Kubernetes Ingress глазами новичка
Ingress это базовый тип ресурса в кубертенесе. Если просто объявить объект типа Ingress в кубернетисе то ничего не произойдет.
Что бы этот ресурс начал работу в кластере кубернетиса должен быть установлен Ingress Controller, который настроит реверсивный прокси в соответствии с Ingress объектом.
Ingress Controller состоит из 2х компонентов — реверсивного прокси и контроллера который общается с API сервером кубернетеса. Реверсивный прокси слушает входящий трафик на портах которые указаны в настройках (обычно в настройках по умолчанию указан только порт 80). Контроллер может быть как отдельным демоном (как в nginx), так и встроенным в прокси (как в traefik).
Не все клауд провайдеры кубернетеса предустанавливают Ingress Controller по умолчанию.
Контроллеры могут запускаться либо как DaemonSet либо как Deployment. DaemonSet идеально использовать как единственный Ingress Controller, что бы реверсивное прокси слушало на всех IP адресах воркеров. Deployment отлично подходит если перед Ingress контроллером стоит балансировщик — от провайдера кубернетиса (GKE, AKS), MetalLB если онпремис или обычный haproxy/nginx установленный на сервере (требутеся ручная настройка). При этой установке возможно установить несколько Ingress Controller.
Как входящий трафик попадает на Ingress Controller
Во всех случаях реверс прокси в Ingress Controller слушает порты где ожидает http/https соединения.
Трафик на этоти порты может попасть тремя путями:
NodePort
Ставить Ingress Controller на NodePort без LoadBalancer имеет мало смысла, так как URL будет включать порт который указан в NodePort http://domain.example.org:32200/.
Для этого варианта лучше использовать Deployments. Это позволит проще скейлить количество подов ответственных за входящий трафик, прописывать им nodeAffinity и запускать несколько ingress controller (например для production и staging).
HostPort
При использовании HostPort порт пробрасывается с хоста где запущен под в этот самый Pod. LoadBalancer на вход не нужен, но для работы сайта в DNS нужно указывать что адрес домена находится на всех узлах.
Пример конфигурации DNS для 3х воркеров:
Для этой установки лучше всего использовать DaemonSet т.к. он позволяет запустить не более одного Pod на хосте. Deployment возможен, но имеет мало смысла т.к. надо прописывать affinity что бы не назначилось 2 Pod на один хост, иначе будет конфликт по портам.
Host network
При запуске Ingress Controller в общей сети с хостом не требуется никаких пробросов портов, но в этом случае все порты которые открыты в Pod будут доступны из интернета. Для запуска лучше использовать DaemonSet. Причины такие же как и с HostPort — что бы избежать конфликта портов.
Что выбрать
Если есть LoadBalancer на входе — NodePort, если нет — HostPort + DNS Round Robin. Для экспериментов можно попробовать Host network, но это не безопасно.
Липкие сессии для самых маленьких [Часть 2], или Как понять Kubernetes и преисполниться в своём познании

Липкие сессии (Sticky-session) — это особый вид балансировки нагрузки, при которой трафик поступает на один определенный сервер группы. Как правило, перед группой серверов находится балансировщик нагрузки (Nginx, HAProxy), который и устанавливает правила распределения трафика на доступные сервера.
В первой части цикла мы уже разобрали как создавать липкие сессии с помощью Nginx. Во второй части разберем создание подобной балансировки средствами Kubernetes.
Все примеры будут под систему MacOS. Установку для других систем смотрите в официальной документации.
Чтобы запустить minikube выполните команду:
Работать с кубом можно через командную строку, для этого нужно установить kubectl.
Эта утилитка ставится и для взаимодействия с реальным кубом. Чтобы посмотреть дашборд с графиками и картиночками выполните:
Только учтите, что команда заблокирует вам консоль, поэтому лучше откройте еще одно окно.

На этом установка учебного кластера завершена. Как по мне, для понимания основ kubernetes нужно разобрать всего 4 ресурса:
В таком порядке и будем рассматривать каждый ресурс по мере запуска приложения в кластере.
Использовать будем код из предыдущей статьи.
Здесь переменная uuid инициализируется вместе с FastAPI приложением. Переменная будет жить, пока работает сервер. Собственно, по значению этой переменной мы будем точно знать, что попали на тот же самый экземпляр приложения.
После сборки я запушил образ в свой публичный репозиторий docker hub:
Всё, мы готовы разворачивать приложение. Для этого нужно кубу указать ряд правил, которыми он будет руководствоваться при запуске вашего приложения. Такие правила называются конфигурацией развертывания (Deployments).
Обычно любой ресурс в Kubernetes описывается в yaml файлах. В нашем случае правил развертывания не много, поэтому обойдемся короткой командой по созданию объекта deployment.
В -–image можете указать свое приложение, которое залили в публичный репозиторий docker hub.
При создании ресурса deployment, создается так же пода (Pod) на узле. Пода это минимальная единица куба, в котором запускается контейнер или множество контейнеров докера. Deployment отслеживает состояние и работоспособность под. Если какая выйдет из строя, то он оперативно запустит новую.
Проверим, что создалось два ресурса deployment и pod.
Про «kubectl get»
kubctl довольно user friendly, например в команде get можно попросить как pod, так и pods, deployment или deployments и т.д.. Можно через запятую (без пробела) перечислить ресурсы, которые хотим получить.
Масштабируем наше приложение до двух сервисов.
И снова проверим состояние pods и deployment, вывод должен быть примерно такой:
Новая пода стала запускаться.
эксперименты с deployment
Как только две поды будут запущены, можно наглядно продемонстрировать работу deployment.
Удалим собственоручно поду pod/sticky-d-57444787d8-rdn6q:
Снова запросим текущее состояние pods и deployment:
Не успела пода *-rdn6q удалиться, на ее место пришла уже новая *-6gjmv.
Теперь давайте отправим запросы на развернутые приложения. Напрямую это сделать не удастся, для этого придумали сервис (Service).
Сервис (Service) в Kubernetes — это абстрактный объект (ресурс), который предоставляет доступ к запущенным подам. Хотя у каждого пода есть уникальный IP-адрес, эти IP-адреса не доступны за пределами кластера без использования сервиса. Сервисы позволяют приложениям принимать трафик и являются стандартным балансировщиком нагрузки на поды.
Сервисы могут по-разному открыты, в зависимости от указанного поля type:
Создадим сервис с типом LoadBalancer. Балансировка происходит по принципу random balancing (про это можно почитать в этой статье, которая ссылается сюда).
Запустить сервис можно командой:
Вывод будет примерно такой:
Отправим запросы на сервис и убедимся, что трафик поступает на разные поды:
Балансировщик не работает? Или мы добились своей цели и получили липкие сессии? Почти!
Мы получили липки сессии курильщика. Дело в том, пока открыто TCP соединение с сервером куб направляет трафик только на одну определенную поду. Но если будет обрыв соединения или мы создадим новое соединение, то можем попасть уже на другую поду. Подробнее об этом смотрите в этой отличной статье. Не такие липкие сессии нужны Готему сейчас. Чтобы обойти эту особенность необходимо убрать галочку keep-alive в Postman.
Посмотрим, что произойдет:
Ура! Мы убедились, что трафик балансируется.
Ресурс сервис довольно бедный балансировщик и умеет распределять трафик для определенного развертывания. Тут вступает ingress, который довольно сильно расширяет возможности балансировки в kubernetes.
Если просто создать ресурс ingress, то ничего не произойдет. Нужно создать ingress-controller. Для активации ingress-controller выполните:
проблемы с активацией ingress-controller?
Для macOS и Windows на момент написания статьи может произойти ошибка, чтобы это поправить нужно выполнить следующие команды:
Это приведет к стиранию всех развертываний и под. Вернитесь назад и повторите развертывание приложения и запуск сервиса.
При успешном запуске Ingress-controller запустится специальная пода, выполните команду:
Результат должен примерно таким:
Подробно на простых примерах зачем нужен ingress
Ingress позволяет балансировать трафик по имени хоста или на основе пути в запросе. Рассмотрим простой пример. Допустим у нас есть два приложения app1 и app2. После мы купили доменное имя, пусть будет awesome-company.com. И мы хотим чтобы наши сервисы были доступны по адресу:
awesome-company.com/app1
awesome-company.com/app2
app1.awesome-company.com
app2.awesome-company.com
Можно так же сделать комбинацию этих двух вариантов.
Ресурс ingress как раз и позволяет это сделать. Ingress балансирует трафик на разные сервисы, являясь такой надстройкой над ними.
Теперь создадим ресурс Ingress. Сделайте новый файлик ingress.yml и вставьте следующий текст:
Все ресурсы описанные в yml файлах применяются командой apply. Проверим, появился ли ingress объект:
Обратите внимание на адрес ресурса, если сделать запрос на 192.168.64.3:80 будет ошибка 404.
«Разрешим» локально доменное имя. Откройте файл /etc/hosts и в последней строчке через пробел запишите ip адрес ingress ресурса и доменное имя сервиса.
И попробуем отправить теперь запрос по адресу sticky.info:
Надо отметить, что балансировка работает несмотря на включенную галочку connection.
Можно схитрить и не определять локально доменное имя. Просто в заголовке запроса указать хост:
На этом завершается краткая вводная по основам kubernetes. Мы успешно развернули простенькое приложение в кластере и получили к нему доступ. Теперь можно глубже погружаться в теорию: например почитать про namespace (мы разворачивали приложение в default пространстве), почитать про остальные ресурсы куба и конечно вникнуть про создание объектов в формате yml.
Теперь наконец сделаем наш трафик липким. Добавим в Ingress.yml annotations c 4 параметрами:
Рассмотрим каждый параметр подробнее:
affinity: укажите значение “cookie”, чтобы включить липкие сессии;
affinity-mode: режим прилипания. Поддерживается два режима — persistent и balanced. При значении balanced трафик будет прилипать к определенному поду только на некоторый промежуток времени. Для вечного прилипания укажите persistent;
session-cookie-name: имя cookie, по значению которого ingress-controller будет ассоциировать трафик с определенной подой;
session-cookie-max-age: время, на которое трафик прилипает к поду, в секундах (настройка нужна если affinity-mode = balanced). После истечения заданного времени ingress-controller сгенеририт новое значение для session-cookie-name и вставит нам в cookie.
И проверим работу липких сессий в кубе:
Ответы будут приходить только от одного конкретного экземпляра приложения. Обратите внимание, что ingress-controller сам подставил нам в cookie значение для key и добавил срок годности прилипания. Через 60 секунд nginx-controller снова сгенерит значение для key, и трафик уже прилипнет к другой поде (но не факт, что к другой).
Теперь посмотрим как это выглядит в коде:
В цикле делаем запрос к приложению и выводим результат запроса и объект cookie.
Ingress-controller сгенерил key и подставил нам в cookie объект Set-Cookie. Трафик прилип на 60 секунд к определенной поде.
Готово! Мы успешно реализовали липкие сессии в Nginx и Kubernetes.
 И напоследок результаты соц. опроса среди IT компаний о необходимости Kubernetes.
И напоследок результаты соц. опроса среди IT компаний о необходимости Kubernetes.
Kubernetes Nginx Ingress: Перенаправление трафика с использованием аннотаций
Kubernetes Nginx Ingress: перенаправление трафика с использованием аннотаций

Перенаправляйте HTTP-трафик или переписывайте URL-адреса с помощью входных аннотаций Kubernetes и Nginx ingress controller. В этой статье объясняется использование аннотаций и их влияние на результирующий файл конфигурации nginx.conf.
nginx.ingress.kubernetes.io/rewrite-target
Пример 1:
Этот делает прозрачный обратный прокси-сервер.
Он не обновляет Location header, поэтому URL-адрес в браузере не меняется.
Пример 2:
Этот изменяет Location header, и URL-адрес в браузере обновляется:
Я предполагаю, что это можно использовать с помощью nginx.ingress.kubernetes.io/configuration-snippet : | (Я еще не пробовал).
Этот метод работает очень хорошо: определяет корневой каталог приложения (Application Root), который контроллер должен перенаправить, если он находится в / контексте:
В результирующем файле nginx.conf оператор if будет добавлен в контекст server :
2.nginx.ingress.kubernetes.io/configuration-snippet: |
3. nginx.ingress.kubernetes.io/server-snippet 😐
4. nginx.ingress.kubernetes.io/permanent-redirect
Довольно понятно, работает отлично
Он добавляет оператор if в файл nginx.conf в разделе /source следующим образом:
Permanent Redirect
Эта аннотация позволяет возвращать постоянное перенаправление вместо отправки данных в вышестоящий канал. Например:
Kubernetes NodePort vs LoadBalancer vs Ingress? Когда и что использовать?
Недавно меня спросили, в чем разница между NodePorts, LoadBalancers и Ingress. Все это разные способы получить внешний трафик в кластер. Давайте посмотрим, чем они отличаются, и когда использовать каждый из них.
Примечание: рекомендации рассчитаны на Google Kubernetes Engine. Если вы работаете в другом облаке, на собственном сервере, на миникубе или чем-то еще, будут отличия. Я не углубляюсь в технические детали. Если хотите подробностей, обратитесь к официальной документации.
ClusterIP
ClusterIP — сервис Kubernetes по умолчанию. Он обеспечивает сервис внутри кластера, к которому могут обращаться другие приложения внутри кластера. Внешнего доступа нет.
YAML для сервиса ClusterIP выглядит следующим образом:
С чего я заговорил о сервисе ClusterIP, если к нему нельзя получить доступ из интернета? Способ есть: с помощью прокси-сервера Kubernetes!
Запускаем прокси-сервер Kubernetes:
Теперь можно выполнять навигацию по API Kubernetes для доступа к этому сервису, используя схему:
Используем этот адрес для доступа к вышеуказанному сервису:
Когда использовать?
Существует несколько сценариев использования прокси-сервера Kubernetes для доступа к сервисам.
Отладка сервисов или подключение к ним напрямую с ноутбука с другими целями
Разрешение внутреннего трафика, отображение внутренних панелей и т. д
Поскольку этот метод требует запуска kubectl в качестве аутентифицированного пользователя, не следует использовать его для предоставления доступа к сервису в интернете или для продакшен-сервисов.
NodePort
Сервис NodePort — самый примитивный способ направить внешний трафик в сервис. NodePort, как следует из названия, открывает указанный порт для всех Nodes (виртуальных машин), и трафик на этот порт перенаправляется сервису.
YAML для службы NodePort выглядит так:
По сути, сервис NodePort имеет два отличия от обычного сервиса ClusterIP. Во-первых, тип NodePort. Существует дополнительный порт, называемый nodePort, который указывает, какой порт открыть на узлах. Если мы не укажем этот порт, он выберет случайный. В большинстве случаев дайте Kubernetes самому выбрать порт. Как говорит thockin, с выбором портов все не так просто.
Когда использовать?
Метод имеет множество недостатков:
На порт садится только один сервис
Доступны только порты 30000–32767
Если IP-адрес узла/виртуальной машины изменяется, придется разбираться
По этим причинам я не рекомендую использовать этот метод в продакшн, чтобы напрямую предоставлять доступ к сервису. Но если постоянная доступность сервиса вам безразлична, а уровень затрат — нет, этот метод для вас. Хороший пример такого приложения — демка или временная затычка.
LoadBalancer
Сервис LoadBalancer — стандартный способ предоставления сервиса в интернете. На GKE он развернет Network Load Balancer, который предоставит IP адрес. Этот IP адрес будет направлять весь трафик на сервис.
Когда использовать?
Если вы хотите раскрыть сервис напрямую, это метод по умолчанию. Весь трафик указанного порта будет направлен на сервис. Нет фильтрации, нет маршрутизации и т.д. Это означает, что мы можем направить на сервис такие виды трафика как HTTP, TCP, UDP, Websockets, gRPC и тому подобное.
! Но есть один недостаток. Каждому сервису, который мы раскрываем с помощью LoadBalancer, нужен свой IP-адрес, что может влететь в копеечку.
Ingress
В отличие от приведенных примеров, Ingress сам по себе не сервис. Он стоит перед несколькими сервисами и действует как «интеллектуальный маршрутизатор» или точка вхождения в кластер.
Есть разные типы контроллеров Ingress с богатыми возможностями.
Контроллер GKE по умолчанию запускает HTTP(S) Load Balancer. Вам одновременно будет доступна маршрутизация в бекенд сервисы на основе путей и субдоменов. Например, все на foo.yourdomain.com отправляем в сервис foo, а путь yourdomain.com/bar/ со всеми вложениями — в сервис bar.
YAML для объекта Ingress на GKE с L7 HTTP Load Balancer выглядит следующим образом:
Когда использовать?
С одной стороны, Ingress — один из лучших способов раскрыть сервисы. С другой стороны — один из самых сложных. Существует множество контроллеров Ingress: Google Cloud Load Balancer, Nginx, Contour, Istio и прочие. Есть и плагины для Ingress-контроллеров, такие как cert-manager, который автоматически предоставляет SSL-сертификаты для сервисов.
Ingress хорош при раскрытии нескольких сервисов на одном IP-адресе, когда все сервисы используют общий протокол L7 (обычно HTTP). Используя встроенную интеграцию GCP, вы платите только за один балансировщик нагрузки. А поскольку Ingress «умный», вы из коробки получаете множество функций (например, SSL, Auth, Routing и т.д.)
За диаграммы спасибо Ahmet Alp Balkan.
Это не самая технически точная диаграмма, но она хорошо иллюстрирует работу NodePort.
(Без)болезненный NGINX Ingress

Итак, у вас есть кластер Kubernetes, а для проброса внешнего трафика сервисам внутри кластера вы уже настроили Ingress-контроллер NGINX, ну, или пока только собираетесь это сделать. Класс!
Спустя несколько месяцев весь внешний трафик для всех окружений (dev, staging, production) направлялся через Ingress-серверы. И все было хорошо. А потом стало плохо.
Все мы отлично знаем, как это бывает: сначала вы заинтересовываетесь этой новой замечательной штукой, начинаете ей пользоваться, а затем начинаются неприятности.
Мой первый сбой в Ingress
Сперва позвольте предупредить: если вы еще не обеспокоены переполнениями очереди приема (accept queue overflows), начинайте беспокоиться.
Не забывайте об очередях
Случилось вот что: стоящее за NGINX приложение начало отвечать с большими задержками, что, в свою очередь, привело к заполнению NGINX listen backlog. Из-за этого NGINX начал сбрасывать соединения, в том числе и те, что пытался установить Kubernetes для проверки работоспособности сервиса (liveness/readiness probes).
А что происходит, когда под не отвечает на такие запросы? Kubernetes думает, что что-то пошло не так, и перезапускает его. Проблема в том, что это одна из тех ситуаций, когда перезапуск пода только усугубляет ситуацию: очередь приема продолжает переполняться, Kubernetes продолжает перезапускать поды, и в итоге их затягивает в водоворот падений и последующих рестартов.
Переполнения очереди TCP listen, согласно netstat
Какие уроки можно извлечь из этой ситуации?
Важность мониторинга
Мой совет №0: никогда не запускайте в production Kubernetes-кластер (или что-то аналогичное), не настроив качественный мониторинг его работы. Сам по себе мониторинг от проблем не избавит, но собранная телеметрия значительно облегчает нахождение первопричин сбоев, что позволяет исправлять их в процессе дальнейшей работы.
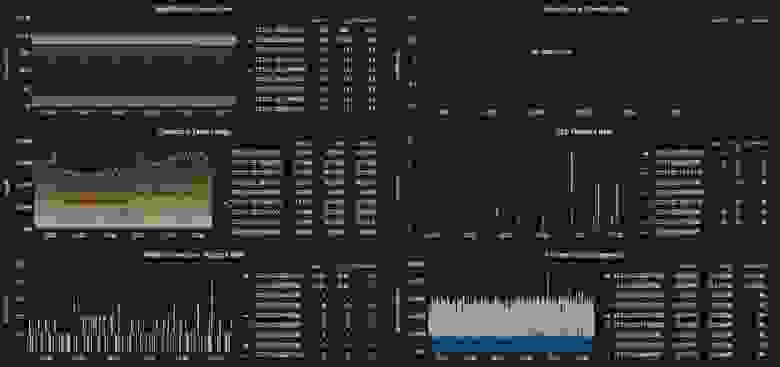
Несколько полезных метрик из `nodenetstat`*
Если и вы поддались повальному увлечению Prometheus, для сбора метрик уровня ноды можете воспользоваться node_exporter. Это удобный инструмент, который позволяет выявлять в том числе и только что описанные проблемы.
Некоторые метрики, получаемые с NGINX Ingress-контроллера
NGINX Ingress-контроллер и сам способен генерировать метрики для Prometheus. Не забудьте наладить их сбор.
Знай свой конфиг
Красота Ingress-контроллера том, что вы можете положиться на эту замечательную программу в вопросе генерации и перезагрузки конфигурации прокси-сервера и больше по этому поводу не беспокоиться. Вам даже не обязательно быть знакомым с нижележащей технологией (NGINX в данном случае). Правда? Нет!
Теперь попробуйте найти что-нибудь несовместимое с вашей установкой. Хотите пример? Давайте начнем с worker_processes auto ;
Оптимальное значение зависит от множества факторов, включая (но не ограничиваясь ими) число процессорных ядер, число жестких дисков с данными и картину нагрузок. Если затрудняетесь в выборе правильного значения, можно начать с установки его равным числу процессорных ядер (значение “auto” пытается определить его автоматически).
Первая проблема: в настоящий момент (будет ли это когда-либо исправлено?) NGINX ничего не знает о cgroups, а значит, в случае auto будет использовано значение количества физических ядер CPU хоста, а не количества «виртуальных» процессоров, как определено в Kubernetes resource requests/limits.
Проведем эксперимент. Что будет, если мы попробуем загрузить следующий файл конфигурации NGINX на двухъядерном сервере в контейнере, ограниченном только одним CPU? Сколько рабочих процессов будет запущено?
Параметры ядра
С Ingress или без него, всегда проверяйте и настраивайте параметры нод в соответствии с ожидаемой нагрузкой.
Это достаточно сложная тема, поэтому я не планирую здесь подробно ее раскрывать. Дополнительные материалы по этом вопросу можно найти в разделе Ссылки.
Kube-Proxy: Таблица Conntrack
Тем, кто использует Kubernetes, думаю, не нужно объяснять, что такое Сервисы и для чего они предназначены. Однако полезно будет рассмотреть некоторые особенности их работы.
В каждой ноде Kubernetes-кластера выполняется kube-proxy, который отвечает за реализацию виртуального IP для Сервисов типа, отличного от ExternalName. В Kubernetes v1.0 прокси выполнялся исключительно в пространстве пользователя. В Kubernetes v1.1 был добавлен iptables-прокси, однако это не был режим по умолчанию. Начиная с Kubernetes v1.2, iptables-прокси используется по умолчанию.
Поскольку различные параметры conntrack должны быть согласованы друг с другом (например, nf_conntrack_maxw и nf_conntrack_buckets ), kube-proxy, начиная работу, устанавливает разумные значения по умолчанию.
Это неплохой вариант, но вам может потребоваться увеличить значения этих параметров, если мониторинг показывает, что у вас заканчивается место, выделенное для conntrack. Однако необходимо помнить, что увеличение значений этих параметров ведет к повышенному потреблению памяти, так что поаккуратнее там.

Мониторинг использования conntrack
Делиться (не) значит заботиться
До недавнего времени у нас был только один экземпляр NGINX Ingress, ответственный за проксирование запросов ко всем приложениям во всех окружениях (dev, staging, production). Я убедился на собственном опыте, что это плохая идея. Не складывайте все яйца в одну корзину.
Думаю, то же самое может быть сказано и по поводу использования одного кластера для всех окружений, однако мы выяснили, что такой подход приводит к более эффективному расходованию ресурсов. Мы запускали dev/staging-поды на уровне QoS с негарантированной доставкой (best-effort QoS tier), используя таким образом ресурсы, оставшиеся от production-приложений.
Обратной стороной медали здесь является то, что мы оказываемся ограничены в действиях, которые можно выполнять по отношению к кластеру. Например, если нам потребуется провести нагрузочное тестирование staging-сервиса, придется быть очень осторожными, чтобы не повлиять на боевые сервисы, запущенные в этом же кластере.
Несмотря на то что контейнеры дают в общем случае хороший уровень изоляции, они по-прежнему зависят от разделяемых ресурсов ядра, которые являются объектом злоупотреблений.
Одна установка Ingress на каждое окружение
Мы уже говорили о том, что нет причин, по которым не стоит использовать по одному Ingress-контроллеру на каждое окружение. Это дает дополнительный уровень защиты на тот случай, если с сервисами в dev и/или staging начнутся проблемы.
Некоторые преимущества этого подхода:
Ingress-классы в помощь
Проблемы с перезагрузками Ingress
К этому моменту у нас был запущен выделенный ingress-контроллер для production-окружения. Все было хорошо до тех пор, пока мы не решили перенести одно WebSocket-приложение на Kubernetes + ingress.
Скоро я заметил странную тенденцию в использовании памяти production-подами ingress.
Что здесь, черт побери, происходит?!
Чтобы понять, что произошло, надо сделать шаг назад и взглянуть на то, как в NGINX реализован процесс перезагрузки конфигурации.
Получив сигнал, главный процесс проверяет правильность синтаксиса нового конфигурационного файла и пытается применить конфигурацию, содержащуюся в нем. Если это ему удается, главный процесс запускает новые рабочие процессы и отправляет сообщения старым рабочим процессам с требованием завершиться. В противном случае, главный процесс откатывает изменения и продолжает работать со старой конфигурацией. Старые рабочие процессы, получив команду завершиться, прекращают принимать новые запросы и продолжают обслуживать текущие запросы до тех пор, пока все такие запросы не будут обслужены. После этого старые рабочие процессы завершаются.
Напомню, что мы проксируем WebSocket-соединения, которые по своей природе являются долгоживущими. WebSocket-соединение может поддерживаться часами, а то и днями, в зависимости от приложения. NGINX-сервер не знает, можно ли разорвать соединение во время перезагрузки, мы должны облегчить ему эту работу. (Например, можно применить стратегию принудительного завершения соединений, бездействующих определенное количество времени, как на клиенте, так и на сервере. Не оставляйте такие вещи на потом.)
Вернемся к нашей проблеме. Если у нас так много рабочих процессов в стадии завершения, значит, конфигурация ingress перезагружалась много раз, а рабочие процессы не могли завершить работу из-за долгоживущих соединений.
Так на самом деле и было. Мы выяснили, что NGINX Ingress-контроллер периодически генерировал различные файлы конфигурации по причине изменения очередности вышестоящих серверов и IP-адресов серверов.
По этой причине NGINX Ingress-контроллер перезагружал конфигурацию несколько раз в минуту, забивая память завершающимися рабочими процессами до тех пор, пока под не становился жертвой OOM killer.
Количество ненужных перезагрузок после установки исправленной версии упало до нуля.
Спасибо @aledbf за помощь в нахождении и исправлении этой ошибки!
Продолжаем минимизировать перезагрузки конфигурации
Важно помнить, что перезагрузки конфигурации — операции затратная, и их лучше избегать, особенно при работе с WebSocket-соединениями. По этой причине мы решили установить отдельный Ingress-контроллер специально для долгоживущих соединений.
В нашем случае изменения в WebSocket-приложениях происходят намного реже, чем во всех остальных, и отдельный контроллер позволяет нам не трогать эти долгоживущие соединения лишний раз.
Отдельная установка также позволяет нам по-разному настраивать Ingress-контроллеры, оптимизируя их под тип обслуживаемых соединений.
Тонкая настройка автомасштабирования подов
Horizontal pod autoscaler в работе на пиковых нагрузках
Еще одна вещь, которую люди часто не осознают, — это то, что у horizontal pod autoscaler есть специальный таймер, который не позволяет масштабироваться несколько раз в течение короткого времени.
Таким образом, если нагрузка на ваше приложение действительно сильно возросла, может потребовать примерно 4 минуты (3 минуты задержки autoscaler + примерно 1 минута на синхронизацию метрик), прежде чем autscaler отреагирует на это, чего может оказаться вполне достаточно для серьезного ухудшения работы сервиса.



