Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа
На предыдущих занятиях мы с вами познакомились с популярной рекуррентной архитектурой LSTM. Она эффективна при анализе долгосрочного контента, но имеет один существенный недостаток – большое число настраиваемых параметров (весовых коэффициентов). Это приводит к большим затратам памяти и длительному процессу обучения таких сетей. Поэтому в 2014 году было предложено упрощение LSTM, которое стало известно под названием управляемые рекуррентные блоки:
Gated Recurrent Units (GRU)
По эффективности блоки GRU сравнимы с LSTM во многих практических задачах: моделирования музыкальных и речевых сигналов, обработка текста и так далее. Существует несколько вариантов этого блока и, как всегда, мы рассмотрим их классическую архитектуру:
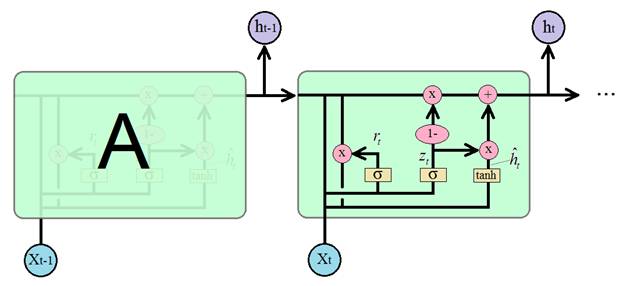

Работа этого блока (ячейки) похожа на блок LSTM только здесь долгосрочный элемент памяти реализован не отдельным каналом, а в самом векторе скрытого состояния  . Наверху мы также видим две поэлементные операции умножения и сложения для забывания ненужной информации и запоминания новой:
. Наверху мы также видим две поэлементные операции умножения и сложения для забывания ненужной информации и запоминания новой:
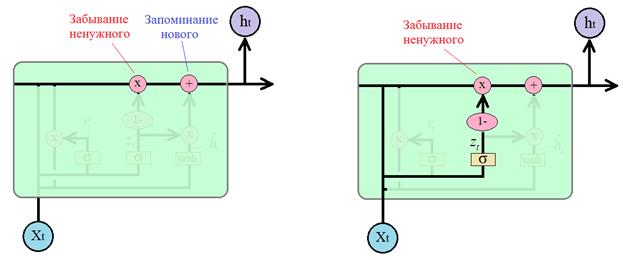
Для определения что забыть, а что оставить, используется вектор

который, затем, поэлементно вычитается из 1 и умножается на вектор предыдущего состояния  :
:

Почему мы здесь делаем это вычитание? Чтобы противоположную информацию использовать как маркер для добавления нового в соседней ветке. Если ее полностью расписать, то получится следующая операция:

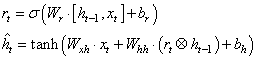
И вычисленная величина добавляется как то, что нужно «запомнить» в векторе скрытого состояния для следующей итерации. В итоге, вычисление имеет вид:

Эта формула и определяет принцип работы ячейки GRU. Если кто из вас знаком с калмановской фильтрацией случайных сигналов:
Формула очень похожа на реализацию фильтра Калмана в дискретном времени. В некотором смысле она работает по этому же принципу: отбрасывает случайные (незначительные) детали и сохраняет главное (важное).
Какую же сеть LSTM или GRU выбирать для практического применения? Все зависит от поставленной задачи, но общая рекомендация такая: сначала лучше воспользоваться сетью GRU, так как она быстрее обучается и если точность решения задачи оказывается недостаточной, то есть смысл попробовать сеть LSTM.
Общим преимуществом сетей LSTM и GRU является решение проблемы исчезающего градиента, характерная для простейшей рекуррентной НС, когда при увеличении числа итераций величина градиента стремится к нулю. В LSTM и GRU благодаря наличию ячейки памяти (возможности хранения долгосрочного контента) градиент не уходит ниже определенного уровня, так как он поддерживается значением сигнала сохраняемого контента.
В Keras рекуррентный слой из ячеек GRU формируется подобно ранее рассмотренному LSTM слою. Для этого используется класс:
в котором первый обязательный параметр units определяет число нейронов внутри GRU ячейки:

Подробное описание параметров GRU слоя в Keras смотрите на странице русскоязычной документации:
Модель сети из предыдущего занятия для сентимент-анализа коротких текстов, можно записать в следующем виде:
Как видите, на уровне Keras это делается элементарно: вместо класса LSTM пишется класс GRU и все.
Одним из общих недостатков блоков LSTM и GRU является их переобучение. Так как каждая ячейка содержит большое число нейронов, то сеть, на их основе также получается большой. А это, как мы знаем, прямой путь к переобучению. Чтобы этого избежать, во-первых, нужно контролировать этот эффект по выборке валидации. И, во-вторых, применять инструменты:
Dropout и Batch Normalization
По умолчанию оба параметра равны нулю (Dropout отключен). Также можно использовать Dropout между рекуррентными слоями. Инструмент Batch Normalization используется только между слоями (внутри ячеек он не применяется).
Я, надеюсь, теперь у вас сложилось представление как работают блоки LSTM и GRU и как их применять на практике.
Видео по теме

Нейронные сети: краткая история триумфа

Структура и принцип работы полносвязных нейронных сетей | #1 нейросети на Python



Ускорение обучения, начальные веса, стандартизация, подготовка выборки | #4 нейросети на Python


Функции активации, критерии качества работы НС | #6 нейросети на Python



Как нейронная сеть распознает цифры | #9 нейросети на Python

Оптимизаторы в Keras, формирование выборки валидации | #10 нейросети на Python


Batch Normalization (батч-нормализация) что это такое? | #12 нейросети на Python

Как работают сверточные нейронные сети | #13 нейросети на Python

Делаем сверточную нейронную сеть в Keras | #14 нейросети на Python

Примеры архитектур сверточных сетей VGG-16 и VGG-19 | #15 нейросети на Python

Теория стилизации изображений (Neural Style Transfer) | #16 нейросети на Python

Делаем перенос стилей изображений с помощью Keras и Tensorflow | #17 нейросети на Python

Как нейронная сеть раскрашивает изображения | #18 нейросети на Python

Введение в рекуррентные нейронные сети | #19 нейросети на Python

Как рекуррентная нейронная сеть прогнозирует символы | #20 нейросети на Python

Делаем прогноз слов рекуррентной сетью Embedding слой | #21 нейросети на Python

Как работают RNN. Глубокие рекуррентные нейросети | #22 нейросети на Python


Как делать сентимент-анализ рекуррентной LSTM сетью | #24 нейросети на Python

Рекуррентные блоки GRU. Пример их реализации в задаче сентимент-анализа | #25 нейросети на Python

Двунаправленные (bidirectional) рекуррентные нейронные сети | #26 нейросети на Python

Автоэнкодеры. Что это и как работают | #27 нейросети на Python

Вариационные автоэнкодеры (VAE). Что это такое? | #28 нейросети на Python

Делаем вариационный автоэнкодер (VAE) в Keras | #29 нейросети на Python

Расширенный вариационный автоэнкодер (CVAE) | #30 нейросети на Python

Что такое генеративно-состязательные сети (GAN) | #31 нейросети на Python

Делаем генеративно-состязательную сеть в Keras и Tensorflow | #32 нейросети на Python
© 2021 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
[ В закладки ] Зоопарк архитектур нейронных сетей. Часть 2

Публикуем вторую часть статьи о типах архитектуры нейронных сетей. Вот первая.
За всеми архитектурами нейронных сетей, которые то и дело возникают последнее время, уследить непросто. Даже понимание всех аббревиатур, которыми бросаются профессионалы, поначалу может показаться невыполнимой задачей.
Поэтому я решил составить шпаргалку по таким архитектурам. Большинство из них — нейронные сети, но некоторые — звери иной породы. Хотя все эти архитектуры подаются как новейшие и уникальные, когда я изобразил их структуру, внутренние связи стали намного понятнее.
Название “Глубокие сверточные обратные глубинные сети (Deep convolutional inverse graphics networks, DCIGN)» может ввести в заблуждение, так как на самом деле это вариационные автоэнкодеры со сверточными и развертывающими сетыми в качестве кодирующей и декодирующей частей соответственно. Такие сети представляют черты изображения в виде вероятностей и могут научиться строить изображение кошки и собаки вместе, взглянув лишь на картинки только с кошками и только с собаками. Кроме того, вы можете показать этой сети фотографию вашего кота с надоедливой соседской собакой и попросить ее вырезать собаку и изображения, и DCIGN справится с этой задачей, даже если никогда не делала ничего подобного. Разработчики также продемонстрировали, что DCIGN может моделировать различные сложные преобразования изображений, например, изменение источника света или поворот 3D объектов. Такие сети обычно обучают методом обратного распространения.
Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in Neural Information Processing Systems. 2015.
Original Paper PDF
Генеративные состязательные сети (Generative adversarial networks, GAN) принадлежат другому семейству нейросетей, это близнецы — две сети, работающие вместе. GAN состоит из любых двух сетей (но чаще это сети прямого распространения или сверточные), где одна из сетей генерирует данные (“генератор”), а вторая — анализирует (“дискриминатор”). Дискриминатор получает на вход или обучающие данные, или сгенерированные первой сетью. То, насколько точно дискриминатор сможет определить источник данных, служит потом для оценки ошибок генератора. Таким образом, происходит своего рода соревнование, где дискриминатор учится лучше отличать реальные данные от сгенерированных, а генератор стремится стать менее предсказуемым для дискриминатора. Это работает отчасти потому, что даже сложные изображения с большим количеством шума в конце концов становятся предсказуемыми, но сгенерированные данные, мало отличающиеся от реальных, сложнее научиться отличать. GAN достаточно сложно обучить, так как задача здесь — не просто обучить две сети, но и соблюдать необходимый баланс между ними. Если одна из частей (генератор или дискриминатор) станет намного лучше другой, то GAN никогда не будет сходиться.
Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in Neural Information Processing Systems. 2014.
Original Paper PDF
Рекуррентные нейронные сети (Recurrent neural networks, RNN) — это те же сети прямого распространения, но со смещением во времени: нейроны получают информацию не только от предыдущего слоя, но и от самих себя в результате предыдущего прохода. Следовательно, здесь важен порядок, в котором мы подаем информацию и обучаем сеть: мы получим разные результаты, если сначала скормим ей “молоко”, а затем “печеньки”, или если сначала “печеньки”, а потом уже “молоко”. У RNN есть одна большая проблема — это проблема исчезающего (или взрывного) градиента: в зависимости от используемой функции активации информация со временем теряется, так же как и в очень глубоких сетях прямого распространения. Казалось бы, это не такая уж серьезная проблема, так как это касается только весов, а не состояний нейронов, но именно в весах хранится информация о прошлом; если вес достигнет значения 0 или 1 000 000, то информация о прошлом состоянии станет не слишком информативной. RNN могут использоваться в самых разнообразных областях, так как даже данные, не связанные с течением времени (не звук или видео) могут быть представлены в виде последовательности. Картинка или строка текста могут подаваться на вход по одному пикселю или символу, так что вес будет использоваться для предыдущего элемента последовательности, а не для того, что случилось X секунд назад. В общем случае, рекуррентные сети хороши для продолжения или дополнения информации, например, автодополнения.
Elman, Jeffrey L. “Finding structure in time.” Cognitive science 14.2 (1990): 179-211.
Original Paper PDF
Долгая краткосрочная память (Long short term memory, LSTM) — попытка побороть проблему взрывного градиента, используя фильтры (gates) и блоки памяти (memory cells). Эта идея пришла, скорее, из области схемотехники, а не биологии. У каждого нейрона есть три фильтра: входной фильтр (input gate), выходной фильтр (output gate) и фильтр забывания (forget gate). Задача этих фильтров — сохранять информацию, останавливая и возобновляя ее поток. Входной фильтр определяет количество информации с предыдущего шага, которое будет храниться в блоке памяти. Выходной фильтр занят тем, что определяет, сколько информации о текущем состоянии узла получит следующий слой. Наличие фильтра забывания на первый взгляд кажется странным, но иногда забывать оказывается полезно: если нейросеть запоминает книгу, в начале новой главы может быть необходимо забыть некоторых героев из предыдущей. Показано, что LSTM могут обучаться действительно сложным последовательностям, например, подражать Шекспиру или сочинять простую музыку. Стоит отметить, что так как каждый фильтр хранит свой вес относительно предыдущего нейрона, такие сети достаточно ресурсоемки.
Hochreiter, Sepp, and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9.8 (1997): 1735-1780.
Original Paper PDF
Управляемые рекуррентные нейроны (Gated recurrent units, GRU) — разновидность LSTM. У них на один фильтр меньше, и они немного иначе соединены: вместо входного, выходного фильтров и фильтра забывания здесь используется фильтр обновления (update gate). Этот фильтр определяет и сколько информации сохранить от последнего состояния, и сколько информации получить от предыдущего слоя. Фильтр сброса состояния (reset gate) работает почти так же, как фильтр забывания, но расположен немного иначе. На следующие слои отправляется полная информация о состоянии — выходного фильтра здесь нет. В большинстве случаем GRU работают так же, как LSTM, самое значимое отличие в том, что GRU немного быстрее и проще в эксплуатации (однако обладает немного меньшими выразительными возможностями).
Chung, Junyoung, et al. “Empirical evaluation of gated recurrent neural networks on sequence modeling.” arXiv preprint arXiv:1412.3555 (2014).
Original Paper PDF
Нейронные машины Тьюринга (Neural Turing machines, NMT) можно определить как абстракцию над LSTM и попытку “достать” нейросети из “черного ящика”, давая нам представление о том, что происходит внутри. Блок памяти здесь не встроен в нейрон, а отделен от него. Это позволяет объединить производительность и неизменность обычного цифрового хранилища данных с производительностью и выразительными возможностями нейронной сети. Идея заключается в использовании адресуемой по содержимому памяти и нейросети, которая может читать из этой памяти и писать в нее. Они называются нейронными машинами Тьюринга, так как являются полными по Тьюриингу: возможность читать, писать и изменять состояние на основании прочитанного позволяет выполнять все, что умеет выполнять универсальная машина Тьюринга.
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural turing machines.” arXiv preprint arXiv:1410.5401 (2014).
Original Paper PDF
Двунаправленные RNN, LSTM и GRU (BiRNN, BiLSTM и BiGRU) не изображены на схеме, так как выглядят в точности так же, как их однонаправленные коллеги. Разница лишь в том, что эти нейросети связаны не только с прошлым, но и с будущим. Например, однонаправленная LSTM может научиться прогнозировать слово “рыба”, получая на вход буквы по одной. Двунаправленная LSTM будет получать также и следующую букву во время обратного прохода, открывая таким образом доступ к будущей информации. А значит, нейросеть можно обучить не только дополнять информацию, но и заполнять пробелы, так, вместо расширения рисунка по краям, она может дорисовывать недостающие фрагменты в середине.
Schuster, Mike, and Kuldip K. Paliwal. “Bidirectional recurrent neural networks.” IEEE Transactions on Signal Processing 45.11 (1997): 2673-2681.
Original Paper PDF
Глубокие остаточные сети (Deep residual networks, DRN) — это очень глубокие FFNN с дополнительными связями между слоями, которых обычно от двух до пяти, соединяющими не только соседние слои, но и более отдаленные. Вместо того, чтобы искать способ находить соответствующие исходным данным входные данные через, скажем, пять слоев, сеть обучена ставить в соответствие входному блоку пару “выходной блок + входной блок”. Таким образом входные данные проходят через все слои нейросети и подаются на блюдечке последним слоям. Было показано, что такие сети могут обучаться образцам глубиной до 150 слоев, что намного больше, чем можно ожидать от обычной 2-5-слойной нейросети. Тем не менее, было доказано, что сети этого типа на самом деле просто RNN без явного использования времени, а также их часто сравнивают с LSTM без фильтров.
He, Kaiming, et al. “Deep residual learning for image recognition.” arXiv preprint arXiv:1512.03385 (2015).
Original Paper PDF
Нейронные эхо-сети (Echo state networks, ESN) — еще один вид рекуррентных нейросетей. Они выделяются тем, что связи между нейронами в них случайны, не организованы в аккуратные слои, и обучаются они по-другому. Вместо подачи на вход данных и обратного распространения ошибки, мы передаем данные, обновляем состояния нейронов и в течение некоторого времени следим за выходными данными. Входной и выходной слои играют нестандартную роль, так как входной слой служит для инициализации системы, а выходной слой — в качестве наблюдателя за порядком активации нейронов, который проявляется со временем. Во время обучения изменяются связи только между наблюдателем и скрытыми слоями.
Jaeger, Herbert, and Harald Haas. “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.” science 304.5667 (2004): 78-80.
Original Paper PDF
Extreme learning machines (ELM) — это те же FFNN, но со случайными связями между нейронами. Они очень похожи на LSM и ESN, но используются скорее подобно сетям прямого распространения, и не это связано не с тем, что они не являются рекуррентными или импульсными, а с тем, что их обучают методом обратного распространения ошибки.
Cambria, Erik, et al. “Extreme learning machines [trends & controversies].” IEEE Intelligent Systems 28.6 (2013): 30-59.
Original Paper PDF
Машины неустойчивых состояний (Liquid state machines, LSM) подобны ESN. Главное их отличие в том, что LSM — это разновидность импульсных нейронных сетей: на замену сигмоидальной кривой приходят пороговые функции, и каждый нейрон также является накопительным блоком памяти. Когда состояние нейрона обновляется, значение рассчитывается не как сумма его соседей, а складывается с самим собой. Как только порог превышен, энергия освобождается и нейрон посылает импульс другим нейронам.
Maass, Wolfgang, Thomas Natschläger, and Henry Markram. “Real-time computing without stable states: A new framework for neural computation based on perturbations.” Neural computation 14.11 (2002): 2531-2560.
Original Paper PDF
Метод опорных векторов (Support vector machine, SVM) служит для нахождения оптимальных решений в задачах классификации. В классическом смысле метод способен категоризировать линейно разделяемые данные: например, определить, на каком рисунке изображен Гарфилд, а на каком — Снупи. В процессе обучения сеть как бы размещает всех Гарфилдов и Снупи на 2D-графике и пытается разделить данные прямой линией так, чтобы с каждой стороны были данные только одного класса и чтобы расстояние от данных до линии было максимальным. Используя трюк с ядром, можно классифицировать данные размерности n. Построив 3D граф, мы сможем отличить Гарфилда от Снупи и от кота Саймона, и чем выше размерность, тем больше мультяшных персонажей можно классифицировать. Этот метод не всегда рассматривается как нейронная сеть.
Cortes, Corinna, and Vladimir Vapnik. “Support-vector networks.” Machine learning 20.3 (1995): 273-297.
Original Paper PDF
И наконец, последний обитатель нашего зоопарка — самоорганизующаяся карта Кохонена (Kohonen networks, KN, или organising (feature) map, SOM, SOFM). KN использует соревновательное обучение для классификации данных без учителя. Сеть анализирует свои нейроны на предмет максимального совпадения с входными данными. Наиболее подходящие нейроны обновляются так, чтобы еще ближе походить на входные данные, кроме того, к входным данным приближаются и веса их соседей. То, насколько изменится состояние соседей, зависит от расстояния до наиболее подходящего узла. KN также не всегда относят к нейронным сетям.
Kohonen, Teuvo. “Self-organized formation of topologically correct feature maps.” Biological cybernetics 43.1 (1982): 59-69.
Original Paper PDF



