Анализ малых данных
КвазиНаучный блог Александра Дьяконова
Знакомьтесь, Джини
Многие путаются в коэффициентах Джини, не понимают, что они бывают разные и для разных задач (и названия у них разные — просто в русском переводе, как всегда, многое схлопывается в один термин).
Есть коэффициент/индекс Джини (Gini coefficient), который используют при оценке качества классификации и регрессии. На русской странице Wiki не очень информативно, но вот на английской всё подробно: изначально это был статистический показатель степени расслоения общества данной страны или региона по отношению к какому-либо изучаемому признаку. Вычисляется как отношение площади фигуры, образованной кривой Лоренца и кривой равенства, к площади треугольника, образованного кривыми равенства и неравенства. Сейчас поясню.
Допустим, в компании работают 4 человека с суммарным доходом 8000$. Равномерное распределение дохода — это 2000$+2000$+2000$+2000$, неравномерное — 0$+0$+0$+8000$. А как оценить неравномерность, скажем, для случая 1000$+1000$+2000$+4000$? Упорядочим сотрудников по возрастанию дохода. Построим кривую (Лоренца) в координатах [процент населения, процент дохода этого населения] — идём по всем сотрудникам и откладывает точки. Для первого — [25%, 12.5%] — это сколько он составляет процентов от всего штата и сколько процентов составляет его доход, для первого и второго — [50%, 25%] — это сколько они составляют процентов и сколько процентов их доход, для первых трёх — [75%, 50%], для всех — [100%, 100%].
 Рис. 1. Вычисление gini с помощью кривой Лоренца
Рис. 1. Вычисление gini с помощью кривой Лоренца
На. Рис. 1. построенная кривая Лоренца показана красным цветом. Кривая Лоренца, которая соответствует равномерному распределению дохода, — синяя диагональ (т.н. кривая равенства). Кривая Лоренца, которая соответствует неравномерному распределению, — зелёная (т.н. кривая неравенства). Вот площадь A, делённая на A+B=0.5, и есть коэффициент Gini.
При оценке качества классификации GINI = 2*AUCROC-1. Про AUCROC я уже как-то писал. Почему это они так связаны нигде подробно не описано. Я нашёл упоминание в работе Supervised Classification and AUC. Там всё логично: если в задаче классификации на два класса 0 и 1 интерпретировать эти числа как доходы. Но чтобы связь была именно GINI = 2*AUCROC-1, должно быть что-то типа рис. 2 (но ROC-кривая и кривая Лоренца это не одно и то же), кстати в презентации Credit Scoring and the Optimization concerning Area under the curve такая же картинка.
 Рис.2. Связь AUCROC и GINI.
Рис.2. Связь AUCROC и GINI.
Есть ещё коэффициент/индекс Джини (Gini impurity), который используется в решающих деревьях при выборе расщепления. Я дал ссылку на английскую Wiki, поскольку русского аналога нет. Он тоже измеряет «равномерность», если p_i — частоты представителей разных классов в листе дерева, то коэффициент Джини для него равен

Только вот это другая равномерность, никак не связанная с рассмотренной ранее. Для первой нужно два показателя — доход и численность населения с таким доходом, а тут только проценты (частоты). В английской версии на странице Gini coefficient написано «не путать с Gini impurity» и наоборот.
Я не знаю, как лучше переводить impurity, скажем, С.П.Чистяков переводит как «загрязненность» (на мой взгляд, не очень звучит…).
Коррадо Джини (Corrado Gini, 1884), который всё это придумал был итальянским статистиком. Но кроме этого, он известный идеолог фашизмa, написал книгу «Научные основы фашизма». Прожил, кстати, довольно много — 80 лет, видимо, после войны не преследовался. Вот так бывает…
Коэффициент Джини — индекс концентрации доходов, справедливости и неравенства
Здравствуйте, уважаемые читатели проекта Тюлягин! В данной статье мы поговорим о таком понятии и показателе как коэффициент (индекс) Джини. В статье вы узнаете что такое индекс Джини и что измеряет и показывает коэффициент. Также вы узнаете как отображается коэффициент Джини на графике и как связан с кривой Лоренца. Кроме этого в статье приведены данные по коэффициенту Джини для стран мира, а также перечислены основные недостатки индекса.

Содержание статьи:
Что такое коэффициент / индекс Джини?
Индекс Джини, или коэффициент Джини, представляет собой меру распределения доходов среди населения, разработанный итальянским статистиком Коррадо Джини в 1912 году. Он часто используется в качестве индикатора экономического неравенства, измерения распределения доходов или, реже, распределения богатства. среди населения. Коэффициент варьируется от 0 (или 0%) до 1 (или 100%), где 0 означает полное равенство, а 1 — полное неравенство. Значения больше 1 теоретически возможны из-за отрицательного дохода или богатства.
Суть коэффициента Джини
В стране, в которой каждый житель имеет одинаковый доход, коэффициент Джини дохода будет равен 0. Страна, в которой один резидент получил весь доход, а все остальные ничего не заработал, будет иметь коэффициент Джини дохода, равный 1.
Тот же анализ может быть применен к распределению богатства («коэффициент Джини богатства»), но поскольку богатство труднее измерить, чем доход, коэффициенты Джини обычно относятся к доходу и выглядят просто как «коэффициент Джини» или «индекс Джини», без указания того, что они относятся к доходу. Коэффициенты богатства Джини, как правило, намного выше, чем для дохода.
Коэффициент Джини — важный инструмент для анализа распределения доходов или богатства в стране или регионе, но его не следует принимать за абсолютное измерение дохода или богатства. По данным ОЭСР, в стране с высоким и низким уровнем доходов может быть один и тот же коэффициент Джини, если доходы распределяются одинаково внутри каждой из них: в Турции и США в 2016 году коэффициенты Джини по доходам составляли около 0,39-0,40. Однако, ВВП Турции на душу населения был менее половины ВВП США (в долларовом выражении 2010 года).
Графическое представление индекса Джини
Индекс Джини часто представляется графически через кривую Лоренца, которая показывает распределение доходов (или богатства) путем нанесения процентиля населения по доходу на горизонтальную ось и совокупного дохода на вертикальной оси. Коэффициент Джини равен площади под линией полного равенства (0,5 по определению) за вычетом площади под кривой Лоренца, деленной на площадь под линией полного равенства. Другими словами, это вдвое больше площади между кривой Лоренца и линией полного равенства.
На приведенном ниже графике 47-й процентиль соответствует 10,46% в Гаити и 17,42% в Боливии, что означает, что нижние 47% гаитян получают 10,46% от общего дохода своей страны, а нижние 47% боливийцев получают 17,42% их дохода. Прямая линия представляет гипотетически равноправное по доходам общество: нижние 47% граждан получают 47% национального дохода.
Чтобы оценить коэффициент Джини дохода для Гаити в 2012 году, мы найдем площадь под кривой Лоренца: около 0,2. Вычитая это число из 0,5 (площадь под линией равенства), мы получаем 0,3, которое затем делим на 0,5. Это дает приблизительный коэффициент Джини 0,6 или 60%. Данные Всемирного Банка дают фактический коэффициент Джини для Гаити в 2012 году как 60,8%. Эта цифра представляет собой чрезвычайно высокое неравенство. По данным ЦРУ, только Микронезия, Центральноафриканская Республика (ЦАР), Южная Африка и Лесото имеют еще большее неравенство.
Другой способ восприятия коэффициента Джини — это показатель отклонения от идеального равенства. Чем дальше кривая Лоренца отклоняется от идеально равной прямой линии (которая представляет собой коэффициент Джини, равный 0), тем выше коэффициент Джини и тем меньше равноправия в обществе. В приведенном выше примере Гаити более неравное, чем Боливия.
Коэффициент Джини в мире
Глобальный Джини
По оценкам Кристофа Лакнера из Всемирного банка и Бранко Милановича из Городского университета Нью-Йорка, коэффициент Джини для глобального дохода составлял 0,705 в 2008 году по сравнению с 0,722 в 1988 году. Однако цифры значительно различаются. По оценкам экономистов DELTA Франсуа Бургиньон и Кристиан Морриссон, этот показатель составлял 0,657 как в 1980, так и в 1992 году. Работа Бургиньона и Морриссона показывает устойчивый рост неравенства с 1820 года, когда глобальный коэффициент Джини составлял 0,500. Книга Лакнера и Милановича показывает снижение неравенства примерно в начале 21 века, как и книга Бургиньона 2015 года:
 Источник: Всемирный банк.
Источник: Всемирный банк.
Экономический рост в Латинской Америке, Азии и Восточной Европе во многом стал причиной недавнего снижения неравенства доходов. В то время как неравенство между странами в последние десятилетия снизилось, неравенство внутри стран возросло.
Коэффициент Джини для стран мира
Ниже приведены коэффициенты Джини дохода для каждой страны, данные по которой представлены Всемирным Банком:
Некоторые из беднейших стран мира (Центральноафриканская Республика) имеют одни из самых высоких в мире коэффициентов Джини (61,3), в то время как многие из самых богатых (Дания) имеют одни из самых низких (28,8). Однако взаимосвязь между неравенством доходов и ВВП на душу населения не является идеальной отрицательной корреляцией, и эта взаимосвязь менялась с течением времени.
Михаил Моатсос из Утрехтского университета и Джоэри Батен из Тюбингенского университета показывают, что с 1820 по 1929 год неравенство несколько увеличивалось, а затем постепенно уменьшалось по мере увеличения ВВП на душу населения. С 1950 по 1970 год неравенство имело тенденцию к снижению, поскольку ВВП на душу населения превышал определенный порог. С 1980 по 2000 год неравенство снизилось с ростом ВВП на душу населения, а затем резко сократилось.
 Три графика, показывающие поведение ВВП в три разных момента времени.
Три графика, показывающие поведение ВВП в три разных момента времени.
Корреляция между коэффициентами Джини и ВВП на душу населения за три периода времени. Источник: Моатсос и Батен.
Недостатки коэффициента Джини
Хотя коэффициент Джини полезен для анализа экономического неравенства, он имеет некоторые недостатки. Точность показателя зависит от достоверных данных о ВВП и доходах. Теневая экономика и неформальная экономическая деятельность присутствуют в каждой стране. Неформальная экономическая деятельность, как правило, составляет большую часть реального экономического производства в развивающихся странах и находится на нижнем уровне распределения доходов внутри стран. В обоих случаях это означает, что индекс измеренных доходов Джини будет завышать истинное неравенство доходов. Получить точные данные о богатстве еще труднее из-за популярности налоговых убежищ (офшорных зон).
Другой недостаток заключается в том, что очень разные распределения доходов могут привести к одинаковым коэффициентам Джини. Поскольку индекс Джини пытается разделить двумерную область (разрыв между кривой Лоренца и линией равенства) до одного числа, он скрывает информацию о «форме» неравенства. В повседневных терминах это было бы похоже на описание содержимого фотографии только по ее длине вдоль одного края или простому среднему значению яркости пикселей.
Хотя использование кривой Лоренца в качестве дополнения может предоставить больше информации в этом отношении, она также не показывает демографические различия между подгруппами внутри распределения, например распределение доходов по возрасту, расе или социальным группам. В этом ключе понимание демографии может быть важным для понимания того, что представляет данный коэффициент Джини. Например, большая часть пенсионеров повышает индекс Джини.
Резюме
А на этом сегодня все про коэффициент (индекс) Джини. Надеюсь статья оказалась для вас полезной. Делитесь статьей в социальных сетях и мессенджерах и добавляйте сайт в закладки. Успехов и до новых встреч на страницах проекта Тюлягин!
Реализация и разбор алгоритма «случайный лес» на Python
Авторизуйтесь
Реализация и разбор алгоритма «случайный лес» на Python

Использование готовых библиотек, таких как Scikit-Learn, позволяет легко реализовать на Python сотни алгоритмов машинного обучения.
В этой статье мы научимся создать и использовать алгоритм «случайный лес» (Random Forest) на Python. Помимо непосредственного изучения кода, мы постараемся понять принципы работы модели. Этот алгоритм составлен из множества деревьев решений, поэтому сначала мы разберёмся, как одно такое дерево решает проблему классификации. После этого с помощью алгоритма решим проблему, используя набор реальных научных данных. Весь код, используемый в этой статье, доступен на GitHub в Jupyter Notebook.
Как работает дерево решений
Дерево решений — интуитивно понятная базовая единица алгоритма случайный лес. Мы можем рассматривать его как серию вопросов да/нет о входных данных. В конечном итоге вопросы приводят к предсказанию определённого класса (или величины в случае регрессии). Это интерпретируемая модель, так как решения принимаются так же, как и человеком: мы задаём вопросы о доступных данных до тех пор, пока не приходим к определённому решению (в идеальном мире).
Базовая идея дерева решений заключается в формировании запросов, с которыми алгоритм обращается к данным. При использовании алгоритма CART вопросы (также называемые разделением узлов) определяются таким образом, чтобы ответы вели к уменьшению загрязнения Джини (Gini Impurity). Это означает, что дерево решений формирует узлы, содержащие большое количество образцов (из набора исходных данных), принадлежащих к одному классу. Алгоритм старается обнаружить параметры со сходными значениями.
Подробности, касающиеся загрязнения Джини, мы обсудим позже, а сейчас давайте создадим дерево решений, чтобы понять, как работает этот алгоритм.
Дерево решений для простой задачи
Начнём с проблемы простой бинарной классификации, изображённой на диаграмме.
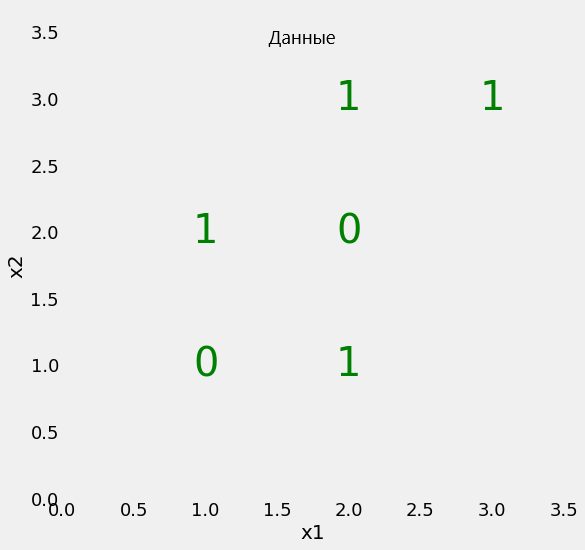
Наш набор данных имеет всего два параметра (две заданные переменные), x1 и x2, а также 6 образцов, несущих эти параметры. Образцы разделены метками на два класса. Хотя это простая задача, линейно классы разделить невозможно. Это означает, что мы не можем нарисовать на предложенной плоскости прямую линию, которая отделит один класс от другого.
В то же время мы можем разбить плоскость на участки (узлы) несколькими прямыми линиями. Именно это делает дерево решений в процессе тренировки. По сути дерево решений — нелинейная модель, создаваемая с помощью множества линейных ограничителей.
Мы используем Scikit-Learn, чтобы создать дерево решений и обучить ( fit ) его, используя наши данные.
Во время обучения мы используем и параметры, и метки, чтобы модель научилась сортировать данные на основе параметров. Для таких простых задач не используется тестовый набор данных. Но при тестировании модели мы сообщаем только параметры и сравниваем результат сортировки с теми метками, которые ожидали получить.
Можно проверить точность предсказаний нашей модели:
Разумеется, мы получим точность 100 %, так как сообщили модели правильные ответы ( y ) и не ограничивали глубину дерева. Но следует помнить, что подобная подгонка дерева решений под тренировочные данные может спровоцировать переобучение модели.
Визуализация дерева решений
Что же на самом деле происходит при обучении дерева решений? Хороший способ понять это — визуализация модели при помощи соответствующей функции Scikit-Learn (подробнее функция рассматривается в данной статье).

Во всех узлах, кроме листьев (цветные узлы без исходящих связей), содержится 5 частей:
Листья не содержат вопроса, так как являются финальными прогнозируемыми значениями классификации. Чтобы обработать новый элемент набора данных, нужно просто двигаться вниз по дереву, используя параметры элемента для ответов на вопросы. В финале вы доберётесь до одного из листьев, значение Class которого и будет прогнозируемым классом элемента.
Чтобы взглянуть на дерево решений под другим углом, мы спроецируем разделения модели на исходные данные.

Каждое разделение отображается одной линией, разделяющей образцы данных на узлы в соответствии со значением параметров. Поскольку максимальная глубина дерева не ограничена, разделение размещает каждый элемент в узел, содержащий только элементы того же класса. Позже мы рассмотрим, как идеальное разделение обучающих данных может привести к переобучению.
Загрязнение Джини
Теперь самое время рассмотреть концепцию загрязнения Джини (математика не так уж страшна, как кажется). Загрязнение Джини — вероятность неверной маркировки в узле случайно выбранного образца. К примеру, в верхнем (корневом) узле вероятность неверной классификации образца равна 44.4 %. Это можно вычислить с помощью уравнения:
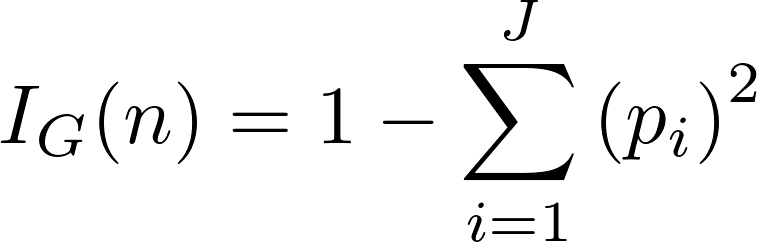
Загрязнение Джини узла n равно 1 минус сумма отношений класса к общему количеству образцов pi, возведённых в квадрат, для каждого из множества классов J (в нашем случае это всего 2 класса). Звучит сложно, поэтому покажем, как вычисляется загрязнение Джини для корневого узла:
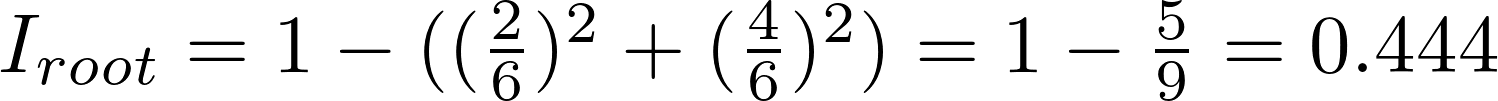
В каждом узле дерево решений ищет такое значение определённого параметра, которое приведёт к максимальному уменьшению загрязнения Джини. В качестве альтернативы для разделения узлов также можно использовать концепцию накопления информации.
Затем процесс разделения повторяется с использованием «жадной», рекурсивной процедуры, пока дерево не достигнет максимальной глубины или в каждом узле не останутся только образцы одного класса. Общевзвешенное загрязнение Джини должно уменьшаться с каждым уровнем. В нашем случае на втором уровне оно составит 0.333:
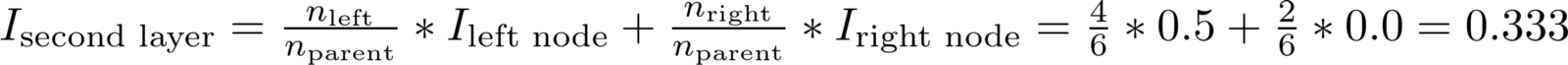
Удельный вес загрязнения Джини для каждого узла равен отношению количества образцов, обработанных этим узлом, к количеству обработанных родительским узлом. Вы можете самостоятельно рассчитать загрязнение Джини для последующих уровней дерева и отдельных узлов, используя данные визуализации. Таким образом, эффективная модель строится на базовых математических операциях.
В итоге общевзвешенное загрязнение Джини последнего слоя сводится к нулю. Это значит, что каждый конечный узел содержит только образцы одного класса, и случайно выбранный образец не может быть неверно классифицирован. Звучит отлично, но помните, что это может быть сигналом того, что модель переобучена. Это происходит, потому что узлы смоделированы только на обучающих данных.
Переобучение, или почему лес лучше одного дерева
Может создаться впечатление, что для решения задачи хватило бы и одного дерева решений. Ведь эта модель не делает ошибок. Однако важно помнить, что алгоритм безошибочно отсортировал только тренировочные данные. Этого и следовало ожидать, поскольку мы указали верные ответы и не ограничили глубину дерева (количество слоёв). Но цель машинного обучения состоит в том, чтобы научить алгоритм обобщать полученную информацию и верно обрабатывать новые, ранее не встречавшиеся данные.
Переобучение происходит, когда мы используем очень гибкую модель (с высокой вместимостью), которая просто запоминает обучающий набор данных, подгоняя узлы под него. Проблема в том, что такая модель выявляет не только закономерности в данных, но и любой присутствующий в них шум. Такую гибкую модель часто называют высоковариативной, поскольку параметры, формирующиеся в процессе обучения (такие как структура дерева решений) будут значительно варьироваться в зависимости от обучающего набора данных.
С другой стороны, у недостаточно гибкой модели будет высокий уровень погрешности, поскольку она делает предположения относительно тренировочных данных (модель смещается в сторону предвзятых предположений о данных). К примеру, линейный классификатор предполагает, что данные распределены линейно. Из-за этого он не обладает достаточной гибкостью для соответствия нелинейным структурам. Ригидная модель может оказаться недостаточно ёмкой даже для соответствия тренировочным данным.
В обоих случаях — и при высокой вариативности, и при высокой погрешности — модель не сможет эффективно обрабатывать новые данные.
Поиск баланса между излишней и недостаточной гибкостью модели является ключевой концепцией машинного обучения и называется компромиссом между вариативностью и погрешностью (bias-variance tradeoff).
Алгоритм дерева решений переобучается, если не ограничить его максимальную глубину. Он обладает неограниченной гибкостью и может разрастаться, пока не достигнет состояния идеальной классификации, в которой каждому образцу из набора данных будет соответствовать один лист. Если вернуться назад к созданию дерева и ограничить его глубину двумя слоями (сделав только одно разделение), классификация больше не будет на 100 % верной. Мы уменьшаем вариативность за счёт увеличения погрешности.
В качестве альтернативы ограничению глубины, которое ведёт к уменьшению вариативности (хорошо) и увеличению погрешности (плохо), мы можем собрать множество деревьев в единую модель. Это и будет классификатор на основе комитета деревьев принятия решений или просто «случайный лес».
Случайный лес
Случайный лес — модель, состоящая из множества деревьев решений. Вместо того,чтобы просто усреднять прогнозы разных деревьев (такая концепция называется просто «лес»), эта модель использует две ключевые концепции, которые и делают этот лес случайным.
Случайная выборка тренировочных образцов
В процессе тренировки каждое дерево случайного леса учится на случайном образце из набора данных. Выборка образцов происходит с возмещением (в статистике этот метод называется бутстреппинг, bootstrapping). Это даёт возможность повторно использовать образцы одним и тем же деревом. Хотя каждое дерево может быть высоковариативным по отношению к определённому набору тренировочных данных, обучение деревьев на разных наборах образцов позволяет понизить общую вариативность леса, не жертвуя точностью.
При тестировании результат выводится путём усреднения прогнозов, полученных от каждого дерева. Подход, при котором каждый обучающийся элемент получает собственный набор обучающих данных (с помощью бутстреппинга), после чего результат усредняется, называется бэггинг (bagging, от bootstrap aggregating).
Случайные наборы параметров для разделения узлов
Вторая базовая концепция случайного леса заключается в использовании определённой выборки параметров образца для разделения каждого узла в каждом отдельном дереве. Обычно размер выборки равен квадратному корню из общего числа параметров. То есть, если каждый образец набора данных содержит 16 параметров, то в каждом отдельном узле будет использовано 4. Хотя обучение случайного леса можно провести и с полным набором параметров, как это обычно делается при регрессии. Этот параметр можно настроить в реализации случайного леса в Scikit-Learn.
Случайный лес сочетает сотни или тысячи деревьев принятия решений, обучая каждое на отдельной выборке данных, разделяя узлы в каждом дереве с использованием ограниченного набора параметров. Итоговый прогноз делается путём усреднения прогнозов от всех деревьев.
Чтобы лучше понять преимущество случайного леса, представьте следующий сценарий: вам нужно решить, поднимется ли цена акций определённой компании. У вас есть доступ к дюжине аналитиков, изначально не знакомых с делами этой компании. Каждый из аналитиков характеризуется низкой степенью погрешности, так как не делает каких-либо предположений. Кроме того, они могут получать новые данные из новостных источников.
Трудность задачи в том, что новости, помимо реальных сигналов, могут содержать шум. Поскольку предсказания аналитиков базируются исключительно на данных — обладают высокой гибкостью — они могут быть искажены не относящейся к делу информацией. Аналитики могут прийти к разным заключениям, исходя из одних и тех же данных. Кроме того, каждый аналитик старается делать прогнозы, максимально коррелирующие с полученными отчётами (высокая вариативность) и предсказания могут значительно различаться при разных наборах новостных источников.
Поэтому нужно не опираться на решение какого-то одного аналитика, а собрать вместе их прогнозы. Более того, как и при использовании случайного леса, нужно разрешить каждому аналитику доступ только к определённым новостным источникам, в надежде на то, что эффекты шумов будут нейтрализованы выборкой. В реальной жизни мы полагаемся на множество источников (никогда не доверяйте единственному обзору на Amazon). Интуитивно нам близка не только идея дерева решений, но и комбинирование их в случайный лес.
Алгоритм Random Forest на практике
Настало время реализовать алгоритм случайного леса на языке Python с использованием Scikit-Learn. Вместо того чтобы работать над элементарной теоретической задачей, мы используем реальный набор данных, разбив его на обучающий и тестовый сеты. Тестовые данные мы используем для оценки того, насколько хорошо наша модель справляется с новыми данными, что поможет нам выяснить уровень переобучения.
Набор данных
Мы попробуем рассчитать состояние здоровья пациентов в бинарной системе координат. В качестве параметров мы используем социально-экономические и персональные характеристики субъектов. В качестве меток мы используем 0 для плохого здоровья и 1 для хорошего. Этот набор данных был собран Центром по Контролю и Предотвращению Заболеваний и размещён в свободном доступе.
Как правило 80 % работы над научным проектом заключается в изучении, очистке и синтезировании параметров из сырых данных (подробнее узнать можно здесь). Однако в этой статье мы сосредоточимся на построении модели.
В данном примере мы сталкиваемся с задачей несбалансированной классификации, поэтому простой параметр точности модели не отобразит истинной её производительности. Вместо этого мы используем площадь под кривой операционных характеристик приёмника (ROC AUC), измерив от 0 (в худшем случае) до 1 (в лучшем случае) со случайным прогнозом на уровне 0,5. Мы также можем построить указанную кривую, чтобы проанализировать модель.
В этом Jupyter notebook содержатся реализации и дерева решений, и случайного леса, но здесь мы сфокусируемся на последнем. После получения данных мы можем создать и обучить этот алгоритм следующим образом:
После нескольких минут обучения модель будет готова выдавать прогнозы для тестовых данных:
Мы рассчитаем прогнозы классификации ( predict ) наряду с прогностической вероятностью ( predict_proba ), чтобы вычислить ROC AUC.
Результаты
Итоговое тестирование ROC AUC для случайного леса составило 0.87, в то время как для единичного дерева с неограниченной глубиной — 0.67. Если вернуться к результатам обработки тренировочных данных, обе модели покажут эффективность, равную 1.00 на ROC AUC. Этого и следовало ожидать, ведь мы предоставили готовые ответы и не ограничивали максимальную глубину каждого дерева.
Несмотря на то, что случайный лес переобучен (показывает на тренировочных данных лучшую производительность, чем на тестовых), он всё же гораздо больше способен к обобщениям, чем одиночное дерево. При низкой вариативности (хорошо) случайный лес наследует от одиночного дерева решений низкую склонность к погрешности (что тоже хорошо).
Мы можем визуализовать кривую ROC для одиночного дерева (верхняя диаграмма) и для случайного леса в целом (нижняя диаграмма). Кривая лучшей модели стремится вверх и влево:
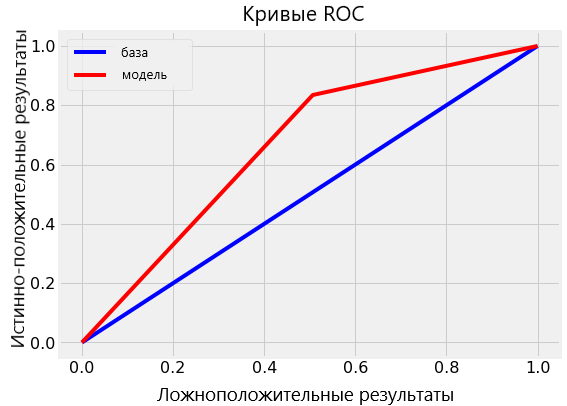
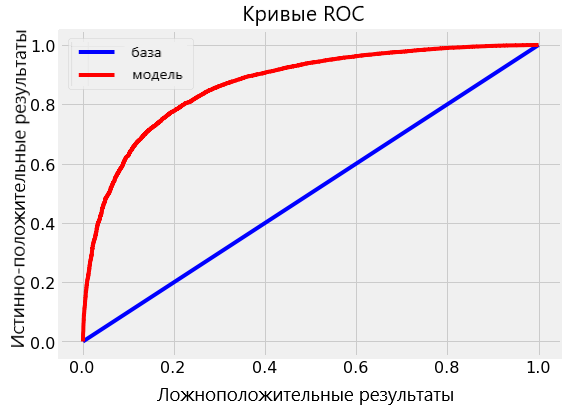
Случайный лес значительно превосходит по точности одиночное дерево.
Ещё один способ оценить эффективность построенной модели — матрица погрешностей для тестовых прогнозов.
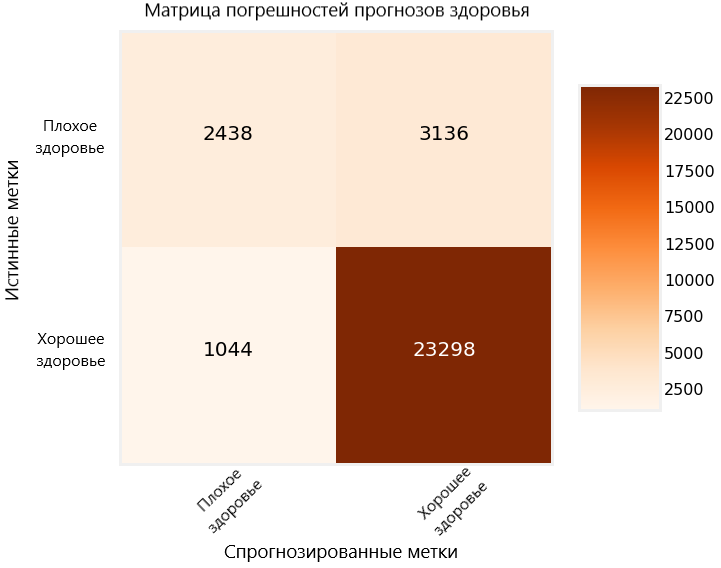
На диаграмме верные прогнозы, сделанные моделью, отображаются в верхнем левом углу и в нижнем правом, а неверные в нижнем левом и верхнем правом. Подобные диаграммы мы можем использовать, чтобы оценить, достаточно ли проработана наша модель и готова ли она к релизу.
Значимость параметра
Значимость параметра в случайном лесу — это суммарное уменьшение загрязнения Джини во всех узлах, использующих этот параметр для разделения. Мы можем использовать это значение для определения опытным путём, какие переменные более всего принимаются во внимание нашей моделью. Мы можем рассчитать значимость параметров в уже обученной модели и экспортировать результаты этих вычислений в Pandas DataFrame следующим образом:
Рассматриваемая величина может также использоваться для синтезирования дополнительных параметров, объединяющих несколько наиболее важных. При отборе параметров их значимость может указать на те, которые можно удалить из набора данных без ущерба производительности модели.
Визуализация единичного дерева леса
Мы также можем визуализовать единичное дерево случайного леса. В данном случае нам придётся ограничить его глубину, иначе оно может оказаться слишком большим для преобразования в изображение. Для этого изображения глубина была ограничена до 6 уровней. Результат всё равно слишком велик, однако, внимательно его изучив, мы можем понять, как работает наша модель.

Следующие шаги
Следующим шагом будет оптимизация случайного леса, которую можно выполнить через случайный поиск, используя RandomizedSearchCV в Scikit-Learn. Оптимизация подразумевает поиск лучших гиперпараметров для модели на текущем наборе данных. Лучшие гиперпараметры будут зависеть от набора данных, поэтому нам придётся проделывать оптимизацию (настройку модели) отдельно для каждого набора.
Можно рассматривать настройку модели как поиск лучших установок для алгоритма машинного обучения. Примеры параметров, которые можно оптимизировать: количество деревьев, их максимальная глубина, максимальное количество параметров, принимаемых каждым узлом, максимальное количество образцов в листьях.
Реализацию случайного поиска для оптимизации модели можно изучить в Jupyter Notebook.
Полностью рабочий образец кода
Приведённый ниже код создан с помощью repl.it и представляет полностью рабочий пример создания алгоритма случайного леса на Python. Можете самостоятельно его запустить и попробовать поэкспериментировать, изменяя код (загрузка пакетов может занять некоторое время).
Заключение и выводы
Хотя мы действительно можем создавать мощные модели машинного обучения на Python, не понимая принципов их работы, знание основ позволит работать более эффективно. В этой статье мы не только построили и использовали на практике алгоритм случайного леса, но и разобрали, как работает эта модель.
Мы изучили работу дерева принятия решений, элемента, из которого состоит случайный лес, и увидели, как можно преодолеть высокую вариативность единичного дерева, комбинируя сотни таких деревьев в лес. Случайный лес работает на принципах случайной выборки образцов, случайного набора параметров и усреднения прогнозов.
В этой статье мы разобрали следующие ключевые концепции:



