Существующие приложения Google для распознавания речи

Компания Google активно внедряет распознавани е речи во многие собственные приложения и инструменты. Вообще, распознавание речи — это сравнительно недавняя функция. Она стала возможной из-за быстрого развития технологий искусственного интеллекта.
Google и распознавание речи
Компания Google активно участвует в новейших технологических разработках. Она одна из первых, кто создал беспилотный автомобиль. Также ее постоянно можно заметить во многих технологических инновационных разработках. Распознавание речи — не исключение, поэтому Гугл создал специализированный сервис по распознаванию голоса — Google Speech API.
Google Speech API
Уже сейчас система распознавания голоса от Go og le применяется во многих сервисах жизнедеятельности человека:
в качестве первоначального оператора, которому нужно определить, к какому специалисту переориентировать клиента;
когда нужно уточнить или распознать адрес доставки;
если нужно аутентифицировать по голосу своих клиентов, когда они осуществляют запрос каких-нибудь конфиденциальных сведений;
когда нужно предоставлять по телефону большой объем однообразной справочной информации своим клиентам;
в сферах голосового самообслуживания клиентов
Скачать GoogleSpeechAPI.zip. В архиве будут находиться 2 сценария действий. Один предполагает проводить запись голосовых сообщений как эт а лон использования сервиса. Второй — это отправка записанных сообщений на сервера Гугл для распознавания этих сообщений.
Использование Google Speech API дает множество преимуществ вашему бизнесу. Однако нужно понимать, что любые передаваемые данные «оседают» на серверах Гугл. Поэтому когда речь идет о конфиденциальности, то тут нужно хорошо все обдумать. Потому что Гугл и «конфиденциальность» или «приватность» — это далеко не синонимы.
Приведем несколько примеров, где реально используется распознавание голоса от Google. Возможно, это не так масштабно, как можно реализовать при помощи Google Speech API, но это дает понимание того, как вообще это работает и где можно применять эту технологию, если вы не являетесь владельцем крупного бизнеса.
5 популярных приложений, где используют распознавание голоса Гугл:
Evernote. Это очень популярное приложение для создания заметок. Помимо стандартного ввода текста, оно поддерживает и распознавание речи, что существенно ускоряет запись заметок.
Speechnotes. В своей работе использует распознавание речи от Google. Основная его функция — это перевод голоса в текст. Идеально подходит тем, кому нужно очень много печатать.
Speechtexter. Также использует технологии Гугл для распознавания голоса. В его собственный словарь можно добавить слова-сокращения, которые часто используете в тексте. Это приложение и будет распознавать — это его особенность и главное отличие от подобных ему приложений.
T2S. Данное приложение очень качественно задействовало распознавание речи от Google. Оно призвано преобразовывать речь в текст, однако может также воспроизводить выделенный текст и экспортировать аудиозаметку в аудиофайл.
Заключение
Как видно, распознавание речи от Google можно использовать для больших и мелких целей. То есть можно задействовать эту технологию для модернизации собственного бизнеса, в качестве замены операторов на телефоне. Но также эту технологию можно использовать в более мелких целях — при создании приложений на Android.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
990x.top
Простой компьютерный блог для души)
Синтезатор речи Google — что это за программа и нужна ли она?

Приветствую. Android содержит функции, при помощи которых можно сэкономить время. Одна из них — синтез речи, позволяющая смартфону преобразовывать текстовое содержимое в аудио. Можно открыть статью на сайте, запустить воспроизведение текста, отрегулировать громкость/тон — положить телефон, заниматься своими делами.
Синтезатор речи Google — что это такое?
Технология озвучивания текста на экране, поддерживается много языков, включая русский.
Является системным компонентом, занимающем немало места (примерно 400 мб):

При отсутствии необходимости озвучивать текст — данный компонент возможно удалить/отключить:
 Продвинутые пользователи могут использовать Titanium Backup (необходим root-доступ) для отключения/удаления.
Продвинутые пользователи могут использовать Titanium Backup (необходим root-доступ) для отключения/удаления.
Примеры использования
Определенные приложения из Google Play могут использовать синтезатор для озвучивания текстового содержимого, подсказок, ваших действий.
Одно условие — приложение должно поддерживать синтез речи. Например некоторые браузеры не поддерживают воспроизведение текста со страницы, но Яндекс Браузер — поддерживает.
Синтезатор речи Google — как активировать?
Откройте настройки, найдите Специальные возможности (располагается в Расширенных настройках). Можно использовать поиск по настройкам, написав слово синтез:
 Выбираем Синтез речи.
Выбираем Синтез речи.
По умолчанию выставлен синтезатор Google, далее можно отрегулировать тон/громкость воспроизведения:

После настройки — в специальных возможностях активирует опцию Озвучивание при нажатии:
 При отсутствии данной опции — установите приложение Android Accessibility Suite.
При отсутствии данной опции — установите приложение Android Accessibility Suite.
После активации появится способность озвучивать текст: нажав на круглый значок в любом приложении — достаточно выделить область текста, после нажать иконку воспроизведения:
 Некоторые модели телефонов данную технологию не поддерживают. Иногда значок находится возле навигационных кнопок (внизу).
Некоторые модели телефонов данную технологию не поддерживают. Иногда значок находится возле навигационных кнопок (внизу).
Заключение
Надеюсь информация оказалась полезной. Удачи.
Использование Google Cloud Speech API v2 в Asterisk для распознавания русской речи
Выбор API для распознавания речи
Я рассматривал только вариант api, коробочные решения были не нужны, поскольку требовали ресурсы, данные для распознания не критичны для бизнеса, да и использование их существенно сложнее и требует больше человеко-часов.
Первым был Yandex SpeechKit Cloud. Мне он сразу понравился простотой использования:
Ценовая политика 400 рублей за 1000 запросов. Первый месяц бесплатно. Но после этого пошли только разочарования:
— На передачу большого предложения, приходил ответ из 2-3 слов
— Распознавались эти слова в странной последовательности
— Попытки изменения топика положительных результатов не принесли
Возможно это было связано со средним качеством записи, мы все тестировали через голосовые шлюзы и древние телефоны panasonic. Пока планирую его в дальнейшем использовать для построения IVR.
Следующим стал сервис от Google. Интернет пестрит статьями, в которых предлагается использовать API для разработчиков Chromium. Сейчас ключей для этого API уже так просто получить нельзя. Поэтому мы будем использовать коммерческую платформу.
Подготовка к использованию Google Cloud Speech API
Нам необходимо будет зарегистрировать проект и создать ключ сервисного аккаунта для авторизации. Вот ссылка для получения триала, необходим гугл-аккаунт. После регистрации необходимо активировать API и создать ключ для авторизации. После необходимо скопировать ключ на сервер.
Перейдем к настройке самого сервера, нам необходимы будут:
— python
— python-pip
— python google api client
Теперь нам необходимо экспортировать две переменных окружения, для успешной работы с апи. Первая это путь к сервисному ключу, вторая название вашего проекта.
Скачаем тестовый аудио файл и попытаемся запустить скрипт:
Отлично! Первый тест успешен. Теперь изменим в скрипте язык распознавания текста и попробуем распознать его:
Гугл возвращает нам ответ в юникоде. Но мы хотим видеть нормальные буквы. Поменяем немного наш voice.py:
Мы будем использовать
Добавим import simplejson. Итоговый скрипт под катом:
Но перед его запуском нужно будет экспортировать ещё одну переменную окружения export PYTHONIOENCODING=UTF-8. Без неё у меня возникли проблемы с stdout при вызове в скриптах.
Отлично. Теперь мы можем вызывать этот скрипт в диалплане.
Пример Asterisk dialplan
Для вызова скрипта я буду использовать простенький диалплан:
Распознавание речи с помощью Google Speech API
Распознавание речи позволяет создавать системы автоматического обслуживания клиентов в тех случаях, когда не применимо управление с помощью тонального набора. В качестве примера можно рассмотреть сервис бронирования авиабилетов, который подразумевает выбор их большого числа городов. Тональное меню в таком сервисе не удобно, поэтому голосовое управление будет самым эффективным. Диалог между системой и абонентом может выглядеть следующим образом:
Общение с таким голосовым порталом становится приближенным к обслуживанию оператором.
Система распознавания голосовых запросов применяется во многих системах, например, для:
Система распознавания речи, как правило, состоит из следующих частей:
Для использования Google Speech API в вашей системе выполните следующие действия:
Шаг 1. Скачайте и импортируйте сценарии в вашу систему Oktell.
Скачать сценарий: Google_Speech_API.zip (для версий Oktell старше 2.10)
В архиве располагаются два сценария:
После импорта сценариев в Oktell, сохраните их «На сервер«
ВНИМАНИЕ: Google Speech API — это платный продукт. В сценарии (компонент Web-запроса GoogleVoice) используется пробный ключ, который может быть заблокирован в следствие определенного числа запросов. При тестах максимальное количество запросов не обнаружено. Если вы хотите приобрести платную версию Google Speech API обратитесь в поддержку Google.
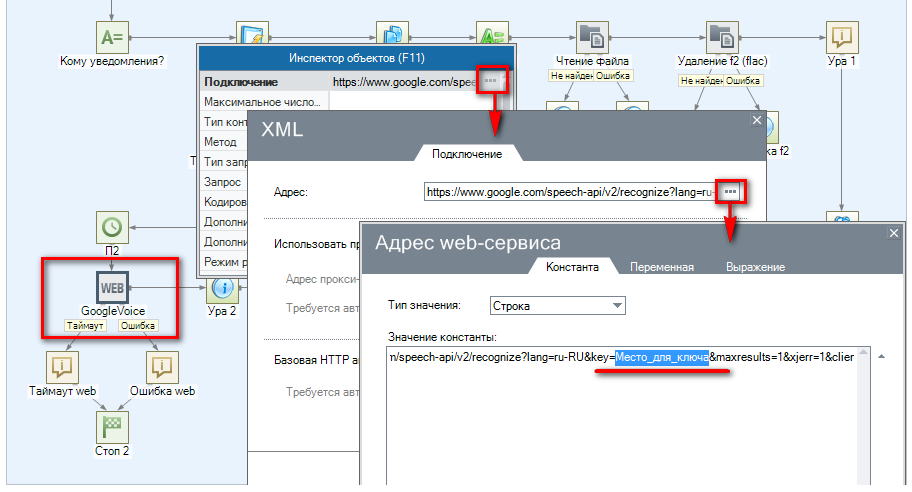
Нажмите «Сохранить«. Затем «Применить«.
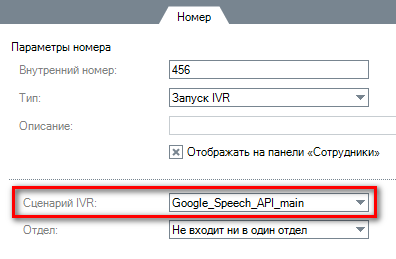
Шаг 3. При звонке на заданный номер (в примере, 456), проговорите сообщение. В конце нажмите «*«. Через несколько секунд появятся уведомления с распознанным текстом.

Полученный текст передается в переменной text, которую затем можно проанализировать и выполнить необходимые действия. Используйте пример Google_Speech_API_main для использования сервиса распознавания в главном сценарии.
Ультимативное сравнение систем распознавания речи: Ashmanov, Google, Sber, Silero, Tinkoff, Yandex

Какое-то время назад мы писали цикл статей про то, как правильно измерять качество систем распознавания речи, и собственно снимали метрики с доступных решений (цикл статей — 1, 2, 3) (на тот момент и коммерческих и некоммерческих решений). На Хабре была выжимка из этого цикла в рамках этой статьи, но до масштабного обновления исследования, достойного публикации на Хабре, руки никак не доходили (это требует как минимум большого количества усилий и подготовки).
Прошло некоторое время и пора обновить наше исследование, сделав его по-настоящему ультимативным. По сравнению с прошлыми исследованиями изменилось или добавилось следующее:
Методология
Мы старались следовать нашей стандартной методологии (см. ссылки выше) с небольшими изменениями:
Сухие метрики
Все модели, кроме Silero bleeding egde, это модели упакованные в production сервисы. Используемый показатель — WER (для простоты восприятия можно мысленно пририсовать знак процента или считать WER процентом ошибок в словах).
| Датасет | Ashmanov | Sber | Sber | Silero | Silero new | Tinkoff | Yandex | ||
|---|---|---|---|---|---|---|---|---|---|
| default | enhanced | IVR | prod | bleeding edge | |||||
| Чтение | 10 | 11 | 10 | 7 | 7 | 6 | 8 | 13 | |
| Умная колонка | 35 | 24 | 6 | 30 | 27 | 27 | 14 | ||
| Энергосбыт | 24 | 39 | 41 | 20 | 16 | 11 | 15 | 13 | |
| Звонки (такси) | 47 | 16 | 18 | 22 | 32 | 13 | 12 | 21 | 15 |
| Публичные выступления | 28 | 27 | 24 | 18 | 14 | 12 | 20 | 21 | |
| Финансы (оператор) | 31 | 37 | 37 | 24 | 33 | 25 | 24 | 23 | 22 |
| Аэропорт | 31 | 36 | 37 | 26 | 21 | 22 | 25 | 21 | |
| Аудио книги | 22 | 60 | 54 | 19 | 24 | 20 | 28 | 22 | |
| Радио | 24 | 61 | 40 | 26 | 18 | 15 | 27 | 23 | |
| Умная колонка (далеко) | 42 | 49 | 8 | 41 | 27 | 52 | 18 | ||
| Банк | 62 | 30 | 32 | 24 | 28 | 39 | 35 | 28 | 25 |
| Звонки (e-commerce) | 34 | 45 | 43 | 34 | 45 | 29 | 29 | 31 | 28 |
| Заседания суда | 34 | 29 | 29 | 31 | 20 | 20 | 31 | 29 | |
| Yellow pages | 45 | 43 | 49 | 41 | 32 | 29 | 31 | 30 | |
| Финансы (клиент) | 43 | 55 | 59 | 41 | 67 | 38 | 37 | 33 | 32 |
| YouTube | 32 | 50 | 41 | 34 | 28 | 25 | 38 | 32 | |
| Звонки (пранки) | 44 | 72 | 66 | 46 | 41 | 35 | 38 | 35 | |
| Медицинские термины | 50 | 37 | 40 | 50 | 35 | 33 | 42 | 38 | |
| Диспетчерская | 61 | 68 | 68 | 54 | 41 | 32 | 43 | 42 | |
| Стихи, песни и рэп | 54 | 70 | 60 | 61 | 43 | 41 | 56 | 54 | |
| Справочная | 39 | 50 | 53 | 32 | 25 | 20 | 27 |
Чем меньше WER, тем лучше.
Также интерес представляет процент пустых ответов сервисов (не совсем ясно, это баг или фича, артефакт нагрузки или самих моделей, но где-то снижение нагрузки помогает снизить этот процент). Традиционно этот процент высокий у Гугла. И как ни странно он довольно высокий у Сбера (и там скорее всего это фича, так как их пропускная способность явно не узкое место).
| Ashmanov | Sber | Sber | Silero | Tinkoff | Yandex | |||
|---|---|---|---|---|---|---|---|---|
| default | enhanced | IVR | ||||||
| Чтение | 0% | 0% | 0% | 0% | 0% | 5% | 4% | |
| Умная колонка | 0% | 2% | 0% | 0% | 4% | 0% | ||
| Энергосбыт | 1% | 12% | 13% | 6% | 0% | 2% | 1% | |
| Звонки (такси) | 0% | 0% | 0% | 1% | 0% | 0% | 7% | 0% |
| Публичные выступления | 0% | 1% | 0% | 0% | 0% | 2% | 0% | |
| Финансы (оператор) | 0% | 0% | 0% | 2% | 0% | 0% | 6% | 0% |
| Аэропорт | 0% | 8% | 10% | 4% | 0% | 4% | 0% | |
| Аудио книги | 0% | 22% | 6% | 2% | 0% | 1% | 0% | |
| Радио | 0% | 19% | 2% | 3% | 1% | 4% | 0% | |
| Умная колонка (далеко) | 0% | 12% | 0% | 0% | 1% | 0% | ||
| Банк | 0% | 2% | 3% | 1% | 1% | 0% | 5% | 1% |
| Звонки (e-commerce) | 0% | 0% | 0% | 7% | 1% | 0% | 7% | 0% |
| Заседания суда | 0% | 0% | 0% | 1% | 0% | 4% | 0% | |
| Yellow pages | 1% | 13% | 9% | 14% | 0% | 2% | 2% | |
| Финансы (клиент) | 0% | 0% | 7% | 35% | 9% | 0% | 5% | 0% |
| YouTube | 0% | 13% | 1% | 6% | 0% | 1% | 0% | |
| Звонки (пранки) | 1% | 33% | 12% | 17% | 5% | 1% | 1% | |
| Медицинские термины | 0% | 1% | 0% | 7% | 0% | 6% | 1% | |
| Диспетчерская | 3% | 26% | 28% | 25% | 0% | 2% | 4% | |
| Стихи, песни и рэп | 2% | 19% | 3% | 25% | 0% | 1% | 1% | |
| Справочная | 1% | 12% | 14% | 9% | 0% | 3% | 0% |
Чем меньше ближе к нулю этот процент, тем лучше.
Качественный анализ и интерпретация метрик
Неудивительно, что каждый силен в том домене, на котором фокусируется. Tinkoff — на звонках в банк, справочную, финансовые сервисы. Сбер имеет ультимативно лучшие результаты на своей «умной колонке» (спекулирую, что они поделились в лучшем случае 1/10 своих данных) и в среднем неплохие показатели. IVR модель Сбера на доменах, где оригинальные данные лежат у нас в 8 kHz, показывает себя достойно, но она не ультимативно лучшая. Приятно удивил Яндекс — в прошлых рейтингах их модели были не в списке лидеров, а сейчас точно лучше, чем в среднем по больнице. Другой сюрприз — Google, который является аутсайдером данного исследования вместе с Ашмановым.
Также интересно посчитать количество доменов, где production модели поставщика лучшие / худшие (допустим с неким «послаблением» в 10% от лучшего или худшего результата):
| Сервис | Лучше всех | Хуже всех |
|---|---|---|
| Ashmanov | 0 | 7 |
| 1 | 13 (9 у enhanced) | |
| Sber | 2 | 0 |
| Sber IVR | 4 | 4 |
| Silero | 13 | 0 |
| Tinkoff | 6 | 2 |
| Yandex | 10 | 1 |
Как и ожидалось — наша модель показывает в среднем неплохие показатели на всех доменах, заметно отставая на банках и финансах. Также если смотреть по формальной метрике «на каком числе доменов модель лучшая или почти лучшая» — то наша модель как минимум лучше всех генерализуется. Если включить в забег нашу bleeding edge модель (мы пока не выкатили ее еще), то она отстает только на «умной колонке» и банковских датасетах, лидируя уже на 17 доменах из 21. Это логично, так как у нас нет своей колонки и банки очень неохотно делятся своими данными даже приватно.
Удобство использования
У Сбера на момент тестирования было только gRPC API. Это не самое удачное решение для SMB клиентов с точки зрения удобства, имеющее более высокий порог на вход. Также в их реализации вообще не прокидываются важные ошибки (или отсутствуют в принципе, чем часто грешат корпоративные сервисы). Документация запрятана внутри портала их экосистемы, но в целом кроме лишней «сложности» проблем особо там нет, читать приятно. 40 страниц на два метода это конечно сильно (мы читали сначала в PDF), но документация хотя бы подробная и с примерами и пояснениями.
У Яндекса и Гугла стандартная корпоративная документация. Она несложная, но иногда длиннее, чем хотелось бы. Есть и обычные и потоковые интерфейсы. У Яндекса кстати она стала сильно приятнее и человечнее с момента, когда я в последний раз ее видел.
У Tinkoff само распознавание работает по умолчанию также через gRPC, а поверх написаны клиенты (в тех, которые мы разбирали было много лишнего). С учетом фокуса на enterprise (оставим за скобками этические, правовые и финансовые последствия монетизации банком ваших данных без явного согласия и возможности отказаться) это имеет больше смысла, чем то, что сделал Сбер. Это уже мои спекуляции, но скорее всего это в первую очередь артефакт разработки решения под свои нужды.
У сервиса Ашманова… вообще нет документации, примеры не работают из коробки, пришлось немного позаниматься перебором для запуска. Отдельно отмечу, что обычно b2b сервисы не славятся читаемыми ошибками и читаемой документацией, но тут вообще не было ни ошибок, ни документации. Или 500-я ошибка или 200 с пустым ответом. Это создает легкий когнитивный диссонанс с учетом проработки анимации девушки-маскота, количества маркетинговых материалов и «успешных» кейсов.

У нашего сервиса само публичное АПИ весьма минималистичное и состоит из 2 методов (синтеза и gRPC нет еще в публичной документации) с примерами. Есть также gRPC АПИ, которое сейчас проходит обкатку. Наверное я тут не лучший судья, но основная ценность как мне кажется состоит в радикальной простоте для публичного АПИ и детальных инструкциях / сайзингах / опциях конфигурирования для более крупных клиентов.
Пропускная способность
Все АПИ, которые мы протестировали (кроме Ашманова) показали себя довольно бодро по скорости (это баг или фича — решать вам). Для измерения пропускной способности мы считаем показатель секунд аудио в секунду на 1 поток распознавания (RTS = 1 / RTF):
| Сервис | RTS per Thread | Threads | Комментарий |
|---|---|---|---|
| Ashmanov | 0.2 | 8 | |
| Ashmanov | 1.7 | 1 | |
| 4.3 | 8 | ||
| Google enhanced | 2.9 | 8 | |
| Sber | 13.6 | 8 | |
| Sber | 14.1 | 1 | |
| Silero | 2.5 | 8 | 4-core, 1080 |
| Silero | 3.8 | 4 | 4-core, 1080 |
| Silero | 6.0 | 8 | 12 cores, 2 1080 Ti |
| Silero | 9.7 | 1 | 12 cores, 2 1080 Ti |
| Tinkoff | 1.4 | 8 | |
| Tinkoff | 2.2 | 1 | |
| Yandex | 5.5 | 2 | 8 — много пустых ответов |
Чем выше RTS, тем лучше.
Поскольку никто не публикует сайзинги облачных и даже иногда коробочных (тут поправьте меня, если пропустил) версий своих систем публично (кстати прошлая версия нашего сайзинга например доступна по ссылке), то довольно сложно оценить адекватность работы систем по ресурсам. Ведь за АПИ может скрываться как одна VDS, так и сотни карт Nvidia Tesla, которыми любят хвастаться корпорации в своих пресс-релизах (что кстати частично подтверждается результатами Сбера — пропускная способность там не падает от роста нагрузки совсем). Расчеты выше не являются заменой полноценным сайзингам.
В защиту нашей системы могу сказать, что за этим бенчмарком стоит довольно слабый сервер конфигурации EX51-SSD-GPU, у которого сейчас есть некоторая фоновая нагрузка и который скорее сейчас оптимизирован на скорость ответа а не на пропускную способность. Еще небольшой тонкий момент состоит в том, что мы считали время каждого запроса и суммировали и поэтому никак не нормализовывали результаты на пинг, но оставим это для следующих исследований.
Вообще меня очень приятно удивили результаты Сбера. На текущих версиях моделей у нас например сайзинг на 12 ядерном процессоре + GPU рассчитан на
150 RTS. По идее это означает, что если мы поднимем тестовый и сервис на 12+ ядрах процессора на чуть более новой карточке, мы должны получить результаты более близкие к Сберу. У нас все равно не получается получить такие же высокие показатели без просадки от нагрузки, но какие-то выводы уже можно строить и получается все равно весьма достойно. Снимаем шляпу перед инженерами Сбера и ставим aspirational цель сделать наш сервис еще в 2-3 раза быстрее.
На цене мы останавливаться особо не будем (большая часть серьезных клиентов все равно не использует облако), но в очередной раз неприятный сюрприз преподнес Гугл выставив круглый счет за смешной (как нам кажется) объем. А ответ прост — зачастую облачные корпоративные сервисы распознавания имеют не только крутой ценник (и в случае Гугла еще и в долларах), но и неочевидные системы округления вверх. В начале своего пути мы тестировали какой-то сервис из Великобритании… который округлял до 60 секунд!

Небольшая ложка дегтя
Довольно приятно, что наш публичный некоммерческий датасет Open STT, неоднократно обсуждавшийся на Хабре, был предвестником релизов публичных данных, например от Сбера. Но долгосрочно все равно хотелось бы видеть хотя бы какую-то соразмерность вклада госкорпораций количеству вложенных в них публичных денег. В сравнении с похожими релизами на западе, мы пока сильно отстаем. Да и Яндекс традиционно не публикует ничего полезного в сфере распознавания речи, интересно почему.
Обновления / ошибки
Я перепутал, второй раз мы тестировали пропускную способность нашего сервиса на 1080 Ti, а не 2080 Ti. Это важно, так как между поколениями сильнее меняется скорость карточек.



