Oracle Database In-Memory
Данная статья подготовлена Алексеем Струченко, начальником отдела оптимизации СУБД и приложений компании «Инфосистемы Джет»
Вышедшая в июле 2014 года опция Database In-Memory является самой ожидаемой и самой обсуждаемой инновацией Oracle в семействе продуктов Oracle Database. За последние несколько месяцев сотрудники компании Oracle регулярно знакомили российское оракловое сообщество с особенностями новой опции.
На Oracle Day 2014 в Москве мне выпала честь дополнить теоретическую презентацию Игоря Мельникова (Oracle) по Database In-Memory практической демонстрацией. Эту демонстрацию в полном объеме показать не удалось – оказалось не так-то просто подключить проектор к ноутбуку, соединенному с демонстрационной базой. Поэтому я решил воспользоваться трибуной Habrahabr и все-таки донести суть демонстрации Database In-Memory до сообщества.
Итак, есть две таблицы – PERSONS и CREDITS, – в которых существенно разное число полей. Структуру таблицы PERSONS приведем целиком, т.к. в ней всего четыре поля (COUNTRY_ID – ссылка на страну, SALARY – поле для аналитики):
| ID | NOT NULL | NUMBER |
| COUNTRY_ID | NUMBER | |
| NAME | VARCHAR2(50) | |
| SALARY | NUMBER |
В таблице CREDITS двадцать три поля, поэтому приведем только существенную часть ее структуры (COUNTRY – ссылка на страну, CREDIT_LIMIT – поле для аналитики):
| ID | NOT NULL | NUMBER |
| NAME | VARCHAR2(50) | |
| COUNTRY | NUMBER | |
| CREDIT_LIMIT | NUMBER |
Справочник стран взят из интернета, таблицы PERSONS и CREDITS заполнены случайным образом так, чтобы их записи ссылались только на страны Европы – всего в таблицах PERSONS и CREDITS получилось по 21248349 записей.
Роль аналитических запросов в демонстрации будут играть запросы вида:
Конкретно этот запрос считает сумму SALARY по всем записям таблицы PERSONS, которые связаны со странами на букву R – в Европе это Россия и Румыния. Причем оба участвующие в запросе поля сложены в In-Memory для обеих таблиц PERSONS и CREDITS:
| PERSONS | COUNTRY_ID | FOR QUERY HIGH |
| PERSONS | SALARY | FOR QUERY HIGH |
| CREDITS | COUNTRY | FOR QUERY HIGH |
| CREDITS | CREDIT_LIMIT | FOR QUERY HIGH |
Результат выполнения аналитического запроса из таблицы PERSONS при использовании Database In-Memory оказывается в ПЯТЬ раз быстрее (ниже приведены тайминги из SQL*Plus и SQL Monitor из Enterprise Manager):

Результат выполнения подобного аналитического запроса из таблицы CREDITS при использовании Database In-Memory оказывается быстрее более чем в СЕМЬСОТ раз:
В таблице PERSONS мало полей, и она заведомо помещается в память и без использования Database In-Memory. В первом опыте мы сравниваем производительность Oracle Database при строковом (традиционный буферный кэш) и колоночном (In-Memory) хранении данных в памяти. Колоночный способ хранения в этом опыте дает выигрыш в пять раз за счет ряда реализованных в In-Memory механизмов.
В таблице CREDITS полей много, и она либо в память не помещается, либо Oracle сам отказывается класть ее в память, опасаясь «вымывания» кеша. Во втором опыте мы сравниваем чтение из памяти и чтение с диска, что хорошо видно на SQL Monitor (синим цветом обозначается ввод–вывод). Чтение из памяти действительно быстрее в сотни раз, и полученный в этом опыте выигрыш в 700 раз вполне ожидаем.
Какой из этого следует вывод? В Database In-Memory действительно реализована красивая наука, способная показывать ускорения запросов в сотни и тысячи раз. Но это должны быть особенные запросы – например, на таких больших таблицах, что в память помещается только несколько нужных для аналитики полей.
А если при тестировании In-Memory будут использоваться запросы из таблиц типа PERSONS, то результат может быть другим, что, возможно, приведет к обманутым ожиданиям. В некотором роде можно считать этот пост инструкцией “Как нужно и как не нужно демонстрировать работу опции Database In-Memory”.
Мы будем рады вашим конструктивным комментариям.
Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
IMDB (In-memory Database)
База данных в памяти (англ. In-memory database, IMDB) — это система управления базами данных, которая при хранении компьютерных данных в основном полагается на оперативную память. Она выделяется на фоне СУБД, в которых используется механизм дискового хранения. Базы данных в памяти быстрее, чем базы данных, оптимизированные для использования дисковых накопителей, поскольку доступ к диску медленнее, чем доступ к памяти, а внутренние алгоритмы оптимизации проще и выполняют меньше инструкций ЦП. Доступ к данным из памяти исключает время на поиск при их запросе, что обеспечивает более быструю и предсказуемую работу, чем при использовании дискового накопителя.
Потенциальным техническим препятствием при хранении данных в оперативной памяти является её энергозависимость. В частности, в случае прекращения электропитания, преднамеренного или нет, данные, хранящиеся в ОЗУ, будут потеряны.
База данных в памяти также может быть известна как база данных основной памяти (англ. main memory database, MMDB), база данных реального времени (англ. real-time database, RTDB) или система базы данных в памяти (англ. in-memory database system, IMDS).
Содержание
Особенности
Базы данных в памяти предназначены для достижения минимального времени отклика, а также чрезвычайно высокой пропускной способности для систем, критичных к производительности. Это возможно потому, что данные сохраняются и обрабатываются в форме, используемой приложением, что устраняет накладные расходы, связанные с переводом и кэшированием. Технология IMDB способна поддерживать развертывание на уровне приложений, управление данными в режиме реального времени и большинство свойств ACID.
Структуры данных и алгоритмы IMDB предназначены исключительно для обеспечения управления данными, событиями и транзакциями на уровне приложений. По сравнению с полностью кэшированными системами управления реляционными базами данных, IMDB используют значительно меньше ресурсов ЦП. Технология IMDB не использует магнитные диски, как место для хранения первичной базы данных. Вместо этого магнитные диски используются для обеспечения стойкости и восстановления. [Источник 1]
Поддержка ACID
IMDB часто поддерживают 3 свойства ACID: атомарность, согласованность и изолированность. Однако, по умолчанию они не поддерживают свойство «долговечность», т.к. хранят данные на устройствах с энергозависимой памятью, которые теряют всю хранящуюся на них информацию, когда отключаются от питания или сбрасываются.
Для реализации поддержки «долговечности» используются следующие механизмы:
С помощью хранилищ с энергонезависимой памятью IMDB может безопасно восстановить своё состояние после перезагрузки системы.
Гибриды с дисковыми базами данных
Гибкость гибридного подхода позволяет добиться баланса между:
В индустрии облачных вычислений появились термины «температура данных» или «горячие данные» и «холодные данные», чтобы классифицировать данные с точки зрения частоты обращений к ним. Горячие данные используются для обозначения критически важных данных, к которым часто обращаются, в то время как холодные данные обозначают данные, которые необходимы реже или менее срочно, например данные, хранящиеся для целей архивирования или аудита. Горячие данные должны храниться способами, предполагающими быстрое извлечение и модификацию. Холодные же данные могут храниться более экономичным способом, и считается, что доступ к таким данным, скорее всего, будет медленнее по сравнению с горячими данными.
В итоге, если какому-либо устройству, особенно из линейки потребительской электроники, требуется система базы данных, производитель может использовать гибридную систему средней стоимости, вместо того, чтобы использовать отдельные дорогостоящие базы данных в оперативной памяти или малопроизводительные базы данных на диске.
Первой подсистемой хранения с поддержкой таблиц и в памяти, и на дисках в единой базе данных была WebDNA, выпущенная в 1995 г.
Стойкие базы данных в памяти

Рисунок 1 – Стойкие IMDB
![]()
Рисунок 2 – Сохранение транзакций на диске
На рисунке 2 показана схема добавления транзакций в журнал. Транзакции всегда добавляются конец файла журнала, что обеспечивает достаточно быструю работу с дисками. Если говорить об обычных магнитных жестких дисках (HDD), то они могут записывать в конец файла со скоростью 100 МБ/с. Таким образом, магнитные диски достаточно быстрые, если они записывают данные последовательно. С другой стороны, они крайне медленные, если делают это произвольно. Такие диски обычно могут выполнять лишь около 100 операций с произвольным доступом в секунду.
Таким образом, стойкие базы данных в памяти могут быть действительно быстрыми при выполнении операций чтения/записи, т.е. такими же быстрыми, как и обычные базы данных в памяти, при этом очень эффективно используя диск и не делая его узким местом.
Использование NVDIMM флэш-памяти в IMBD
Существуют два основных требования к хранению базы данных в памяти: постоянный носитель для хранения зафиксированных транзакций, что обеспечивает долговечность и для целей восстановления, если базу данных необходимо перезагрузить в память, и постоянное хранилище для хранения копии или резервной копии базы данных в полном объеме.
Наилучшим носителем информации в этом случае является флэш-память. Перемещение флэш-памяти ближе к процессору уменьшает задержку, поэтому PCIe SSD или устройства хранения данных NVDIMM, работающие по каналу памяти, обеспечивают минимально возможное её значение.
Хранилище канала памяти помещает флэш-память в оборудование, которое использует форм-фактор DIMM, и подключается непосредственно к материнской плате сервера, обеспечивая твердотельное хранилище на шине DRAM. Это приводит к чрезвычайно низкой задержке операций ввода-вывода, но требует изменений BIOS и драйверов операционной системы, чтобы позволить ОС идентифицировать память как энергонезависимую. Изменения BIOS необходимы для предотвращения сбоя памяти сервера при проверках во выполнения POST.
Что касается требования о более быстрой перезагрузке баз данных, то, очевидно, флэш-память также имеет здесь преимущество. Чтение всей базы данных в память из флэш-памяти всегда будет намного быстрее, чем с дискового накопителя.
Проблема здесь, конечно, заключается в стоимости, поскольку флэш-память значительно дороже, чем диск, и, в случае использования базы данных в памяти, доступ к ней осуществляется очень редко. Однако в кластерных средах инвестиции в совместное решение на основе флэш-памяти могут быть разумными.
Преимущества и недостатки IMDB
Сценарии использования
Ставки в реальном времени
Ставки в реальном времени означают покупку и продажу показов онлайн-рекламы. Обычно ставку нужно делать, пока пользователь загружает веб-страницу, т.е. за 100-120 миллисекунд, а иногда и за 50 миллисекунд. В течение этого периода времени приложения ставок в режиме реального времени запрашивают у всех покупателей ставки на рекламное место, выбирают выигрышную ставку на основе нескольких критериев, отображают ставку и собирают информацию после показа рекламы. Базы данных в памяти являются идеальным выбором для приема, обработки и анализа данных в реальном времени с задержкой менее миллисекунды.
Игровые рейтинговые таблицы
Относительная рейтинговая таблица в играх показывает позицию игрока относительно других игроков аналогичного ранга. Такие таблицы могут помочь привлечь игроков и тем самым не дать геймерам стать демотивированными по сравнению только с лучшими игроками. Для игр с миллионами игроков базы данных в памяти могут быстро доставлять результаты сортировки и обновлять рейтинговую таблицу в режиме реального времени.
Кэширование
In-memory архитектура для веб-сервисов: основы технологии и принципы
In-Memory — набор концепций хранения данных, когда они сохраняются в оперативной памяти приложения, а диск используется для бэкапа. В классических подходах данные хранятся на диске, а память — в кэше. Например, веб-приложение с бэкендом для обработки данных запрашивает их в хранилище: получает, трансформирует, а по сети перегоняется много данных. В In-Memory вычисления отправляются к данным — в хранилище, где обрабатываются и сеть нагружается меньше.
Благодаря своей архитектуре, в In-Memory в разы, а иногда и на порядки, быстрее скорость доступа к данным. Например, аналитики банка хотят посмотреть в аналитическом приложении отчет по выданным кредитам в динамике по дням за прошлый год. Этот процесс на классической СУБД займет минуты, а c In-Memory появится почти сразу. Всё потому, что подход позволяет кэшировать гораздо больше информации и она хранится в оперативной памяти «под рукой». Приложению не нужно запрашивать данные у жесткого диска, доступность которых ограничена скоростью сети и диска.
Какие еще возможности доступны с In-Memory и что это за подход, расскажет Владимир Плигин — инженер компании GridGain. Этот обзорный материал будет полезен разработчикам бэкенда веб-приложений, которые не работали с In-Memory и хотят попробовать, или интересуются современными трендами разработки программных решений и проектированием архитектуры.
Примечание. Статья основана на расшифровке доклада Владимира на конференции #GetIT Conf. До введения самоизоляции мы регулярно проводили митапы и конференции для разработчиков в Москве и Санкт-Петербурге: обсуждали тренды, актуальные вопросы разработки, проблемы и их решения. Сейчас конференции не провести, зато самое время поделиться полезными материалами с прошлых.
Кто и как использует In-Memory
In-Memory используют чаще всего там, где требуется быстрое взаимодействие с пользователем или обработка больших массивов данных.
In-Memory как основное хранилище
Один из наших клиентов — крупный поставщик медицинского научного оборудования из США. Они используют In-Memory решение, как основное хранилище данных. Все данные хранятся на диске, а подмножество данных, которое активно используется, держат в оперативной памяти. Методы доступа к хранилищу стандартные — GDBC (Generic Database Connector) и язык запросов SQL.
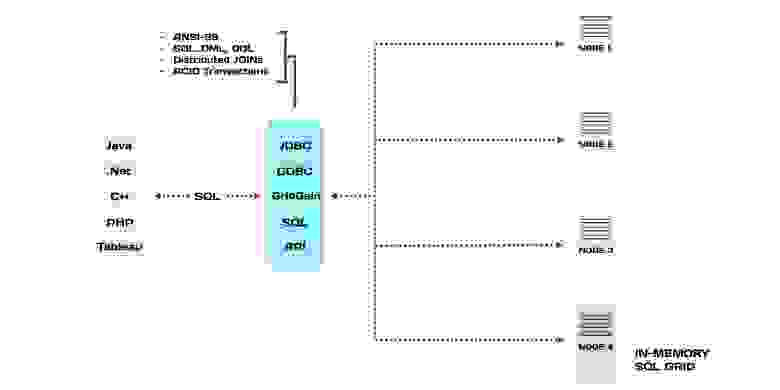
Все вместе это называется In-Memory Database (IMDB) или Memory-Centric Storage. У этого класса решений много названий, это не единственные.
Для создания отказоустойчивых приложений
Представим классическую архитектуру отказоустойчивого веб-приложения. Она работает так: все запросы распределяет веб-балансировщик между серверами. Эта система устойчива, потому что серверы дублируют друг друга и подстраховывают при инцидентах.
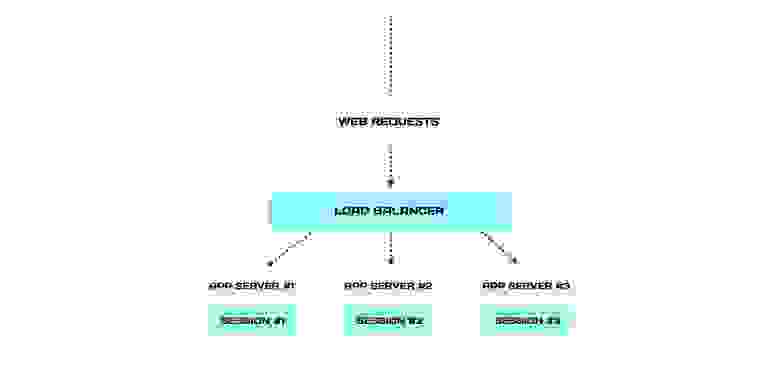
Балансировщик направляет все запросы с одной сессии строго на один сервер. Это механизм стики-сессий: каждая сессия привязывается к серверу, в котором она локально хранится и обрабатывается.
Что произойдет, когда откажет один из серверов?
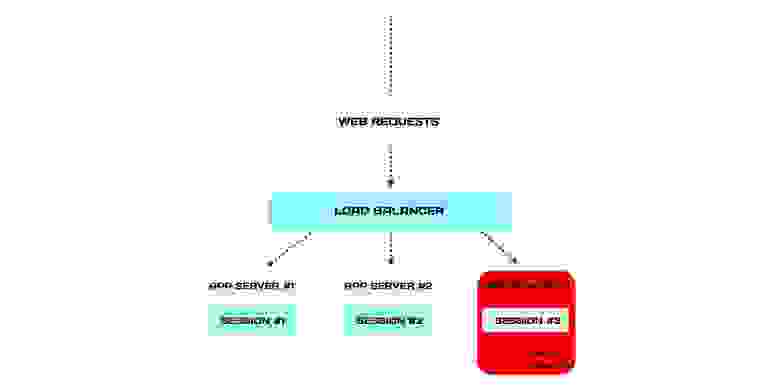
Сервис не пострадает, потому что архитектура дублирована. Но мы потеряем подмножество сессий умершего сервера. А заодно и пользователей, которые привязаны к этим сессиям. Например, клиент оформляет заказ и внезапно его выкидывает из кабинета. Он будет недоволен, когда заново авторизуется и обнаружит, что все придется оформлять еще раз.
От веб-приложения требуется поддерживать большое количество пользователей и не «тормозить» чтобы им было комфортно работать. Но при отказе, с каждым следующим запросом время на общение с хранилищем сессий будет все больше. Это увеличивает среднюю задержку (latency) для остальных пользователей. Но они не хотят ждать больше, чем привыкли.
Эту проблему можно решить, как другой наш клиент — крупный PASS-провайдер из США. Он использует In-Memory, чтобы кластеризовать веб-сессии. Для этого хранит их не локально, а централизованно — в In-Memory кластере. В этом случае сессии доступны гораздо быстрее, потому что уже они находятся в оперативной памяти.
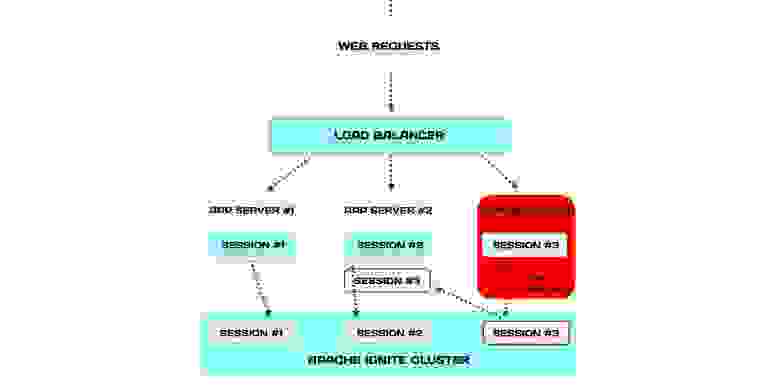
Когда сервер падает, балансировщик отправляет запросы упавшего на другие серверы, как и в классической архитектуре. Но есть важное различие: сессии хранятся в In-Memory кластере и у серверов есть доступ к сессиям упавшего сервера.
Такая архитектура повышает отказоустойчивость всей системы. Больше того, возможно вообще отказаться от механизма стики-сессий.
Гибридная транзакционно-аналитическая обработка (HTAP)
Обычно транзакционные и аналитические системы держат отдельно. Когда они разделяются, под нагрузку попадает основная база. Для аналитической обработки данные копируются в реплику, чтобы аналитическая обработка не мешала транзакционным процессам. Но копирование идет с отставанием — без отставания реплицировать невозможно. Если будем делать это синхронно, это будет также замедлять основную базу и выигрыша не получим.
В HTAP всё работает иначе — одно и то же хранилище данных используется для транзакционной нагрузки от приложений, и для аналитических запросов, которые могут долго выполняться. Когда данные лежат в оперативной памяти, аналитические запросы выполняются быстрее, а сервер с БД нагружается меньше (в среднем).
Гибридный подход «ломает стену» между обработкой транзакций и аналитикой. Если мы выполняем аналитику на том же хранилище, то аналитические запросы запускаются на данных из оперативной памяти. Они гораздо точнее, более интерпретируемые и адекватные.
Интеграция In-Memory решений
Простой (относительно) способ — разработать все с нуля. Мы держим данные на диске, а горячие храним в памяти. Это помогает переживать перезагрузки серверов или отключения.
Здесь работают два основных сценария, когда данные хранятся на диске. В первом мы хотим переживать падения или штатные перезагрузки кластера или частей — хотим использовать, как простую базу данных. Во втором сценарии, когда данных слишком много, какая-то часть из них в памяти.
Если нет возможности все построить с нуля, возможно интегрировать In-Memory в уже существующую архитектуру. Но не все In-Memory решения для этого подходят. Есть три обязательных условия. In-Memory решение должно поддерживать:
Если вам важен быстрый доступ к данным и их обработка, например, для бизнес-аналитики — можно задуматься над внедрением In-Memory. А для реализации можете использовать оба способа при проектировании новой архитектуры.
In-memory базы данных: применение, масштабирование и важные дополнения
Мы продолжаем экспериментировать с форматами проведения митапов. Недавно на боксерском ринге мы сталкивали централизованную шину данных и Service Mesh. В этот раз решили попробовать нечто более миролюбивое — StandUp, то бишь открытый микрофон. Темой выбрали in-memory базы данных.
В каких случаях стоит переходить на in-memory? Как и зачем масштабировать? И на что стоит обратить внимание? Ответы в выступлениях спикеров, которые мы осветим в этом посте.
Но для начала представим спикеров:
Переход на in-memory
Современные тенденции финансового рынка предъявляют гораздо более строгие требования по времени отклика и работе средств автоматизации процессов в целом. К тому же, практически все крупнейшие финансовые институты стремятся сегодня к построению собственных экосистем.
В связи с этим мы видим для себя два основных применения in-memory решений. Во-первых, это кэширование интеграционных данных. По классическому сценарию в крупных компаниях существует нескольких автоматизированных систем, которые обеспечивают предоставление данных по запросу пользователя. Либо внешней системы — но в этом случае инициатором в большинстве случаев является пользователь. Традиционно эти системы хранили структурированные определенным образом данные в БД, осуществляя доступ к ней по запросу.
Сегодня такие системы уже не удовлетворяют требованиям в части нагрузки. Здесь не стоит забывать и про удаленные вызовы указанных систем системами-потребителями. Отсюда вытекает необходимость пересмотра подходов к хранению и представлению данных — пользователям, автоматизированным системам или отдельным сервисам. Логичный выход — хранение актуальных данных, используемых сервисами, на уровне слоя in-memory; на рынке есть немало подобных успешных кейсов.
Это был первый кейс. Второй — это эффективное, с технической точки зрения, управление бизнес-процессами. Традиционные BPM-системы автоматизируют выполнение тех или иных операций в соответствии с заранее определенным алгоритмом. И во множестве случаев возникают вопросы: почему же эти системы работают недостаточно эффективно и недостаточно быстро?
Как правило, подобные системы пишут каждый свой шаг (или небольшой набор шагов, оформленный в виде бизнес-транзакции) в базу данных. Так что они завязаны на время отклика и взаимодействия с данными системами. Сейчас количество экземпляров бизнес-процессов, выполняющихся одновременно в режиме реального времени, на порядки больше чем 10 лет назад. Так что современные системы управления бизнес-процессами должны иметь существенно более высокую производительность и обеспечивать исполнение децентрализованных приложений. Тем более что сегодня все компании движутся к формированию большого микросервисного окружения. Задача в том, чтобы различные экземпляры бизнес-процессов могли разделять и эффективно использовать оперативные данные. В рамках оркестровки имеет смысл хранить их в in-memory решении.
Проблема согласования
Предположим, что у нас огромное количество узлов и сервисов, что выполняется ряд бизнес-процессов, действия которых реализованы в виде микросервисов. Чтобы повысить производительность, каждый из них начинает писать свое состояние в локальный экземпляр памяти. Мы получаем большое количество локальных экземпляров. Как обеспечить актуальность и согласованность для всех?
Мы используем зонирование in-memory области. Например, в зависимости от бизнес-домена. Когда мы нарезаем бизнес-домен, то определяем, чтобы те или иные микросервисы/бизнес-процессы работали только в рамках той зоны, которая отвечает за соответствующий домен. Так мы можем ускорить обновление кэша и всю работу in-memory решения.
При этом кэш, отвечающий за домен, работает в режиме полной репликации – ограниченное ввиду распределения по доменам количество узлов обеспечивает скорость и и корректность работы решения в данном режиме. Зонирование и максимальное дробление помогает решить проблемы синхронизации, работы кластера и т.д. на большом общем количестве узлов.
Часто возникают естественные вопросы о надежности in-memory решений. Да, туда можно класть не все. У нас с целью обеспечения надежности рядом с in-memory всегда остаются базы данных. Например, для важных вопросов с отчетностью, которую нужно сводить вместе, что бывает сложно на большом количестве узлов. Так что наше видение на сегодняшний день: синергия двух подходов.
Также стоит отметить, что эти два подхода тоже не совсем правильно только противопоставлять. И в то же время замыкаться на них. Производители и контрибьюторы современных систем виртуализации в режиме контейнеров, такие как Kubernetes, уже обеспечивают нам варианты для долговременного надежного хранения. Уже появились хорошие промышленные кейсы по внедрению решений, в которых хранение осуществляется в подобном виртуализированном формате.
Одна из крупнейших газет США предоставляет возможность своим читателям в режиме онлайн получить любой номер, который выходил с момента старта выпуска этой газеты в 19 веке. Можем представить уровень нагрузки. Хранение реализовано ими посредством платформы Apache Kafka, развернутой в Kubernetes. Вот еще один вариант хранения информации и предоставления к ней доступа под большой нагрузкой большому количеству клиентов. При проектировании новых решений на этот вариант также стоит обратить внимание.
Масштабирование in-memory баз данных с Tarantool
Предположим, у нас есть сервер. Он принимает запросы, хранит данные. Вдруг запросов и данных становится больше, сервер перестает справляться с нагрузкой. Можно загрузить в сервер больше железа, и он будет принимать больше запросов. Но это тупиковый путь сразу по трем причинам: дороговизна, ограниченность в технических возможностях и проблемы с отказоустойчивостью. Вместо этого существует горизонтальное масштабирование: к серверу приходят «друзья», которые помогают ему выполнять задачи. Два основных типа горизонтального масштабирования — это репликация и шардинг.
Репликация — это когда есть много серверов, они все хранят одни и те же данные и клиентские запросы раскидываются по всем этим серверам. Так масштабируются вычисления, не данные. Это работает, когда данные помещаются на одном узле, но клиентских запросов так много, что один сервер не справляется. Также тут сильно повышается отказоустойчивость.
Для масштабирования данных используется шардинг: делается много серверов, и они хранят разные данные. Так вы масштабируете и вычисления и данные. Но отказоустойчивость в этом случае невысока. Если один сервер откажет, то часть данных потеряется.
Есть третий подход — их скомбинировать. Мы разделяем кластер на подкластеры, называем их реплика-сетами. В каждом из них хранятся одни и те же данные, и между реплика-сетами данные не пересекаются. В итоге получается и масштабирование данных, и вычислений, и отказоустойчивость.
Репликация
Репликация бывает двух типов: асинхронная и синхронная. Асинхронная — это когда клиентские запросы не дожидаются, пока данные разлетятся по репликам: записи на одну реплику достаточно. Как только данные попали на диск, в журнал, транзакция завершается успехом и когда-нибудь в фоне эти данные реплицируются. Синхронная — когда транзакция делится на 2 фазы: prepare и commit. Commit не вернет success, пока данные не отреплицируются на некоторый кворум реплик.
Асинхронная репликация, очевидно, быстрее, потому что ничего не упирается в сеть. Данные в сеть будут посылаться в фоне, а сама транзакция как записалась в журнал, так и завершилась. Но есть проблема: реплики могут друг от друга отставать, появляться рассинхронизации.
Синхронная репликация надежнее, но сильно медленнее и сложнее в реализации. Там действуют сложные протоколы. В Tarantool можно выбирать любой из этих типов репликаций, в зависимости от задач.
Отставание реплик порождает не только рассинхронизацию, но и проблему неосведомленности мастера: он не знает как отдать свои изменения реплике. Изменения обычно отдаются инкрементально — их применили, и в том же виде они улетают на реплику. Но что с ними делать, если реплика недоступна? Например, в Tarantool все можно настраивать, и мастер становится очень гибок.
Еще одна задача: как сделать топологию сложной? В Mail.ru, например, есть топология с сотнями Tarantool. В ней есть tarantool-ядро к которому по кругу прицеплены тарантулы-реплики для бекапов. В Tarantool можно делать совершенно произвольные топологии, репликация с этим отлично живет.
Шардинг
Теперь перейдем к масштабированию данных: шардингу. Он бывает двух типов: диапазонами и хешами. Шардинг диапазонами — это когда все данные сортируются по некоторому ключу шардирования, и эта большая последовательность разбивается на диапазоны так, чтобы в каждом диапазоне было примерно одинаковое количество данных. И каждый диапазон целиком хранится на каком-нибудь одном физическом узле. Но обычно такой шардинг не нужен. К тому же, он всегда очень сложен.
Также есть шардирование хешами. Оно как раз и представлено в Tarantool. Оно гораздо проще в реализации, использовании и почти всегда подходит вместо шардирования диапазонами. Работает так: мы считаем хеш-функцию от записи и она возвращает номер физического узла, в который сохранять. Есть проблемы: во-первых, трудно быстро выполнить сложный запрос.
Во-вторых, существует проблема решардинга. Существует какая-то шард-функция, которая возвращает номер того физического шарда, в который надо сохранить ключ. И когда меняется количество узлов, шард-функция тоже меняется. Это означает, что для всех данных, которые есть в кластере, ее придется заново пересчитать и проверить. Более того, в классическом шардинге некоторые данные переедут не на новую ноду, а просто будут тасоваться между старыми нодами. Бесполезные переносы свести к нулю в классическом шардинге нельзя.
В Tarantool используется виртуальный шардинг: данные распределяются не по физическим узлам, а по виртуальным. Виртуальным бакетам в виртуальном кластере. А виртуальные стораджи раскладываются по физическим. И уже там гарантируется, что каждый виртуальный сторадж целиком лежит на каком-то одном физическом сторадже.
Как это решает проблему решардинга? Дело в том, что количество бакетов фиксировано и серьезно превышает количество физических узлов. Таким образом, сколько бы вы ни масштабировали физически свой кластер, бакетов всегда будет достаточно, чтобы хранить данные и равномерно их распределять. А за счет того, что шард-функция неизменна, при изменении состава кластера не придется ее пересчитывать.
В итоге мы получаем три типа шардинга: диапазоны, хеши и виртуальные бакеты. В случае с диапазонами и бакетами есть проблема физического поиска.
Как ее решить? Первый способ: просто запретить решардинг. Тогда для решардинга придется создавать новый кластер и все туда переносить. Второй способ: всегда заходить на все узлы. Но в этом нет никакого смысла, поскольку нужно масштабироваться, а вычисления так не масштабируются. Третий вариант: прокси-модуль, который служит своего рода маршрутизатором по бакетам. Вы запускаете его, отправляете туда запрос, указав номер бакета, и он отправит ваш запрос как прокси на нужный физический узел.
Продвинутая In-Memory на примере платформы GridGain
Бизнес предъявляет дополнительные требования к базам данных. Он хочет, чтобы это все было отказо- и катастрофоустойчиво. Он хочет высокой доступности: чтобы ничего никогда не терялось, чтобы можно было быстро восстановиться. Также нужна легкая и дешевая масштабируемость, несложная поддержка, доверие платформе и эффективные механизмы доступа.
Все эти идеи не новы. Многие из этих вещей в той или иной степени реализованы в классических СУБД, в частности, репликации между ЦОДами.
In-Memory — это уже не технология-«стартап», это зрелые продукты, которые применяются в крупнейших компаниях по всему миру (Barclays, Citi Group, Microsoft и т.д.). Предполагается, что там все эти требования выполняются.
Так если вдруг случилась катастрофа, должна существовать возможность восстановиться из бэкапа. И если речь идет о финансовой организации, важно чтобы этот бэкап был консистентным, а не просто копией со всех дисков. Чтобы не было ситуации, когда на части узлов данные были восстановлены на момент X, а на другой части — на момент Y. Очень важно иметь Point-in-time Recovery, чтобы даже в ситуации порчи данных или особенно жесткой аварии минимизировать объем потерь.
Важно уметь вытеснять данные на диск. Чтобы кластер не падал под сверхнагрузкой и продолжал хоть медленнее, но работать. И чтобы быстро поднимался с диска, а потом уже перекачивал данные в память.
Реакция In-Memory на аварии с включенными компонентами отказоустойчивости GridGain и без них
Отказоустойчивый кластер должен легко масштабироваться горизонтально и вертикально. Не хочется платить за свой сервер и смотреть на то, как половина ресурсов простаивает. Не хочется, чтобы был ад из сотен процессов, которыми нужно управлять. Хочется простую с точки зрения поддержки систему, с легким ввод-выводом узлов из кластера и развитой, зрелой системой мониторинга.
Рассмотрим в этом ракурсе MongoDB. Все, кто работал с MongoDB, знают о большом количество процессов. Если у нас есть шардированная MongoDB из 5-и шардов, то на каждом шарде будет реплика-сет из трех процессов (при коэффициенте избыточности 3). А это уже 15 процессов только на сами данные. Хранение конфигурации кластера — еще плюс 3 процесса, в сумме получает 18, и это без учета роутеров. Хотите 20 шардов — добро пожаловать в ад из 63+ (например, еще 8, итого 71) процессов.
Сравним с Cassandra. Берем все те же 5 шардов — это 5 процессов и 5 узлов при том же коэффициенте избыточности 3, что намного проще в плане управления. Хочу 20 шардов — это 20 процессов. Я могу масштабировать мой кластер на любое количество узлов, не обязательно кратное 3 (или иному значению коэффициента избыточности). Намного легче и дешевле для внедрения и поддержки, чем реплика-сеты.
Кроме того, нужно доверять системе, понимать, что за люди стоят за каждым отдельным продуктом. В идеале лицензия должна быть open source или open core. Чтобы в случае смерти вендора можно было что-нибудь сделать. Также хорошо, если исходный код управляется независимым сообществом — мы все помним, как MongoDB и Redis сменили лицензии по одному желанию управляющей компании. Как Aerospike в начале года ввели ограничения на «open source» community-редакцию.
Нужен эффективный доступ к данным. Структурированный язык запросов в том или ином виде есть практически у всех. Чаще всего используют SQL, нужно чтобы адаптация с этим языком была максимально легкой. В этом помогут распределенное выполнение запросов, когда не нужно отправлять запрос отдельно на каждый узел, а можно общаться с кластером как с «единым окном». Не задумываясь с точки зрения API, что это набор узлов (вспомните, как тяжело работа с Memcache на больших объемах даже на уровне простейших put/get, без потенциально сложных SQL-запросов), распределенный DDL и гарантии ACID.
И наконец поддержка. Если что-то вдруг не работает, то компания просто теряет деньги. Для некоторых направлений это не критично, но зачастую важно, чтобы за продукт и его работу кто-то нес ответственность. Чтобы можно было в любой момент предъявить претензию, и она была быстро решена.
Этим постом мы завершаем год Промсвязьбанка на Хабре. Собрали новогодние пожелания для хабровчан в небольшом видео:



