Kubernetes 1.23: обзор основных новшеств
Этой ночью официально выпустят новую версию Kubernetes — 1.23. Рассказываем о самых интересных нововведениях (alpha), а также о некоторых фичах, которые перешли на уровень выше (beta, stable).

Для подготовки статьи использовалась информация из таблицы Kubernetes enhancements tracking, CHANGELOG-1.23, обзор Sysdig, а также конкретные issues, pull requests и Kubernetes Enhancement Proposals (KEPs).
В новом релизе 47 улучшений — это на 9 меньше, чем в прошлом. Из них:
19 новых функций (alpha);
17 продолжают улучшаться (beta);
11 признаны стабильными (stable).
По количеству нововведений и функций, которые стабилизировались, в этот раз лидируют связанные с хранилищем — начнем с них.
Мы сознательно не стали переводить названия фич на русский. Они преимущественно состоят из специальной терминологии, с которой инженеры чаще встречаются в оригинальной формулировке. К тому же соответствующие issues и KEPs проще гуглить по-английски.
Хранилище
Honor Persistent Volume reclaim policy
Политика возврата (reclaim policy) томов типа Persistent Volume (PV) может не соблюдаться, если PV работает в связке с PVC (Persistent Volume Claim):
PV соблюдает политику, если PVC удаляется до удаления PV.
Если первым из пары удаляется PV, политика возврата не выполняется, а связанный с PV внешний ресурс хранения не удаляется.
Альфа-версия новой фичи отвечает за обязательное соблюдение политики возврата PV, если его удаление происходит раньше, чем удаление PVC. Как это обеспечивается:
если обновление обрабатывается до того, как PVC удален, удаление связанного PV игнорируется.
FSGroup to CSI driver on mount
Recovery from volume expansion failure
С помощью PVC можно расширять емкость хранилища, запрашивая у провайдера том нужного объема. Иногда пользователи запрашивают больше, чем может выдать провайдер — например, 500 Гб, когда доступно только 100. При этом контроллер, который отвечает за расширение томов, хотя и получает отказ, продолжает повторять запросы. Процесс зацикливается.
ослаблена проверка API при обновлении PVC, чтобы разрешить уменьшение pvc.Spec.Resources ;
Авторы KEP’а приводят алгоритм обработки запроса на изменение PVC:
Также приводится шесть примеров различных пользовательских сценариев, при которых фича может быть полезна.
Миграции на CSI
Portworx file in-tree to CSI driver migration
Очередной прогресс в рамках большого проекта по миграции со встроенных в кодовую базу Kubernetes плагинов (in-tree) на CSI-драйверы. На этот раз свой CSI-драйвер получило хранилище Portworx от компании Pure Storage. Подробнее об этом драйвере можно почитать в документации проекта.
Ceph RBD in-tree provisioner to CSI driver migration
Фича, при активации которой все операции с плагинами RBD перенаправляются на внешний CSI-драйвер для Ceph. К слову, этот CSI-драйвер помогает избавиться от проблемы с блокировкой RBD, с которой мы регулярно сталкиваемся на практике при использовании containerd.
Stable-фичи
До стабильного уровня дошли:
AWS EBS in-tree to CSI driver migration — миграция на CSI-драйвер для AWS EBS (#1487).
Non-recursive volume ownership (FSGroup) — оптимизация процесса делегирования прав при bind-монтировании томов в контейнер (KEP).
Config FSGroup Policy in CSI Driver object — возможность для CSI-драйверов определять права доступа на основе FSGroup (KEP).
Generic inline ephemeral volumes — API, чтобы определять встроенные эфемерные тома непосредственно в спецификации Pod’ов (KEP).
CRD Validation Expression Language
Новая фича предлагает упрощенный вариант проверки пользовательских ресурсов (custom resources), которые добавляются в CRD (Custom Resource Definition). Ранее для этого использовались только вебхуки, в которых прописывались правила проверки. Такой механизм усложнял разработку и мог влиять на работоспособность CRD. Теперь правила можно писать на скриптовом языке Common Expression Language (CEL) прямо в схемах CustomResourceDefinition с помощью x-kubernetes-validations extension :
CEL — достаточно легкий, простой и безопасный язык. Он поддерживает предварительный анализ и проверку выражений, чтобы обнаруживать синтаксические и другие ошибки во время проверки custom resources.
OpenAPI enum types
Альфа-версия улучшения в OpenAPI, который теперь поддерживает перечисления, то есть данные типа enum. По умолчанию данные enum отображаются в конфигурации API как обычные строки с комментариями, в которых указывается тип данных. Это усложняет код и приводит к дублированию.
Теперь, если определить значения как строки:
… то далее с помощью маркера +enum можно явно вводить алиас, который найдет и использует все нужные возможные значения:
Генератор OpenAPI поймет, что допустимые значения — только TCP, UDP и SCTP.
Повысился статус у фичи Priority and Fairness Server Requests (#1040), которая предлагает более продвинутую систему приоритизации запросов типа max-in-flight. Подробнее о новом обработчике запросов мы рассказывали в обзоре K8s 1.18.
cAdvisor-less, CRI-full Container and Pod stats
Усовершенствование обобщает усилия по организации процесса, при котором вся статистика о запущенных контейнерах и Pod’ах извлекается из Container Runtime Interface (CRI). Тем самым отпадает необходимость в cAdvisor.
В числе причин, по которым решили отказаться от cAdvisor:
среда исполнения контейнеров лучше «осведомлена» об их поведении, чем cAdvisor;
cAdvisor не поддерживает некоторые среды, например виртуальные машины, а также Windows-контейнеры;
CPUManager policy option to distribute CPUs across NUMA nodes
Политика CPU Manager получила обновление в альфа-версии, которое улучшает распределение ресурсов ЦПУ при работе с NUMA-узлами (Non-Uniform Memory Architecture).
По умолчанию CPU Manager выделяет процессоры NUMA-узлам последовательно из общего пула ресурсов: сначала одному, затем второму и так далее. У некоторых узлов при этом может быть меньше ресурсов, чем у других — например, потому, что общий ресурс ЦПУ ограничен. Это приводит к появлению узких мест при исполнении параллельного кода, основанного на барьерах и других примитивах синхронизации. Код такого рода выполняется настолько быстро, насколько позволяет самый медленный worker — в нашем случае это тот NUMA-узел, которому досталось меньше процессорной мощности.
Новая фича распределяет ресурсы ЦПУ равномерно между всеми NUMA-узлами. Это ускоряет общую производительность приложений, которые создаются под NUMA-архитектуру. Опция устанавливается с помощью параметра distribute-cpus-across-numa в настройке политики CPU Manager типа static и активируется, когда запрос на ресурсы поступает от двух и более узлов.
Add gRPC probe to Pod
Liveness-, Readiness- и Startup probes — три разных типа проверки состояния Pod’а. Сейчас они работают по протоколам HTTP(S) и TCP. Новая фича добавляет поддержку gRPC — открытого фреймворка для удаленного вызова процедур, который часто используется в микросервисной архитектуре.
Возможность использовать встроенный gRPC среди прочего избавляет от необходимости использовать сторонние инструменты для проверки состояния контейнеров вроде grpc_health_probe(1). Вот как выглядит вариант конфигурации для readinessProbe :
Beta-фичи
Add options to reject non SMT-aligned workload. Фичу представили в предыдущем релизе. Благодаря ей CPU Manager более точечно распределяет ресурсы CPU между специфическими рабочими нагрузками. В частности — дает больший приоритет приложениям, адаптированным под одновременную многопоточность (SMT). Подробности — в KEP.
Ephemeral Containers. «Эфемерные контейнеры» — легковесные контейнеры, которые помогают при отладке обычных контейнеров. Впервые фича появилась еще в Kubernetes 1.16. По своему назначению «эфемерные контейнеры» схожи с плагином kubectl-debug, необходимость в котором теперь отпадает.
Kubelet CRI Support. Поддержка CRI (Container Runtime Interface). Меж тем распространение исполняемых сред на базе CRI типа containerd растет и CRI-O на фоне приближающегося устаревания Dockershim.
Приложения
Add count of ready Pods in Job status
Job controller отслеживает статус Job’ы по полю active (внутри Job.status.active ), которое показывает количество запущенных Pod’ов в состоянии Running (запущен) или Pending (ожидает). В реальности Job’а может находиться в состоянии Pending долгое время — например, если у кластера ограниченные ресурсы и образы скачиваются медленно. Поскольку Job.status.active показывает еще и Pod’ы в состоянии ожидания, конечный пользователь или контроллер может не знать реального прогресса по запущенным Pod’ам — готовы они или нет. Это особенно важно, если Pod’ы работают как worker’ы и общаются между собой.
Beta-фичи
Job tracking without lingering Pods. Функция, которая позволяет Job’ам быстрее удалять неиспользуемые Pod’ы, чтобы освободить ресурсы кластера. Подробнее — в нашем предыдущем обзоре и в KEP.
Add minReadySeconds to StatefulSets. Возможность указывать в настройках StatefulSets минимальное количество секунд, за которые созданный Pod должен перейти в состояние готовности (KEP). То же самое ранее было реализовано, например, для Deployment и DaemonSet.
Stable-фичи
CronJobs периодически запускают в кластере Kubernetes задания по аналогии с тем, как это делает cron в UNIX-подобных системах. Фича была представлена в Kubernetes 1.4 и переведена в beta-статус в версии 1.8.
Статус beta получило улучшение Topology Aware Hints, которое помогает контролировать трафик между зонами в мультикластерной инфраструктуре и увеличивать производительность сети (KEP).
Две фичи перешли в категорию stable:
Add IPv4/IPv6 dual-stack support. Поддержка двойного сетевого стека, которая позволяет назначать Pod’ам оба протокола (KEP).
Namespace Scoped Ingress Class Parameters. Возможность определять в параметрах IngressClass пространство имен для scope (KEP).
Разное
Identify Pod’s OS during API Server admission (Windows)
По умолчанию при подключении Pod’а к API-серверу его ОС не идентифицируется. Поэтому некоторые плагины доступа — такие как PodSecurityAdmission — могут накладывать ненужные ограничения безопасности на Pod и мешать его работе. Другие же плагины, наоборот, вообще не применяют ограничения безопасности, что еще хуже.
Deprecate klog specific flags in Kubernetes components
klog — библиотека для записи логов, реализованная на Go. klog применяется для логирования компонентов ядра K8s: kube-apiserver, kube-controller-manager, kube-scheduler, kubelet. У библиотеки масса недостатков. Например, запись логов при помощи klog в 7-8 раз медленнее, чем в JSON-формате. Еще — внушительное legacy от родительского проекта glog.
Сообщество решило, что устранять все проблемы и поддерживать klog нецелесообразно. Вместо этого предлагается использовать альтернативные форматы и оптимизировать существующие, например JSON. В этом релизе поддержка флагов для настройки klog признается устаревшей, а позже будет удалена (когда именно — пока неизвестно).
kubeadm: replace the legacy kubelet-config-x.y naming
kubectl events
Новая команда kubectl events снимает эти ограничения и добавляет новые возможности. Теперь, например, определенные события можно отфильтровать по типу, менять порядок сортировки событий, отбирать события только за последние N минут, увидеть изменения конкретного объекта. Разработчики получают более детальную информацию о событиях, от которых непосредственно зависит работа приложения.
Stable-фичи
Defend against logging secrets via static analysis. Защита от логирования секретов на основе статического анализа (#1933). Подробнее о работе фичи и причинах ее появления — в нашем обзоре K8s 1.20.
Reduce Kubernetes build maintenance. Улучшение во внутренней инфраструктуре Kubernetes, которое обобщает проделанную работу по перемещению всех сценариев сборки K8s в make build и удалению bazel build (KEP).
Некоторые из удаленных фич
Исправлено: драйвер тома файловой системы WPD (код 10) или желтый восклицательный знак —
Том-драйвер WPD FileSystem — это один из драйверов, о которых вы никогда не услышите, пока они не начали плохо себя вести и отображали различные сообщения об ошибках на вашем компьютере. Существует довольно много разных проблем, которые могут возникнуть с драйвером тома WPD FileSystem Volume, и некоторые из них встречаются чаще, чем другие.
Все эти проблемы имеют сходные методы и решения, которые можно использовать для решения проблемы, поэтому обязательно просмотрите всю статью, чтобы найти решение, которое работает лучше всего для вас.
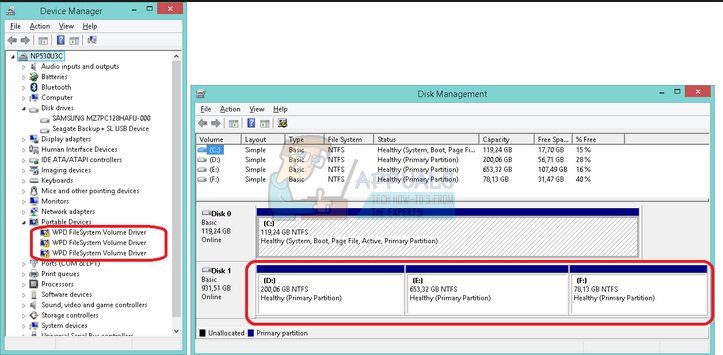
Решение 1. Назначьте буквы дисков в диспетчере дисков
Наиболее распространенные ошибки, связанные с драйвером тома WPD FileSystem Volume, такие как ошибка Code 10 или просто желтый восклицательный знак рядом с ним, сигнализирующий о том, что что-то не так, могут быть исправлены следующим способом, который состоит просто в назначении букв дисков каждому устройству хранения на ваш компьютер, особенно тот, который вызывает проблемы при подключении.
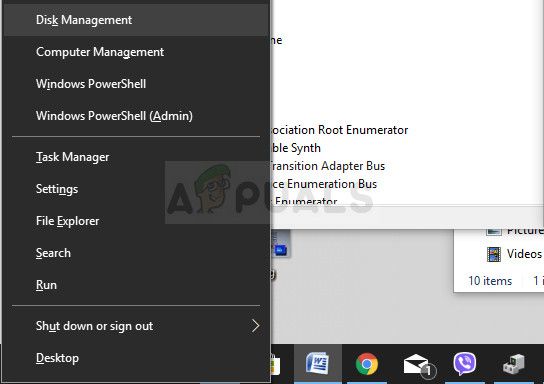
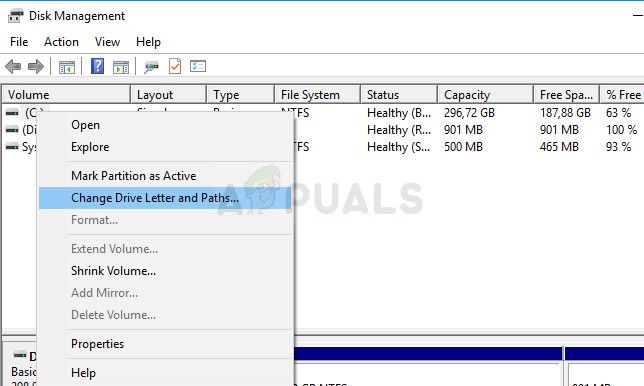
После завершения этого процесса пришло время перейти к диспетчеру устройств и перезапустить наше устройство. Следуйте инструкциям ниже:
Решение 2. Удалите все неиспользуемые скрытые устройства в диспетчере устройств
Честно говоря, даже несмотря на то, что в окнах диспетчера устройств есть кнопка, которая отображает скрытые устройства, Windows фактически не отображает все скрытые устройства, и есть три типа устройств, которые не будут отображаться даже после выбора этой опции. Единственный способ просмотреть и удалить эти устройства — создать новую переменную среды.
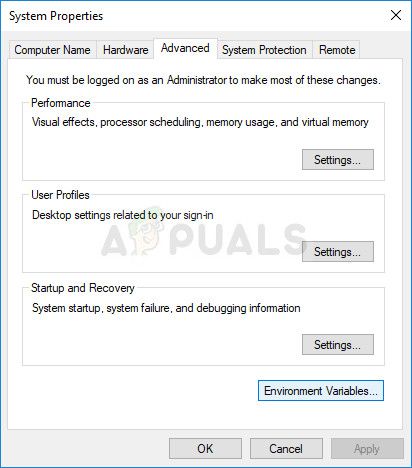
Решение 3. Переустановите драйвер тома файловой системы Microsoft WPD вручную
Если что-то не так с драйвером, который управляет переносными устройствами, подключенными к вашему компьютеру, то лучше решить проблему с ним напрямую, а не консультироваться с другими. Проблему можно решить, просто переустановив этот драйвер вручную с помощью диспетчера устройств.
Virtual Volumes от компании VMware – внедрять нельзя ждать?
Компания VMware завершила длительную и кропотливую работу над новой концепцией СХД выпуском в свет vSphere 6.0 с поддержкой программных хранилищ и структуры Virtual Volumes (VVols), о которых и будет мой сегодняшний пост. Начну с официального определения от производителя: «Virtual Volumes — это новая структура интеграции и управления, обеспечивающая виртуализацию массивов SAN и NAS благодаря созданию эффективной эксплуатационной модели, которая оптимизирована для виртуализированных сред и ориентирована на особенности приложения, а не инфраструктуры».
Представляется, что в будущем Virtual Volumes заменят VMFS, поскольку VMware никогда не распыляется на поддержку двух различных вариантов для ключевых компонентов инфраструктуры, то есть на двойную работу. Сперва они упразднили ESX спустя несколько лет после выхода ESXi, затем – VSA, выпустив на замену VSAN, а теперь пытаются перевести пользователей с vSphere Client на Web Client; допускаю, что в какой-то момент они могут решить перейти от vCenter Server на Windows к VCSA. Поэтому можно предположить, что аналогичная судьба ждет VMFS, от которой откажутся в пользу VVols – разумеется, после того, как они достигнут определенной стадии «зрелости» и будут приняты к использованию большинством пользовательской аудитории. Подтверждением этой мысли является и тот факт, что поддержка VVols включена во все редакции vSphere.
Выясним, однако, для начала, почему эксперты советуют не торопиться с внедрением Virtual Volumes.
Причина №1. Не поддерживается репликация массивов СХД
Это достаточно серьезный резон, особенно для крупных организаций, у которых репликация массивов СХД является основополагающей в их стратегии защиты и восстановления данных. Поддержка репликации хранилища на сегодня не заявлена в спецификации VASA 2.0, так что SRM и vMSC не работают с VVols – для кого-то этого будет достаточно, чтобы не читать дальше. Замечу, однако, что хотя VMware и не поддерживает репликацию массивов СХД, некоторые производители планируют или уже обеспечивают такую поддержку, так что некий workaround существует (но его все же нельзя использовать с SRM или vMSC до тех пор, пока VMware не включит его в спецификацию VASA).
Причина №2. Это первая версия новой архитектуры программного хранилища
Да-да, невзирая на годы, затраченные на разработку, это лишь версия 1.0, и, как первая версия любого продукта, она подвержена «болезни роста», что может заставить пользователей пока подождать. К тому же наблюдается определенный недостаток поддержки функциональной совместимости (а именно — репликации); что же касается поддержки со стороны собственно массива СХД (что тоже потребовало значительных трудозатрат со стороны производителей) – она также выходит в начальной версии. Среди производителей, участвовавших в разработке архитектуры – всеми уважаемые HP, NetApp и Dell, которые занимались этим несколько лет, поэтому именно их решения, скорее всего, будут наиболее зрелыми в плане готовности к использованию.
Причина №3. Не все производители СХД реализуют полную поддержку VVols
На текущий момент есть четверка производителей, у которых в VMware Hardware Compatibility Guide заявлена поддержка Day 1 для VVols. Этот список, разумеется, будет расширяться по мере того, как другие компании-производители будут завершать разработку и проходить сертификацию VMware для VVols; сейчас производители заняты также и расширением спектра поддерживаемых возможностей для VVols.
Причина №4. Кто выйдет победителем в борьбе за сферы влияния на ЦОД?
Помните, как это было, когда вы впервые рассказали сетевому администратору про vSwitch и озвучили требования к сети для vSphere? Без сомнения, человек почувствовал, как власть ускользает из его рук. Возможно, вам даже не удалось разойтись миром:). Аналогичный сценарий вполне вероятен и сегодня, когда вы заведете речь о VVols в разговоре с администратором СХД. Впрочем, как показала история, «сопротивление бесполезно!» — и как тогда администраторы vSphere выиграли борьбу с сетевыми админами, так и теперь они, скорее всего, победят и администраторов СХД. Чтобы обойтись без драки, советуем привлечь их к сотрудничеству, разъясняя, что же такое VVols, как это работает и как это упростит их жизнь от того, что взаимоотношения виртуальной инфраструктуры и СХД значительно улучшатся.
Причина №5. Насколько масштабируема эта архитектура?
Пока еще нет достаточных статистических данных по производительности, чтобы посмотреть, насколько хорошо VVols масштабируемы в сравнении с VMFS, т.е. будут ли они в этом отношении лучше, хуже или такими же. Предполагаю, что это решение примерно аналогично VMFS в смысле масштабируемости, или даже чуть лучше нее. Строго говоря, VVols разрабатывались не как средство увеличения производительности относительно VMFS, а как совершенно новая архитектура программного хранилища, новый подход, ориентированный на виртуальную машину как на единицу хранения в массиве СХД. Это же можно сказать и относительно сравнения RDM и VMFS – речь шла не о повышении производительности, и VMware доказала, что производительность у них одинаково высока, поэтому я вполне допускаю, что подобное произойдет и с VVols. Есть сведения, что в настоящий момент VMware выполняет тесты на сравнение производительности, и результаты, надеюсь, скоро будут доступны.
Причина № 6. Функциональные возможности работы с массивами СХД требуют отдельных лицензий
VMware достаточно долго пыталась мимикрировать под данную функциональность внутри vSphere, предлагая «тонкие диски», снапшоты виртуальных машин, Storage vMotion, Storage I/O Control, и т.д., и т.п. Жизнь многих из этих фич в будущем прекратится, поскольку внедрение VVols опять же приведет к использованию массива СХД. То есть процесс снятия снапшота виртуальной машины автоматически превратится в создание снапшота массива СХД; аналогично, если для динамического выделения ресурса хранения сейчас применяются «тонкие диски», то в будущем этим будут заниматься массивы СХД. Это даже к лучшему, ибо они позволяют выполнять эти операции быстрее и эффективнее. Тем не менее, чтобы использовать данные функции, для массива СХД потребуются соответствующие лицензии. Одни производители, возможно, включат эту функциональность в основной набор поддерживаемых операций, а другие – нет, поэтому следует уточнить стоимость поддержки указанных функциональных возможностей в вашем конкретном случае.
Причина № 7. Когда подтянутся поставщики решений резервного копирования?
Внедрение VVols коснется архитектуры процесса резервного копирования “Direct to SAN”, поскольку теперь он имеет дело с Protocol Endpoint и VASA storage provider. На данный момент еще нет сведений о массовой поддержке данного подхода со стороны поставщиков решений резервного копирования, но в скором будущем они, конечно, появятся. Узнайте у вашего поставщика, как скоро ваше решение для резервного копирования будет поддерживать VVol. Например, Veeam поддержал vVol в выпущенном недавно обновлении Veeam Availability Suite 8.0 Update 2 (подробнее можно прочитать здесь).
Теперь о позитивном.
Хотя список причин, по которым можно не торопиться с внедрением VVols, выглядит достаточно серьезно, во всех остальных отношениях VVols являются оптимальным архитектурным решением для СХД в среде vSphere и предоставляют множество преимуществ. Так, аналогично тому как VSAN позволяет внедрить Storage Policy Based Management (SPBM) на уровне виртуальных машин, VVols дают ту же возможность для shared storage – и преимущества, конечно, не ограничиваются лишь этим.
Поэтому теперь предлагаю рассмотреть список аргументов «За скорейшее внедрение Virtual Volumes»:
Причина №1. Всегда есть возможность выбора и гибкие опции
Совершенно необязательно «окончательно и бесповоротно» переходить на VVols — виртуальные тома можно использовать и наряду с VMFS или NFS. VVols — это просто еще одна опция для вашей архитектуры. Можно легко перемещать виртуальные машины с VMFS/NFS на VVols и обратно, используя Storage vMotion, так что вы можете настроить Storage Container на виртуальный том и создавать или мигрировать машины, как вам удобно.
Причина №2. Присоединиться к энтузиастам в освоении новых технологий
Перешли с ESX на ESXi позже других и запоздало изучали отличия и нюансы работы? Долго не могли привыкнуть к vSphere Web Client? Давайте оставим в прошлом эти «грабли» и не будем ждать, что VVols придется осваивать в «добровольно-принудительном» режиме. Чем раньше вы приступите к ознакомлению с новинкой, тем уверенней вы будете себя чувствовать, когда другие еще только начнут свои первые робкие шажки в этом направлении. А выступать в роли эксперта – почетно и приятно, ведь здорово, когда людям пригодились знания, которые ты им передал.
Причина №3. Место на диске снова свободно!
Помните, в vSphere 5.0, когда VMware внедрила автоматический возврат неиспользуемого места на диске командой UNMAP, это приводило к ошибкам, и в результате пришлось отказаться от автоматизации этой операции и делать это вручную до сей поры, но теперь автоматизация снова с нами – благодаря VVols. Массив СХД, имея полное представление о удалении или перемещении виртуальной машины, сразу после этого может выполнить возврат более неиспользуемого места. Больше не требуется вручную запускать esxcli — с VVols все происходит автоматически. Если нужен возврат места с еще более высоким уровнем гранулярности, то можно еще выполнить на гостевой ОС команду UNMAP. Такой подход позволит повысить эффективность использования массива СХД.
Причина №4. Доступность во всех редакциях vSphere
Если ваш массив СХД поддерживает VVols, нет нужды переходить на другую редакцию vSphere – с VVols работают все редакции. Настроить VVols несложно, так что это не должно стать сдерживающим фактором, как раз наоборот.
Причина №5. Облегчает переход к Storage Policy Based Management
Не отставайте от пользователей VSAN, которые уже вовсю применяют Storage Policy Based Management. Этот подход к управлению инфраструктурой позволяет вам настраивать политики управления СХД в соответствии с функциональными возможностями массива СХД – таким образом, использование ресурсов и возможностей вашей СХД становится ориентированным непосредственно на виртуальные машины. Управление на основе политик позволяет назначать ресурсы в точном соответствии с потребностями виртуальной машины, а также следить за соблюдением этих назначений. Компания VMware потратила много сил и средств на создание этого механизма управления – и все для того, чтобы обеспечить максимальную эффективность и гибкость при выделении ресурсов массива СХД для виртуальных машин.
Причина №6. Оптимальное использование возможностей массива СХД
Массив СХД – это, по сути, механизм для выполнения операций чтения\записи, а также софт, предназначенный для работы именно с этим механизмом. Вместе они представляют собой мощный инструмент для работы с данными. Использование VMFS и СХД vSphere предполагает, что имеется еще некий «посредник», который указывает собственно массиву СХД, что и когда делать. Разумеется, такая цепочка – не самый эффективный метод работы. Избавившись же от такого «посредника» и дав в распоряжение массиву СХД возможности самоконтроля, мы получили систему с наибольшей эффективностью и оптимальным результатом. Заметим также, что возможности массива СХД куда шире, чем сопоставимой СХД vSphere, плюс к тому, у массива всё куда прозрачнее относительно ресурсов СХД, нежели у vSphere. Естественно, что такие вещи, как как динамическое выделение ресурса (thin provisioning), снапшоты и собственно QoS в реализации с использованием массивов СХД гораздо более эффективны.
Причина №7. Управление VVols не требует специальных навыков
Для того, чтобы работать с VVols, нет необходимости переквалифицироваться в администратора СХД. С задачами администрирования VVols вполне справится среднестатистический ИТ-админ, а если вы – администратор VMware, то вам даже не понадобится лишний раз открывать консоль управления СХД, поскольку интеграция SPBM и VVols с vCenter предоставляет вам единый инструмент управления (можно контролировать политики и виртуальные тома из интерфейса VMware).
Причина №8. Единая архитектура для всех
Файлы или блоки? NFS, iSCSI или Fiber Channel? Теперь это совершенно без разницы, ибо VVols воплощают единую архитектуру программного хранилища для всех протоколов хранения и внедряют, так сказать, единый «уровень общения с vSphere». Если вы используете VVols, вам уже неважно, что там было — VMFS и блоки или NFS и файлы, у вас теперь просто VVols и ряд универсальных компонентов, используемых с любым протоколом хранения. Конечно, у каждого протокола есть свои особенности, но VVols позволяет «причесать всех под одну гребенку», поскольку использует не уникальные, а идентичные свойства всех протоколов.
Причина №9. Единица хранения – виртуальная машина
И на десерт самая, пожалуй, «вкусная» причина: теперь массивы СХД умеют работать с каждой отдельно взятой виртуальной машиной. С использованием VMFS «прозрачность» распространялась до уровня LUN, и ни уровнем ниже – из-за этого мы не имели представления о том, какие машины находятся на том или ином томе VMFS. С внедрением VVols парадигма меняется: единицей хранения теперь стала виртуальная машина. К примеру, если мы хотим сделать снапшот массива для одной машины, это вполне осуществимо (тогда как с VMFS нам приходилось делать снапшот для всего LUN). Если вам нужно назначить политики QoS на конкретные виртуальные машины Tier-1, это также можно сделать, поскольку эта функциональная возможность теперь работает на уровне виртуальных машин. Таким образом, мы отходим от концепции VMFS, которая была недостаточно эффективной с точки зрения использования массивов СХД. Теперь мы можем выделять ресурсы на СХД по мере необходимости, без того, чтобы резервировать огромные пространства для VMFS. Это и была основная идея, которую VMware воплотила в Virtual Volumes.
Разумеется, каждый будет решать вопрос об использовании Virtual Volumes, основываясь на своем собственном понимании ситуации. (Все же помните, что наступит момент, и станут говорить уже не «если вы перейдете на VVols», а «когда вы переходите на VVols».) Без сомнения, у нового подхода есть значительные преимущества – в частности, это наиболее эффективное выделение ресурсов для виртуальных машин – но до принятия решения следует тщательно проанализировать, как внедрение VVols согласуется с текущей работой вашей инфраструктуры и перспективами ее развития. Поскольку же переход на новую архитектуру можно совершать постепенно, как уже было сказано, используя Virtual Volumes наряду с NFS или VMFS (то бишь «есть слона по частям»), я могу его только приветствовать.



