GitLab CI для непрерывной интеграции и доставки в production. Часть 1: наш пайплайн

Итак, GitLab CI: что можно ещё рассказать о нём? На хабре уже есть статьи про установку, про настройку раннеров, про командное использование, про GitLab Flow. Пожалуй, не хватает описаний того, как используется GitLab CI в реальном проекте, где задействовано несколько команд. А в современном мире разработки ПО это действительно так: ведь есть (как минимум) разработчики, тестировщики, DevOps- и релиз-инженеры. С подобным разделением на команды мы работаем уже несколько лет. В этой статье я расскажу о том, как мы, используя и улучшая возможности GitLab CI, реализовали и применяем в production для коллектива из нескольких команд процессы непрерывной интеграции (CI) и отчасти доставки приложений (CD).
Наш пайплайн
Если вы сталкивались с CI-системами ранее, то понятие пайплайна вам знакомо — это последовательность выполнения стадий (здесь и далее в статье для термина stage использую перевод «стадия»), каждая из которых включает несколько задач (здесь и далее в статье job — «задача»). От момента внесения изменений в код до выката в production приложение по очереди оказывается в руках разных команд — подобному тому, как это происходит на конвейере. Отсюда и возник термин pipeline («конвейер» — один из вариантов дословного перевода). В нашем случае это выглядит так:
Краткие пояснения по используемым стадиям:
Как это используется?
Начну с рассказа о пайплайне с точки зрения его использования — то, что можно назвать user story. Тут выяснится, что на самом деле пайплайна у нас даже два: укороченный для веток и полноценный для тегов. И вот как выглядят эти последовательности:
Пайплайн и стадии в деталях
Задачи на стадии build собирают приложение. Для этого мы используем свою разработку — Open Source-утилиту dapp (о её основных возможностях читайте и смотрите в этой статье + видео), которая хорошо ускоряет инкрементальную сборку. Поэтому сборка запускается автоматически для веток с префиксами feature_ (код приложения), infra_ (код инфраструктуры) и тегов, а не только для нескольких традиционно «главных» веток (master/develop/production/release).
Обновлено 06 сентября 2019 г.: в настоящее время проект dapp переименован в werf, его код переписан на Go, а документация значительно улучшена.
Следующая стадия — staging — это набор сред для разработчиков, DevOps-инженеров и тестировщиков. Здесь объявлено несколько задач, разворачивающих приложения из веток с префиксами feature_ и infra_ в урезанных средах для быстрого тестирования новой функциональности или инфраструктурных изменений (код сборки приложения хранится в репозитории приложения).
Стадии pre-production и production доступны только для тегов. Обычно тег вешается после того, как релиз-инженеры принимают несколько merge-запросов из протестированных веток. В целом можно сказать, что мы используем GitLab Flow с тем лишь отличием, что нет автоматического развёртывания на production и потому нет отдельных веток, а используются теги.
Стадия approve — это две задачи: approve и not approve. Первая включает возможность развёртывания на production, вторая — выключает. Эти задачи существуют для того, чтобы в случае проблем на production было видно, что развёртывание происходило не просто так, а с согласия релиз-инженера. Однако суть не в лишении кого-то премии, а в том, что непосредственно развёртывание на production проводит зачастую не сам релиз-инженер, а команда DevOps. Релиз-инженер, запуская задачу approve, разрешает тем самым «нажать на кнопку» deploy to production команде DevOps. Можно сказать, что эта стадия выносит на поверхность то, что могло бы остаться в почтовой переписке или в устной форме.
Такая схема взаимодействия хорошо себя показала в работе, однако пришлось потрудиться, чтобы реализовать её. Как оказалось, GitLab CI не поддерживает из коробки некоторые нужные вещи…
Всё довольно просто и скорее всего понятно. Для каждой задачи используются следующие директивы:
Он демонстрирует возможность формата YAML определять общие блоки и подключать их в нужное место на нужном уровне. Подробнее см. в документации.
Таким образом, задачи на стадиях build, testing, staging, pre-production, которые должны быть доступны для веток infra_, feature_ и тегов, принимают следующий вид:
А задачи на стадиях approve и production, которые доступны только для тегов, имеют такой вид:
Что дальше?
Полная реализация задуманного стала возможной только благодаря нескольким патчам к GitLab и использованию артефактов задач. Подробнее об этом читайте в следующей части статьи: «GitLab CI для непрерывной интеграции и доставки в production. Часть 2: преодолевая трудности».
Customize pipeline configuration
You can customize how pipelines run for your project.
Change which users can view your pipelines
Auto-cancel redundant pipelines
Use the interruptible keyword to indicate if a running job can be cancelled before it completes.
Skip outdated deployment jobs
Your project may have multiple concurrent deployment jobs that are scheduled to run in the same time frame.
This can lead to a situation where an older deployment job runs after a newer one, which may not be what you want.
Older deployment jobs are skipped when a new deployment starts.
For more information, see Deployment safety.
Retry outdated jobs
A deployment job can fail because a newer one has run. If you retry the failed deployment job, the environment could be overwritten with older source code. If you click Retry, a modal warns you about this and asks for confirmation.
For more information, see Deployment safety.
Specify a custom CI/CD configuration file
Custom CI/CD configuration file examples
Then other users and projects can access the configuration file without being able to edit it.
Choose the default Git strategy
Limit the number of changes fetched during clone
Set a limit for how long jobs can run
Jobs that exceed the timeout are marked as failed.
You can override this value for individual runners.
Add test coverage results to a merge request
You can use https://rubular.com to test your regex. The regex returns the last match found in the output.
If the pipeline succeeds, the coverage is shown in the merge request widget and in the jobs table. If multiple jobs in the pipeline have coverage reports, they are averaged.


Test coverage examples
Use this regex for commonly used test tools.
View code coverage history
The historic data for each job is listed in the dropdown above the graph.

Coverage check approval rule
You can implement merge request approvals to require approval by selected users or a group when merging a merge request would cause the project’s test coverage to decline.

Remove color codes from code coverage
Some test coverage tools output with ANSI color codes that aren’t parsed correctly by the regular expression. This causes coverage parsing to fail.
Some coverage tools don’t provide an option to disable color codes in the output. If so, pipe the output of the coverage tool through a small one line script that strips the color codes off.
Pipeline badges
Pipeline badges indicate the pipeline status and a test coverage value for your project. These badges are determined by the latest successful pipeline.
View the code for the pipeline status and coverage reports badges

Pipeline status badge
You can access a pipeline status badge image by using the following link:
Display only non-skipped status
Test coverage report badge
You can define the regular expression for the coverage report that each job log is matched against. This means that each job in the pipeline can have the test coverage percentage value defined.
To access the test coverage badge, use the following link:
To get the coverage report from a specific job, add the job=coverage_job_name parameter to the URL. For example, the following Markdown code embeds the test coverage report badge of the coverage job in your README.md :
Test coverage report badge colors and limits
Badge styles
Pipeline badges can be rendered in different styles by adding the style=style_name parameter to the URL. Two styles are available:

Flat square (Introduced in GitLab 11.8):
Custom badge text
The text for a badge can be customized to differentiate between multiple coverage jobs that run in the same pipeline. Customize the badge text and width by adding the key_text=custom_text and key_width=custom_key_width parameters to the URL:
Автозагрузка приложения при помощи Gitlab: готовые решения Penguin-team для небольших компаний


Минимум слов. Максимум дела.
В одном письме в месяц
7-дневный курс по Google Ads (Junior+)
По сути, это набор готовых решений, который подойдет для небольших компаний. И если вы обычно не используете некоторые технологии из-за их сложности или громоздкости, этот текст — для вас.
CI/CD — это концепция непрерывной интеграции и доставки. Она реализуется как конвейер, облегчая слияние только что закомиченного кода в основную кодовую базу.
Это основа наших тестирований. Она позволяет запускать различные типы тестов на каждом этапе (выполнение интеграционного аспекта) и завершать их запуском с развертыванием закомиченного кода в фактический продукт, который видят конечные пользователи (выполнение доставки ).
CI/CD необходима для разработки программного обеспечения по Agile-методологии, которая рекомендует использовать автоматическое тестирование для быстрой наладки рабочего ПО. Автоматическое тестирование дает заинтересованным лицам доступ к вновь созданным функциям и обеспечивает быструю обратную связь.
Сервисы в помощь
Мы в работе используем Gitlab. У него есть 2000 минут в месяц для использования процесса непрерывной интеграции кода и возможность создавать гибкую структуру проектов, групп и подгрупп для разграничения доступа команд к разным проектам. Эти два преимущества сыграли решающую роль при выборе для нас.
Далее я приведу 2 реальных примера из собственной практики. Они работают на наших проектах — и позволят загружать приложения различной сложности и структуры на сервер вам.
CI/CD pipelines
Pipelines are the top-level component of continuous integration, delivery, and deployment.
Jobs are executed by runners. Multiple jobs in the same stage are executed in parallel, if there are enough concurrent runners.
If all jobs in a stage succeed, the pipeline moves on to the next stage.
If any job in a stage fails, the next stage is not (usually) executed and the pipeline ends early.
In general, pipelines are executed automatically and require no intervention once created. However, there are also times when you can manually interact with a pipeline.
Types of pipelines
Configure a pipeline
For a list of configuration options in the CI pipeline file, see the GitLab CI/CD Pipeline Configuration Reference.
Ref specs for runners
When a runner picks a pipeline job, GitLab provides that job’s metadata. This includes the Git refspecs, which indicate which ref (branch, tag, and so on) and commit (SHA1) are checked out from your project repository.
This table lists the refspecs injected for each pipeline type:
| Pipeline type | Refspecs |
|---|---|
| pipeline for branches | + :refs/pipelines/ and +refs/heads/ :refs/remotes/origin/ |
| pipeline for tags | + :refs/pipelines/ and +refs/tags/ :refs/tags/ |
| pipeline for merge requests | + :refs/pipelines/ |
The refs refs/heads/ and refs/tags/ exist in your project repository. GitLab generates the special ref refs/pipelines/ during a running pipeline job. This ref can be created even after the associated branch or tag has been deleted. It’s therefore useful in some features such as automatically stopping an environment, and merge trains that might run pipelines after branch deletion.
View pipelines
You can find the current and historical pipeline runs under your project’s CI/CD > Pipelines page. You can also access pipelines for a merge request by navigating to its Pipelines tab.

Click a pipeline to open the Pipeline Details page and show the jobs that were run for that pipeline. From here you can cancel a running pipeline, retry jobs on a failed pipeline, or delete a pipeline.
Starting in GitLab 14.2, you can change the pipeline column to display the pipeline ID or the pipeline IID.
If you use VS Code to edit your GitLab CI/CD configuration, the GitLab Workflow VS Code extension helps you validate your configuration and view your pipeline status.
Run a pipeline manually
Pipelines can be manually executed, with predefined or manually-specified variables.
You might do this if the results of a pipeline (for example, a code build) are required outside the normal operation of the pipeline.
The pipeline now executes the jobs as configured.
Prefill variables in manual pipelines
You can use the value and description keywords to define pipeline-level (global) variables that are prefilled when running a pipeline manually.
The description is displayed next to the variable. It can be used to explain what the variable is used for, what the acceptable values are, and so on:
You cannot set job-level variables to be pre-filled when you run a pipeline manually.
Run a pipeline by using a URL query string
The format of the pipelines/new URL is:
Add manual interaction to your pipeline
Manual jobs, allow you to require manual interaction before moving forward in the pipeline.
You can do this straight from the pipeline graph. Just click the play button to execute that particular job.
For example, your pipeline can start automatically, but require a manual action to deploy to production. In the example below, the production stage has a job with a manual action:
Start multiple manual actions in a stage
Multiple manual actions in a single stage can be started at the same time using the “Play all manual” button. After you click this button, each individual manual action is triggered and refreshed to an updated status.
Skip a pipeline
Alternatively, if you are using Git 2.10 or later, use the ci.skip Git push option. The ci.skip push option does not skip merge request pipelines.
Delete a pipeline
Users with the Owner role in a project can delete a pipeline by clicking on the pipeline in the CI/CD > Pipelines to get to the Pipeline Details page, then using the Delete button.

Pipeline quotas
Each user has a personal pipeline quota that tracks the usage of shared runners in all personal projects. Each group has a usage quota that tracks the usage of shared runners for all projects created within the group.
When a pipeline is triggered, regardless of who triggered it, the pipeline quota for the project owner’s namespace is used. In this case, the namespace can be the user or group that owns the project.
How pipeline duration is calculated
Total running time for a given pipeline excludes retries and pending (queued) time.
Visually, it can be viewed as:
The union of A, B, and C is (1, 4) and (6, 7). Therefore, the total running time is:
How pipeline quota usage is calculated
Pipeline quota usage is calculated as the sum of the duration of each individual job. This is slightly different to how pipeline duration is calculated. Pipeline quota usage doesn’t consider any overlap of jobs running in parallel.
The pipeline quota usage is the sum of each job’s duration. In this example, 8 runner minutes would be used, calculated as: 3 + 3 + 2.
Pipeline security on protected branches
A strict security model is enforced when pipelines are executed on protected branches.
Variables marked as protected are accessible only to jobs that run on protected branches, preventing untrusted users getting unintended access to sensitive information like deployment credentials and tokens.
Runners marked as protected can run jobs only on protected branches, preventing untrusted code from executing on the protected runner and preserving deployment keys and other credentials from being unintentionally accessed. In order to ensure that jobs intended to be executed on protected runners do not use regular runners, they must be tagged accordingly.
Visualize pipelines
Pipelines can be complex structures with many sequential and parallel jobs.
To make it easier to understand the flow of a pipeline, GitLab has pipeline graphs for viewing pipelines and their statuses.
Pipeline graphs can be displayed as a large graph or a miniature representation, depending on the page you access the graph from.
GitLab capitalizes the stages’ names in the pipeline graphs.
View full pipeline graph
The pipeline details page displays the full pipeline graph of all the jobs in the pipeline.
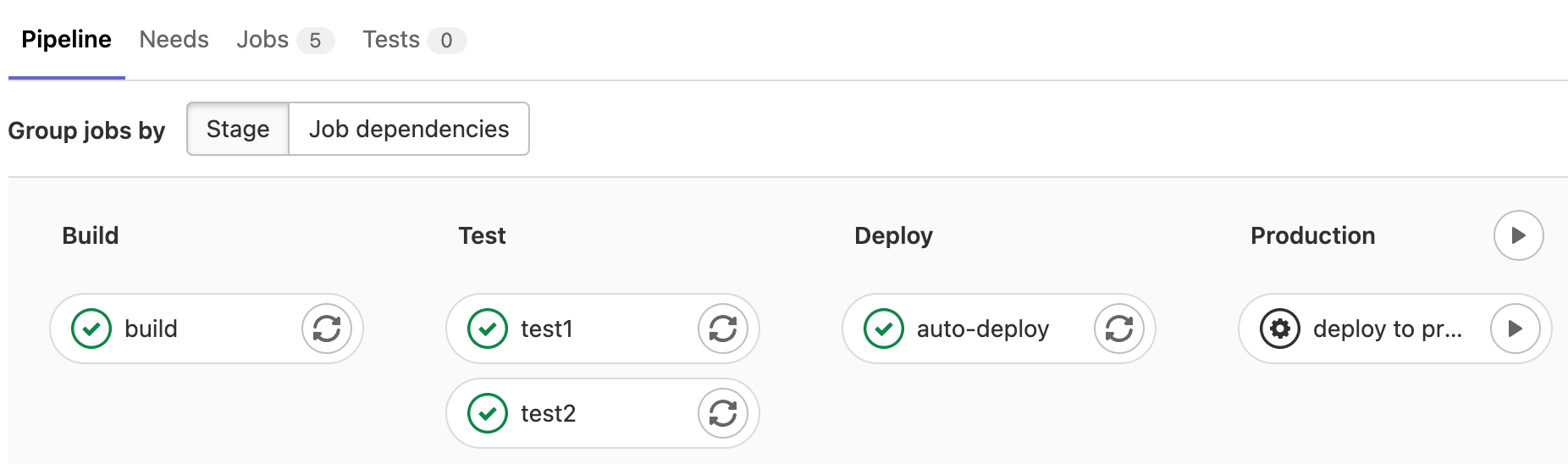
You can group the jobs by:
Stage, which arranges jobs in the same stage together in the same column:

Job dependencies, which arranges jobs based on their needs dependencies.
Multi-project pipeline graphs help you visualize the entire pipeline, including all cross-project inter-dependencies.
View job dependencies in the pipeline graph
You can arrange jobs in the pipeline graph based on their needs dependencies.
Jobs in the leftmost column run first, and jobs that depend on them are grouped in the next columns.
For example, test-job1 depends only on jobs in the first column, so it displays in the second column from the left. deploy-job1 depends on jobs in both the first and second column and displays in the third column:

To add lines that show the needs relationships between jobs, select the Show dependencies toggle. These lines are similar to the needs visualization:

To see the full needs dependency tree for a job, hover over it:

Pipeline mini graphs
Pipeline mini graphs allow you to see all related jobs for a single commit and the net result of each stage of your pipeline. This allows you to quickly see what failed and fix it.
Pipeline mini graphs only display jobs by stage.
Stages in pipeline mini graphs are collapsible. Hover your mouse over them and click to expand their jobs.
| Mini graph | Mini graph expanded |
|---|---|
 |  |
Pipeline success and duration charts
Pipeline analytics are available on the CI/CD Analytics page.
Pipeline badges
Pipeline status and test coverage report badges are available and configurable for each project. For information on adding pipeline badges to projects, see Pipeline badges.
Pipelines API
Как настроить непрерывную интеграцию на GitLab с помощью Docker

Раньше, возможно, вы уже пытались использовать различные программы и инструменты для эффективного развертывания приложений. В этой статье я покажу вам быстрый и простой способ настройки непрерывной интеграции для вашей среды с помощью GitLab и Docker. Так давайте приступим!
Список того, на что мы обратим внимание:
Jenkins, неплохо справляется с непрерывной интеграцией и выдачей. Mantisотлично справляется с отслеживанием возможных проблем. Однако, для достижения большей эффективности и качества нашего проекта нам необходимо объединить эти инструменты. Например, в будущем нам может понадобиться, чтобы git-commit напрямую подключался к уже существующим проблемам или запускал автоматизированное тестирование, после обновления коммитов главной ветви.
Как правило, большинство инструментов обеспечивают интеграцию с другими общими сервисами по умолчанию. Однако их по-прежнему сложно настраивать. Более того, весь рабочий процесс будет нарушен, если какой-либо сервис в цепи будет отключен. Поэтому, было бы здорово, если бы для выполнения этих задач существовала бы единая платформа и именно поэтому я и выбрал GitLab.
GitLab CI
GitLab.com — это сервис, основанный на SAAS — одной из форм облачных вычислений, где вы без труда сможете разместить свои Git-репозиторий, отслеживать возможные проблемы и писать wiki с помощью языка разметки markdown. GitLab CI также позволяет вам настраивать непрерывную интеграцию с использованием любого из образов Docker, доступного на Docker Hub. Давайте рассмотрим это на примере!
GitLab CI YML
Определение этапа
Глубже взглянем на этот этап.
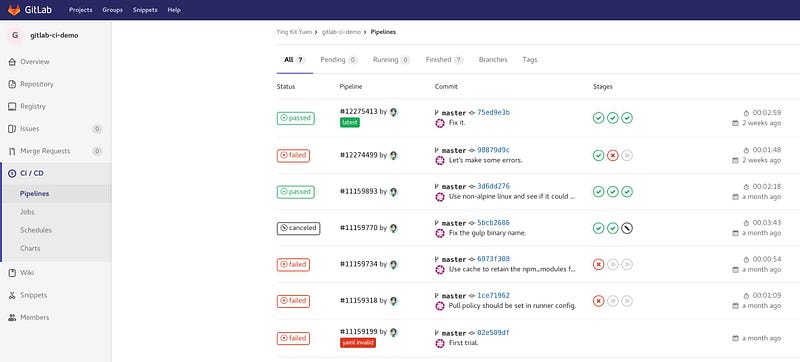
Запуск Pipeline (процесс разработки)
В настройках, обратите внимание на вкладку Pipeline в меню CI/CD. Там вы сможете увидеть всю историю процесса разработки.
Детальнее разберем этот этап
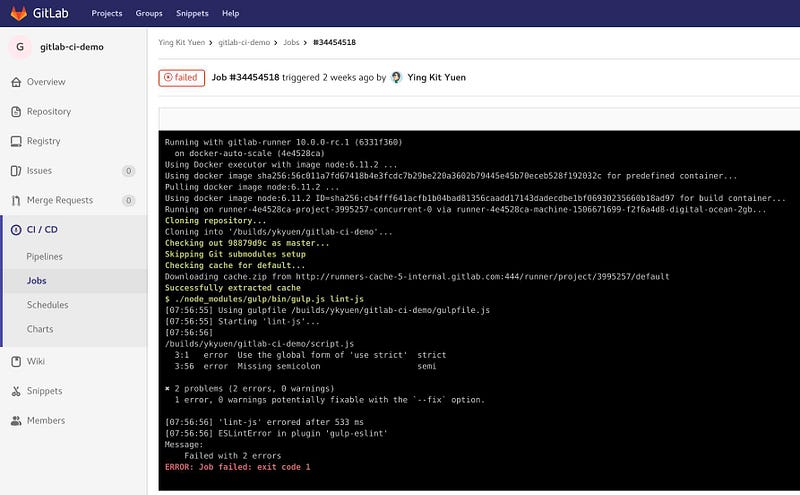
Нажав на определенный Pipeline, вы можете прочитать подробный консольный вывод любого из этапов. Это полезно, когда появляются сбои в работе.
Преимущества использования GitLab CI совместно с Docker
Для различных проектов могут потребоваться различные платформы, такие как Node.js, Ant, Maven. Раньше, используя инструмент Jenkins, я должен был убедиться, что все платформы установлены на сервере. Используя Docker, вы можете ссылаться на зависимости, доступные на Docker Hub без запроса администратора сервера, для установки этих зависимостей на самом сервере. На самом деле, в Jenkins есть плагин для создания Pipeline и он также может работать с Docker. Но как я и утверждал ранее, вам постоянно придется следить за его обновлениями, что не так уж и хорошо с точки зрения затрат дополнительных усилий и времени.
Хоть я и предпочитаю использовать GitLab CI, это не значит, что он может полностью заменить инструмент Jenkins. Ведь в Jenkins есть одно огромное преимущество — это удобный и легконастраиваемый пользовательский интерфейс, который будет удобен не только для разработчиков, но и для QA (специалист по обеспечению качества), для выполнения определенных задач, таких как развертывание и проведение интеграционных тестов.
Выбирая подходящий инструмент, знайте, что он не должен быть идеальным
Ключ к успеху лежит не в выборе идеального инструмента. Главным элементом успеха являются люди, которые его используют. Поэтому перед тем как искать для себя новый инструмент или программу, попытайтесь сначала определить проблему, которую вы бы хотели решить в первую очередь.



