиданий. Итогом её использования компанией Intel в основе процессоров для настольного сегмента рынка стало значительное сокращение популярности продуктов компании, в особенности на розничном рынке. Потребители процессоров так и не смогли смириться с целым набором слабых мест, присущих процессорам семейств Pentium 4 и Pentium D, включающим невысокую производительность, запредельное тепловыделение и энергопотребление.
Но Intel учится на своих ошибках. В начале этого года было объявлено о кардинальной смене подхода к оптимизации потребительских качеств будущих CPU компании. От простой погони за максимальной производительностью Intel переходит к постановке во главу угла такого параметра, как соотношение быстродействия и энергопотребления. Именно с этих позиций инженеры Intel и создавали новую Core Microarchitecture (первоначальный вариант названия – Next Generation Microarchitecture), которая легла в основу процессоров Conroe.
Хочется заметить, что ряд критически настроенных обозревателей достаточно язвительно раскритиковал Intel за несколько непривычную постановку исходной задачи. Ведь с точки зрения соотношения производительности и энергопотребления чрезвычайно эффективными могут быть и экстраэкономичные процессоры, не обладающие приемлемым уровнем быстродействия. Однако не следует воспринимать всё слишком буквально. Меняя свои приоритеты, инженеры Intel указывают в первую очередь на тот факт, что теперь, помимо увеличения скорости CPU, они будут обращать самое пристальное внимание и на энергопотребление, которое объявлено не менее важной характеристикой конечного продукта.
Именно поэтому не следует думать, что основным преимуществом процессоров, построенных на базе микроархитектуры Core, станет их низкое тепловыделение и энергопотребление. На самом деле, инженеры приложили немало усилий и к увеличению производительности процессоров. Как демонстрируют предварительные тесты, Conroe имеет все шансы стать одним из самых быстрых CPU для настольных компьютеров. Это как раз и подогревает к нему и без того немалый интерес. Весьма вероятно, что появление на рынке процессоров Conroe сможет подвинуть семейство Athlon 64 на второй план, переведя его, пусть на время, из высшей лиги в категорию продуктов лишь для бюджетных компьютеров и компьютеров среднего уровня.
реклама
Очевидно, что, в свете вышесказанного, знакомству с Conroe, да и вообще с микроархитектурой Core, необходимо уделить повышенное внимание. Перед тем, как мы получим возможность подробно познакомиться с результатами всесторонних тестовых испытаний, некоторое время следует уделить и материальной части. В этой статье мы постараемся раскрыть основные сильные стороны микроархитектуры Core, благодаря которым процессоры Conroe смогут похвастать высокой производительностью наряду с небольшим тепловыделением. Кроме того, мы ознакомимся с некоторыми предварительными данными о производительности этих процессоров и обобщим имеющуюся информацию об их модельном ряде.
Intel Core Microarchitecture: основы
Согласно хорошо известной формуле, популяризацию которой начала ещё компания AMD при вводе в обращение своего процессорного рейтинга, производительность определяется как произведение тактовой частоты процессора на величину, определяющую количество инструкций, исполняемых CPU за один такт. Таким образом, есть два основных пути для увеличения быстродействия: наращивание тактовых частот и увеличение числа инструкций, исполняемых за один такт. С первым параметром всё понятно, а второй – определяется внутренним строением процессора и зависит от количества таких функциональных узлов процессора, как декодеры инструкций и исполнительные блоки.
Кроме того, есть и ещё один метод для повышения скорости процессоров – уменьшение числа операций, необходимых для обработки одних и тех же объёмов данных. Хорошей иллюстрацией прогресса в этом направлении можно считать внедрение наборов SIMD инструкций SSE, SSE2 и SSE3, позволяющих «одним махом» выполнять векторные операции.
Что же касается энергопотребления, то оно представляется как произведение тактовой частоты процессора, квадрата напряжения, при котором функционирует процессорное ядро, и некой константы «динамическая ёмкость», определяемой микроархитектурой CPU, и зависящей от числа транзисторов и их активности во время работы процессора.
В результате заключаем, что для оптимизации микроархитектуры с точки зрения соотношения производительности и энергопотребления разработчики должны фокусироваться в первую очередь на установлении баланса между количеством инструкций, исполняемых процессором за такт, и динамической ёмкостью. Напряжение питания ядра, также оказывающее влияние на соотношение производительности и энергопотребления, мало зависит от микроархитектуры и определяется, главным образом, технологическим процессом. Тактовая же частота, как показывают приведённые выкладки, на рассматриваемое соотношение вообще не влияет. Под влиянием этих идей и разрабатывалась микроархитектура Core.
Исходя из сформулированных требований, в качестве основы для будущих процессоров инженеры Intel выбрали, не NetBurst (что совершенно неудивительно), а существующую микроархитектуру мобильных процессоров, которые, являясь дальнейшим развитием Pentium Pro, Pentium II и Pentium III, обладают достаточно высоким уровнем быстродействия при хорошей экономичности. Впрочем, при этом новая микроархитектура Core содержит значительные усовершенствования, направленные как на увеличение производительности и расширение функциональности, так и на снижение энергопотребления. Соответственно, говорить о том, что перспективные процессоры станут адаптированными (с учётом новой сферы применения) Pentium M, было бы абсолютно неверно.
Судить об этом можно опираясь на простое перечисление основных формальных характеристик микроархитектуры Core. Например, процессоры, базирующиеся на Intel Core Microarchitecture, смогут обрабатывать до четырёх инструкций за такт, в чём они будут превосходить всех своих предшественников, включая и CPU на базе микроархитектуры NetBurst. Таким образом, теоретически, при одинаковой тактовой частоте будущие процессоры Intel смогут опережать в скорости работы все современные CPU, включая и текущие конкурирующие предложения AMD. Длина исполнительного конвейера процессоров с микроархитектурой Core составит 14 стадий. Это значит, что частоты будущих CPU будут определённо ниже, чем у Pentium 4 и Pentium D, длина конвейера у которых превышает 30 стадий. Но с точки зрения «производительности на ватт» короткий конвейер является скорее плюсом, чем минусом.
реклама
Что же касается более конкретных деталей, то первые процессоры, входящие в Intel Core Microarchitecture, будут иметь двухъядерный дизайн (выполненный на едином полупроводниковом кристалле), обладать кеш-памятью первого уровня объёмом 64 Кбайта (которая будет разделяться на две части по 32 Кбайта для кода и данных) и комплектоваться общей (разделяемой) на оба ядра кеш-памятью второго уровня объёмом 2 или 4 Мбайта. Чрезвычайно важно отметить, что процессоры с микроархитектурой Core будут обладать поддержкой 64-битных расширений Enhanced Memory 64 Technology (EM64T). Это существенное отличие новой микроархитектуры от микроархитектуры процессоров Pentium M, которые, как и более современные их последователи Core Duo, 64-битные режимы работы не поддерживают в силу заложенных в них ограничений.
Особенности микроархитектуры Core таковы, что она позволяет создание процессоров с различными характеристиками, нацеленными на всевозможные сегменты рынка. Как утверждают разработчики, искусственное уменьшение предельного энергопотребления процессоров с будущей микроархитектурой в два раза требует лишь 15-процентного снижения максимальной тактовой частоты. Благодаря этому свойству новая микроархитектура даст одновременный старт трём параллельным семействам процессоров: для мобильного рынка, настольных систем и серверов.
Процессоры с новой микроархитектурой для ноутбуков, получившие кодовое имя Merom, будут выпускаться исходя из их требуемого типичного тепловыделения, не превышающего 35 Ватт. Это позволит при сохранении того же, как и у мобильных компьютеров на базе современных процессоров Intel Core Duo, времени работы от аккумулятора, достичь более чем 20-процентного прироста в производительности.
Серверные варианты процессоров, названные кодовым именем Woodcrest, по сравнению с доступными в настоящее время двухъядерными CPU линейки Xeon, получат 80-процентный прирост в быстродействии, а их типичное энергопотребление снизится примерно на 35% и составит около 80 Вт.
Что же касается процессоров для «настольного» сегмента рынка, то им присвоено кодовое имя Conroe. По прогнозам рост производительности Conroe по сравнению со старшими моделями линейки Pentium D 9XX составит около 40%. При этом типичное энергопотребление упадёт примерно на такую же величину. В результате, энергопотребление будущих процессоров для настольных компьютеров (исключая модели, нацеленные на энтузиастов) будет лежать в пределах 65 Вт.
Приведённые данные по производительности и энергопотреблению выглядят весьма впечатляюще. Однако в то, что на такое способны процессоры, в основе которых лежит микроархитектура Pentium M, верится с трудом. Поэтому, чтобы развеять ненужные сомнения, самое время поговорить о том, какие же микроархитектурные инновации внесены в Intel Core Microarchitecture.
Основные усовершенствования
Intel Wide Dynamic Execution
Первое упоминание термина Dynamic Execution (динамическое исполнение) относится к процессорам Pentium Pro, Pentium II и Pentium III. Говоря о динамическом исполнении команд в этих процессорах, Intel подразумевал принципиально новую суперскалярную микроархитектуру P6, способную выполнять анализ потока кода, и обладающую возможностями спекулятивного (упреждающего) и внеочередного исполнения команд. При переводе процессоров для настольных компьютеров на микроархитектуру NetBurst, Intel стал говорить уже об усовершенствованном динамическом исполнении, которое, помимо перечисленных выше свойств, обладало более глубоким уровнем анализа кода и значительно улучшенными алгоритмами предсказания переходов.
Теперь же, в новой микроархитектуре Core, речь идёт о «широком» динамическом исполнении. Широким оно стало благодаря тому, что будущие процессоры Intel смогут исполнять больше операций за такт, нежели их предшественники. Благодаря добавлению в каждое ядро дополнительного декодера и исполнительных устройств, каждое из ядер будущих процессоров сможет выбирать из программного кода и исполнять до четырёх x86 инструкций одновременно, в то время как остальные процессоры AMD и Intel (как «настольные», так и мобильные), могут обрабатывать не более трёх инструкций за такт. На четыре декодера (один для сложных инструкций и три – для простых) микроархитектура Core предполагает наличие шести портов запуска (один – Load, два – Store и три универсальных). Кроме того, микроархитектура Core получила более совершенный блок предсказания переходов и более вместительные буферы команд, используемые на различных этапах анализа кода для оптимизации скорости исполнения.
Следует напомнить, что предшественники микроархитектуры Core, процессоры Pentium M, обладали чрезвычайно интересной технологией micro-ops fusion, направленной на снижение «накладных расходов» при выполнении некоторых x86 команд. Суть технологии micro-ops fusion чрезвычайно проста. В случае если x86 команда распадается на зависимые друг от друга микроинструкции, декодер осуществляет их привязку друг к другу. Такие последовательности микроинструкций, «склеенные» технологией micro-ops fusion для исполнения процессором в определённом порядке, представляются процессором на всех этапах, кроме собственно исполнения, одной командой. Это позволяет избежать ненужных простоев процессора в случае, если связанные микроинструкции оказываются оторванными друг от друга в результате работы алгоритмов внеочередного выполнения.
В дополнение к весьма удачной технологии micro-ops fusion, микроархитектура Core получила технологию macrofusion. Данная технология направлена на увеличение числа исполняемых за такт команд и заключается в том, что ряд пар связанных между собой последовательных x86 инструкций, таких как, например, сравнение со следующим за ним условным переходом, представляются внутри процессора одной микроинструкцией. Такая микроинструкция рассматривается планировщиком и выполняется на исполнительных устройствах как одна команда. Таким путём достигается как увеличение темпа исполнения кода, так и некоторая экономия энергии.
Intel Advanced Digital Media Boost
реклама
Отдельным направлением, по которому выполнялось совершенствование микроархитектуры Core, стала переработка блоков исполнения SIMD инструкций (SSE, SSE2, SSE3). Современное программное обеспечение, например, для обработки изображений, видео и звука, шифрования, научной и финансовой деятельности, достаточно широко использует наборы команд SSE, которые позволяют работать со 128-битовыми операндами различного характера (векторами и целочисленными либо вещественночисленными данными повышенной точности).
Именно этот факт заставил инженеров Intel задуматься об ускорении работы SSE блоков процессора, тем более что до настоящего времени процессоры Intel исполняют одну SSE-инструкцию, работающую с 128-битными операндами, лишь за два такта. Один такт тратился на обработку старших 64 бит, второй такт – на обработку младших. Новая же микроархитектура Core позволит ускорить работу с SSE инструкциями в два раза. Блоки SSE в будущих процессорах будут полностью 128-битовыми, что даёт возможность увеличить количество данных, обрабатываемых процессором за такт. И особенно в тех задачах, которые используют SIMD инструкции наиболее активно, а это, в первую очередь, различного рода мультимедиа-приложения.
Помимо увеличения скорости работы блоков исполнения SIMD инструкций, Intel в очередной раз провёл ревизию системы команд SSE. Результатом стало то, что уже ставший привычным набор инструкций SSE3 будет вновь дополнен восемью новыми командами. Вообще говоря, указанное расширение набора команд SSE3 задумывалось ещё при внедрении процессоров с кодовым именем Tejas, но в силу их отмены соответствующая модификация нашла своё место в микроархитектуре Core.
Intel Advanced Smart Cache
реклама
Поскольку микроархитектура Core изначально проектируется в двухъядерном варианте, разработчики получили возможность оптимизировать отдельные функциональные блоки будущих процессоров с учётом их этой особенности. Так, в отличие от доступных в настоящее время CPU для настольных компьютеров, процессоры с микроархитектурой Core получат разделяемый между вычислительными ядрами L2 кеш. Алгоритмы работы этой кеш-памяти во многом подобны тем механизмам, которые реализованы в настоящее время в двухъядерных мобильных процессорах Intel Core Duo.
Плюсов такого подхода к реализации кеш-памяти видится несколько. Во-первых, у процессора появляется возможность гибко регулировать размеры областей кеша, используемых каждым из ядер. Иными словами, доступ ко всему объёму L2 кеша может получить любое из ядер процессора с микроархитектурой Core. Это, в частности, значит и то, что когда одно из ядер бездействует, второе получает в своё полное распоряжение весь объём кеш-памяти. Если же одновременно работают два процессорных ядра, то кеш делится между ними пропорционально, в зависимости от частоты обращений каждого ядра к оперативной памяти. Более того, если оба ядра работают синхронно с одними и теми же данными, то хранятся они в общем L2 кеше только однократно. То есть, разделяемый интеллектуальный L2 кеш процессоров с микроархитектурой Core гораздо более эффективен и, даже можно сказать, более вместителен, чем два отдельных кеша, разделённых между ядрами.
Разделяемая кеш-память может оказаться полезной двухъядерным процессорам и в некоторых других случаях. Например, идущие в настоящие время разговоры о технологии Core Multiplexing Technology указывают на то, что инженеры Intel готовы представить на суд общественности механизм динамического отключения второго ядра, в зависимости от характера нагрузки на процессор. Очевидно, что в этом случае единый на два ядра кеш второго уровня способен решить массу проблем с технической реализацией этой технологии.
Второй значительный плюс объединённой кеш-памяти второго уровня заключается в том, что благодаря такой его организации значительно снижается нагрузка на оперативную память системы и на процессорную шину. Дело в том, что в этом случае перед системой не стоит задача контроля и обеспечения когерентности кеш-памяти различных ядер. В системах с двухъядерными процессорами с раздельными кешами, в случае, если оба ядра работают с одними и теми же данными, эти данные дублируются в кеш-памяти каждого из ядер. Таким образом, возникает необходимость в контроле их актуальности. Перед тем, как извлечь такие данные из L2 кеша для обработки, каждое процессорное ядро должно проверить, не изменило ли эти данные другое ядро. И если это так, то требуется обновление содержимого кеш-памяти, которое в системах на базе процессоров с микроархитектурой NetBurst выполняется через системную шину и оперативную память. Общий же на два ядра кеш позволяет полностью отказаться от этого неэффективного алгоритма.
реклама
Кроме того, посредством управляющей логики, предусмотренной в процессорах с микроархитектурой Core, станет возможным более простой обмен данными и между кеш-памятью первого уровня каждого из ядер через общий L2 кеш, что в итоге даст возможность гораздо более результативного взаимодействия ядер при совместной работе над одной задачей.
Intel Smart Memory Access
Технологии, объединенные под этим собирательным названием, направлены на уменьшение задержек, которые могут возникнуть при доступе процессора к обрабатываемым данным. Очевидно, что для этой цели как нельзя лучше подходит предварительная выборка данных из памяти в обладающие гораздо более низкой латентностью L1 и L2 кеши процессора. Надо сказать, что алгоритмы предварительной выборки данных эксплуатируются в процессорах Intel достаточно давно. Однако с выходом микроархитектуры Core соответствующий функциональный узел будет усовершенствован.
Микроархитектура Core предполагает реализацию в процессоре шести независимых блоков предварительной выборки данных. Два блока нагружаются задачей предварительной выборки данных из памяти в общий L2 кеш, ещё по два блока работают с кешами первого уровня каждого из ядер CPU. Каждый из этих блоков независимо друг от друга отслеживает закономерные обращения (потоковые, либо с постоянным шагом внутри массива) исполнительных устройств к данным. Базируясь на собранной статистике, блоки предварительной выборки стремятся подгружать данные из памяти в процессорный кеш ещё до того, как к ним последует обращение.
Также, L1 кеш каждого из ядер процессоров, построенных на базе Intel Core Microarchitecture, имеет по одному блоку предварительной выборки инструкций, работающий по аналогичному принципу.
реклама
Кроме улучшенной предварительной выборки данных, Intel Smart Access предполагает ещё одну интересную технологию, названную memory disambiguation (устранение противоречий в памяти). Данная технология направлена на повышение эффективности работы алгоритмов внеочередного исполнения инструкций, осуществляющих чтение и запись данных в памяти. Дело в том, что в современных процессорах, осуществляющих внеочередное исполнение команд, не допускается выполнение команды чтения до того, как не будут завершены все инструкции сохранения данных. Объясняется это тем, что планировщик заранее не обладает информацией о зависимости загружаемых и сохраняемых данных.
Однако достаточно часто последовательные инструкции сохранения и загрузки данных из памяти не имеют между собой никакой взаимной зависимости. Поэтому, отсутствие возможности изменения порядка их выполнения зачастую снижает загрузку исполнительных устройств и эффективность работы CPU в целом. Для решения этой проблемы и предусматривается новая технология memory disambiguation. Она предусматривает специальные алгоритмы, позволяющие с достаточно высокой вероятностью устанавливать зависимость последовательных команд сохранения и загрузки данных, и даёт возможность, таким образом, применять внеочередное выполнение инструкций к этим командам.
Таким образом, при условии правильной работы алгоритмов memory disambiguation процессор получает возможность более эффективного использования собственных исполнительных устройств. В случаях же ошибок в определении зависимых инструкций загрузки и сохранения данных, которые, согласно информации разработчиков, случаются достаточно редко, технология memory disambiguation детектирует возникший конфликт, перезагружает корректные данные и инициирует повторное исполнение «ошибочно» выполненной ветви кода.
Совместное использование предварительной выборки данных и технологии memory disambiguation повышает эффективность работы процессора с памятью не только за счёт минимизации возможных простоев исполнительных устройств, но и благодаря более эффективному использованию пропускной способности шины и снижению латентностей при обращениях к памяти.
реклама
Intel Intelligent Power Capability
Так как при разработке новой микроархитектуры Core инженеры стремились к оптимизации параметра «производительность на ватт», а также из-за того, что данная микроархитектура будет использоваться и в основе процессоров для ноутбуков, разработчики Intel сразу предусмотрели набор технологий, направленных на снижение энергопотребления и тепловыделения. Безусловно, будущие процессоры получат в своё распоряжение хорошо зарекомендовавшие себя технологии семейства Demand Based Switching (в первую очередь, Enhanced Intel SpeedStep и Enhanced Halt State). Но речь в данном случае идёт не о них.
Процессоры, основанные на микроархитектуре Core, получат возможность интерактивного отключения тех собственных подсистем, которые не используются в данный момент. Причём речь в данном случае идёт не о ядрах целиком. Декомпозиция процессора на отдельные функциональные узлы выполнена на гораздо более низком уровне. Каждое из процессорных ядер поделено на большое количество блоков и внутренних шин, питание которыми управляется раздельно посредством специализированных дополнительных логических схем. Главной особенностью этих схем, входящих в Intel Intelligent Power Capability, является то, что их работа не влечёт за собой увеличение времени отклика процессора на внешние воздействия, вызванное необходимостью приводить отключенные блоки в функциональное состояние.
Следует отметить, что возможность деактивации различных блоков CPU во время его работы заставило разработчиков пересмотреть подход к измерению температуры процессора. Процессоры с микроархитектурой Core будут снабжаться несколькими температурными датчиками, расположенными на ядре в тех местах, которые предрасположены к сильному нагреву. Для обработки показаний этих многочисленных датчиков процессор будет содержать специальную схему, определяющую максимальную температуру. Именно эта температура и будет рапортоваться процессором пользователю и системам аппаратного мониторинга.
реклама
Краткое сравнение микроархитектур: Intel Core и AMD K8
Естественно, основными соперниками для процессоров, построенных на базе микроархитетуры Core, выступят современные процессоры AMD, базирующиеся на микроархитектуре K8. Ведь именно эти процессоры следует считать самыми прогрессивными на данный момент. Давайте посмотрим с теоретических позиций, как смотрится новая микроархитектура Intel на фоне старой доброй микроархитектуры AMD.
| Intel Core | AMD K8 | |
| L1 кеш данных | 32 Кбайта | 64 Кбайта |
| L1 кеш инструкций | 32 Кбайта | 64 Кбайта |
| Латентность кеша L1 | 3 цикла | 3 цикла |
| Ассоциативность L1 кеша | 8-way | 2-way |
| Размер L1 TLB | Инструкции – 128 вхождений | Инструкции – 32 вхождения |
| Данные – 256 вхождений | Данные – 32 вхождения | |
| Максимальный размер L2 кеша | 4 Мбайта на два ядра | 1 Мбайт на каждое ядро |
| Латентность кеша L2 | 14 циклов | 12 циклов |
| Ассоциативность L2 кеша | 16-way | 16-way |
| Ширина шины L2 кеша | 256 бит | 128 бит |
| Размер L2 TLB | — | 512 вхождений |
| Длина конвейера | 14 стадий | 12 стадий |
| Число x86 декодеров | 1 сложный и 3 простых | 3 сложных |
| Целочисленные исполнительные устройства | 3 ALU + 2 AGU | 3 ALU + 3AGU |
| Load/Store устройства | 2 (1 Load + 1 Store) | 2 |
| FP исполнительные устройства | FADD + FMUL + FLOAD + FSTORE | FADD + FMUL + FSTORE |
| SSE исполнительные устройства | 3 (128-битные) | 3 (64-битные) |
Из приведённой таблицы ясно уже многое. А самое главное, это то, что процессоры с микроархитектурой Core имеют более «широкую» архитектуру, позволяющую выполнять больше инструкций за такт, нежели процессоры с микроархитектурой K8. Хотя исполнительные устройства процессоров с обеими конкурирующими архитектурами способны выполнять до трёх целочисленных x86 и x87 команд за такт, микроархитектура Core должна продемонстрировать подавляющее преимущество на SSE операциях. В то время как процессоры K8 могут совершать за один такт лишь одну или две 128-битные команды, Core может выполнить до трёх таких команд.
Кроме того, преимущество микроархитектуры Core кроется в гораздо более совершенной системе декодирования кода. Вместе с тем, что число декодеров в этом процессоре доведено до четырёх, применение технологии macrofusion может позволить обеспечить декодирование до пяти инструкций за такт (в идеальном случае). Процессоры же конкурента не способны на декодирование более трёх инструкций одновременно. Всё это позволяет говорить о том, что декодеры процессоров с микроархитектурой Core смогут более полно загружать исполнительные устройства этого процессора, выполняя в наиболее благоприятных для процессора условиях до четырёх команд за такт и превышая общий темп исполнения команд процессорами с микроархитектурой K8 на 33%.
К этому остаётся добавить и более эффективные алгоритмы работы с данными, присутствующие в процессорах семейства Core. Преимущества этой микроархитектуры заметны в первую очередь при рассмотрении системы кеширования данных. L1 кеш Core, хотя и имеет меньший размер, но может похвастать более высокой степенью ассоциативности. А L2 кеш просто имеет больший объём и более высокую пропускную способность. При этом разделяемое строение кеш-памяти второго уровня способно также получить дополнительные преимущества при многопоточной нагрузке.
Важным дополнением алгоритмов предварительной выборки данных, присутствующих в процессорах, построенных на основе микроархитектуры Core, следует считать и не имеющую аналогов в процессорах конкурента технологию memory disambiguation, позволяющую считать будущие процессоры Intel более out-of-order (внеочередными с точки зрения кода).
Фактически, единственным остающимся после появления микроархитектуры Core неоспоримым преимуществом AMD K8 следует считать лишь интегрированный контроллер памяти, который, несомненно, способен обеспечить более низкую латентность при работе с данными. Однако хватит ли этого AMD, чтобы бороться с будущими процессорами Conroe – очень большой вопрос, на который нам ещё предстоит найти ответ. Впрочем, в любом случае инженеры AMD не планируют сидеть, сложа руки. В будущих ядрах процессоров Athlon 64, запланированных на начало 2008 года, проектируются определённые улучшения, которые направлены на ликвидацию узких мест архитектуры. Однако это – тема отдельной статьи.
Микроархитектура Core для десктопов: процессоры Core 2 Duo
После рассмотрения основных особенностей микроархитектуры Core с теоретических позиций, самое время посмотреть на то, что мы получим на практике применительно к настольным компьютерам.
Процессоры Conroe, представляющие собой десктопное воплощение Core Microarchitecture, будут анонсированы в последних числах июля. Официальное название процессоров Conroe, под которым они начнут покорять рынок, звучит как Core 2 Duo. Очевидно, что такое имя подчёркивает принадлежность этих CPU к новой прогрессивной микроархитектуре.
Надо заметить, что Intel планирует достаточно агрессивный запуск продаж новых процессоров, дабы анонс Core 2 Duo не был награждён обидным эпитетом «бумажного» в преддверии активизации продаж, вызванных наступлением сезона «back-to-school». В день анонса не только ведущие партнёры Intel объявят о доступности решений, основанных на новой микроархитектуре, но и продвинутые пользователи смогут найти долгожданные процессоры в магазинах. Сомневаться в возможностях Intel выдержать намеченные ранее сроки вряд ли стоит: к настоящему времени компания располагает достаточно большим количеством образцов, которые свидетельствуют об отсутствии архитектурных и производственных препятствий на пути Conroe на рынок. Тем более что процессоры Conroe будут производиться с использованием хорошо отлаженного технологического процесса P1264 с нормами 65 нм. То есть, на базе того же самого техпроцесса, который уже давно используется для производства процессоров.
Первые представители линейки процессоров Core 2 Duo, с которыми нам предстоит столкнуться, будут обладать разделяемой между ядрами кеш-памятью второго уровня объёмом 2 или 4 Мбайта. При этом на первом этапе их тактовые частоты будут начинаться на отметке 1.86 ГГц и достигать в старших моделях 2.93 ГГц. В дальнейшем, по мере завоевания рынка, тактовые частоты линейки будут расширены в обе стороны.
Процессоры с микроархитектурой Core будут использовать процессорную шину Quad Pumped Bus, которая уже доказала свою эффективность во всех секторах рынка. Для процессоров Core 2 Duo частота этой шины, по крайней мере, на первых порах, будет установлена в 1067 МГц. Приятно, что использование старой шины заставило Intel отказаться от экспериментов с процессорной упаковкой. Conroe, также как и современные модели Pentium 4 и Pentium D, будут выпускаться в LGA775 обличии.
Однако сохранение старого типа упаковки не означает совместимости со старыми материнскими платами. Для поддержки Core 2 Duo от системных плат будет требоваться не только возможность тактования фронтальной шины на частоте 1067 МГц. Кроме этого материнские платы для новых процессоров должны использовать иной модуль регулирования напряжения (VRM 11). Поэтому, для придания совместимости с Core 2 Duo производителям придётся выпускать обновлённые материнские платы, в основе которых могут лежать чипсеты Intel 975X Express, Intel P965 Express, NVIDIA nForce 5XX Intel Edition или ATI Xpress 3200 Intel Edition.
Рейтинг моделей процессоров Core 2 Duo будет формироваться по тем же принципам, что и рейтинг мобильных процессоров линейки Core Duo. Для новой линейки он будет выглядеть как EXXXX, где лидирующая литера E указывает на предназначенность процессора к семейству продуктов для использования в настольных системах, а следующее за ней четырёхзначное число является отображением уровня производительности и технологической «продвинутости» продукта.
Следует отметить, что линейка Core 2 Duo будет расширена и моделью процессора «Extreme Edition». Такой CPU будет называться Core 2 Extreme и его рейтинг будет иметь вид XXXXX. Основным отличием Core 2 Extreme от Core 2 Duo (помимо экстремально высокой цены) станет повышенная тактовая частота.
Полностью линейка процессоров Conroe на начальный момент будет иметь следующий вид:
Предварительное тестирование производительности
То, что от новых процессоров с микроархитектурой Core можно ожидать многого, сомнению не подвергается. Однако, для того, чтобы получить хотя бы примерное представление о том, каким окажется уровень производительности Core 2 Duo, нужны практические испытания. К счастью, в наших руках оказался один из многочисленных инженерных образцов процессора Core 2 Duo, благодаря которому мы можем представить вашему вниманию предварительные тесты носителя новой микроархитектуры Intel.
Для тестов нам достался процессор Core 2 Duo E6600, работающий на частоте 2.4 ГГц и оснащённый L2 кеш-памятью объёмом 4 Mбайта.
Процессор, оказавшийся в наших руках, имел номер степпинга B0, соответственно, это лишь инженерный экземпляр. Серийные процессоры Conroe, которые появятся в продаже через месяц, будут иметь более новый степпинг ядра. Поэтому, приводимые нами результаты тестов носят статус предварительных, строить окончательные выводы, базируясь на них, пока нельзя.
Для испытаний процессора нами была выбрана материнская плата Intel D975XBX Bad Axe, которая, начиная с номера ревизии 304, имеет совместимый с Core 2 Duo стабилизатор питания CPU.
Итак, тестовые системы, принимавшие участие в экспериментах, были построены на базе следующего оборудования:
Тестирование выполнялась при настройках BIOS Setup материнских плат, установленных на максимальную производительность.
Заметим, что для сравнения с перспективным процессором Intel Core 2 Duo мы сознательно использовали процессоры AMD, работающие в новой платформе Socket AM2. Использование именно этих CPU даёт возможность получить на платформе от AMD максимальную производительность, при условии применения быстрой DDR2-800 SDRAM. Поэтому, можно говорить о том, что для AMD весь потенциал для увеличения быстродействия уже исчерпан, улучшения результатов процессоров этого производителя в ближайшее время ждать не откуда.
Переходим непосредственно к результатам тестов. В первую очередь – простенькие однопоточные бенчмарки, популярные в оверклокерской среде:



