Ibm svc что это
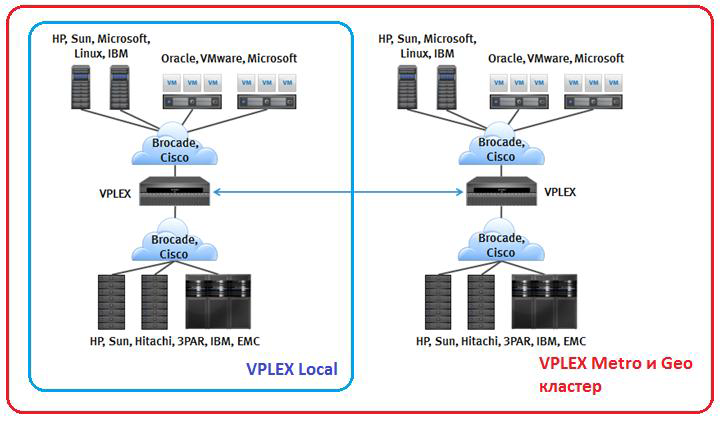

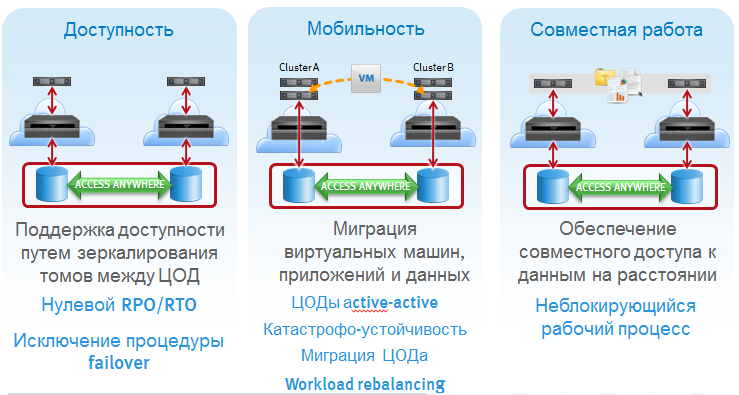
Три основных функции доступны пользователям EMC VPLEX:
1. Обеспечение высокой доступности данных с нулевым временем простоя за счет зеркалирования томов между удаленными ЦОД и полностью автоматизированного процесса переключения между площадками. Полная интеграция с большим списком серверного кластерного ПО (Oracle, VMware, Microsoft, Veritas, IBM и т.д.).
2. Обеспечение мобильности данных. Гибкая и прозрачная миграция данных между площадками, балансировка нагрузки, обеспечение технологических остановок оборудования без остановки работы приложений.
3. Обеспечение одновременного совместного доступа к одним и тем же данным с разнесенных площадок. Полная поддержка
IBM SVC – аппаратный комплекс, который изначально создавался для виртуализации СХД в рамках одной площадки. Архитектурно SVC представляет собой контроллерную пару от системы хранения среднего уровня. SVC не создавалась для того, чтобы обеспечить катастрофоустойчивость инфраструктуры в рамках двух площадок, вместо этого, компания IBM предприняла попытку использовать решение для одной площадки, «растянув» его на две.
Для общего понимания принципов работы необходимо осознать, что IBM SVC – это фактически контроллерная пара от системы хранения среднего уровня с большим количеством единичных точек отказа для каждого контроллера (работающая в типичном для этого класса режиме ALUA).
При построении системы виртуализации СХД между двумя площадками мы получаем фактически растянутую СХД среднего уровня со всеми ограничениями по вычислительной мощности, гибкости, масштабируемости и надежноcти.
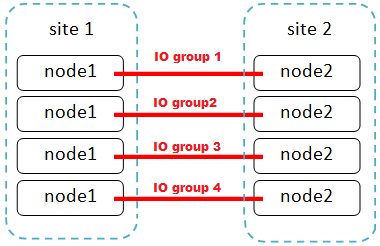
Что происходит, если по каким-то причинам IO-группа недоступна? Происходит простой в работе – так как том на других IO-группах не виден. В последней версии ПО для SVC появилась возможность online перемещать тома между IO-группами, но здесь больше ограничений, чем поддерживаемых конфигураций: работает это только в Windows (может потребоваться перезагрузка хоста) и в Linux. Ни кластеры, ни VMware, ни тем более Unix не поддерживаются при этой операции.
В отличие от IBM SVC, EMC VPLEX обладает hi-end архитектурой, производится гибкая балансировка нагрузки по узлам VPLEX, все элементы задублированы, отсутствуют единые точки отказа. Тома не «привязаны» к контроллерам и даже в случае выхода всего контроллера из строя, данные будут доступны через другие контроллеры. При этом, продолжает выполняться тесная интеграция с широким набором серверного кластерного ПО и не требуется перезагрузка хостов.
Важной особенностью EMC VPLEX является процесс работы с кэшем и синхронизация данных на удаленных площадках. Благодаря своей усовершенствованной архитектуре, VPLEX позволяет производить операции записи на обе площадки за один раз.
Это четко подтверждает документация IBM: The connection between each site in the system associated with the SAN Volume Controller nodes must guarantee a minimum bandwidth of 4 gigabits or 2 times the peek host-write I/O workload, whichever is higher (http://www.redbooks.ibm.com/redpieces/pdfs/sg248072.pdf).
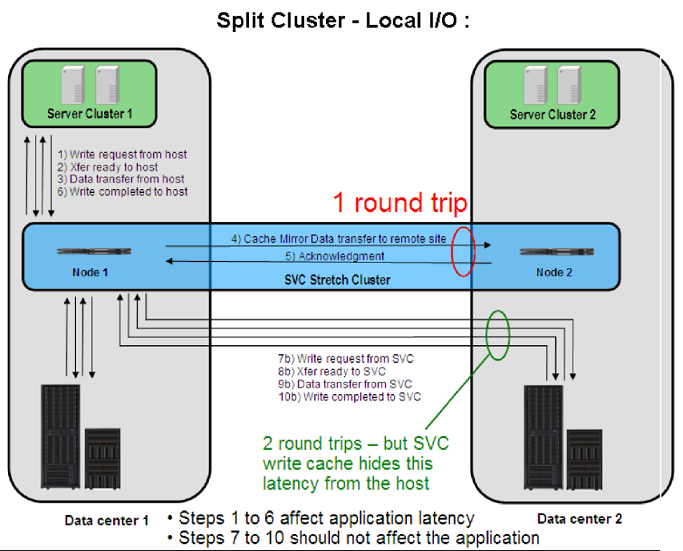
Но бывает еще хуже : если операция записи происходит на «не основной» контроллер для тома, то она проходит канал между площадками трижды: к предыдущему случаю добавляется передача данных от «не основного» контроллера «основному». Это лeгко может быть на практике, например, миграция одной из виртуальных машин на другой сервер кластера, находящийся на удаленной площадке.
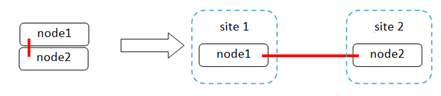
С подключениями все еще интереснее. Типичная схема подключения IBM SVC в распределенном режиме (Split-site system configuration without using ISLs), выглядит примерно следующим образом.
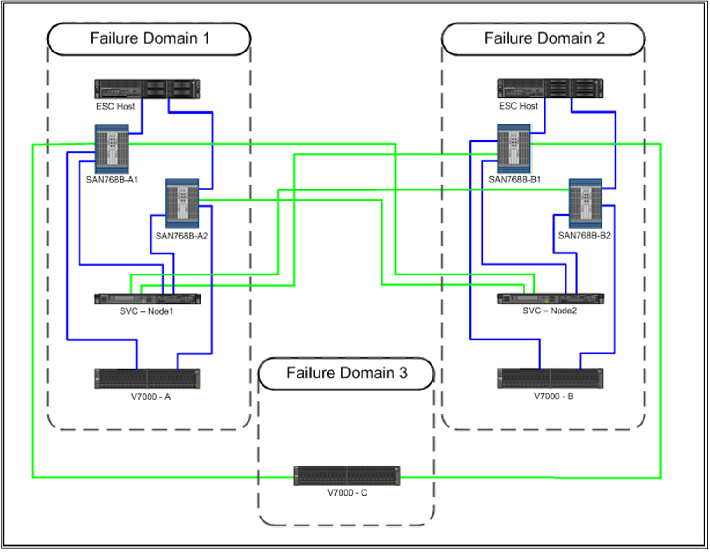
Здесь сразу много что бросается в глаза:
обеим нодам SVC требуется доступ к системам хранения обеих площадок, именно поэтому они подключаются не в какую-то отдельную репликационную фабрику, а напрямую в продуктивные фабрики SAN обеих площадок, нужны отдельные кабели между площадками и longwave SFP в контроллеры SVC
в качестве кворума используется третья площадка, подключенная по SAN, на которой должен присутствовать полноценный том СХД, на который будут ориентироваться ноды SVC – совсем не экономичное решение и сложное с точки зрения обеспечения каналов
Самое интересное, что в некоторых случаях и кворумный диск не помогает. Например, поведение системы, когда обе площадки видят кворум, но при этом не видят друг друга, согласно документации IBM (http://www.redbooks.ibm.com/redpieces/pdfs/sg248072.pdf) будет определяться кто первый схватит кворум – то есть, никто не знает, что будет происходить. На все отказы идет реакция на уровне нод SVC целиком, то есть нельзя задать правила, чтобы при аварии часть томов оставалась работать на одной площадке, а часть на другой.
В случае использования EMC VPLEX, все процедуры распределения томов между площадками при потере связи четко прописаны и работа системы в целом носит полностью предсказуемый характер. Для подключения арбитра на третьей площадке не требуется выделенный дрогостоящий канал FC.
Отдельного упоминания заслуживают вопросы производительности. На каждой ноде SVC присутствует по одной карте FC c 4 портами. В распределенном режиме работы два из них фактически заняты общением со второй нодой и с ресурсами удаленной площадки. Таким образом, для работы с хостами и массивами локальной площадки остается всего лишь 2 FC порта на той же самой FC карте, по одному порту в фабрике. Данное ограничение может фатально повлиять на производительность виртуализованной среды, сократить количество подключаемых серверов и систем хранения данных.
Архитектура и производственные показатели контроллеров EMC VPLEX превосходят характеристики контроллеров IBM SVC (по количеству портов ввода-вывода, процессорным ядрам, объему кэш-памяти) и соответствуют уровню систем Hi-End класса.
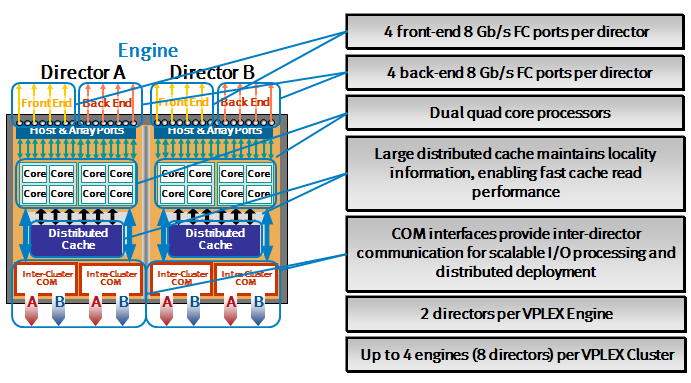
Один VPLEX Metro кластер в максимальной конфигурации с 4 сдвоенными контроллерами на каждой площадке может обрабатывать до 2 240 000 IO/s или 23,2GB/s
Таким образом, можно сделать вывод, что хоть решения EMC VPLEX и IBM SVC, на первый взгляд, реализуют схожий функционал, тем не менее остаются принципиально разными решениями.
EMC VPLEX – это надежное, производительное и полнофункциональное решение для виртуализации инфраструктуры хранения, масштабируемое от малых конфигураций до проектов Enterprise-уровня. В системах EMC VPLEX реализована новая архитектура, которая вобрала в себя более чем 20-летний опыт EMC в области проектирования, внедрения и усовершенствования решений корпоративного класса для интеллектуального кэширования и защиты распределенных данных.
EMC VPLEX выбирают те Заказчики, которым важна надежность хранения данных, производительность и масштабируемость.
IBM SVC – реализован на базе контроллеров систем хранения среднего уровня, обладает рядом существенных ограничений по производительности и надежности. Больше предназначен для малых предприятий для виртуализации некритичных данных.
В итоге, для удобства восприятия, консолидируем наиболее значимые отличия EMC VPLEX и IBM SVC в единой таблице.
Системы хранения данных: как медленно, но верно они отвязываются от железа

Авария в первом дата-центре и автоматический перезапуск сервисов в другом
Виртуализация — одна из моих любимых тем. Дело в том, что сейчас можно практически полностью забыть про используемое железо и организовать, например, систему хранения данных в виде «логического» юнита, который умеет взаимодействовать с информацией по простым правилам. При этом все процессы между виртуальным юнитом и реальным железом в разных ЦОДах лежат на системе виртуализации и не видны приложениям.
Это даёт кучу преимуществ, но и ставит ряд новых проблем: например, есть вопрос обеспечения консистентности данных при синхронной репликации, которая накладывает ограничения на расстояния между узлами.
К примеру — скорость света становится реальным физическим барьером, который не даёт заказчику поставить второй ЦОД дальше 40-50, а то и меньше, километров от первого.
Но давайте начнём с самого начала — как работает виртуализация систем хранения, зачем оно всё надо, и какие задачи решаются. И главное — где конкретно вы сможете выиграть и как.
Немного истории
Сначала были сервера с внутренними дисками, на которых хранилась вся информация. Это довольно простое и логичное решение быстро стало не самым оптимальным, и со временем мы стали использовать внешние хранилища. Сначала простые, но постепенно потребовались специальные системы, позволяющие хранить невероятно много данных и давать к ним очень быстрый доступ. СХД отличались друг от друга объёмом, надёжностью и скоростью. В зависимости от конкретных технологий (например, магнитная лента, жесткие диски или даже SSD, которыми сейчас, конечно, никого не удивить) можно было варьировать эти параметры в довольно широком диапазоне — главное, чтобы были деньги.
Для ИТ-директоров сейчас один из самых главных критериев СХД — надёжность. Например, час простоя для банка вполне может стоить как 10-20 таких шкафов с железом, не говоря уже о репутационных потерях — поэтому основной парадигмой стали географически распределенные отказоустойчивые решения. Проще говоря – железки, дублирующие друг друга, которые стоят в двух разных дата-центрах.
I ступень: Два сервера со встроенными дисками
II ступень: СХД и две машины в одном ЦОДе.
III ступень: Разные ЦОДы и репликация между ними (самый распространенный вариант)
IV ступень: Виртуализация этого хозяйства. Кстати, в связку в середине можно воткнуть, например, дополнительно резервное копирование.
V ступень: Виртуализация СХД (EMC VPLEX)
Один из инструментов решения такой задачи – EMC VPLEX, на примере которого можно чётко понять плюсы этой самой виртуализации.
Сравнение систем
До VPLEX: есть два сервера, каждый видит свой том, между томами репликация. Один всегда стоит и ждёт, второй всегда работает. Резервный сервер не имеет прав на запись, пока не отказал основной ЦОД
После внедрения VPLEX: репликация не нужна. Оба сервера видят только один виртуальный том, как подключенный напрямую к себе. Каждый сервер работает со своим томом, и каждый думает, что это локальный том. В реальности каждый работает со своей СХД.
До: для переноса данных на другое хранилище (физическую СХД), нужна перенастройка серверов, кластеров и так далее. Это снижает отказоустойчивость и может стать причиной ошибок: при переконфигурации кластер может разъехаться, например.
После: можно без снижения отказоустойчивости и прозрачно для серверов перенести данные (все СХД скрыты под VPLEX и сервера про железо даже не знают). Механика такая: добавляем новую СХД, подключаем её под VPLEX, зеркалируем, не убирая старую, потом переключаем – и сервер даже не замечает.
До: есть проблемы с разными вендорами, например, нельзя настраивать репликацию HP с массивом EMC.
После: можно подключить массив HP и EMC (или других производителей) и спокойно из двух стораджей собрать том. Это особенно круто, потому что у крупных заказчиков часто гетерогенный «зоопарк», который плотно интегрируется и легко модернизируется. Это значит, что любую критичную систему можно легко и просто перенести на новое железо без сопутствующей головной боли.
До: нужно время на переключение репликации и кластера.
После: перезапускается только приложение в кластере, оно всегда либо на одной ноде, либо на второй, но прозрачно и быстро перебрасывается.
До: архитектура — геокластер со всеми ограничениями.
После: архитектура – локальный кластер. Точнее, сервер так думает, и поэтому нет никаких сложностей в работе с ним.
До: необходимо ПО управления репликацией.
После: VPLEX на системном уровне следит за репликацией. Да и вообще, репликации, по сути, нет – есть «зеркало».
До: SRM накладывает свои ограничения на перезапуск VM в резервном ЦОДе.
После: стандартный VMotion работает при перемещении ВМ на резервную площадку (предваряя вопрос про канал: да, у нас широкий канал между площадками, так как мы говорим о серьёзном Disaster Recovery решении).
Как переезжать без простоя системы?
Переезжать с одной железки на другую приходится довольно часто: примерно раз в два-три года высоконагруженные системы требуют модернизации. В России реалии таковы, что многие заказчики просто боятся трогать свои системы и плодят «костыли» вместо переноса — и часто вполне оправданно, потому что примеров ошибок при переезде тоже много. С VPLEX переезжать просто — главное, знать про такую возможность.
Ещё один интересный момент — это перенос систем, по которым производительность непонятна. Например, банк запускает новый сервис, и его наличие становится через полгода важным конкурентным преимуществом. Нагрузка на железо растёт, нужно делать сложный и мучительный переезд (банки боятся даже одной потерянной транзакции, и даже 5 миллисекунд промаха — это проблема). В этом случае VPLEX-подобные системы становятся единственной более-менее разумной альтернативой. Иначе быстро и прозрачно подменить СХД будет непросто.
Допустим, система старая и жестко привязана к железу. При переезде на другое железо нужна среда, которая поможет осуществить перенос без влияния на работу пользователей и сервисов. Поместив такую систему под VPLEX, ее можно будет легко переносить между вендорами — приложения даже не заметят. С поддержкой ОС проблем также не возникает. В списке совместимости все основные операционки, встречающиеся у заказчика. В экзотических случаях, можно проверить совместимость с вендором или партнером и получить подтверждение.
Берём действующую систему СХД (слева) и зеркалируем средствами EMC VPLEX незаметно для сервера и приложений(справа). В терминах VPLEX это называется Distributed volume. Сервер продолжает думать что работает с одним стораджем и одним томом.
Фактически, первая СХД становится чем-то похожим на кусок зеркала. Её мы отключаем — и переезд готов.
Про синхронизацию
Есть три конфигурации – Local (1 ЦОД), Metro (синхронная репликация) и Geo (2 асинхронных ЦОД). Разновидность синхронной репликации с x-подключением – Campus. Синхронная репликация наиболее востребована (это 99% внедрений в России). Здесь в дело вступает бессердечная скорость света, которая устанавливает максимальное расстояние между ЦОДами — должно хватить 5 миллисекунд на прохождение сигнала. Можно настраивать и с 10 миллисекундами, но чем ближе ЦОДы — тем лучше. Обычно это 30-40 километров максимум.
Варианты схемы для синхронной репликации
VPLEX даёт серверам доступ на чтение-запись. Серверы видят один том данных каждый на своей площадке, но на деле это виртуальный распределённый том VPLEX. Metro позволяет большие задержки, Campus даёт большую надёжность. В Campus это выглядит так:
Самое приятное — никаких проблем с переключением репликации при перемещении виртуальных машин.
При использовании Campus отказ всех дисковых подсистем и локальной части VPLEX приведет к потере только половины путей для диска. Сами же диски останутся доступны серверам – только уже через x-подключение и удаленную часть VPLEX. Вот как это работает для Oracle.
Есть ещё ситуации типа ЦОДов в Москве и Новосибирске, они решаются асинхронной репликацией. Её VPLEX тоже умеет, но уже в конфигурации Geo.
А если авария?
Здесь VPLEX Metro и VMware HA (но может быть и Hyper-V) — и авария в одном из ЦОДов.
Сервисы перезапускаются в другом ЦОД без участия администратора, т.к. для Vmware это единый HA кластер.
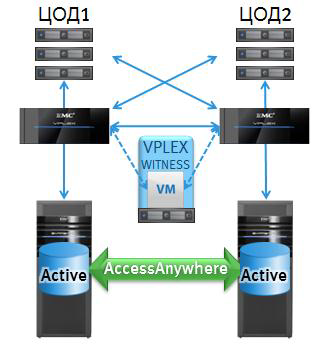
В середине есть Witness — это виртуалка, которая контролирует состояние обоих кластеров и следит, чтобы при разрыве связи между ними оба не начали обрабатывать данные. То есть защищает от машинной «шизофрении». Witness позволяет в случае аварии работать с наиболее актуальной копией только одному кластеру — и после устранения проблемы второй просто получает более свежую версию данных и продолжает работать.
Witness разворачивается либо на третьей площадке, либо у облачного провайдера. Она коммуницирует с EMC VPLEX по IP посредством VPN. Больше ей ничего для работы не нужно.
Данные на удалённой площадке
Получить данные, физически расположенные в другом ЦОДе — также не вопрос. Зачем? Например, если в основном ЦОДе не хватает места. Тогда можно занять его в резервном.
Гетерогенное железо
Экосистема «VPLEX и партнеры»
В центре решений КРОК на базе технологий EMC мы построили такое решение. На одной площадке СХД EMC, сервера Cisco (для многих новость, что Cisco выпускает весьма хорошие сервера), на другой площадке виртуализована система Hitachi, а сервера IBM. Но как видите, все остальные вендоры тоже спокойно поддерживаются. На той неделе мы проводили демонстрацию системы для одного из банков, для которого и был собран стенд, и их специалисты сами убедились, что косяков нет, и интеграция реально гладкая. В ходе демонстрации мы имитировали различные аварии и сбои, которые мы заготовили, либо заказчик их предлагал по ходу встречи. Следующий этап – пилотный проект на нескольких небольших системах. Несмотря на наличие уже опыта эксплуатации этих железок, каждый заказчик хочет убедиться сам, что все работает. Центр решений сделан именно для этого, так что мы не против.
Ещё бонусы
Как работает доступ к данным?
Наверняка вам уже интересно, как же это работает уровнем ниже. Итак, раньше при записи на одной площадке и чтении с другой был шанс попасть на неактуальные данные. В VPLEX есть система каталогов, которая показывает, на какой ноде данные наиболее свежие, поэтому кэш-память можно считать общей на всю систему.
При чтении только что записанного другой машиной участка работает вот такая связка.
Конфигурация
Можно начать с малого, например, поставить блок, который содержит 2 контроллера (то есть это уже отказоустойчивая конфигурация, до 500 000 iops) — дальше можно перейти к средней конфигурации или достичь максимальной 4-узловой конфигурации в стойке в каждом из ЦОД. То есть до 2.000.000 iops, что не всегда нужно, но вполне достижимо. Можно пойти дальше и создавать домены VPLEX, но до этого на нашем рынке еще, думаю, никто не дорос.
Плюсы и минусы
IBM SAN Volume Controller
Упростите управление инфраструктурой хранения данных, многоуровневой структурой хранения и дополнительными функциями

Преимущества SAN Volume Controller (SVC) для вашего бизнеса
IBM SAN Volume Controller (SVC) на основе программного обеспечения IBM Spectrum Virtualize™, входящего в семейство продуктов IBM Spectrum Storage™, относится к системам хранения данных корпоративного класса. SVC помогает организациям улучшить экономические показатели управления данными за счет масштабирования нагрузки, что особенно важно для успешной работы. Системы SVC могут обрабатывать огромные объемы данных из мобильных и социальных приложений, поддерживать развертывание в гибких гибридных облачных средах, а также обеспечивать производительность и масштабируемость, необходимую для получения аналитической информации с помощью новейших аналитических технологий.
Преимущества
Повышение ценности данных
Сократите расходы на хранение за счет более эффективного использования данных и ускорения работы приложений, анализирующих бизнес-информацию.
Повышение безопасности данных
Усильте защиту данных от разглашения и разверните комплексную стратегию обеспечения высокой доступности, включая перераспределение приложений и данных и полное аварийное восстановление, в том числе в облаке.
Упрощение управления данными
Обеспечьте внедрение стратегии управления данными независимо от выбранной инфраструктуры с помощью тесно интегрированных функций корпоративного класса и единой системы управления в гетерогенных средах хранения данных.
Доступность на уровне 99,9999%
Обеспечьте высочайшие уровни доступности для поддержки важнейших приложений.
Защита от киберугроз
Добавьте линию защиты от программ-вымогателей с помощью неизменяемых и изолированных копий, которые можно восстановить в кратчайшие сроки после атаки.
Отличительные особенности IBM SAN Volume Controller
Улучшение работы хранилища
Технология IBM Spectrum Virtualize, применяемая в IBM SAN Volume Controller (SVC), позволяет изолировать приложения от физических устройств хранения данных. Это обеспечивает непрерывную работу приложений даже во время выполнения изменений в инфраструктуре хранения данных. Кроме того, при этом повышается эффективность использования как новых, так и имеющихся хранилищ. В целях повышения гибкости и снижения затрат в SVC добавлено множество функций корпоративного класса, которые традиционно применялись по отдельности в системах хранения данных.
Улучшенные возможности для гибридного облака
Развертывание гибридного облака порождает новые проблемы. Каким образом ее внедрить без замены имеющихся систем хранения на системы, поддерживающие облачную среду? Если используются решения нескольких поставщиков, то как максимально упростить решения с несколькими облачными средами? IBM Spectrum Virtualize в SVC и общедоступных облачных средах обеспечивает миграцию данных в облако или аварийное восстановление в облаке с помощью одного гибридного облачного решения для более чем 500 поддерживаемых систем хранения данных, что позволяет существенно ускорить и упростить развертывание с одновременным сокращением стоимости.
Сокращение объема данных
Пулы для сокращения объемов данных поддерживают сложные технологии снижения расхода памяти: тонкое резервирование, дедупликация, сжатие, а также освобождение и повторное использование емкости. Благодаря сжатию с аппаратной поддержкой эти пулы можно использовать с активными первичными данными, что существенно расширяет круг данных, сокращение которых может оказаться полезным. Как в новых, так и в имеющихся хранилищах можно добиться заметного увеличения полезной емкости без ущерба для быстродействия приложений.
Устойчивость данных
В цифровую эпоху устойчивость данных имеет решающее значение. Вы должны быть защищены от разрушительных событий любого рода, включая природные катаклизмы, кибератаки и человеческие ошибки, и должны иметь возможность быстро восстановиться после инцидента. IBM SAN Volume Controller предоставляет полный набор функций по обеспечению отказоустойчивости и доступности данных, непрерывности бизнеса и защиты данных, включая миграцию данных без прерывания работы, удаленное зеркальное копирование, высокую доступность с помощью технологий расширяемых кластеров и IBM HyperSwap, а также стопроцентную доступность данных и неизменяемые копии для защиты от кибератак.
Повышение уровня доступности приложений
На крупных предприятиях отключение приложений недопустимо, однако перемещение данных по-прежнему является одной из основных причин плановых простоев. Виртуализация данных IBM Spectrum Virtualize с помощью SVC обеспечивает перемещение данных между целыми системами хранения данных или массивами, не ограничивая при этом доступ к данным. Данная функция может быть применена во время замены устаревших хранилищ на новые, перераспределения нагрузки или перемещения данных с дисковых накопителей во флэш-хранилища в многоуровневой инфраструктуре хранения.
Многоуровневая система хранения
Развертывание многоуровневой системы хранения данных является важной стратегией управления затратами на хранение данных. Однако вплоть до настоящего времени различия в работе и управлении, существующие между разными типами хранилищ (даже если они принадлежат одному поставщику), не позволяли развернуть полноценные многоуровневые системы хранения данных. Автоматическое обеспечение многоуровневого хранения с помощью функции Easy Tier на базе ИИ позволяет повысить производительность при меньших затратах за счет более эффективного использования флэш-памяти или нескольких уровней дисковых накопителей.
Доступность данных на уровне 99,9999%
Важность доступности данных для бизнеса невозможно переоценить: любой простой влечет за собой немедленные последствия в виде потери лояльности клиентов и финансовых расходов. Системы SVC с актуальным программным обеспечением гарантируют доступность данных на уровне 99,9999%. Эти системы обеспечивают отсутствие единой точки отказа, программные средства управления корпоративного класса и возможность проведения обслуживания параллельно с операциями ввода-вывода. Кроме того, облачный продукт IBM Storage Insights обнаруживает ошибки конфигурации для дальнейшего повышения уровня доступности.
Распределенная высокая доступность
Функция IBM HyperSwap поддерживает хранилища и серверы в двух центрах обработки данных. В данной конфигурации решение позволяет серверам в двух ЦОД одновременно обращаться к данным с поддержкой автоматического переключения в случае сбоя. В сочетании с функциями перераспределения серверных данных, например VMware vMotion или PowerVM Live Partition Mobility, данная конфигурация может обеспечить перенос носителей и виртуальных машин между двумя ЦОД, расположенных на расстоянии до 300 км друг от друга, без нарушения работы.
Управление на основе ИИ и упреждающая поддержка
IBM Storage Insights позволяет лучше отслеживать закономерности в показателях производительности и емкости ресурсов хранения и быстро реагировать на ситуации, в которых требуется вмешательство службы поддержки. Storage Insights отслеживает работоспособность, свободную емкость и производительность блочных систем хранения, управляемых с помощью SVC и сетевых интерфейсов Broadcom и Cisco, а также представляет консолидированную информацию на единой панели. Благодаря прогнозной аналитике на основе ИИ можно выявить потенциальные неполадки до того, как они превратятся в проблемы. Упрощенный процесс обращения в службу поддержки и автоматизация передачи журналов позволяет ускорить устранение неполадок.
Масштабируемость и производительность
Упрощенное управление
Программное обеспечение IBM Spectrum Virtualize предлагает удобный в использовании графический интерфейс для централизованного управления. Этот простой интерфейс обеспечивает согласованность административных задач настройки, управления и обслуживания в разных системах хранения данных, в том числе от разных производителей, что существенно упрощает управление и помогает снизить вероятность ошибок. SVC поддерживает Container Storage Interface (CSI), Red Hat Ansible, Microsoft System Center Operations Manager и VMware vCenter.
Расширенные возможности виртуализации сервера
Контейнеризация и виртуализация сервера помогают ускорить процесс инициализации сервера и снизить сопутствующие расходы; виртуализация системы хранения данных имеет аналогичные преимущества для хранения данных. IBM Spectrum Virtualize в SVC дополняет технологии контейнеризации и виртуализации сервера, в частности IBM PowerVM, Microsoft Hyper-V, VMware vSphere, Red Hat OpenShift, CRI-O и Kubernetes.



