Welcome To Getverify Lda
As Getverify Lda, the priority of our corporate identity is to meet customer satisfaction and needs as soon as possible.
About
Getverify Lda is designed as a front-end to the modern and user experience that runs smoothly at all screen resolutions in your mobile applications.
Up-To-Date Software Standards
We ensure that the designed website is coded in accordance with today’s software standards and that the architecture is built correctly.
Responsive Design
Getverify Lda is designed as a front-end to the modern and user experience that runs smoothly at all screen resolutions in your mobile applications. Designs are transferred in a responsive manner so that they can be seen on all mobile devices without problems.
Latest Technologies
We follow new mobile technologies closely and equip our applications with the latest technologies. Java, Objective C, Cordova, and Node JS among others, and we are developing high-performance software.

Getverify Lda
As Getverify Lda, the priority of our corporate identity is to meet customer satisfaction and needs as soon as possible.
While meeting these needs, we maintain a healthy dialogue with our customers and maintain a high level of quality service, high performance, productivity and reliability at work.

Our Services
We ensure that the designed website is coded in accordance with today’s software standards and that the architecture is built correctly.
Android App
Android mobile application for your company that is totally tailored to your needs.
IOS Application
IOS mobile application for your company that is fully geared to your needs.
Web Design And Application
Web Design for your company that is totally suited to your needs.
E-Commerce
E-Commerce page for your company that is totally suited to your needs.
Пришла СМС от SMS Verify с кодом: что это?
31.12.2020 2 Просмотры
СМС Verify – это списание средств за сообщения с коротких номеров, которые приходят для подтверждения или идентификации пользователя. Чаще всего, это различные уведомления от социальных сетей, банков. В сбербанке таким уведомлением является «900». Раньше сбербанк сам оплачивал такие сообщения, но сейчас эта услуга стала платной.
Опция направлена на повышение безопасности. Услуга является преградой перед хакерами и мошенниками.
Можно ли отключить?
Отключить оповещения от Verify не получится, потому что в дальнейшем вы не сможете получать сообщения с кодами от социальных сетей, банков, магазинов и так далее.

Но получение вами неизвестного пароля может быть попыткой мошенничества. В такой ситуации нужно незамедлительно обратиться в сервисный центр вашего оператора. Они помогут отключить мошенническую услугу. Неизвестный полученный пароль ни в коем случае не нужно никуда вводить, потому что есть угроза списания средств с вашего баланса.

Опыт абонентов
Некоторым пользователям даже глубокой ночью не дают покоя Verify оповещения. Понятно, что они являются ошибкой или мошенническими действиями. Приходят сообщения с паролем подтверждения для Инстаграма, Фэйсбука. К счастью, большинство пользователей понимает, что это обман и ничего вводить не стоит. Но бывают случаи, когда наивные получатели Verify СМС верят и вводят комбинации цифр. Аккаунты таких пользователей в социальных сетях взламываются, а деньги с баланса номера списываются.
Важно всегда помнить, что неизвестные полученные пароли никогда не стоит никуда вводить. Если же нежелательные Verify преследуют ваш телефон уже несколько дней, то обратитесь в сервисный центр вашего оператора.
Как отменить автоматическое списание средств с Google Кошелька (с привязанной карты) за «Подписку ivi»
Чтобы отменить автоматическое списание средств с Google Кошелька (с привязанной карты) выполните следующие действия (на устройстве, с которого осуществляли оплату):


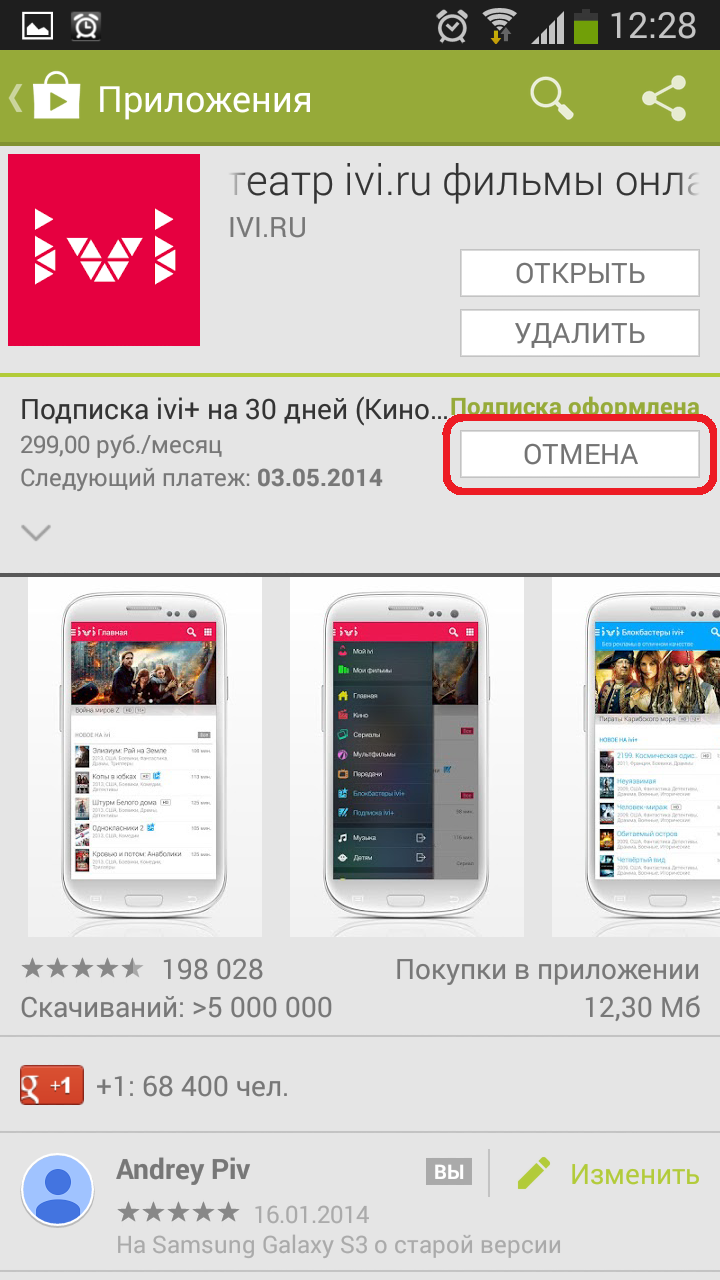
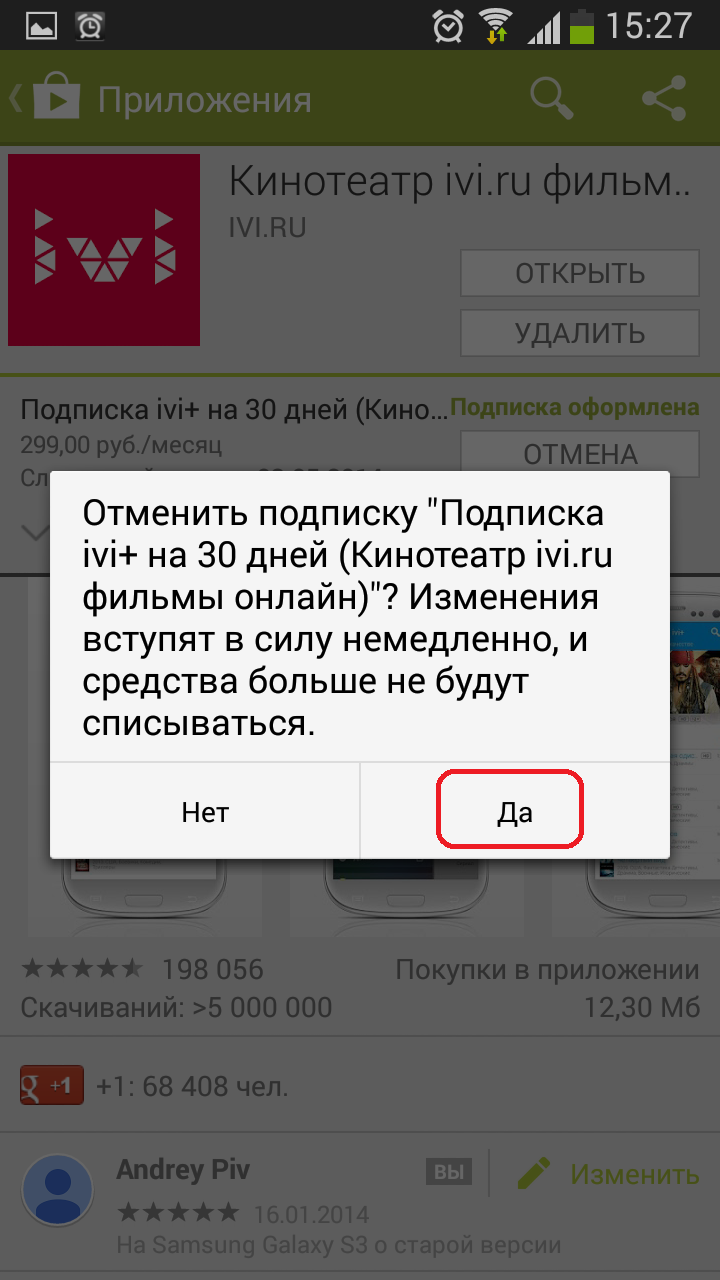
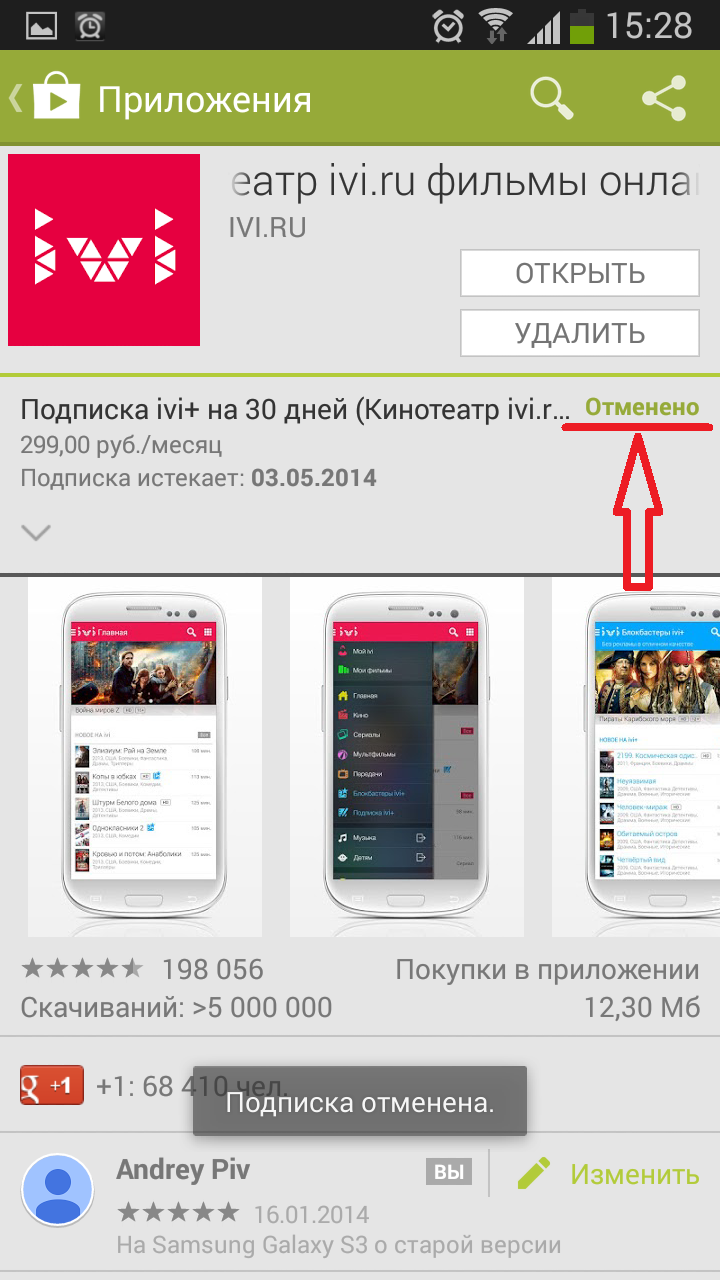
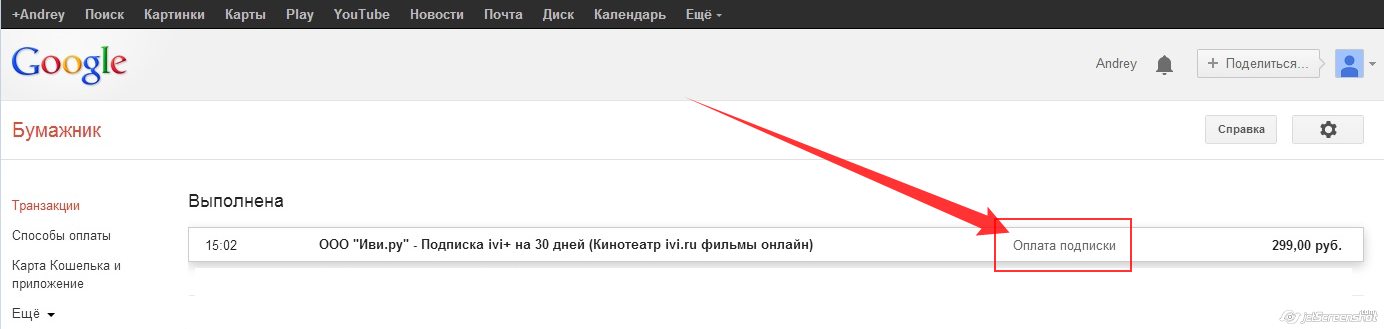
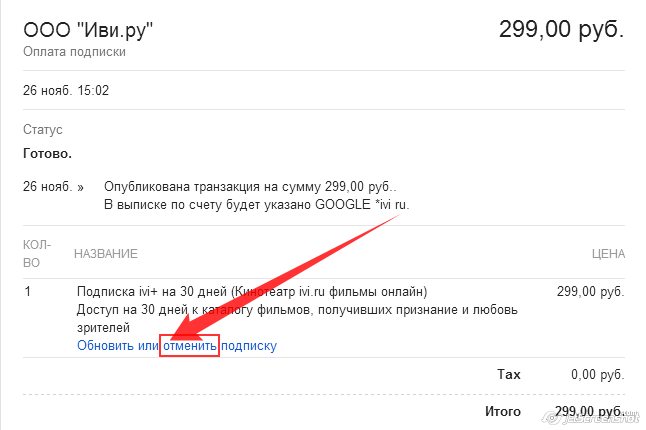
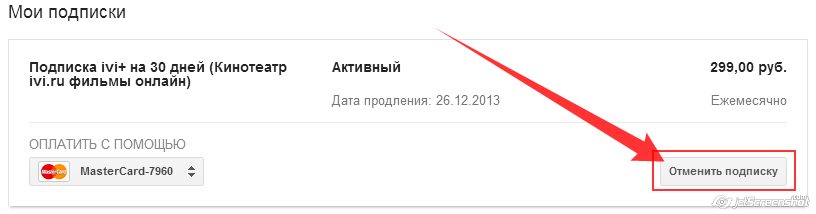
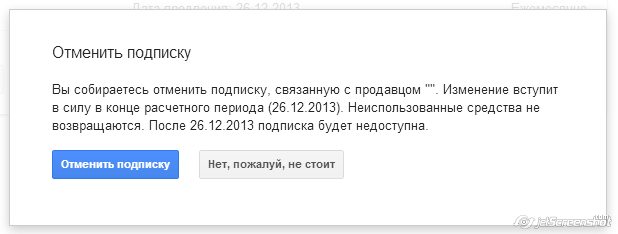
Более подробную информацию можете получить непосредственно на сайте поддержки Google: https://support.google.com/googleplay/answer/2476088
Ответы 0
Сервис поддержки клиентов работает на платформе UserEcho
Поделиться
Рады приветствовать вас в Центре поддержки пользователей ivi.
Вы можете задать нам любой вопрос или предложить идею, написав на электронный адрес: support@ivi.ru
При этом мы рекомендуем вам обратиться к нашей Базе знаний, в которой вы можете найти массу интересной и полезной информации.
Также вы можете получить консультацию, позвонив по телефону 8-800-234-49-23.
Звонок бесплатен для вас.
Просим вас воздержаться от:
За нарушение указанных правил пользователь будет попадать в бан (без предупреждения).
Google Get Verify LDA: что это такое, сняли деньги, отменить подписку
19.07.2020 1,323 Просмотры
Пользователи интернета устали от массовой рассылки рекламы и нежелательных сообщений. Многим надоедают звонки с неизвестных номеров. Тем, кто хочет ограничить поток информации, и не заинтересован в распространяемых материалах, устанавливают специальное программное обеспечение, которое способно фильтровать данные. Одним из разработчиков такого рода приложений размещаемых в Google Play выступает Getverify Lda. Владельцы устройств обнаруживают, что с их карты сняли деньги за ПО, когда получают сообщение «Покупка GOOGLE*GETVERIFY LDA 1 290 ₽», но не знают, как отменить подписку.
Что это
GOOGLE GETVERIFY LDA – сообщение, которое приходит пользователям Google Play после подписки на услуги и последующей оплаты через аккаунт Play Маркет. Соответствующая сумму списывают непосредственно с карты привязанной к сервису.
Сняли деньги
Текст «Покупка GOOGLE*GETVERIFY LDA» для большинства пользователей означает незапланированные траты и потерю средств в размере 1 290 ₽. Информация, на что конкретно была потрачена сумма размещается в папке история покупок Гугл Плей. Уточнить правомерно ли были списаны деньги позволяет официальная страница магазина приложений https://pay.google.com/payments/home.

Как отменить подписку
Столкнувшись с такой ситуацией, владельцы учетной записи в Плей Маркете пытаются найти выход и, если не вернуть свои деньги, то хотя бы предотвратить повтор таких ситуаций в дальнейшем. Обезопасить счет поможет настройка аккаунта с установкой защиты от случайных и нежелательных покупок.
Чтобы предотвратить негативные последствия, отказаться от обязательств, отменив подписку в личном кабинете, необходимо изменить настройки:
Еще один вариант избавиться от обязательств и дополнительных расходов – удалить соответствующее приложение из Google Play, но это не является основанием для возврата предыдущих сумм.
Снятие средств с формулировкой Google GetVerify LDA отражает расходы на покупку приложения или наличие подписки на услуги. Предотвратить незапланированное списание средств поможет контроль и защита от случайных и нежелательных покупок, а также пункт «Отменить подписку».
Запускаем LDA в реальном мире. Подробное руководство
Предисловие
На просторах интернета имеется множество туториалов объясняющих принцип работы LDA(Latent Dirichlet Allocation — Латентное размещение Дирихле) и то, как применять его на практике. Примеры обучения LDA часто демонстрируются на «образцовых» датасетах, например «20 newsgroups dataset», который есть в sklearn.
Особенностью обучения на примере «образцовых» датасетов является то, что данные там всегда в порядке и удобно сложены в одном месте. При обучении продакшн моделей, на данных, полученных прямиком из реальных источников все обычно наоборот:
Исторически, я стараюсь учиться на примерах, максимально приближенных к реалиям продакшн-действительности потому, что именно таким образом можно наиболее полно прочувстовать проблемные места конкретного типа задач. Так было и с LDA и в этой статье я хочу поделиться своим опытом — как запускать LDA с нуля, на совершенно сырых данных. Некоторая часть статьи будет посвящена получению этих самых данных, для того, чтобы пример обрел вид полноценного ‘инженерного кейса’.
Topic modeling и LDA.
Для начала, рассмотрим, что вообще делает LDA и в каких задачах используется.
Наиболее часто LDA применяется для Topic Modeling(Тематическое моделирование) задач. Под такими задачами подразумеваются задачи кластеризации или классификации текстов — таким образом, что каждый класс или кластер содержит в себе тексты со схожими темами.
Для того, чтобы применять к датасету текстов(далее корпус текстов) LDA, необходимо преобразовать корпус в term-document matrix(Терм-документная матрица).
Терм-документная матрица — это матрица которая имеер размер  , где
, где
N — количество документов в корпусе, а W — размер словаря корпуса т.е. количество слов(уникальных) которые встречаются в нашем корпусе. В i-й строке, j-м столбце матрицы находится число — сколько раз в i-м тексте встретилось j-е слово.
LDA строит, для данной Терм-документной матрицы и T заранее заданого числа тем — два распределения:
Значения ячеек данных матриц — это соответственно вероятности того, что данная тема содержится в данном документе(или доля темы в документе, если рассматривать документ как смесь разных тем) для матрицы ‘Распределение тем по текстам’.
Для матрицы ‘Распределение слов по темам’ значения — это соотв-но вероятность встретить в тексте с темой i слово j, качествено, можно рассматривать эти числа как коэффициенты характеризующие, то насколько данное слово характерно для данной темы.
Следует сказать, что под словом тема понимается не ‘житейское’ определение этого слова. LDA выделяет T тем, но что это за темы и соответствуют ли они каким-либо известным темам текстов, как например: ‘Спорт’, ‘Наука’, ‘Политика’ — неизвестно. В данном случае, уместно скорее говорить о теме, как о некой абстрактной сущности, которая задается строкой в матрице распределения слов по темам и с некоторой вероятностью соответствует данному тексту, если угодно можно представить ее, как семейство характерных наборов слов встречающихся вместе, с соответствующими вероятностями(из таблицы) в некотором определенном множестве текстов.
Если вам интересно более подробно и ‘в формулах’ изучить как именно обучается и работает LDA, то вот некоторые материалы(которые использовались автором):
Добываем дикие данные
Для нашей ‘лабораторной работы’, нам понадобится кастомный датасет со своими недостатками и особенностями. Добыть его можно в разных местах: выкачать отзывы с Кинопоиска, статьи из Википедии, новости с какого-нибудь новостного портала, мы возьмем чуть более экстремальный вариант — посты из сообществ ВКонтакте.
Делать это мы будем так:
Инструменты и статьи
Для выкачивания постов будем использовать модуль vk для работы с API ВКонтакте, для Python. Один из наиболее замысловатых моментов при написании приложения с использованием API ВКонтакте — это авторизация, к счастью, код выполняющий эту работу уже написан и есть в открытом доступе, кроме vk я использовал небольшой модуль для авторизации — vkauth.
Ссылки на используемые модули и статьи для изучения API ВКонтакте:
Пишем код
И так, с помощью vkauth, авторизируемся:
В процессе, был написан небольшой модуль содержащий все необходимые для выгрузки контента в соответствующем формате функции, ниже они преведены, давайте пройдемся по ним:
Итоговый пайплайн имеет следующий вид:
Fails
В целом, сама по себе процедура выкачивания данных не представляет собой ничего трудного, обратить внимание следует лишь на два момента:
При совершении большого количества запросов, например в цикле, мы так же будем ловить ошибки. Эту проблему можно решить несколькими способами:
В данной работе был выбран простой и медленный способ, в дальнейшем, я возможно напишу микростатью про способы обхода или ослабления ограничений на количество запросов в секунду.
С затравочным ‘некоторым’ пользователем имеющим
150 друзей, удалось добыть 4679 текстов — каждый характеризует некоторое сообщество ВК. Тексты сильно варьируются по размеру и написаны на многих языках — часть из них не пригодна для наших целей, но об этом мы поговорим чуть дальше.
Основная часть

Пройдемся по всем блокам нашего пайплайна — сначала, по обязательным(Идеально), затем по остальным — они, как раз и представляют наибольший интерес.
CountVectorizer
Перед тем, как учить LDA, нам необходимо представить наши документы в виде Терм-документной матрицы. Это обычно включает в себя такие операции как:
Все эти действия в sklearn удобно реализованы в рамках одной программной сущности — sklearn.feature_extraction.text.CountVectorizer.
Все, что нужно сделать это:
Аналогично с CountVectorizer`ом, LDA, прекрасно реализовано в Sklearn и других фреймворках, поэтмому уделять непосредственно их реализациям много места, в нашей, сугубо практической статье нет особого смысла.
Все, что нужно, чтобы запустить LDA это:
Preprocessing
Если мы просто возьмем наши тексты сразу после того как скачали их и конвертируем в Терм-документную матрицу с помощью CountVectorizer, со встроеным дефолтным токенайзером, мы получим матрицу размера 4679×769801(на используемых мной данных).
Размер нашего словаря будет составлять 769801. Даже если допустить, что большая часть слов информативны, то мы все равно вряд ли получим хороший LDA, нас ждет что-то вроде ‘Проклятия размерностей’, не говоря уже о том, что практически для любого компьютера, мы просто забьем всю оперативную память. На деле, большя часть этих слов совершенно не информативны. Огромная часть из них это:
Кроме того, многие группы в ВК специализируются исключительно на изображениях — там почти нет текстовых постов — тексты соответствующие им вырождены, в Терм-документной матрице они будут давать нам практически полностью нулевые строки.
И так, давайте же отсортируем это все!
Токенизируем все тексты, уберем из них пунктуацию и числа, посмотрим на гистограмму распределения текстов по количеству слов:
Уберем все тексты размером меньше 100 слов(их 525)
Теперь словарь:
Удаление всех лексем(слова) состоящих не из букв, в рамках нашей задачи — это вполне допустимо. CountVectorizer делает это сам, даже если нет, то думаю здесь не нужно приводить примеров(они есть в полной версии кода к статье).
Одной из наиболее распространенных процедур по уменьшению размера словаря является удаление так называемых stopwords(стопворды) — слов не несущих смысловой нагрузки или/и не имеющих тематической окрашенности(в нашем случае — Topic Modeling же). Такими словами в нашем случае являются, например:
В модуле nltk есть сформированные списки стопвордов на русском и на английском, но они слабоваты. В интернете можно найти еще списки стопвордов для любого языка и добавить их к тем, что есть в nltk. Так мы и сделаем. Возьмем дополнительно стопворды отсюда:
На практике, при решении конкретных задач списки стопвордов постепенно корректируются и дополняются по мере обучения моделей, так как для каждого конкретного датасета и задачи существуют свои конкретные ‘несодержательные’ слова. Мы тоже подберем себе кастомных стопвордов после обучения нашего LDA ‘первого поколения’.
Сама по себе процедура удаления стопвордов встроена в CountVectorizer — нам только нужен их список.
Достаточно ли того, что мы сделали?
Большинство слов которые находятся в нашем словаре по-прежнему не слишком информативны для обучения на них LDA и не находятся в списке стопвордов. Поэтому применим к нашим данным еще один способ фильтрации.

, где
t — слово из словаря.
D — корпус(множество текстов)
d — один из текстов корпуса.
Посчитаем IDF всех наших слов, и отсечем слова с самым большим idf(очень редкие) и с самым маленьким(широкораспространенные слова).
Полученный после вышеописанных процедур уже вполне пригоден для обучения LDA, но произведем еще стемминг — в нашем датасете часто встречаются одни и те же слова, но в разных падежах. Для стемминга использовался pymystem3.
После применения вышеописанных фильтраций размер словаря уменьшился с 769801 до
13611 и уже с такими данными, можно получить LDA модель приемлимого качества.
Тестирование, применение и тюнинг LDA
Теперь, когда у нас есть датасет, препроцессинг и модели которые мы обучили на обработаном датасете, хорошо было бы проверить адекватность наших моделей, а так же соорудить для них какие-нибудь приложения.
В качестве приложения, для начала рассмотрим задачу генерации ключевых слов для данного текста. Сделать это в достаточно простом варианте можно следующим образом:
Напишем простой класс-интерфейс который и будет реализовывать данный способ генерации ключевых слов:
Применим наш метод к нескольким текстам и посмотрим что получается:
Cообщество: Агентство путешествий «Краски Мира»
Ключевые слова: [‘photo’, ‘social’, ‘travel’, ‘сообщество’, ‘путешествие’, ‘евро’, ‘проживание’, ‘цена’, ‘польша’, ‘вылет’]
Cообщество: Food Gifs
Ключевые слова: [‘масло’, ‘ст’, ‘соль’, ‘шт’, ‘тесто’, ‘приготовление’, ‘лук’, ‘перец’, ‘сахар’, ‘гр’]
Результаты выше не ‘cherry pick’ и выглядят вполне адекватно. На деле, это результаты из уже настроенной модели. Первые LDA, которые были обучены в рамках этой статьи выдавали существенно более плохие результаты, среди ключевых слов можно было часто увидеть, например:
Настройка(тюнинг) модели производился следующим образом:
Подобную ‘чистку’, следует проводить аккуратно, предварительно просматривая, те самые 10% слов. Скорее, так следует выбирать кандидатов на удаление, а после уже в ручную отбирать из них слова которые следует удалить.
Где-то на 2-3 поколении моделей, с подобным способом отбора стопвордов, для топ-5% широкораспространенных топ-слов распределений мы получаем:
[‘любой’, ‘полностью’, ‘правильно’, ‘легко’, ‘следующий’, ‘интернет’, ‘небольшой’, ‘способ’, ‘сложно’, ‘настроение’, ‘столько’, ‘набор’, ‘вариант’, ‘название’, ‘речь’, ‘программа’, ‘конкурс’, ‘музыка’, ‘цель’, ‘фильм’, ‘цена’, ‘игра’, ‘система’, ‘играть’, ‘компания’, ‘приятно’]
Еще приложения
Первое, что приходит в голову конкретно мне — это использовать распределения тем в тексте как ‘эмбеддинги’ текстов, в такой интерпретации можно применять к ним алгоритмы визуализации или кластеризации, и искать уже итоговые ‘эффективные ‘ тематические кластеры таким образом.
На выходе, мы получим следующего вида картинку:
Крестики — это центры тяжести(cenroids) кластеров.
На изображении tSNE ембеддингов, видно, что кластеры выделенные с помощью KMeans, образуют достаточно связные и чаще всего пространственно разделимые между собой множества.



