Как просмотреть таблицу стилей css, введенную расширением Google Chrome с помощью инструментов dev?
Я впрыскиваю файл css из моего расширения chrome с помощью манифеста.в JSON (полный текст):
в инструментах Chrome Dev, если я проверяю элемент, на который влияет введенный css, правила видны, но в правом верхнем углу, где обычно находится исходное имя файла, он просто говорит «injected stylesheet.»Я хотел бы просмотреть все вводимые правила, даже те, которые влияют на элементы, которые в настоящее время не существуют в DOM.
Edit: я только что обнаружил, что этот вопрос также появляется как «под-вопрос»этот, однако никто там не попытался ответить на него, хотя есть принятый ответ.
3 ответов
когда расширение находится под вашим контролем, Пол Айриш предлагает использовать этот шаблон кода, чтобы сделать ваши стили проверяемыми: https://github.com/lateral/chrome-extension-blogpost/compare/master. paulirish:master
для расширений других людей, насколько я могу судить, нет способа просмотреть исходный код из введенных таблиц стилей в DevTools, если вы идете content_scripts маршрут.
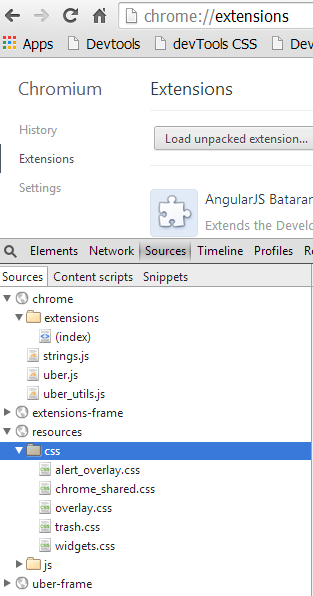
использовать следующий процесс:
перейдите на страницу расширения (chrome: / / extensions)
выберите Developer mode флажок
клик Inspect Views в тексте под соответствующим расширением
Приоритет и наследование в СSS на практике

По просьбам читателей сегодня я попытаюсь раскрыть такую важную тему в CSS, как приоритет и наследование. А так же вы узнаете о незаменимом помощнике в контексте сегодняшней темы, как для верстальщика, так и для front-end разработчика – веб-инспекторе.
О наследовании в CSS
Что нужно знать о наследовании в CSS при верстке сайтов? Рассмотрим это на примере фрагмента макета.
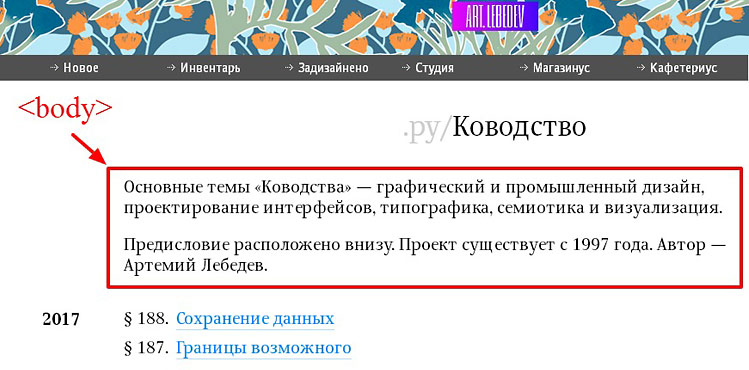
Верстальщик должен стремится не плодить лишний код, ведь для этого и существует принцип наследования. Верстка любой страницы начинается с тега body. Это значит, что мы прописываем цвет фона страницы и все атрибуты основного шрифта заранее в тег body (предок). То есть, все теги (p, div), что находятся внутри body, являются его потомками, они так же унаследуют белый фон и заданный шрифт, если мы не перебьем их другими свойствами.
Если для тега h1 зададим другие значения цвета и шрифта, в таком случае тег h1 уже не потомок body.
Здесь надо уточнить, что по наследству передаются главным образом цвет фона и все шрифтовые атрибуты. Нельзя унаследовать атрибуты ссылок, размеры отступов, полей, блоков.
О приоритетах в CSS
Приоритетность таблиц стилей в порядке возрастания для верстальщика:
В каких случаях надо писать стили внутри страницы? Если, эта страница уникальна по дизайну, отличается от остальных.
Это была теория, на практике же все выглядит куда понятнее. Очень часто верстальщику приходится разбираться в чужом коде. Например стоит такая задача – изменить цветовую гамму страницы или всего сайта. Если этот условный сайт сверстан вручную и достаточно грамотно, то найти какие из стилей применены к тому или иному тегу, легко. Просто следуя тем существующим правилам приоритета и наследования. Смотрите какие стили на странице расположены ниже или специфичнее (#id против .class) и совсем уже явно – это !important, те и будут главнее.
Сущий ад начинается, если сайт работает например на WordPress-е. Там столько всего намешано: несколько CSS внешних файлов (wp темы, bootstrap-а, плагинов woocommerce, jetpack, виджетов, шорткодов) и это не считая styles внутри страниц. Как же в такой каше разобраться?
Волшебный веб-инспектор
Прямо на ваших глазах я поменяю цвет заголовка h1 с черного на сиреневый. Разумеется, что эта замена произошла виртуально, только в вашем браузере. После обновления браузера, будет как раньше. Вот таким быстрым способом, можно не открывая фотошоп, подобрать цветовую гамму, затем скопировать прямо из веб-инспектора новый код и вставить в файл CSS стилей. Вопрос только в какой, если их там целая куча?
Давайте разбираться пошагово:
В нашем примере, это style.css темы WordPress-а. Это подтвердилось, тем, что мы щёлкнув по черному квадратику рядом с атрибутом color, выбрали другой цвет. Цвет изменился, значит файл стилей выбран верно.
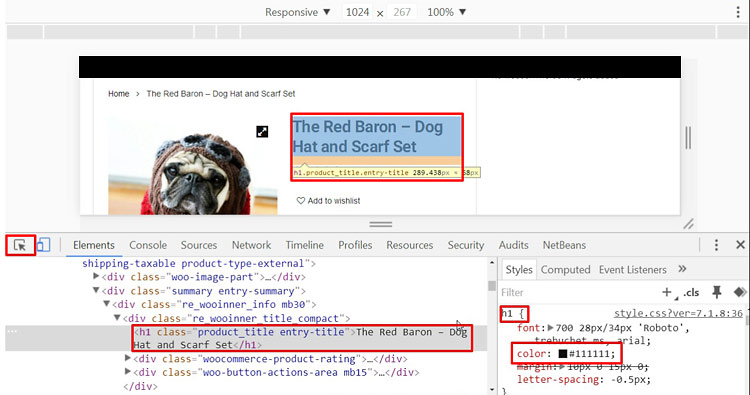
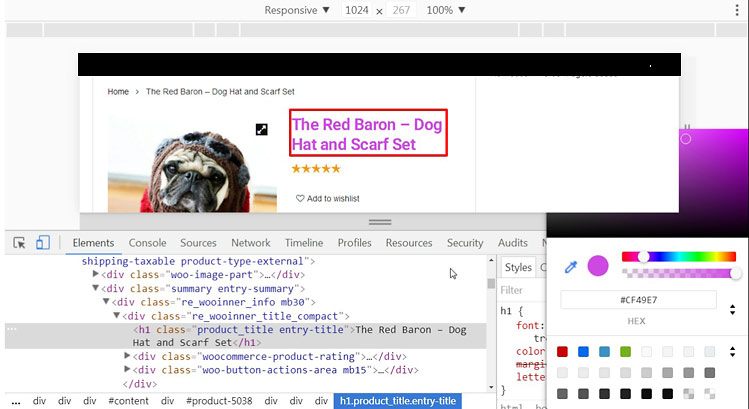
Вся правая часть вкладки Styles описывает только тег h1.
The Red Baron – Dog Hat and Scarf Set
В Styles отображаются все изменения, которые происходили с тегом h1. А вкладка Computed показывает – что в итоге осталось, окончательный вариант.
Как видите все не так страшно, при правке чужого кода, вам в помощь веб-инспектор. А когда вы сами верстаете с нуля, вы же двигаетесь поэтапно и сразу видите результат.

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Комментарии ( 3 ):
вы так всех новичков здесь напугаете, после прочтения вашего коммента, у них сложится впечатление, что авторы статей щадят их нервы, скрывая страшную правду о коварном CSS, который мучает даже могучего дядьку Гугла. Это была шутка :)). А если серьезно, то человек слишком практичен, чтобы ломать голову, над тем, что ему сейчас не нужно. По мере углубления в процесс обучения, возникнут и другие вопросы, ответы на которые, найдутся в сообществах.
Для добавления комментариев надо войти в систему.
Если Вы ещё не зарегистрированы на сайте, то сначала зарегистрируйтесь.
Copyright © 2010-2021 Русаков Михаил Юрьевич. Все права защищены.
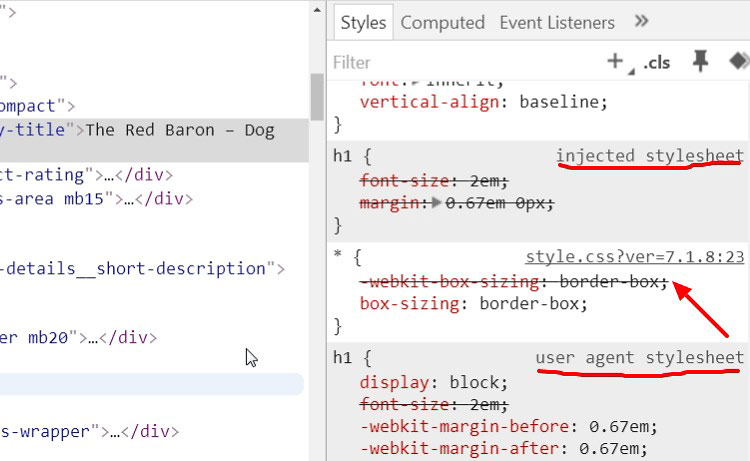
Однако, инспектор кода показывает, что user agent stylesheet блокирует эту директиву (скриншот).
Есть ли способ как-то обойти или ликвидировать эту блокировку?
 User Agent
User Agent
Прошу прощения, если такая тема уже была. Пишу браузер с ипользованием TWebBrowser. При входе, к.
Стилей вцелом довольно много, и часть из них подключаются внешним файлом, а часть находятся непосредственно в HTML файле.
Я привел лишь одну заблокированную браузнром директиву, а на самом деле их несколько.
Наверняка мой случай не уникальный и хотелось бы понять, как решаются такие проблемы. Ведь возникновение конфликта стилей можно обойти?
тоже парился со стилями пока не сделал просто копировал с user agent stylesheet.
Добавил к своим стилям и все переопределилось.
ul, menu, dir < user agent stylesheet.
display: block;
list-style-type: disc;
-webkit-margin-before: 1em;
-webkit-margin-after: 1em;
-webkit-margin-start: 0px;
-webkit-margin-end: 0px;
-webkit-padding-start: 40px;
>
Добавил к стилю к моему параметры из user agent stylesheet.
ul.item <
list-style-type: none;
display: block;
float: left;
list-style-type: disc;
-webkit-margin-before: 0em;
-webkit-margin-after: 0em;
-webkit-margin-start: 0px;
-webkit-margin-end: 0px;
-webkit-padding-start: 2px;
>
подмена user agent’a
короче надо нарегить рефералов (знаю что так нехорошо делать, но надо). какой софт (или сайти).
Пустой user-agent
Есть самописный скрипт для отслеживания посещений сайта. В базу сохраняются некоторые данные.
Почему user agent stylesheet перекрывает мои стили
А во-вторых, почему вообще, в принципе, в дефолтнонастроенном браузере его стиль, без особого приказа, может перекрывать стиль установленный в таблице стилей? В чью светлую голову пришла такая мысль? Очень хочется в рожу дать.


Примеры в студию что ли.
>Первый абзац слева от картинки
Который из них первый абзац слева? (
Запусти Firebug/Dragonfly (в зависимости от браузера) и выдели этот элемент. Просмотри цепочку наследования CSS свойств. Возможно твоего id там банально нет.
Конечно я запускал. В том-то и дело что стиль переопределяется. Я же это в Dragonfly и вижу. Т.е. оно видит что шрифт унаследован и показывает что он переопределен. В этом и трабла.
Блин, спасибо. Битрикс, такой битрикс.
да, не дай бог мне с ним поработать
Вы разработчик битрикса?
Звучит как «можно получить откат» 🙂
Просто это ценз. Люди купившие на ровном месте то, что можно плучить на халяву [я имею ввиду CMS вообще], уж наверняка и за работу заплатят, потому что они наверняка знают, что за все в интернете надо платить, и что все за что в интернете надо платить, стоит дорого.
Мне собственно просто не угодила архитектура всей цмс, она не удобна, я считаю что в готовом сайте человек должен видеть только те функции, которые он потребовал в ТЗ и ничего лишнего. А в битриксе там много чего нелогичного
Ну согласен архитектура не самая лучшая. Но и не худшая далеко.
Мало того, что много лишнего, так еще много частных всяких решений, прикрученных непонятно зачем на основе общей идеи инфоблоков, при этом нормального интерфеса для работы с этим универсальным объектом нет. Это же нонсенс! Его приходится делать каждый раз собственными руками.
А то как оно написано? Иногда разный стиль кода внутри одного класса! А есть файлы по 2000 строк без единой функции.
Но самое плохое как вояют под ним сайты. Это надо видеть! Вот из недавнего: https://plus.google.com/u/0/112929298698740639866/posts/CdhwYHw2Ed4
Зафигачить больше сотни правил обработки адресов где можно было бы обойтись одним. Ну это полная жесть. Вся мощь регулярных выражений.
Ну и так далее. Вобщем иногда работа у меня смешнее Амстердама.
Вот как раз из-за этих штук я не хочу с ним связываться, всё только потому что не хочется работать над тем, где очень много тупости, просто когда видишь такое, настроение пропадает работать с продуктом.
Мне вот интересно, как происходила его разработка.
20 Петь пишут ядро, потом 20 Вась допиливают ядро, дальше 30 Саш вносят корректировки для расширения функционала, ну и никто им всем не говорил о едином стиле написания, либо говорили, но многим было пофиг на это.
Причем в некоторых моментах такой быдлокоддинг встречается, что понимаешь что там писали его в школе на уроках информатики
Ну я думаю это проблема часто многих продуктов
Как быстрее DOM построить: парсинг, async, defer и preload
На сегодняшний день, джентльменский набор по ускорению сайта включает в себя всё от минификации и оптимизации файлов до кеширования, CDN, разделения кода и так называемого tree shaking. Но даже если вы не знакомы с этой терминологией, значительного ускорения можно добиться и парой ключевых слов с продуманной структурой кода.
По кирпичикам
HTML описывает структуру страницы. Для того, чтобы браузер смог извлечь из HTML хоть какую то пользу, его надо конвертировать в понятный браузерам формат — Document Object Model или попросту DOM. У браузера есть специальная функция парсер, позволяющая конвертировать из одного формата в другой. HTML парсер конвертирует HTML в DOM.
Связи различных элементов в HTML определяются вложенностью тегов. В DOM, эти же связи образуют древовидную структуру данных. У каждого тега HTML в DOM есть своя вершина (вершина DOM).
Шаг за шагом браузер строит DOM. Как только первые строки кода становятся доступными, браузер начинает парсить HTML, добавляя вершины в дерево.
У DOM две роли: объектная репрезентация HTML документа и в то же время DOM служит интерфейсом, связывая страницу с внешним миром, например с JavaScript. Если, например, вызвать document.getElementById() то функция вернёт вершину DOM. Для манипуляции с вершиной и тем как её видит пользователь у вершины есть множество функций.
CSS стили на странице отображаются в модель CSSOM — CSS Object Model. Очень похож на DOM, но для CSS, а не HTML. В отличии от DOM, CSSOM нельзя построить пошагово, т.к. стили в CSS могут переопределять друг друга. Браузеру приходится значительно потрудится чтобы применить CSS к DOM.
История тега <script>
Раньше, чтобы запустить скрипт, нужно было приостановить парсинг и продолжить его только после выполнения скрипта JavaScript’ом.
Скрипты также могут отправлять запросы в DOM и если это происходит во время постройки DOM, результат может оказаться непредсказуемым.
document.write() — функция-наследие, которая может сломать страницу самым неожиданным образом, поэтому лучше её не использовать, даже если браузеры будут её поддерживать. По этим причинам в браузерах были разработаны хитрые методы обхода проблем с производительностью, вызванных блокированием скриптов, о них чуть ниже.
А что с CSS?
JavaScript приостанавливает парсинг HTML, т.к. скрипты могут менять страницу. CSS не может изменить страницу, поэтому причин останавливать процесс парсинга у него нет, так?
Из-за этого CSS может блокировать парсинг в зависимости от порядка подключения скриптов и стилей на странице. Если внешние таблицы стилей находятся до скриптов, то создание DOM и CSSOM может мешать друг другу. Когда парсер доходит до скрипта, постройка DOM не может продолжаться до тех пор, пока JavaScript не выполнит скрипт, а JavaScript в свою очередь не может быть запущен, пока CSS не скачается, распарится и CSSOM станет доступным.
Ещё один момент, о котором не стоит забывать. Даже если CSS не будет блокировать постройку DOM, он блокирует процесс рендеринга. Браузер ничего не покажет пока у него не будет готовых DOM и CSSOM. Это потому, что зачастую страницы без CSS непригодны для использования. Если браузер покажет кривую страницу без CSS, а потом через мгновение полную стилизованную страницу, то у пользователя возникнет когнитивный диссонанс.
У этого явления есть название — Проблеск Неоформленного Содержания, сокращённо ПнОС [Flash of Unstyled Content или FOUC]
Во избежание таких проблем нужно как можно быстрее предоставить CSS. Помните золотое правило «стили сверху, скрипты снизу»? Теперь вы в курсе почему это важно!
Назад в будущее. Спекулятивный парсинг
Приостанавливание парсера при каждой встрече со скриптом будет означать задержку в обработке остальных данных, подгружаемых в HTML.
Раньше, если взять несколько скриптов и изображений, подгрузив их, например, так:
Процесс парсинга выглядел бы как показано ниже:
Такое поведение изменилось в 2008 годах, когда IE представил так называемый «опережающий загрузчик» [the lookahead downloader]. С помощью него файлы подгружались в фоновом режиме прямо во время выполнения скриптов. Вскоре этот метод переняли и Firefox, Chrome с Safari, используя его под разными названиями, равно как и большинство современных браузеров. У Chrome с Safari это «предварительный анализ» [the preload scanner], а у Firefox — спекулятивный парсер. Идея вот в чём, с учётом того, что постройка DOM во время выполнения скриптов весьма рискованна, можно всё ещё парсить HTML чтобы посмотреть какие ресурсы должны быть подгружены. Затем обнаруженные файлы добавляются в очередь на загрузку и скачиваются параллельно в фоновом режиме. И к моменту завершения скрипта, необходимые файлы могут быть уже готовы к использованию.
Таким образом с применением такого метода, процесс парсинга выше, выглядел бы так:
Такой процесс называется «спекулятивным», иногда «рискованным», потому что HTML всё ещё может меняться во время выполнения скрипта (напомню про document.write ), что может привести к работе проделанной впустую. Но несмотря что такой сценарий возможен, он крайне редок, именно поэтому спекулятивный парсинг даёт огромный прирост производительности.
В то время как другие браузеры загружают таким способом только привязанные файлы, парсер Firefox ещё и продолжает строить DOM во время выполнения скриптов. Плюс этого в том что если спекуляция прошла, то часть работы в постройке DOM уже будет проделана. А вот в случае неудачной спекуляции работы будет затрачено больше.
(Пред)загрузка
При использовании такой техники загрузки можно значительно повысить скорость загрузки и никаких специальных навыков для этого не понадобится. Но если вы веб разработчик, то знание механизма спекулятивного парсинга поможет использовать его по максимуму.
Различные браузеры предзагружают различные типы ресурсов. Все основные браузеры обязательно предзагружают следующие:
Количество файлов, которые могут быть загружены параллельно, ограничено и варьируется от браузера к браузеру. Это ещё зависит от множество факторов, таких как скачиваются ли файлы из одного сервера или из разных, используется протокол HTTP/1.1 или HTTP/2. Чтобы отрендерить страницу как можно быстрее, браузеры используют сложные алгоритмы и скачивают ресурсы с разными приоритетами, зависящие от типа ресурса, местоположения на странице и состояния самого процесса рендеринга.
При спекулятивном парсинге, браузер не запускает inline JavaScript блоки. Это означает, что если подгружать файлы в скриптах, то они наверняка окажутся последними в очереди на загрузку.
Поэтому это очень важно упростить задачу браузера при загрузке важных ресурсов. Можно, например, вставить их в HTML теги или перенести скрипт загрузки в inline и как можно выше в коде страницы. Хотя иногда требуется наоборот, загрузить файлы как можно позже, т.к. они не столь важные. В таком случае, чтобы спрятать ресурс от спекулятивного парсера, его можно подключить как можно позже на странице через JavaScript. Чтобы узнать больше о том как оптимизировать страницу для спекулятивного парсера, можно пройти по ссылке MDN руководства [на русском].
defer и async
Но скрипты выполняющиеся последовательно остаются проблемой. И не все скрипты действительно важны для пользователя, такие как скприпты аналитики, например. Идеи? Можно загружать их асинхронно.
Атрибуты defer и async были придуманы специально для этого, чтобы дать возможность разработчикам указать какие скрипты можно загружать асинхронно.
Оба этих атрибута подскажут браузеру, что он может продолжить парсить HTML и в тоже время загрузить эти скрипты в фоне. При таком раскладе, скрипты не будут блокировать постройку DOM и рендеринг, в результате чего, пользователь увидит страницу ещё до того, как все скрипты загрузятся.
Разница между defer и async в том, что они начинают выполнять скрипты в разный момент времени.
Где бы они не были указаны, скрипты с async загружаются с низким приоритетом, зачастую после всех остальных скриптов, без блокирования постройки DOM. Но если скрипт с async загрузится быстрее, то его выполнение может заблокировать постройку DOM и все остальные скрипты, которым только предстоит загрузиться.
Замечание: атрибуты async и defer работают только для внешних скриптов. Без параметра src они будут проигнорированы.
preload
async и defer прекрасно подходят если вы не паритесь о некоторых скриптах, но что делать с ресурсами на странице, которые важны для пользователя? Спекулятивные парсеры полезны, но подходят только для горстки типов ресурсов и действуют по своей заложенной логике. В целом, нужно загружать CSS в первую очередь, потому что он блокирует рендеринг, последовательные скрипты должны всегда иметь приоритет выше чем асинхронные, видимые изображения должны быть доступны скорее и есть ещё шрифты, видео, SVG… короче говоря, всё сложно.
Как автор, вам лучше знать какие именно ресурсы важны для рендеринга страницы. Некоторые из них часто погребенны в CSS или скриптах и браузеру придётся пройти сквозь дебри пока он хотя бы до них доберётся. Для таких важных ресурсов теперь можно использовать <link rel=»preload»> чтобы подсказать браузеру загрузить файл как можно скорее.
Все что требуется написать это:
Список того, что можно загрузить весьма велик и атрибут as скажет браузеру, какой именно контент он загружает. Возможные значения этого отрибута:
Шрифты, пожалуй, самый важный элемент для загрузки, который спрятан в CSS. Шрифты необходимы для рендеринга текста на странице, но они не будут загружены пока браузер не удостоверится что именно они будут использованы. А эта проверка происходит только после парсинга и применения CSS и когда стили уже применены к вершинам DOM. Это происходит достаточно поздно в процессе загрузки страницы и как правило приводит к неоправданной задержке рендеринга текста. Этого можно избежать, использовав атрибут preload при загрузке шрифтов. Одна деталь на которую стоит обратить внимание при предзагрузке шрифтов, это то, что нужно устанавливать атрибут crossorigin, даже если шрифт находится на том же домене.
В данное время возможности предзагрузки ограничены и браузеры только начинают применять этот метод, но за прогрессом можно следить тут.
Заключение
Браузеры это сложные существа, которые эволюционируют с 90-х. Мы разобрали некоторые причуды из прошлого равно как и новейшие стандарты в веб разработке. Эти рекомендации помогут сделать сайты приятнее для пользователя.
Если вы хотите узнать больше о работе браузеров, то ниже пара статей, которые могут быть вам интересны:



