🐱 Как ИИ рисует котиков. Говорим о генеративно-состязательных нейросетях (GAN)
Теперь компьютеры могут самостоятельно создавать реалистичные изображения, в том числе и картинки с милыми котиками.


Оля Ежак для Skillbox Media
Ян Гудфеллоу — хороший друг
Ян учился в аспирантуре Монреальского университета (Канада) и работал над диссертацией по нейронным сетям. Однажды вечером начинающие учёные отмечали в баре защиту диплома своего коллеги. Они обсуждали, как можно научить компьютер рисовать. И не просто рисовать, а создавать изображения, неотличимые от настоящих фотографий. Например, кошек, ведь все же любят разглядывать фото котиков. И почему бы не заставить алгоритмы генерировать их в неограниченном количестве?
Друзья Гудфеллоу полагали, что для этого потребуется заложить в компьютерную программу математические формулы и правила, описывающие, как должны располагаться элементы фотографии, чтобы из них получилось реалистичное изображение. Но Ян утверждал, что такой подход не сработает. Невозможно измерить гармонию и перевести её на сухой язык математики.
Гудфеллоу настаивал на использовании нейронных сетей, исследованием которых занимался. Однако коллеги скептически отнеслись к этой идее. Нейросети ранее уже пытались применять для рисования, и результаты были далеки от идеала. К тому же нейросети требовали длительного процесса обучения с участием человека.
И тогда Гудфеллоу предложил гениальную модель: в ней не одна, а две нейронные сети. И они сами обучают друг друга. Первая генерирует изображения, вторая оценивает плоды её работы. Если созданная картинка выглядит неестественно, вторая сеть вернёт её на доработку. Но если картинка окажется хорошей, нейросеть допустит её для показа людям.
Все сомневались, что это сработает. Вернувшись домой, Гудфеллоу не лёг спать. Всю ночь он писал программу, работающую по этой модели. К утру всё было готово: нейросети успешно генерировали реалистичные изображения. И не только кошек, но и практически чего угодно.
Ян Гудфеллоу опубликовал результаты в научной статье. Новую модель он назвал генеративно-состязательной сетью (GAN). Так молодой учёный не только помог своим друзьям, но и подарил искусственному интеллекту возможность творить.

«Генеративно-состязательные сети — это самая интересная идея в машинном обучении за последние десять лет».
Ян Лекун,
директор по исследованиям искусственного интеллекта Facebook (цитата)
Сейчас GAN повсеместно применяют для автоматической генерации изображений. Они создают картинки с животными (котики традиционно в приоритете) и с людьми, пишут произведения изобразительного искусства, которые выставляются в крупных галереях, в том числе и в нашей Третьяковке.
Пожалуй, самым известным и скандальным достижением генеративно-состязательных сетей стала продажа на аукционе Christie’s картины, созданной искусственным интеллектом. Полотно под названием «Портрет Эдмонда Белами» (на нём изображен вымышленный человек) ушло в 2018 году с молотка
за 432 500 долларов.

Придумав персонажа по фамилии Белами, создатели картины остроумно отдали дань уважения Яну Гудфеллоу, изобретателю GAN. Его фамилия на английском означает «хороший друг». А если перевести её на французский, то как раз получится bel ami.
Судьба Гудфеллоу и его изобретения сложилась успешно. В 2017 году американские учёные внесли его в список «Лучших молодых новаторов». За несколько последних лет Ян успел поработать в передовых лабораториях по созданию искусственного интеллекта: в Google Brain, в проекте Илона Маска OpenAI и в Apple.

Автор статей про IT-технологии. Преподаватель, доцент. Инженер по первому образованию, по второму — журналист. Кандидат технических наук.
Разбираемся, как это работает
Нейронные сети — это упрощённые компьютерные аналоги человеческого мозга, их главное преимущество — способность обучаться на примерах. Они могут менять внутренние настройки, чтобы улучшать результаты работы.
В генеративно-состязательной модели, как мы уже поняли, содержатся две нейронные сети, и работают они автономно, практически без вмешательства человека.
Предположим, что перед ними стоит задача — научиться создавать изображения кошек.
Первая нейросеть называется генератором, её часто обозначают буквой G, мы можем условно именовать её сетью-художником. Она учится рисовать котов и предъявляет результаты работы второй нейросети — дискриминатору, он обозначается буквой D. Её мы можем условно назвать сетью-экспертом.
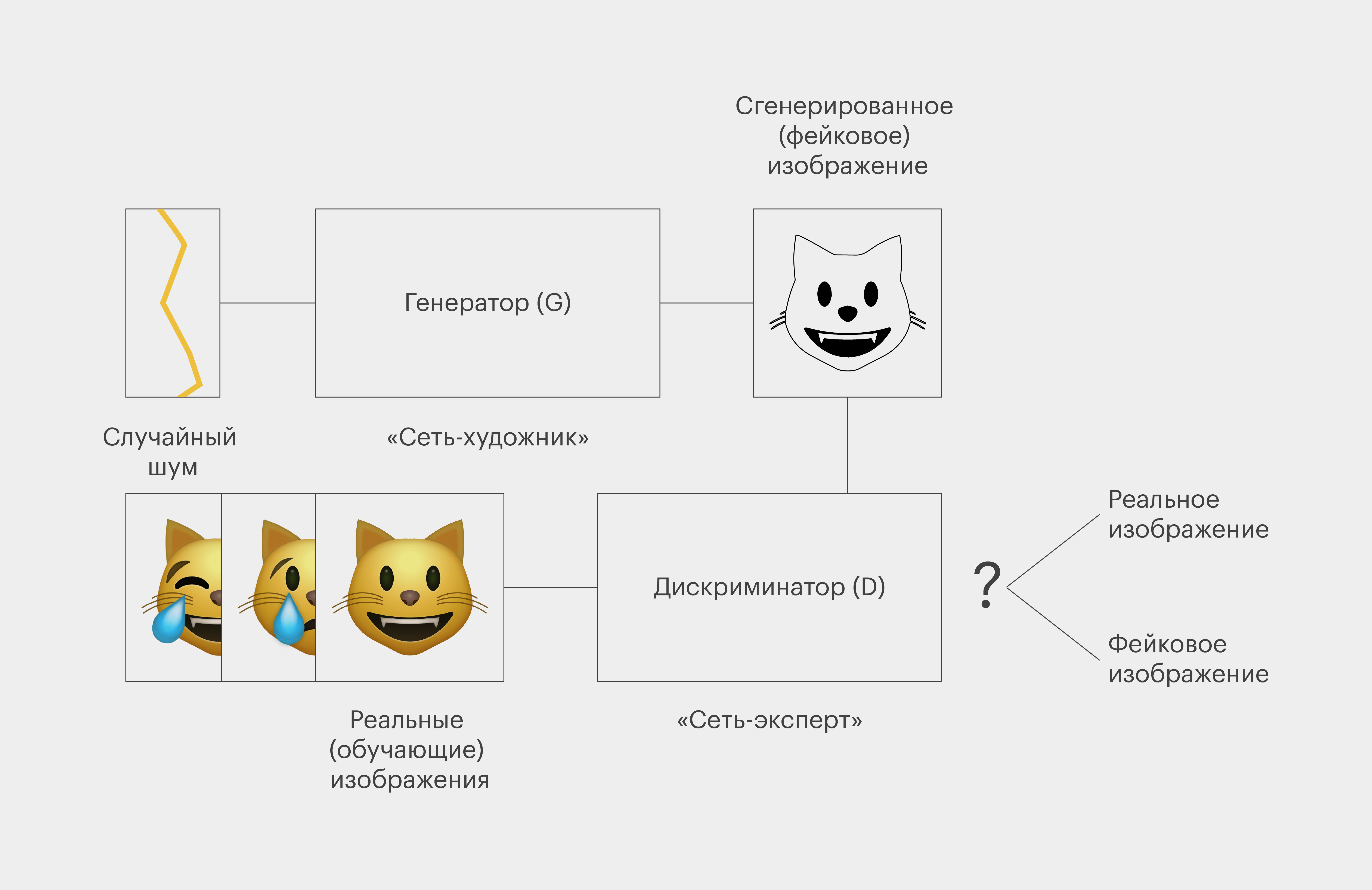
Чтобы стать экспертом в области изображения кошек, дискриминатор прошёл отдельное предварительное обучение. Он изучил тысячи реально существующих фотографий котиков.
Рассмотрев все эти изображения, сеть-эксперт сформировала своё представление о том, как могут выглядеть кошки (например, что у них есть лапы, хвост, усы, глаза). При этом дискриминатор не получил от программистов никаких дополнительных данных, поэтому его знания не являются полными.
Далее в работу включается сеть-художник. Она вообще не представляет, как могут выглядеть коты. Её задача — постоянно рисовать что-нибудь, предъявлять рисунки сети-эксперту, получать от неё обратную связь и совершенствовать свои творения.
Вначале создаваемые генератором картинки совершенно не похожи на кошек и могут выглядеть как жёлтые кляксы. Естественно, дискриминатор отвергает такие рисунки, но при этом он выдаёт генератору косвенные подсказки о том, как следует изменить изображения, чтобы они более соответствовали его представлениям о кошках.
Получив множество отказов, сеть-художник не теряет оптимизма. С упорством творческого маньяка она раз за разом переделывает рисунки и пытается протащить их через строгую экспертизу дискриминатора.
Сети словно состязаются между собой — отсюда и название модели. При этом победа одной сети неминуемо означает поражение второй и наоборот. Генератор обучается так, что пытается максимизировать вероятность ошибки дискриминатора. Дискриминатор, с другой стороны, пытается минимизировать вероятность своей ошибки. В науке такую ситуацию называют минимаксной игрой.
Через несколько тысяч попыток генератор, наконец, создаёт реалистичное изображение кота, и дискриминатор не может отличить его от настоящего. Для генератора это будет очевидная победа, а вот для дискриминатора — поражение. Ведь он принял фейкового кота за реальную фотографию, а значит, ошибся.
В итоге модель выдает людям только те картинки, которые прошли через фильтр дискриминатора. Поскольку сеть-эксперт не обладает всей полнотой знаний о строении кошек, то, к сожалению, иногда пропускает изображения-уродцы вроде кошек с глазами на хвосте (слабонервным лучше не смотреть!).
Чтобы творить разнообразные изображения, генератор получает на свой вход случайный шум. Элемент случайности позволяет сети-художнику создавать разные варианты изображения котов: менять цвет шерсти, форму тела, расположение лап, глаз и так далее. Иначе был бы велик соблазн всё время предъявлять сети-эксперту одну и ту же картинку, которая однажды успешно прошла через фильтр.
Конечно, это очень упрощённое описание, но оно даёт общее представление о принципах работы GAN.
Посмотрим результаты — с котиками и не только
Крупнейшие IT-компании и простые энтузиасты разработали множество своих вариантов реализации генеративно-состязательных нейросетей.
Например, сотрудники компании Google представили в 2018 году алгоритм под названием BigGAN. Он генерирует настолько правдоподобные изображения, что его результаты впечатлили даже Яна Гудфеллоу.
В том же году NVIDIA создала собственную модель StyleGAN. Её код и вся интересующая специалистов информация были опубликованы на GitHub. Создатели обучили сеть генерировать изображения несуществующих человеческих лиц, автомобилей, спален и, конечно же, кошек. Результаты работы StyleGAN разработчики выложили в интернете.
Вдохновившись этой моделью нейросетей, инженер Филипп Ван создал на базе StyleGAN сервис This Cat Does Not Exist («Этого кота не существует»). Если вы зайдёте на сайт, то увидите на экране изображение несуществующего кота, созданное с помощью генеративно-состязательной сети. Чтобы сгенерировать новую картинку, достаточно просто обновить страницу в браузере.

Аналогичные сайты Ван создал для картинок с лошадьми и для человеческих лиц.
Сервис по генерации изображений несуществующих людей получил неожиданную популярность среди многочисленных злоумышленников. Используя возможности искусственного интеллекта, они создали в соцсетях фейковые страницы, заполненные реалистичными фотографиями вымышленных пользователей. Поддельные аккаунты используются для онлайн-мошенничества, распространения дезинформации и спама.
Руководителям сайтов теперь пришлось озаботиться созданием алгоритмов, способных распознавать таких лжепользователей. Например, администраторы Facebook уже удалили более трёх миллиардов (!) подозрительных аккаунтов.
Также GAN широко используются в современном изобразительном искусстве. И «Портрет Эдмонда Белами» — далеко не единственный образец. Многие художники применяют компьютерные технологии в своём творчестве.
Например, София Креспо создала с помощью компьютера цикл картин под названием «Нейронный зоопарк». Благодаря GAN ей удалось сгенерировать изображения, сочетающие в себе черты нескольких животных и растений. Получилось довольно симпатично, результаты вы можете оценить и сами, заглянув на сайт Neural Zoo.
Ещё один проект Софии — This Jellyfish Does Not Exist («Этой медузы не существует»). При каждом обновлении страницы сайт выдает фейковое изображение небольшой медузы, полученное с помощью нейронных сетей.
И напоследок, забавный сервис, связанный с нейронными сетями и кошками. Американский учёный Кристофер Гёссе разработал алгоритм edges2cats, что можно перевести как «каракули-в-котов». Он предназначен для превращения нарисованных от руки картинок в фотореалистичные изображения кошек.
Чтобы воспользоваться программой, нужно зайти на сайт и нарисовать что-то, хотя бы отдалённо напоминающее усато-полосатое животное. Остальную работу за вас выполнит нейронная сеть. Кстати, сервис работает ещё с изображениями сумок, обуви и фасадов зданий.
Подведём итоги
Изобретение Яна Гудфеллоу изменило наш мир навсегда. Новая модель нейронных сетей подарила искусственному интеллекту способность творить. Теперь, когда мы смотрим на фотографии людей, котов, лошадей или даже медуз, мы не можем быть до конца уверены в том, что это не искусно сделанная компьютером подделка.
Если вы любите котиков (хотя это необязательно), желаете больше узнать о нейронных сетях и получить востребованную профессию в этой стремительно развивающейся области знаний, то программы Skillbox помогут вам в этом.
По-английски: Generative Adversarial Network.
Устойчивость обучения GAN
Впервые идея GAN была опубликована Яном Гудфеллоу Generative Adversarial Nets, Goodfellow et alб 2014, после этого GAN’ы являются одними из лучших генеративнх моделей.
Как и у любой другой генеративной модели задача GAN построить модель данных, а если более конкретно научиться генерировать семплы из распределения максимально близкого к распределению данных (обычно имеется датасет ограниченного размера, распределение данных в котором мы хотим промоделировать).
GAN’ы огромным количеством достоинств, но у них есть один существенный недостаток – их очень сложно обучать.
В последнее время вышел ряд работ посвященных устойчивости GAN:
Я пытался сделать текст максимально простым и по-возможности использовать только простейшую математику. К сожалению, для того чтобы обосновать почему мы можем рассматривать свойства 2-х мерных векторных полей, приходится немножко копнуть в сторону вариационного исчисления. Но если кому-то эти термины не знакомы – можете смело переходить сразу к рассмотрению 2-х мерных векторных полей для разных типов GAN.
Мы попробуем сейчас заглянуть под капот процедуры обучения и понять чтоже там происходит.
GAN, основная проблема
GAN’ы состоят из двух нейронных сетей: дискриминатора и генератора. Генератор — позволяет семплировать из некоторого распределения (обычно его называют распределением генератора). Дискриминатор получает на вход семплы из оригинального датасета и генератора и учится предсказывать откуда этот семпл (датасет или генератор).

Процесс обучения GAN выглядит следующим образом:
Нас будет интересовать совсем другое. А именно, из-за того что у нас идет соревнование двух нейронных сетей, задача перестает быть поиском минимума (максимума), а превращается в частных случаях в поиск седловой точки (т.е на 2 и 3 шаге мы один и тот же функционал пытаемся максимизировать по параметрам дискриминатора и минимизировать по параметрам генератора), а в более общих на 2 и 3 шаге мы можем оптимизировать абсолютно разные функционалы. Очевидно что задача минимакса это частный случай оптимизации разных функционалов – один функционал берется с разными знаками.
Давайте посмотрим на это в формулах. Будем считать что pd(x) – распределение откуда семплирован датасет, pg(x) – это распределение генератора, D(x) – выход с дискриминатора.
При обучении дискриминатора мы зачастую максимизируем такой функционал:


При обучении генератора мы максимизируем:

Вектор градиентов при этом:

В дальнейшем мы увидим что можно функционалы заменить соответственно на:


Где  выбираются по определенным правилам. Кстати Ян Гудфеллоу в своей оригинальной статье использует
выбираются по определенным правилам. Кстати Ян Гудфеллоу в своей оригинальной статье использует  как при обучении обычного дискриминатора, а
как при обучении обычного дискриминатора, а  выбирает таким чтобы улучшить градиенты на начальном этапе обучения:
выбирает таким чтобы улучшить градиенты на начальном этапе обучения:

На первый взгляд казалось бы задача очень похожа на обычную задачу обучения градиентным спуском (подъемом). Почему же тогда все кто сталкивался с обучением GAN’ов сходятся в том что это чертовски трудно?
Ответ кроется в структуре векторного поля, которое мы используем для обновления параметров нейронных сетей. В случае обычной задачи классификации мы используем только вектор градиентов, т.е поле является потенциальным (собственно оптимизируемый функционал является потенциалом этого векторного поля). А потенциальные векторные поля обладают некоторыми замечательными свойствами, одним из которых является отсутствие замкнутых кривых. Т.е в этом поле невозможно ходить кругами. А вот при обучении GAN несмотря на то что векторные поля для генератора и дискриминатора по отдельности являются потенциальными (это же градиетны), суммарное векторное поле не будет потенциальным. А это означает, что в этом поле могут быть замкнутые кривые, т.е мы можем ходить кругами. А это очень и очень плохо.
Возникает вопрос почему же все таки нам удается достаточно успешно обучать GAN, может поле таки безвихревое (потенциальное)? А если это так, то почему это так сложно?
Забегу вперед, поле к сожалению не является потенциальным, но оно обладает рядом хороших свойств. К сожалению, поле так же очень чувствительно к параметризации нейронных сетей (выбору функций активации, использованию DropOut, BatchNormalization и т.д.). Но обо всем по-порядку.
“Градиентное” поле GAN
Нам необходимо оптимизировать оба функционала одновременно. Если предположить что D(x) и pg(x) абсолютно гибкие функции, т.е. мы можем в любой точке брать любое число, независимо от других точек. То известный факт из вариационного исчисления – изменять функцию нужно в напралении вариационной производной этого функционала (в общем-то полный аналог градиентного подъема).
Выпишем вариационную производную:


Мы будем рассматривать только первый фукнционал (для дискриминатора), для второго будет все тоже самое.
Но учитывая что на самом деле функцию мы можем менять только в множестве функций которые предствимы нашей нейронной сетью мы запишем:

изменения параметров сети, в общем то обычный градиентный спуск (подъем):

µ — скорость обучения. Ну и производная по параметрам сети:

А теперь собираем все вместе:

Где: 
Я раньше не встречал этой функции в литературе по машинному обучению, поэтому назову ее параметрическим ядром системы.
Ну или если перейти к непрерывным шагам по времи (от разностных уравнений к дифференциальным) получим:

Это уравнение показывает внутреннюю связь оригинального поля (поточечного для дискриминатора) и параметризации нейронной сети. Полностью аналогичное уравнение мы получим для генератора.
Учитывая что K(x,y) (параметрическое ядро) это положительно определенная функция (ну а как же ведь она представима в виде скалярного произведения градиентов в соответсвующих точках), можно сделать вывод что любые изменения обучаемых функций (дискриминатора и генератора) принадлежат гильбертову пространству порожденному ядром, т.е. K(x,y). Интересно можно ли здесь получить какие нибудь содержательные результаты? Но мы в ту сторону смотреть пока не будем, а посмотрим в другую.
Как видно устойчивость GAN определяется двумя составляющими: вариационными производными функционалов и параметризацией нейронной сети. Наша задача посмотреть как ведет себя это поле поточечно, т.е в случае если наша сеть может представить абсолютно любую функцию. Задача превращается в анализ двумерного векторного поля. А это, я думаю, в наших силах.
Устойчивость


Очевидно что эти уравнения можно рассматривать всего лишь для одной точки х, с учетом того как выглядят наши вариационные производные:


Первое требование к этой системе уравнений – правые части должны обращаться в 0 когда: 
Иначе мы будем пытаться обучать модель, которая заведомо не будет сходится к правильному решению. Т.е. D обязано быть решением следующего уравннеия:

Обозначим это решение как  .
.
С учетом того что pg(x) плотность вероятности к правой части мы можем прибавить любое число не нарушая производных. Для того чтобы обеспечить 0 правой части в нужной точке вычтем значение в т. (это необходимо делать, если мы хотим рассматривать pg поточечно – переход от поля параметризованного плотностями вероятностей к свободным полям).
Как результат получаем следующее поле:

C этого момента будем изучать точки покоя и устойчивость полей именно такого вида.
Мы можем изучать два вида устойчивости: локальную (в окрестности точки покоя) и глобальную (используя метод функций Ляпунова).
Для изучения локальной устойчивости необходимо вычислить матрицу Якоби поля.
Для того чтобы поле было локально “устойчивым” необходимо чтобы собственные числа имели отрицательную действительную часть.
Различные виды GAN
Классический GAN
В классическом GAN мы используем обычный logloss:
Для обучения дискриминатора необходимо его максимизировать, для генератора – минимизировать. При этом поле будет выглядеть так:


Давайте посмотрим как будут эволюционировать параметры (pg и D) в этом поле. Для этого используем такой простой питоновский скрипт:
Для начальной точки  это будет выглядеть так:
это будет выглядеть так:
Точка покоя такого поля будет: pg = pd и D = 0.5
Можно легко проверить что действительные части собственных чисел матрицы Якоби отрицательны, т.е поле локально устойчиво.
Мы не будем заниматься доказательством глобальной устойчивости. Но если очень интересно можно поиграться с питоновским скриптом и убедиться что поле устойчиво для любых допустимых начальных значений.
Модификация Яна Гудфеллоу
Поле же будет выглядеть так:

Питоновский скрипт будет тот же, только отлична функция поля:
И при тех же начальных данных картинка выглядит так:
И опять же легко проверить что поле будет локально устойчивым.
Т.е с точки зрения сходимости такая модификация не ухудшает свойства GAN, зато имеет свои преимущества с точки зрения обучения нейронных сетей.
Wasserstein GAN

Где D принадлежит классу 1-Липшицевых функций по х.
Мы хотим максимизировать его по D и минимизировать по pg.
Очевидно что в этом случае: 
И поле будет выглядеть так:


В этом поле легко угадывается окружность с центром в точке  .
.
Т.е если мы пойдем по этому полю, то будем вечно ходить по кругу.
Вот пример траектории в таком поле:
Возникает вопрос, почему же тогда получается обучать этот вид GAN? Ответ очень прост – в данном анализе не учитывается факт 1-Липшицевости D. Т.е мы не можем брать произвольные функции. Кстати это хорошо согласуется с результатами авторов… статьи. Для избежания хождения по кругу они рекомндуют тренировать дискриминатор до сходимости: Wasserstein GAN
Новые варианты GAN
Подбором функций  можно создавать различные варианты GAN. Главное требование к этим функциям это обеспечить наличие «правильной» точки покоя и устойчивость этой точки (желательно глобальную, но хотя бы локальную). Предоставляю читателю возможность самому вывести ограничения на функции f1, f2 и f3, необходимые для локальной устойчивости. Это несложно – достаточно рассмотреть квадратное уравнение для собственных чисел матрицы Якоби.
можно создавать различные варианты GAN. Главное требование к этим функциям это обеспечить наличие «правильной» точки покоя и устойчивость этой точки (желательно глобальную, но хотя бы локальную). Предоставляю читателю возможность самому вывести ограничения на функции f1, f2 и f3, необходимые для локальной устойчивости. Это несложно – достаточно рассмотреть квадратное уравнение для собственных чисел матрицы Якоби.
Приведу пример такого GAN:

Опять же предлагаю читателю самому построить поле этого GAN и доказать его устойчивость. (Кстати это одно из немногих полей для которого доказательтво глобальной устойчивости элементарно – достаточно выбрать функцию Ляпунова расстояние до точки покоя). Только нужно учесть что точка покоя D = 1.
Заключение и дальнейшие исследования
Из приведенного анализа видно что все классические GAN (за исключением Wassertein GAN, которая имеет свои способы улучшения стабильности) обладают «хорошими» полями. Т.е. следование этим полям имеет единственную точку покая в которой распределение генератора равно распределению данных.
Почему же тогда обучение GAN такая тяжелая задача. Ответ прост – параметризация нейронных сетей. При «плохой» параметризации мы можем так же пойти гулять кругами. Например в мои эксперименты показывают что, например, использование BatchNormalization в любой из сетей сразу превращает поле в замкнутое. А лучше всего работает Relu активация.
К сожалению на данный момент нет ни единого способа теоретически проверить какие элементы нейросети как меняют поле. Мне докажется переспективным исследовать свойства парметрического ядра системы —  .
.
Хотелось еще рассказать про способы регуляризации полей GAN и взгляд с позиции двумерных полей на это. Рассмотреть алгоритмы Reinforcement Learning с этой позиции. И еще много чего. Но к сожалению, статья и так получилась слишком большой, так что об этом как нибудь в другой раз.



