Сравнение способов резервного копирования

Подготовку нового сервера к работе следует начинать с настройки резервного копирования. Все, казалось бы, об этом знают — но порой даже опытные системные администраторы допускают непростительные ошибки. И дело здесь не только в том, что задачу настройки нового сервера нужно решать очень быстро, но еще и в том, что далеко не всегда бывает ясно, какой способ резервного копирования нужно использовать.
Конечно, идеальный способ, который бы всех устраивал, создать невозможно: везде есть свои плюсы и минусы. Но в то же время вполне реальным представляется подобрать способ, максимально подходящий под специфику конкретно проекта.
В этой статье мы расскажем об основных способах резервного копирования серверов под управлением Linux-систем и о наиболее типичных проблемах, с которыми могут столкнуться новички в этой очень важной области системного администрирования.
Схема организации хранения и восстановления из резервных копий
Часто причиной восстановления данных служит повреждение файловой системы или дисков. Т.е. бекапы нужно хранить где-то на отдельном сервере-хранилище. В этом случае проблемой может стать «ширина» канала передачи данных. Если у вас выделенный сервер, то резервное копирование очень желательно выполнять по отдельному сетевому интерфейсу, а не на том же, что выполняет обмен данных с клиентами. Иначе запросы вашего клиента могут не «поместиться» в ограниченный канал связи. Или из-за трафика клиентов бекапы не будут сделаны в срок.

Далее нужно подумать о схеме и времени восстановления данных с точки зрения хранения бекапов. Может быть вас вполне устраивает, что бекап выполняется за 6 часов ночью на хранилище с ограниченной скоростью доступа, однако восстановление длиной в 6 часов вас вряд ли устроит. Значит доступ к резервным копиям должен быть удобным и данные должны копироваться достаточно быстро. Так, например, восстановление 1Тб данных с полосой в 1Гб/с займет почти 3 часа, и это если вы не «упретесь» в производительность дисковой подсистемы в хранилище и сервере. И не забудьте прибавить к этому время обнаружения проблемы, время на решение об откате, время проверки целостности восстановленных данных и объем последующего недовольства клиентов/коллег.
Инкрементальное резервное копирование
При инкрементальном резервном копировании копируются только файлы, которые были изменены со времени предыдущего бэкапа. Последующее инкрементальное резервное копирование добавляет только файлы, которые были изменены с момента предыдущего. В среднем инкрементальное резервное копирование занимает меньше времени, так как копируется меньшее количество файлов. Однако процесс восстановления данных занимает больше времени, так как должны быть восстановлены данные последнего полного резервного копирования, плюс данные всех последующих инкрементальных резервных копирований. При этом в отличие от дифференциального копирования, изменившиеся или новые файлы не замещают старые, а добавляются на носитель независимо.
Инкрементальное копирование чаще всего производится с помощью утилиты rsync. С его помощью можно сэкономить место в хранилище, если количество изменений за день не очень велико. Если измененные файлы имеют большой размер, то они будут скопированы полностью без замены предыдущих версий.
С более подробной информацией о работе rsync можно ознакомиться на официальном сайте.
Для каждого файла rsync выполняет очень большое количество операций. Если файлов на сервере много или если процессор сильно загружен, то скорость резервного копирования будет существенно снижена.
Из опыта можем сказать, что проблемы на SATA-дисках (RAID1) начинаются примерно после 200G данных на сервере. На самом деле всё, конечное же, зависит от количества inode. И в каждом случае эта величина может смещаться как в одну так и в другую сторону.
После определенной черты время выполнения резервного копирования будет очень долгим или попросту не будет отрабатывать за сутки.
Для того, чтобы не сравнивать все файлы, есть lsyncd. Этот демон собирает информацию об изменившихся файлах, т.е. мы уже заранее будем иметь готовый их список для rsync. Следует, однако, учесть, что он дает дополнительную нагрузку на дисковую подсистему.
Дифференциальное резервное копирование
При дифференциальном резервном копировании каждый файл, который был изменен с момента последнего полного резервного копирования, копируется всякий раз заново. Дифференциальное копирование ускоряет процесс восстановления. Все, что вам необходимо — это последняя полная и последняя дифференциальная резервная копия. Популярность дифференциального резервного копирования растет, так как все копии файлов делаются в определенные моменты времени, что, например, очень важно при заражении вирусами.
Дифференциальное резервное копирование осуществляется, например, при помощи такой утилиты, как rdiff-backup. При работе с этой утилитой возникают те же проблемы, что и при инкрементальном резервном копировании.
В целом, если при поиске разницы в данных осуществляется полный перебор файлов, проблемы такого рода резервирования аналогичны проблемам с rsync.
Хотим отдельно отметить, что если в вашей схеме резервного копирования каждый файл копируется отдельно, то стоит удалять/исключать ненужные вам файлы. Например, это могут быть кеши CMS. В таких кешах обычно очень много маленьких файлов, потеря которых не скажется на корректной работе сервера.
Полное резервное копирование
Полное копирование обычно затрагивает всю вашу систему и все файлы. Еженедельное, ежемесячное и ежеквартальное резервное копирование подразумевает создание полной копии всех данных. Обычно оно выполняется по пятницам или в течение выходных, когда копирование большого объёма данных не влияет на работу организации. Последующие резервные копирования, выполняемые с понедельника по четверг до следующего полного копирования, могут быть дифференциальными или инкрементальными, главным образом для того, чтобы сохранить время и место на носителе. Полное резервное копирование следует проводить по крайней мере еженедельно.
В большинстве публикаций по соответствующей тематике рекомендуется полное резервное копирование выполнять один или два раза в неделю, а в остальное время время — использовать инкрементальное и дифференциальное. В таких советах есть свой резон. В большинстве случаев полного резервного копирования раз в неделю вполне достаточно. Выполнять его повторно имеет смысл в том случае, если у вас нет возможности на стороне хранилища актуализировать полный бекап и для обеспечения гарантии корректности резервной копии (это может понадобиться, например, в случаях, если вы по тем или иным причинам не доверяете имеющимся у вас скриптам или софту для резервного копирования.
Рассмотрим их характерные особенности на примере:
Резервировать мы будем только /home. Все остальное можно быстро восстановить вручную. Можно также развернуть сервер системой управления конфигурациями и подключить к нему наш /home.
Полное резервное копирование на уровне файловой системы
Типичный представитель: dump.
Утилита создает «дамп» файловой системы. Можно создавать не только полную, но и инкрементальную резервную копию. dump работает с таблицей inode и «понимает» структуру файлов (так, разреженные файлы сжимаются).
Создавать дамп работающей файловой системы «глупо и опасно», потому что ФС может изменяться во время создания дампа. Его надо создавать со снапшота (чуть позже мы обсудим особенности работы со снапшотами более подробно), отмонтированной или замороженной ФС.
Такая схема так же зависит от количества файлов, и время её выполнения будет расти с ростом количества данных на диске. В то же время у dump скорость работы выше, чем у rsync.
В случае, если требуется возобновить не резервную копию целиком, а, например, только пару случайно испорченных файлов), извлечение таких файлов утилитой restore может занять слишком много времени
Полное резервное копирование на уровне устройств
Например, с одним MySQL это будет выглядеть так:
* Коллеги рассказывают истории как у кого-то «read lock» иногда приводил к дедлокам, но на моей памяти такого не было ни разу.
Далее можно копировать снапшот в хранилище. Главное — следить за тем, чтобы во время копирования снапшот не самоуничтожился и не забывать, что при создании снапшота скорость записи упадет в разы.
Бекапы СУБД можно создать отдельно (например, используя бинарные логи), устранив тем самым простой на время сброса кеша. А можно создавать дампы в хранилище, запустив там инстанс СУБД. Резервное копирование разных СУБД — это тема для отдельных публикаций.
Копировать снапшот можно с использованием докачки (например, rsync с патчем для копирования блочных устройств bugzilla.redhat.com/show_bug.cgi?id=494313), можно по блокам и без шифрования (netcat, ftp). Можно передавать блоки в сжатом виде и монтировать их в хранилище при помощи AVFS, и примонтировать на сервере раздел с бекапами по SMB.
Сжатие устраняет проблемы скорости передачи, забития канала и места в хранилище. Но, однако если вы не используете AVFS в хранилище, то на восстановление только части данных у вас уйдет много времени. Если будете использовать AVFS, то столкнетесь с её «сыростью».
Альтернатива сжатию блоками — squashfs: можно подмонтировать, к примеру, по Samba раздел к серверу и выполнить mksquashfs, но эта утилита так же работает с файлами, т.е. зависит от их количества.
К тому же при создании squashfs тратится достаточно много ОЗУ, что может легко привести к вызову oom-killer.
Безопасность
Необходимо обезопасить себя от ситуации когда хранилище или ваш сервер будут взломаны. Если взломан сервер, то лучше чтобы не было прав на удаление/изменение файлов в хранилище у пользователя, который записывает туда данные.
Если взломано хранилище, то права бекапного пользователя на сервере так же желательно ограничить по максимуму.
Если канал резервного копирования может быть прослушан, то нужны средства шифрования.
Заключение
У каждой системы резервного копирования свои минусы и свои плюсы. В этой статье мы постарались осветить часть нюансов при выборе системы резервного копирования. Надеемся, что они помогут нашим читателям.
В качестве решений по резервному копированию, можно использовать supload и наше облачное хранилище.
Читателей, которые не могут оставлять комментарии здесь, приглашаем к нам в блог.
Инкрементальные бэкапы postgresql с pgbackrest — курс молодого бойца от разработчика
Я — разработчик. Я пишу код, с базой данных взаимодействую лишь как пользователь. Я ни в коем случае не претендую на должность системного администратора и, тем более, dba. Но…
Так вышло, что мне нужно было организовать резервное копирование postgresql базы данных. Никаких облаков — держи SSH и сделай, чтобы все работало и не просило денег. Что мы делаем в таких случаях? Правильно, пихаем pgdump в cron, каждый день бэкапим все в архив и если совсем разошлись — отправляем этот архив куда-нибудь подальше.
В этот раз сложность состояла в том, что по планам база должна была расти примерно на +- 100 МБ в день. Разумеется, уже через пару недель желание бэкапить все pgdump’ом отпадет. Тут на помощь приходят инкрементальные бэкапы.
Интересно? Добро пожаловать под кат.
Инкрементальный бэкап — разновидность резервной копии, когда копируются не все файлы источника, а только новые и измененные с момента создания предыдущей копии.
Как и любой разработчик, СОВЕРШЕННО не желающий (на тот момент) разбираться в тонкостях postgres я хотел найти зеленую кнопку. Ну, знаете, как в AWS, DigitalOcean: нажал одну кнопку — получил репликацию, нажал вторую — настроил бэкапы, третью — все откатил на пару часов назад. Кнопки и красивого GUIшного инструмента я не нашел. Если вы знаете такой (бесплатный или дешевый) — напишите об этом в комментариях.
Погуглив я нашел два инструмента pgbarman и pgbackrest. С первым у меня просто не задалось (очень скудная документация, пытался все поднять по старинным мануалам), а вот у второго документация оказалась на уровне, но и не без изъяна. Чтобы упростить работу тем, кто столкнется с подобной задачей и была написана данная статья.
Дочитав данную статью вы научитесь делать инкрементальные бекапы, сохранять их на удаленный сервер (репозиторий с бэкапами) и восстанавливать их в случае утери данных или иных проблем на основном сервере.
Подготовка
Для воспроизведения мануала вам понадобятся два VPS. Первый будет хранилищем (репозиторием, на котором будут лежат бэкапы), а второй, собственно, сам сервер с postgres (в моем случае 11 версия postgres).
Подразумевается, что на сервере с postgres у вас есть root, sudo пользователь, пользователь postgres и сам postgres установлен (пользователь postgres создается автоматически при установке postgresql), а на сервере-репозитории есть root и sudo пользователь (в мануале будет использоваться имя пользователя pgbackrest).
Чтобы у вас было меньше проблем при воспроизведении инструкции — курсивом я прописываю где, каким пользователем и с какими правами я исполнял команду во время написания и проверки статьи.
Установка pgbackrest
Репозиторий (пользователь pgbackrest):
1. Скачиваем архив с pgbackrest и переносим его содержимое в папку /build:
2. Устанавливаем необходимые для сборки зависимости:
3. Собираем pgbackrest:
4. Копируем исполняемый файл в директорию /usr/bin:
5. Pgbackrest требует наличие perl. Устанавливаем:
6. Создаем директории для логов, даем им определенные права:
Postgres сервер (sudo пользователь или root):
Процесс установки pgbackrest на сервере с postgres аналогичен процессу установки на репозитории (да, pgbackrest должен стоять на обоих серверах), но в 6-ом пункте вторую и последнюю команды:
Настройка взаимодействия между серверами через passwordless SSH
Для того, чтобы pgbackrest корректно работал, необходимо настроить взаимодействие между postgres сервером и репозиторием по файлу-ключу.
Репозиторий (пользователь pgbackrest):
Создаем пару ключей:
Внимание! Указанные выше команды выполняем без sudo.
Postgres сервер (sudo пользователь или root):
Создаем пару ключей:
Репозиторий (sudo пользователь):
Копируем публичный ключ postgres сервера на сервер-репозиторий:
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя postgres сервера!
Postgres сервер (sudo пользователь):
Копируем публичный ключ репозитория на сервер с postgres:
На данном шаге попросит пароль от root пользователя. Вводить нужно именно пароль root пользователя репозитория!
Репозиторий (root пользователь, для чистоты эксперимента):
Postgres сервер (root пользователь, для чистоты эксперимента):
Убеждаемся, что без проблем получаем доступ.
Настройка postgres сервера
Postgres сервер (sudo пользователь или root):
1. Разрешим «стучаться» на postgres сервер с внешних ip. Для этого отредактируем файл postgresql.conf (находится в папке /etc/postgresql/11/main), добавив в него строчку:
Если такая строка уже есть — либо раскомментируйте ее, либо установите значение параметра как ‘*’.
В файле pg_hba.conf (так же находится в папке /etc/postgresql/11/main) добавляем следующие строчки:
2. Внесем необходимые настройки в postgresql.conf (он находится в папке /etc/postgresql/11/main) для работы pgbackrest:
3. Внесем необходимые настройки в файл конфигурации pgbackrest (/etc/pgbackrest/pgbackrest.conf):
4. Перезагрузим postgresql:
Настройка сервера-репозитория
Репозиторий (pgbackrest пользователь):
Внесем необходимые настройки в файл конфигурации pgbackrest
(/etc/pgbackrest/pgbackrest.conf):
Создание хранилища
Репозиторий (pgbackrest пользователь):
Создаем новое хранилище для кластера main:
Проверка
Postgres сервер (sudo пользователь или root):
Проверяем на postgres сервере:
Репозиторий (pgbackrest пользователь):
Проверяем на сервере-репозитории:
Убеждаемся, что в выводе видим строку «check command end: completed successfully».
Устали? Переходим к самому интересному.
Делаем бэкап
Репозиторий (pgbackrest пользователь):
1. Выполняем резервное копирование:
2. Убеждаемся, что бэкап был создан:
Pgbackrest создаст первый полный бэкап. При желании вы можете запустить команду бэкапа повторно и убедиться, что система создаст инкрементальный бэкап.
Если вы хотите повторно сделать полный бэкап, то укажите дополнительный флаг:
Если вы хотите подробный вывод в консоль, то также укажите:
Восстанавливаем бэкап
Postgres сервер (sudo пользователь или root):
1. Останавливаем работающий кластер:
2. Восстанавливаемся из бэкапа:
Чтобы восстановить базу в состояние последнего ПОЛНОГО бэкапа используйте команду без указания recovery_target:
Важно! После восстановления может оказаться так, что база зависнет в режиме восстановления (будут ошибки в духе ERROR: cannot execute DROP DATABASE in a read-only transaction). Честно говоря, я еще не понял, с чем это связано. Решается следующим образом (нужно будет малость подождать после исполнения команды):
На самом деле, есть возможность восстановить конкретный бэкап по его имени. Здесь я лишь укажу ссылку на описание данной фичи в документации. Разработчики советуют использовать данный параметр с осторожностью и объясняют почему. От себя могу добавить, что я его использовал. Если очень нужно — убедитесь, что после восстановления база вышла из recovery mode (select pg_is_in_recovery() должен показать «f») и на всякий случай сделайте полный бэкап после восстановления.
3. Запускаем кластер:
После восстановления бэкапа нам необходимо выполнить повторный бэкап:
Репозиторий (pgbackrest пользователь):
На этом все. В заключение хочу напомнить, что я ни в коем случае не пытаюсь строить из себя senior dba и при малейшей возможности буду использовать облака. В настоящее время сам начинаю изучать различные темы вроде резервного копирования, репликаций, мониторинга и т.п. и о результатах пишу небольшие отчеты, дабы сделать небольшой вклад в сообщество и оставить для себя небольшие шпаргалки.
В следующих статьях постараюсь рассказать о дополнительных фичах — восстановление данных на чистый кластер, шифрование бэкапов и публикацию на S3, бэкапы через rsync.
Инкрементально обновляемый бэкап как стратегия резервного копирования СУБД
На сегодняшний день существует множество вариантов резервного копирования СУБД Oracle, которые позволяют администраторам спать спокойно по ночам и не переживать о том, что могло бы случиться, и как можно было бы этого избежать. Также в помощь – множество программного обеспечения, позволяющего упростить ежедневные рутинные задачи.
Использование Recovery Manager (RMAN), согласно официальной документации, является рекомендованным и одним из наиболее оптимальных способов для резервного копирования и восстановления базы данных Oracle. А возможность выполнять «горячие» бэкапы, оставляя базу доступной для чтений и изменений, делает эту утилиту мощным инструментом для резервирования высокодоступных систем.
В статье я не буду говорить обо всех возможностях Recovery manager, а опишу одну из интересных стратегий резервного копирования, позволяющую по-новому взглянуть на построение системы отказоустойчивости на предприятии. Технология инкрементально обновляемого бэкапа появилась в 10-й версии Oracle. Она предоставляет те же возможности по восстановлению, что и копирование образа базы (image copy), но более быстрая и оказывает меньшую нагрузку на ресурсы системы. Также эта опция сокращает время восстановления за счет меньшего количества журналов, которые необходимо применить для актуализации данных.
Концепция
Суть сохранения данных при помощи Recovery manager в том, что мы один раз делаем полную копию базы, а затем только копируем изменения, при этом – каждый раз при выполнении инкрементального бэкапа предыдущий накатывается на образ базы, актуализируя данные. В результате наш бэкап на физическом уровне состоит всегда из копии данных и файла изменения.

Рассмотрим пример выполнения:
RUN
<
RECOVER COPY OF DATABASE
WITH TAG ‘incremental’;
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG ‘incremental’
DATABASE;
>
Эту команду мы можем поставить в расписание на ежедневное выполнение. Вот как она будет интерпретироваться:
День 0
День 1
День 2 и последующие
Рассмотрим пример команды восстановления с окном в 7 дней:
RUN
<
RECOVER COPY OF DATABASE
WITH TAG ‘incremental’
UNTIL TIME ‘SYSDATE — 7’;
BACKUP
INCREMENTAL LEVEL 1
FOR RECOVER OF COPY WITH TAG ‘incremental’
DATABASE;
>
Оптимизация
Вместе с инкрементально обновляемым бэкапом мы можем использовать еще одну технологию – BLOCK CHANGE TRACKING. При выполнении резервного копирования recovery manager исследует каждый блок данных, отслеживая изменения. Время выполнения такой процедуры прямо пропорционально размеру файлов данных. Она может быть достаточно длительной, даже если было изменено всего лишь несколько блоков. Начиная с 10-й версии в Oracle была представлена новая технология — BLOCK CHANGE TRACKING мы можем создать специальный файл, который записывает модифицированные блоки с момента предыдущего бэкапа. Затем RMAN использует его, чтобы определить изменения. Уже не нужно полностью изучать все доступные данные. Таким образом, скорость выполнения инкрементальной копии прямо пропорциональна измененным блокам. Благодаря реализации такого функционала можно существенно уменьшить время выполнения резервирования.
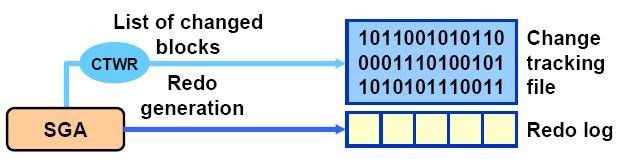
Быстрое восстановление
SWITCH DATABASE TO COPY;
RECOVER DATABASE;
Дифференциальные и инкрементальные бэкапы MySQL

Для MySQL существует широко известный инструмент по созданию резервных копий баз данных — mysqldump, который создаёт дамп посредством записи серии SQL-инструкций для восстановления таблиц и данных целевой базы данных.
Он неплохо подходит для резервного копирования небольших баз данных, но когда база данных набирает приличный «вес» и возникает необходимость резервного копирования чаще, чем раз в сутки, скорость создания и размеры дампов могут стать проблемой. В данном случае на помощь приходят утилиты, создающие копию бинарных файлов баз данных, например, такие как Percona XtraBackup.
Percona XtraBackup поддерживает «горячее» резервное копирование для серверов MySQL, Percona, MariaDB и Drizzle (бета) всех версий.
Среди преимуществ такого подхода можно выделить следующие:
Как это работает
XtraBackup начинает копировать файлы баз данных, запоминая номер транзакции на момент начала (LSN), так как копирование файлов занимает какое-то время, данные в них могут измениться, поэтому параллельно XtraBackup запускает процесс, который отслеживает файлы с логами транзакций и копирует все изменения прошедшие с начала копирования.
После того как файлы скопированы, для получения работоспособной копии XtraBackup должен выполнить этап восстановления (crash recovery), используя сохранённый лог транзакций, на данном этапе к файлам баз данных будут применены завершённые транзакции из файла лога транзакций. Транзакции, которые изменили данные, но не были завершены, будут отменены.
После этого этапа файлы баз данных можно использовать для восстановления сервера путём его остановки и копирования файлов в их первоначальное расположение — вручную или используя XtraBackup (обычно это /var/lib/mysql, если сервер MySQL настроен по умолчанию).
Дифференциальные и инкрементальные бэкапы
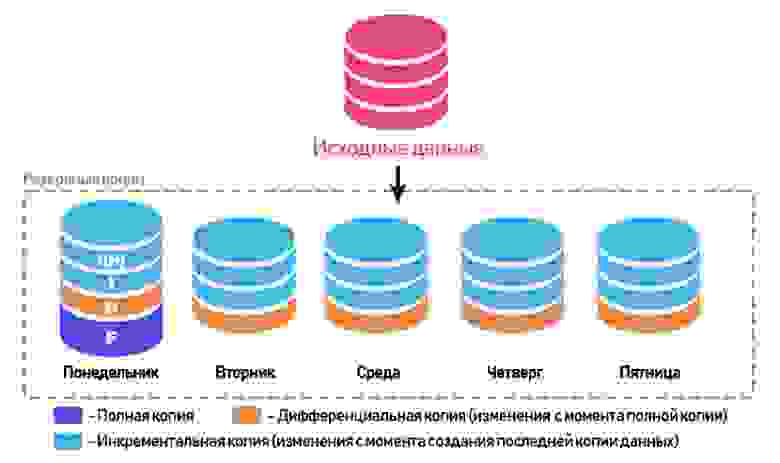
Часто бывает так, что потеря данных даже за короткий промежуток времени весьма чувствительна, и возникает необходимость делать резервное копирование как можно чаще.
Создание полных бэкапов больших баз данных чаще, чем раз в день, может быть затруднительным — как правило, из-за размера дампов, тут как раз возможность копирования только выполненных изменений будет как нельзя кстати.
В зависимости от стратегии копирования могут использоваться дифференциальные и инкрементальные бэкапы, дополнительно к полным. Дифференциальный бэкап содержит изменения в данных относительно полного бэкапа, инкрементальный — содержит изменения со времени последнего частичного бэкапа – последней инкрементальной копии.
В зависимости от размера баз данных и необходимой частоты резервного копирования стратегии могут заметно отличаться, я же рассмотрю вариант с «недельным» планом, когда в конце недели создаётся полный бэкап, в начале каждого рабочего дня создаётся дифференциальный бэкап, и каждый час в течение рабочего времени — создание инкрементального бэкапа.
Такой план в самом плохом сценарии позволит сохранить данные, не потеряв более одного часа, или восстановить состояние баз на начало любого рабочего часа. А наличие дифференциального бэкапа позволит сократить количество необходимых копий, используемых при восстановлении.
Установка XtraBackup и настройка расписания
Дальнейшие действия выполнялись на CentOS 8, скачать подходящую версию XtraBackup можно с официального сайта.
По умолчанию XtraBackup ищет данные конфигурации сервера и данные подключения пользователя из файлов:
1. Установка:
Скачаем и установим XtraBackup из RPM:
Если планируется использовать компрессию, потребуется установить Qpress:
2. Проверим, что установка прошла успешно:
3. Создадим минимальную версию скрипта, который можно будет вызывать по расписанию в cron:
4. Добавим расписание в /etc/crontab:
Теперь резервное копирование будет выполняться по заданному расписанию в каталог /data/backups/db (как было задано в скрипте), но нужно учесть, что копирование не начнется, пока не будет создан полный и дифференциальный бэкап (в понедельник), поэтому, чтобы проверить работу скрипта, мы создадим их вручную:
Восстановление
Для восстановления состояния баз на требуемое время, нам нужно будет выполнить последовательно этапы:
1. Разархивирование
2. Подготовка:
Теперь, когда в каталоге /data/backups/db/20210913-FULL/ у нас готовые к использованию файлы баз данных, осталось остановить сервер, удалить или перенести старые файлы и скопировать новые файлы в оригинальное расположение и восстановить владельца файлов (mysql).
3. Применение резервной копии:
Заключение
Как известно, администраторы делятся на тех, кто не делает бэкап, и тех, кто уже делает. Последних же можно ещё поделить на тех, кто не проверяет целостность резервных копий, и тех, кто уже проверяет.
Этап с проверкой целостности выходит за пределы данной статьи, что не отменяет его важности, также стоит упомянуть, что статья не описывает всех нюансов использования Xtrabackup, но может послужить отправной точкой для администраторов, решивших делать бэкап чаще, чем раз в сутки.



