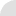Подробная информация о процессоре, о которой мы будем говорить, содержит в себе сведения о количестве ядер, о наличии режима hyper threading, об архитектуре, о размере кэша и т. д. Найти в вашей системе эту информацию, относящуюся к процессору, может быть слегка затруднительным, поскольку ее нужно получать помощью разных команд.
К командам, которые мы будем использовать, относятся команды lscpu, /proc/cpuinfo и lstopo (hwloc). С их помощью можно узнать подробную информацию о ядрах и процессорах. В следующих примерах объясняется, как следует интерпретировать результаты, выдаваемые этими командами.
1. Поставщик и модель процессора
Чтобы определить поставщика и название модели процессора, выполните с помощью команды grep поиск в файле /proc/cpuinfo.
Это процессор фирмы Intel. Затем находим имя модели, которое можно использовать для поиска точных спецификаций на сайте Intel.
Это процессор «Core 2 Quad Q8400».
2. Архитектура
С помощью команды lscpu можно узнать архитектуру процессора.
Архитектура — x86_64, что означает 64 разрядную архитектуру.
3. Частота
Частоту/скорость работы процессора можно узнать с помощью команды lscpu и в файле /proc/cpuinfo.
Поскольку большинство современных процессоров работают на более низких частотах для экономии энергии, частота, о которой сообщается, может быть ниже, чем действительная частота работы указанного процессора. Когда нагрузка увеличивается, они переключаются на более высокую частоту.
Изменение частоты можно обнаружить в файле of /proc/cpuinfo, если использовать для этого команду watch.
Запустите в терминале указанную выше команду и, пока она работает, запустите какую-нибудь задачу, которая интенсивно использует процессор, и частота должна увеличиться.
4. Количество ядер
Каждое ядро процессора является, на самом деле, независимым процессором. Несколько ядер позволяют процессору одновременно выполнять несколько команд в программе, в результате чего скорость обработки данных увеличивается.
Команда lscpu указывает «количество ядер в одном сокете».
Таким образом, в этом случае количество ядер в процессоре равно 4.
В файле /proc/cpuinfo также есть информация о количестве ядер, но ее получить немного сложнее и запутаннее.
Простой подсчет количества процессоров может дать неправильное количество.
В случае, когда используется режим hyper threading, количество процессоров, которые видит операционная система, в два раза превышает количество ядер. Но в файле /proc/cpuinfo есть поле с именем «core id», которое уникально для каждого ядра одного процессора. Подсчет этих имен позволяет получить четкое представление о количестве реальных ядер в процессоре
Несколько процессоров
Редко, но в тех случаях, если вы используете систему, в которой имеется несколько физических процессоров (да, это означает 2 или больше процессоров, установленных на материнской плате), то результаты в файле /proc/cpuinfo будут другими. В случае нескольких процессоров, «physical id» будет означать несколько значений.
Если есть более одного идентификатора физического процессора, то это означает, что в системе есть несколько физических процессоров. И в каждом процессоре вы должны посчитать ядра отдельно.
5. Технология Hyper threading
Hyper threading это технология фирмы Intel, которая позволяет одному ядру выполнять обработку так, как если бы это было два ядра. Это в определенных случаях также некоторым образом увеличивает вычислительную мощность каждого ядра.
Чтобы проверить, поддерживается ли в процессоре режим hyper-threading, необходимо сравнить два значения. Первым является фактическое количество ядер, а вторым — логическое количество.
Если количество ядер равно количеству процессоров, которые видно в ОС, то режим hyper threading отсутствует. В противном случае, т. е. если количество блоков обработки больше (в два раза больше) числа ядер, то режим hyper threading присутствует.
В качестве примера возьмем процессор Core 2 Quad Q8400
Количество процессоров, как показано в /proc/cpuinfo, равно 4
Количество «cpu cores» = 4, также, как и «siblings» = 4, а «core id» = 4
Поэтому общее число процессоров равно количеству фактических ядер. Следовательно на этом процессоре режим hyper threading отсутствует, что и подтверждается спецификациями процессора, приводимыми на сайте Intel.
Процессор с технологией hyper threading
Сведения, касающиеся hyper threading, которые присутствуют в /proc/cpuinfo или в выходных данных lscpu будут отличаться.
Обратите внимание на строку «Thread(s) per core: 2», указывающую, что в каждом ядре есть по 2 потока; ядер, в общей сложности, четыре. Таким образом, количество процессоров, которые видны в ОС, равно 8.
Теперь давайте взглянем на данные из /proc/cpuinfo.
Здесь «cpu cores» = 4 и «siblings» = 8 означают, что имеется 4 ядра и по 2 гиперпотока на ядро. Количество процессоров, как это показано в /proc/cpuinfo, также будет равно 8.
Флаг HTT в выходных данных dmidecode и флаг ht во флагах /proc/cpuinf могут давать неверную информацию, касающуюся режима hyper threading.
Для процессора Core2Quad Q8400 dmidecode и /proc/cpuinfo показывают, что флаг гиперпотоков установлен, несмотря на то, что в данном процессоре режим hyper threading недоступен.
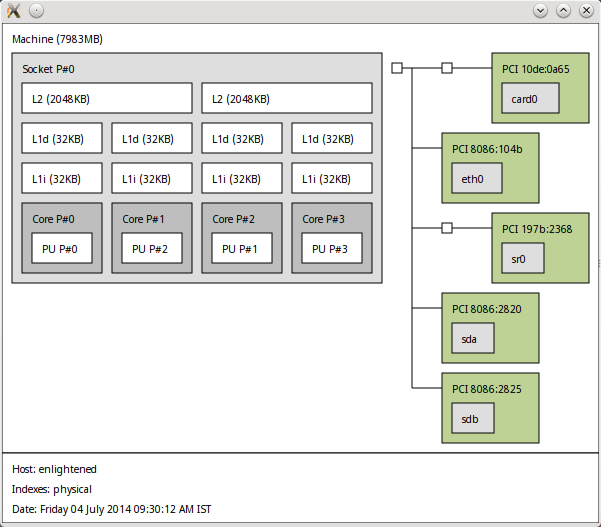
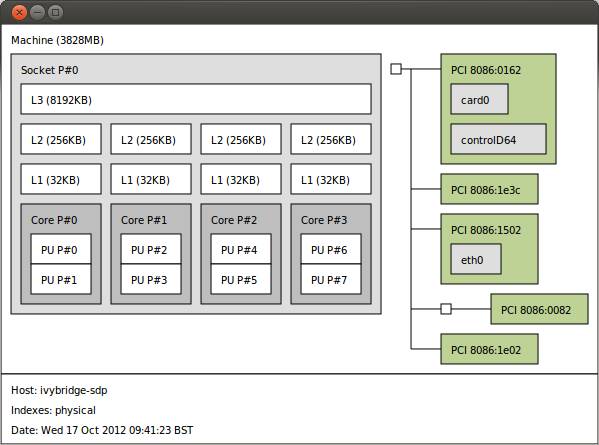
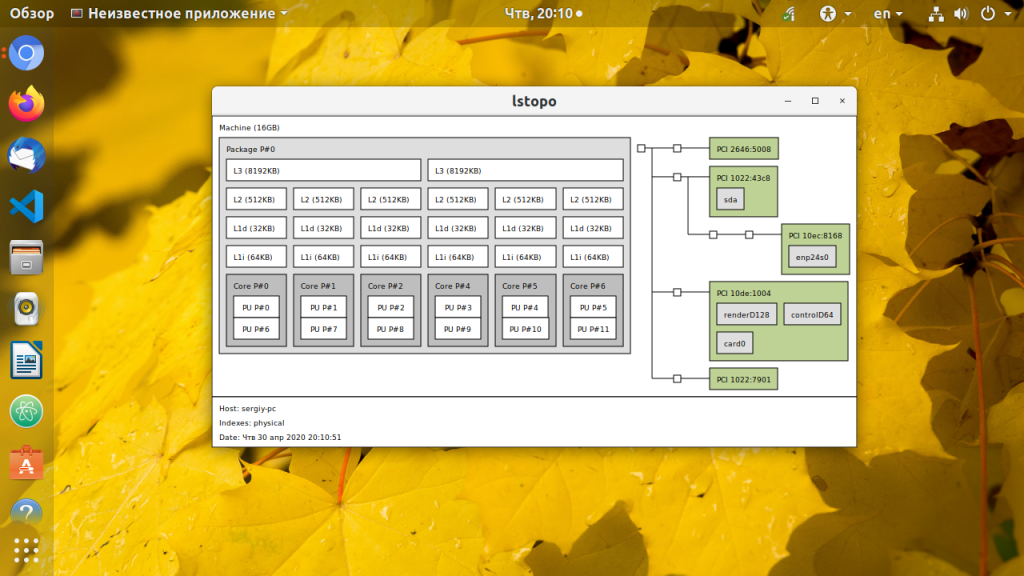
Утилита hwloc / lstopo
Утилита hwloc является небольшой утилитой, которая сообщает о структуре процессора в виде приятной диаграммы. В диаграмме показано количество ядер, наличие режима hyper threading и объем кэш-памяти. Обо всем рассказывает одна схема.
Процессор с технологией hyper threading
Для процессора с режимом hyper threading, выдаваемая диаграмма hwloc может выглядеть следующим образом
Информация о процессоре Linux
В зависимости от ваших потребностей о процессоре можно узнать различную информацию. Вам может понадобится производитель, модель, тактовая частота, количество ядер или потоков, конфигурация кэша, доступные расширения процессора (аппаратная виртуализация, AES, MMX, SSE) и так далее. В Linux существует уйма инструментов как командной строки так и с графическим интерфейсом которые показывают информацию об оборудовании и в том числе процессоре.
В этой статье собраны самые лучшие и удобные инструменты с помощью которых можно посмотреть характеристики процессора Linux. Среди них есть как консольные утилиты, так и графические.
Информация о процессоре Linux
1. /proc/cpuinfo
Здесь вы можете узнать количество ядер и потоков процессора, тактовую частоту, модель, доступные расширения процессора, и еще несколько других вещей.
2. cpufreq-info
Утилита cpufreq-info входит в набор утилит для управления частотой процессора cpufrequtils, и позволяет посмотреть частоту каждого из ядер процессора, максимальную и минимальную частоты на которых может работать процессор, а также политику управления cpufreq. Перед использованием утилиту надо установить:
sudo apt install cpufrequtils
Для просмотра информации о первом ядре используйте:
3. cpuid
Консольная утилита cpuid показывает подробную информацию о процессоре используя набор функций CPUID. Выводится тип и семейство процессора, расширения, конфигурация кэша, TLB и информация про функции управления питанием. Для установки выполните:
sudo apt install cpuid
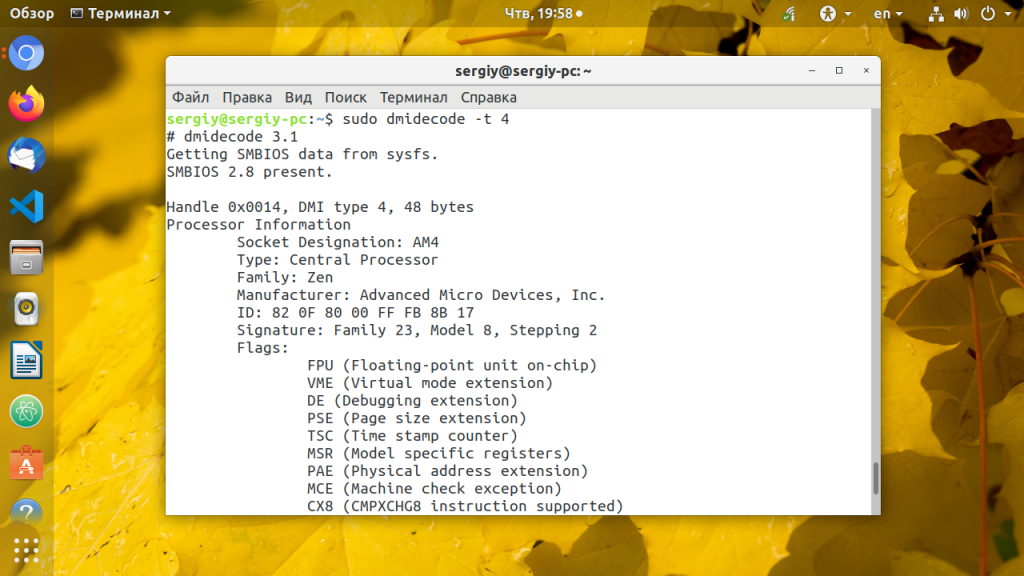
4. dmidecode
Утилита dmidecode собирает подробную информацию об оборудовании системы на основе данных DMI в BIOS. Отображаемая информация включает производителя, версию процессора, доступные расширения, максимальную и минимальную скорость таймера, количество ядер, конфигурацию кэша L1/L2/L3 и т д. Здесь информация о процессоре Linux намного легче читается чем у предыдущей утилиты.
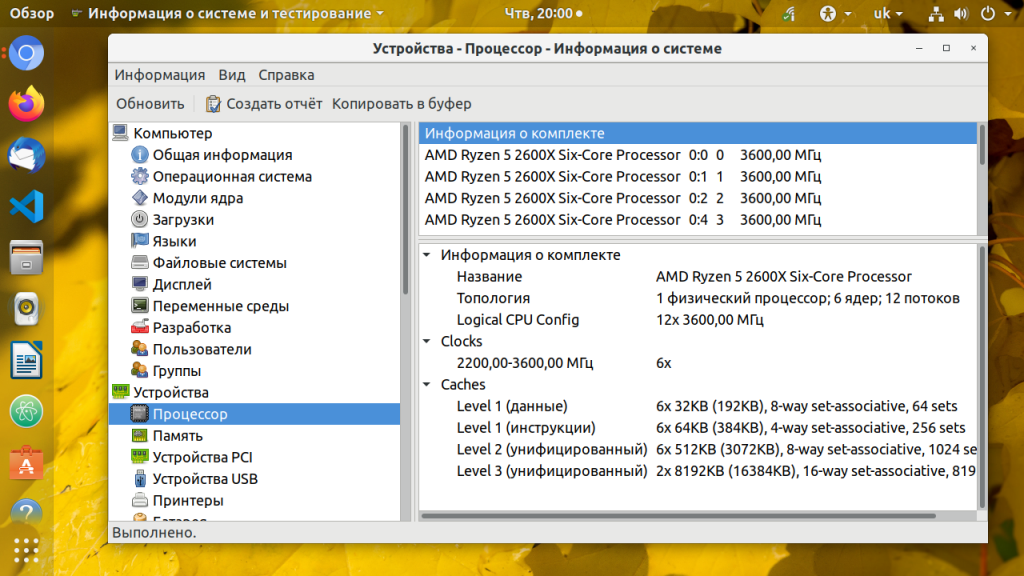
5. hardinfo
Hardinfo это графическая утилита которая позволяет получить информацию о процессоре и другом оборудовании в системе в графическом интерфейсе. Утилиту надо установить:
sudo apt install hardinfo
6. i7z
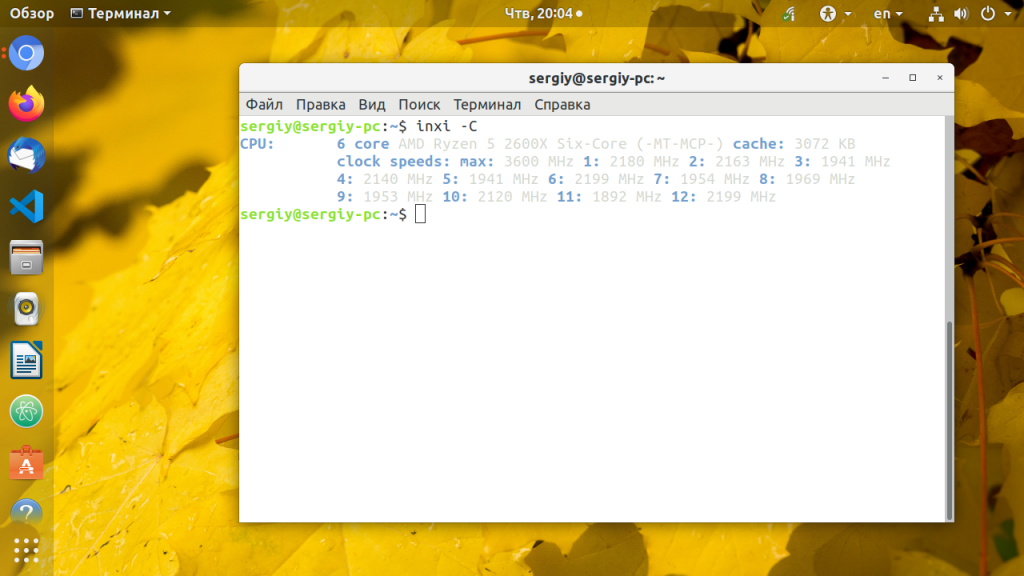
7. inxi
sudo apt install inxi
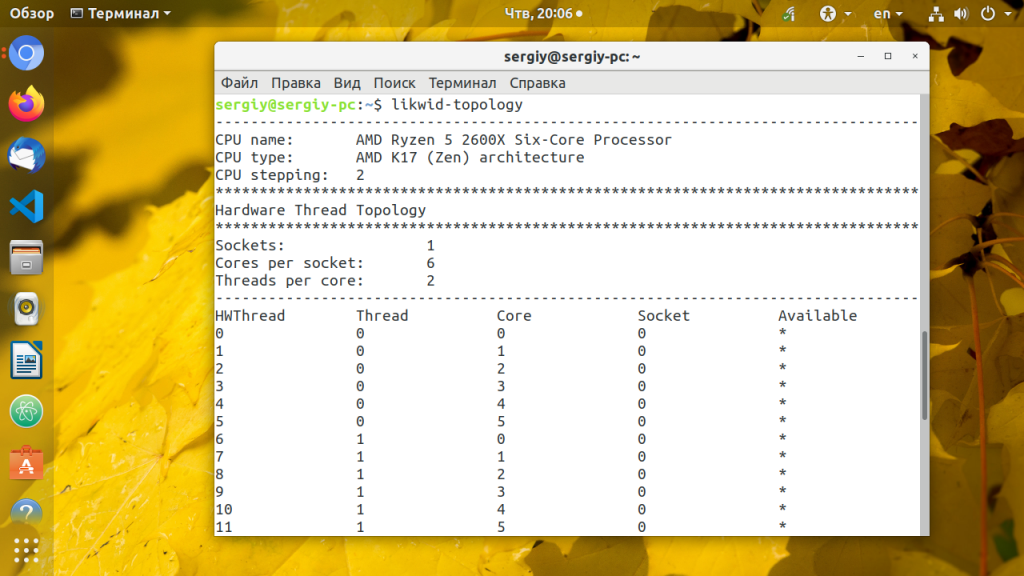
8. likwid-topology
sudo apt install likwid
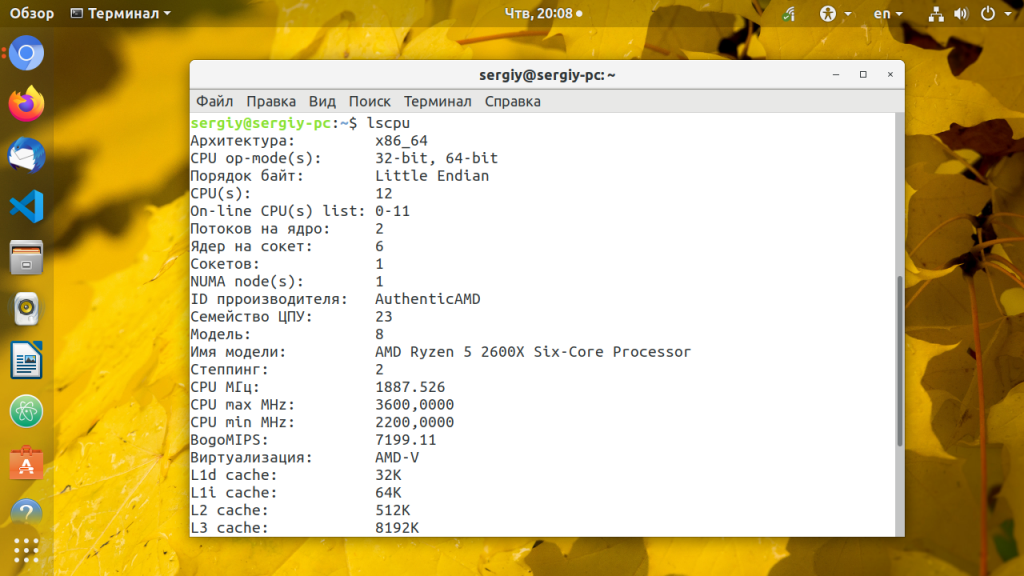
9. lscpu
Команда lscpu отображает содержимое /proc/cpuinfo в более удобном для пользователя виде. Например, архитектуру процессора, количество активных ядер, потоков, сокетов.
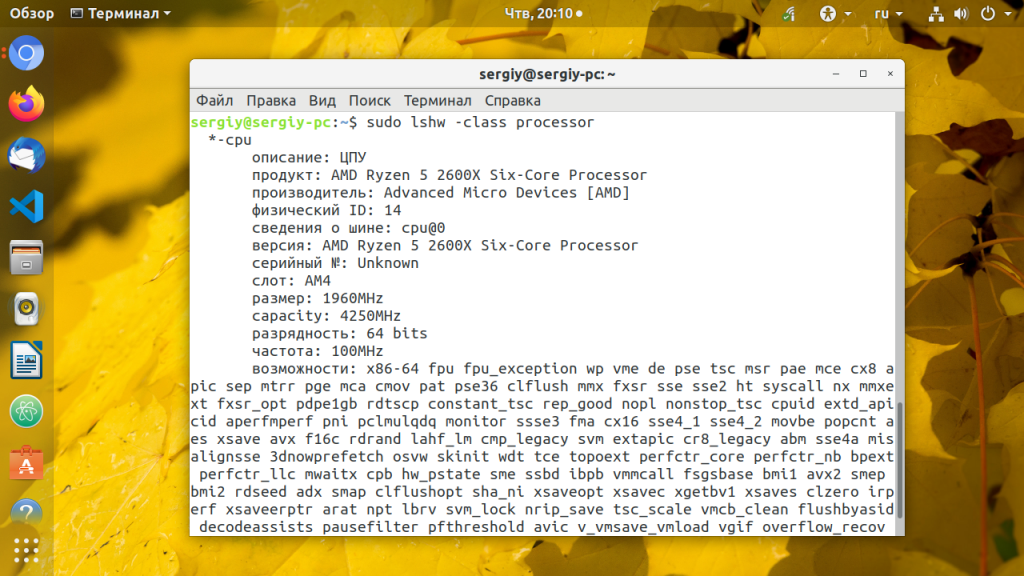
10. lshw
11. lstopo
Утилита lstopo входит в пакет hwloc и визуализирует топологию системы. Сюда входит процессор, память, устройства ввода/вывода. Эта команда полезна для идентификации архитектуры процессора и топологии NUMA. Установка:
sudo apt install hwloc
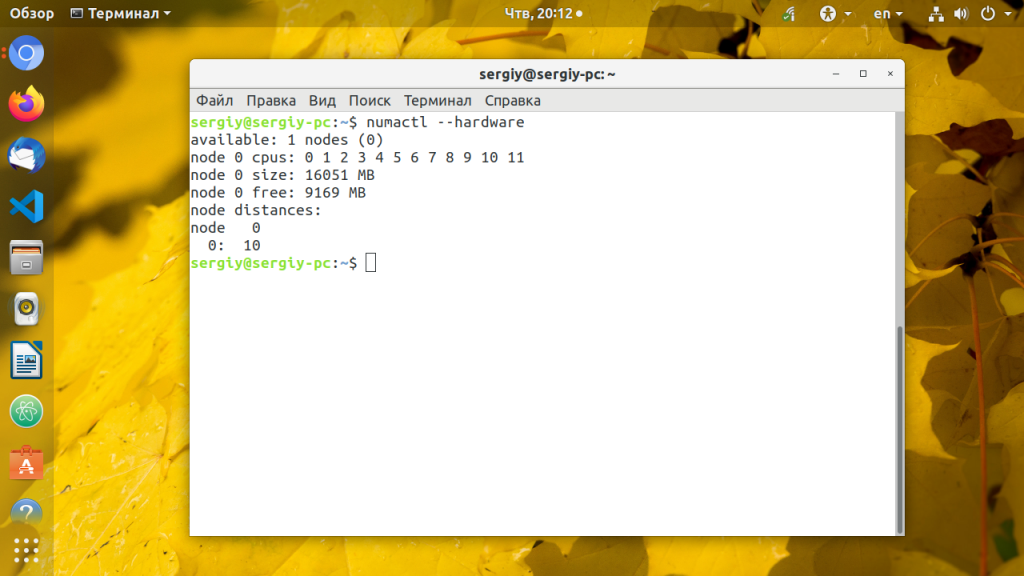
12. numactl
Первоначально разрабатываемая для настройки планировки NUMA и политик управления памятью в Linux numactl также позволяет посмотреть топологию NUMA:
sudo apt install numactl
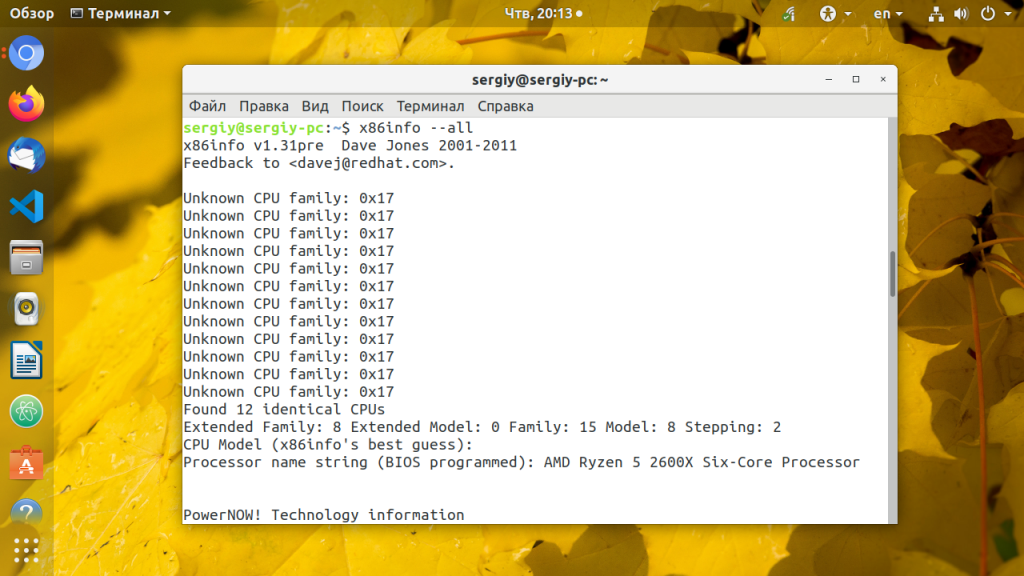
13. x86info
sudo apt install x86info
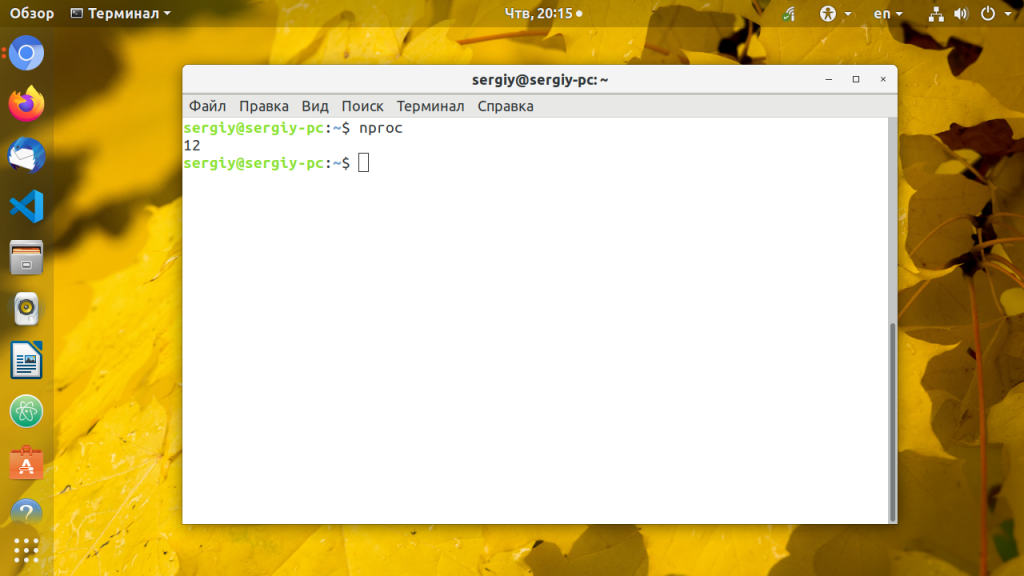
14. nproc
Утилита просто выводит количество доступных вычислительных потоков. Если процессор не поддерживает технологию HyperThreading, то будет выведено количество ядер:
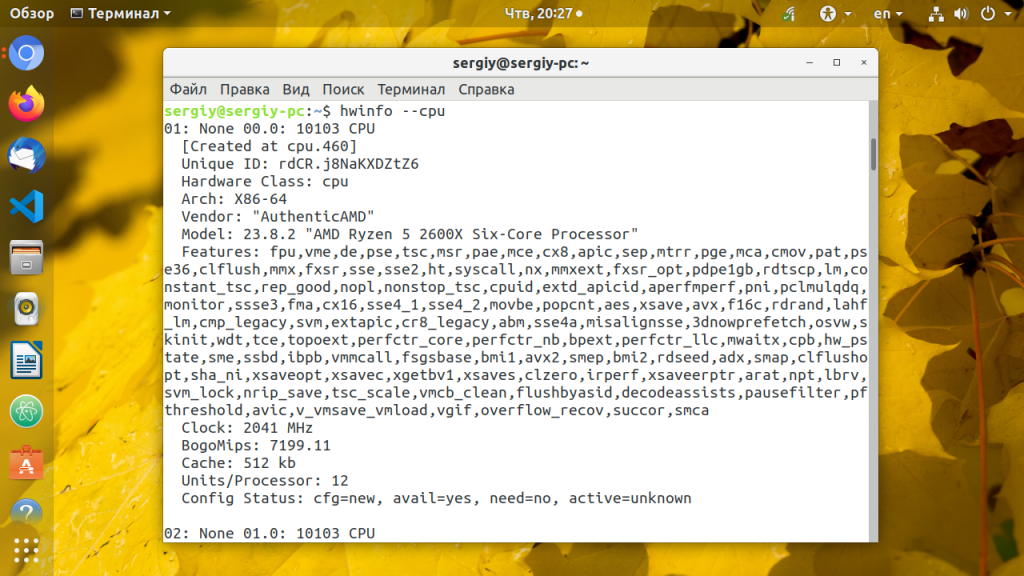
15. hwinfo
Утилита hwinfo позволяет выводить информацию о различном оборудовании, в том числе и о процессоре. Программа отображает модель процессора, текущую частоту, поддерживаемые расширения. Наверное, это самый простой способ узнать частоту процессора Linux:
Выводы
В этой статье мы собрали самые популярные утилиты которые позволяют посмотреть процессор linux. Как видите, их действительно очень много. А какими программами пользуетесь вы? Мне нравится lscpu. Напишите в комментариях!
hwloc comes with an extensive C programming interface and several command line utilities. Each of them is fully documented in its own manual page; the following is a summary of the available command line tools.
lstopo and lstopo-no-graphics
lstopo (also known as hwloc-ls) displays the hierarchical topology map of the current system. The output may be graphical or textual, and can also be exported to numerous file formats such as PDF, PNG, XML, and others. Advanced graphical outputs require the «Cairo» development package (usually cairo-devel or libcairo2-dev ).
lstopo and lstopo-no-graphics accept the same command-line options. However graphical outputs are only available in lstopo. Textual outputs (those that do not depend on heavy external libraries such as Cairo) are supported in both lstopo and lstopo-no-graphics.
This command can also display the processes currently bound to a part of the machine (via the –ps option).
Note that lstopo can read XML files and/or alternate chroot filesystems and display topological maps representing those systems (e.g., use lstopo to output an XML file on one system, and then use lstopo to read in that XML file and display it on a different system).
hwloc-bind
hwloc-bind can also be used to retrieve the current process’ binding.
hwloc-calc
hwloc-calc is generally used to create bitmap strings to pass to hwloc-bind. Although hwloc-bind accepts many forms of object specification (i.e., bitmap strings are one of many forms that hwloc-bind understands), they can be useful, compact representations in shell scripts, for example.
hwloc-calc generates bitmap strings from given hardware objects with the ability to aggregate them, intersect them, and more. hwloc-calc generally uses the same syntax than hwloc-bind, but multiple instances may be composed to generate complex combinations.
Note that hwloc-calc can also generate lists of logical processors or NUMA nodes that are convenient to pass to some external tools such as taskset or numactl.
hwloc-info
hwloc-info dumps information about the given objects. It is intended to be used with tools such as grep for filtering certain attribute lines. When no object is specified, hwloc-info prints a summary of the topology.
hwloc-distrib
hwloc-distrib generates a set of bitmap strings that are uniformly distributed across the machine for the given number of processes. These strings may be used with hwloc-bind to run processes to maximize their memory bandwidth by properly distributing them across the machine.
hwloc-ps
hwloc-ps is a tool to display the bindings of processes that are currently running on the local machine. By default, hwloc-ps only lists processes that are bound; unbound process (and Linux kernel threads) are not displayed.
hwloc-gather-topology
hwloc-gather-topology is a Linux-specific tool that saves the relevant topology files of the current machine into a tarball (and the corresponding lstopo output). These files may be used later (possibly offline) for simulating or debugging a machine without actually running on it.
hwloc-distances
hwloc-distances displays all distance matrices attached to the topology. Note that lstopo may also display distance matrices in its verbose textual output. However lstopo only prints matrices that cover the entire topology while hwloc-distances also displays matrices that ignore part of the topology.
hwloc-annotate
hwloc-annotate may add object attributes such as string information (see Custom string infos for details). It reads an input topology from a XML file and outputs the annotated topology as another XML file.
hwloc-assembler
hwloc-assembler combines several XML topology files into a single multi-node XML topology. It may then be used later as input with hwloc_topology_set_xml() or with the HWLOC_XMLFILE environment variable. See Multi-node Topologies for details.
hwloc-assembler-remote
hwloc-assembler-remote is a frontend to hwloc-assembler. It takes care of contacting the given list of remote hosts (through ssh) and retrieving their topologies as XML before assembling them with hwloc-assembler.
Portable Hardware Locality (hwloc)
About
Presentations
Open MPI Team
FAQ
Videos
Performance
Open MPI Software
Download
Documentation
Source Code Access
Bug Tracking
Regression Testing
Version Information
Sub-Projects
Hardware Locality
Download v2.7 (beta)
Download v2.6 (stable)
Download v2.5 (old)
Download v2.4 (older)
Download v1.11 (ultrastable)
Download ancient
Documentation
Tutorials
Best of lstopo
XML topology database
License
Mailing lists
Bug tracking
Git access
Nightly snapshots
Network Locality
MPI Testing Tool
Open MPI User Docs
Open Tool for Parameter Optimization
Community
Mailing Lists
Getting Help/Support
Contribute
Contact
License
hwloc 2.7.0rc1 Beta release
> Read more
hwloc 2.6.0 Major release
> Read more
Upgrading to v2.0 API Guide for Porting your Code
> Read more
XML topology database Repository of XML topologies
> Read more
The Best of lstopo Best lstopo graphical outputs
> Read more
hwloc primarily aims at helping applications with gathering information about increasingly complex parallel computing platforms so as to exploit them accordingly and efficiently. For instance, two tasks that tightly cooperate should probably be placed onto cores sharing a cache. However, two independent memory-intensive tasks should better be spread out onto different sockets so as to maximize their memory throughput. As described in this paper, OpenMP threads have to be placed according to their affinities and to the hardware characteristics. MPI implementations apply similar techniques while also adapting their communication strategies to the network locality as described in this paper or this one.
hwloc may also help many applications just by providing a portable CPU and memory binding API and a reliable way to find out how many cores and/or hardware threads are available.
Portability and support
hwloc supports the following operating systems:
Additionally hwloc can detect the locality PCI devices as well as OpenCL, CUDA and Xeon Phi accelerators, network and InfiniBand interfaces, etc. See the Best of lstopo for more examples of supported platforms. The topologies of many existing platforms are also available in the XML topology database for testing your software on architectures you don’t have access to.
hwloc may display the topology in multiple convenient formats (see v2.6.0 examples and the Best of lstopo). It also offers a powerful programming interface to gather information about the hardware, bind processes, and much more.
To check whether hwloc works on a particular machine, just try to build it and run lstopo or lstopo-no-graphics. If some things do not look right (e.g. bogus or missing cache information), see Questions and bugs below
Documentation
More details are available in the Documentation (in both PDF and HTML). The documentation for each version contains examples of outputs and an API interface example (these links are for v2.6.0).
The materials from several hwloc tutorials are available online.
Getting and using hwloc
hwloc is open-source, available under the BSD license.
The latest hwloc releases are available on the download page. The GIT repository is also accessible for online browsing or checkout.
The version string of the latest release or release-candidate is available from here. For the latest on a specific series, replace «current» with «v2.4» for instance.
hwloc is already available as official packages for many Linux distributions (at least Debian/Ubuntu, Fedora/RHEL, SUSE, ArchLinux, Slackware, Gentoo and their derivatives), as well as NetBSD, FreeBSD, Cygwin, Mac OS X ports, and HP-UX. It is also available as EasyBuild and Spack packages.
Questions and bugs
Bugs should be reported in the tracker. Opening a new issue automatically displays lots of hints about how to debug and report issues.
See also the wiki page about Linux kernel bugs (or BIOS bugs) affecting locality information in hwloc.
Questions may be sent to the users or developers mailing lists.
There is also a #hwloc IRC channel on Freenode (irc.freenode.net).
Publications
For a general-purpose hwloc citations, please use the following one. This paper introduces hwloc, its goals and its implementation. It then shows how hwloc may be used by MPI implementations and OpenMP runtime systems as a way to carefully place processes and adapt communication strategies to the underlying hardware.
François Broquedis, Jérôme Clet-Ortega, Stéphanie Moreaud, Nathalie Furmento, Brice Goglin, Guillaume Mercier, Samuel Thibault, and Raymond Namyst. hwloc: a Generic Framework for Managing Hardware Affinities in HPC Applications. In Proceedings of the 18th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP2010), Pisa, Italia, February 2010. IEEE Computer Society Press. https://hal.inria.fr/inria-00429889
For citing how hwloc deals with new heterogeneous memory hierarchies (Knights Landing’s MCDRAM, high-bandwidth memory (HBM), non-volatile memory (NVDIMM), etc), use this paper:
Brice Goglin. Exposing the Locality of Heterogeneous Memory Architectures to HPC Applications. In Proceedings of the First ACM International Symposium on Memory Systems (MEMSYS16), Washington, DC, USA, October 2016. https://hal.inria.fr/hal-01330194
When discussing the overhead of topology discovery and why XML or synthetic topologies are useful, use this paper:
Brice Goglin. On the Overhead of Topology Discovery for Locality-aware Scheduling in HPC. In Proceedings of the 25th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP2017), St Petersburg, Russia, March 2017. https://hal.inria.fr/hal-01402755
About the memory footprint of hwloc and the new shmem topology API in hwloc 2.0:
Brice Goglin. Memory Footprint of Locality Information on Many-Core Platforms. In Proceedings of the 6th Workshop on Runtime and Operating Systems for the Many-core Era (ROME 2018), held in conjunction with IPDPS, Vancouvert, BC, Canada, May 2018. https://hal.inria.fr/hal-01644087
For citing hwloc’s I/O device locality and cluster/multi-node support, please use the following one instead. This paper explains how I/O locality is managed in hwloc, how device details are represented, how hwloc interacts with other libraries, and how multiple nodes such as a cluster can be efficiently managed.
Brice Goglin. Managing the Topology of Heterogeneous Cluster Nodes with Hardware Locality (hwloc). In Proceedings of 2014 International Conference on High Performance Computing & Simulation (HPCS 2014), Bologna, Italy, July 2014. https://hal.inria.fr/hal-00985096
For citing hwloc’s hierarchical modeling of computing, memory and I/O resources as well as multi-node support, use this paper:
Brice Goglin. Towards the Structural Modeling of the Topology of next-generation heterogeneous cluster Nodes with hwloc. Inria, November 2016. https://hal.inria.fr/hal-01400264
History / credits
hwloc is the evolution and merger of the libtopology and Portable Linux Processor Affinity (PLPA) projects. Because of functional and ideological overlap, these two code bases and ideas were merged and released under the name «hwloc» as an Open MPI sub-project. hwloc is now mostly developed by the TADaaM team at Inria (Bordeaux, France).
libtopology was initially developed by the Inria Runtime team-project as a way to discover hardware affinities inside the Marcel threading library. With the advent of multicore machines, this work became interesting for much more than multithreading. So libtopology was extracted from Marcel and became an independent library.
Portability tests are performed thanks to the Inria Continuous Integration platform.
How do you pronounce «hwloc»?
When in doubt, say «hardware locality.»
Some of the core developers say «H. W. Loke»; others say «H. W. Lock». We’ve heard several other pronunciations as well. We don’t really have a strong preference for how you say it; we chose the name for its Google-ability, not its pronunciation.