Git blob что это
Вся информация требуемая чтобы представить историю проекта хранится в особым образом организованных файлах. Все файлы хранят ссылаются друг на друга с помощью 40-значного «имени объекта» и это имя выглядит так:
Вы увидите эти 40-значные строки повсюду в Git. В каждом случае имя вычисляется как SHA1 значение содержимого объекта. SHA1 хэш это криптографическая хэш-функция. Для нас это значит то, что практически нереально найти два разных объекта с одинаковым именем. Это дает огромную выгоду; такую как:
Объекты
Почти все в Git построено вокруг манипуляций этой простой структурой состоящей из четырех различных типов объектов. Это что-то вроде своеобразной файловой-системы надстроенной над файловой-системой компьютера.
Различия с SVN
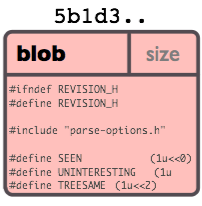
Объект типа блоб
Блоб обычно хранит содержимое файла.
Вы можете использовать git show чтобы исследовать содержимое блоба. Предположим у нас есть SHA-значение блоба, таким образом чтобы просмотреть его содержимое выполните выполнить:
Объект «блоб» это всего лишь некоторая порция бинарных данных. Он ни на что не ссылается у него нет каких либо атрибутов, нет даже имени файла.
Поскольку блоб полностью определяется его собственным содержимым, то если два файла в директории или даже в разных версиях репозитория имеют одинаковое содержимое, они будут разделять один и тот же блоб объект. Объект полностью независит от его расположения в дереве каталогов, и переименование файла не изменит объект с которым этом файл связан.
Объект дерево

Команда git show более общая, и также может быть использована чтобы исследовать дерево объектов, но git ls-tree даст вам больше подробностей. Предположим у нас есть SHA значение дерева, тогда мы можем исследовать его следующим образом:
Как вы можете видеть, объект дерево содержит список записей. Каждая запись состоит из вида, типа объекта, SHA1 значения, и имени соответственно. Записи отсортированы по имени. Так выглядит содержимое одной директории дерева.
Ссылка на объект в дереве может быть как блобом (файлом по сути) так и деревом (поддиректорией). Поскольку имена всех объектов, деревьев и блобов, совпадает с SHA хэш-значением их содержимого, то SHA значения двух деревьев будут идентичны только если их содержимое (включая, рекурсивно, содержимое всех поддиректорий) идентично.
Это свойство позволяет git быстро найти отличия между двумя родственными объектами типа дерево, так как git может игнорировать объекты с одинаковыми именами.
Замечание: деревья могут также содержать записи коммитов. Более продробно от этом в секции Подмодули.)
Отметьте для себя, что все файлы имеют права 644 или 755: фактически git обращает внимание только на бит исполнения.
Объекты коммит
Объект «коммит» связывает физическое состояние дерева с описпнием того каким образом мы пришли к этому и почему.

Как вы можете это видеть, коммит определяется:
Объектная модель
Теперь когда мы рассмотрели 3 главных объекта (блоб, дерево и коммит), давайте теперь посмотрим как они объединяются.
Если у нас есть простой проект со след. структурой директории:
И мы выполнили коммит всего этого в репозиторий Git, это будет выглядеть след. образом:
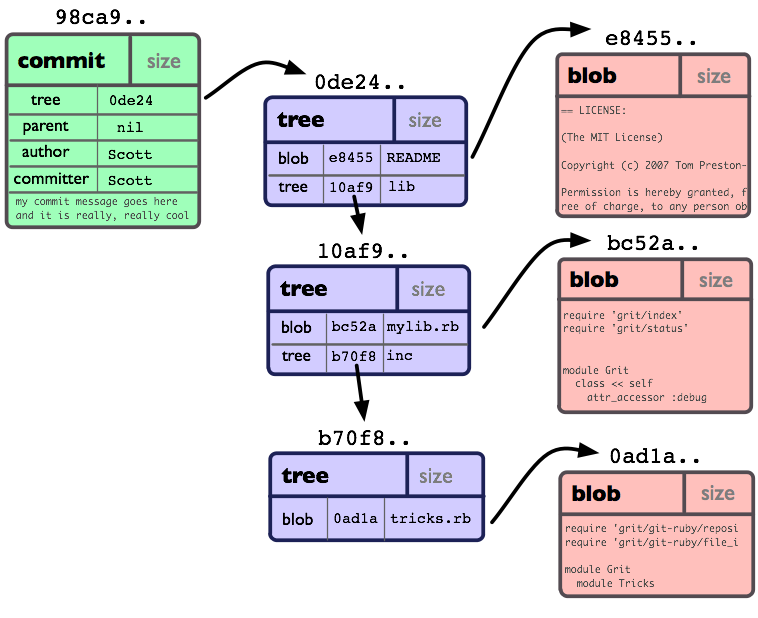
Вы можете видеть что мы создали объект дерево для каждой директории (включая корневую) и объект блоб для каждого файла. Затем, мы имеем объект коммит указывающий на кореневую директорию, и мы можем отследить как наш проект выглядел в момент коммита.
Объект таг
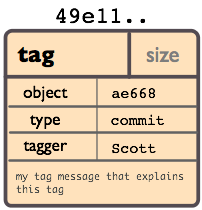
Объект таг содержит имя объекта (называетмого просто ‘объект’), тип объекта, имя тага, или разработчика («таггер») который создал таг, и сообщение, которое может содержить подпись. Это можно увидеть выполнив git cat-file:
Просмотрите документацию команды git tag чтобы изучить как создавать и проверять объекты таг. (Заметьте что git tag может также использоваться чтобы создавать «легковесные таги», которые не являеются объектами таг вообще, это просто ссылки чьи имена начинаются с «refs/tags/»).
Объекты Git
Git — контентно-адресуемая файловая система. Здорово. Что это означает? А означает это, по сути, что Git — простое хранилище ключ-значение. Можно добавить туда любые данные, в ответ будет выдан ключ по которому их можно извлечь обратно.
Для начала создадим новый Git-репозиторий и убедимся, что каталог objects пуст:
Результат выполнения команды — 40-символьная контрольная сумма. Это SHA-1 хеш — контрольная сумма содержимого и заголовка, который будет рассмотрен позднее. Теперь можно посмотреть как Git хранит ваши данные:
Теперь вы умеете добавлять данные в Git и извлекать их обратно. То же самое можно делать и с файлами. Например, можно проверсионировать один файл. Для начала, создадим новый файл и сохраним его в базе данных Git:
Теперь изменим файл и сохраним его в базе ещё раз:
Теперь в базе содержатся две версии файла, а также самый первый сохранённый объект:
Теперь можно откатить файл к его первой версии:
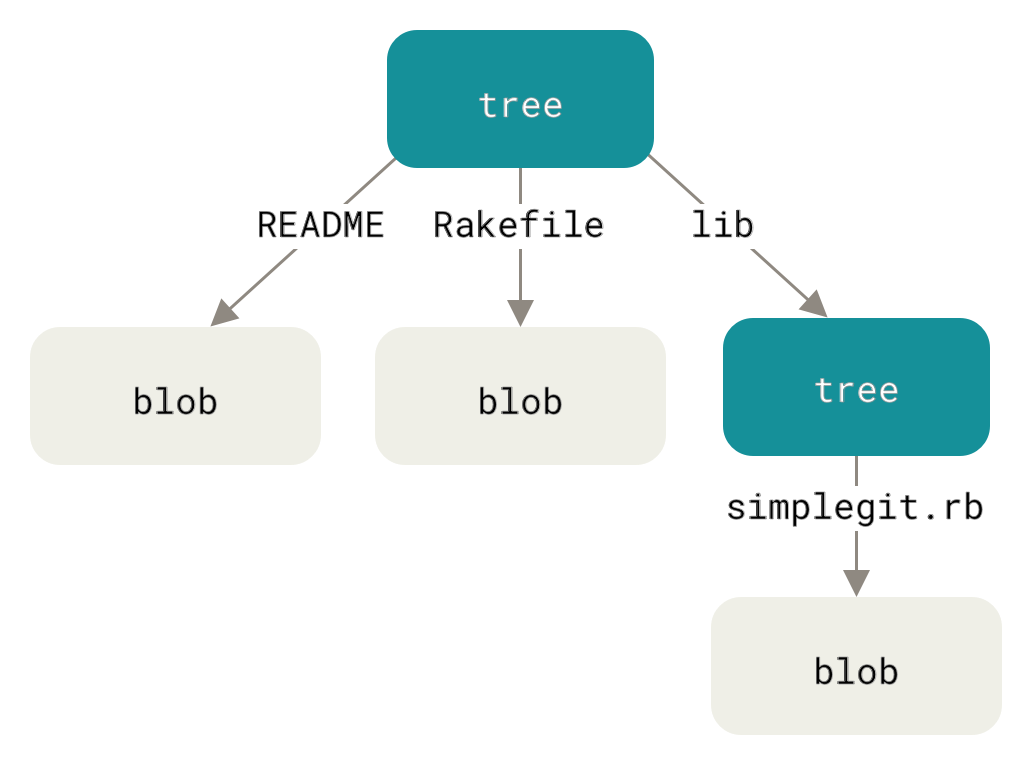
Деревья
Следующий тип объектов, который мы рассмотрим, — деревья — решают проблему хранения имён файлов, а также позволяют хранить группы файлов вместе. Git хранит данные сходным с файловыми системами UNIX способом, но в немного упрощённом виде. Содержимое хранится в деревьях и блобах, где дерево соответствует каталогу на файловой системе, а блоб более или менее соответствует inode или содержимому файла. Дерево может содержать одну или более записей, содержащих SHA-1 хеш, соответствующий блобу или поддереву, права доступа к файлу, тип и имя файла. Например, дерево последнего коммита в проекте может выглядеть следующим образом:
Вы можете столкнуться с различными ошибками при использовании синтаксиса master^
Концептуально, данные хранятся в Git примерно так:
В данном случае права доступа 100644 — означают обычный файл. Другие возможные варианты: 100755 — исполняемый файл, 120000 — символическая ссылка. Права доступа в Git сделаны по аналогии с правами доступа в UNIX, но они гораздо менее гибки: указанные три режима — единственные доступные для файлов (блобов) в Git (хотя существуют и другие режимы, используемые для каталогов и подмодулей).
Давайте создадим новое дерево со второй версией файла test.txt и ещё одним файлом:
Теперь в области подготовленных файлов содержится новая версия файла test.txt и новый файл new.txt. Зафиксируем изменения, сохранив состояние индекса в новое дерево, и посмотрим, что из этого вышло:
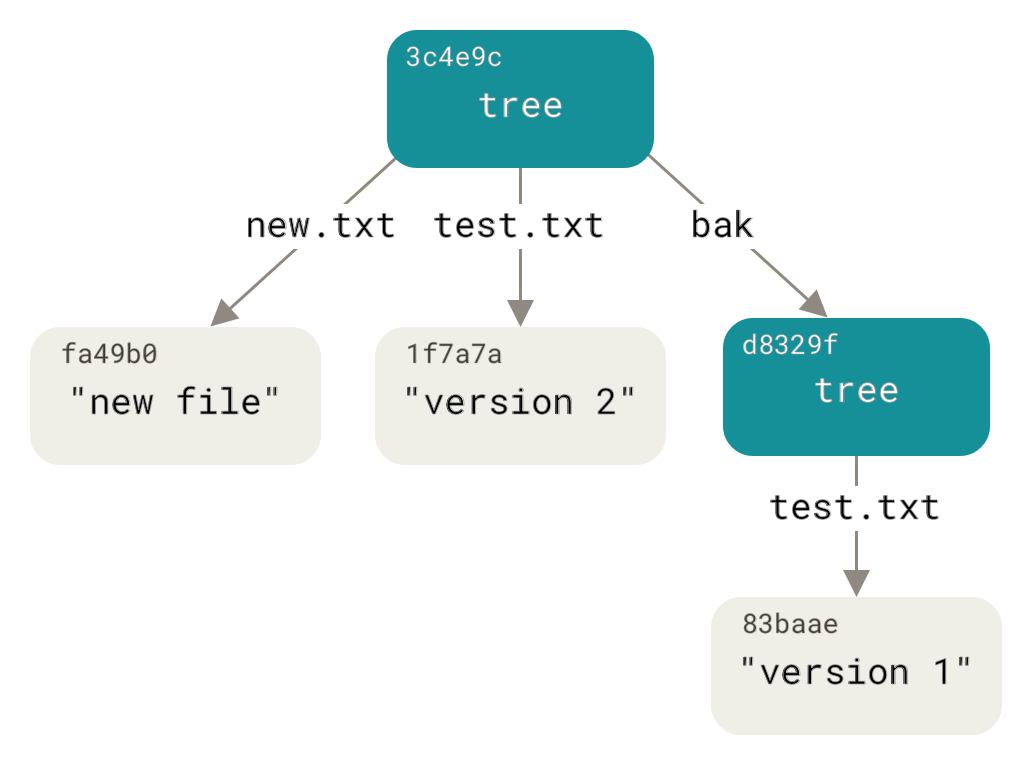
Объекты коммитов
У вас есть три дерева, соответствующих разным состояниям проекта, но предыдущая проблема с необходимостью запоминать все три значения SHA-1, чтобы иметь возможность восстановить какое-либо из этих состояний, ещё не решена. К тому же у нас нет никакой информации о том, кто, когда и почему сохранил их. Такие данные — основная информация, хранимая в объекте коммита.
Для создания коммита необходимо вызвать команду commit-tree и задать SHA-1 нужного дерева и, если необходимо, родительские коммиты. Начнём с создания коммита для самого первого дерева:
Полученный вами хеш будет отличаться, так как отличается дата создания и информация об авторе. Далее в этой главе используйте собственные хеши коммитов и тегов. Просмотреть созданный объект коммита можно командой cat-file :
Формат объекта коммита прост: в нём указано дерево верхнего уровня, соответствующее состоянию проекта на некоторый момент; родительские коммиты, если существуют (в примере выше объект коммита не имеет родителей); имена автора и коммиттера (берутся из полей конфигурации user.name и user.email ) с указанием временной метки; пустая строка и сообщение коммита.
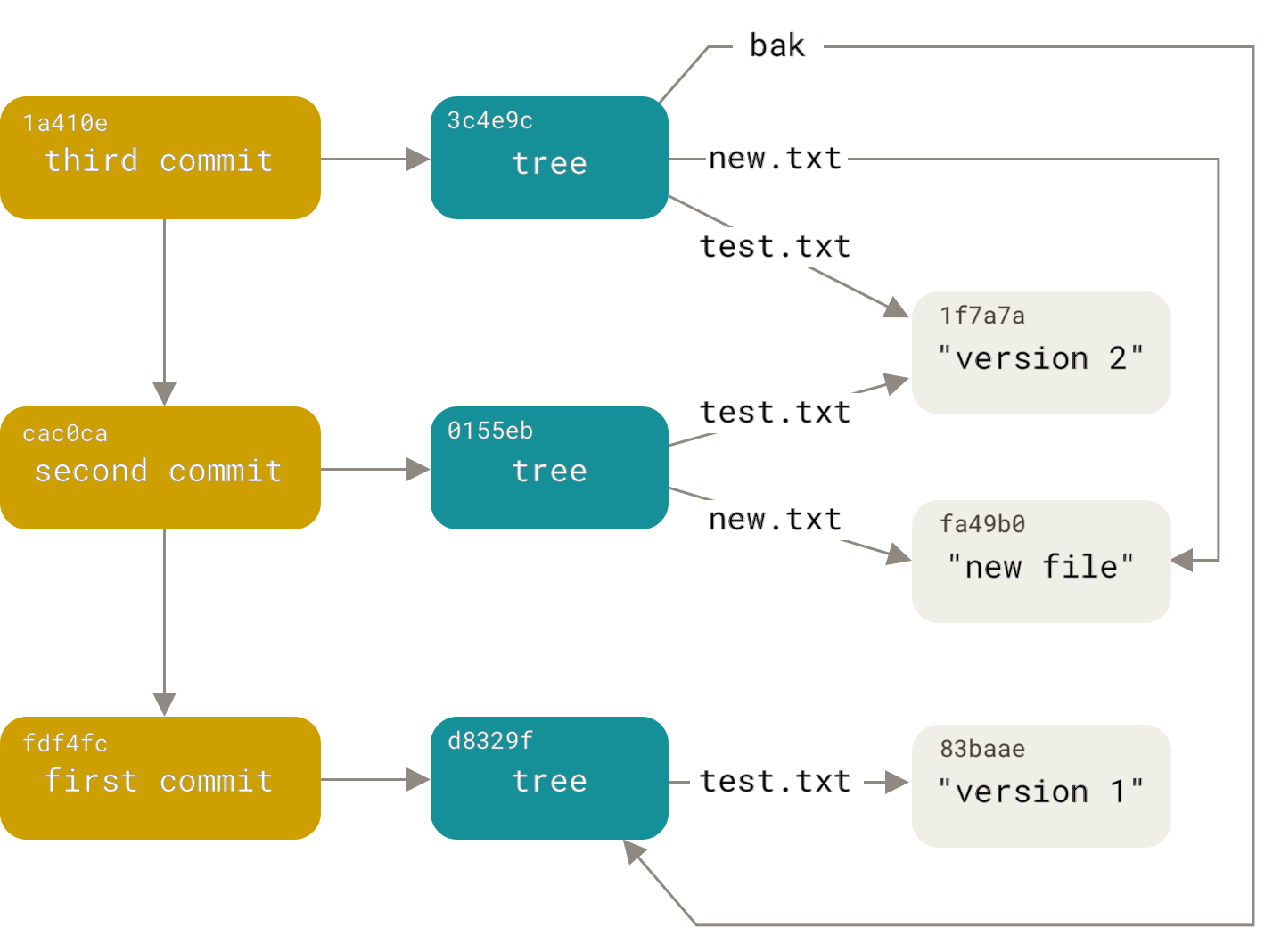
Далее, создадим ещё два объекта коммита, каждый из которых будет ссылаться на предыдущий:
Если пройти по всем внутренним ссылкам, получится граф объектов, представленный на рисунке:
Хранение объектов
Ранее мы упоминали, что вместе с содержимым объекта сохраняется дополнительный заголовок. Давайте посмотрим, как Git хранит объекты на диске. Мы рассмотрим как происходит сохранение блоб объекта — в данном случае это будет строка «what is up, doc?» — в интерактивном режиме на языке Ruby.
Для запуска интерактивного интерпретатора воспользуйтесь командой irb :
Git создаёт заголовок, начинающийся с типа объекта, в данном случае это блоб. Далее идут пробел, размер содержимого в байтах и в конце нулевой байт:
Git объединяет заголовок и оригинальный контент, а затем вычисляет SHA-1 сумму от полученного результата. В Ruby значение SHA-1 для строки можно получить, подключив соответствующую библиотеку командой require и затем вызвав Digest::SHA1.hexdigest() :
Git сжимает новые данные при помощи zlib, в Ruby это можно сделать с помощью одноимённой библиотеки. Сперва необходимо подключить её, а затем вызвать Zlib::Deflate.deflate() :
Теперь проверим содержимое объекта с помощью git cat-file :
Вот и всё, мы создали корректный блоб объект для Git.
Все другие объекты создаются аналогичным образом, меняется лишь запись о типе в заголовке: «blob», «commit» либо «tree». Стоит добавить, что блоб может иметь практически любое содержимое, однако содержимое объектов деревьев и коммитов записывается в очень строгом формате.
Внутреннее устройство Git: хранение данных и merge
О статье
Материал ориентирован прежде всего на читателей, умеющих работать с Git на уровне обычного пользователя и знающих основные концепции работы с ним. Возможно, статья не будет содержать ничего нового для разработчиков систем контроля версий, поддерживающих легкое создание веток и их надежное слияние. Вся информация взята из открытых источников, в том числе из исходных текстов Git (2d242fb3fc19fc9ba046accdd9210be8b9913f64).
Хранение данных: объекты
Узнать тип объекта можно, набрав
Также хранение объектов целиком позволяет делать надежное слияние веток с разрешением конфликтов. Но об этом чуть позже.
Tree (иерархия ФС)
объекте типа дерево (англ. tree) хранится список записей, который соответствует иерархии файловой системы. Одна запись представляет из себя следующее:
Права файла в Git могут иметь лишь очень ограниченный набор значений:
040000 — директория;
100644 — обычный файл;
100755 — файл с правами исполнения;
120000 — символическая ссылка.
Тип объекта — это BLOB или tree, для файла и директории соответственно. То есть в объекте типа tree для корневой директории хранится вся иерархия файловой системы, поскольку внутри одного дерева могут быть ссылки на другие деревья.
Commit
В Git один коммит (англ. сommit) представляет из себя ссылку на объект tree, соответствующий корневой директории, и ссылку на родительский коммит (кроме самого первого коммита в репозитории). Также в коммите есть информация об авторе и UNIX timestamp от времени создания.
Pack-файлы
«. It’s worth explaining (you are probably aware of it, but
let me go through the basics anyway) how git delta-chains work, and how
they are so different from most other systems.
In other SCM’s, a delta-chain is generally fixed. It might be «forwards»
or «backwards», and it might evolve a bit as you work with the repository,
but generally it’s a chain of changes to a single file represented as some
kind of single SCM entity. In CVS, it’s obviously the *,v file, and a lot
of other systems do rather similar things.
Git also does delta-chains, but it does them a lot more «loosely». There
is no fixed entity. Delta’s are generated against any random other version
that git deems to be a good delta candidate (with various fairly
successful heursitics), and there are absolutely no hard grouping rules.
It also means that the choice of deltas is a much more open-ended
question. If you limit the delta chain to just one file, you really don’t
have a lot of choices on what to do about deltas, but in git, it really
can be a totally different issue».
Если кратко, то в pack-файлах объекты группируются по схожести (например, тип и размер), после чего они сохраняются в виде «цепочек». Первый элемент цепочки представляет из себя самую новую версию объекта, а следующий за ним являются диффом к предыдущему. Самые новые версии объекта считаются наиболее запрашиваемыми, поэтому они хранятся выше в цепочке.
Таким образом, Git всё же хранит диффы, но только на уровне непосредственного хранения данных. С точки зрения любого API уровнем выше, Git оперирует объектами целиком, что позволяет реализовывать различные стратегии слияния и легко разрешать конфликты.
Хранение истории
В Git нет отдельного хранилища истории. Всю историю можно развернуть, но лишь пройдя по ссылкам на родителя из нужного вам коммита. Если необходимо просмотреть историю только по одному файлу (или по поддиректории), Git всё равно должен проделать то же самое, но он будет возвращать отфильтрованные результаты. Стоит иметь это ввиду, когда вы делаете интеграцию с Git, и не заставлять Git делать полный просмотр истории на каждый файл.
К тому же, как вы могли заметить, Git не хранит информацию о переименовании файлов. Если нужно понять, переименован файл или нет, Git производит анализ содержимого хранящихся у него объектов и с некоторым (настраиваемым) допуском считает, что файл был переименован.
Merge: трехстороннее слияние (стратегия resolve)
Если нужно выполнить слияние двух веток, то git по умолчанию использует стратегию recursive, но о ней чуть позже. До того, как появилась эта стратегия, использовалась стратегия resolve, которая представляет из себя трехстороннее слияние. Для того, чтобы выполнить такое слияние, нужно иметь 3 версии: общий родитель, версия из одной ветки и версия из другой ветки. Если вы выполняете слияние файлов, то такое трехсторонее слияние может выполняться утилитой diff3, которая входит в стандартный пакет diffutils. Эта скромная и редко упоминаемая утилита, так или иначе, делает всю «грязную работу» по слиянию в большинстве существующих систем контроля версий, включая RCS, CVS, SVN и, конечно же, Git.
Помимо использования аналога diff3 (конкретная реализация, используемая в Git — это LibXDiff), Git также «на лету» вычисляет переименования файлов и использует эту информацию для слияния tree-объектов. Слияние иерархий директорий не представляет из себя ничего принципиально сложного по сравнению с тем, чтобы выполнить слияние файлов, но порождает очень много различных видов конфликтов.
Небольшая иллюстрация того, как Git выполняет трехстороннее слияние в простом случае (взято из man git-merge):
Предположим, у нас есть такая история и текущая ветка — master:
Тогда git merge topic повторит изменения, сделанные в topic начиная с коммита, когда история разветвилась (коммит E), и создаст новый коммит H, у которого будет два родителя, и сообщение коммита, которое предоставит пользователь.
Тем не менее разработка в ветках topic и master может быть продолжена, и тогда слияние уже не будет выглядеть так просто: у нас может быть больше, чем один коммит, который подходит под определение «общий предок»:
Если мы будем использовать стратегию resolve, то будет выбран самый старый общий предок (коммит E). Если в результате выполнения merge были конфликты, разрешённые в коммите H, нам всё равно нужно будет разрешать их ещё раз.
Для выполнения слияния с помощью стратегии resolve Git возьмет коммит E в качестве общего предка и коммиты M и P в качестве двух новых версий. Если в коммите C был конфликт, то конфликтующие изменения можно откатить с помощью git revert (например, это проделано в коммите K), тогда конечное состояние M уже не будет содержать в себе конфликта, и при слиянии конфликтов тоже не будет.
Merge made by the ‘recursive’ strategy
Представим себе такую историю:
Результатом выполнения этой операции будет виртуальный коммит, который представляет из себя «смерженное» состояние всех общих предков в правильном порядке — разрешение конфликтов тоже попадет в этот коммит, причем более свежие коммиты будут иметь приоритет. Когда мы получили общего предка, выполняется трехсторонее слияние, описанное выше.
Выдержка из merge-recursive.c:
Низкоуровневые команды Git
Если вы работали какое-то время с Git, то вы наверняка знаете о командах checkout, branch, pull, push, rebase, commit и некоторых других. Но изначально Git создавался не как полноценная система контроля версий, а как фреймворк для её создания. Поэтому в Git есть очень богатый набор встроенных команд, которые работают на низком уровне. Приведем некоторые из них, весьма полезные, на наш взгляд:
git rev-parse
Эта команда является очень простой: она возвращает хеш коммита для указанной ревизии. Например, git rev-parse HEAD вернет хеш коммита, на который указывает HEAD.
Подводные камни: Что касается запросов вида branch ^other_branch, Git может неправильно вывести результаты, если у коммитов стоит неправильное время. Например, в выводе могут быть пропущены коммиты, которые «произошли в будущем» по сравнению с merge ветки.
git diff-index
Показывает разницу между рабочей копией и индексом (.git/index). В индексе Git хранит кеш lstat() от всех файлов, о которых он знает.
git cat-file
Эта команда уже встречалась в статье, но её всё же стоит упомянуть ещё раз. Она позволяет получить содержимое коммита и любого другого объекта Git.
git ls-tree
Выводит содержимое tree-объекта в приемлемом виде.
git ls-remote
Выводит информацию о ветках и тегах (вместе с хешами коммитов) из указанного удаленного репозитория.
GIT_SSH
Если вы писали скрипты, которые делают git pull, то скорее всего сталкивались с тем, что SSH запрашивает подтверждение «аутентичности» удаленного репозитория, причём делает это интерактивно. Решение этой проблемы не столь изящное, потому что GIT_SSH должен быть путем к исполняемому файлу (а не опции SSH):
Заключение
Как можно было увидеть, Git позволяет действительно хорошо и надежно работать с ветками, в том числе корректно обрабатывать ситуации, когда у двух веток есть более одного общего предка. Если только вашей целью не является написание своей системы контроля версий, мы бы рекомендовали использовать результаты работы Git, а не пытаться воспроизвести его алгоритм слияния.
Надеемся, данный материал оказался интересным для вас и позволил понять, почему Git работает именно так, а не иначе. Полагаем, что статья будет также полезной для разработчиков различных интерфейсов к Git, приводя к более глубокому пониманию того, что же происходит «под капотом».
Юрий Насретдинов, разработчик Badoo
Коммиты — это снимки, а не различия

Git имеет репутацию запутывающего инструмента. Пользователи натыкаются на терминологию и формулировки, которые вводят в заблуждение. Это более всего проявляется в «перезаписывающих» историю командах, таких как git cherry-pick или git rebase. По моему опыту, первопричина путаницы — интерпретация коммитов как различий, которые можно перетасовать. Однако коммиты — это не различия, а снимки! Я считаю, что Git станет понятным, если поднять занавес и посмотреть, как он хранит данные репозитория. Изучив модель хранения данных мы посмотрим, как новый взгляд помогает понять команды, такие как git cherry-pick и git rebase.
Если хочется углубиться по-настоящему, читайте главу о внутренней работе Git (Git internals) книги Pro Git. Я буду работать с репозиторием git/git версии v2.29.2. Просто повторяйте команды за мной, чтобы немного попрактиковаться.
Хеши — идентификаторы объектов
Самое важное, что нужно знать о Git-объектах, — это то, что Git ссылается на каждый из них по идентификатору объекта (OID для краткости), даёт объекту уникальное имя.
Мы привыкли к тому, что OID даны в виде укороченной шестнадцатеричной строки. Строка рассчитана так, чтобы только один объект в репозитории имел совпадающий с ней OID. Если запросить объект слишком коротким OID, мы увидим список соответствующих подстроке OID.
Блобы — это содержимое файлов
На нижнем уровне объектной модели блобы — содержимое файла. Чтобы обнаружить OID файла текущей ревизии, запустите git rev-parse HEAD:
Если я отредактирую файл README.md на моём диске, то git status предупредит, что файл недавно изменился, и хэширует его содержимое. Когда содержимое файла не совпадает с текущим OID в HEAD:README.md, git status сообщает о файле как о «модифицированном на диске». Таким образом видно, совпадает ли содержимое файла в текущей рабочей директории с ожидаемым содержимым в HEAD.
Деревья — это списки каталогов
Обратите внимание, что блобы хранят содержание файла, но не его имя. Имена берутся из представления каталогов Git — деревьев. Дерево — это упорядоченный список путей в паре с типами объектов, режимами файлов и OID для объекта по этому пути. Подкаталоги также представлены в виде деревьев, поэтому деревья могут указывать на другие деревья!
Воспользуемся диаграммами, чтобы визуализировать связи объектов между собой. Красные квадраты — наши блобы, а треугольники — деревья.
Деревья дают названия каждому подпункту и также содержат такую информацию, как разрешения на файлы в Unix, тип объекта (blob или tree) и OID каждой записи. Мы вырезаем выходные данные из 15 верхних записей, но можем использовать grep, чтобы обнаружить, что в этом дереве есть запись README.md, которая указывает на предыдущий OID блоба.
При помощи путей деревья могут указывать на блобы и другие деревья. Имейте в виду, что эти отношения идут в паре с именами путей, но мы не всегда показываем эти имена на диаграммах.
Само дерево не знает, где внутри репозитория оно находится, то есть указывать на дерево — роль объектов. Дерево, на которое ссылается ^
Коммиты — это снапшоты
Коммит — это снимок во времени. Каждый содержит указатель на своё корневое дерево, представляющее состояние рабочего каталога на момент снимка.
В коммите есть список родительских коммитов, соответствующих предыдущим снимкам. Коммит без родителей — это корневой коммит, а коммит с несколькими родителями — это коммит слияния.
Коммиты также содержат метаданные, которые описывают снимки, например автора и коммиттера (включая имя, адрес электронной почты и дату) и сообщение о коммите. Сообщение о коммите для автора коммита — это возможность описать цель коммита по отношению к родителям.
Например, коммит в v2.29.2 в Git-репозитории описывает этот релиз, также он авторизован, а его автор — член команды разработки Git.
Заглянув немного дальше в историю при помощи git log, мы увидим более подробное сообщение о коммите, оно рассказывает об изменении между этим коммитом и его родителем.
Круги на диаграммах будут представлять коммиты:
Квадраты — это блобы. Они представляют содержимое файла.
Треугольники — это деревья. Они представляют каталоги.
Круги — это коммиты. Снапшоты во времени.
Ветви — это указатели
В Git мы перемещаемся по истории и вносим изменения, в основном не обращаясь к OID. Это связано с тем, что ветви дают указатели на интересующие нас коммиты. Ветка с именем main — на самом деле ссылка в Git, она называется refs/heads/main. Файлы ссылок буквально содержат шестнадцатеричные строки, которые ссылаются на OID коммита. В процессе работы эти ссылки изменяются, указывая на другие коммиты.
Это означает, что ветки существенно отличаются от Git-объектов. Коммиты, деревья и блобы неизменяемы (иммутабельны), это означает, что вы не можете изменить их содержимое. Изменив его, вы получите другой хэш и, таким образом, новый OID со ссылкой на новый объект!
Общая картина
Посмотрим на всю картину. Ветви указывают на коммиты, коммиты — на другие коммиты и их корневые деревья, деревья указывают на блобы и другие деревья, а блобы не указывают ни на что. Вот диаграмма со всеми объектами сразу:
Время на диаграмме отсчитывается слева направо. Стрелки между коммитом и его родителями идут справа налево. У каждого коммита одно корневое дерево. HEAD указывает здесь на ветку main, а main указывает на самый недавний коммит.
Корневое дерево у этого коммита раскинулось полностью под ним, у остальных деревьев есть указывающие на эти объекты стрелки, потому что одни и те же объекты доступны из нескольких корневых деревьев! Эти деревья ссылаются на объекты по их OID (их содержимое), поэтому снимкам не нужно несколько копий одних и тех же данных. Таким образом, объектная модель Git образует дерево хешей.
Рассматривая объектную модель таким образом, мы видим, почему коммиты — это снимки: они непосредственно ссылаются на полное представление рабочего каталога коммита!
Вычисление различий
Несмотря на то, что коммиты — это снимки, мы часто смотрим на коммит в его историческом представлении или видим его на GitHub как diff. На самом же деле сообщение о коммите часто ссылается на различие. генерируемое динамически из данных снимка путём сравнения корневых деревьев коммита и его родителя. Git может сравнить не только соседние снимки, но и два любых снимка вообще.
Чтобы сравнить два коммита, сначала рассмотрите их корневые деревья, которые почти всегда отличаются друг от друга. Затем в поддеревьях выполните поиск в глубину, следуя по парам, когда пути для текущего дерева имеют разные OID.
В примере ниже корневые деревья имеют разные значения для docs, поэтому мы рекурсивно обходим их. Эти деревья имеют разные значения для M.md, таким образом, два блоба сравниваются построчно и отображается их различие. Внутри docs N.md по-прежнему тот же самый, так что пропускаем их и возвращаемся к корневому дереву. После этого корневое дерево видит, что каталоги things имеют одинаковые OID, так же как и записи README.md.
На диаграмме выше мы заметили, что дерево things не посещается никогда, а значит, не посещается ни один из его достижимых объектов. Таким образом, стоимость вычисления различий зависит от количества путей с разным содержимым.
Теперь, когда понятно, что коммиты — это снимки, можно динамически вычислять разницу между любыми двумя коммитами. Почему тогда этот факт не общеизвестен? Почему новые пользователи натыкаются на идею о том, что коммит — это различие?
Одна из моих любимых аналогий — дуализм коммитов как дуализм частиц, при котором иногда коммиты рассматриваются как снимки, а иногда — как различия. Суть дела в другом виде данных, которые не являются Git-объектами — в патчах.
Подождите, а что такое патч?
Патч — это текстовый документ, где описывается, как изменить существующую кодовую базу. Патчи — это способ самых разрозненных команд делиться кодом без коммитов в Git. Видно, как патчи перетасовываются в списке рассылки Git.
Патч содержит описание изменения и причину ценности этого изменения, сопровождаемые выводом diff. Идея такова: некий разработчик может рассматривать рассуждение как оправдание применения патча, отличающегося от копии кода нашего разработчика.
Git может преобразовать коммит в патч командой git format-patch. Затем патч может быть применён к Git-репозиторию командой git apply. В первые дни существования открытого исходного кода такой способ обмена доминировал, но большинство проектов перешли на обмен коммитами непосредственно через пул-реквесты.
Самая большая проблема с тем, чтобы делиться исправлениями, в том, что патч теряет родительскую информацию, а новый коммит имеет родителя, который одинаков с вашим HEAD. Более того, вы получаете другой коммит, даже если работаете с тем же родителем, что и раньше, из-за времени коммита, но при этом коммиттер меняется! Вот основная причина, по которой в объекте коммита Git есть разделение на «автора», и «коммиттера».
Самая большая проблема в работе с патчами заключается в том, что патч трудно применить, когда ваш рабочий каталог не совпадает с предыдущим коммитом отправителя. Потеря истории коммитов затрудняет разрешение конфликтов.
Идея перемещения патчей с места на место перешла в несколько команд Git как «перемещение коммитов». На самом же деле различие коммитов воспроизводится, создавая новые коммиты.
Если коммиты — это не различия, что делает git cherry-pick?
Вычисляет разницу между коммита и его родителя.
Применяет различие к текущему HEAD.
Создаёт новый коммит, корневое дерево которого соответствует новому рабочему каталогу, а родитель созданного коммита — HEAD.
Перемещает ссылку HEAD в этот новый коммит.
Важно понимать, что мы не «перемещали» коммит так, чтобы он был поверх нашего текущего HEAD, мы создали новый коммит, и его вывод diff совпадает со старым коммитом.
А что делает git rebase?
Команда git rebase — это способ переместить коммиты так, чтобы получить новую историю. В простой форме это на самом деле серия команд git cherry-pick, которая воспроизводит различия поверх другого, отличного коммита.
Затем команда rebase просто переходит в местоположению и выполняет команды git cherry-pick в этом диапазоне коммитов, начиная со старых. В конце мы получили новый набор коммитов с разными OID, но схожих с первоначальным диапазоном.
Для примера рассмотрим последовательность из трёх коммитов в текущей ветке HEAD с момента разветвления target. При запуске git rebase target, чтобы определить список коммитов A, B, и C, вычисляется общая база P. Затем поверх target они выбираются cherry-pick, чтобы создать новые коммиты A’, B’ и C’.
Коммиты A’, B’ и C’ — это совершенно новые коммиты с общим доступом к большому количеству информации через A, B и C, но они представляют собой отдельные новые объекты. На самом деле старые коммиты существуют в вашем репозитории до тех пор, пока не начнётся сбор мусора.
С помощью команды git range-diff мы даже можем посмотреть на различие двух диапазонов коммитов! Я использую несколько примеров коммитов в репозитории Git, чтобы сделать rebase на тег v2.29.2, а затем слегка изменю описание коммита.
Обратите внимание: результирующий range-diff утверждает, что коммиты 17e7dbbcbc и 2aa8919906 «равны», а это означает, что они будут генерировать один и тот же патч. Вторая пара коммитов различается: показано, что сообщение коммита изменилось, есть правка в README.md, которой не было в исходном коммите.
Если пройти вдоль дерева, вы увидите, что история коммитов всё ещё существует у обоих наборов коммитов. Новые коммиты имеют тег v2.29.2 — в истории это третий коммит, тогда как старые имеют тег v2.28.0 — болеее ранний, а в истории он также третий.
Если коммиты – не отличия, тогда как Git отслеживает переименования?
Внимательно посмотрев на объектную модель, вы заметите, что Git никогда не отслеживает изменения между коммитами в сохранённых объектных данных. Можно задаться вопросом: «Откуда Git знает, что произошло переименование?»
Git не отслеживает переименования. В нём нет структуры данных, которая хранила бы запись о том, что между коммитом и его родителем имело место переименование.
Вместо этого Git пытается обнаружить переименования во время динамического вычисления различий. Есть два этапа обнаружения переименований: именно переименования и редактирования.
После первого вычисления различий Git исследует внутренние различия, чтобы обнаружить, какие пути добавлены или удалены. Естественно, что перемещение файла из одного места в другое будет выглядеть как удаление из одного места и добавление в другое. Git попытается сопоставить эти действия, чтобы создать набор предполагаемых переименований.
На первом этапе этого алгоритма сопоставления рассматриваются OID добавленных и удалённых путей и проверяется их точное соответствие. Такие точные совпадения соединяются в пары.
Вторая стадия — дорогая часть вычислений: как обнаружить файлы, которые были переименованы и отредактированы? Посмотреть каждый добавленный файл и сравните этот файл с каждым удалённым, чтобы вычислить показатель схожести в процентах к общему количеству строк. По умолчанию что-либо, что превышает 50 % общих строк, засчитывается как потенциальное редактирование с переименованием. Алгоритм сравнивает эти пары до момента, пока не найдёт максимальное совпадение.
Вы заметили проблему? Этот алгоритм прогоняет A * D различий, где A — количество добавлений и D — количество удалений, то есть у него квадратичная сложность! Чтобы избежать слишком долгих вычислений по переименованию, Git пропустит часть с обнаружением редактирований с переименованием, если A + D больше внутреннего лимита. Ограничение можно изменить настройкой опции diff.renameLimit в конфигурации. Вы также можете полностью отказаться от алгоритма, просто отключив diff.renames.
Я воспользовался знаниями о процессе обнаружения переименований в своих собственных проектах. Например, форкнул VFS for Git, создал проект Scalar и хотел повторно использовать большое количество кода, но при этом существенно изменить структуру файла. Хотелось иметь возможность следить за историей версий в VFS for Git, поэтому рефакторинг состоял из двух этапов:
, чтобы посмотреть историю переименовывания.
Я сократил вывод: два этих последних коммита на самом деле не имеют пути, соответствующего Scalar/CommandLine/ScalarVerb.cs, вместо этого отслеживая предыдущий путь GVSF/GVFS/CommandLine/GVFSVerb.cs, потому что Git распознал точное переименование содержимого из коммита fb3a2a36 [RENAME] Rename all files.
Не обманывайтесь больше
Теперь вы знаете, что коммиты — это снапшоты, а не различия! Понимание этого поможет вам ориентироваться в работе с Git.
И теперь мы вооружены глубокими знаниями объектной модели Git. Не важно, какая у вас специализация, frontend, backend, или вовсе fullstack — вы можете использовать эти знания, чтобы развить свои навыки работы с командами Git’а или принять решение о рабочих процессах в вашей команде. А к нам можете приходить за более фундаментальными знаниями, чтобы иметь возможность повысить свою ценность как специалиста или вовсе сменить сферу.
Узнайте, как прокачаться в других специальностях или освоить их с нуля:



