Работа с элементами страницы в JavaScript
Учебник JavaScript
Практика
Работа с DOM
Практика
Некоторые продвинутые вещи
Рекомендованное ES6
Некоторые видео могут забегать вперед, тк к этому месту учебника мы прошли еще не весь ES6. Просто пропускайте такие видео, посмотрите потом.
Регулярки
Разное
Работа с канвасом
Практика
Контекст
Drag-and-Drop
Практика по ООП
Ваша задача: посмотрите, попробуйте повторить.
Практика
Promise ES6
Библиотека jQuery
Тк. jQuery устаревает, объявляю эти уроки не обязательными и выношу в конец учебника (так по уровню уроки середины учебника, если что). В перспективе переедет в отдельный учебник по jq.
В данном уроке мы разберем работу с элементами страницы на языке JavaScript.
Работа с innerHTML, outerHTML
В прошлом уроке мы с вами учились считывать и записывать значения атрибутов, а теперь будем делать тоже самое, но уже со внутренним содержимым тегов. Это делается с помощью свойства innerHTML, которое можно считывать и перезаписывать, меняя тем самым содержимое тегов.
HTML код станет выглядеть так:
Можно записывать не только текст, но и теги и они будут работать (в нашем случае текст станет жирным):
HTML код станет выглядеть так:
Кроме свойства innerHTML существует также свойство outerHTML, которое перезаписывает не только внутренний текст тега, но и сам тег. Смотрите пример:
HTML код станет выглядеть так:
Как вы видите, наш абзац исчез и заменился на тег b.
Работа с getElementsByTagName
Во всех примерах выше мы с вами работали с методом getElementById, который получал только одно свойство по его атрибуту id. Однако существуют и другие способы получения свойств, к примеру, с помощью метода getElementsByTagName, который получает группу тегов по их имени. Например, можно получить все абзацы p или все заголовки h2.
Давайте поменяем текст всех трех абзацев:
HTML код станет выглядеть так:
В следующем примере мы сменим содержимое всех абзацев на страницы на ‘!’, воспользовавшись для этого циклом for:
HTML код станет выглядеть так:
Обращение к свойствам через свойства document
В следующем примере первый alert выведет null:
Работа с формами
Можно получить все HTML формы на странице через document.forms. В результате мы получим массив форм, будто он был получен с помощью getElementsByTagName (точнее это будет не массив, а псевдомассив (или коллекция) свойств).
Мы можем, к примеру, обратиться к любой форме, как к энному свойству массива, например, к форме с номером 0:
HTML код станет выглядеть так:
А можем перебрать все формы с помощью цикла:
HTML код станет выглядеть так:
Кроме того, к формам можно обращаться по имени вместо номера. Это имя задается в атрибуте name тега
Получение и установка контента элементам в JavaScript

Свойство textContent и как оно работает
textContent – это свойство, которое предназначено для работы с текстовым контентом элемента. Оно позволяет его как получить (включая текстовое содержимое всего его потомков), так и установить.
Примеры с textContent
1. При получении текста элемента, содержащего один текстовый узел, textContent возвратит текст, находящийся внутри этого текстового узла.
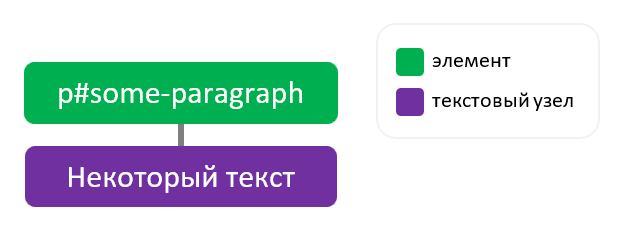
2. Для элемента, который содержит множество других узлов, textContent вернёт конкатенацию (сложение) текстов всех его текстовых узлов.
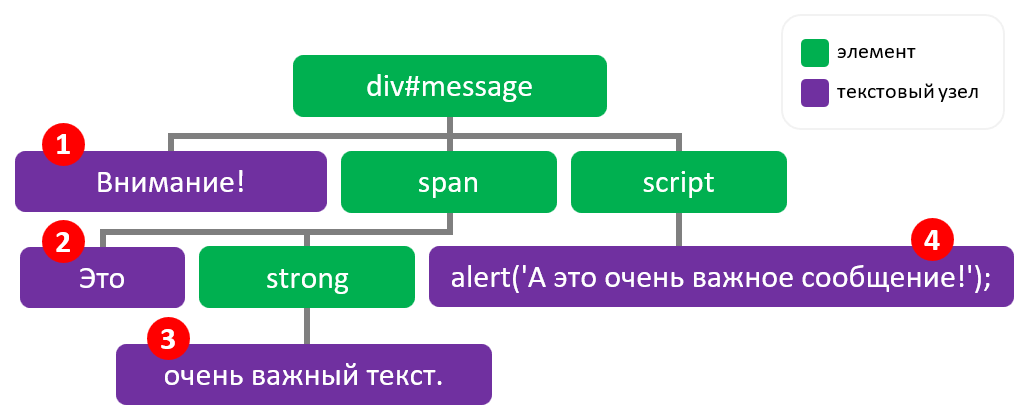
В этом примере текстовые узлы обозначены цифрами. textContent вернёт сложение текстов этих текстовых узлов.
При установке элементу текстового содержимого, textContent удалит всего его узлы (при их наличии), и добавит в него один текстовый узел, содержащий указанный текст.
4. Например, установим элементу #message новое текстовое содержимое:

5. Например, создадим элемент « div.alert », вставим в него некоторый текст и добавим его на страницу перед закрывающим тегом body :
innerText, outerText и их отличие от textContent
innerText также как textContent используется для извлечения текста из элементов.
При установке элементу текстового контента, innerText также как textContent удаляет все имеющиеся в нём узлы и создаёт новый текстовый узел с указанным содержимым.
Синтаксис свойства innerText :
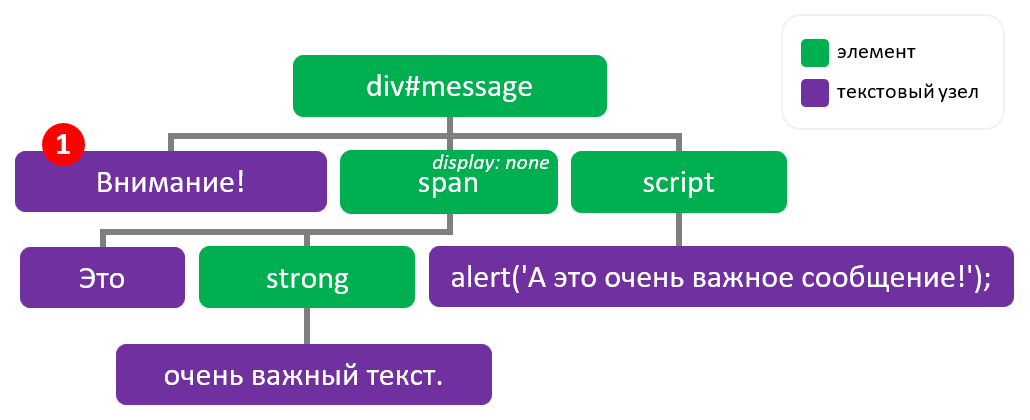
В этом примере мы ещё дополнительно удалим отображение элемента span из документа, т.е. установим ему « display: none »:
Таким образом innerText учитывает стили элементов, и возвращает только текст отображаемый этим элементом в браузере.
outerText
Синтаксис свойства outerText :
Его отличие от innerText только в том, что outerText при установки элементу текстового контента удаляет не только всё его содержимое, но и сам этот элемент и помещает на этом месте новый текстовый узел с заданным текстом.
innerHTML и outerHTML
innerHTML предназначен для установки или получения HTML разметки элемента.
Например, установим элементу ul#list новое HTML содержимое:
Пример, в котором получим HTML разметку некоторого элемента:
Задание HTML содержимого элементу с помощью innerHTML всегда сопровождается удалением его контента и установкой ему новой HTML разметки, но основе указанной строки, которая была разобрана внутренним парсером браузера как HTML.
Но на самом деле это не так. Этот код выполняет следующее:
Эквивалентная запись кода, приведённого выше:
Таким образом, используя такую запись мы не просто добавляем некоторый HTML в конец элемента, а полностью переустанавливаем его. Выполнение такого кода обычно сопровождается «миганием».
Пример использования innerHTML для очистки содержимого элемента:
Например, получить и изменить HTML контент элемента р с id=»myP» :


outerHTML
Свойство outerHTML устанавливает или возвращает HTML контент, представляющий сам элемент и его дочерние элементы.
innerHTML что такое как использовать примеры
Все эти вопросы об innerHTML мы рассмотрим на данной страницу.
Каким-то странным образом мы совсем упустили свойство innerHTML в javascript и если вы встречали наш сайт на просторах интернета. То вы знаете, нашу концепцию – минимум теории и максимум практики!
Всё о innerHTML javascript применение примеры использования
Что такое innerHTML!?
Какую часть элемента получает innerHTML схема:
Чтобы увидеть, какую часть получает innerHTML, вот вам картинка, innerHTML будет получать все, что выделено красным.
 Какую часть элемента получает innerHTML схема:
Какую часть элемента получает innerHTML схема:
Нужно понимать, что мы можем не только заменить данные с помощью innerHTML.
Нои проделать обратное действие получить данные внутри тега.
Самый простой пример использования innerHTML.
Использованный код в примере:
Алгоритм работы innerHTML
В качестве примеров рассмотрим следующие 3 алгоритма:
Получить данные с помощью innerHTML
И последнее : мы должны, что-то сделать с нашими полученными данными, например вывести их с помощью alert.
Чтобы передать данные с помощью innerHTML также существует алгоритм:
Как и в первом случае, мы должны обратиться к тегу в который будем отправлять данные.
И последнее : передаем данные с помощью innerHTML
Опять мы должны обратиться к тегу, ко всем тегам, которые нам нужны.
И последнее : одновременно получаем и передаем данные с помощью innerHTML
Получить содержимое блока с помощью innerHTML и вывести через alert!?
С теорией закончили… надеюсь, с вами произошло тоже самое, что и со мной!
Я ничего не понял! В этом пункте рассмотрим алгоритм №1.
Т.е.
В момент действия получаем данные innerHTML
Выведем полученные данные alert
Чтобы разобраться, нам потребуется пример использования innerHTML.
Пример получения данных с помощью innerHTML
Для этого нам понадобится какой-то блок, пусть это будет div, добавим id :
Чтобы мы его могли увидеть добавим в элемент id example, с бордюром и цветом.
Теперь, чтобы вы могли увидеть вживую работу innerHTML, напишем простой скрипт, использовали:
Теперь можно нажать на кнопку и получить данные с помощью innerHTML
Передать данные внутрь блока с помощью innerHTML.
Открыть их в двух окнах друг против дурга и сравнить и тогда будет понятно, о чем идет речь ниже!.
В момент действия передаем данные innerHTML
Получить данные с помощью innerHTML и передать в другой блок с помощью innerHTML
Открыть их в двух окнах друг против дурга и сравнить и тогда будет понятно, о чем идет речь ниже!.
В момент действия получим и передаем данные innerHTML
Возьмем предыдущий пункт, добавим еще один блок div:
Обратимся к нему также как и раньше через querySelector
И в функцию введем некоторые изменения:
А в другой блок будем полученное вставлять тоже через innerHTML:
Сообщение системы комментирования :
Форма пока доступна только админу. скоро все заработает. надеюсь.
Шпаргалка по JS-методам для работы с DOM

Основные источники
Введение
JavaScript предоставляет множество методов для работы с Document Object Model или сокращенно DOM (объектной моделью документа): одни из них являются более полезными, чем другие; одни используются часто, другие почти никогда; одни являются относительно новыми, другие признаны устаревшими.
Я постараюсь дать вам исчерпывающее представление об этих методах, а также покажу парочку полезных приемов, которые сделают вашу жизнь веб-разработчика немного легче.
Размышляя над подачей материала, я пришел к выводу, что оптимальным будет следование спецификациям с промежуточными и заключительными выводами, сопряженными с небольшими лирическими отступлениями.
Сильно погружаться в теорию мы не будем. Вместо этого, мы сосредоточимся на практической составляющей.
Для того, чтобы получить максимальную пользу от данной шпаргалки, пишите код вместе со мной и внимательно следите за тем, что происходит в консоли инструментов разработчика и на странице.
Вот как будет выглядеть наша начальная разметка:
У нас есть список ( ul ) с тремя элементами ( li ). Список и каждый элемент имеют идентификатор ( id ) и CSS-класс ( class ). id и class — это атрибуты элемента. Существует множество других атрибутов: одни из них являются глобальными, т.е. могут добавляться к любому элементу, другие — локальными, т.е. могут добавляться только к определенным элементам.
Мы часто будем выводить данные в консоль, поэтому создадим такую «утилиту»:
Миксин NonElementParentNode
Данный миксин предназначен для обработки (браузером) родительских узлов, которые не являются элементами.
В чем разница между узлами (nodes) и элементами (elements)? Если кратко, то «узлы» — это более общее понятие, чем «элементы». Узел может быть представлен элементом, текстом, комментарием и т.д. Элемент — это узел, представленный разметкой (HTML-тегами (открывающим и закрывающим) или, соответственно, одним тегом).
Небольшая оговорка: разумеется, мы могли бы создать список и элементы программным способом.
Для создания элементов используется метод createElement(tag) объекта Document :
Одним из основных способов получения элемента (точнее, ссылки на элемент) является метод getElementById(id) объекта Document :
Почему идентификаторы должны быть уникальными в пределах приложения (страницы)? Потому что элемент с id становится значением одноименного свойства глобального объекта window :
Миксин ParentNode
Данный миксин предназначен для обработки родительских элементов (предков), т.е. элементов, содержащих одного и более потомка (дочерних элементов).
Такая структура называется коллекцией HTML и представляет собой массивоподобный объект (псевдомассив). Существует еще одна похожая структура — список узлов (NodeList ).
Для дальнейших манипуляций нам потребуется периодически создавать новые элементы, поэтому создадим еще одну утилиту:
Наша утилита принимает 4 аргумента: идентификатор, текст, название тега и CSS-класс. 2 аргумента (тег и класс) имеют значения по умолчанию. Функция возвращает готовый к работе элемент. Впоследствии, мы реализуем более универсальный вариант данной утилиты.
Одной из интересных особенностей HTMLCollection является то, что она является «живой», т.е. элементы, возвращаемые по ссылке, и их количество обновляются автоматически. Однако, эту особенность нельзя использовать, например, для автоматического добавления обработчиков событий.
Создадим универсальную утилиту для получения элементов:
Наша утилита принимает 3 аргумента: CSS-селектор, родительский элемент и индикатор количества элементов (один или все). 2 аргумента (предок и индикатор) имеют значения по умолчанию. Функция возвращает либо один, либо все элементы (в виде обычного массива), совпадающие с селектором, в зависимости от значения индикатора:
Миксин NonDocumentTypeChildNode
Миксин ChildNode
Данный миксин предназначен для обработки дочерних элементов, т.е. элементов, являющихся потомками других элементов.
Интерфейс Node
Данный интерфейс предназначен для обработки узлов.
Интерфейс Document
Фрагменты позволяют избежать создания лишних элементов. Они часто используются при работе с разметкой, скрытой от пользователя с помощью тега template (метод cloneNode() возвращает DocumentFragment ).
createTextNode(data) — создает текст
createComment(data) — создает комментарий
importNode(existingNode, deep) — создает новый узел на основе существующего
Интерфейсы NodeIterator и TreeWalker
Интерфейсы NodeIterator и TreeWalker предназначены для обхода (traverse) деревьев узлов. Я не сталкивался с примерами их практического использования, поэтому ограничусь парочкой примеров:
Интерфейс Element
Данный интерфейс предназначен для обработки элементов.
Работа с classList
Работа с атрибутами
insertAdjacentElement(where, newElement) — универсальный метод для вставки новых элементов перед/в начало/в конец/после текущего элемента. Аргумент where определяет место вставки. Возможные значения:
insertAdjacentText(where, data) — универсальный метод для вставки текста
Text — конструктор для создания текста
Comment — конструктор для создания комментария
Объект Document
Свойства объекта location :
reload() — перезагружает текущую локацию
replace() — заменяет текущую локацию на новую
title — заголовок документа
head — метаданные документа
body — тело документа
images — псевдомассив ( HTMLCollection ), содержащий все изображения, имеющиеся в документе
Следующие методы и свойство считаются устаревшими:
Миксин InnerHTML
Геттер/сеттер innerHTML позволяет извлекать/записывать разметку в элемент. Для подготовки разметки удобно пользоваться шаблонными литералами:
Расширения интерфейса Element
Вот несколько полезных ссылок, с которых можно начать изучение этих замечательных инструментов:
Иногда требуется создать элемент на основе шаблонной строки. Как это можно сделать? Вот соответствующая утилита:
Существует более экзотический способ создания элемента на основе шаблонной строки. Он предполагает использование конструктора DOMParser() :
Еще более экзотический, но при этом самый короткий способ предполагает использование расширения для объекта Range — метода createContextualFragment() :
В завершение, как и обещал, универсальная утилита для создания элементов:
Заключение
Разумеется, шпаргалка — это всего лишь карманный справочник, памятка для быстрого восстановления забытого материала, предполагающая наличие определенного багажа знаний.
VDS от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
JavaScript | Чем отличается innerText от innerHTML?
На первых порах изучения JavaScript бывают непонятны отличительные черты некоторых свойств объектов. Например, в инструментах разработчика не всегда можно понять разницу между innerText и innerHTML. Такое бывает из-за одинакового строкового содержимого в этих свойствах у элемента.
Так в чём же различие?
innerText — показывает всё текстовое содержимое, которое не относится к синтаксису HTML. То есть любой текст, заключённый между открывающими и закрывающими тегами элемента будет записан в innerText. Причём если внутри innerText будут ещё какие-либо элементы HTML со своим содержимым, то он проигнорирует сами элементы и вернёт их внутренний текст.
innerHTML — покажет текстовую информацию ровно по одному элементу. В вывод попадёт и текст и разметка HTML-документа, которая может быть заключена между открывающими и закрывающими тегами основного элемента.
Видео
Примеры
У нас есть ненумерованный список бытовой техники с ценами. Информация оформлена в виде форматированного текста. Цена выделена жирным шрифтом. Внутри круглых скобок курсивом прописано полное название валюты, цвет текста — красный.
 4 пункта из списка
4 пункта из списка
Так выглядит HTML-код списка:
Давайте теперь посмотрим на различия в выводе innerText и innerHTML. Как мы будем это делать? Все операции будем писать напрямую в консоль браузера.
1. Для начала получим список всех элементов . (HTMLCollection — коллекция HTML)
 Получение массива HTML-элементов одного типа в JavaScript
Получение массива HTML-элементов одного типа в JavaScript
2. Потом будем обращаться к элементам HTML коллекции (в нашем случае объектам HTMLCollection) и выводить у них свойства innerText и innerHTML
innerText
 Вывод в консоль браузера свойство innerText
Вывод в консоль браузера свойство innerText
innerHTML
 Вывод в консоль браузера свойство innerText
Вывод в консоль браузера свойство innerText
В случае с innerHTML мы получаем «салат» в котором намешаны HTML-элементы и текстовое содержимое. Фактически это тоже строковый тип данных. Визуально воспринимать такое содержимое гораздо сложнее.
Вывод
Разные задачи требуют разных подходов в реализации алгоритмов. Для быстрой и наглядной информации лучше использовать innerText. Для получения качественных структур данных лучше использовать innerHTML.
Кем являются innerText и innerHTML на самом деле, когда мы говорим о JavaScript?
innerText и innerHTML являются свойствами объектов JavaScript, которые получают именование по стандарту DOM. Что это значит?
Когда мы получаем какой-либо элемент из документа, то он является самым обычным объектом JavaScript.
Приведу живой пример на реальном сайте. Давайте получим элемент какой-нибудь ссылки.
 HTML-элемент ссылки в разметке — электрогриль
HTML-элемент ссылки в разметке — электрогриль
Стандартная HTML-разметка нам проста и понятна:
Теперь давайте посмотрим как её видит JavaScript во всём документе
 Начальная часть свойств объекта ссылки — JavaScript
Начальная часть свойств объекта ссылки — JavaScript  Средняя часть свойств объекта ссылки — JavaScript
Средняя часть свойств объекта ссылки — JavaScript  Конечная часть свойств объекта ссылки — JavaScript
Конечная часть свойств объекта ссылки — JavaScript



