30.12. Java – Класс HashSet
Класс HashSet в Java расширяет AbstractSet и реализует интерфейс Set. Он создает коллекцию, которая использует хеш-таблицу для хранения.
Хэш-таблица хранит информацию с помощью механизма, называемого хешированием. В хэшировании информационный контент ключа используется для определения уникального значения, называемого его хэш-кодом.
Хэш-код затем используется как индекс, в котором хранятся данные, связанные с ключом. Преобразование ключа в его хэш-код выполняется автоматически.
Содержание
Конструкторы
Ниже приведен список конструкторов, предоставляемых классом HashSet.
| № | Конструктор и описание |
| 1 | HashSet( ) Этот конструктор создает стандартный HashSet. |
| 2 | HashSet(Collection c) Этот конструктор инициализирует хэш-набор, используя элементы коллекции c. |
| 3 | HashSet(int capacity) Этот конструктор инициализирует емкость хэш-набора для заданной целочисленной емкости. Емкость растет автоматически по мере добавления элементов в HashSet. |
| 4 | HashSet(int capacity, float fillRatio) Этот конструктор инициализирует как емкость, так и коэффициент заполнения (также называемый нагрузочной способностью) хэш-набора из его аргументов. При этом отношение заполнения должно находиться в диапазоне от 0,0 до 1,0, и это определяет, как полный набор хэша, прежде чем его размер будет увеличен. В частности, когда количество элементов больше, чем емкость хеш-множества, умноженная на его коэффициент заполнения, хэш-набор расширяется. |
Методы
Помимо методов, унаследованных от его родительских классов, HashSet определяет следующие методы:
| № | и описание |
| 1 | boolean add(Object o) Добавляет указанный элемент к этому набору, если он еще не присутствует. |
| 2 | void clear() Удаляет все элементы из этого набора. |
| 3 | Object clone() Возвращает мелкую копию этого экземпляра HashSet: сами элементы не клонируются. |
| 4 | boolean contains(Object o) Возвращает true, если этот набор содержит указанный элемент. |
| 5 | boolean isEmpty() Возвращает true, если этот набор не содержит элементов. |
| 6 | Iterator iterator() Возвращает итератор по элементам этого набора. |
| 7 | boolean remove(Object o) Удаляет указанный элемент из этого набора, если он присутствует. |
| 8 | int size() Возвращает количество элементов в этом наборе (его количество элементов). |
Пример
Следующая программа демонстрирует работу нескольких методов, поддерживаемых HashSet в Java:
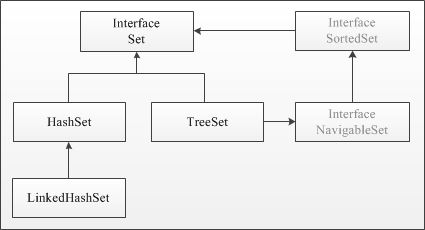
Набор данных интерфейса Set
Реализация интерфейса Set представляет собой неупорядоченную коллекцию, которая не может содержать дублирующие данные.
Интерфейс Set включает следующие методы :
| Метод | Описание |
|---|---|
| add(Object o) | Добавление элемента в коллекцию, если он отсутствует. Возвращает true, если элемент добавлен. |
| addAll(Collection c) | Добавление элементов коллекции, если они отсутствуют. |
| clear() | Очистка коллекции. |
| contains(Object o) | Проверка присутствия элемента в наборе. Возвращает true, если элемент найден. |
| containsAll(Collection c) | Проверка присутсвия коллекции в наборе. Возвращает true, если все элементы содержатся в наборе. |
| equals(Object o) | Проверка на равенство. |
| hashCode() | Получение hashCode набора. |
| isEmpty() | Проверка наличия элементов. Возвращает true если в коллекции нет ни одного элемента. |
| iterator() | Функция получения итератора коллекции. |
| remove(Object o) | Удаление элемента из набора. |
| removeAll(Collection c) | Удаление из набора всех элементов переданной коллекции. |
| retainAll(Collection c) | Удаление элементов, не принадлежащих переданной коллекции. |
| size() | Количество элементов коллекции |
| toArray() | Преобразование набора в массив элементов. |
| toArray(T[] a) | Преобразование набора в массив элементов. В отличии от предыдущего метода, который возвращает массив объектов типа Object, данный метод возвращает массив объектов типа, переданного в параметре. |
К семейству интерфейса Set относятся HashSet, TreeSet и LinkedHashSet. В множествах Set разные реализации используют разный порядок хранения элементов. В HashSet порядок элементов оптимизирован для быстрого поиска. В контейнере TreeSet объекты хранятся отсортированными по возрастанию. LinkedHashSet хранит элементы в порядке добавления.
Набор данных HashSet
Конструкторы HashSet :
Методы HashSet
HashSet содержит методы аналогично ArrayList. Исключением является метод add(Object o), который добавляет объект только в том случае, если он отсутствует. Если объект добавлен, то метод add возвращает значение — true, в противном случае false.
Пример использования HashSet :
В консоли мы должны увидеть только 4 записи. Следует отметить, что порядок добавления записей в набор будет непредсказуемым. HashSet использует хэширование для ускорения выборки.
Следует отметить, что реализация HashSet не синхронизируется. Если многократные потоки получают доступ к набору хеша одновременно, а один или несколько потоков должны изменять набор, то он должен быть синхронизирован внешне. Это лучше всего выполнить во время создания, чтобы предотвратить случайный несинхронизируемый доступ к набору :
Набор данных LinkedHashSet
Класс LinkedHashSet наследует HashSet, не добавляя никаких новых методов, и поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор.
Также, как и HashSet, LinkedHashSet не синхронизируется. Поэтому при использовании данной реализации в приложении с множеством потоков, часть из которых может вносить изменения в набор, следует на этапе создания выполнить синхронизацию :
Набор данных TreeSet
Класс TreeSet создаёт коллекцию, которая для хранения элементов использует дерево. Объекты хранятся в отсортированном порядке по возрастанию.
Конструкторы TreeSet :
Методы TreeSet
В следующем измененном примере с использования TreeSet в консоль будут выведены значения в упорядоченном виде.
HashSet в Java
Вступление:
HashSet в Java реализует интерфейс Set, т.е. не допускает дублирования. Он внутренне поддерживается HashMap, который работает по принципу хеширования.
Java HashSet не синхронизирован. Кроме того, нет гарантии сохранения порядка вставки элементов.
Создание HashSet :
Мы можем создать Java HashSet, используя один из следующих конструкторов:
Каждый из этих конструкторов довольно интуитивно понятен.
Давайте быстро создадим HashSet, используя конструктор по умолчанию:
Обычно используемые методы:
Давайте теперь посмотрим на некоторые методы, которые могут помочь нам манипулировать с помощью Java HashSet:
1. логическое сложение (E e):
Он просто добавляет элемент к данному набору, если его еще нет. Если элемент уже присутствует, add () просто возвращает false:
2. логическое значение содержит (Object obj):
Метод contains () возвращает true, если элемент существует в указанном наборе, в противном случае — false :
3. логическое удаление (Object obj):
4. логическое значение isEmpty ():
Возвращает true для пустого набора, иначе false :
5. int size ():
Он просто возвращает количество элементов, присутствующих в данном наборе.
6. void clear ():
Метод clear () удаляет все значения, присутствующие в указанном наборе, что делает его пустым.
Внутренняя реализация:
который является фиктивным объектом.
Итерация по HashSet :
Мы можем использовать один из следующих способов для перебора элементов в HashSet :
1. forEach () :
Начиная с Java 8, мы можем использовать forEach () для перебора любой коллекции Java :
2. forEachRemaining ():
Java 8 также поддерживает конструкцию forEachRemaining (), которая будет использоваться с любым итератором в коллекции :
3. Итерация с использованием итератора :
В случае, если мы находимся на Java 7 или более ранних версиях, мы можем просто перебрать итератор:
4. Расширен для цикла:
Мы также можем использовать расширенный цикл for для прохождения через элементы:
Вывод:
В этом уроке мы узнали, как создавать и работать с Java HashSet. Мы также знаем, что Java HashSet внутренне использует HashMap для своей реализации.
Оставьте первый комментарий.
Мнения, высказанные участниками Java Code Geeks, являются их собственными.
Готовимся к собеседованию: что нужно знать о коллекциях в Java
Освежаем знания о коллекциях в Java и закрепляем их на практике.

Коллекции в Java — одна из любимых тем на собеседованиях Java-разработчиков любого уровня. Без них не обходятся и экзамены на сертификат Java Professional.
Вспомним основные типы коллекций, их реализации в Java, проверим понимание на практике.
Что такое коллекции
Коллекции — это наборы однородных элементов. Например, страницы в книге, яблоки в корзине или люди в очереди.
Инструменты для работы с такими структурами в Java содержатся в Java Collections Framework. Фреймворк состоит из интерфейсов, их реализаций и утилитарных классов для работы со списками: сортировки, поиска, преобразования.

Фулстек-разработчик. Любимый стек: Java + Angular, но в хорошей компании готова писать хоть на языке Ада.
Галопом по Европам, или Кратко об интерфейсах
Set — это неупорядоченное множество уникальных элементов.
Например, мешочек с бочонками для игры в лото: каждый номер от 1 до 90 встречается в нём ровно один раз, и заранее неизвестно, в каком порядке бочонки вынут при игре.
List — упорядоченный список, в котором у каждого элемента есть индекс. Дубликаты значений допускаются.
Например, последовательность букв в слове: буквы могут повторяться, при этом их порядок важен.
Queue — очередь. В таком списке элементы можно добавлять только в хвост, а удалять — только из начала. Так реализуется концепция FIFO ( first in, first out) — «первым пришёл — первым ушёл». Вам обязательно напомнят это правило, если попробуете пролезть без очереди в магазине:

А ещё есть LIFO (last in, first out), то есть «последним пришёл — первым ушёл». Пример — стопка рекламных буклетов на ресепшене отеля: первыми забирают самые верхние (положенные последними). Структуру, которая реализует эту концепцию, называют стеком.
Deque может выступать и как очередь, и как стек. Это значит, что элементы можно добавлять как в её начало, так и в конец. То же относится к удалению.
Будет здорово, если на собеседовании вы назовёте Deque правильно: «дэк», а не «д экью», как часто говорят.
Map состоит из пар «ключ-значение». Ключи уникальны, а значения могут повторяться. Порядок элементов не гарантирован. Map позволяет искать объекты (значения) по ключу.
Пример: стопка карточек с иностранными словами и их значениями. Для каждого слова (ключ) на обороте карточки есть вариант перевода (значение), а вытаскивать карточки можно в любом порядке.
Не путайте интерфейс Collection и фреймворк Collections. Map не наследуется от интерфейса Collection, но входит в состав фреймворка Collections.
Соберём всё вместе
| Set | List | Queue | Map | |
|---|---|---|---|---|
| Возможны дубликаты | ❌ | ✅ | ✅ | ✅ для значений |
❌ для ключей
Такие разные реализации
Реализаций интерфейсов так много, что при желании можно организовать вполне себе упорядоченный Map и даже отсортированное множество. Пройдёмся кратко по основным классам.
Реализации List
Класс ArrayList подойдёт в большинстве случаев, если вы уже определились, что вам нужен именно список (а не Map, например).
Строится на базе обычного массива. Если при создании не указать размерность, то под значения выделяется 10 ячеек. При попытке добавить элемент, для которого места уже нет, массив автоматически расширяется — программисту об этом специально заботиться не нужно.
Список проиндексирован. При включении нового элемента в его середину все элементы с б ольшим индексом сдвигаются вправо:
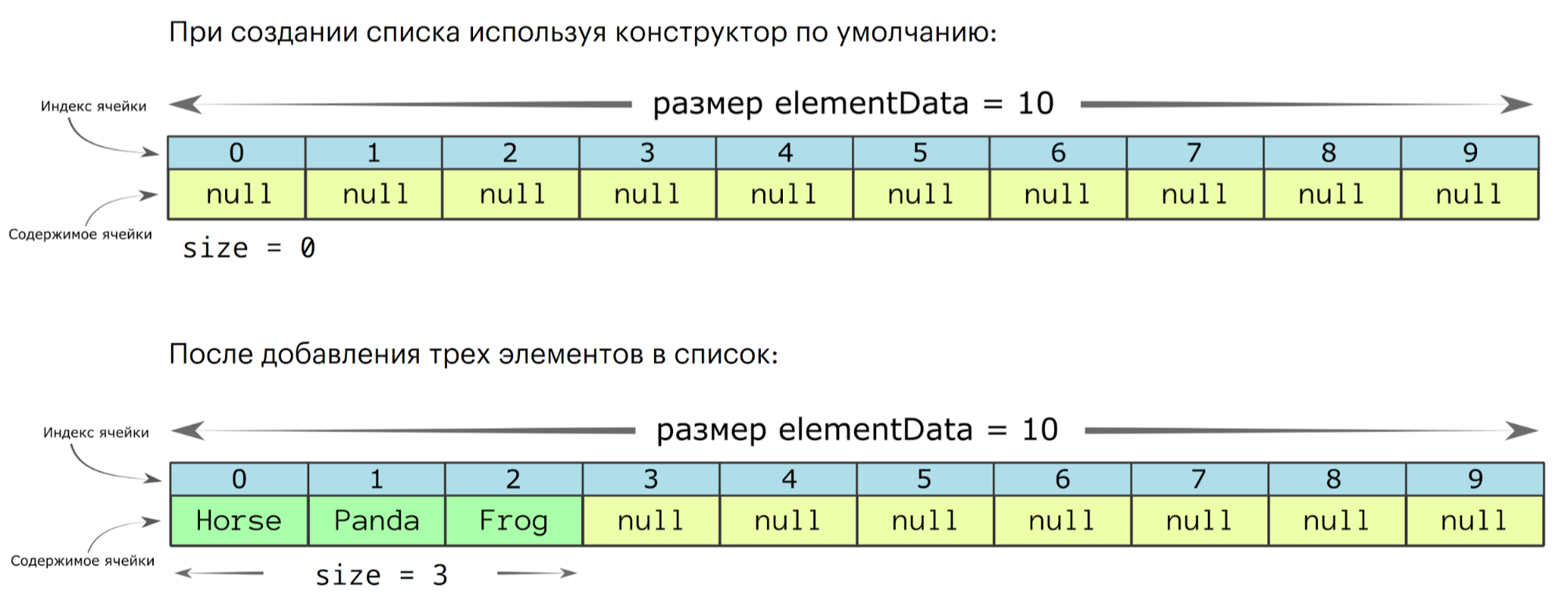
При удалении элемента все остальные с бо́льшим индексом сдвигаются влево:
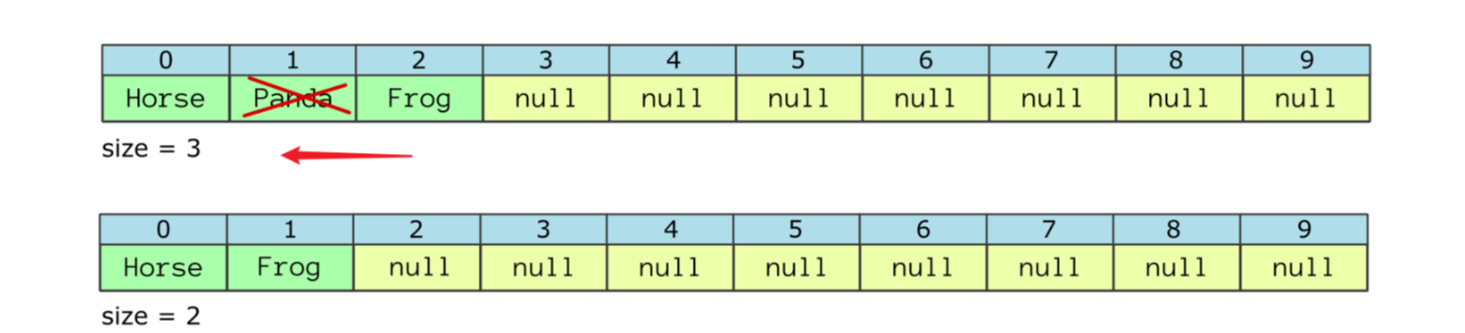
Класс LinkedList реализует одновременно List и Deque. Это список, в котором у каждого элемента есть ссылка на предыдущий и следующий элементы:
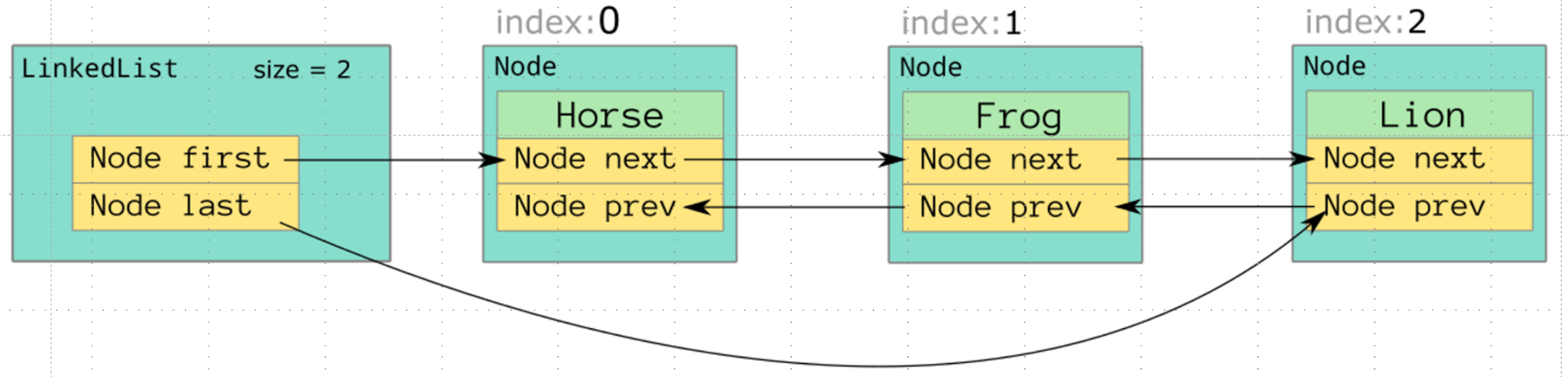
Благодаря этому добавление и удаление элементов выполняется быстро — времязатраты не зависят от размера списка, так как элементы при этих операциях не сдвигаются: просто перестраиваются ссылки.
На собеседованиях часто спрашивают, когда выгоднее использовать LinkedList, а когда — ArrayList.
Правильный ответ таков: если добавлять и удалять элементы с произвольными индексами в списке нужно чаще, чем итерироваться по нему, то лучше LinkedList. В остальных случаях — ArrayList.
В целом так и есть, но вы можете блеснуть эрудицией — рассказать, что под капотом. При добавлении элементов в ArrayList (или их удалении) вызывается нативный метод System.arraycopy. В нём используются ассемблерные инструкции для копирования блоков памяти. Так что даже для больших массивов эти операции выполняются за приемлемое время.
Реализации Queue
Про одну из них, LinkedList, мы рассказали выше.
Класс ArrayDeque — это реализация двунаправленной очереди в виде массива с переменным числом элементов.
Новые значения можно добавлять в начало или конец списка, и удалять оттуда же. Причём эти операции выполняются быстрее, чем при использовании LinkedList.
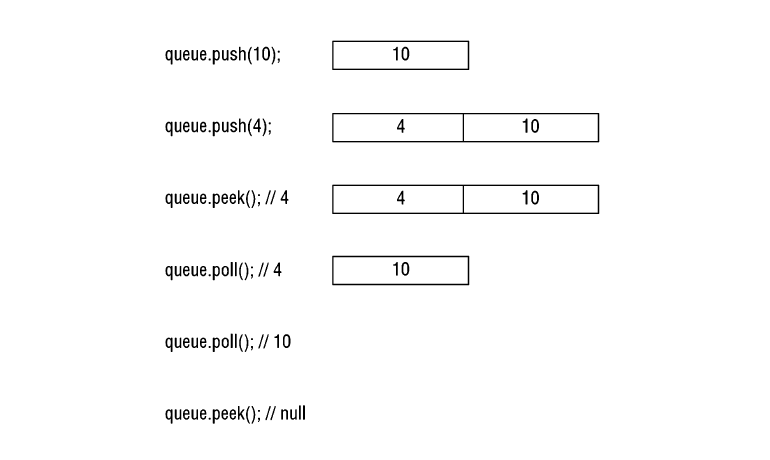
Класс PriorityQueue — упорядоченная очередь. По умолчанию элементы добавляются в естественном порядке: числа по возрастанию, строки по алфавиту и так далее, либо алгоритм сравнения задаёт разработчик.
Этот класс может быть полезен, например, для нахождения n минимальных чисел в большом неупорядоченном списке:
Такая реализация выгоднее по скорости и объёму памяти, чем подход с сортировкой первоначального списка.
Реализации Set
Класс HashSet использует для хранения данных в хеш-таблице. Это значит, что при манипуляциях с элементами используется хеш-функция — hashCode() в Java.
Хеш-таблица — структура данных, в которой все элементы помещаются в бакеты (buckets), соответствующие результату вычисления хеш-функции.
Например, администратор в гостинице может класть ключ в коробку с номером от 1 до 9, вычисляя его по такому алгоритму: складывать все цифры номера, пока не получится одноразрядное число.
Здесь алгоритм вычисления — хеш-функция, а результат вычисления — хеш-код.
Тогда ключ от номера 356 попадёт в коробку 5 (3 + 5 + 6 = 14; 1 + 4 = 5), а ключ от номера 123 — в коробку с номером 6.
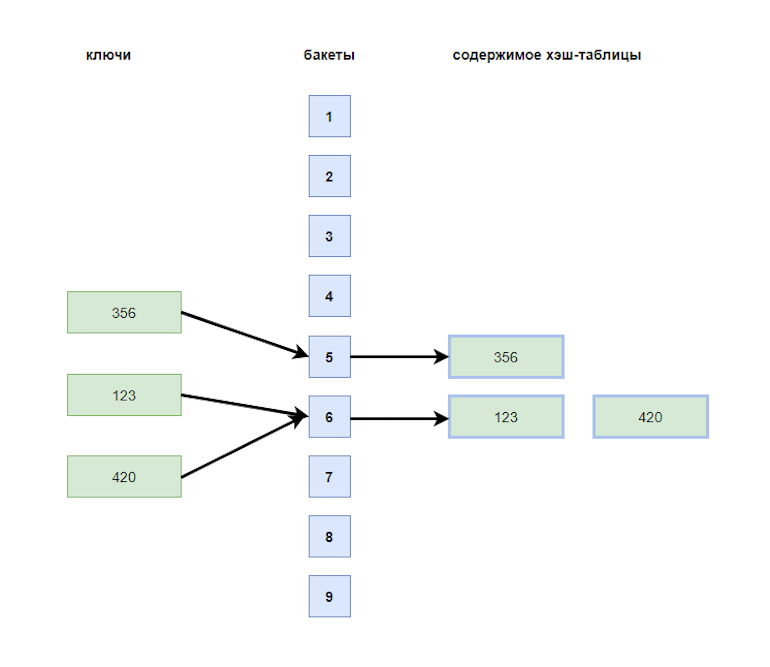
Добавление, поиск и удаление элементов при такой организации происходит за постоянное время, независимо от числа элементов в коллекции.
О классе TreeSet вспоминают в тех случаях, когда множество должно быть упорядочено. Каким образом упорядочивать — определяет разработчик при создании нового TreeSet. По умолчанию элементы располагаются в естественном порядке. Организованы они в виде красно-чёрного дерева.
Реализации Map
Класс HashMap хранит данные в виде хеш-таблицы, как и HashSet. Более того, HashSet внутри использует HashMap. При этом ключом выступает сам элемент.
Класс TreeMap строится тоже на базе красно-чёрного дерева. Элементы здесь упорядочены (в естественном или заданном при создании порядке) в каждый момент времени. При этом вставка и удаление более затратны, чем в случае с HashMap.
Класс LinkedHashMap расширяет возможности HashMap тем, что позволяет итерироваться по элементам в порядке их добавления. Как и в LinkedList, здесь каждая пара-значение содержит ссылку на предыдущий и последующий элементы.
Ещё один хитрый вопрос на собеседовании: в каких коллекциях допускаются null-элементы?
Ответ: почти во всех, но нельзя добавлять null-значения в упорядоченные структуры, которые при добавлении нового элемента используют сравнение.
Обоснование: мух советуют отделять от котлет — иными словами, нельзя сравнивать принципиально разные, несопоставимые вещи. Так же и в Java невозможно понять, что больше: null или число 1, или null или строка «hello».
Поэтому null-значения запрещены в TreeMap и TreeSet.
Ещё они недопустимы в ArrayDeque, так как методы этого класса (например, poll() — удаление элемента из начала очереди) используют null как признак пустоты коллекции.
Попрактикуемся
Чтобы убедиться, что вы не просто вызубрили теорию, а хорошо понимаете предмет, на собеседовании вам могут предложить задания вроде «что произойдёт при выполнении кода»
Разберём типовые задачи на понимание коллекций.
Задачи для ArrayList
Что будет напечатано после выполнения кода ниже:
Правильный ответ: test2:test4:test1:test4:test2:test3:
Элементы в ArrayList нумеруются начиная с нуля. Поэтому элемент с номером 1 — это test2.
Следующим действием мы добавляем строку «test4» в ячейку с индексом 1. При этом элементы с бо́льшим индексом сдвигаются вправо.
Вторая часть вывода ( test4) показывает, что теперь по индексу 1 извлекается именно test4.
Далее мы обходим все элементы списка и убеждаемся, что они выводятся именно в порядке добавления.
Что будет выведено при выполнении кода:
Правильный ответ: 2:2
Первая часть понятна: добавили два элемента, поэтому размер списка равен двум. Остаётся вопрос: почему не был удалён «test1»?
Перед удалением элемента его нужно найти в списке. ArrayList и остальные коллекции, которые не используют алгоритмы хеширования, применяют для поиска метод equals().
Строки сравниваются по значению, поэтому «test3» не эквивалентно «test1» и «test2». А раз ни один элемент не соответствует критерию поиска, ничего не удалится — размер списка останется прежним.
Проверьте себя: подумайте, что произойдёт, если вместо
Задачи для Set
Что выведет фрагмент кода ниже:
Правильный ответ: 3:, а дальше точно не известно.
Так как строки сравниваются по значению, а дубликаты во множествах недопустимы, второй «Иван» не станет частью множества. В итоге размер множества будет равен 3.
В каком порядке будут выведены элементы множества — определённо мы сказать не можем: во множествах порядок добавления не сохраняется.
Что выведет фрагмент кода:
Правильный ответ: 4.
Как же так, ведь во множество должны попадать уникальные элементы?
Прежде чем добавить новый элемент в множество, вычисляется его hashCode() — чтобы определить бакет, куда он может быть помещён.
Если бакет пуст, элемент будет добавлен. Иначе уже добавленные элементы с таким же значением хеша сравниваются с кандидатом при помощи метода equals(). Если дубликат не найден, новый элемент становится частью множества. Он попадёт в тот же бакет.
Мы добавляем в Set объекты типа Person — созданного нами класса. Этот класс, как и все ссылочные типы, наследуется от класса Object.
Так как мы не переопределили метод hashCode(), будет использована родительская реализация. В ней хеш вычисляется на основе данных адреса (реализация зависит от JVM).
Метод equals() тоже не переопределён. В классе-родителе этот метод просто сравнивает ссылки на объекты. Это значит, что даже если хеш случайно совпадёт для каких-то из четырёх элементов, equals() в любом случае вернёт false.
Таким образом, каждый из четырёх кандидатов попадёт в множество.
Проверьте себя: изменится ли что-нибудь, если переопределить hashCode() вот так:
А если ещё и equals() переопределить, как на фрагменте ниже:
Реализации интерфейса Set, Queue
— Ну как твой процессор?
— Норм. Посидел час в жидком азоте и как новенький!
— Отлично. Тогда давай продолжим.
Коллекции Set.
Set переводится как множество. А множество, с математической точки зрения, — это набор уникальных элементов. Но т.к. не все программисты – математики, то обычно говорят, что Set – это коллекция уникальных элементов, или коллекция, которая не позволяет хранить одинаковые элементы.
Не знаю, давала Элли тебе иерархию наследования для Set, но если нет, то вот она:

HashSet – это коллекция, которая для хранения элементов внутри использует их хэш-значения, которые возвращает метод hashCode().
— Использование hash-кодов позволяет довольно быстро искать, добавлять и удалять элементы из множества (Set).
Но учти, чтобы объекты твоих классов можно было класть в Set и правильно находить их там, у твоего класса должны быть правильно реализованы методы hashCode & equals.
И тот и другой активно используются внутри HashSet/HashMap.
Если ты забудешь реализовать метод hashCode(), то рискуешь, что твой объект в коллекции Set не будет найден, даже если он там есть.
— Да, помню, я помню. Ты мне уже рассказывал раньше об этом. Все робоуши прожужжал.
— Ок. Тогда вот тебе еще полезная информация.
Допустим, ты правильно реализовал hashCode и equals в своем классе и такой весь радостный хранишь объекты в Set’е.
Но потом ты взял и поменял один из объектов, при этом поменялись его внутренние данные, которые используются в вычислении хэша. И хэш объекта стал другим.
А это значит, что когда ты будешь его искать в Set’е, его скорее всего не найдут.
— Ничего себе! Это как же?
— Это всем известный косяк с работой хешей. Грубо говоря, поиск в HashSet (и в HashMap) гарантированно работает правильно, только если объекты – immutable.
— Ничего себе! И что, никто ничего не делает?
— Все делают вид, что проблемы не существует. Но на собеседованиях это частенько спрашивают, так что возможно, тебе стоит запомнить этот факт…
LinkedHashSet – это HashSet, в котором элементы хранятся еще и в связном списке. Обычный HashSet не поддерживает порядок элементов. Во-первых, официально его просто нет, во-вторых, даже внутренний порядок может сильно поменяться при добавлении всего одного элемента.
А у LinkedHashSet можно получить итератор и с его помощью обойти все элементы именно в том порядке, в котором они добавлялись в LinkedHashSet. Не часто, но иногда это может очень понадобится.
— Ясно. Люблю, когда у классов есть такие «на всякий случай» разновидности. Обычно такие случаи наступают не так уж и редко.
— TreeSet – это коллекция, которая хранит элементы в виде упорядоченного по значениям дерева. Внутри TreeSet содержится TreeMap который и хранит все эти значения. А этот TreeMap использует красно —черное сбалансированное бинарное дерево для хранения элементов. Поэтому у него очень быстрые операции add, remove, contains.
— Ага. Я помню, мы же совсем недавно это разбирали. А я еще думал – и где это применяется.
А оказывается, одни из самых популярных коллекций в Java используют это.
— Ага. Хотелось бы увидеть лицо спрашивающего в этот момент. Я, пожалуй, даже заучу эту фразу. …
А в принципе, Set оказался не таким уж и простым, как мне казалось в самом начале.
— Зато с Queue ситуация гораздо проще:

Queue – это очередь. Элементы добавляются в конец очереди, а выбираются из ее начала.
PriorityQueue – это фактически единственная классическая реализация интерфейса Queue, не считая LinkedList, который формально тоже является очередью.
Ладно, что-то я устал, на сегодня все. Давай до свидания.



