Чек-лист для отладки нейронной сети: 5 шагов на пути к успеху
Список шагов для устранения проблем, связанных с обучением, обобщением и оптимизацией модели глубокого обучения и отладки нейронной сети.

Программный код машинного обучения не совсем похож на другие программные решения. Поэтому он может быть достаточно сложен для отладки. Даже для простых нейронных сетей прямого распространения необходимо принять несколько решений об архитектуре сети, инициализации весов и оптимизации нейросети. На всех этих этапах в концепции обучения и их реализации в виде кода модели могут вкрасться коварные ошибки.
Чейз Робертс в статье «Как делать юнит тесты для машинного обучения» (англ.) выделил три основных типа ловушек:
Что же с этим делать? Эта статья предоставит структуру, которая поможет вам отладить ваши нейронные сети.
1. Начните с простого
Нейронную сеть со сложной архитектурой, регуляризацией и планировщиком скорости обучения будет сложнее отлаживать, чем простую сеть. Этот пункт может представляться несколько надуманным, ведь он не имеет отношения к отладке имеющейся нейросети. Но он важен для тех, кто хочет со старта контролировать ситуацию.
Создайте сначала простую модель
Создайте небольшую сеть с одним скрытым слоем и убедитесь, что все работает правильно. Постепенно усложняя модель, проверяйте, работает ли каждый аспект структуры (дополнительный слой, параметр и т. д.).
Обучите модель на одной точке из массива данных
В качестве быстрой проверки работоспособности используйте одну или две точки тренировочных данных. Нейросеть должна немедленно переобучаться до 100% точности. Если модель не может «воспроизвести» такой малый объем данных, она либо слишком мала, чтобы их аппроксимировать, либо уже имеется ошибка. Итак, вы убедились: модель работает. Прежде чем двигаться дальше, попробуйте потренировать ее один или несколько периодов дискретизации (epoch).
2. Потери
Потери модели (loss) – основной критерий оценки производительности и собственный критерий нейросети, по которому определяется важность какого-либо параметра, поэтому убедитесь в следующем:
Обратите внимание на начальные потери – соответствует ли их порядок модели, начинающейся со случайных предположений. В Стэндфордском курсе CS231n Андрей Карпатый предлагает следующее: «Убедитесь, что вы получаете ожидаемые потери при инициализации малыми параметрами. Регуляризацию сначала лучше уменьшить до нуля. Так, для CIFAR-10 с классификатором Softmax мы ожидаем, что начальные потери будут 2.302. У нас 10 классов, значит, вероятность диффузии составляет 0.1. Потеря Softmax является отрицательным логарифмом от вероятности. То есть потери равны –ln(0.1) = 2.302»
Для бинарного случая выполняется аналогичный расчет для каждого из классов. Допустим, данные на 20% состоят из нулей и 80% – из единиц. Ожидаемая начальная потеря составляет –0.2ln(0.5)–0.8ln(0.5) = 0.693. Если исходные потери много больше 1, нейронная сеть не сбалансирована должным образом (т. е. плохо инициализирована), или данные не нормализованы.
3. Проверьте промежуточные выходы слоев и соединения
Для отладки нейронной сети бывает полезным понимать внутреннюю динамику и ту индивидуальную роль, которую играют промежуточные слои и межсоединения. Вы можете столкнуться с ошибками:
Если значение градиента равно нулю, это может означать, что скорость обучения в оптимизаторе слишком мала. Или то, что вы столкнулись с первой из перечисленных ошибок.
Помимо просмотра абсолютных значений обновлений градиента, обязательно следите за величинами активаций, весов и обновлениями каждого слоя. Например, величина обновлений параметров (весов и смещений) должна составлять 1-e3.
Существует явление, называемое «умирающий ReLU» или «проблема исчезающего градиента». Оно происходит, когда нейроны обучаются с большим отрицательным смещением весов. В этом случае нейроны больше не активируются ни на одной из точек данных. Вы можете использовать проверку градиента для отслеживания таких ошибок, аппроксимируя градиент численным образом. Для этого ознакомьтесь с соответствующими разделами CS231n (раз и два) и специальным уроком Эндрю Ына.
Что касается визуализации нейронной сети, Файзан Шейх описал три основных группы методов:
Существует множество полезных инструментов для визуализации активаций и соединений отдельных слоев, например, ConX и TensorBoard. Здесь представлен пример визуализацией нейросети, сделанной с помощью ConX:
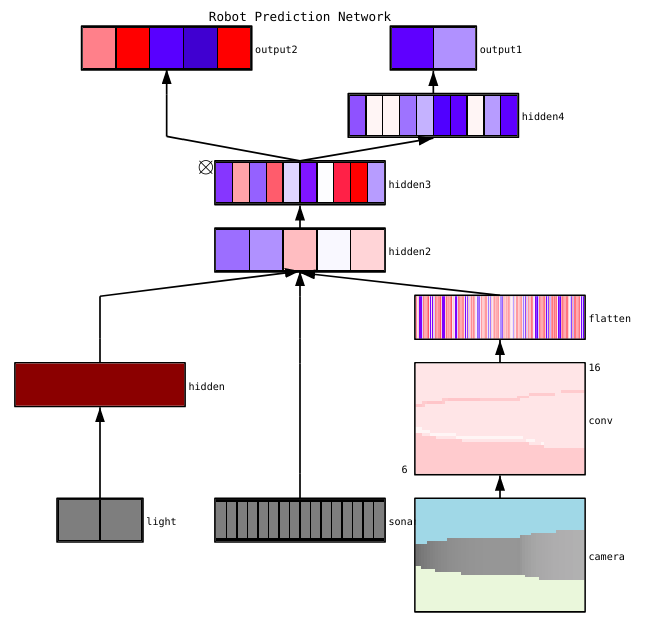
Если для вас важны вопросы отладки нейронной сети, обрабатывающей изображения, ознакомьтесь с красочной публикацией Эрика Риппела «Визуализация частей сверточных нейронных сетей с использованием Keras и кошек» (англ.).
4. Диагностика параметров
Нейронные сети имеют огромное число параметров для настройки, к тому же взаимосвязанных, что затрудняет их оптимизацию. Обратите внимание: эта сфера является областью активных исследований. Так что изложенные ниже рекомендации – лишь начальные точки.
Размер батча (mini-batch)
С одной стороны, размер пакета должен быть довольно большим, чтобы сделать оценку ошибки градиента. С другой, батч должен быть довольно мал, чтобы градиентный спуск мог регуляризовать нейросеть. Слишком малые размеры батча заставляют процесс обучения быстро сходиться за счет шума и могут приводить к трудностям оптимизации.
В публикации «Об использовании крупных батчей для глубокого обучения: разрыв в обобщении и острые минимумы» (англ.) говорится: «На практике наблюдалось, что при использовании крупных батчей качество модели ухудшалось. Это было определено по способности модели к обобщению. Исследуя причину ухудшения, мы представили численные доказательства того, что метод крупных батчей имеет тенденцию сходиться к резким минимизаторам функций обучения и тестирования. А резкие минимумы, как известно, приводят к худшей обобщающей способности. Напротив, методы с малыми батчами сходятся к плоским минимизаторам. Эксперименты подтверждают мнение, что такое поведение обусловлено внутренним шумом при оценке градиента».
Скорость обучения
При низкой скорости обучения процесс рискует застрять в локальных минимумах. Слишком высокая скорость обучения приведет к расхождению процесса оптимизации, так как вы можете «перепрыгнуть» через узкую, но глубокую часть функции потерь. Рассмотрите вопрос планирования скорости обучения, чтобы правильно снижать скорость обучения по мере тренировки нейросети. В курсе CS231n имеется раздел, посвященный методикам реализации процедуры отжига при настройке скорости обучения. Многие фреймворки используют планировщики скорости обучения или схожие стратегии. Приведем здесь ссылки на соответствующие разделы документации: Keras, TensorFlow, PyTorch, MXNet.
Ограничение нормы градиента (gradient clipping)
Gradient clipping предполагает ограничение параметров градиента в процессе обратного распространения по максимальному значению или максимальной норме. Этот подход полезен для устранения взрывных градиентов.
Пакетная нормализация
Пакетная нормализация используется для нормализации входных данных каждого слоя, чтобы бороться с проблемой внутреннего ковариантного сдвига. Наиболее распространенные ошибки, связанные с пакетной нормализацией, описаны в соответствующей публикации Дишэнка Банзала.
Стохастический градиентный спуск
Существует несколько разновидностей стохастического градиентного спуска (СГС), использующих импульс, адаптивные скорости обучения и обновления Нестерова. Но ни одна из этих разновидностей не выигрывает одновременно и по эффективности обучения, и по его обобщению (см. обзор алгоритмов оптимизации градиентного спуска и эксперимент SDG > Adam). Рекомендуемой отправной точкой является Adam или простой СГС с импульсом Нестерова.
Регуляризация
Регуляризация имеет решающее значение для построения обобщаемой модели. Она добавляет штраф за сложность модели или экстремальные значения параметров. Это значительно уменьшает дисперсию модели без существенного увеличения ее смещения.
Важное замечание дается в курсе CS231n: «Часто функция потерь представляет собой сумму потерь данных и потерь регуляризации (например, штраф L2 по весам). Опасность в том, что потеря регуляризации может превысить потерю данных. В этом случае градиенты будут исходить в основном от компонента, обусловленного регуляризацией. Он обычно имеет более простое выражение градиента. Это может маскировать неправильную реализацию градиента потери данных». В таком случае вы должны отключить регуляризацию и независимо проверить градиент потери данных.
Исключение (dropout)
Исключение – еще одна техника, позволяющая регуляризовать вашу нейросеть и избежать переобучения. Использование дропаута в процессе обучения заключается в ограничении числа активных нейронов при помощи вероятностного гиперпараметра. В результате нейросети требуется использовать другое подмножество параметров для пакета, на котором происходит обучение. Исключение уменьшает изменение определенных параметров, которые начинают доминировать над другими. То есть более обученные нейроны получают в сети больший вес.
Теперь важное предупреждение, если вы используете вместе дропаут и пакетную нормализацию. Будьте осторожны с порядком выполнения этих операций или совместным использованием. В этом вопросе пока не найден консенсус. Некоторые идеи на этот счет можно найти в следующей публикации.
5. Документируйте результаты экспериментов и отладки нейронной сети
Легко недооценивать важность документации ваших экспериментов до тех пор пока вы не забудете какие скорости обучения и веса классов вы ранее использовали. Важно иметь возможность легко отслеживать, просматривать и воспроизводить предыдущие эксперименты. Это уменьшает объем повторяемых работ и упрощает процесс отладки нейронной сети.
Ручное документирование информации практически всегда трудоемко. Поэтому пригодятся такие инструменты, как Comet.ml, помогающие автоматически отслеживать наборы данных, изменения кода, историю экспериментов и производственные модели. В том числе и такие ключевые сведения о вашей модели, как гиперпараметры, показатели производительности и детали программного окружения.
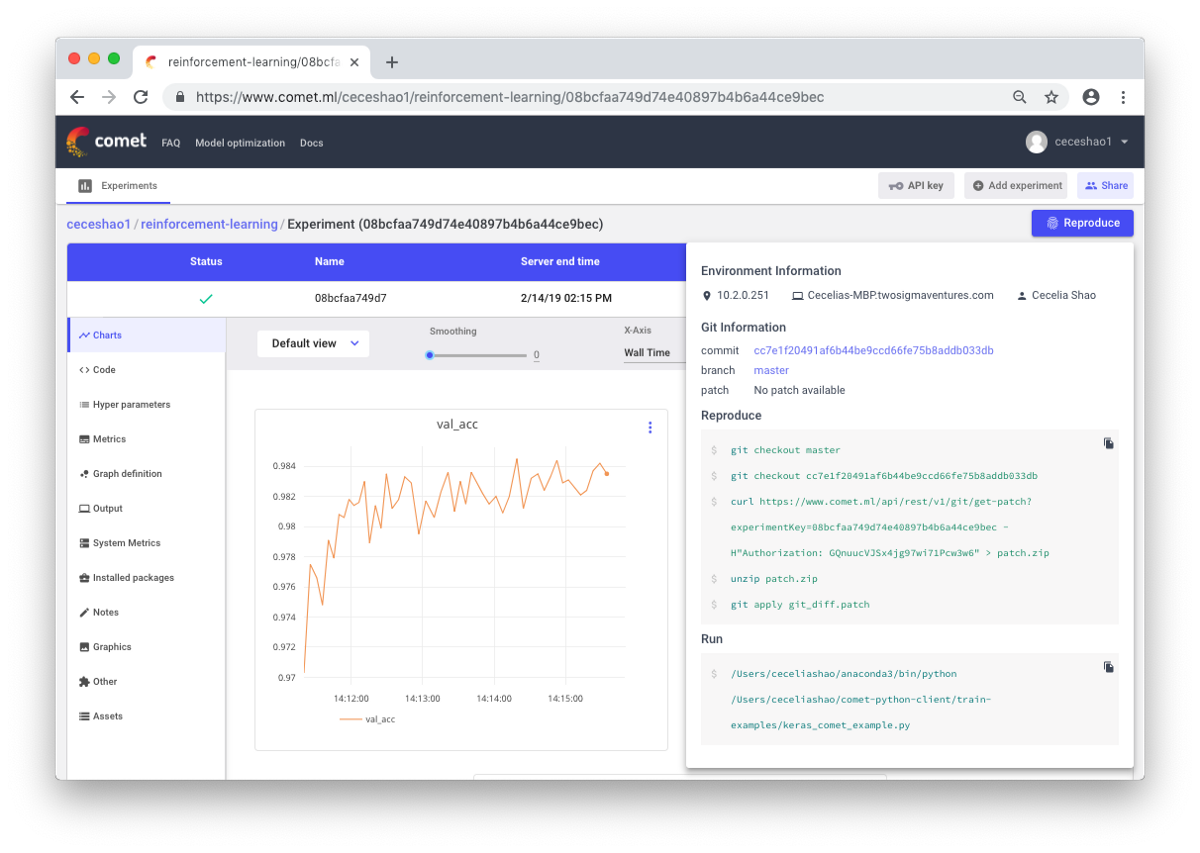
Нейросеть может быть чувствительной к небольшим изменениям данных, параметров и версий пакетов. Это может приводить к падению производительности модели. Отслеживание вашей работы – первый шаг, который вы можете предпринять, чтобы стандартизировать рабочую среду.
How to apply Gradient Clipping in PyTorch
Two common issues with training recurrent neural networks are vanishing gradients and exploding gradients. Exploding gradients can occur when the gradient becomes too large, resulting in an unstable network. Vanishing gradients can happen when optimization gets stuck at a certain point because the gradient is too small to progress.The training process can be made stable by changing the gradients either by scaling the vector norm or clipping gradient values to a range.
Using gradient clipping you can prevent exploding gradients in neural networks.Gradient clipping limits the magnitude of the gradient.There are many ways to compute gradient clipping, but a common one is to rescale gradients so that their norm is at most a particular value. With gradient clipping, pre-determined gradient thresholds are introduced, and then gradient norms that exceed this threshold are scaled down to match the norm.This prevents any gradient to have norm greater than the threshold and thus the gradients are clipped.
There are two main methods for updating the error derivative:
1.Gradient Scaling: Whenever the gradient norm is greater than a particular threshold, we clip the gradient norm so that it stays within the threshold. This threshold is sometimes set to 1. You probably want to clip the whole gradient by its global norm.
2.Gradient Clipping: It forces the gradient values to a specific minimum or maximum value if the gradient exceeded an expected range. We set a threshold value and if the gradient is more than that then it is clipped.
Gradient Scaling
In RNN the gradients tend to grow very large (exploding gradient) and clipping them helps to prevent this from happening. Using torch.nn.utils.clip_grad_norm_ to keep the gradients within a specific range.
For example, we could specify a norm of 1.0, meaning that if the vector norm for a gradient exceeds 1.0, then the values in the vector will be rescaled so that the norm of the vector equals 1.0.
The clip_grad_norm_ modifies the gradient after the entire back propagation has taken place. clip_grad_norm_ is invoked after all of the gradients have been updated. I.e. between loss.backward() and optimizer.step(). So during loss.backward(), the gradients that are propagated backward are not clipped until the backward pass completes and clip_grad_norm_() is invoked. optimizer.step() will then use the updated gradients.
The norm is computed over all gradients together as if they were concatenated into a single vector. All of the gradient coefficients are multiplied by the same clip_coef.
Now, we’ll define the training loop in which gradient calculation along with optimizer steps will be defined. Here we’ll also define our clipping instruction.
2.Gradient Clipping by value
It clipping the derivatives of the loss function to have a given value if a gradient value is less than a negative threshold or more than the positive threshold.
To apply Clip-by-norm you can change this line to:
The value for the gradient vector norm or preferred range can be configured by trial and error, by using common values used in the literature, or by first observing common vector norms or ranges via experimentation and then choosing a sensible value.
Gradient Clipping
What is Gradient Clipping?
Gradient clipping is a technique to prevent exploding gradients in very deep networks, usually in recurrent neural networks. A neural network is a learning algorithm, also called neural network or neural net, that uses a network of functions to understand and translate data input into a specific output. This type of learning algorithm is designed based on the way neurons function in the human brain. There are many ways to compute gradient clipping, but a common one is to rescale gradients so that their norm is at most a particular value. With gradient clipping, pre-determined gradient threshold be introduced, and then gradients norms that exceed this threshold are scaled down to match the norm. This prevents any gradient to have norm greater than the threshold and thus the gradients are clipped. There is an introduced bias in the resulting values from the gradient, but gradient clipping can keep things stable.
Why is this Useful?
Practical Uses of Gradient Clipping
– Gradient clipping is a technique used in deep learning to optimize and solve problems. Deep learning is a subfield of machine learning that uses algorithms inspired by the structure and function of the human brain and neural networks.
The world’s most comprehensive
data science & artificial intelligence
glossary
Research that mentions Gradient Clipping

A Loss Curvature Perspective on Training Instability in Deep Learning

Training Deep Neural Networks Without Batch Normalization

Reverse engineering learned optimizers reveals known and novel mechanisms

Towards Unified INT8 Training for Convolutional Neural Network
![]()
Deep Transfer Learning for Land Use Land Cover Classification: A Comparative Study

NeuralDP Differentially private neural networks by design

Input Invex Neural Network
How to Avoid Exploding Gradients With Gradient Clipping
Last Updated on August 28, 2020
Training a neural network can become unstable given the choice of error function, learning rate, or even the scale of the target variable.
Large updates to weights during training can cause a numerical overflow or underflow often referred to as “exploding gradients.”
The problem of exploding gradients is more common with recurrent neural networks, such as LSTMs given the accumulation of gradients unrolled over hundreds of input time steps.
A common and relatively easy solution to the exploding gradients problem is to change the derivative of the error before propagating it backward through the network and using it to update the weights. Two approaches include rescaling the gradients given a chosen vector norm and clipping gradient values that exceed a preferred range. Together, these methods are referred to as “gradient clipping.”
In this tutorial, you will discover the exploding gradient problem and how to improve neural network training stability using gradient clipping.
After completing this tutorial, you will know:
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.

How to Avoid Exploding Gradients in Neural Networks With Gradient Clipping
Photo by Ian Livesey, some rights reserved.
Tutorial Overview
This tutorial is divided into six parts; they are:
Exploding Gradients and Clipping
Neural networks are trained using the stochastic gradient descent optimization algorithm.
This requires first the estimation of the loss on one or more training examples, then the calculation of the derivative of the loss, which is propagated backward through the network in order to update the weights. Weights are updated using a fraction of the back propagated error controlled by the learning rate.
It is possible for the updates to the weights to be so large that the weights either overflow or underflow their numerical precision. In practice, the weights can take on the value of an “NaN” or “Inf” when they overflow or underflow and for practical purposes the network will be useless from that point forward, forever predicting NaN values as signals flow through the invalid weights.
The difficulty that arises is that when the parameter gradient is very large, a gradient descent parameter update could throw the parameters very far, into a region where the objective function is larger, undoing much of the work that had been done to reach the current solution.
The underflow or overflow of weights is generally refers to as an instability of the network training process and is known by the name “exploding gradients” as the unstable training process causes the network to fail to train in such a way that the model is essentially useless.
In a given neural network, such as a Convolutional Neural Network or Multilayer Perceptron, this can happen due to a poor choice of configuration. Some examples include:
Exploding gradients is also a problem in recurrent neural networks such as the Long Short-Term Memory network given the accumulation of error gradients in the unrolled recurrent structure.
Exploding gradients can be avoided in general by careful configuration of the network model, such as choice of small learning rate, scaled target variables, and a standard loss function. Nevertheless, exploding gradients may still be an issue with recurrent networks with a large number of input time steps.
One difficulty when training LSTM with the full gradient is that the derivatives sometimes become excessively large, leading to numerical problems. To prevent this, [we] clipped the derivative of the loss with respect to the network inputs to the LSTM layers (before the sigmoid and tanh functions are applied) to lie within a predefined range.
A common solution to exploding gradients is to change the error derivative before propagating it backward through the network and using it to update the weights. By rescaling the error derivative, the updates to the weights will also be rescaled, dramatically decreasing the likelihood of an overflow or underflow.
There are two main methods for updating the error derivative; they are:
Gradient scaling involves normalizing the error gradient vector such that vector norm (magnitude) equals a defined value, such as 1.0.
… one simple mechanism to deal with a sudden increase in the norm of the gradients is to rescale them whenever they go over a threshold
Gradient clipping involves forcing the gradient values (element-wise) to a specific minimum or maximum value if the gradient exceeded an expected range.
Together, these methods are often simply referred to as “gradient clipping.”
When the traditional gradient descent algorithm proposes to make a very large step, the gradient clipping heuristic intervenes to reduce the step size to be small enough that it is less likely to go outside the region where the gradient indicates the direction of approximately steepest descent.
It is a method that only addresses the numerical stability of training deep neural network models and does not offer any general improvement in performance.
The value for the gradient vector norm or preferred range can be configured by trial and error, by using common values used in the literature or by first observing common vector norms or ranges via experimentation and then choosing a sensible value.
In our experiments we have noticed that for a given task and model size, training is not very sensitive to this [gradient norm] hyperparameter and the algorithm behaves well even for rather small thresholds.
It is common to use the same gradient clipping configuration for all layers in the network. Nevertheless, there are examples where a larger range of error gradients are permitted in the output layer compared to hidden layers.
The output derivatives […] were clipped in the range [−100, 100], and the LSTM derivatives were clipped in the range [−10, 10]. Clipping the output gradients proved vital for numerical stability; even so, the networks sometimes had numerical problems late on in training, after they had started overfitting on the training data.
Want Better Results with Deep Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Download Your FREE Mini-Course
Gradient Clipping in Keras
Keras supports gradient clipping on each optimization algorithm, with the same scheme applied to all layers in the model
Gradient clipping can be used with an optimization algorithm, such as stochastic gradient descent, via including an additional argument when configuring the optimization algorithm.
Two types of gradient clipping can be used: gradient norm scaling and gradient value clipping.
Gradient Norm Scaling
Gradient norm scaling involves changing the derivatives of the loss function to have a given vector norm when the L2 vector norm (sum of the squared values) of the gradient vector exceeds a threshold value.
For example, we could specify a norm of 1.0, meaning that if the vector norm for a gradient exceeds 1.0, then the values in the vector will be rescaled so that the norm of the vector equals 1.0.
This can be used in Keras by specifying the “clipnorm” argument on the optimizer; for example:



