Kubernetes Ingress глазами новичка
Ingress это базовый тип ресурса в кубертенесе. Если просто объявить объект типа Ingress в кубернетисе то ничего не произойдет.
Что бы этот ресурс начал работу в кластере кубернетиса должен быть установлен Ingress Controller, который настроит реверсивный прокси в соответствии с Ingress объектом.
Ingress Controller состоит из 2х компонентов — реверсивного прокси и контроллера который общается с API сервером кубернетеса. Реверсивный прокси слушает входящий трафик на портах которые указаны в настройках (обычно в настройках по умолчанию указан только порт 80). Контроллер может быть как отдельным демоном (как в nginx), так и встроенным в прокси (как в traefik).
Не все клауд провайдеры кубернетеса предустанавливают Ingress Controller по умолчанию.
Контроллеры могут запускаться либо как DaemonSet либо как Deployment. DaemonSet идеально использовать как единственный Ingress Controller, что бы реверсивное прокси слушало на всех IP адресах воркеров. Deployment отлично подходит если перед Ingress контроллером стоит балансировщик — от провайдера кубернетиса (GKE, AKS), MetalLB если онпремис или обычный haproxy/nginx установленный на сервере (требутеся ручная настройка). При этой установке возможно установить несколько Ingress Controller.
Как входящий трафик попадает на Ingress Controller
Во всех случаях реверс прокси в Ingress Controller слушает порты где ожидает http/https соединения.
Трафик на этоти порты может попасть тремя путями:
NodePort
Ставить Ingress Controller на NodePort без LoadBalancer имеет мало смысла, так как URL будет включать порт который указан в NodePort http://domain.example.org:32200/.
Для этого варианта лучше использовать Deployments. Это позволит проще скейлить количество подов ответственных за входящий трафик, прописывать им nodeAffinity и запускать несколько ingress controller (например для production и staging).
HostPort
При использовании HostPort порт пробрасывается с хоста где запущен под в этот самый Pod. LoadBalancer на вход не нужен, но для работы сайта в DNS нужно указывать что адрес домена находится на всех узлах.
Пример конфигурации DNS для 3х воркеров:
Для этой установки лучше всего использовать DaemonSet т.к. он позволяет запустить не более одного Pod на хосте. Deployment возможен, но имеет мало смысла т.к. надо прописывать affinity что бы не назначилось 2 Pod на один хост, иначе будет конфликт по портам.
Host network
При запуске Ingress Controller в общей сети с хостом не требуется никаких пробросов портов, но в этом случае все порты которые открыты в Pod будут доступны из интернета. Для запуска лучше использовать DaemonSet. Причины такие же как и с HostPort — что бы избежать конфликта портов.
Что выбрать
Если есть LoadBalancer на входе — NodePort, если нет — HostPort + DNS Round Robin. Для экспериментов можно попробовать Host network, но это не безопасно.
Что такое контроллер объекта ingress Шлюза приложений?
Контроллер объекта ingress Шлюза приложений (AGIC) — это приложение Kubernetes, которое позволяет клиентам Службы Azure Kubernetes (AKS) использовать собственную подсистему балансировки нагрузки уровня 7 Шлюза приложений Azure, чтобы предоставлять доступ к облачному программному обеспечению через Интернет. Контроллер AGIC отслеживает кластер Kubernetes, в котором он размещен, и постоянно передает в шлюз приложений обновленные данные, чтобы выбранные службы были доступны в Интернете.
Контроллер объекта ingress работает в собственном pod в AKS клиента. AGIC отслеживает изменения, вносимые в подмножество ресурсов Kubernetes. Состояние кластера AKS преобразовывается в конфигурацию шлюза приложений и применяется к Azure Resource Manager (ARM).
Преимущества контроллера объекта ingress Шлюза приложений
AGIC помогает устранить необходимость создания другой подсистемы балансировки нагрузки или общедоступного IP-адреса для кластера AKS и избежать нескольких прыжков в пути данных, по которому запросы передаются в кластер AKS. Шлюз приложений обращается к модулям pod напрямую с помощью частных IP-адресов и не нуждается в службах NodePort или KubeProxy. Это также повышает производительность развертываний.
Контроллер объекта ingress поддерживается исключительно номерами SKU Standard_v2 и WAF_v2, что также обеспечивает преимущества автомасштабирования. Шлюз приложений может реагировать на увеличение или уменьшение объема трафика и соответствующим образом изменять масштаб, не используя ресурсы из кластера AKS.
Использование Шлюза приложений в дополнение к AGIC также помогает защитить кластер AKS, так как обеспечивает политику TLS и функции брандмауэра веб-приложения (WAF).
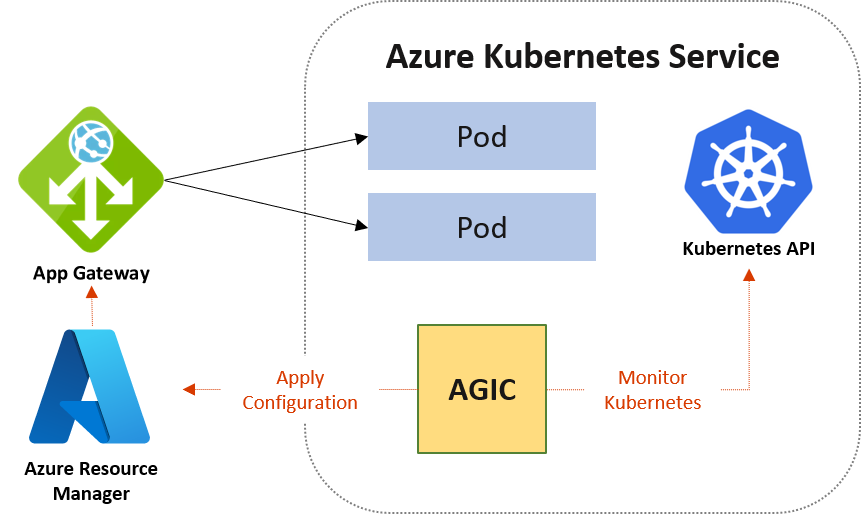
Для настройки AGIC используется ресурс ingress Kubernetes, а также службы, развертывания и модули pod. AGIC предоставляет ряд функций, использующих встроенную подсистему балансировки нагрузки уровня 7 Шлюза приложений Azure. Вот некоторые из них:
Разница между развертыванием Helm и надстройкой AKS
Существуют два способа развертывания AGIC в кластере AKS. Первый способ — используя Helm, второй — используя AKS в качестве надстройки. Основное преимущество развертывания AGIC в качестве надстройки AKS заключается в том, что это гораздо проще, чем развертывание с помощью Helm. Для новой конфигурации можно развернуть новый шлюз приложений и новый кластер AKS с AGIC, включенным в качестве надстройки, выполнив одну строку команд в Azure CLI. Надстройка также является полностью управляемой службой, что предоставляет дополнительные преимущества, такие как автоматическое обновление и расширенная поддержка. Оба способа развертывания AGIC (с помощью Helm и надстройки AKS) полностью поддерживаются корпорацией Майкрософт. Кроме того, надстройка обеспечивает лучшую интеграцию с AKS, так как является надстройкой первого класса.
Надстройка AGIC по-прежнему развертывается как pod в кластере AKS клиента, однако существует ряд различий между версией развертывания Helm и версией надстройки AGIC. Ниже приведен список различий между этими двумя версиями.
Клиенты могут развернуть только одну надстройку AGIC в кластере AKS, и каждая надстройка AGIC в настоящее время может быть назначена только одному шлюзу приложений. Для развертываний, требующих более одного контроллера AGIC на кластер или нескольких контроллеров AGIC, предназначенных для одного шлюза приложений, можно использовать контроллеры AGIC, развернутые с помощью Helm.
Обзор и сравнение контроллеров Ingress для Kubernetes

При запуске кластера Kubernetes для конкретного приложения следует понимать, какие требования представляет к этому ресурсу само приложение, бизнес и разработчики. При наличии этой информации можно приступать к принятию архитектурного решения и, в частности, к выбору конкретного Ingress-контроллера, коих на сегодняшний день уже большое количество. Чтобы составить базовое представление об имеющихся вариантах без необходимости изучать множество статей/документации и т.п., мы и подготовили этот обзор, включив в него основные (production ready) Ingress-контроллеры.
Надеемся, что он поможет коллегам в выборе архитектурного решения — по крайней мере, станет отправной точкой для получения более подробной информации и практических экспериментов. Предварительно мы изучили другие подобные материалы в сети и, как ни странно, не обнаружили ни одного более-менее полного, а главное — структурированного — обзора. Итак, заполним же этот пробел!
Критерии
Чтобы в принципе проводить сравнение и получить сколько-нибудь полезный результат, надо понимать не просто предметную область, но и иметь конкретный список критериев, которые и будут задавать вектор исследования. Не претендуя на анализ всех возможных случаев применения Ingress/Kubernetes, мы постарались выделить наиболее общие требования к контроллерам — будьте готовы, что всю свою специфику и частности в любом случае придётся изучать отдельно.
Но начну с характеристик, которые стали настолько привычными, что реализованы во всех решениях и не рассматриваются:
Поддерживаемые протоколы
Один из основополагающих критериев для выбора. Ваше ПО может работать не по стандартному HTTP или же требовать работу сразу по множеству протоколов. Если ваш случай — нестандартный, обязательно берите в расчет этот фактор, дабы не пришлось потом перенастраивать кластер. У всех контроллеров список поддерживаемых протоколов варьируется.
ПО в основе
Есть несколько вариантов приложений, на которых основан контроллер. Популярные — это nginx, traefik, haproxy, envoy. В общем случае, возможно, не слишком влияет на то, как принимается и передается трафик, однако всегда полезно знать потенциальные нюансы и особенности того, что «под капотом».
Маршрутизация трафика
На основе чего можно принимать решение о направлении трафика в тот или иной сервис? Обычно это host и path, но бывают и дополнительные возможности.
Пространство имен в рамках кластера
Пространство имён (namespace) — возможность логически разбивать ресурсы в Kubernetes (например, на stage, production и т.п.). Есть Ingress-контроллеры, которые надо ставить отдельно в каждый namespace (и тогда он может направлять трафик только в pod’ы этого пространства). А есть такие (и их явное большинство), что работают глобально на весь кластер — в них трафик направляется в любой pod кластера, независимо от пространства имён.
Пробы для upstream’ов
Каким образом обеспечивается направление трафика в здоровые экземпляры приложения, сервисов? Есть варианты с активными и пассивными проверками, повторными попытками (retries), circuit breakers (подробнее о них см., например, в статье про Istio), собственными реализациями проверок состояния (custom health checks) и т.п. Весьма важный параметр, если у вас высокие требования к доступности и своевременному выводу из балансировки отказавших сервисов.
Алгоритмы балансировки
Тут множество вариантов: от традиционных round-robin до экзотических вроде rdp-cookie, а также отдельные возможности вроде sticky sessions.
Аутентификация
Какие схемы авторизации поддерживает контроллер? Basic, digest, oauth, external-auth — думаю, что эти опции должны быть знакомы. Это важный критерий, если используется много контуров для разработчиков (и/или просто закрытых), доступ к которым осуществляется через Ingress.
Распределение трафика
Поддерживает ли контроллер такие часто применяемые механизмы для распределения трафика, как канареечные выкаты (canary), A/B-тестирование, зеркалирование трафика (mirroring/shadowing)? Это по-настоящему больная тема для приложений, которые требуют аккуратного и точного управления трафика для продуктивного тестирования, отладки продуктовых ошибок не на бою (или с минимальными потерями), анализа трафика и т.п.
Платная подписка
Есть ли платный вариант у контроллера, с расширенными функциональными возможностями и/или технической поддержкой?
Графический интерфейс (Web UI)
Имеется ли какой-либо графический интерфейс для управления конфигурацией контроллера? В основном для «сподручности» и/или для тех, кому требуется вносить какие-то изменения в конфигурацию Ingress’а, но работать с «сырыми» шаблонами неудобно. Может пригодится в случае, если разработчики хотят налету проводить какие-либо эксперименты с трафиком.
JWT-валидация
Наличие встроенной проверки JSON web-токенов для авторизации и валидации пользователя конечному приложению.
Возможности для кастомизации конфига
Расширяемость шаблонов в смысле наличия механизмов, позволяющих добавлять в стандартные шаблоны конфигурации собственные директивы, флаги и т.д.
Базовые механизмы защиты от DDOS
Простые алгоритмы rate limit или же более сложные варианты отсеивания трафика на основе адресов, белых списков, стран и т.д.
Трассировка запросов
Возможности наблюдения, отслеживания и отладки запросов от Ingress’ов к конкретным сервисам/pod’ам, а в идеале — и между сервисами/pod’ами тоже.
Контроллеры Ingress
Список контроллеров был сформирован на основе официальной документации Kubernetes и этой таблицы. Некоторые из них мы исключили из обзора ввиду специфичности или малой распространенности (ранней стадии развития). Оставшиеся же рассмотрены ниже. Начнём с общего описания решений и продолжим сводной таблицей.
Ingress от Kubernetes
Это официальный контроллер для Kubernetes, который разрабатывается сообществом. Очевидно из названия, он основан на nginx и дополнен различным набором Lua-плагинов, применяемых для реализации дополнительных возможностей. Благодаря популярности самого nginx’а и минимальных модификаций над ним при использовании в качестве контроллера, этот вариант может быть самым простым и понятным в конфигурации среднестатистическим инженером (с опытом в web).
Ingress от NGINX Inc
Официальный продукт разработчиков nginx. Имеет платную версию, основанную на NGINX Plus. Основная идея — высокий уровень стабильности, постоянная обратная совместимость, отсутствие каких-либо посторонних модулей и заявленная повышенная скорость (в сравнении с официальным контроллером), достигнутая благодаря отказу от Lua.
Бесплатная версия существенно урезана, в том числе даже при сравнении с официальным контроллером (из-за отсутствия всё тех же Lua-модулей). Платная при этом имеет достаточно широкий дополнительный функционал: метрики в реальном времени, JWT-валидация, активные health check’и и другое. Важное преимущество перед NGINX Ingress — полноценная поддержка TCP/UDP-трафика (и в community-версии тоже!). Минус — отсутствие фич по распределению трафика, что, впрочем, «имеет максимальный приоритет для разработчиков», но требует времени на реализацию.
Kong Ingress
Продукт, разрабатываемый компанией Kong Inc. в двух вариантах: коммерческий и бесплатный. Основан на nginx, возможности которого расширены большим количеством модулей на Lua.
Изначально был ориентирован на обработку и маршрутизацию запросов API, т.е. как API Gateway, однако на данный момент стал полноценным Ingress-контроллером. Основные преимущества: множество дополнительных модулей (в том числе и от сторонних разработчиков), которые легко ставить и конфигурировать и с помощью которых реализуется широкий спектр дополнительных возможностей. Впрочем, встроенные функции уже предлагают многие возможности. Конфигурация работы производится с помощью CRD-ресурсов.
Важная особенность продукта — работа в рамках одного контура (вместо cross-namespaced) является спорной темой: кому-то покажется недостатком (приходится плодить сущности для каждого контура), а для кого-то — фича (больший уровень изоляции, т.к. если сломан один контроллер, то проблема ограничена одним только контуром).
Traefik
Прокси, который изначально создавался для работы с маршрутизацией запросов для микросервисов и их динамической среды. Отсюда и многие полезные возможности: обновление конфигурации совсем без перезагрузок, поддержка большого количества методов балансировки, веб-интерфейс, проброс метрик, поддержка различных протоколов, REST API, канареечные релизы и многое другое. Приятной особенностью также является поддержка сертификатов Let’s Encrypt из коробки. Недостаток — для организации высокой доступности (HA) у контроллера потребуется устанавливать и подключать собственное KV-хранилище.
HAProxy
HAProxy давно известен в качестве прокси и балансировщика трафика. В рамках кластера Kubernetes с ним предлагается «мягкое» обновление конфигурации (без потери трафика), service discovery на основе DNS, динамическая конфигурация с помощью API. Привлекательным может стать полная кастомизация шаблона конфигов с помощью замены CM’а, а также возможности использования в нём функций библиотеки Sprig. В целом же основной акцент решения делается на высокую скорость работы, его оптимизированность и эффективность в потребляемых ресурсах. Преимущество контроллера — поддержка рекордного числа различных способов балансировки.
Voyager
Основанный на HAproxy контроллер, который позиционируется как универсальное решение, поддерживающее широкие возможности на большом количестве провайдеров. Предлагается возможность для балансировки трафика на L7 и L4, а балансировку TCP L4-трафика в целом можно назвать одной из ключевых фич решения.
Contour
В основу этого решения не только лёг Envoy: оно разработано совместно с авторами этого популярного прокси. Важная особенность — возможность разделения управления ресурсами Ingress с помощью CRD-ресурсов IngressRoute. Для организаций со множеством команд разработки, использующих один кластер, это помогает максимально обезопасить работу с трафиком в соседних контурах и защитить их от ошибок при изменении ресурсов Ingress.
Также предлагается расширенный набор методов балансировки (присутствует зеркалирование запросов, автоповторы, ограничение по rate’у запросов и многое другое), детальный мониторинг потока трафика и сбоев. Возможно, для кого-то будет существенным недостатком отсутствие поддержки sticky sessions (хотя работы уже ведутся).
Istio Ingress
Комплексное service mesh-решение, которое является не только Ingress-контроллером, управляющим поступающим трафиком извне, но и контролирует весь трафик в рамках кластера. «Под капотом», в качестве sidecar-прокси для каждого сервиса, используется Envoy. В сущности это большой комбайн, который «может всё», а основная его идея — максимальная управляемость, расширяемость, безопасность и прозрачность. С его помощью вы можете в тонкостях настраивать маршрутизацию трафика, авторизацию доступа между сервисами, балансировку, мониторинг, канареечные релизы и многое другое. Подробнее об Istio читайте в серии статей «Назад к микросервисам с Istio».
Ambassador
Ещё одно решение на основе Envoy. Имеет бесплатную и коммерческую версии. Позиционируется как «полностью родное для Kubernetes», что приносит соответствующие преимущества (тесная интеграция с методами и сущностями кластера K8s).
Сравнительная таблица
Итак, кульминация статьи — эта огромная таблица:
Она кликабельна для возможности более детального просмотра, а также доступна в формате Google Sheets.
Подведём итоги
Цель статьи — предоставить более полное понимание (впрочем, совершенно не исчерпывающее!) того, какой выбор сделать в вашем конкретном случае. Как обычно бывает, каждый контроллер имеет свои достоинства и недостатки…
Классический Ingress от Kubernetes хорош своей доступностью и проверенностью, достаточно богатыми возможностями — в общем случае его должно «хватить за глаза». Однако, если есть повышенные требования к стабильности, уровню фич и разработки, стоит обратить внимание на Ingress с NGINX Plus и платной подпиской. Kong имеет богатейший набор плагинов (и, соответственно, обеспечиваемых ими возможностей), причём в платной версии их даже больше. У него широкие возможности по работе в качестве API Gateway, динамического конфигурирования на основе CRD-ресурсов, а также базовых сервисов Kubernetes.
При повышенных требованиях к балансировке и методам авторизации присмотритесь к Traefik и HAProxy. Это Open Source-проекты, проверенные годами, очень стабильные и активно развивающиеся. Contour появился уже пару лет как на свет, но выглядит всё еще слишком молодо и имеет лишь базовые возможности, добавленные поверх Envoy. Если есть требования по наличию/встраиванию WAF перед приложением, стоит обратить внимание на тот же Ingress от Kubernetes или HAProxy.
А самые богатые по функциям — это продукты, построенные на базе Envoy, в особенности Istio. Он представляется комплексным решением, который «может всё», что, впрочем, означает и значительно более высокий порог вхождения по конфигурации/запуску/администрированию, чем у других решений.
Нами в качестве стандартного контроллера был выбран и до сих пор используется Ingress от Kubernetes, который покрывает 80—90% потребностей. Он вполне надёжен, легко конфигурируется, расширяется. В общем случае, при отсутствии специфичных требований, он должен подойти большинству кластеров/приложений. Из таких же универсальных и относительно простых продуктов можно порекомендовать Traefik и HAProxy.
Назад к микросервисам вместе с Istio. Часть 1
Прим. перев.: Service mesh’и определённо стали актуальным решением в современной инфраструктуре для приложений, следующих микросервисной архитектуре. Хотя Istio может быть на слуху у многих DevOps-инженеров, это довольно новый продукт, который, будучи комплексным в смысле предоставляемых возможностей, может потребовать значительного времени для знакомства. Немецкий инженер Rinor Maloku, отвечающий за облачные вычисления для крупных клиентов в телекоммуникационной компании Orange Networks, написал замечательный цикл материалов, что позволяют достаточно быстро и глубоко погрузиться в Istio. Начинает же он свой рассказ с того, что вообще умеет Istio и как на это можно быстро посмотреть собственными глазами.
Istio — Open Source-проект, разработанный при сотрудничестве команд из Google, IBM и Lyft. Он решает сложности, возникающие в приложениях, основанных на микросервисах, например, такие как:
Менеджер проектов: Как долго добавлять возможность обратной связи?
Разработчик: Два спринта.
МП: Что. Это ведь всего лишь CRUD!
Р: Сделать CRUD — простая часть задачи, но нам ещё потребуется аутентифицировать и авторизовывать пользователей и сервисы. Поскольку сеть ненадёжна, понадобится реализовать повторные запросы, а также паттерн circuit breaker в клиентах. Ещё, чтобы убедиться, что вся система не упала, понадобятся таймауты и bulkheads (подробнее об обоих упомянутых паттернах см. дальше в статье — прим. перев.), а для того, чтобы обнаруживать проблемы, потребуется мониторинг, трассировка, […]
МП: Ох, давайте тогда просто вставим эту фичу в сервис Product.
Думаю, идея понятна: объём шагов и усилий, которые требуются для добавления одного сервиса, огромен. В этой статье мы рассмотрим, как Istio устраняет все упомянутые выше сложности (не являющиеся целевыми для бизнес-логики) из сервисов.
Примечание: Статья предполагает, что у вас есть практические знания по Kubernetes. В ином случае рекомендую прочитать моё введение в Kubernetes и только после этого продолжить чтение данного материала.
Идея Istio
В мире без Istio один сервис делает прямые запросы к другому, а в случае сбоя сервис должен сам обработать его: предпринять новую попытку, предусмотреть таймаут, открыть circuit breaker и т.п.
Сетевой трафик в Kubernetes
Istio же предлагает специализированное решение, полностью отделённое от сервисов и функционирующее путём вмешательства в сетевое взаимодействие. И таким образом оно реализует:
Архитектура Istio
Istio перехватывает весь сетевой трафик и применяет к нему набор правил, вставляя в каждый pod умный прокси в виде sidecar-контейнера. Прокси, которые активируют все возможности, образуют собой Data Plane, и они могут динамически настраиваться с помощью Control Plane.
Data Plane
Вставляемые в pod’ы прокси позволяют Istio с лёгкостью добиться соответствия нужным нам требованиям. Например, проверим функции повторных попыток и circuit breaker.
Как retries и circuit breaking реализованы в Envoy
Отлично! Теперь вы можете захотеть отправиться в вояж с Istio, но всё ещё есть какие-то сомнения, открытые вопросы. Если это универсальное решение на все случаи в жизни, то у вас возникает закономерное подозрение: ведь все такие решения в действительности оказываются не подходящими ни для какого случая.
И вот наконец вы спросите: «Оно настраивается?»
Теперь вы готовы к морскому путешествию — и давайте же познакомимся с Control Plane.
Control Plane
Он состоит из трёх компонентов: Pilot, Mixer и Citadel, — которые совместными усилиями настраивают Envoy’и для маршрутизации трафика, применяют политики и собирают телеметрические данные. Схематично всё это выглядит так:
Взаимодействие Control Plane с Data Plane
Envoy’и (т.е. data plane) сконфигурированы с помощью Kubernetes CRD (Custom Resource Definitions), определёнными Istio и специально предназначенными для этой цели. Для вас это означает, что они представляются очередным ресурсом в Kubernetes со знакомым синтаксисом. После создания этот ресурс будет подобран control plane’ом и применён к Envoy’ям.
Отношение сервисов к Istio
Мы описали отношение Istio к сервисам, но не обратное: как же сервисы относятся к Istio?
Честно говоря, о присутствии Istio сервисам известно так же хорошо, как рыбам — о воде, когда они спрашивают себя: «Что вообще такое вода?».

Иллюстрация Victoria Dimitrakopoulos: — Как вам вода? — Что вообще такое вода?
Таким образом, вы можете взять рабочий кластер и после деплоя компонентов Istio сервисы, находящиеся в нём, продолжат работать, а после устранения этих компонентов — снова всё будет хорошо. Понятное дело, что при этом вы потеряете возможности, предоставляемые Istio.
Достаточно теории — давайте перенесём это знание в практику!
Istio на практике
После создания кластера и настройки доступа к Kubernetes через консольную утилиту можно установить Istio через пакетный менеджер Helm.
Установка Helm
Установите клиент Helm на своём компьютере, как рассказывают в официальной документации. Его мы будем использовать для генерации шаблонов для установки Istio в следующем разделе.
Установка Istio
Для простоты идентификации ресурсов Istio создайте в кластере K8s пространство имён istio-system :
Завершите установку, перейдя в каталог [istio-resources] и выполнив команду:
Теперь мы готовы продолжить в следующем разделе, где поднимем и запустим приложение.
Архитектура приложения Sentiment Analysis
Воспользуемся примером микросервисного приложения Sentiment Analysis, использованного в уже упомянутой статье-введении в Kubernetes. Оно достаточно сложное, чтобы показать возможности Istio на практике.
Приложение состоит из четырёх микросервисов:
На этой схеме помимо сервисов мы видим также Ingress Controller, который в Kubernetes маршрутизирует входящие запросы на соответствующие сервисы. В Istio используется схожая концепция в рамках Ingress Gateway, подробности о котором последуют.
Запуск приложения с прокси от Istio
Для дальнейших операций, упоминаемых в статье, склонируйте себе репозиторий istio-mastery. В нём содержатся приложение и манифесты для Kubernetes и Istio.
Вставка sidecar’ов
Теперь каждый pod, который будет разворачиваться в пространстве имён по умолчанию ( default ) получит свой sidecar-контейнер. Чтобы убедиться в этом, давайте задеплоим тестовое приложение, перейдя в корневой каталог репозитория [istio-mastery] и выполнив следующую команду:
Визуально это представляется так:
Прокси Envoy в одном из pod’ов
Теперь, когда приложение поднято и функционирует, нам потребуется разрешить входящему трафику приходить в приложение.
Ingress Gateway
Лучшая практика добиться этого (разрешить трафик в кластере) — через Ingress Gateway в Istio, что располагается у «границы» кластера и позволяет включать для входящего трафика такие функции Istio, как маршрутизация, балансировка нагрузки, безопасность и мониторинг.
Компонент Ingress Gateway и сервис, который пробрасывает его вовне, были установлены в кластер во время инсталляции Istio. Чтобы узнать внешний IP-адрес сервиса, выполните:
Мы будем обращаться к приложению по этому IP и дальше (я буду ссылаться на него как EXTERNAL-IP), поэтому для удобства запишем значение в переменную:
Если попробуете сейчас зайти на этот IP через браузер, то получите ошибку Service Unavailable, т.к. по умолчанию Istio блокирует весь входящий трафик, пока не определён Gateway.
Ресурс Gateway
Gateway — это CRD (Custom Resource Definition) в Kubernetes, определяемый после установки Istio в кластере и активирующий возможность указывать порты, протокол и хосты, для которых мы хотим разрешить входящий трафик.
В нашем случае мы хотим разрешить HTTP-трафик на 80-й порт для всех хостов. Задача реализуется следующим определением (http-gateway.yaml):
Конфигурация применяется вызовом следующей команды:
Теперь шлюз разрешает доступ к порту 80, но не имеет представления о том, куда маршрутизировать запросы. Для этого понадобятся Virtual Services.
Ресурс VirtualService
VirtualService указывает Ingress Gateway’ю, как маршрутизировать запросы, которые разрешены внутри кластера.
Запросы к нашему приложению, приходящие через http-gateway, должны быть отправлены в сервисы sa-frontend, sa-web-app и sa-feedback:
Маршруты, которые необходимо настроить с VirtualServices
Рассмотрим запросы, которые должны направляться на SA-Frontend:
Применим VirtualService вызовом:
Примечание: Когда мы применяем ресурсы Istio, Kubernetes API Server создаёт событие, которое получает Istio Control Plane, и уже после этого новая конфигурация применяется к прокси-серверам Envoy каждого pod’а. А контроллер Ingress Gateway представляется очередным Envoy, сконфигурированным в Control Plane. Всё это на схеме выглядит так:
Конфигурация Istio-IngressGateway для маршрутизации запросов
Перед тем, как продолжить, поработайте немного с приложением, чтобы сгенерировать трафик (его наличие необходимо для наглядности в последующих действиях — прим. перев.).
Kiali : наблюдаемость
Чтобы попасть в административный интерфейс Kiali, выполните следующую команду:
… и откройте http://localhost:20001/, залогинившись под admin/admin. Здесь вы найдете множество полезных возможностей, например, для проверки конфигурации компонентов Istio, визуализации сервисов по информации, собранной при перехвате сетевых запросов, получения ответов на вопросы «Кто к кому обращается?», «У какой версии сервиса возникают сбои?» и т.п. В общем, изучите возможности Kiali перед тем, как двигаться дальше — к визуализации метрик с Grafana.
Grafana: визуализация метрик
Собранные в Istio метрики попадают в Prometheus и визуализируются с Grafana. Чтобы попасть в административный интерфейс Grafana, выполните команду ниже, после чего откройте http://localhost:3000/:
Кликнув на меню Home слева сверху и выбрав Istio Service Dashboard в левом верхнем углу, начните с сервиса sa-web-app, чтобы посмотреть на собранные метрики:
Здесь нас ждёт пустое и совершенно скучное представление — руководство никогда такое не одобрит. Давайте же создадим небольшую нагрузку следующей командой:
Вот теперь у нас гораздо более симпатичные графики, а в дополнение к ним — замечательные инструменты Prometheus для мониторинга и Grafana для визуализации метрик, что позволят нам узнать о производительности, состоянии здоровья, улучшениях/деградации в работе сервисов на протяжении времени.
Наконец, посмотрим на трассировку запросов в сервисах.
Jaeger : трассировка
Трассировка нам потребуется, потому что чем больше у нас сервисов, тем сложнее добраться до причины сбоя. Посмотрим на простой случай из картинки ниже:
Типовой пример случайного неудачного запроса
Запрос приходит, падает — в чём же причина? Первый сервис? Или второй? Исключения есть в обоих — давайте посмотрим на логи каждого. Как часто вы ловили себя за таким занятием? Наша работа больше похожа на детективов программного обеспечения, а не разработчиков…
Это широко распространённая проблема в микросервисах и решается она распределёнными системами трассировки, в которых сервисы передают друг другу уникальный заголовок, после чего эта информация перенаправляется в систему трассировки, где она сопоставляется с данными запроса. Вот иллюстрация:
Для идентификации запроса используется TraceId
В Istio используется Jaeger Tracer, который реализует независимый от вендоров фреймворк OpenTracing API. Получить доступ к пользовательского интерфейсу Jaeger можно следующей командой:
Теперь зайдите на http://localhost:16686/ и выберите сервис sa-web-app. Если сервис не показан в выпадающем меню — проявите/сгенерируйте активность на странице и обновите интерфейс. После этого нажмите на кнопку Find Traces, которая покажет самые последние трейсы — выберите любой — покажется детализированная информация по всем трейсам:
Этот трейс показывает:
(A) За проброс заголовков отвечает Istio; (B) За заголовки отвечают сервисы
Istio делает основную работу, т.к. генерирует заголовки для входящих запросов, создаёт новые span’ы в каждом sidecare’е и пробрасывает их. Однако без работы с заголовками внутри сервисов полный путь трассировки запроса будет утерян.
Необходимо учитывать (пробрасывать) следующие заголовки:
Это несложная задача, однако для упрощения её реализации уже существует множество библиотек — например, в сервисе sa-web-app клиент RestTemplate пробрасывает эти заголовки, если просто добавить библиотеки Jaeger и OpenTracing в его зависимости.
Заметьте, что приложение Sentiment Analysis демонстрирует реализации на Flask, Spring и ASP.NET Core.
Теперь, когда стало ясно, что мы получаем из коробки (или почти «из коробки»), рассмотрим вопросы тонко настраиваемой маршрутизации, управления сетевым трафиком, безопасности и т.п.!
Прим. перев.: об этом читайте в следующей части материалов по Istio от Rinor Maloku, переводы которых последуют в нашем блоге в ближайшее время. UPDATE (14 марта): Вторая часть уже опубликована.



