Мне нужна Ваша помощь. Есть Железо HP Proliant ML350 на нем Windows SBS 20003 SP1. Raid 5. Получается 3 x HDD 70Gb – Raid5 = 144 Gb 1 x HDD вспомогательный.
Установлено DNS, DHCP, Exchange.
Сегодня ночью сам по себе server перезагрузился и перестал грузится, после 2 или 3 попытке он загрузился. Захожу в логии и пишет (The driver detected a controller error on) начал сразу смотреть device manager и показывает 2-контроллера (LSI Adapter, Ultra320 SCSI 2000 series, w10201030) желтого цвета с вопросительным знаком.
Может, обновит драйвер контроллера и как правильно это сделать.
Вопрос: Как устранить эту неполадку без малых потер или безболезненно, учитывая там Raid-5.
Всего записей: 116 | Зарегистр. 04-07-2008 | Отправлено:11:58 05-02-2014
ipmanyak
———- В сортире лучше быть юзером, чем админом.
Всего записей: 10822 | Зарегистр. 10-12-2003 | Отправлено:12:36 05-02-2014
Crocodial
Junior Member
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору 1) Да, уже скопировал. Сделал backup
2) в том то и дела что после (The driver detected a controller error on) ничего нету. Только до этого сообщение было еще одно (Driver detected an internal error in its data structures) и все.
3) Посмотрел на морду в корзине, все лампочки горят ЗЕЛЕНОГО цвета. 4) Есть HP array configuration utility, постараюсь через него войти и посмотрет
Всего записей: 116 | Зарегистр. 04-07-2008 | Отправлено:12:57 05-02-2014
ipmanyak
———- В сортире лучше быть юзером, чем админом.
Всего записей: 10822 | Зарегистр. 10-12-2003 | Отправлено:13:20 05-02-2014
Crocodial
Junior Member
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Да, как раз у меня тоже raid samrt array 641 controller. У меня на device manager показывает:
Проста driver обновит на (LSI adapter Ultra320 SCSI 2000 series, w/1020/1030 ScsiPort) Сейчас с нета скачаю и попробую.
Проста я не сталкивался с Raid 5, При обновление драйвера (LSI adapter Ultra320 SCSI 2000 series, w/1020/1030 ScsiPort) настройки raid 5 также сохраняется?
Кстати я запустил HP ACU, посмотрел вроде нормально, может тебе скину лог, посмотришь, может я что-то не угледел.
Всего записей: 116 | Зарегистр. 04-07-2008 | Отправлено:15:02 05-02-2014
ipmanyak
———- В сортире лучше быть юзером, чем админом.
Всего записей: 10822 | Зарегистр. 10-12-2003 | Отправлено:15:11 05-02-2014
Crocodial
Junior Member
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору я благодарен что сразу отвечаешь на мои вопросы. ipmanyak в начале я писал что:
3 x HDD 70Gb – Raid5 = 144 Gb 1 x HDD вспомогательный.
Может мне e-mail скинещь я тебе скриншот отправляю device manager и логи от ACU.
Если вернемся на device manager
Disk drives: HP Logical Volume SCSI Disk Device HP Logical Volume SCSI Disk Device
Logical Drive #1, RAID 5, 140 GB OK Logical Drive #2, RAID 5, 35 GB OK
В системе у тебя сколько дисков? По этим данным должно быть два диска такого объема. Их у тебя два? Операционка на каком стоит? Короче погляди в винде что там у тебя и в диспетчере дисков что показывает? Что в твоем понимании вспомогательный диск? Мне ничего не нужно отправлять, скриншоты выкладывай в различные обменники и ссылки на них сюда с тэгом url или img например на http://piccy.info/ или на http://pixs.ru/ Приведи ошибку из системного журнала на этот LSI. c полным текстом, номером ошибки и ее источником.
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Вот ссылки на скриншот с device manager
Система установлена на С Диске. Как показывает Disc Management
Disc 0 ( это С, D, E диски) общий объём 140 gb это и есть raid 5) Disc 1 (это F диск) объём 35 gb
Вывод: что система установлена на С диски на Raid 5 массиве.
А диск F (35 GB) вне массива. Это мое мнение. Я прав?
Всего записей: 116 | Зарегистр. 04-07-2008 | Отправлено:16:59 05-02-2014
ipmanyak
Platinum Member
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Crocodial Да. Так что если это всё у тебя в контроллере 641, то на LSI контроллер можно плевать. Но если хочешь, чтобы все было красиво, смотри ошибки в журнале системы. Ты так сюда о них и не написал. P.S. В следующий раз скриншот делай не всего экрана, а текущего окна, клавишами ALT+ Print Screen
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Выключил Сервак, открыл крышку проверил все разъёмы, шлейфы, питания после включил Сервак и на LSI ках перестал показывать восклицательный знак с желтым цветом. Сам был удивлен. Кстати что мне пришло в голову 2 дня в одну и то же время почти 00:20 он сам по себе перегружался. А у меня в 23:30 каждый день начинается backup на внешний носитель. Вот думаю сегодня его попробую отключить и проверить. Позже потом отпишусь.
А ошибки в журнале системы:
Системное администрирование и мониторинг Linux/Windows серверов и видео CDN
Статьи по настройке и администрированию Windows/Linux систем
В предыдущей статье шла речь о мониторинге физических дисков под LSI 2108 Megaraid контроллером. Теперь хочу навести инструкцию по мониторингу физических дисков под Hewlett-Packard Company Smart Array контроллером под дистрибутивом Ubuntu 12.04. Эта инструкция подойдет под любой дистрибутив линукс, отличается только процесс установки утилиты мониторинга hpacucli.
Мониторинг дисков используя hpacucli
Для начала убедимся, что у нас HP контроллер. Для этого есть очень удобный и распространенный способ – просмотр имеющихся pci-устройств командой lspci.
Так же признаком HP-raid контроллера есть наличие символьного устройства hpilo.
Так же можно воспользоваться утилитами smartctl и lshw чтобы узнать тип подключенных дисков, но это не многообещающий вывод. Он только даст нам направление, в котором нужно копать.
После того, как мы убедились в наличии HP/Compaq Smart Array Controller — первым делом установим специализированную (заточенную под HP рейд контроллеры) утилиту hpacucli.
Теперь проверяем работу утилиты. Для начала посмотрим конфигурацию контроллера.
Как видим, у нас есть три логических диска, которые являют собой два RAID1 и один RAID 5. В первых два рейда входит по два физических диска, в третий – 4 физических диска. Контроллер подключен к слоту с номером 0 (Slot 0). Команда hpacucli может и не найти ни единого контроллера, даже если он действительно подключен и нормально работает. Если вы столкнулись с такой проблемой…
… и при этом вы точно уверены в том, что у вас HP контроллер – нужно установить дополнительную утилиту uname26. Дело в том, что некоторые программы заточены под ядро 2.6, и их нужно запускать в режиме совместимости с ядрами 3.0 и выше. hpacucli утилита не исключение и для корректной работы (в отдельных случаях) ее нужно запускать в режиме совместимости (в контексте ядра 2.6). Для этого качаем утилиту uname26 и компилируем.
Теперь запускаем нашу команду в контексте 2.6 ярда.
Проблема решена. Если по прежнему осталась — попробуйте установить самую последнюю версию программы.
С этого вывода мы можем наблюдать статусы логических и физических дисков, но, как мы знаем, еще нужно мониторить статус батареи (BBU), статус контроллера и статус рейда. Для этого используем детальный вывод и словим статус контроллера и батареи.
Теперь можно словить статус рейда.
Всю нужную информацию мы получили. Можно также написать маленький скрипт, который будет нам выводить общий статус здоровья дисков под HP/Compaq Smart Array Controller.
Немного разъясню скрипт. Вначале я ловлю статусы всех контроллеров, рейдов, батареи, физических и логических дисков. Очевидно, что если с ними нет проблем, то последние два символа каждой словленной строки – «ОК». Таким образом, была написана функция read_stat, которая выводит последние два символа строки состояния каждого элемента (т.е. слово «ОК»), и если эти символы не совпадают с «ОК» — проблема с одним из элементов, следовательно, ловим эту ошибку и увеличиваем счетчик на 1. Чтобы увидеть лог ошибок – скрипт нужно запустить с аргументом log.
Как видим, проблем с HP контроллером нет. Теперь запустим скрипт на сервере, где есть проблема.
Список полезные команд для проверки дисков под CCISS (HP/Compaq Smart Array Controller) контроллером используя утилиту hpacucli.
Замена BBU для Write Back cache
Что такое Write Back cache я уже объяснял в предыдущих статьях. К примеру, в megaraid контроллерах политика записи на диск может включаться для отдельного виртуального диска, в HP рейдах, она включается для всего контроллера. Что нам нужно сделать, это заменить (или убедиться что работает) BBU и включить. Проверяем что у нас на данный момент.
Как видим, кэш выключен, но с BBU все в порядке, по этому можно свободно включить политику кэширования.
И проверяем статус после.
Вот, в принципе, и все.
Мониторинг дисков используя smartctl
Так же можно использовать smartctl для мониторинга дисков за HP/Compaq Smart Array контроллером. У нас есть 8 физических дисков. Поэтому можно запустить проверку всех параметров первых 8-ми дисков задав тип устройства CCISS (HP/Compaq Smart Array Controller). На практики, тип логического устройства не имеет никакого значения ТОЛЬКО для HP контроллеров под дистрибутивом Ubuntu 12.04. На остальных такой зависимости не проверял, так что сначала проверьте или совпадает модель физического диска при разных комбинациях логических устройств. К примеру
Как видим при смене логического устройства(sda, sdb, sdc), но при неизменном порте устройства (cciss,0) – мы получаем информацию об одном и том же устройстве. Так что можно смело запускать скрипт такого типа, для проверки состояния дисков.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь Для начала добавим демон в автозагрузку.
Практика LSI
Даже самые заядлые скептики уже признают, что технологии SSD обладают рядом неоспоримых преимуществ по сравнению с обычными жесткими дисками и позволяют получить значительно большую производительность операций ввода/вывода (а в некоторых случаях скорости I/O — много не бывает). Вместе с тем, SSD еще не готовы к повсеместному внедрению вместо традиционных жестких дисков по целому ряду причин: начиная с цены и заканчивая надежностью. Что же делать? На выручку приходят гибридные решения, которые сочетают традиционные диски с SSD, позволяя получить (пусть и с определенными оговорками) преимущества обоих решений.
Если не углубляться в детали, то сам принцип работы гибридных систем достаточно прост (а если углубиться — то можно настолько погрузиться, что и не вернешься за год) и одинаков для всех систем, начиная с дисков Seagate Momentus XT и Apple Fusion Drive, заканчивая дорогими и сложными решениями для больших систем хранения данных и дата-центров, о которых сегодня и пойдет речь.
Для основного хранения данных используются традиционные жесткие диски, по необходимости объединенные в RAID, а SSD используется для кэширования самых часто используемых данных, к которым надо обращаться чаще всего. Управление кэшированием системы берут на себя, и чаще всего кэш-раздел в системе вообще недоступен в виде отдельного диска.
В больших и «серьезных» системах вопросы оптимизации ввода/вывода стоят еще острее, чем для настольных компьютеров. То, что для пользователя является секундной задержкой в запуске тяжелой программы, в случае нагруженного сервера может вылиться во многие тысячи долларов убытков, если дисковая подсистема станет «бутылочным горлышком», замедляющим всю работу.
Говоря о больших системах хранения данных, нельзя не вспомнить про компанию LSI, которая, являясь одним из крупнейших поставщиков для систем хранения данных, не могла остаться в стороне. В портфеле продуктов LSI есть набор решений для ускорения работы дисковых систем, объединенных в семейство Nytro.
Линейка этих продуктов делится на три группы.
Nytro WarpDrive Application Acceleration Card
SSD диск, выполненный в виде PCI-express карты, которая может быть установлена в большинство современных серверов, предоставляя высокоскоростной диск для нужд системы.
Комплекс из карты WarpDrive и специализированного ПО, интегрирующегося в систему и использующего SSD для кеширования критичных данных. Такой подход позволяет ускорять любые блочные системы хранения, вне зависимости от способа подключения (iSCSI, DAS, SAS, FC или любой другой). Все что нужно для ускорения – блочное устройство.
Nytro MegaRAID Application Acceleration Card
Эти карты по-сути являются RAID контроллерами, построенными на топовых решениях RAID-on-chip от LSI, с добавлением скоростного NAND Flash. Специальные алгоритмы автоматически определяют данные, которые надо кешировать, поэтому данное решение работает независимо от операционной системы и полностью прозрачно для нее.
Чтобы продемонстрировать на практике, как можно ускорить работу с вводом/выводом, 11 апреля в LSI провели семинар или «workshop», посвященный этой теме (подробности об этом мероприятии приведены чуть ниже).
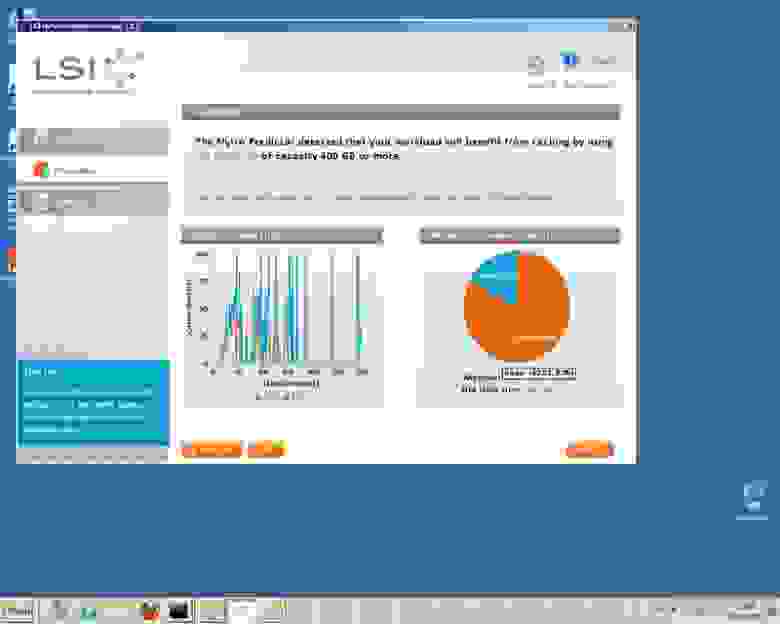
Поскольку корпоративный IT требует разумного и взвешенного подхода, перед внедрением какой-либо технологии или решения необходимо убедиться, решит ли оно существующую проблему. Для того, чтобы помочь разобраться в этом вопросе, в LSI разработали програму Nytro Predictor, работающую с двумя основными серверными операционными системами — Windows и Linux. Predictor использует стандартные для каждой системы инструменты для сбора статистики: xperf для Windows и blktrace для Linux, работая в фоне, полностью прозрачно для пользовательских задач.
Для понимания Predictor-у необходимо какое-то время поработать в фоне, собирая данные, пока компьютер выполняет типичные задачи (лучше дать времени с запасом). После этого можно ознакомиться с результатами его работы, и на основании этого уже решать — что делать.
Теперь давайте вернемся к техническому семинару и посмотрим на все это на практике.
Для экспериментов использовался тестовый стенд следующей конфигурации:
Сервер SuperMicro на платформе X8ST3-F, OS Windows 2008 Server R2
Система хранения данных 630J
Nytro MegaRAID 8110 (200 Gb)
Nytro XD BLP4-400 (400 Gb)
Контроллер MegaRAID 9271-4i
Контроллер 9266-8i с функцией CacheVault и блоком CVM01
Запуск Predictor-а и моделирование нагрузки. В роли типичной нагрузки выступал MSSQL запрос, обрабатывающий много данных.
Запустили профайлер для сбора данных и потом выполнили запрос. Если профайлер работал мало времени — результаты будут малополезными
Собрав данных в ходе работы сервера в его «типичном» режиме, мы отдаем их на обрабоку «предсказателю». Проанализировав их, он выносит свой вердикт.
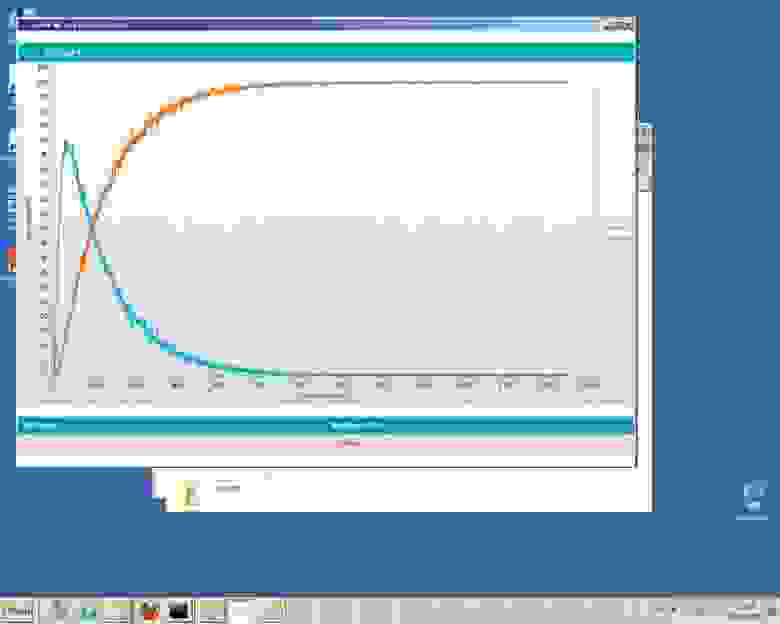
Можно подробно посмотреть, как распределялись запросы чтения/записи в зависимости от размеров блока, и даже в какие сектора шли чтение/запись.
Вот очень показательный пример работы Nytro Predictor на реальной SAN-системе. На графиках очень четко видно, как по мере «прогрева» кеш оптимизирует ввод-вывод.
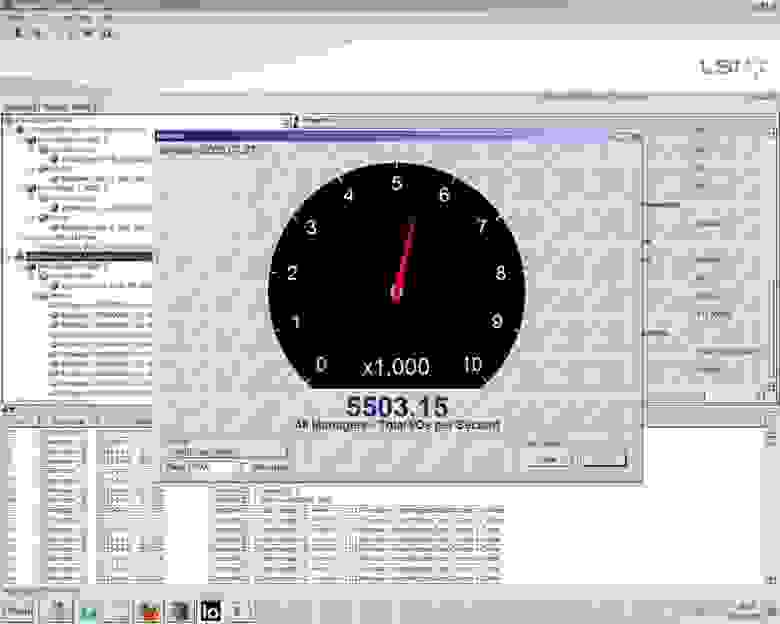
Разумеется, лучше всего результаты смотреть на реальных тестах. Вот пример, использовавшийся в ходе workshop. Для начала замер производительности системы на RAID0, собранной из 10 HDD Seagate Cheetah 146Gb 15K. JBOD LSI 620J. Контроллер: 9266-8i. Платформа: SuperMicro X8ST3-F, OS Windows 2008 Server R2
Теперь, замер после подключения Nytro MegaRAID 8110, обратите внимание, что полученные результаты более чем на порядок лучше.
Вот простой пример того, как работает SSD в больших системах хранения данных. Если у вас остались вопросы — буду рад на них ответить.