Что такое распознавание изображений и как ИИ помогает в их распознании?
Распознавание изображений (часть искусственного интеллекта (ИИ)) является еще одной популярной тенденцией, набирающей обороты в настоящее время – к 2021 году ожидается, что ее рынок достигнет почти 39 миллиарда долларов. Теперь пришло время присоединиться к тренду и узнать, что такое распознавание изображений и как оно работает.
Что такое распознавание изображений?
Как всегда, давайте начнем с основ. Прежде всего, вы должны помнить, что распознавание и обработка изображений не являются синонимами. Обработка изображения означает преобразование изображения в цифровую форму и выполнение определенных операций с ним. В результате можно извлечь некоторую информацию из такого изображения.
Этапы обработки изображений:
Теперь вы видите, что распознавание изображений является одним из этапов обработки изображений. Те специфические особенности, которые были упомянуты, включают людей, места, здания, действия, логотипы и другие возможные переменные на изображениях. Следовательно, распознавание изображений – это процесс идентификации и обнаружения объекта в цифровом изображении и одно из применений компьютерного зрения. Иногда это также называют классификацией изображений, и это применяется в большом количестве отраслей.
Как работает распознавание изображений?
Теперь несколько слов о том, как работает распознавание изображений. Первым шагом здесь является сбор и организация данных. В отличие от людей, компьютеры воспринимают изображение как векторное или растровое изображение.
Поэтому после создания конструкций, изображающих объекты и особенности изображения, компьютер анализирует их. Затем данные упорядочиваются – важная информация извлекается, а ненужная исключается. Вторым этапом процесса распознавания изображений является построение прогнозирующей модели. Алгоритм классификации должен быть тщательно обучен, иначе он не сможет выполнять свои функции. Когда все сделано и протестировано, вы можете пользоваться функцией распознавания изображений.
Как ИИ помогает распознавать изображения?
Искусственный интеллект делает возможными все функции распознавания изображений. Чтобы дать вам лучшее понимание, вот некоторые из них:
1. Распознавание лиц.
С помощью ИИ система распознавания лиц сопоставляет черты лица с изображения, а затем сравнивает эту информацию с базой данных, чтобы найти совпадение. Распознавание лиц используется производителями мобильных телефонов (как способ разблокировки смартфона), социальными сетями (распознавание людей на изображении, которое вы загружаете, и их пометка), и т.д. Тем не менее, такие системы вызывают много проблем конфиденциальности, так как иногда данные могут быть собраны без разрешения пользователя. Кроме того, даже самые передовые системы не могут гарантировать 100% точность. Что если система распознавания лиц смешивает случайного пользователя с преступником? Это не то, чего кто-то хочет, но это все еще возможно. Однако технологии постоянно развиваются поэтому однажды эта проблема может исчезнуть.
2. Распознавание объектов.
Системы распознавания объектов выбирают и идентифицируют объекты из загруженных изображений (или видео). Визуальный поиск, вероятно, является наиболее популярным приложением этой технологии.
3. Распознавание образов.
4. Анализ изображения.
Вам нужно краткое изложение конкретного изображения? Используйте ИИ для анализа изображений. В результате все объекты изображения (формы, цвета и т. д.) будут проанализированы, и вы получите полезную информацию об изображении.
Распознавание образов и научное знание
Последние достижения в распознавании образов впечатляют. Достаточно вспомнить результаты соревнований на базе ImageNet. Сразу же возникает вопрос, что дальше? Как мы можем использовать полученные достижения?
Что-то важное началось, когда Fei-Fei стартовала ImageNet проект. Похоже на революцию.
Меня на подсознательном уровне не отпускала одна маленькая деталь, часто упоминаемая в обсуждении соревнований ImageNet. А именно, как точно нейронные сети распознают породы собак. Есть в этом что-то, что резонирует с моей нейронной сетью. И наконец-то я тоже понял то, что многие из вас поняли давным давно. Теперь я попытаюсь сформулировать то, что я понял.
Породы собак – это довольно узкая, хорошо проработанная и очень специализированная область наших знаний. Чтобы разбираться в породах, надо видеть и запомнить очень-очень много специфических деталей. Надо знать много связанной с породами информации, к примеру историю пород, методы скрещивания, основы генетики. Надо проштудировать массу книг и постоянно отслеживать новую информацию в этой области. Причем внешность собаки, если можно сказать, ее изображение имеет решающее значение для данной области науки. Окей, согласен, разведение пород можно отнести к науке с большой натяжкой. Давайте лучше скажем — «имеет решающее значение для данной области знаний».
Недавно я работал над системой по распознаванию автомобилей и кораблей. Используя готовые модели, которые блистали в соревновании ImageNet, я не получил хороших результатов. Очевидно в базе ImageNet фотографий кораблей было значительно меньше, чем фото собак.
Где можно найти фото кораблей? Собраны ли эти фотографии в каких-нибудь базах или реестрах? Может и собраны, но найти их я не смог. Еще один маленький вопрос опустился в мою нейронную сеть и не давал спокойно спать.
Пару дней назад я опять наткнулся на популярную базу изображений для новичков, на базу цветков ириса. Что-то щелкнуло в мозгу и стало укладываться в модель.
Имеющиеся базы знаний и изображений
Классификация – один из старейших научных методов. Сразу вспоминается Карл Линней с его единой системой классификации.

Изображение объекта в этих системах – одна из необходимых и главнейших частей классификации. Это, по сути, часть знаний, представление знаний.
Какие базы изображений нужны ученым, инженерам, специалистам на повседневной основе Давайте попробуем выбрать наугад:
Агрономия, растения

Медицина, бактерии

Рыболовство, рыбы
Геология, руды
Биология, насекомые

И так далее и тому подобное. Как только попытаешься копнуть, окажется, что буквально везде мы имеем дело с изображениями и буквально везде мы принимаем решения на основе изображений.
Необходимость баз данных изображений
Изображения объектов используются практически везде. Понятно, что работа по распознаванию объектов ускорилась и улучшилась, если бы мы могли везде и всегда использовать системы распознавания, вместо того, чтобы вручную искать объекты в горе книг или приглашать экспертов.
Изображения есть. Но они разбросаны по книгам и коллекциям. Они не представлены в формате, удобном для автоматической обработки. И их мало. Их явно недостаточно для тренировки хорошей системы распознавания.
Модель
Пришла пора представить вам мою модель. Мне стыдно, что до меня так долго доходили всем и так понятные вещи. Я понимаю, что ничего нового в этой модели нет. Но сочинение этого текста помогло мне сформулировать проблему. Поэтому я взял на себя смелость отдать этот текст вам на обсуждение.
Специализированные базы изображений
Любая область науки и инженерии, имеющая дело с видимыми объектами, получит очевидные преимущества, создав базу изображений (или базы).
Специализированные модели распознавания изображений
Любая область науки и инженерии, имеющая дело с видимыми объектами, получит очевидные преимущества, создав свои системы распознавания изображений.
Комбинация специализированных систем распознавания
Ясно, что готовые специализированные системы распознавания надо научиться встраивать, комбинировать.
Готовая система для создания баз изображений
И может быть, имеет смысл сделать готовую систему, библиотеку для создания баз изображений. Чтобы было удобно, к примеру, импортировать изображения, размечать их. Но может быть мы сможем обойтись чем-нибудь более простым, типа Amazon Mechanical Turk?
Помечтаем
Как бы упростился мой последний проект, если бы я имел доступ не только к моделям ImageNet, но и к готовым моделям распознавания кораблей, катеров, каяков, гидросамолетов, грузовиков, легковых машин, велосипедов. Если бы все эти модели можно было легко скомбинировать.
Если говорить в общем, то создание специализированных систем распознавания помогло бы формализовать знания в отношении видимой стороны сущностей. Узко специализированные знания можно будет распространять и использовать быстро, дешево и эффективно. Экспертные оценки можно будет получить, используя смартфон с камерой.
Почему состязательные атаки на системы распознавания образов — это серьёзно
Используемая сейчас архитектура разработки ИИ для распознавания изображений имеет серьёзные уязвимости, при эксплуатации которых можно серьёзно запутать компьютер, заставив его выдавать неправильные результаты. Какие существуют проблемы и способы обмана ИИ — в нашем материале.
Возможно, вы знаете, кроме машинного обучения существует и вредоносное машинное обучение (Adversarial Machine Learning). Первые публикации по теме AML относят к 2004 году. Примерно до 2015 года, пока ML не получило широкого распространения на практике, вредоносное ML также носило теоретический характер. Однако в 2013 году Christian Szegedy из Google AI, пытаясь понять, как нейросети «думают», обнаружил интересную особенность этого ML-метода. Оказалось, системы распознавания изображений легко обмануть путём небольших изменений.
Классическим примером стало изображение панды, которое компьютер распознавал неправильно. Хитрость в том, что в исходное изображение панды, распознаваемое с вероятностью 57,7 %, добавили шум, невидимый человеческому глазу, но заметный для компьютерной системы. В результате нейросеть считает, что вместо панды на картинке изображён гиббон с вероятностью 99,3 %.
О примерах adversarial атак хорошо рассказано в этой статье. Если коротко, то есть два типа AML-атак:
уклонение (evasion), при которых злоумышленник старается вызвать неадекватное поведение уже готового продукта со встроенной в него ML-моделью
отравление (poisoning), когда злоумышленник стремится получить доступ к данными и процессу обучения ML-модели, чтобы ее «отравить» (обучить неправильно) для последующей неадекватной работы.
Последние лет пять атаки на системы распознавания образов с помощью тщательно созданных изображений считались забавной, но простой проверкой правильности концепции. Однако группа учёных из университета Аделаиды в Австралии считают, что использование популярных наборов данных изображений для коммерческих ИИ-проектов может создать новую угрозу кибербезопасности.
Чего испугались учёные
Возможно, вы помните статью о проблемах распознавания лиц. Так вот, учёные провели ряд экспериментов по обману ИИ. В ходе одного из экспериментов система распознавания лиц, с высочайшей точностью способная распознать на изображении бывшего президента США Барака Обаму, была введена в заблуждение. С вероятностью 80% она была уверена, что мужчина в тёмном балахоне и с напечатанным изображением цветка также является Бараком Обамой. То, что фальшивое лицо находилось не на плечах, а на уровне груди человека, систему никак не смущало.
Источник: https://www.youtube.com/watch?v=Klepca1Ny3c
Надо отдать должное исследователям, сумевшим создать подобное изображение, способное обмануть нейросеть. Хотя аналогичные прецеденты уже были. Можно вспомнить очки со странным узором, которые позволяли обмануть систему распознавания лиц ещё в 2016 году, или специально созданные изображения, которые пытаются видоизменить дорожные знаки.
Вы же понимаете, что при желании так можно обмануть автопилот, подсунув ему фальшивый дорожный знак или выдать себя за другого человека во время преступления?
Клавиатура классифицируется как раковина в модели WideResNet50 на ImageNet
Распознавание изображений как новый вектор атаки
Получается, что нейросеть можно не просто обмануть, можно заставить её считать, что личность А на самом деле — Б. Причём способность вводить в заблуждение подобные системы с помощью созданных изображений очень легко переносится на многие другие архитектуры. Например, все изображения справа распознаются системой как страус:
Примеры, которые приводят учёные в своей работе, отражают уязвимость активно используемой архитектуры разработки ИИ для распознавания изображений. Это не критика отдельных наборов данных или конкретных архитектур машинного обучения, это комплексная проблема. От неё не получится легко защититься путём переключения наборов данных или моделей, переобучения моделей или любым другим аналогичным способом.
Эксплойты команды из Аделаиды иллюстрируют слабость всей нынешней архитектуры систем разработки. Слабость, которая может привести к тому, что многие будущие системы распознавания изображений легко будут обходиться манипуляциям злоумышленников. Потенциал новых атак с использованием состязательных изображений будет неисчерпаем, потому что при создании систем распознавания никто не предвидел появление подобного рода проблем. Так же, как не предполагали компьютерных проблем 2000 года (помните, как это было в 1999?), падения Пизанской башни
Представьте себе, что актуальные образы состязательных атак (таких как цветок на одном из изображений выше), будут добавляться в качестве «уязвимости нулевого дня» в системы безопасности будущего. Примерно так же антивирусы ежедневно обновляют свои вирусные базы.
Состязательные изображения, о которых мы говорим, генерируются при наличии доступа к наборам данных изображений, которые обучили компьютерные модели. Вам не нужен «привилегированный» доступ к обучающим данным (или архитектурам моделей), поскольку наиболее популярные наборы данных (и многие обученные модели) без труда можно скачать с торрентов.
Например, Голиаф среди наборов данных компьютерного зрения, ImageNet, доступен на торрентах во всех его многочисленных итерациях, без его обычных ограничений, позволяя создавать наборы тестов.

Если у вас есть данные, что мешает вам выполнить «реверс-инжиниринг» любого популярного набора данных вроде Cityscapes или CIFAR? Есть и другие датасеты, которые можно использовать. Десятью наиболее популярными наборами данных изображений в компьютерном зрении являются:
CALTECH-101 и 256 (оба доступны и их можно скачать с торрентов);
MNIST (официально доступен, также есть на торрентах);
Pascal VOC (доступен также есть на торрентах);
MS COCO (доступен, также есть на торрентах);
Скачать, изучить и найти способ обмануть эти нейросети — вполне выполнимая задача.
Атаки на состязательные изображения становятся возможными не только благодаря практике машинного обучения с использованием опенсорсного подхода, но и благодаря корпоративной культуре разработки ИИ. Повторное использование хорошо зарекомендовавших себя наборов данных компьютерного зрения — вполне обычная практика, ведь реализовать их намного дешевле, чем создавать заново, они хорошо поддерживаются и обновляются.
Вот и получается, что нехватка новых наборов данных, высокая стоимость разработки наборов изображений, зависимость от старых «фаворитов» и тенденция просто адаптировать старые наборы данных — все это усугубляет проблему, поднятую исследователями из Австралии.
Посмотрим, что будет дальше.
Что ещё интересного есть в блоге Cloud4Y
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
AirTest IDE и Image Recognition — автоматизация тестирования мобильных игр на основе распознавания изображений
В предыдущей статье мы познакомились с AirTest IDE, но, на всякий случай, давайте повторим: AirTest IDE разработан компанией NetEase и предназначен для «hard-to-automate» приложений, таких как, например, игр. Собственно на них и делается основной упор разработчиками, хотя это не мешает использовать AirTest и для любых других приложений.
Данная работа является второй в цикле, посвящённому AirTest IDE. Первую, обзорную, статью про AirTest IDE вы можете найти здесь, а третью и последнюю, которая посвящена фреймворку UI автоматизации Poco — по данной ссылке.
Сегодня же я расскажу вам об одном из 2х основных фреймворков — AirTest. AirTest — это кросс-платформенный фреймворк для автоматизации UI, основанный на принципах распознавания изображений (Image Recognition), который, как заявляют разработчики, подходит для игр и приложений. AirTest Project на GitHub содержит 4 проекта: Airtest, Poco, iOS-Tangent, multi-device-runner.
А теперь давайте перейдём к самому интересному!
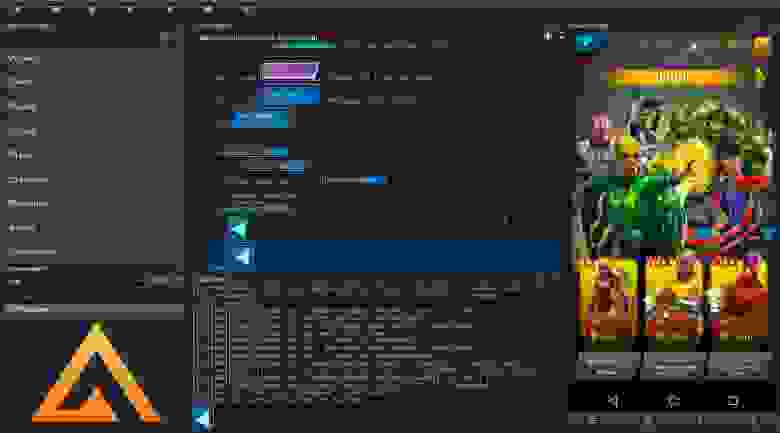
Как работает AirTest
AirTest обрабатывает полученные скриншоты на основе процесса thresholding. Суть заключается в том, чтобы сравнить интенсивность пикселей на изображении с некоторым числом (threshold value) и, если значение пикселя больше, то назначить ему цвет (чаще всего используется белый). В противном случае назначается другой цвет — чёрный. Как итог, на выходе получаем черно-белое изображение. Из этого следует естественное ограничение — AirTest не учитывает цвет во время распознавания. К примеру, если у вас используется объект с одним и тем же силуэтом, но разной, к примеру, раскраской и вам нужно проверить наличие элемента именно с определенной цветовой палитрой, то это будет крайне затруднительно, а может и не сработает вовсе.
К примеру в рамках пробы AirTest IDE было решено поработать с игрой Marvel Puzzle Quest. При загрузке персонажи с данной комикс вселенной мелькают на экране в определенном порядке. Время от времени у них меняются костюмы и это впервые насторожило меня. В примере ниже я ожидал, в рамках теста, Человека Паука в классическом, а получил в стелс костюме. Тест, собственно, прошёл успешно, а произошло это по причине описанной выше — использование чёрно-белого изображения во время распознавания. Пример того, что ожидалось и что, в итоге, получилось:
Улучшение вероятности успешного завершения тестов
Как вы уже поняли, Image Recognition — это далеко не панацея, хоть и работает здесь он хорошо. Для написания качественных тестов вам не избежать написания кода и, соответственно, знания основ Python. К примеру прежде чем искать конкретный элемент, неплохо было бы убедиться, что он действительно есть на экране. Бывают случаи, когда AirTest «промахивается» и может принять неправильный элемент за тот, что нужен вам. Время от времени бывают проблемы с распознаванием текста, который вы хотите найти при помощи Image Recognition. AirTest может спутать результаты и считать, что нужный вам текст есть на экране, но, на самом деле, текст там совершенно другой. Процесс анализа результатов призвана упростить система генерации отчётов, которая уже встроена в AirTest IDE. Создать и открыть отчёт можно после завершения теста/скрипта при помощи сочетания клавиш Ctrl/Cmd+L.
По общим рекомендациям я бы выделил ещё и следующее.
И если вы хотите спросить «Возможно ли изменить настройки процесса поиска изображений?», то я вам отвечу — да, это возможно.
Настройки поиска изображений (Image Recognition)
Пользователю позволено и рекомендуется работать с настройками Image Recognition, чтобы добиться нужных результатов, оптимизировать время и вероятность успешного распознавания элементов (success rate) на экране. Эти настройки хранятся в окне Image Editor и, чтобы открыть его, вам нужно дважды кликнуть на нужное изображение в Script Editor. Настройки распознавания каждой картинки нужно менять отдельно либо использовать глобальные переменные, если, к примеру, вы хотите увеличить требования к точности threshold операции для вашего проекта.
Image Editor содержит в себе рабочую зону, а также «Snapshot+Recognition» и «Show Help» кнопки. Первая отвечает за сравнение вашей текущей картинки со snapshot версией. Snapshot картинка захватывается с текущего окна на вашем девайсе. Вторая кнопка открывает мануал по функционалу Image Editor. В правой части окна отображается текущая картинка для поиска, а также такие настройки как filename, threshold, target_pos и rgb.
Написание автоматизированных тестов при помощи AirTest
В текущей версии программы вы можете пользоваться следующими командами, которые доступны в окне AirTest Assistant:
Данные команды разделены на 3 основные группы: Операции (Operations), вспомогательные функции (Auxiliary functions) и проверки (Assertions). Вы можете выбрать нужную вам группу при помощи соответствующего фильтра (выпадающее меню сразу под названием окна).
Команды, которым необходимо изображение, активируют функции записи скриншота сразу после нажатия на соответствующую кнопку. К примеру, чтобы выбрать на какой элемент нажать на экране, выберите команду touch в AirTest Assistant и в окне Device Screen, на активном устройстве, обведите нужный для нажатия элемент. После этого в главном окне (Script Editor) появится соответствующая команда, в нашем случае touch, с изображением в качестве параметра. Как итог, процесс автоматизации выглядит следующим образом (гифка записана с устаревшей версии AirTest IDE):
Если вы по какой-то причине не хотите вручную создавать скриншоты и\или в целом писать код, то можете воспользоваться функцией автоматической записи. Активировать её можно при помощи нажатии на кнопку «камеры» напротив выпадающего меню с группами команд в окне Airtest Assistant. Автозапись — штука достаточно точная и удобная, но, само-собой, не является панацеей и не заменит ручного набора кода.
Стоит упомянуть ещё 3 горячие клавиши — F5 (запуск скрипта), F10 (остановка запущенного скрипта), Ctrl+L/Cmd+L (создание отчёта на основе законченного теста).
Запускать готовые тесты можно и без UI, используя терминал (command line). Больше информации об этом в целом и о запуске тестов в частности можно найти здесь.
Пример отрывка теста, написанного при помощи AirTest фреймворка можно найти под спойлером!
Само-собой UI в вашем приложении/игре не состоит сплошь и рядом из уникальных иконок, кнопок, задников и т.п. Плюс ко всему периодически визуально идентичные элементы могут встречаться на одном экране, например кнопки, слайдеры и т.д. Чаще всего в таких случаях AirTest не сможет распознать нужный вам элемент и, либо тест упадет с ошибкой, либо будет выбран неверный элемент интерфейса для дальнейших манипуляций.

Специально для таких случаев был разработан ещё один фреймворк, который уже встроен в AirTest IDE. Он Poco и вкратце о нём уже было рассказано в статье с общим обзором Airtest IDE. Подробнее же о данном фреймворке я расскажу в следующей статье.
Расскажите, пользовались ли вы уже AirTest IDE и что вы думаете о данном инструменте. Буду рад обсуждению в комментариях!



