Что такое выражение Git Revision?
Итак, я использую Git GUI для создания репозитория. Но я не могу найти НИКАКИХ следов в Google, документации или где-либо еще, что такое «Revision Expression», и это требуется для создания новой ветки.
Кроме того, похоже, что это используется во многих других местах программы, поэтому я считаю, что это важно знать.
Я нашел вопрос по этому поводу в StackOverflow, но парень так и не получил ответа.
Мне просто нужно знать: что такое Revision Expression?
4 ответа
git должен иметь возможность идентифицировать фиксацию во время ряда общих операций
Есть несколько способов идентифицировать фиксацию. Вы можете использовать ветку, тег, фиксацию sha1 или выражения. Например:
HEAD в конечном итоге преобразуется в конкретную фиксацию, и вам будет предоставлен журнал для этого. Вы могли бы также сказать:
Теперь это настоящая фиксация.
УКАЗАНИЕ ИЗМЕНЕНИЙ
Параметр ревизии обычно, но не обязательно, называет объект фиксации. Они используют так называемый расширенный синтаксис SHA1. Вот несколько способов написания имен объектов. Те, которые перечислены в конце этого списка, служат для обозначения деревьев и блобов, содержащихся в коммите.
Полное имя объекта SHA1 (40-байтовая шестнадцатеричная строка) или его подстрока, уникальная в репозитории. Например. dae86e1950b1277e545cee180551750029cfe735 и dae86e называют один и тот же объект фиксации, если в вашем репозитории нет другого объекта, имя которого начинается с dae86e.
Вывод из git-describe; то есть ближайший тег, за которым необязательно следует тире и количество коммитов, за которым следует тире, буква g и сокращенное имя объекта.
HEAD называет коммит, на котором основаны ваши изменения в рабочем дереве. FETCH_HEAD записывает ветку, которую вы выбрали из удаленного репозитория при последнем вызове git-fetch. ORIG_HEAD создается командами, которые резко перемещают вашу ГОЛОВУ, чтобы записать положение ГОЛОВКИ перед их операцией, чтобы вы могли вернуть кончик ветви в состояние до того, как вы легко их запустили. MERGE_HEAD записывает коммит (и), которые вы объединяете в свою ветку при запуске git-merge.
Ссылка, за которой следует суффикс @ с порядковым номером, заключенным в пару скобок (например, <1>, <15>), чтобы указать n-е предшествующее значение этой ссылки. Например, master @ <1>— это непосредственное предшествующее значение master, а master @ <5>— это 5-е предшествующее значение master. Этот суффикс можно использовать только сразу после имени ссылки, и ссылка должна иметь существующий журнал ($ GIT_DIR / logs /).
Вы можете использовать конструкцию @ с пустой частью ref для доступа к журналу ссылок текущей ветки. Например, если вы находитесь в ветке blabla, то @ <1>означает то же, что и blabla @ <1>.
Специальная конструкция @ <->означает, что первая ветка была извлечена перед текущей.
параметра редакции означает, что объект фиксации является прародителем-го поколения указанного объекта фиксации после только первого родителя. Т.е. rev
3 эквивалентен rev ^^^, который эквивалентен rev ^ 1 ^ 1 ^ 1. См. Ниже иллюстрацию использования этой формы.
Суффикс ^, за которым следует имя типа объекта, заключенное в пару скобок (например, v0.99.8 ^
Суффикс ^, за которым следует пустая пара скобок (например, v0.99.8 ^ <>) означает, что объект может быть тегом, и рекурсивно разыменовывать тег, пока не будет найден объект, не являющийся тегом.
Суффикс: за которым следует путь; это называет blob или дерево по заданному пути в древовидном объекте, названном частью перед двоеточием.
Вот иллюстрация Джона Лелигера. Оба узла фиксации B и C являются родителями узла фиксации A. Родительские коммиты располагаются слева направо.
Когда вы впервые пытаетесь создать ветку, Git GUI запрашивает выражение Revision, насколько я понимаю, я думаю, что git нуждается в уже созданной и зафиксированной ветке, чтобы отслеживать недавно внесенные изменения, такие как (новая ветка / модификация в файлах) на сравните это с чем-нибудь (здесь главная ветка).
Подводя итог, когда Emacs запрашивает ревизию, просто введите это 40-значное шестнадцатеричное число.
Gahooa дает исчерпывающий ответ. Обычный случай:
Что такое Git Revision Expression?
Итак, я использую Git GUI для создания репозитория. Но я не могу найти ЛЮБОЙ след в Google, Документации или где-либо еще, что такое «выражение ревизии», и это необходимо для создания новой ветви.
Кроме того, кажется, что это используется во многих других местах в программе, поэтому я считаю, что это важно знать.
Я нашел вопрос по этому вопросу в StackOverflow, но парень так и не получил ответа.
Мне просто нужно знать: что такое выражение ревизии?

4 ответов
Git должен иметь возможность идентифицировать коммит во время ряда общих операций
Существует несколько способов определения коммита. Вы можете использовать ветку, тэг, коммит sha1 или выражения. Например:
HEAD в конечном итоге преобразуется в конкретный коммит, и вы получите журнал для этого. Вы также можете сказать:
Теперь это фактический коммит.
УТОЧНИТЕЛЬНЫЕ ПЕРЕСМОТРЫ
Параметр ревизии обычно, но не обязательно, именует объект фиксации. Они используют так называемый расширенный синтаксис SHA1. Вот различные способы написания имен объектов. Те, что перечислены в конце этого списка, должны называть деревья и BLOB-объекты, содержащиеся в коммите.
Полное имя объекта SHA1 (40-байтовая шестнадцатеричная строка) или его подстрока, которая является уникальной в хранилище. E. г. dae86e1950b1277e545cee180551750029cfe735 и dae86e оба называют один и тот же объект фиксации, если в вашем хранилище нет другого объекта, имя которого начинается с dae86e.
Выход из git-description; я. е. ближайший тег, за которым может следовать тире и количество коммитов, за которыми следуют тире, g и сокращенное имя объекта.
HEAD называет коммит, на котором основаны ваши изменения в рабочем дереве. FETCH_HEAD записывает ветку, которую вы извлекли из удаленного репозитория с вашим последним вызовом git-fetch. ORIG_HEAD создается командами, которые резко перемещают ваш HEAD, чтобы записать положение HEAD перед их работой, чтобы вы могли изменить кончик ветви обратно в состояние до того, как вы легко запустили их. MERGE_HEAD записывает коммиты, которые вы объединяете в ветке, когда вы запускаете git-merge.
Ссылка, за которой следует суффикс @ с порядковым номером, заключенным в пару скобок (например, г. <1>, <15>) для указания n-го предшествующего значения этой ссылки. Например, master @ <1>является непосредственным предшествующим значением master, а master @ <5>является 5-м предшествующим значением master. Этот суффикс может использоваться только сразу после имени ссылки, и ссылка должна иметь существующий журнал ($ GIT_DIR / logs /).
Вы можете использовать конструкцию @ с пустой частью ref, чтобы получить reflog текущей ветви. Например, если вы находитесь на ветке blabla, то @ <1>означает то же самое, что и blabla @ <1>.
Специальная конструкция @ <->означает, что ветвь th была проверена перед текущей.
Суффикс ^ к параметру ревизии означает первого родителя этого объекта фиксации. ^ означает th родителя (я. е. rev ^ эквивалентно rev ^ 1). Как специальное правило, rev ^ 0 означает сам коммит и используется, когда rev является именем объекта тега, который ссылается на объект фиксации.
к параметру ревизии означает объект фиксации, который является прародителем поколения с именованным объектом фиксации, следуя только за первым родителем. Я. е. rev
3 эквивалентен rev ^^^, что эквивалентно rev ^ 1 ^ 1 ^ 1. Ниже приведена иллюстрация использования этой формы.
Суффикс ^, за которым следует имя типа объекта, заключенное в пару скобок (например, г. v0. 99. 8 ^
Суффикс ^ с пустой парой скобок (например, г. v0. 99. 8 ^ <>) означает, что объект может быть тегом, и рекурсивно разыменовывает тег, пока не будет найден объект без тега.
Суффикс: сопровождается путем; это имя большого двоичного объекта или дерева по заданному пути в объекте tree-ish, названном частью перед двоеточием.
Двоеточие, за которым может следовать номер этапа (от 0 до 3) и двоеточие, за которым следует путь; это имя объекта BLOB-объекта в индексе по заданному пути. Отсутствующий номер этапа (и двоеточие, следующее за ним) именует запись этапа 0. Во время объединения стадия 1 является общим предком, стадия 2 является версией целевой ветви (обычно текущей ветвью), а стадия 3 является версией из объединяемой ветви.
Вот иллюстрация, Джон Лелигер. Оба узла фиксации B и C являются родителями узла фиксации A. Коммиты родителей упорядочены слева направо.
What is a Git Revision Expression?
So, I am using Git GUI to make a repository. But I cant find ANY trace on Google, the Documentation, or anywhere else what a ‘Revision Expression’ is, and it is required to create a new Branch.
Also, it seems that this is used many other places in the program, so I belive it is important to know.
I did find a question on this on StackOverflow, but the guy never got an answer.
I just need to know: What is a Revision Expression?
Answers
git needs to be able to identify a commit during a number of common operations
There are a number of ways to identify a commit. You could use a branch, tag, commit sha1, or expressions. For example:
HEAD eventually resolves to a specific commit, and you will be given the log for that. YOu could also say:
master is a branch, and that will also resolve to a specific commit.
Now that IS the actual commit.
The below documentation is what you are looking for. Taken from the git-rev-parse command documentation at http://www.kernel.org/pub/software/scm/git/docs/git-rev-parse.html.
SPECIFYING REVISIONS
A revision parameter typically, but not necessarily, names a commit object. They use what is called an extended SHA1 syntax. Here are various ways to spell object names. The ones listed near the end of this list are to name trees and blobs contained in a commit.
The full SHA1 object name (40-byte hexadecimal string), or a substring of such that is unique within the repository. E.g. dae86e1950b1277e545cee180551750029cfe735 and dae86e both name the same commit object if there are no other object in your repository whose object name starts with dae86e.
An output from git-describe; i.e. a closest tag, optionally followed by a dash and a number of commits, followed by a dash, a g, and an abbreviated object name.
HEAD names the commit your changes in the working tree is based on. FETCH_HEAD records the branch you fetched from a remote repository with your last git-fetch invocation. ORIG_HEAD is created by commands that moves your HEAD in a drastic way, to record the position of the HEAD before their operation, so that you can change the tip of the branch back to the state before you ran them easily. MERGE_HEAD records the commit(s) you are merging into your branch when you run git-merge.
A ref followed by the suffix @ with an ordinal specification enclosed in a brace pair (e.g. <1>, <15>) to specify the n-th prior value of that ref. For example master@ <1>is the immediate prior value of master while master@ <5>is the 5th prior value of master. This suffix may only be used immediately following a ref name and the ref must have an existing log ($GIT_DIR/logs/).
You can use the @ construct with an empty ref part to get at a reflog of the current branch. For example, if you are on the branch blabla, then @ <1>means the same as blabla@<1>.
The special construct @ <->means the th branch checked out before the current one.
A suffix ^ to a revision parameter means the first parent of that commit object. ^ means the th parent (i.e. rev^ is equivalent to rev^1). As a special rule, rev^0 means the commit itself and is used when rev is the object name of a tag object that refers to a commit object.
to a revision parameter means the commit object that is the th generation grand-parent of the named commit object, following only the first parent. I.e. rev
3 is equivalent to rev^^^ which is equivalent to rev^1^1^1. See below for a illustration of the usage of this form.
A suffix ^ followed by an object type name enclosed in brace pair (e.g. v0.99.8^
A suffix ^ followed by an empty brace pair (e.g. v0.99.8^<>) means the object could be a tag, and dereference the tag recursively until a non-tag object is found.
A suffix : followed by a path; this names the blob or tree at the given path in the tree-ish object named by the part before the colon.
A colon, optionally followed by a stage number (0 to 3) and a colon, followed by a path; this names a blob object in the index at the given path. Missing stage number (and the colon that follows it) names a stage 0 entry. During a merge, stage 1 is the common ancestor, stage 2 is the target branch’s version (typically the current branch), and stage 3 is the version from the branch being merged.
Here is an illustration, by Jon Loeliger. Both commit nodes B and C are parents of commit node A. Parent commits are ordered left-to-right.
Git revision expression что это
Можно вернуться к предыдущему commit-у чтобы просмотреть содержимое какого-нибудь файла и потом снова вернуться к последней версии файла.
Меню Repository | Visualize All Branch History открывает gitk:
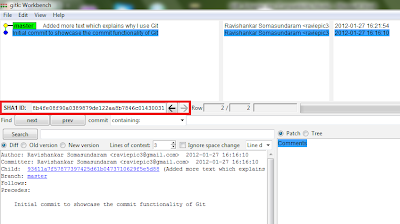
Цветные кружки показывают сделанные commit-ы, а справа от них комментарии.
SHA1 ID это commit ID, который используется для отката/наката изменений.
Если теперь в Git Gui зайти в Branch | Checkout (Ctrl + O), вставить в поле Revision Expression какой-нибудь SHA1 ID и нажать Checkout то произойдет переход на эту ревизию.
Чтобы вернуться к последним изменениям надо сделать в Git Gui:
1) Branch | Checkout
2) Выбрать Localbranch и затем master
3) Нажать кнопку Checkout
git log показывает историю репозитория предоставляя следующую информацию: commit ID, автор, дата, и комментарий.
При указании commit ID достаточно указывать первый 5 символов вместо всех 40.

Чтобы вернуться к последним изменниям достаточно дать команду:
Примечание: когда вы возвращаетесь на предыдущий commit вы «парите в воздухе» потому что все изменения которые вы сделаете исчезнут при возврате к master.
Перманентный откат (reset)
Есть три типа resetting-а:
1) В Git Gui переходим в меню Repository | Visualize All Branch History, откроется Gitk.
2) Нажимаем правой кнопкой мыши на commit-e и выбираем Reset master branch to here.
3) В появившемся окне выбираем тип resetting-а.
4) File | Reload (Ctrl + F5) чтобы перезагрузить Gitk.
Ежедневная работа с Git
Я совсем не долго изучаю и использую git практически везде, где только можно. Однако, за это время я успел многому научиться и хочу поделиться своим опытом с сообществом.
Конечно, я попытаюсь рассказать обо всём по-порядку, начиная с основ. Поэтому, эта статья будет крайне полезна тем, кто только начинает или хочет разобраться с git. Более опытные читатели, возможно, найдут для себя что-то новое, укажут на ошибки или поделятся советом.
Вместо плана
Очень часто, для того чтобы с чем-то начать я изучаю целую кучу материалов, а это — разные люди, разные компании, разные подходы. Всё это требует много времени на анализ и на понимание того, подойдёт ли что-нибудь мне? Позже, когда приходит понимание, что универсальное решение отсутствует, появляются совершенно другие требования к системе контроля версий и к разработке.
Окружение
Если вы открываете консоль, пишите git и получаете вот это:
Перестаём бояться экспериментировать
Строго говоря, даже неудачный git push можно исправить.
Поэтому, спокойно можете клонировать любой репозиторий и начать изучение.
Строим репозитории
В первую очередь нужно понять что такое git-репозиторий? Ответ очень прост: это набор файлов. Папка `.git`. Важно понимать, что это только набор файлов и ничего больше. Раз 20 наблюдал проблему у коллег с авторизацией в github/gitlab. Думая, что это часть git-системы, они пытались искать проблему в конфигруации git, вызывать какие-то git-команды.
В частности, при клонировании вот так:
урл «превращается» в
Т.е. используется SSH и проблемы нужно искать в нём. Как правило, это неправильно настроенный или не найденный ssh-ключ. Гуглить надо в сторону «SSH Auth Key git» или, если совсем по взрослому, проверить, что же происходит:
Какие протоколы поддерживаются поможет справка (раздел GIT URLS):
Сделаем себе один (будет нашим главным тестовым репозиторием):
Итог: у нас есть 3 репозитория. Там ничего нет, зато они готовы к работе.
Начало GIT
Скандалы! Интриги! Расследования!
Как это всё работает?
Как это всё можно понять и запомнить?
Для этого нужно заглянуть под капот. Рассмотрим всё в общих чертах.
Git. Почти под капотом
Git сохраняет в commit содержимое всех файлов (делает слепки содержимого каждого файла и сохраняет в objects). Если файл не менялся, то будет использован старый object. Таким образом, в commit в виде новых объектов попадут только изменённые файлы, что позволит хорошо экономить место на диске и даст возможность быстро переключиться на любой commit.
Это позволяет понять, почему работают вот такие вот забавные штуки:
Да, не стоит хранить «тяжёлые» файлы, бинарники и прочее без явной необходимости. Они там останутся навсегда и будут в каждом клоне репозитория.
Каждый коммит может иметь несколько коммитов-предков и несколько дочерних-коммитов: 
Мы можем переходить (восстанавливать любое состояние) в любую точку этого дерева, а точнее, графа. Для этого используется git checkout:
Каждое слияние двух и более коммитов в один — это merge (объединение двух и более наборов изменений).
Каждое разветвление — это появление нескольких вариантов изменений.
Кстати, тут хочется отметить, что нельзя сделать тэг на файл/папку, на часть проекта и т.д. Состояние восстанавливается только целиком. Поэтому, рекомендуется держать проекты в отдельном репозитории, а не складывать Project1, Project2 и т.д. просто в корень.
Теперь к веткам. Выше я написал:
В Git нет веток* (с небольшой оговоркой)
Получается, что так и есть: у нас есть много коммитов, которые образуют граф. Выбираем любой путь от parent-commit к любому child-commit и получаем состояние проекта на этот коммит. Чтобы коммит «запомнить» можно создать на него именованный указатель.
Такой именованный указатель и есть ветка (branch). Так же и с тэгом (tag). `HEAD` работает по такому же принципу — показывает, где мы есть сейчас. Новые коммиты являются продолжением текущей ветки (туда же куда и смотрит HEAD).
Указатели можно свободно перемещать на любой коммит, если это не tag. Tag для того и сделан, чтобы раз и навсегда запомнить коммит и никуда не двигаться. Но его можно удалить.
Вот, пожалуй, и всё, что нужно знать из теории на первое время при работе с git. Остальные вещи должны показаться теперь более понятными.
Терминология
index — область зафиксированных изменений, т.е. всё то, что вы подготовили к сохранению в репозиторий.
commit — изменения, отправленные в репозиторий.
HEAD — указатель на commit, в котором мы находимся.
master — имя ветки по-умолчанию, это тоже указатель на определённый коммит
origin — имя удалённого репозитория по умолчанию (можно дать другое)
checkout — взять из репозитория какое-либо его состояние.
Простые правки
Если вы сделали что-то не так, запутались, не знаете, что происходит — эти две команды вам помогут.
Вернёмся к нашим репозиториям, которые создали раньше. Далее обозначу, что один разработчик работает в dev1$, а второй в dev2$.
Поделимся со всеми. Но поскольку мы клонировали пустой репозиторий, то git по умолчанию не знает в какое место добавить коммит.
Он нам это подскажет:
Второй разработчик может получить эти изменения, сделав pull:
Добавим ещё пару изменений:
Посмотрим, что же мы сделали (запускаем gitk):
Выделил первый коммит. Переходя по-порядку, снизу вверх, мы можем посмотреть как изменялся репозиторий:
До сих пор мы добавляли коммиты в конец (там где master). Но мы можем добавить ещё один вариант README.md. Причём делать мы это можем из любой точки. Вот, например, последний коммит нам не нравится и мы пробуем другой вариант. Создадим в предыдущей точке указатель-ветку. Для этого через git log или gitk узнаем commit id. Затем, создадим ветку и переключимся на неё:
Выглядит это так:
Теперь нам понятно, как создаются ветки из любой точки и как изменяется их история.
Быстрая перемотка
Наверняка, вы уже встречали слова fast-forward, rebase, merge вместе. Настало время разобраться с этими понятиями. Я использую rebase, кто-то только merge. Тем «rebase vs merge» очень много. Авторы часто пытаются убедить, что их метод лучше и удобнее. Мы пойдём другим путём: поймём, что же это такое и как оно работает. Тогда сразу станет ясно, какой вариант использовать в каком случае.
Пока, в пределах одного репозитория, сделаем ветвление: создадим файл, положим в репозиторий, из новой точки создадим два варианта файла и попробуем объединить всё в master:
Создадим файл collider.init.sh с таким содержанием:
Добавим, закоммитим и начнём разработку в новой ветке:
Обратите внимание, что в имени ветки не запрещено использовать символ ‘/’, однако, надо быть осторожным, т.к. в файловой системе создаётся папка с именем до ‘/’. Если ветка с таким названием как и папка существует — будет конфликт на уровне файловой системы. Если уже есть ветка dev, то нельзя создать dev/test.
A если есть dev/test, то можно создавать dev/whatever, но нельзя просто dev.
Теперь, в каждой ветке напишем код, который, соответственно, будет запускать и уничтожать наш коллайдер. Последовательность действий приблизительно такая:
Разработка закончена и теперь надо отдать все изменения в master (там ведь старый коллайдер, который ничего не может). Объединение двух коммитов, как и говорилось выше — это merge. Но давайте подумаем, чем отличается ветка master от collider/start и как получить их объединение (сумму)? Например, можно взять общие коммиты этих веток, затем прибавить коммиты, относящиеся только к master, а затем прибавить коммиты, относящиеся только к collider/start. А что у нас? Общие коммиты — есть, только коммиты master — нет, только collider/start — есть. Т.е. объединение этих веток — это master + коммиты от collider/start. Но collider/start — это master + коммиты ветки collider/start! Тоже самое! Т.е. делать ничего не надо! Объединение веток — это и есть collider/start!
Ещё раз, только на буквах, надеюсь, что будет проще для восприятия:
master = C1 + C2 +C3
collider/start = master + C4 = C1 + C2 +C3 + C4
master + collider/start = Общие_коммиты(master, collider/start) + Только_у(master) + Только_у(collider/start) = (C1 + C2 +C3) + (NULL) + (C4) = C1 + C2 +C3 + C4
Как быстро узнать, что fast-forward возможен? Для этого достаточно посмотреть в gitk на две ветки, которые нужно объединить и ответить на один вопрос: существует ли прямой путь от ветки А к B, если двигаться только вверх (от нижней к верхней). Если да — то будет fast-forward.
В теории понятно, пробуем на практике, забираем изменения в master:
Результат (указатель просто передвинулся вперёд):
Объединение
Теперь забираем изменения из collider/terminate. Но, тот, кто дочитал до сюда (дочитал ведь, да?!) заметит, что прямого пути нет и так красиво мы уже не отделаемся. Попробуем git попросить fast-forward:
Что и следовало ожидать. Делаем просто merge:
Я даже рад, что у нас возник конфликт. Обычно, в этом момент некоторые теряются, лезут гуглить и спрашивают, что делать.
Для начала:
Конфликт возникает при попытке объединить два и более коммита, в которых в одной и той же строчке были сделаны изменения. И теперь git не знает что делать: то ли взять первый вариант, то ли второй, то ли старый оставить, то ли всё убрать.
Как всегда, две самые нужные команды нам спешат помочь:
Мы находимся в master, туда же указывает HEAD, туда же и добавляются наши коммиты.
Файл выглядит так:
Из-за того что изменения были в одних и тех же местах конфликтов получилось много. Поэтому, я брал везде первый вариант, а второй копировал сразу после первого, но с gui это сделать довольно просто. Вот результат — вверху варианты файла, внизу — объединение (простите за качество):
Сохраняем результат, закрываем окно, коммитим, смотрим результат:
Мы создали новый коммит, который является объединением двух других. Fast-forward не произошёл, потому, что не было прямого пути для этого, история стала выглядеть чуть-чуть запутаннее. Иногда, merge действительно нужен, но излишне запутанная история тоже ни к чему.
Вот пример реального проекта:
| | |
Конечно, такое никуда не годится! «Но разработка идёт параллельно и никакого fast-forward не будет» скажете вы? Выход есть!
Перестройка
Что же делать, чтобы история оставалась красивой и прямой? Можно взять нашу ветку и перестроить её на другую ветку! Т.е. указать ветке новое начало и воспроизвести все коммиты один за одним. Этот процесс и называется rebase. Наши коммиты станут продолжением той ветки, на которую мы их перестроим. Тогда история будет простой и линейной. И можно будет сделать fast-forward.
Другими словами: мы повторяем историю изменений с одной ветки на другой, как будто бы мы действительно брали другую ветку и заново проделывали эти же самые изменения.
Для начала отменим последние изменения. Проще всего вернуть указатель master назад, на предыдущее состояние. Создавая merge-commit, мы передвинули именно master, поэтому именно его нужно вернуть назад, желательно (а в отдельных случаях важно) на тот же самый commit, где он был.
Как результат, наш merge-commit останется без какого-либо указателя и не будет принадлежать ни к одной ветке.
Используя gitk или консоль перемещаем наш указатель. Поскольку, ветка collider/start уже указывает на наш коммит, нам не нужно искать его id, а мы можем использовать имя ветки (это будет одно и тоже):
Когда с коммита или с нескольких коммитов пропадает указатель (ветка), то коммит остаётся сам по себе. Git про него забывает, не показывает его в логах, в ветках и т.д. Но физически, коммит никуда не пропал. Он живёт себе в репозитории как невостребованная ячейка памяти без указателя и ждёт своего часа, когда git garbage collector её почистит.
Иногда бывает нужно вернуть коммит, который по ошибке был удалён. На помощь придёт git reflog. Он покажет всю историю, по каким коммитам вы ходили (как передвигался указатель HEAD). Используя вывод, можно найти id пропавшего коммита, сделать его checkout или создать на коммит указатель (ветку или тэг).
Выглядит это примерно так (история короткая, поместилась вся):
Посмотрим, что получилось:
Для того, чтобы перестроить одну ветку на другую, нужно найти их общее начало, потом взять коммиты перестраиваемой ветки и, в таком же порядке, применить их на основную (base) ветку. Очень наглядная картинка (feature перестраивается на master):
Важное замечание: после «перестройки» это уже будут новые коммиты. А старые никуда не пропали и не сдвинулись.
В теории разобрались, пробуем на практике. Переключаемся в collider/terminate и перестраиваем на тот коммит, куда указывает master (или collider/start, кому как удобнее). Команда дословно «взять текущую ветку и перестроить её на указанный коммит или ветку»:
Откроется редактор в котором будет приблизительно следующее:
Если коротко: то в процессе перестройки мы можем изменять комментарии к коммитам, редактировать сами коммиты, объединять их или вовсе пропускать. Т.е. можно переписать историю ветки до неузнаваемости. На данном этапе нам это не нужно, просто закрываем редактор и продолжаем. Как и в прошлый раз, конфликтов нам не избежать:
На данном этапе мы удаляли, редактировали, объединяли правки, а на выходе получили красивую линейную историю изменений:
Перерыв
Дальше примеры пойдут по сложнее. Я буду использовать простой скрипт, который будет в файл дописывать случайные строки.
На данном этапе нам не важно, какое содержимое, но было бы очень неплохо иметь много различных коммитов, а не один. Для наглядности.
Скрипт добавляет случайную строчку к файлу и делает git commit. Это повторяется несколько раз:
Передача и приём изменений
git remote
Как отмечалось выше, origin — это имя репозитория по умолчанию. Имена нужны, т.к. репозиториев может быть несколько и их нужно как-то различать. Например, у меня была копия репозитория на флешке и я добавил репозиторий flash. Таким образом я мог работать с двумя репозиториями одновременно: origin и flash.
Имя репозитория используется как префикс к имени ветки, чтоб можно было отличать свою ветку от чужой, например master и origin/master
В справке по git remote достаточно хорошо всё описано. Как и ожидается, там есть команды: add, rm, rename, show.
show покажет основные настройки репозитория:
Чтобы добавить существующий репозиторий используем add :
git fetch
Команда говорит сама за себя: получить изменения.
Стоит отметить, что локально никаких изменений не будет. Git не тронет рабочую копию, не тронет ветки и т.д.
Будут скачены новые коммиты, обновлены только удалённые (remote) ветки и тэги. Это полезно потому, что перед обновлением своего репозитория можно посмотреть все изменения, которые «пришли» к вам.
Ниже есть описание команды push, но сейчас нам нужно передать изменения в origin, чтобы наглядно показать как работает fetch:
Теперь от имени dev2 посмотрим, что есть и получим все изменения:
Выглядит это так:
Обратите внимание, что мы находимся в master.
Что можно сделать:
git checkout origin/master — переключиться на удалённый master, чтобы «пощупать» его. При этом нельзя эту ветку редактировать, но можно создать свою локальную и работать с ней.
git merge origin/master — объединить новые изменения со своими. Т.к. у нас локальных изменений не было, то merge превратится в fast-forward:
git pull
В 95% случаев, вам не нужно менять это поведение.
git push
На все вопросы может ответить расширенный вариант использования команды:
git push origin :
Примеры:
Включаемся в проект
К этому моменту уже более-менее понятно, как работает push, pull. Более смутно представляется в чём разница между merge и rebase. Совсем непонятно зачем это нужно и как применять.
Когда кого-нибудь спрашивают:
— Зачем нужна система контроля версий?
Чаще всего в ответе можно услышать:
— Эта система помогает хранить все изменения в проекте, чтобы ничего не потерялось и всегда можно было «откатиться назад».
А теперь задайте себе вопрос: «как часто приходится откатываться назад?» Часто ли вам нужно хранить больше, чем последнее состояние проекта? Честный ответ будет: «очень редко». Я этот вопрос поднимаю, чтобы выделить гораздо более важную роль системы контроля версий в проекте:
Система контроля версий позволяет вести совместную работу над проектом более, чем одному разработчику.
То, на сколько вам удобно работать с проектом совместно с другими разработчиками и то, на сколько система контроля версий вам помогает в этом — самое важное.
Используете %VCS_NAME%? Удобно? Не ограничивает процесс разработки и легко адаптируется под требования? Быстро? Значит эта %VCS_NAME% подходит для вашего проекта лучше всего. Пожалуй, вам не нужно ничего менять.
Типичные сценарии при работе над проектом
Чтобы добиться такого процесса, нужно чётко определиться где и что будет хранится. Т.к. ветки легковесные (т.е. не тратят ресурсов, места и т.д.) под все задачи можно создать отдельные ветки. Это является хорошей практикой. Такой подход даёт возможность легко оперировать наборами изменений, включать их в различные ветки или полностью исключать неудачные варианты.
Исправление багов
Создадим ветку dev и рассмотрим типичный сценарий исправления багов.
И второй разработчик «забирает» новую ветку к себе:
Пусть 2 разработчика ведут работу каждый над своим багом и делают несколько коммитов (пусть вас не смущает, что я таким некрасивым способом генерирую множество случайных коммитов):
Когда работа закончена, передаём изменения в репозиторий. Dev1:
На первый взгляд, кажется, что здесь много действий и всё как-то сложно. Но, если разобраться, то описание того, что нужно сделать намного больше, чем самой работы. И самое главное, мы уже так делали выше. Приступим к практике:
Посмотрим на результат:
Теперь, всё как положено: наши изменения в dev и готовы быть переданы в origin.
Передаём:
Нам откроется редактор и даст возможность исправить нашу историю, например, поменять порядок коммитов или объединить несколько. Об этом писалось выше. Я оставлю как есть:
После того как все конфликты решены, история будет линейной и логичной. Для наглядности я поменял комментарии (интерактивный rebase даёт эту возможность):
Теперь наша ветка продолжает origin/dev и мы можешь отдать наши изменения: актуальные, адаптированные под новые коммиты:
Далее история повторяется. Для удобства или в случае работы над несколькими багами, как говорилось выше, удобно перед началом работы создать отдельные ветки из dev или origin/dev.
Feature branch
Бывает так, что нужно сделать какой-то большой кусок работы, который не должен попадать в основную версию пока не будет закончен. Над такими ветками могут работать несколько разработчиков. Очень серьёзный и объёмный баг может рассматриваться с точки зрения процесса работы в git как фича — отдельная ветка, над которой работают несколько человек. Сам же процесс точно такой же как и при обычном исправлении багов. Только работа идёт не с dev, а с feature/name веткой.
Вообще, такие ветки могут быть коротко-живущими (1-2 неделя) и долго-живущими (месяц и более). Разумеется, чем дольше живёт ветка, тем чаще её нужно обновлять, «подтягивая» в неё изменения из основной ветки. Чем больше ветка, тем, вероятно, больше будет накладных расходов по её сопровождению.
Начнём с коротко-живущих (short-live feature branches)
Обычно ветка создаётся с самого последнего кода, в нашем случае с ветки dev:
Теперь работу на feature1 можно вести в ветке feature/feature1. Спустя некоторое время в нашей ветке будет много коммитов, и работа над feature1 будет закончена. При этом в dev тоже будет много изменений. И наша задача отдать наши изменения в dev.
Выглядеть это будет приблизительно так:
Ситуация напоминает предыдущую: две ветки, одну нужно объединить с другой и передать в репозиторий. Единственное отличие, это две публичные (удалённые) ветки, а не локальные. Это требует небольшой коммуникации. Когда работа закончена, один разработчик должен предупредить другого, что он собирается «слить» изменения в dev и, например, удалить ветку. Таким образом передавать в эту ветку что-либо будет бессмысленно.
А дальше алгоритм почти такой как и был:
Картинка, feature1 стала частью dev, то что на и нужно было:
Делаем push и чистим за собой ненужное:
Долго-живущие ветки (long-live feature branches)
Сложность долго-живущих веток в их поддержке и актуализации. Если делать всё как описано выше то, вероятно быть беде: время идёт, основная ветка меняется, проект меняется, а ваша фича основана на очень старом варианте. Когда настанет время выпустить фичу, она будет настолько выбиваться из проекта, что объединение может быть очень тяжёлым или, даже, невозможным. Именно поэтому, ветку нужно обновлять. Раз dev уходит вперёд, то мы будем просто время от времени перестраивать нашу ветку на dev.
Всё бы хорошо, но только нельзя просто так взять и перестроить публичную ветку: ветка после ребэйза — это уже новый набор коммитов, совершенно другая история. Она не продолжает то, что уже было. Git не примет такие изменения: два разных пути, нет fast-forward’а. Чтобы переписать историю разработчикам нужно договориться.
Кто-то будет переписывать историю и принудительно выкладывать новый вариант, а в этот момент остальные не должны передавать свои изменения в текущую ветку, т.к. она будет перезаписана и всё пропадёт. Когда первый разработчик закончит, все остальные перенесут свои коммиты, которые они успеют сделать во время переписи уже на новую ветку. Кто говорил, что нельзя ребэйзить публичные ветки?
Приступим к практике:
Второй разработчик подключается к работе всё стандартно:
Добавим ещё несколько коммитов в основную ветку dev и история будет такая:
Настало время актуализировать feature/long, но при этом разработка должна продолжиться отдельно. Пусть перестраивать будет dev1. Тогда он предупреждает dev2 об этом и начинает:
В это время dev2 продолжает работать, но знает, что ему нельзя делать push, т.к. нужной ветки ещё нет (а текущая будет удалена).
Первый заканчивает rebase и история будет такой:
Ветка перестроена, а origin/feature/long остался там, где и был. Цели мы достигли, теперь нужно поделиться со всеми:
Git лишний раз напоминает, что что-то не так. Но теперь, мы точно знаем, что мы делаем, и знаем, что так надо:
Теперь можно работать дальше предупредив остальных об окончании работ.
Посмотрим, как эти изменения отразились на окружающих и на dev2 в частности:
N, чтобы указать на предыдущий N-ый коммит.
HEAD
1 — это предыдущий, а HEAD
2 — это предпредыдущий. HEAD
5 — 5 коммитов назад. Удобно, чтобы не запоминать id.
Посмотрим, как теперь нам перестроить только один коммит:
1
Если бы нам надо было перетянуть 4 коммита, то было бы feature/long
Осталось продолжить работу.
Hotfixes
Hotfixы нужны, т.к. бывают очень критичные баги, которые нужно исправить как можно быстрее. При этом нельзя передать вместе с hotfix-ом последний код, т.к. он не оттестирован и на полное тестирование нет времени. Нужно только это исправление, максимально быстро и оттестированное. Чтобы это сделать, достаточно взять последний релиз, который был отправлен на продакшен. Это тот, где у вас остался tag или master. Тэги играют очень важную роль, помогая понять что именно было собрано и куда это попало.
Тэги делаются командой
Всякие полезности
Git позволяет настраивать aliasы для различных команд. Это бывает очень удобно и сокращает время набора команд. Приводить здесь примеры не буду, в Интернете их полно, просто поищите.
Перед тем, как отдавать свои изменения их можно перестроить на самих себя, чтобы привести историю в порядок.
Например, в логах может быть такое:
Перестроим сами себя, но начиная с 6 коммитов назад:
Теперь в интерактивном режиме можно объединить (squash) первые два коммита в один и последние четыре. Тогда история будет выглядеть так:
Такое намного приятнее передавать в общим репозиторий.
Выводы
Причемания и апдейты
gcc рекомендовал посмотреть на Git Extensions.
borNfree подсказал ещё один GUI клиент Source Tree.
zloylos поделился ссылкой на визуализатор для git
olancheg предложил посмотреть на ещё один туториал для новичков.
PS. Что тут обычно пишут, когда первый пост на хабре? Прошу не судить строго, писал как мог.



