Как обнаружить бота на сайте или определяем загрузку страницы с помощью Chrome Headless

характеру их поведения на сайте. И хотя она все еще находится в разработке, но вы уже можете начать использовать ее. Код библиотеки доступен на Github по ссылке. В настоящее время я тестирую новую технику обнаружения, не стесняйтесь оспаривать ее эффективность и целесообразность работы над ней, а также писать мне.
Что представляет собой headless браузер?
Headless браузер – это браузер без графического интерфейса, который используется для загрузки и обработки содержимого веб-страниц. Им можно программно управлять для автоматизации выполнения различных задач, таких как выполнение тестов или создания скриншотов веб-страниц.
Зачем может понадобится определять загрузку страницы headless браузером?
Помимо этих двух вполне безобидных вариантов использования, упомянутых нами выше, headless браузер также может использоваться для вредоносных целей. Наиболее частым случаем его такого использования это парсинг веб-страниц, увеличение количества показов рекламы или поиск уязвимостей на веб-сайте.
До сих пор одним из самых популярных headless браузеров был PhantomJS. И поскольку он разработан основе платформы Qt, то это подразумевает наличия большого числа отличий от популярных браузеров. Как будет показано в этом посте ниже, его можно обнаружить с помощью некоторых достаточно простых методов.
Начиная с версии 59, Google выпустила headless версию своего браузера Chrome. В отличие от PhantomJS, он основан на обычном Chrome, а не другой платформе, что затрудняет обнаружение его присутствия на сайте.
User agent
Следующий фрагмент кода, позволяет определить присутствие headless Chrome:
Тип пользовательского агента можно также определить из содержимого HTTP заголовков. Однако подменить его наименование злоумышленнику для обоих случаев простая тривиальная задача.
Plugins
Обращение к свойству navigator.plugins возвращает массив подключаемых в браузере плагинов. Обычно в Chrome мы находим плагины в любом случае подключаемые по умолчанию, например, такие как Chrome PDF viewer или Google Native Client. И напротив, в headlessрежиме, возвращаемый массив не содержит ни одного плагина.
Languages
WebGL
WebGL, предоставляет API для отображения результатов 3D-рендеринга на холсте HTML canvas. С помощью этого API можно запросить возможности графического процессора, а также его средств визуализации.
Тем не менее не все Chrome headless будут иметь одинаковые значения для рендера и средства визуализации. Другие сохраняют значения, которые также можно найти в headless версии браузера. Тем не менее, наличие значений Mesa Offscreen и Brian Paul явно указывают на использвание headless версии.
Browser features
Библиотека Modernizr позволяет проверить, присутствует ли в браузере широкий спектр новых возможностей HTML5 и CSS3. Единственная разница, которую мы можем обнаружить между Chrome и headless Chrome, заключается в том, что последний не имеет hairline функциональности, которая определяет поддержку hidpi для retina экранов устройств.
Отсутствующие изображения
И наконец, рассмотрим последний метод для обнаружения ботов, который является, с моей точки зрения, наиболее надежным. Он основан на вычислении браузером Chrome размера изображения, используемого в случае если изображение не может быть загружено.
В случае простого браузера Chrome изображение будет иметь ширину и высоту, которые зависят от масштаба окна браузера, но отличны от нуля. В headless Chrome изображение будет иметь ширину и высоту равную нулю.
Опыт 2 миллионов headless-сессий
Опубликовано 4 июня 2018 года в корпоративном блоге browserless
Рады сообщить, что недавно мы преодолели рубеж в два миллиона обслуженных сессий! Это миллионы сгенерированных скриншотов, напечатанных PDF и протестированных сайтов. Мы сделали почти всё, что вы можете придумать делать с headless-браузером.
Хотя приятно достичь такой вехи, но на пути оказалось явно много накладок и проблем. В связи с огромным объёмом полученного трафика хотелось бы сделать шаг назад и изложить общие рекомендации для запуска headless-браузеров (и puppeteer) в продакшне.
Вот некоторые советы.
1. Не используйте headless-браузер вообще

Изменчивое потребление ресурсов Headless Chrome
Никоим образом, если это вообще возможно, вообще не запускайте браузер в режиме headless. Особенно на той же инфраструктуре, что и ваше приложение (см. выше). Headless-браузер непредсказуем, прожорлив и размножается как мистер Мисикс из «Рика и Морти». Почти всё, что может сделать браузер (кроме интерполирования и запуска JavaScript), можно сделать с помощью простых инструментов Linux. Библиотеки Cheerio и другие предлагают элегантный Node API для извлечения данных HTTP-запросами и скрапинга, если такова ваша цель.
Например, вы можете забрать страницу (предполагая, что это некий HTML) и произвести скрапинг простыми командами вроде таких:
Очевидно, скрипт не охватывает все случаи использования, и если вы читаете данную статью, то скорее всего вам придётся использовать headless-браузер. Поэтому приступим.
2. Не запускайте headless-браузер без необходимости
Мы столкнулись с многочисленными пользователями, которые пытаются держать браузер запущенным, даже если он не используется (с открытыми соединениями). Хотя это может быть хорошей стратегией, чтобы ускорить запуск сеанса, но приведёт к краху через несколько часов. Во многом потому что браузеры любят кэшировать всё подряд и постепенно выедают память. Как только вы прекратили интенсивно использовать браузер — сразу закройте его!
В browserless мы обычно сами исправляем эту ошибку за пользователей, всегда устанавливая какой-то таймер на сессию и закрывая браузер при отключении WebSocket. Но если вы не используете наш сервис или резервный образ Docker, то обязательно убедитесь в каком-нибудь автоматическом закрытии браузера, потому что будет неприятно, когда всё упадёт посреди ночи.
3. Ваш друг page.evaluate
В Puppeteer есть много приятных методов вроде сохранения DOM-селекторов и прочего в окружении Node. Хотя это очень удобно, но вы легко можете выстрелить себе в ногу, если что-то на странице заставит мутировать этот узел DOM. Пусть это не так круто, но в реальности лучше всю работу на стороне браузера выполнять в контексте браузера. Обычно это означает загрузку page.evaulate для всей работы, которую надо сделать.
Например, вместо чего-то подобного (три действия async):
Лучше сделать так (одно действие async):
Другое преимущество обернуть действия в вызов evaluate — это переносимость: этот код можно для проверки запустить в браузере вместо того, чтобы пытаться переписать код Node. Конечно, всегда рекомендуется использовать отладчик для сокращения времени разработки.
4. Распараллеливайте браузеры, а не веб-страницы
Лучше сделайте так:
5. Очередь и ограничение параллельной работы
Лучший и самый простой способ — взять наш образ Docker и запустить его с необходимыми параметрами:
6. Не забывайте про page.waitForNavigation
Например, такой console.log не срабатывает в одном месте (см. демо):
7. Используйте Docker для всего необходимого
А чтобы избежать процессов-зомби (обычное дело в Chrome), то лучше для правильного запуска использовать что-то вроде dumb-init:
Если хотите узнать больше, взгляните на наш Dockerfile.
8. Помните о двух разных средах выполнения
Полезно помнить, что здесь две среды выполнения JavaScript (Node и браузер). Это отлично для разделения задач, но неизбежно происходит путаница, потому что некоторые методы потребуют явной передачи ссылок вместо замыканий или подъёмов (hoistings).
Таким образом, вместо ссылки на selector через замыкания:
Как работает Headless Chrome
Уже из названия понятно, что headless-браузер — это нечто без головы. В контексте фронтенда — это незаменимый инструмент разработчика, с помощью которого можно тестировать код, проверять качество и соответствие верстке. Виталий Слободин на Frontend Conf решил, что необходимо познакомиться с устройством этого инструмента поближе.
Под катом компоненты и особенности работы Headless Chrome, интересные сценарии использования Headless Chrome. Вторая часть про Puppeteer — удобную Node.js-библиотеку для управления Headless-режимом в Google Chrome и Chromium.
О спикере: Виталий Слободин — бывший разработчик PhantomJS — тот, кто закрыл его и похоронил. Иногда помогает Константину Токареву ( annulen) в «воскрешенной» версии QtWebKit — том самом QtWebKit, где есть поддержка ES6, Flexbox и многие других современных стандартов.
Виталий любит исследовать браузеры, в свободное время копаться в WebKit, Chrome и прочее, прочее. Про браузеры сегодня и поговорим, а именно про безголовые браузеры и всю их семейку призраков.
Что такое безголовый браузер?
Уже из названия понятно, что это нечто без головы. В контексте браузера это значит следующее.

Нас интересует только верхний компонент Browser UI. Это тот самый интерфейс пользователя — окошки, меню, всплывающие уведомления и все остальное.
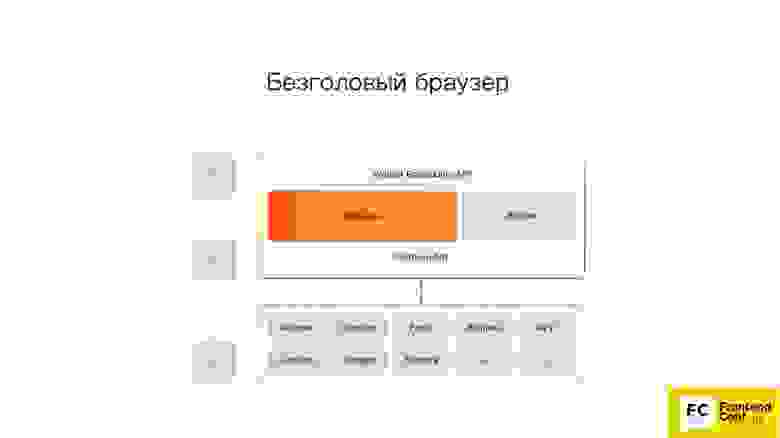
Так выглядит безголовый браузер. Заметили разницу? Мы полностью убираем интерфейс пользователя. Его больше нет. Остается только браузер.
Сегодня мы будем говорить именно про Headless Chrome (). В чем между ними разница? На самом деле, Chrome — это брендированная версия Chromium, у которой есть проприетарные кодеки, тот же самый H.264, интеграции с сервисами Google и все остальное. Chromium — это просто открытая реализация.

Дата рождения Headless Chrome: 2016 год. Если вы сталкивались с ним, то можете задать мне каверзный вопрос: «Как так, я помню новость 2017 года?» Дело в том, что команда инженеров из Google связывалась с разработчиками PhantomJS еще в 2016 году, когда они только-только начинали реализовывать Headless-режим в Chrome. Мы писали целые гуглдоки, как мы будем реализовывать интерфейс и прочее. Тогда Google хотели сделать интерфейс, полностью совместимый с PhantomJS. Это уже потом команда инженеров пришла к решению не делать таковую совместимость.
Об интерфейсе для управления (API), в качестве которого выступает Chrome DevTools protocol, поговорим позже и посмотрим, что с его помощью можно делать.
Эта статья будет строится по принципу пирамиды Puppeteer (с англ. кукловод). Хорошее название выбрано — кукловод — тот, кто управляет всеми остальными!

В основании пирамиды лежит Headless Chrome — безголовый Chrome — что это такое?
Headless Chrome

В центре — Headless browser — тот самый Chromium или Chrome (обычно Chromium). У него есть так называемые отрисовщики (RENDERER) — процессы, которые отрисовывают содержимое страницы (ваше окно). Причем, каждой вкладке нужен свой отрисовщик, поэтому, если открыть много вкладок, то Chrome запустит столько же процессов для отрисовки.
Поверх всего этого — ваше приложение. Если мы берем Chromium или Headless Chrome, то поверх него будет Chrome, либо какое-то приложение, в которое вы можете встроить его. Ближайшим аналогом можно назвать Steam. Все знают, что по сути Steam — это просто браузер к сайту Steam. Он, конечно, не headless, но похож на эту схему.
Есть 2 способа встраивать безголовый Chrome в ваше приложение (или его использовать):
Но помимо всего этого у вас еще появляются дополнительные вещи, в том числе:
Компоненты Chromium
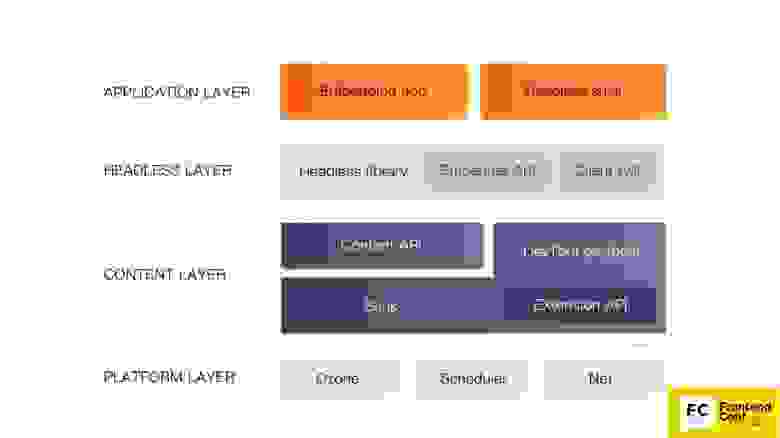
Опять слышу каверзный вопрос: «Зачем мне эта страшная схема? Я пишу под (вставьте название любимого фреймворка)».
Я считаю, что разработчик должен знать, как устроен его инструмент. Если вы пишите под React, вы должны знать, как работает React. Если вы пишите под Angular, вы должны знать, что у Angular под капотом.
Потому что в случае чего, допустим, фатальной ошибки или очень серьезного бага на продакшене, вам придется разбираться с «кишками», и вы просто можете потеряться там — где, что и как. Если вы, например, будете писать тесты или использовать Headless Chrome, вы тоже можете столкнуться с некоторыми его странностями поведения и багами. Поэтому я вам вкратце расскажу, какие у Chromium есть компоненты. Когда вы увидите большой stack trace, вы уже будете знать, в какую сторону копать и как вообще это можно поправить.
Самый низкий уровень Platform layer. Его компоненты:
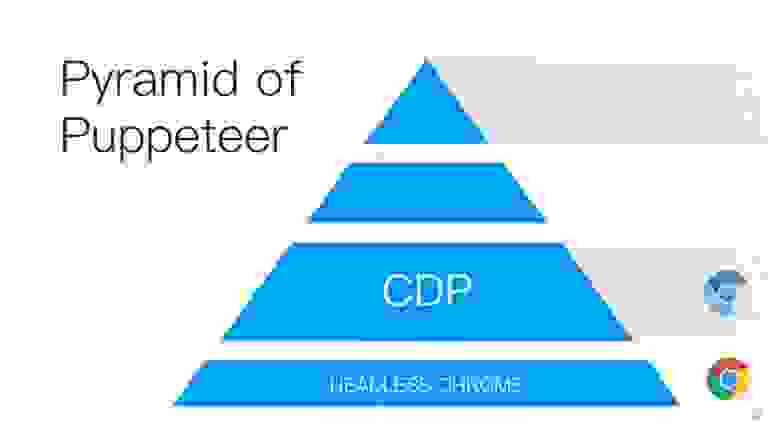
Chrome DevTools protocol
Мы все сталкивались с Chrome DevTools protocol, поскольку пользуемся панелью разработчиков в Chrome или удаленным отладчиком — теми же самыми средствами разработки. Если вы запускаете средства разработчика в удаленном режиме, общение с браузером происходит при помощи именно DevTools protocol. Когда вы ставите debugger, смотрите code coverage, используете геолокацию или еще что-нибудь — все это управляется при помощи DevTools.

На самом деле сам DevTools protocol имеет огромное количество методов. Ваше средство разработчика не имеет доступа, наверное, к 80% из них. Реально там можно делать все!
Давайте разберем, что из себя представляет этот протокол. На самом деле он очень простой. В нем есть 2 компонента:
Они общаются при помощи простого JSON:


Puppeteer
Установить Puppeteer можно при помощи любимого пакетного менеджера — будь то yarn, npm или любой другой.
Использовать его тоже легко — просто запрашиваете его в своем Node.js-скрипте, и уже, по сути, можете использовать.
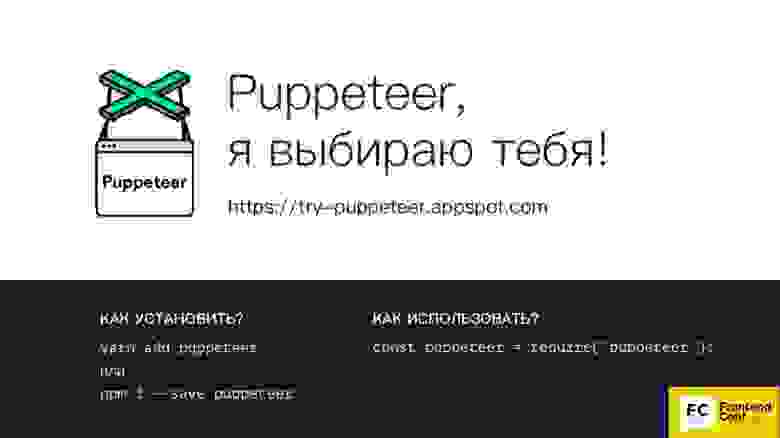
По ссылке https://try-puppeteer.appspot.com вы можете прямо на сайте написать скрипт, выполнить его и получить результат прямо в браузере. Все это будет реализовано при помощи Headless Chrome.
Рассмотрим простейший скрипт под Node.js:
Здесь мы просто открываем страничку и печатаем ее в PDF. Посмотрим работу этого скрипта в режиме реального времени:
Все будет классно, но непонятно — что там внутри. Конечно, у нас же headless-браузер, мы же ничего не видим. Поэтому у Puppeteer есть специальный флаг, который называется headless: false:
Он нужен для запуска headless-браузера в режиме headful, когда вы сможете увидеть какое-то окно и посмотреть, что же происходит с вашей страницей в режиме реального времени, то есть как ваш скрипт взаимодействует с вашей страницей.

Так будет выглядеть тот же самый скрипт, когда мы добавим этот флаг. Слева появляется окно браузера — уже нагляднее.
Плюсы Puppeteer:
+ Это Node.js-библиотека для безголового Chrome.
+ Поддержка legacy-версий Node.js >= 6.
+ Легкая установка.
+ Высокоуровневый API для управления всей этой гигантской машиной.
Безголовый Chrome устанавливается легко и без вмешательства в систему. При первой установке Puppeteer скачивает версию Chromium и устанавливает ее прямо в папку node_modules именно под вашу архитектуру и ОС. Вам не нужно ничего скачивать дополнительно, он это делает автоматически. Вы также можете использовать и вашу любимую версию Chrome, которая установлена у вас в системе. Это тоже можно сделать — Puppeteer предоставляет вам такой API.
К сожалению, есть и минусы, если брать именно базовую инсталляцию.
Минусы Puppeteer:
− Нет top-level функций: синхронизации закладок и паролей; поддержки профилей; аппаратного ускорения и т.д.
− Программный рендеринг — наиболее весомый минус. Все вычисления и отрисовки происходят на вашем CPU. Но и тут инженеры Google нас скоро удивят — работы по реализации аппаратного ускорения уже ведутся. Уже сейчас можно попытаться его использовать, если вы смелы и отважны.
− До недавнего времени не было поддержки расширений — теперь ЕСТЬ! Если вы хитрый разработчик, можете взять ваш любимый AdBlock, указать, как Puppeteer’у его использовать, и вся реклама будет заблокирована.
− Нет поддержки аудио/видео. Потому что, ну зачем headless-браузеру аудио и видео.
Что может Puppeteer:
Изоляция сессий
Что это такое, с чем ее едят, и не подавимся ли мы? — Не подавимся!
Изоляция сессий — это отдельные «хранилища» для каждой вкладки. Когда вы запускаете Puppeteer, вы можете создать новую страницу, и у каждой новой страницы у вас может быть отдельное хранилище, в том числе:
Изоляция сессий позволяет сэкономить ресурсы и время при запуске параллельных сессий. Допустим, вы тестируете сайт, который собирается в development-режиме, то есть bundle не минимизированы, и весят 20 МБ. Если вы хотите просто его закэшировать, то можете указать Puppeteer использовать кэш общий для всех страниц, которые создаются, и этот bundle будет закэширован.
Можно сериализовать сессии для последующего использования. Вы пишите тест, который проверяет некое действие у вас на сайте. Но у вас есть проблема — сайт требует авторизацию. Вы же не будете в каждом тесте постоянно добавлять before для авторизации на сайте. Puppeteer позволяет залогиниться на сайте один раз, и потом переиспользовать эту сессию в дальнейшем.
Виртуальные таймеры
Возможно, вы уже используете виртуальные таймеры. Если вы двигали ползунок в средстве разработчика, который ускоряет или замедляет анимацию (и мыли после этого руки конечно же!), то в этот момент вы использовали виртуальные таймеры в браузере.
Браузер может использовать виртуальные таймеры вместо реальных, чтобы «прокрутить» время вперед для ускорения загрузки страницы или завершения анимации. Допустим, у вас тот же самый тест, вы заходите на главную страницу, а там анимация на 30 секунд. Никому не выгодно, чтобы тест ждал все это время. Поэтому вы можете просто ускорить анимацию, чтобы она была завершена мгновенно при загрузке страницы, и ваш тест продолжил работу.
Можно остановить время, пока выполняется сетевой запрос. Например, вы тестируете реакцию вашего приложения на то, когда запрос, ушедший на бэкенд, очень долго выполняется, либо возвращается с ошибкой. Вы можете остановить время — Puppeteer это позволяет.
На слайде ниже есть еще один вариант: остановить и продолжить работу отрисовщика (renderer). В экспериментальном режиме была возможность сказать браузеру не заниматься отрисовкой, а позже, если понадобится, запросить скриншот. Тогда бы безголовый Chrome все бы быстро отрисовал, выдал скриншот, и снова перестал бы отрисовывать что-либо. К сожалению, разработчики уже успели поменять принцип работы этого API и такой функции больше нет.
Схематичный вид виртуальных таймеров ниже.

В верхней строке два обычных таймера: первый стартует в первую единицу времени и выполняется за одну единицу времени, второй стартует в третью единицу времени и выполняется за три единицы времени.
Ускорение таймеров — они запускаются друг за другом. Когда мы их приостанавливаем, у нас появляется промежуток времени, после которого все таймеры стартанут.
Рассмотрим это на примере. Ниже обрезанный кусок кода, который по сути просто загружает страницу с анимацией с codepen.io и ждет:
Это демонстрация выполнения в ходе доклада — просто анимация.
Теперь при помощи Chrome DevTools protocol отправим метод, который называется Animation.setPlaybackRate, передадим в качестве параметров ему playbackRate с значением 12:
Загружаем ту же самую ссылку, и анимашка стала работать гораздо быстрее. Это происходит за счет того, что мы использовали виртуальный таймер и ускорили проигрывание анимации в 12 раз.
Давайте теперь проведем эксперимент — передадим playbackRate: 0 — и посмотрим, что же будет. А будет вот что: анимации вообще нет, она не проигрывается. Нулевое и отрицательные значения просто приостанавливают полностью всю анимацию.
Работа с сетевыми запросами
Вы можете перехватывать сетевые запросы путем установки следующего флага:
В таком режиме появляется дополнительное событие, которое срабатывает, когда отправляется или приходит какой-то сетевой запрос.
Вы можете менять запрос на лету. Это значит, что вы можете полностью менять все его содержимое (body) и его заголовки, инспектировать, даже отменять запрос.
Это нужно для того, чтобы обрабатывать авторизацию или аутентификацию, в том числе базовую аутентификацию по HTTP.
Еще вы можете сделать покрытие кода (JS/CSS). При помощи Puppeteer можно все это автоматизировать. Все мы знаем утилиты, которые могут загрузить страничку, показать, какие классы в ней используются и т.д. Но довольны ли мы ими? Думаю, нет.
Браузер знает лучше, какие селекторы и классы используются — он же браузер! Он всегда знает, какой JavaScript выполнился, какой нет, какой CSS используется, какой нет.
Опять на помощь приходит Chrome DevTools protocol:
В первых двух строчках запускаем сравнительно новую фичу, которая позволяет узнать покрытие кода. Запускаем JS и CSS, переходим на какую-то страничку, потом говорим — стоп — и можем посмотреть результаты. Причем это не какие-то мнимые результаты, а те, которые видит браузер именно за счет движка.
Помимо всего прочего, уже есть плагин, который для Puppeteer это все экспортирует в istanbul.
На вершине пирамиды Puppeteer находится скрипт, который вы написали на Node.js — он как крестный отец всем нижним пунктам.

Но… «не всё спокойно в датском королевстве. » — как писал Уильям Шекспир.
Что не так с безголовыми браузерами?
У безголовых браузеров есть проблемы несмотря на то, что все их крутые фичи могут так много.
Отличие в рендеринге страницы на разных платформах
Я очень люблю этот пункт и постоянно про это рассказываю. Давайте посмотрим на эту картинку.

Здесь обычная страничка с обычным текстом: справа — отрисовка в Chrome на Linux, слева — под Windows. Те, кто тестирует скриншотами, знают, что всегда устанавливается значение, называемое «порогом погрешности», которое определяет, когда скриншот считается идентичным, а когда нет.
На самом деле проблема в том, что как бы вы не старались установить этот порог, погрешность всегда будет выходить за эту грань, и вы все равно будете получать ложно позитивные результаты. Это связано с тем, что все страницы, и даже веб-шрифты рендерятся по-разному на всех трех платформах — на Windows по одному алгоритму, на MacOS по-другому, в Linux вообще зоопарк. Вы не можете просто взять и тестировать скриншотами.
Вы скажете: «Мне просто нужна эталонная машина, где я буду запускать все эти тесты и сравнивать скриншоты». Но на самом деле это дико неудобно, потому что вам придется ждать CI, а вы хотите здесь и сейчас локально на машине у себя проверить, не сломали ли вы что-нибудь. Если у вас эталонные скриншоты делаются на Linux-машине, а у вас Mac, то будут ложные результаты.
Поэтому я и говорю, что не тестируйте скриншотами вообще — забудьте это.
Кстати, если вы все-таки хотите тестировать скриншотами, есть замечательная статья Романа Дворнова «Unit-тестирование скриншотами: преодолеваем звуковой барьер». Это прямо детективное чтиво.
Блокировки
Многие крупные контент-провайдеры не любят, когда вы делаете scraping или получаете их контент нелегальным способом. Представим, что я крупный контент-провайдер, и хочу сыграть с вами в одну игру. Есть два GET-запроса в двух разных браузерах. 
Сможете ли вы угадать, где здесь Chrome? Вариант «оба» не принимается — Chrome тут только один. Скорее всего, вы не сможете ответить на этот вопрос, а я, как крупный контент-провайдер, могу: справа — PhantomJS, а слева — Chrome. 
Я могу дойти до такой степени, что буду обнаруживать ваши браузеры (что это именно — Chrome или FireFox) путем сопоставления порядка HTTP заголовков в ваших запросах. Если хост идет первым — я четко знаю — это Chrome. Дальше могу не сравнивать. Да, конечно, есть более сложные алгоритмы — мы проверяем не только порядок, но еще и значения, и т.д. и т.п. Но важен факт, что я могу слепками сравнивать ваши заголовки, проверять, кто вы есть, а потом просто блокировать вас или не блокировать.
Невозможно реализовать некоторые функции (Flash)
Вы когда-нибудь изучали углубленно, прямо хардкорно, Flash в браузерах? Как-то я заглянул — потом полгода не спал.
Все мы помним, как мы раньше смотрели YouTube, когда еще был Flash: ролик крутится, все хорошо. Но в тот момент, когда создается встраиваемый объект на странице типа Flash, он всегда запрашивает реальное окно у вашей ОС. То есть помимо окна вашего браузера, внутри YouTube-окошка Flash было еще одно окно вашей ОС. Flash не может работать, если вы не дадите ему реальное окно — причем не просто реальное окно, а окно, которое видно у вас на экране. Поэтому некоторые функции в безголовых браузерах реализовать невозможно, в том числе, Flash.
Полная автоматизация и боты
Как я уже сказал ранее, крупные контент-провайдеры очень боятся, когда вы пишите пауков или граббинги, которые просто крадут информацию, которая предоставляется платно.
В ход идут разные ухищрения. Есть статьи о том, как все-таки обнаруживать headless-браузеры. Могу сказать, что вы никак не сможете обнаружить headless-браузеры. Все методы, которые там описаны, обходятся. Например, там были способы обнаружения при помощи Canvas. Помню, даже был один скрипт, который смотрел, как движется мышка по экрану, и заполнял Canvas. Мы же люди и двигаем мышку довольно медленно, а Headless Chrome гораздо шустрее. Скрипт понимал, что слишком быстро заполняется Canvas — значит, это, скорее всего, безголовый Chrome. Мы это тоже обошли, просто замедлив браузер — не проблема.
Нет стандартного (единого) API
Если вы смотрели headless-реализации в других браузерах — будь это Safari или FireFox — там это все реализовано при помощи webdriver API. В Chrome есть Chrome DevTools protocol. В Edge вообще ничего не понятно — что там есть, чего нет.
WebGL?
Люди тоже просят WebGL в headless-режиме. По этой ссылке вы можете попасть на багтрекер Google Chrome. Там разработчики активно голосуют за реализацию headless-режима для WebGL, и уже он может что-то рисовать. Их сейчас просто сдерживает аппаратный рендеринг. Как только закончат реализацию аппаратного рендеринга, то и WebGL автоматически будет доступен, то есть что-то можно будет делать в фоне.
Но не все так плохо!
У нас появляется второй игрок на рынке — 11 мая 2018 была новость, что Microsoft в своем браузере Edge решил реализовать почти тот же самый протокол, который используется в Google Chrome. Они специально создали консорциум, где обсуждают протокол, который хотят довести до промышленного стандарта, чтобы вы могли взять свой скрипт и запустить его и под Edge, и под Chrome, и под FireFox.
Но есть одно «но» — у Microsoft Edge нет headless-режима, к сожалению. У них есть голосовалка, где люди пишут: «Дайте нам headless-режим!» — но они молчат. Наверное, что-то пилят втайне.
TODO (заключение)
Я рассказал это все для того, чтобы вы могли прийти к вашему менеджеру, или, если вы менеджер, к разработчику, и сказать: «Все! Мы не хотим больше Selenium — давайте нам Puppeteer! Будем в нем тестировать». Если это случится, я буду рад.
Но если вы сможете изучать, как и я, браузеры, используя Puppeteer, активно постить баги, или отправлять pull request, то я буду рад еще больше. Этот инструмент в OpenSource лежит на GitHub, написан на Node.js — вы можете просто в него брать и контрибьютить.
Случай с Puppeteer уникален тем, что в Google работает две команды: одна занимается именно Puppeteer, вторая — именно headless-режимом. Если пользователь находит баг, пишет о нем наа GitHub, то, если этот баг не в Puppeteer, а в Headless Chrome, баг переходит в команду Headless Chrome. Если они его там фиксят, то Puppeteer очень быстро обновляется. За счет этого получается единая экосистема, когда сообщество помогает улучшать браузер.
Поэтому я призываю вас помогать улучшать инструмент, который используете не только вы, но и другие разработчики и тестировщики.
Frontend Conf Moscow — специализированная конференция фронтенд-разработчиков состоится 4 и 5 октября в Москве, в Инфопространстве. Список принятых докладов уже опубликован на сайте конференции.
В нашей рассылке мы регулярно делаем тематические обзоры выступлений, рассказываем о вышедших расшифровках и будущих мероприятиях — подписывайтесь, чтобы получать новости первым.
А это ссылка на наш Youtube-канал по фронтенду, там собраны все выступления, относящиеся к разработке клиентской части проектов.



