Операторы (итераторы) плана выполнения в SQL Server
При исследовании плана выполнения запроса некоторые операторы возникают снова и снова в качестве виновников многих проблем с производительностью.
Здесь я хочу рассмотреть те операторы плана выполнения, которые я обычно ищу в первую очередь, когда решаю проблемы производительности. Наличие этих операторов в ваших планах не обязательно плохо, но стоит их дважды проверить на предмет причины узкого места производительности запроса.
Index Seek и Index Scan
В целом, это довольно хорошее обобщение. Однако часто важно проверить, что делают ваши операторы поиска и сканирования, поскольку это может быть не всегда то, что вы ожидали.
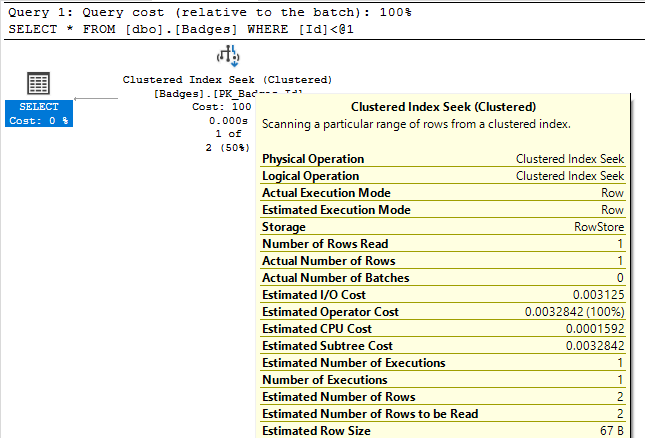
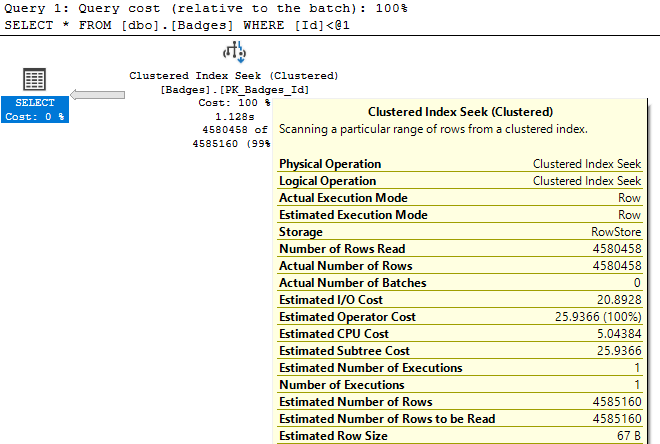
Например, взгляните на свойство Actual Number of Rows (фактическое число строк) для этих двух операторов index seek:
В первом результирующем наборе мы видим, что index seek возвращает 1 строку на основании предложения WHERE нашего запроса. Это та производительность, которая бы нам понравилась! Однако во втором запросе SQL Server «ищет» 4 миллиона строк. Когда index seek возвращает 4 миллиона строк, это необязательно плохо, если именно это и требовалось от запроса. Этот пример показывает, что не все поисковые операции сильно таргетированы и быстро возвращают результат, как вы это могли бы ожидать, видя в плане оператор index seek.
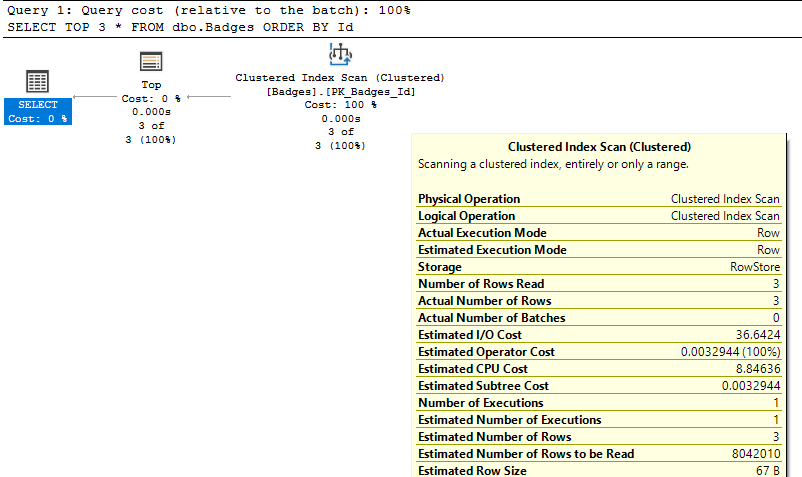
Как и то, что index scan не обязательно означает плохую производительность:
В этом случае сканирование индекса возвращает только 3 записи. Вы не смогли бы получить лучшую производительность, чем ту, которую уже имеете, даже если вы попытаетесь перестроить запрос/индексы, чтобы добиться операции Index Seek.
RID Lookup и Key Lookup
Еще одна пара операторов, на которые я обращаю внимание в плане запроса при анализе производительности, это операторы RID Lookup (поиск идентификатора записи) и Key Lookup (поиск ключа).
Поиск ключей имеет больше нюансов. SQL Server использует Key Lookup, когда он знает, что с большей эффективностью может использовать некластеризованный индекс, а затем перейти к кластерзованному индексу для поиска оставшихся значения строк, которые отсутствуют в некластеризованном индексе.
Однако, если все, что нужно SQL Server от операции Key Lookup, это единственный столбец данных, возможно, проще всего добавить этот столбец в ваш существующий некластеризованный индекс. Да, размер индекса увеличится на один столбец, но если SQL Server сможет избежать необходимости обращаться к двум индексам для извлечения всех необходимых данных, это, вероятно, в целом окажется более эффективным.
Sort (сортировка)
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать их, насколько это возможно.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, еще одной возможностью является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. Замена единственного оператора сортировки на индексную временную таблицу не даст выигрыша в производительности. Но если вы можете повторно использовать временную таблицу неоднократно в плане выполнения вашего запроса, то вы получите чистую экономию.
Spools
Спулы бывают разных типов, но большинство из них можно сформулировать как операторы, которые сохраняют промежуточную таблицу результатов в tempdb.
SQL Server часто использует спул для обработки сложных запросов, преобразуя данные в рабочую таблицу в базе tempdb для использования её данных в последующих операциях. Побочным эффектом здесь является необходимость записи данных на диск в tempdb.
Когда я вижу операцию спула, то, первую очередь, пытаюсь найти способ перезаписи запроса, чтобы избежать спула. Если это не получается, использую метод «разделяй и властвуй» для временных таблиц, который может также заменить спул, обеспечивая больший контроль по сравнению с тем, как SQL Server записывает и индексирует данные в tempdb.
Соединения
Интересно выделить соединения слиянием (Merge join), поскольку я редко вижу их в реальных запросах. Они вызывают радость, а не беспокойство, так как они, как правило, являются наиболее эффективными из операторов логического соединения.
Соединения вложенными циклами (Nested loops join), как раз наоборот, я вижу часто. Обычно я не уделяю им много внимания, если что-то не покажется мне подозрительным в их окружении. Nested loops join выполняют довольно эффективное соединение относительно небольших наборов данных.
Я всегда тщательно исследую Hash match join. Эти операторы соединения обычно выбираются оптимизатором запросов по одной из двух причин:
1. Соединяемые наборы данных настолько велики, что они могут быть обработаны только с помощью hash match join. 2. Наборы данных не упорядочены по столбцам соединения, и SQL Server думает, что вычисление хэшей и цикл по ним будет быстрей, чем сортировка данных.
Для первого сценария вы мало что можете сделать, если не найти способа соединять меньшие объемы данных.
Второй сценарий полезно рассмотреть немного более внимательно. Если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этого более быстрый алгоритм соединения.
Параллелизм (Parallelism)
Операторы Parallelism обычно считаются хорошими вещами: SQL Server дробит ваши данные на множество частей для асинхронной обработки на множестве процессоров, сокращая общее время работы, требуемое для выполнения вашего запроса.
Однако параллелизм может стать плохим, если ВСЕ (или большинство) запросов используют его. Параллелизм не магия, процессоры по-прежнему выполняют тот же самый объем работы (и отнимают ресурсы у других запросов, которые могут быть запущены), плюс дополнительная нагрузка, которую вы должны учесть, на SQL Server по дроблению и последующему объединению всех данных из множества потоков процессоров.
Я обычно подозреваю параллелизм, если оказывается, что большинство исследуемых запросов на сервере производят параллельные планы. Если это так, я могу рассмотреть вопрос о пересмотре порогового значения стоимости для настройки параллелизма, если оно установлено слишком низким.
Описание операторов плана выполнения запроса в Microsoft SQL Server. Какая иконка, что обозначает
Приветствую Вас на сайте Info-Comp.ru! Продолжаем рассматривать план выполнения запроса и сегодня мы поговорим об операторах, которые наиболее часто встречаются в плане запроса, узнаем, что означает тот или иной оператор и как обозначается, т.е. как он выглядит в плане.
Напомню, ранее мы уже рассматривали план выполнения запроса, например, в следующих статьях:
Операторы плана выполнения запроса
Чтобы создать план выполнения запроса, который показывает, как именно будет достигнут результат выполнения SQL инструкции, оптимизатор запросов использует операторы, которые описывают конкретные действия.
Операторы плана запроса делятся на логические и физические:
Результатом плана выполнения запроса является дерево физических операторов, которое как раз и описывает, как именно SQL Server будет выполнять SQL инструкцию, т.е. как именно будет достигнут результат этой SQL инструкции.
План запроса можно посмотреть графически в SQL Server Management Studio, как это делается, я показывал в статье – Как посмотреть план запроса в SQL Server.
Ну а сейчас давайте рассмотрим конкретные операторы, которые наиболее часто мы будем видеть в плане выполнения запроса.
Иконка
Оператор
Описание
Assert
Данный оператор предназначен для проверки условий. Например, он проверяет целостность ссылок или гарантирует, что скалярный вложенный запрос возвращает одну строку.
Для каждой входной строки оператор Assert вычисляет выражение в столбце «Аргумент» плана запроса:
Этот оператор использует поисковые возможности индексов для получения строк из кластеризованного индекса, т.е. выполняет поиск в кластеризованном индексе.
Argument содержит имя кластеризованного индекса и предикат SEEK. Подсистема хранилища использует этот индекс для обработки только тех строк, которые удовлетворяют данному предикату. Также может включаться предикат WHERE, в котором подсистема хранилища вычисляет выражение для всех строк, удовлетворяющих предикату SEEK, но это не является обязательным.
Clustered Index Delete
Оператор удаляет строки из кластеризованного индекса. Если в Argument есть предикат WHERE, то удаляются только строки, удовлетворяющие условиям предиката.
Clustered Index Insert
Оператор вставляет в кластеризованный индекс новые строки. Argument содержит предикат SET, который указывает значение, устанавливаемое для каждого столбца.
Index Scan
Оператор Index Scan предназначен для сканирования всех записей некластеризованного индекса. Если в Argument присутствует необязательный предикат WHERE, то возвращаются только те строки, которые удовлетворяют условию, указанному в этом предикате.
Index Seek
Данный оператор выполняет поиск в некластеризованном индексе.
Argument содержит имя некластеризованного индекса и предикат SEEK. Подсистема хранилища использует этот индекс для обработки только тех строк, которые удовлетворяют данному предикату. Также может включаться предикат WHERE, в котором подсистема хранилища вычисляет выражение для всех строк, удовлетворяющих предикату SEEK.
Поиск в индексе является более эффективной операцией, чем сканирование индекса, однако если в запросе запрашивается большая часть данных индекса, то гораздо быстрее будет один раз просканировать индекс, чем осуществлять поиск каждого значения. Таким образом, Index Seek не всегда эффективнее, чем Index Scan, SQL Server сам определяет, что выбрать в том или ином случае на основе внутреннего порогового значения.
Key Lookup
Данный оператор выполняет поиск данных в кластеризованном индексе. Возникает он, например, тогда, когда происходит получение данных из некластеризованного индекса, однако один из столбцов, указанных в запросе, отсутствует в этом некластеризованном индексе, т.е. в данном случае SQL Server по ключу обращается в кластеризованный индекс за недостающими данными. В большинстве случаев можно выиграть в производительности, избавившись от этого оператора, например, создав покрывающий индекс.
Заметка! Проектирование индексов для оптимизации запросов в Microsoft SQL Server.
RID Lookup
Этот оператор похож на Key Lookup, однако он выполняет поиск данных не в кластеризованном индексе, а в таблице «куче». Иными словами, если Вы видите данный оператор, значит у Вас есть таблица «куча», что в большинстве случаев является менее эффективным способом хранения данных, чем их хранение в кластеризованном индексе.
Compute Scalar
Данный оператор вычисляет выражение и выдает скалярную величину. Затем эту величину можно вернуть в качестве результата или использовать в запросе, например, в предикате фильтра или соединения.
Constant Scan
Этот оператор вводит в запрос одну или несколько константных строк. Он возникает, например, когда мы используем конструктор табличных значений VALUES.
Concatenation
Данный оператор принимает данные с нескольких входов, объединяет их, и возвращает один общий результат. Оператор Concatenation мы можем встретить в плане запроса, когда используем конструкцию UNION ALL.
Filter
Этот оператор принимает входные данные и возвращает только те строки, которые удовлетворяют критерию фильтрации (предикату).
Nested Loops
Это оператор вложенных циклов. Он выполняет логические операции соединения. Иными словами, данный оператор возникает, когда мы соединяем несколько таблиц, при этом один набор данных соединения имеет небольшой размер (обычно менее десяти строк), а другой набор данных сравнительно большой и индексирован по соединяемым столбцам.
Nested Loops встречается достаточно часто, так как является самой быстрой операцией соединения на небольшом объеме данных.
Если оба набора данных будут достаточно большие, то данный способ соединения будет крайне неэффективен.
Заметка! Что нужно знать и уметь разработчику T-SQL. Технологии, языки, навыки.
Hash Match
Данный оператор также возникает при соединении таблиц, однако здесь используется другой алгоритм.
Оператор Hash Match строит хэш-таблицу при помощи вычисления хэш-значения для каждой строки одного набора данных. Затем для каждой строки другого набора данных, с помощью той хэш-функции, он вычисляет хэш-значение и осуществляет поиск совпадений по хэш-таблице.
Такой способ физического соединения данных возникает тогда, когда мы обрабатываем большие, несортированные и неиндексированные наборы данных, при этом он делает это достаточно эффективно.
Merge Join
Еще один способ соединения таблиц. Однако в данном случае требуется, чтобы оба набора данных были отсортированы.
Данный способ соединения наиболее эффективен в тех случаях, когда два набора данных достаточно велики, при этом они отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов).
Если оба набора данных велики и имеют сходные размеры, но не отсортированы, то соединение слиянием с предварительной сортировкой и хэш-соединение (Hash Match) имеют примерно одинаковую производительность. Однако хэш-соединения часто выполняются быстрее, если наборы данных значительно отличаются по размеру.
Принцип работы данного оператора следующий: он получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется следующая строка и снова происходит сравнение. Этот процесс повторяется, пока не будет выполнена обработка всех строк, т.е. пока этот, назовем его курсор, не дойдет до конца.
Adaptive Join
Данный оператор появился относительно недавно, и он также предназначен для соединения таблиц. Однако Adaptive Join откладывает выбор метода соединения до завершения сканирования первых входных данных, в результате у SQL Server более точные сведения о том, какой способ соединения будет эффективней: Nested Loops или Hash Match.
Таким образом, во время выполнения план запроса может динамически переключаться на более эффективный алгоритм соединения без перекомпиляции.
Заметка! Статистика в Microsoft SQL Server – что это такое и для чего она нужна.
Index Spool
Оператор Index Spool сканирует входные данные, и помещает их в буфер, который хранится в базе данных tempdb, этот буфер существует только в течение выполнения запроса. При этом для этих временных данных создается некластеризованный индекс, который позволяет использовать поддерживаемый индексами механизм поиска для вывода только строк, отвечающих требованиям предиката SEEK.
Примечание!В большинстве случаев задействование tempdb в запросе отрицательно сказывается на его скорости выполнения, т.е. желательно проанализировать и переписать запрос так, чтобы исключить Spool в tempdb (во всех его проявлениях).
Table Spool
Оператор Table Spool сканирует входную таблицу и помещает копию каждой строки в буфер, который находится в базе данных tempdb и существует только в течение времени жизни запроса.
Spool
Оператор Spool сохраняет промежуточные результаты запроса в базе данных tempdb.
Table Scan
Данный оператор получает строки из таблицы, указанной в столбце Аргумент плана выполнения запроса.
Если предикат WHERE присутствует в столбце Argument, возвращаются только строки, удовлетворяющие условию, указанному в этом предикате.
Sort
Оператор Sort сортирует входящие строки. Сортировка является достаточно трудоемкой операцией, поэтому лучше ее избегать, например, это можно достигнуть путем создания индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Top
Оператор Top просматривает входные данные и возвращает только указанное число или процент строк.
Stream Aggregate
Это оператор — статистическое выражение потока, он группирует строки в один или несколько столбцов и вычисляет одно или несколько агрегатных выражений, возвращенных запросом. Данный оператор возникает, когда мы используем GROUP BY и агрегатные выражения.
Parallelism
Оператор Parallelism делит данные на несколько частей для параллельной обработки, тем самым сокращая общее время выполнения запроса.
В большинстве случаев параллельная обработка является эффективной операцией, однако это создает дополнительную нагрузку на процессоры и в некоторых случаях, например, когда большинство запросов на сервере используют параллелизм, она может вызвать снижение общей производительности сервера.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Основные операции плана выполнения SQL Server
Данная статья представляет собой описание основных операций, отображаемых в планах выполнения запросов СУБД MS SQL Server.
Index Seek
Поиск по некластеризованному индексу. В большинстве случаев является хорошим для производительности, так как представляет собой прямой доступ SQL Server к требуемым строкам данных. Однако это вовсе не означает, что он всегда работает быстро, например, если он возвращает большое число строк, то по производительности он будет практически равен Index Scan.
Index Scan
Сканирование некластеризованного индекса. Обычно наличие этой операции плохо отражается на производительности, поскольку она предполагает последовательное чтение индекса для извлечения большого числа строк, приводя к более медленной обработке. Но бывают исключения, например, применение директивы TOP, ограничивающей число возвращаемых записей; если возвращать всего несколько строк, то операция сканирования будет выполняться достаточно быстро, и вы не сможете получить лучшую производительность, чем ту, которую уже имеете, даже если вы попытаетесь перестроить запрос/индексы, чтобы добиться операции Index Seek.
RID Lookup
Поиск идентификатора записи, является узким местом производительности запроса. Но это легко исправить: если вы видите этот оператор, это означает, что у вас отсутствует кластеризованный индекс на таблице. По крайней мере, вы должны добавить кластеризованный индекс, и тут же получите некоторый рост производительности для большинства ваших запросов.
Key Lookup
Поиск ключей. Возникает, когда SQL Server предполагает, что он с большей эффективностью может использовать некластеризованный индекс, а затем перейти к кластерзованному индексу для поиска оставшихся значения строк, которые отсутствуют в некластеризованном индексе. Это не всегда плохо: обращение SQL Server к кластеризованному индексу для извлечения недостающих значений довольно эффективный метод по сравнению с необходимостью создавать и поддерживать совершенно новые индексы.
Однако, если все, что нужно SQL Server от операции Key Lookup, это единственный столбец данных, гораздо проще добавить этот столбец в ваш существующий некластеризованный индекс. Размер индекса увеличится на один столбец, но SQL Server сможет избежать необходимости обращаться к двум индексам для извлечения всех необходимых данных и это в целом окажется более эффективным решением.
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать ее, насколько это возможно.
Простой способ избежать оператора сортировки – иметь данные, хранящиеся в предварительно упорядоченном виде. Это может быть выполнено созданием индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, то еще одним выходом является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. В таком случае, если вы будете повторно использовать временную таблицу в плане выполнения вашего запроса, то вы получите чистую экономию.
Spool
Спулы бывают разных типов, но большинство из них можно сформулировать как операторы, которые сохраняют промежуточную таблицу результатов в tempdb.
SQL Server часто использует спул для обработки сложных запросов, преобразуя данные во временную таблицу в базе tempdb для использования её данных в последующих операциях. Побочным эффектом здесь является необходимость записи данных на диск.
Для ускорения выполнения запроса можно попытаться найти способ его перезаписи таким образом, чтобы избежать спула. Если это не получается, использую метод «разделяй и властвуй» для временных таблиц, который может также заменить спул, обеспечивая больший контроль по сравнению с тем, как SQL Server записывает и индексирует данные в tempdb.
Merge Join
Соединение слиянием. Редко встречаются в реальных запросах, как правило, являются наиболее эффективными из операторов логического соединения.
Оптимизатор выбирает использование соединение слиянием, когда входные данные уже отсортированы или SQL Server может выполнить сортировку данных с относительно небольшой стоимостью.
Операция неприменима, если входные данные не отсортированы.
Nested Loops Join
Соединение вложенными циклами. Встречаются очень часто. Выполняют довольно эффективное соединение относительно небольших наборов данных.
Соединение вложенными циклами не требует сортировки входных данных. Однако производительность можно улучшить при помощи сортировки источника входных данных; SQL Server сможет выбрать более эффективный оператор, если оба входа отсортированы.
Операция неприменима, если данные слишком велики для хранения в памяти.
Hash Match Join
Операция используется всегда, когда невозможно применить другие виды соединения. Она выбираются оптимизатором запросов по одной из двух причин:
При первом сценарии трудно оптимизировать выполнение запроса, если только не найти способа соединять меньшие объемы данных.
При втором же сценарии, если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этой операции более быстрый алгоритм соединения.
Операторы Hash Match Join достаточно эффективны тогда, когда не сбрасывают данные в tempdb.
Parallelism
Операторы параллелизма обычно считаются хорошими вещами: SQL Server дробит ваши данные на множество частей для асинхронной обработки на множестве процессоров, сокращая общее время работы, требуемое для выполнения вашего запроса.
Однако параллелизм может стать плохим, если большинство запросов используют его. При параллелизме процессоры по-прежнему выполняют тот же самый объем работы, что и без него, тем самым отнимая ресурсы у других запросов, которые могут быть запущены, плюс накладывается дополнительная нагрузка на SQL Server по дроблению и последующему объединению всех данных из множества нитей выполнения.
Если параллелизм является узким местом производительности, можно рассмотреть вопрос об изменении порогового значения стоимости для настройки параллелизма, если оно установлено слишком низким.
Stream Aggregate
Статистическое выражение потока. Группирует строки в один или несколько столбцов и вычисляет одно или несколько агрегатных выражений (пример: COUNT, MIN, MAX, SUM и AVG), возвращенных запросом. Выход этого оператора может быть использован последующими операторами запроса, возвращен клиенту или то и другое. Оператору Stream Aggregate необходимы входные данные, упорядоченные по группируемым столбцам. Оптимизатор использует перед этим оператором оператор Sort, если данные не были ранее отсортированы оператором Sort или используется упорядоченный поиск или просмотр в индексе.
Compute Scalar
Оператор Compute Scalar вычисляет выражение и выдает вычисляемую скалярную величину. Затем эту величину можно вернуть пользователю или сослаться на нее в каком-либо запросе, а также выполнить эти действия одновременно. Примерами одновременного использования этих возможностей являются предикаты фильтра или соединения. Всегда возвращает одну строку. Часто применяется для того, чтобы конвертировать результат Stream Aggregate в ожидаемый на выходе тип int (когда Stream Aggregate возвращает bigint в случае с COUNT, AVG при типах столбцов int).
Concatenation
Оператор просматривает несколько входов, возвращая каждую просмотренную строку. Используется в запросах с UNION ALL. Копирует строки из первого входного потока в выходной поток и повторяет эту операцию для каждого дополнительного входного потока.
Filter
Оператор просматривает входные данные и возвращает только те строки, которые удовлетворяют критерию фильтрации (предикату).