Lighthouse
Lighthouse is an open-source, automated tool for improving the quality of web pages. You can run it against any web page, public or requiring authentication. It has audits for performance, accessibility, progressive web apps, SEO and more.
You can run Lighthouse in Chrome DevTools, from the command line, or as a Node module. You give Lighthouse a URL to audit, it runs a series of audits against the page, and then it generates a report on how well the page did. From there, use the failing audits as indicators on how to improve the page. Each audit has a reference doc explaining why the audit is important, as well as how to fix it.
You can also use Lighthouse CI to prevent regressions on your sites.
Check out the video below from Google I/O 2019 to learn more about how to use and contribute to Lighthouse.
Get started
Choose the Lighthouse workflow that suits you best:
Run Lighthouse in Chrome DevTools
Lighthouse powers the Audits panel of Chrome DevTools. To run a report:
Click the Audits tab.
 Figure 1. To the left is the viewport of the page that will be audited. To the right is the Audits panel of Chrome DevTools, which is now powered by Lighthouse
Figure 1. To the left is the viewport of the page that will be audited. To the right is the Audits panel of Chrome DevTools, which is now powered by Lighthouse
Click Perform an audit. DevTools shows you a list of audit categories. Leave them all enabled.
Click Run audit. After 30 to 60 seconds, Lighthouse gives you a report on the page.
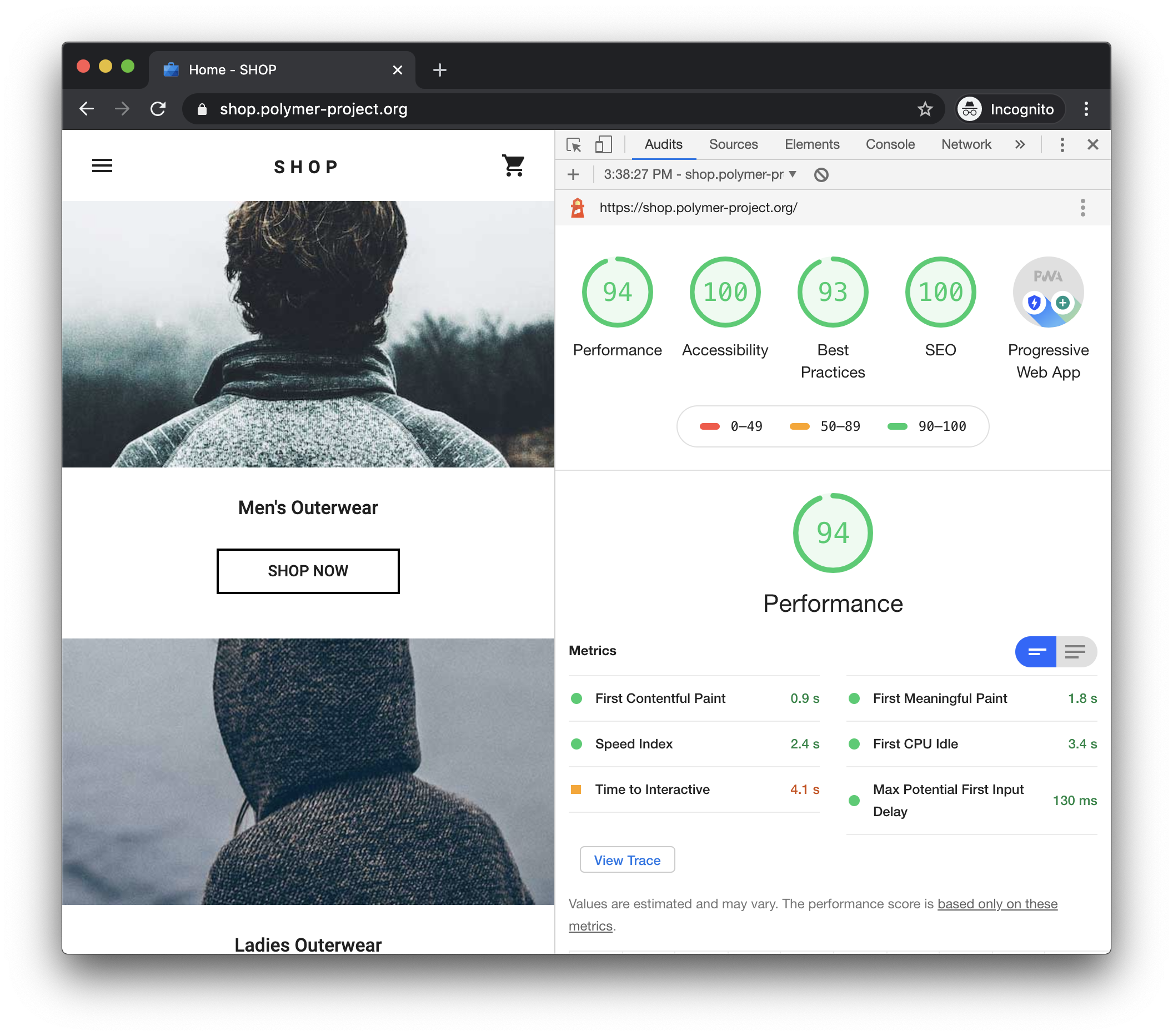 Figure 2. A Lighthouse report in Chrome DevTools
Figure 2. A Lighthouse report in Chrome DevTools
Install and run the Node command line tool
To install the Node module:
To see all the options:
Run the Node module programmatically
See Using programmatically for an example of running Lighthouse programmatically, as a Node module.
Run Lighthouse as a Chrome Extension
To install the extension:
Install the Lighthouse Chrome Extension from the Chrome Webstore.
In Chrome, go to the page you want to audit.
 Figure 3. The Lighthouse menu
Figure 3. The Lighthouse menu
Click Generate report. Lighthouse runs its audits against the currently-focused page, then opens up a new tab with a report of the results.
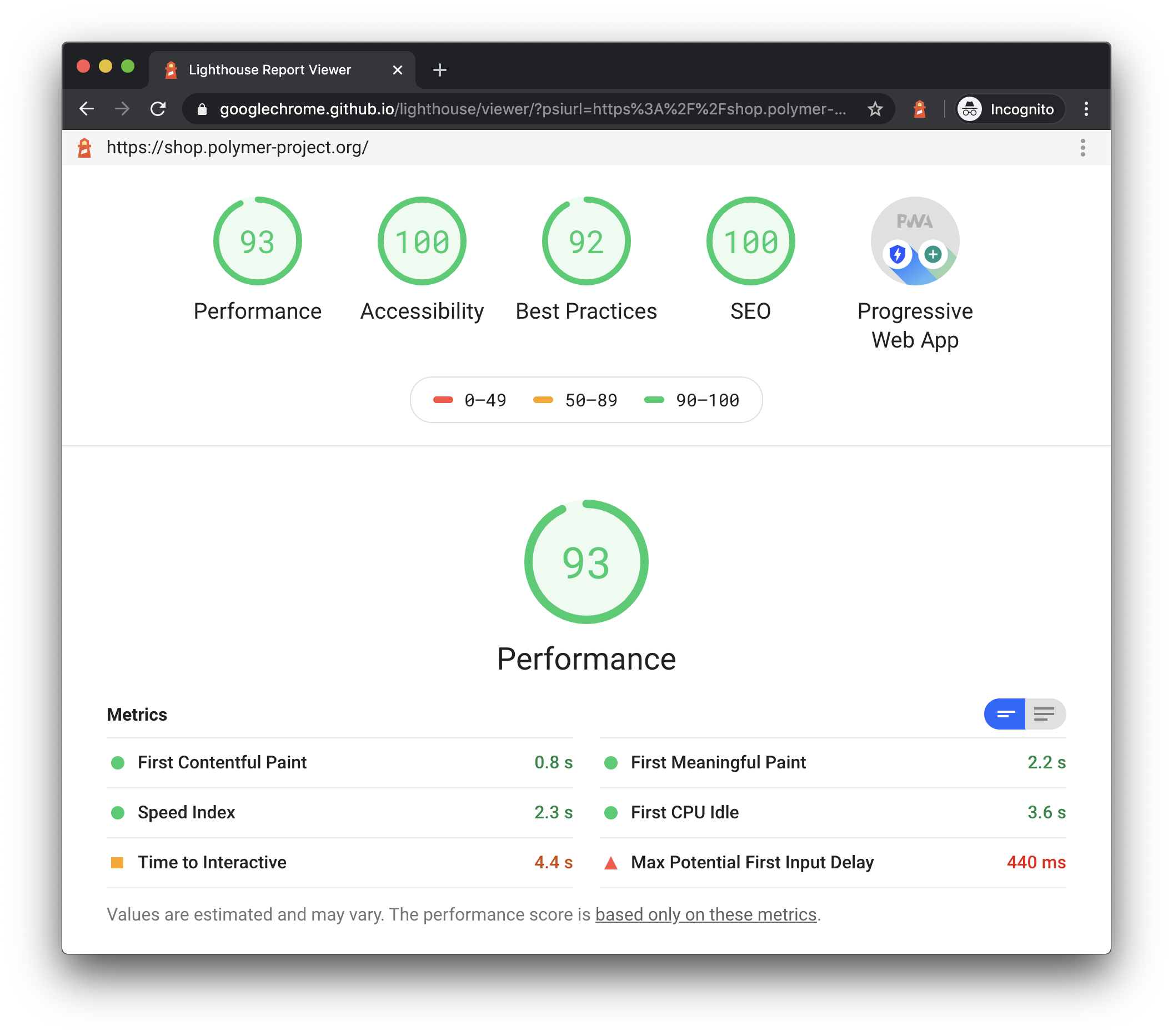 Figure 4. A Lighthouse report
Figure 4. A Lighthouse report
Run PageSpeed Insights
To run Lighthouse on PageSpeed Insights:
Click Analyze.
 Figure 5. The PageSpeed Insights UI
Figure 5. The PageSpeed Insights UI
Share and view reports online
Use the Lighthouse Viewer to view and share reports online.
 Figure 6. The Lighthouse Viewer
Figure 6. The Lighthouse Viewer
Share reports as JSON
The Lighthouse Viewer needs the JSON output of a Lighthouse report. The list below explains how to get the JSON output, depending on what Lighthouse workflow you’re using:
Command line. Run:
Lighthouse Viewer. Click Export > Save as JSON.
To view the report data:
Share reports as GitHub Gists
If you don’t want to manually pass around JSON files, you can also share your reports as secret GitHub Gists. One benefit of Gists is free version control.
To export a report as a Gist from the report:
To view a report that’s been saved as a Gist:
Open the Viewer, and paste the URL of a Gist into it.
Lighthouse extensibility
Lighthouse aims to provide guidance that is relevant and actionable for all web developers. To this end, there are two features now available that allow you to tailor Lighthouse to your specific needs.
Stack Packs allow Lighthouse to detect what platform your site is built on and display specific stack-based recommendations. These recommendations are defined and curated by experts from the community.
To contribute a Stack Pack, review the Contributing Guidelines.
For more information about how to create your own plugin, check out our Plugin Handbook in the Lighthouse GitHub repo.
Integrate Lighthouse
Contribute to Lighthouse
Lighthouse is open source and contributions are welcome. Check out the repository’s issue tracker to find bugs that you can fix, or audits that you can create or improve upon. The issues tracker is also a good place to discuss audit metrics, ideas for new audits, or anything else related to Lighthouse.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Обновление Google Lighthouse: что, зачем и почему
Вовсю разворачивается новый апдейт Google Core Web Vitals, а вебмастера тщательно оттачивают параметры TBT и FCP своих проектов. Тем временем команда Lighthouse выпустила обновление сервиса, где оптимизировала расчет CLS и пересчитала значимость каждого параметра в совокупной оценке производительности сайта.
Подробнее в материале с github о методах расчета параметров производительности, сборе аналитических данных в Lighthouse и CWV, и том, какими сервисами пользоваться для оптимизации сайта под Core Web Vitals.
Напомним о математических расчетах, лежащих в основе показателей Lighthouse и оценки производительности. В Lighthouse v8.0 параметры FCP и TBT оцениваются более строго. Обновили CLS: по-новому вычисляется значение сдвига макета. Кроме того, общая оценка производительности была переформирована — мы придали больше веса факторам CLS и TBT, немного снизили значимость метрик FCP, SI и TTI.
Мы проанализировали около миллиона URL в HTTP Archive и пришли к выводу, что с обновлением Lighthouse 8.0 оценка производительности для большинства сайтов останется такой же или даже улучшится.
20% сайтов — оценка упадет до 5 пунктов и менее.
20% сайтов — оценка Lighthouse изменится незначительно.
30% сайтов — оценка станет лучше на несколько пунктов.
30% сайтов — оценка вырастет на 5 пунктов и более.
Причина падения оценки производительности связана с ужесточением расчета значения TBT и повышением значимости этой метрики в общей доле оценки. В основном улучшения оценок Lighthouse также связаны с изменениями TBT в длительном периоде рендеринга, перерасчетом метрики CLS, а также с повышением значимости обеих метрик в совокупной оценке производительности.
Изменение значимости по метрикам:
Изменение значимости по фазам:
Метрика была представлена в предыдущей версии Lighthouse v6, но была не до конца проработанной. Мы внесли в метрику CLS ряд улучшений и исправлений, в том числе благодаря письмам вебмастеров. Значимость CLS увеличилась с 5% до 15%. Это связано с не только с усовершенствованием формулы расчета оценки, но и с включением метрики в параметры Core Web Vitals.
Почему показатели Core Web Vitals оцениваются по-разному?
Показатели Core Web Vitals являются независимыми сигналами Page Experience. Мы считаем, что при оценке значимости показателей Lighthouse основывается на подходе, который улучшает пользовательское взаимодействие со страницей.
Показатели LCP, CLS и TBT — это три наиболее значимые метрики оценки производительности в Lighthouse и Core Web Vitals.
Core Web Vitals ссылаются на набор ключевых UX-метрик, привязаны к их пороговым значениям и процентилю измерения этих метрик. В целом, CWV фокусируется на данных наблюдений.
*Прим. Данные наблюдений — «полевые данные», сведения в отчете об удобстве пользования браузером Chrome.
Оценка Lighthouse — это средство понимания уровня текущих возможностей для улучшения некоторых элементов UX. Чем ниже оценка, тем выше вероятность, что пользователь столкнется с трудностями при взаимодействии со страницей.
Синтетические (лабораторные) данные Lighthouse частично совпадают с данными Core Web Vitals. В Lighthouse поддерживаются два из трех основных показателей (LCP и CLS) с такими же порогами прохождения при тестировании страницы, как и в Core Web Vitals.
В Lighthouse нет возможности просчитать время от загрузки страницы до первого взаимодействия пользователя со страницей из-за особенностей синтетического сбора данных, поэтому Lighthouse не вычисляет FID, например. Вместо этого в Lighthouse есть TBT, который можно рассматривать как прокси-метрику для FID. Хотя эти два показателя измеряют разные вещи, они оба показывают уровень интерактивности страницы.
Наиболее эффективен комбинированный подход. Используйте данные наблюдений (CWV) для долгосрочного UX-мониторинга и синтетические данные (Lighthouse), чтобы создать наилучший возможный UX-сценарий рендеринга страницы.
CrUX суммирует данные за последние 28 дней, поэтому потребуется терпение и время, чтобы измерить корреляцию между изменениями на сайте и оценкой производительности. Отчеты Lighthouse позволяют отладить и оптимизировать среду, которая воспроизводится с немедленной обратной связью. Кроме того, синтетические инструменты могут предоставить значительно больше критических деталей, чем инструменты наблюдений CrUX, так как они не ограничены лимитами API других веб-ресурсов.
Синтетические данные Lighthouse и данные наблюдений CrUX не совпадают, но любое существенное улучшение синтетических показателей будет заметно и в наблюдениях после обновления. Чем выше оценка Lighthouse, тем меньше потерь в инструменте наблюдений.
Данные наблюдений анализируют все успешные загрузки страниц. Но такой метод сбора информации имеет объективную погрешность в данных, например, в случае с неудачными или прерванными загрузками, при появлении блокирующих расширений на страницах.
Пользователи, у которых был положительный опыт взаимодействия с сайтом, будут чаще его использовать. Поэтому мы в первую очередь заботимся о производительности сайта. Синтетика покажет качество пользовательского взаимодействия с конкретной страницей, в то время как данные наблюдений по ней могут просто отсутствовать.
Мобильные отчеты Lighthouse имитируют слабую 4G-связь на устройствах Android. Такой анализ помогает улучшить взаимодействие с вашим сайтом, когда данные наблюдений не предоставляют таких условий. Lighthouse находит наихудший пользовательский опыт, который нельзя увидеть в данных наблюдений. Это актуально в ситуациях, когда UX-взаимодействие было настолько плохим, что пользователь больше не возвращался на страницу, а значит, не был затрекан для статистики.
Как всегда, наилучшей практикой является использование и синтетических данных, и данных наблюдений в совокупности для понимания и оптимизации взаимодействия сайта с пользователем. Больше информации о наблюдениях и синтетике тут.
Переформирование оценки параметра, скорее всего, не скажется на синтетических измерениях, но сильно повлияет на данные наблюдений по CLS. Lighthouse 8 вводит еще одну корректировку определения CLS: показатель включает сдвиги макета из сабфреймов. Это обобщает наш подсчет CLS с тем, как CrUX вычисляет CLS.
Таким образом, iframe, включая те, что вы не можете контролировать, могут добавлять дополнительные сдвиги макета, а это влияет на оценку CLS. Имейте в виду: вклад сабфреймов измеряется в окне iframe в области просмотра.
Общие черты между TBT (собранному в синтетической среде) и FID (собранному в контексте поля) заключаются в том, что они измеряют влияние на отклик пользовательскому вводу при загрузке длинных задач в основном потоке. В остальном они абсолютно разные. FID измеряет время задержки между пользовательским вводом и откликом браузера. TBT примерно показывает, насколько критична блокировка всех задач основного потока.
Для одной страницы вполне вероятно получить хорошие результаты FID, но при этом плохой показатель TBT. Немного сложнее, но все же возможно, добиться хорошего показателя TBT, но при этом снизить оценку по показателю FID *. Поэтому не думайте, что ваши показатели TBT и FID будут коррелировать. Масштабный анализ показал, что ρ Спирмена — коэффициент ранговой корреляции — составляет около 0,40. Это указывает на связь показателей, но не настолько сильную, насколько бы нам хотелось.
С точки зрения Lighthouse, текущий порог прохождения FID довольно низкий, а процент записи для FID (75-й процентиль) недостаточен для обнаружения проблем. 95-й процентиль — гораздо более сильный индикатор проблемных UX-взаимодействий для этого показателя. Мы рекомендуем вебмастерам, ориентированным на пользователя, сосредоточиться на 95-м процентиль всех задержек пользовательского ввода, а не только на первом вводе, чтобы своевременно выявлять и решать проблемы, которые возникают только в 5% случаев.
* Кроме того: изменение FID Chrome 91 для double-tap-to-zoom (двойной клик для увеличения объекта) фиксит множество случаев с «высоким FID/низким TBT» и может быть обнаружено в показателях данных наблюдений по страницам.
Большинство случаев с «высоким FID/низким TBT», вероятно, связано с неправильными метатегами viewport, которые Lighthouse отмечает в отчете. Настройка viewport для мобильных устройств, минимизация JS, блокирующего основной поток, поддержание низкого значения TBT — это основные задачи для улучшения FID в данных наблюдений.
Изменения во всех обновлениях оценок Lighthouse нужны, чтобы показать, как улучшилось UX-качество страниц. Также они помогают сфокусировать взгляд на ключевых приоритетах.
Тяжеловесный JS и длинные задачи — усугубляющаяся проблема. Наблюдаемый FID — слишком мягкая метрика, которая не решает проблему глобально. Lighthouse исторически оценивал свои показатели интерактивности на уровне 40–55% от оценки производительности, а поскольку интерактивность является ключом к UX, мы поддерживаем вес 40% (TBT и TTI вместе) и в Lighthouse 8.0.
Кривая оценки FCP была скорректирована для соответствия текущему фактическому «хорошему» порогу, в результате чего оценка стала более строгой. Кривую TBT сделали более жесткой, чтобы приблизиться к кривой идеальной оценки. У TBT была, и до сих пор остается, более плавная кривая, что диктуется нашей методологией. Но новая кривая более линейна, поэтому улучшение метрики положительно повлияет на оценку производительности. Новая кривая графика будет заметно изменяться, если постепенно улучшать производительность страницы. Вес FCP снизился с 15% до 10%, потому что он учитывается индексом скорости только частично.
TTI крайне полезен, поскольку это самый крупный анализируемый показатель, часто свыше 10 секунд.
И все же мы видим TBT как более надежный показатель оценки работоспособности основного потока и его влияния на интерактивность, к тому же он имеет небольшую изменчивость. TTI анализирует выполнение длительных задач, часто связанных с тяжеловесным JavaScript. Тем не менее мы продолжим снижать значимость TTI и, вероятно, удалим его в будущем обновлении Lighthouse.
Оценка производительности Lighthouse рассчитывается на основе значимости всего набора показателей производительности. Вы можете посмотреть текущие и предыдущие оценки и значимость параметров Lighthouse в калькуляторе оценок, а также узнать больше о специфике расчета оценок здесь.
Нам очень нравится интерактивная древовидная карта, сортировка аудитов по метрикам и новый аудит политики безопасности контента, который был разработан совместно с командой Google Web Security.
Автор перевода Group Head команды RACURS Лилия Граевская.
Как собрать свой Lighthouse
Чем интенсивнее наш feature delivering, тем быстрее падает производительность. И, конечно, приходит время автоматизировать процесс слежения, чтобы просадка не дошла до прода или даже staging-окружения.
Про прод-мониторинг, оптимизацию и ручной анализ производительности легко узнать на web.dev. Но по автоматизации слежения за производительностью до того, как фичи покатятся в прод, информации не так уж много. Сегодня расскажу, как для профилирования собрать практически свой Lighthouse, чтобы проводить performance-тесты и успешно бороться с просадкой в работе команды фронтендеров.

Мы, как разработчики, начинаем что-то профилировать чаще всего несистемно — когда что-то совсем затормозит на проде или кто-то подсветит проблему. Мы берем чашечку кофе и открываем трейсинг. Потому что это первый инструмент, который приходит в голову. Может быть ещё вспомним про Lighthouse, но в любом случае мы пытаемся понять, что там на странице происходит.
В трейсинге мы видим много фреймов, еще больше запрашиваемых ресурсов, какие-то другие интересные штуки. И если мы смотрим на это раз в месяц, то всё это каждый раз новое — как с этим работать, пока непонятно.
Но если мы занимаемся этим регулярно, то постепенно у нас складывается «джентльменский набор»:
В первую очередь, это, конечно, вкладка Performance, которая показывает подробный анализ того, что у нас на странице происходит.
Потом добавляются bundle-анализаторы, чтобы посмотреть, что у нас содержится в ресурсах и из чего они состоят.
Еще мы можем добавить DevTools CPU Profile, чтобы понять, насколько быстро выполняется JS — и в подробностях ознакомиться с временем выполнения кода.
И напоследок — Lighthouse или Google PageSpeed Insight в качестве overview по метрикам.
Со временем это всё превращается в стандартный flow, и мы начинаем что-то оптимизировать — и добиваемся, скажем, ускорения по какой-то ключевой метрике на целых 30%. Но вдруг происходит деплой тридцати фич — каждый разработчик добавил по одному MPM-модулю весом в 500 килобайт. И наша метрика возвращается на исходную или даже ухудшается.

Решить эту ситуацию можно с помощью профилирования сразу после разработки. Но мало какой разработчик согласится заниматься профилированием сразу после написания кода: это занимает достаточно много времени, при этом сложно понять, что конкретно поменялось и что конкретно из правок повлияло на производительность.
Но можно автоматизировать этот процесс, чтобы не затормозился или не остановился feature-delivering. После отправки pull request’а можно сразу собрать всю нужную информацию для оптимизации, устранить причину ухудшения производительности, если она есть, а после этого — задеплоить уже качественный код.
Но что мы можем использовать для автоматизированного профилирования?
Lighthouse и Lighthouse-ci
Lighthouse — это хороший инструмент, с его помощью вы получите классные отчеты с информацией по всем ключевым метрикам, и даже вполне понятные советы по оптимизациям. Все его User-centric метрики из коробки всегда актуальные, потому что Google следит за этим. Его можно встроить в CI/CD — есть пакет, который основан на Puppeteer — и получать все нужные данные в JSON или даже в виде HTML-отчетов.
Но есть и существенные минусы. Во-первых, у него вечно разные результаты — даже если вы будете прогонять один замер огромное количество раз, будет довольно высокий разброс. А советы Lighthouse хоть и дает, но очень общие — что какой-то ресурс очень плох и его надо как-то вырезать. При этом вместо его имени вы видите хэш, и что в нем содержится — абсолютно непонятно.
Второй минус — его сложно масштабировать и добавлять в него новый функционал. Если вы захотите написать какой-то сценарий, чтобы проанализировать что-то более глубоко, встроив код на страницу при профилировании, то у вас это не получится. У него есть, конечно, система плагинов, которая позволяет вам анализировать трейсинги и вычленять оттуда дополнительные метрики, но на этом всё.
Ещё ему нужен Performance-бюджет — особенно если вы попытаетесь встроить его в CI. При этом он измеряет только загрузку страницы. Из коробки у него нет ретроспективы, то есть вы постоянно рассматриваете ситуацию в режиме настоящего времени, не представляя, какие показатели были раньше и что вообще на них повлияло. В Lighthouse-ci есть чуть более продвинутая тема по сравнению замеров различных ревизий между собой, но в Lighthouse ее нет совсем.
Даже если вы встроите Lighthouse в CI, всё равно придется запускать профайлер и webpack-bundle-analyzer, чтобы основательно разобраться в том, что влияет на производительность. То есть мы снова вернулись к ручному анализу:

Как мы можем это переоформить, чтобы вместо постоянного и довольно сложного flow у нас было время для более полезных вещей? Во-первых, стоит всё-таки отказаться от Lighthouse, потому что загрузка страницы — это не единственный показатель перфоманса, за которым стоит следить. Несмотря на то, что Google таргетит на него, у нас есть, например, SPA. А каждый второй сайт имеет какую-то динамику в своей основе — и за этим тоже нужно следить.
Как собрать свой Lighthouse
Вместо Lighthouse прекрасно работает Puppeteer — это Chrome, но без головы. На нем можно писать функциональные тесты, и там есть CDP — Chrome DevTools Protocol. Это программный интерфейс к DevTools — самая важная его часть, которая позволит нам сделать из него всё что угодно. Для нас будут полезными Tracing, Network, Emulation и Coverage:
Tracing даст нам записи тех тайм-лайнов, которые мы видим во вкладке Perfomance.
Network — это эмуляция сети для троттлинга, обработчиков запросов, и так далее.
Emulation — это эмуляция непосредственно в viewport девайса, который мы хотим замерить.
Coverage — это выполнение кода на странице, чтобы понять, какой код у нас на странице выполнялся, а какой — нет.
Профайлер из Chrome DevTools можно заменить на некий эвристический велосипед, а bundle analyzer — на простой JSON, который можно сортировать по определенным критериям и предоставлять разработчику. В результате получим triforce, который будет решать проблемы профилирования для разработчиков.
Покажу, как мы можем собрать наш Lighthouse.
Пишем профайлер
Что нам нужно для этого от Puppeteer? User-centric метрики из Lighthouse. Navigation timing, чтобы иметь представление о том, когда у нас какие ресурсы загрузились, на каком timestamp’е находилась страница и прочие детали. Данные о выполнении скриптов, чтобы, например, подсчитать Time to Interactive или просто понимать, что у нас на странице выполнялось. И данные о содержимом ресурсов, тех же чанков.
Для получения данных нужно достучаться до CDP через Puppeteer. Откроем страницу в браузере и поднимем CDP-сессию. И дальше мы сможем с ней общаться с помощью метода send, отправляя функции на выполнение и получая результат.
И попробуем сразу собрать трейсинги. Настраиваем окружение, которое нам позволит нормализовать сеть, сделать ее Fast 3G, затроттлить CPU и сделать окружение, которое будет троттлить всю страницу и показывать результаты для среднестатистического пользователя. Для записи трейсингов у Puppeteer есть встроенные методы, которые перенаправляют вызов метода в CDP. Перейдя на страницу, можно получить этот трейсинг в строковом формате, и запарсить его.
В результате получится масштабный JSON, своего рода Big Data для фронтенда. Его структура данных — это Trace Events. Она используется не только на фронтенде, а также в ядре Linux и Android для одного и того же — построения трейсингов, тайм-лайнов, где видно, что у вас происходило. Но из документации по этому формату есть только общие описания того, что в нем может быть. Они находятся в проекте Catapult-project на GitHub — у них, кстати, очень много тулзов, которые помогают измерять производительность.
В этом формате нам пригодятся 4 основных свойства. В первую очередь это args — полезная нагрузка, где содержатся какие-то произвольные объекты и структуры данных. Они коррелируются с именем события. Далее, это ph — фаза, которая описывает тип события в этом трейсинге. Из ключевых событий — Duration Events, Complete Events и Mark Events. Duration event связан с событиями begin и end, а Mark Events — это отметки на тайм-лайне с time stamps. Последние нам нужны, чтобы как-то скоординировать этот event и понять, когда он происходил.
В принципе этого всего достаточно, чтобы запарсить все события и собрать нужную нам информацию.
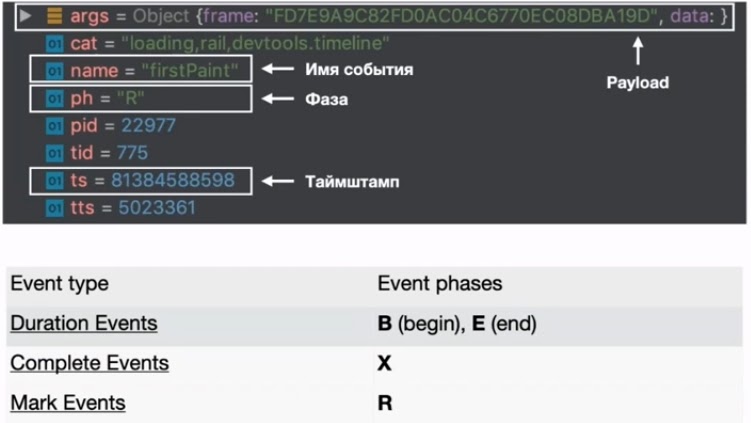
Категория (cat) будет нужна, чтобы отфильтровать событие по какому-то критерию. Например, вам нужны только user-timing. Или понять, какие вообще категории есть у вас в этом трейсинге.
На какие события мы будем смотреть?
Там их порядка 200, но актуальными для перфоманса можно назвать, например, Meaningful-отрисовки, Contentful Paint, Navigation timings и тому подобные штуки. Вот список тех, что использую я:

Нам также будет нужна точка отправки, т.е. с какого момента начала загружаться страница и соответственно — наш парсинг. Для этого найдем в массиве событие с name == responseStart и получим его timestamp.
Выполняем скрипты
Теперь фильтруем весь массив событий по какому-то имени, например, EvaluateScript, и получаем сразу все нужные нам значения: время выполнения скрипта, время начала его выполнения и адрес ресурса.
Дополнительно есть еще другие события, которые описывают отправку запросов, обработчики XML Http Requests, срабатывания таймеров, Request Animation Frame. В принципе, всё, что хотите, можно намайнить в трейсингах и предоставить разработчику. Все события можно найти здесь.
Нам также полезно понимать, какой объем от конкретного ресурса выполнялся. Сделать это можно с помощью Coverage. Достаточно вызвать у страницы метод записи коверейджа и после этого остановить запись, в тот момент, который вы посчитаете нужным. И можем подсчитать в абсолютном или относительном значении объем кода, который у нас выполнялся.
В итоге у нас есть сырые данные по использованию кода и их можно прицепить к уже имеющейся информации по содержимому чанков. Это уже позволит оптимизировать ваш сайт и детектировать, где что прибавляется или убавляется.
Внутри данных больше всего нам интересен массив с промежутками кода, который выполнялся в конкретном файле. Из этой инфы можно получить уже относительные значения в сравнении с длиной файла. Можно даже использовать эти данные вкупе с сорс-мапами и получить точную информацию о том, что использовалось в автоматическом режиме.
Теперь, чтобы понять, когда загружались конкретные ресурсы, смотрим сеть.
Анализируем сеть
Для этого смотрим четыре связанных с помощью payload события — ResourceSendRequest, ResourceReceiveResponse, ResourceReceivedData и ResourceFinish — и возьмем от них timestamp’ы. Их можно организовать в мапу со всеми события, которые там есть и привязаны к конкретному запросу.
Вместе с этим можно получить все имеющиеся на странице вызовы User TIming API: просто профильтровать массив по категории blink.user_timing. В Lighthouse они отображаются в отчете. Размещаем на странице User Timing, то есть выполняем performance.mark. И найдя в трейсинге событие с таким именем, получаем time stamp.
Получаем User TIming API
После этого соберем описание каждого запроса, где будет всё, что нам нужно — размер ресурса, время начала его загрузки и конца загрузки, получения первого байта и так далее.
Оставшиеся события из трейсинга можно собрать в мапу с помощью find — это firstPaint и подобные штуки.
Собираем оставшиеся события
Опции, которых не хватает в Lighthouse
SPA-сценарии
В первую очередь в Lighthouse не хватает функциональных тестов для замеров — например, переходов по роутингу или открытий поп-ап. Каждому разработчику стоит задуматься, насколько у него быстро открываются странички в режиме SPA и какие-то попапы. В Puppeteer это очень легко сделать, есть много методов, которые позволяют манипулировать страницей. Например, click и waitForSelector, которые позволяют на что-то кликнуть и дождаться появления селектора.
Помимо этого можно добавить обвязку из записи трейсинга и коверейджа и получить более подробную информацию об этих операциях: запись сети, выполнение скриптов, которое уже происходило в этой итерации, и коверейдж. А потом их дополнительно проанализировать на предмет, что у вас происходило в процессе SPA-шного перехода или загрузки попап.
Содержимое чанков
Оно нужно для понимания того, что у вас вообще там содержится и что стоит выпиливать. Когда мы используем бандлеры — webpack, rollup или parcel, они преобразуют исходники в обезличенные наборы чанков, которые скрываются под хэшами. Это не дает нам представления об их содержимом.
Мне же хотелось получить некую мапу, которая бы нам говорила, какой чанк соответствует какому набору модулей. Тут можно использовать webpack, который поставляет статы с описанием всего, что транспилировалось и бандлеризировалось. Мы получим JSON, который весит порядка 100 мегабайт, но его сложно анализировать.
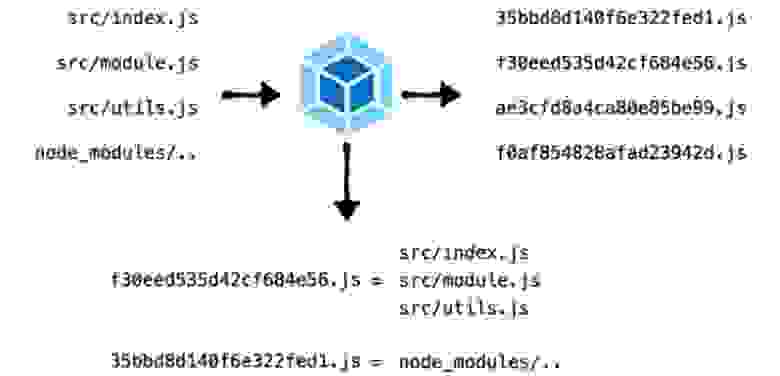
Поэтому мой коллега, Сергей Милюков, создал вариант лучше. Его плагин помогает собирать более лаконичные данные о том, что содержится в сгенерированных ресурсах. Там есть input и output. В input содержатся модули, которые участвуют в сборке, в output — все чанки на выходе. Это удобно читать в JSON даже глазами, а анализировать с помощью JS — тем более.
Что-то сверху — Script Injection
В Puppeteer, в отличие от Lighthouse, можно встраивать дополнительные скрипты на страницу, выполняя какой-то дополнительный код. Можно манипулировать страницей, обращаться к ней и что-то на ней выполнять перед загрузкой страницы, после чего грузятся уже ваши данные. Также можно добавлять скрипт-теги, например, npm-пакет сразу на страницу в процессе профилирования.
Или можно дождаться получения Boolean результата. Этот метод возвращает promise, который разрезолвится, когда эта, переданная в качестве аргумента, функция вернет его.
Это всё можно применить к очень крутой вещи — Element Timing API. Собрав их с помощью performance observer, можно выполнить этот код сразу перед загрузкой страницы. После этого переходим на страницу, которую хотим замерить, и получаем наши Element timing’s, выполнив просто evaluate. Мы получим еще данные для анализа.
Получаем Element timing’s
Есть нюансы. Аргументы нужно передавать и в коллбэк, и методу evaluate или остальным. И весь код, который работает в коллбэках, будет выполнен в области видимости вашей страницы.
Итак, мы собрали свой Lighthouse со всеми особенностями, которые нам нужны. Мы уже можем это использовать для мониторинга производительности. Правда, это даст вам только наблюдение за циферками.
Чтобы получить профит, обнаружив ухудшение производительности, нужно применить всё это в Performance-тестах. Об этом я расскажу в следующий раз.
11-12 октября встречаемся в Москве на FrontendConf 2021. Программа составлена, расписание опубликовано. Все подробности на сайте.
Не так давно Глеб Михеев, глава ПК, рассказал про подготовку к конференции и доклады, которые его заинтересовали, пока ПК проводил отбор.



