Практическое применение сервера с FPGA

В данной статье будет рассказано о попытке ускорить операции над разреженными булевыми матрицами, реализованные на OpenCL, с помощью замены целевой платформы GPGPU на FPGA.
Эта задача возникла при работе над библиотекой примитивов линейной алгебры, необходимых для решения некоторых задач анализа графов. Данные, структурированные в виде графов, играют огромную роль в современной жизни и встречаются в таких областях, как социальные сети, транспортные и коммуникационные сети, являются основой для набирающих популярность графовых баз данных.
Объем таких данных неуклонно растет и потому для получения хорошей производительности в задачах анализа графов все острее встает вопрос о разработке параллельных алгоритмов, что оказывается нетривиальной задачей из-за нерегулярности данных.
Одним из подходов к решению такой проблемы является использование линейной алгебры: граф естественным образом представим в виде матрицы (например, матрицы смежности), а задача выражается через операции над матрицами и векторами. Например, построение транзитивного замыкания и поиск кратчайших путей могут быть выражены через произведение и поэлементную сумму матриц смежности в различных полукольцах (булевом и min-plus соответственно).
Данную идею развивает стандарт GraphBLAS, описывающий набор примитивов и операций линейной алгебры, необходимый для реализации различных алгоритмов анализа графов. Этот стандарт определяет операции над произвольными моноидами и полукольцами и его реализация на массово-параллельных платформах является нетривиальной инженерной задачей. Поэтому в данной работе мы сконцентрировались на важном частном случае, на булевой линейной алгебре.
Важным аспектом прикладных задач является то, что реальные графы сильно разрежены: в случае представления их в виде матрицы смежности большинство ячеек окажутся пустыми. Это выдвигает дополнительные требования к реализации операций, так как матрицы должны храниться в специализированных форматах для экономии памяти.
Одной из естественных платформ для реализации операций разреженной линейной алгебры является GPGPU, что подтверждается, например, такими библиотеками, как cuSparse, clSparse и др. Однако, данные библиотеки реализуют операции над такими типами данных, как float или double, что является избыточным при работе с булевыми матрицами. Более того, ряд операций, необходимых при анализе графов (например, произведение Кронекера) в них не представлен. Потому нами была реализована библиотека разреженной булевой линейной алгебры. Языком разработки был выбран OpenCL C для того, чтобы обеспечить максимальную переносимость решения.
Выбор стандарта OpenCL позволил нам рассматривать в качестве целевой платформы не только CPU и GPGPU, но и FPGA, благодаря наличию таких решений, как «Intel FPGA SDK for OpenCL» или SDAccel Environment от Xilinx. Создание программы для FPGA – это прежде всего разработка архитектуры, на которой программа работает наиболее эффективно, а подобные инструменты позволяют использовать FPGA как еще одно устройство для исполнения OpenCL-кода, снимая с разработчика задачу создания архитектуры.
И хотя производители инструментов часто описывают процесс разработки как «написал код, отладил на GPU, запустил на FPGA», вопрос об эффективности результирующего решения без адаптации кода под специфику FPGA в ряде случаев остается открытым.
Наш случай один из таких. Таким образом, нам было необходимо выяснить, можно ли с помощью использования FPGA в качестве целевой платформы повысить производительность библиотеки операций разреженной линейной алгебры. При этом необходимо максимально переиспользовать уже существующий OpenCL-код, эффективно работающий на GPGPU.
Что такое FPGA
Ядром FPGA как устройства является перепрограммируемая логическая матрица (ПЛИС, программируемая логическая интегральная схема), что позволяет изменять логику работы устройства (чипа) и предоставляет разработчику (и пользователю) «мягкий» (изменяемый) чип. Этим ПЛИС принципиально отличаются от «жестких» систем, таких как, например, центральный процессор или графический сопроцессор, низкоуровневая логика работы которых (архитектура) задана единожды при производстве и не может быть изменена в процессе использования.
Схема матрицы представлена на рисунке ниже. Матрица состоит из набора программируемых логических ячеек, поведение которых, как правило, задается таблицами истинности, и программируемых коммутаторов, соединяющих эти ячейки, что позволяет управляемо собирать более сложные функции из простых.
Схема программируемой логической матрицы
Стоит отметить, что современные ПЛИС содержат не только программируемые логические блоки, но и набор предопределенных блоков с более сложными функциями, которые зависят от специфики устройства. Например, большинство ПЛИС содержат мультиплексоры для целых чисел и даже для чисел с плавающей запятой. Такие операции часто используются в различных устройствах и алгоритмах и нет смысла каждый раз программировать их заново и тратить на это логические блоки.
В современном мире можно выделить две больших, частично пересекающихся, группы устройств, именуемых FPGA. Первая категория — это так называемые отладочные платы и дизайн-платы, предназначенные прежде всего для разработки архитектуры новых устройств и ее отладки перед выпуском в серийное производство. Вторая — так называемые FPGA-ускорители, предназначенные для ускорения определенных задач и в чем-то схожие по своим задачам с GPGPU.
Такие ускорители, как и GPGPU, как правило являются специализированными сопроцессорами основного, центрального, процессора и предназначены для того, чтобы быстро решать конкретную, часто достаточно узкую задачу, а взаимодействие с ними на высоком уровне схоже с работой с GPGPU и представлено на рисунке ниже. В нашей задаче нас будет интересовать именно вторая категория, так как мы хотим использовать FPGA как ускоритель для операций линейной алгебры.
Общая схема FPGA-ускорителя.
Custom Core — ядра сконфигурированные для решения конкретной задачи
Изначально для программирования логической матрицы использовались низкоуровневые языки типа VHDL и Verilog, которые предназначались прежде всего для описания архитектуры устройства и логики его работы, для чего и используются по сей день. Однако, когда речь идет об использовании FPGA как ускорителя, возникает потребность в том, чтобы описывать прикладную задачу, для чего указанные языки оказываются слишком низкоуровневыми.
Дабы устранить данную проблему, в настоящее время активно развиваются инструменты, позволяющие использовать OpenCL C для программирования FPGA. Несмотря на то, что предлагаемый язык С-подобен и в известном смысле является низкоуровневым, это существенно упрощает разработку, так как позволяет программировать в более привычных для прикладного разработчика терминах.
Конечно, за повышение уровня абстракции приходится платить, в частности, уменьшением уровня контроля и, возможно, уменьшением производительности решения. Однако, история развития языков программирования показывает, что качественная инструментальная поддержка процесса разработки, хорошие компиляторы, и плюсы высокого уровня абстракции в некоторых сферах позволяют нивелировать незначительные потери в производительности.
В нашем случае для эксперимента использовался набор инструментов Intel FPGA SDK for OpenCL, и плата от Euler Project с установленным чипом Arria 10. А цель как раз и заключалась в том, чтобы выяснить, даст ли использование данного стека технологий возможность получить высокопроизводительное и переносимое решение для разреженной линейной алгебры.
Разреженная линейная алгебра
Как было сказано, одной из особенностей разрабатываемой библиотеки является работа с разреженными структурами данных. В частности, для матриц был выбран формат DCSR — модификация классического CSR (Compressed Sparse Row), предназначенная для сильно разреженных матриц.
В качестве основных операций были выбраны поэлементное сложение двух матриц и классическое умножение, как операции, наиболее часто используемые в прикладных алгоритмах, и наиболее нетривиальные с точки зрения получения высокопроизводительных реализаций (особенно это касается умножения).
Для умножения разреженных матриц на GPGPU разработано множествоалгоритмов и лидирующими по производительности на сегодняшний день являются алгоритмы В. Лю (основанный на слиянии) и Ю. Нагасака (использующий хэш-таблицы). Оба этих алгоритма были реализованы на OpenCL и в результате экспериментов было выяснено, что алгоритм Ю. Нагасака на GPGPU работает быстрее, чем алгоритм В. Лю на интересных для нас данных. В дальнейшем необходимо было оценить их производительность при использовании FPGA в качестве целевой платформы.
Для сложения матриц используется перевод в координатный формат, в котором сложение сводится к объединению двух упорядоченных массивов. Возможности по ускорению этой операции с использованием FPGA также было решено оценить в рамках эксперимента.
Особенности реализации
Хотя мы говорим о том, чтобы использовать для разработки под FPGA уже привычный и знакомый стандарт OpenCL и соответствующий язык программирования, есть ряд особенностей, которые необходимо учитывать при запуске уже имеющегося кода, отлаженного на GPU, на FPGA.
Первая особенность связана с необходимостью статической компиляции для FPGA. Стандарт OpenCL подразумевает распространение программ в виде исходных кодов и компиляцию драйвером конкретного устройства при обращении, что реализовано для большинства GPGPU и чем активно пользуются разработчики, формируя код ядер и компилируя их по ходу выполнения основной программы (хоста). Однако, чтобы запустить код на FPGA, необходима предварительная компиляция, что может потребовать изменений как в кода хоста, так и в кода ядер.
Для компиляции ядер используется компилятор aoc, который в связке с «Intel® Quartus® Prime» создает бинарный файл с описанием архитектуры логической матрицы. Необходимо иметь ввиду, что данный этап очень ресурсозатратный: процесс компиляции небольшого ядра для поэлементного сложения двух векторов может занимать около 40 минут, более сложные ядра, вроде тех, которые возникли в нашей задачи, компилировались порядка 4–6 часов.
Следующий важный момент заключается в том, что результат компиляции не просто «выполняется» FPGA, а фактически перепрограммирует ее. При этом один файл описывает одну конфигурацию. А это означает, во-первых, что загрузка бинарного файла на FPGA занимает существенное время (около секунды в нашем случае), что, например, делает нерациональным использование нескольких файлов для одной матричной операции. Во-вторых, единовременно на FPGA может быть загружен один такой файл. Что приводит к желанию компилировать как можно больше ядер в один бинарный файл.
Однако, чем больше ядер обрабатываются за один вызов компилятора, тем сложнее ему распределить ресурсы FPGA для их выполнения этих ядер. Более того, ресурсы FPGA ограничены, что также ограничивает количество ядер, которые могут компилироваться, а значит и выполняться, одновременно.
Так, например, умножение с хэш-таблицами (алгоритм Нагасака) содержит 16 различных ядер, но и такое количество не удалось скомпилировать на устройстве из-за недостатка ресурсов. Типичное предупреждение в таком случае — предупреждения о превышении допустимых ресурсов памяти:
Большое количество ядер в умножении связано с группировкой рядов матрицы по ожидаемым вычислительным затратам. Мы сокращали количество групп, пока процесс компиляции не завершился успешно. Сложение требует значительно меньшего числа ядер, и его удалось запустить без существенных изменений.
Эксперименты
Для экспериментов были выбраны квадратные матрицы из SuiteSparse Matrix Collection различного размера и различной степени заполненности. Характеристики матриц приведены в таблице 2 (Nnz — Number of Non Zeroes, количество ненулевых элементов). Умножение тестировалось на возведении матрицы в квадрат, а сложение на вычислении суммы матрицы со своим квадратом, где квадрат заранее предпросчитан.
Для возможности оценить эффект от использования FPGA, эксперименты были проведены как на FPGA (Intel® Arria® 10), так и на GPGPU (AMD Radeon Vega Frontier Edition). Детальные характеристики оборудования, на котором производились измерения, представлены в таблице 1.
| Вендор | AMD | Intel |
|---|---|---|
| Имя | Radeon Vega Frontier Edition | Arria® 10 |
| Глобальная память, Gb | 15,98 | 8 |
| Локальная память, Kb | 64 | 16 |
| Макс. размер блока | 256 | 2147483647 |
| Частота, MHz | 1600 | 1000 |
| Число АЛУ | 4096 | 427200 |
Таблица 1. Характеристика оборудования, использованного для замеров производительности
Необходимо отметить, что указанная для FPGA частота — это максимальная частота тактового генератора. Реальная частота зависит от выполняемого кода и в нашем случае, по информации, полученной от компилятора (статистика Kernel clock), для сложения и умножения составляет порядка 240 MHz.
Отметим, что при экспериментах измерялось время работы «клиентской» функции, то есть время необходимое на передачу данных на FPGA и обратно включается в замеры. Аналогично и для GPU. Результаты экспериментов показаны в таблице 2. Время измерялось в миллисекундах. Прочерк означает, что не удалось дождаться завершения вычислений за разумное время.
| Сложение (мс) | Умножение (мс) | ||||||
|---|---|---|---|---|---|---|---|
| № | Число строк, млн | Nnz(M), млн | Nnz(M + M2), млн | GPGPU | FPGA | GPGPU | FPGA |
| 1 | 0,06 | 0,24 | 0,92 | 1,71 ± 0,30 | 86,51 | 2,78 ± 1,46 | 5590,79 |
| 2 | 0,11 | 0,24 | 0,39 | 1,32 ± 0,12 | 58,54 | 2,43 ± 0,25 | 9824,65 |
| 3 | 0,40 | 3,20 | 14,97 | 11,43 ± 3,18 | 1572,83 | 38,60 ± 3,92 | 40527,5 |
| 4 | 0,74 | 5,16 | 26,40 | 17,19 ± 4,59 | 2714,14 | 55,65 ± 6,07 | 67595,9 |
| 5 | 0,92 | 5,11 | 30,81 | 19,34 ± 4,68 | 3077,81 | 85,97 ± 8,78 | 77601,9 |
| 6 | 1,09 | 3,08 | 9,93 | 7,92 ± 2,58 | 944677 | 19,75 ± 1,27 | 96978,8 |
| 7 | 1,39 | 3,84 | 12,26 | 9,01 ± 2,68 | 1167,12 | 23,29 ± 1,68 | 122992 |
| 8 | 1,44 | 3,10 | 8,41 | 6,78 ± 2,59 | 771219 | 23,08 ± 1,84 | 126465 |
| 9 | 1,97 | 5,53 | 17,74 | 11,89 ± 3,23 | 1686,66 | 29,35 ± 1,65 | 175612 |
| 10 | 2,22 | 4,88 | 13,63 | 9,27 ± 2,81 | 1248,45 | 29,66 ± 0,85 | — |
Таблица 2. Сравнение производительности сложения и умножения матриц на GPGPU AMD Radeon Vega Frontier Edition и FPGA Intel® Arria® 10
Как видно из результатов экспериментов, код, ориентированный на особенности GPU, оказался неэффективен на устройстве с совершенно другой архитектурой. Здесь, правда, нужно учесть, что при работе с разреженными матрицами и на видеокартах не происходит полной утилизации мощности устройства.
Результаты, которых удалось добиться сообществу к настоящему моменту — это итог многих лет развития алгоритмов для работы с разреженными матрицами и экспериментов с распределением нагрузки, способами обработки строк.
Чтобы выявить причину столь существенного замедления, были отдельно проанализированы все этапы алгоритмов. Одним из самых слабых мест оказалась префиксная сумма, которая используется как в сложении, так и в умножении. Например, на массиве размером 10^7 элементов данная операция занимает в среднем 253 мс, тогда как даже центральный процессор может выполнить данную операцию за 79 мс (при неоптимизированной реализации).
К сожалению, нам не удалось найти реализацию префиксной суммы для FPGA, которая была бы сравнима с GPU по производительности, и, судя по возникающим в сообществе вопросам, эта проблема все еще остается открытой.
Выводы
Проведенный эксперимент показал, что создание переносимой библиотеки для разреженной линейной алгебры на OpenCL C хотя и возможно, но в текущих реалиях использование FPGA как целевой платформы не дает выигрыша в производительности. При этом, необходимо обратить внимание на следующие важные моменты.
Во-первых, эффективная реализация операций разреженной линейной алгебры — область, в которой до сих пор ведутся работы даже для таких более привычных платформ, как многоядерные CPU и GPGPU. Создание подобных решений для FPGA — область, в которой ведуться активные исследования («The algorithms for FPGA implementation of sparse matrices multiplication», «SpArch: Efficient Architecture for Sparse Matrix Multiplication»), и на текущий момент с использованием более низкоуровневых средств.
Во-вторых, проведенный эксперимент показал зрелость стека технологий, применяемого для разработки под FPGA с использованием OpenCL C: реализованные в ходе эксперимента современные алгоритмы сложения и умножение разреженных матриц весьма сложны и достаточно объемны на фоне, например, реализации сверточных фильтров.
Отдельно необходимо отметить, что, хотя мы и говорим об использовании стандарта OpenCL, в действительности, для повышения эффективности разрабатываемых решений, для FPGA, как Intel, так и Xilinx предоставляют специфичные расширения языка. Вместе с этим, существуют и специфичные техники оптимизации кода, уместные для FPGA, но вряд ли применимые, например, для GPGPU.
Таким образом, технология уже достаточно зрелая, чтобы использовать ее для решения реальных задач. Необходимо только аккуратно проанализировать особенности предметной области и конкретной решаемой задачи. Так, существует ряд вычислительных задач, которые одинаково хороши как для видеокарт, так и для FPGA. Например, обработка изображений и видео. И вот для таких задач переносимые решения, утилизирующие как FPGA, так и GPGPU, уже могут быть разработаны в единой среде с использованием OpenCL C.
Автор текста — Семен Григорьев (Доцент кафедры информатики СПбГУ)
Технология FPGA для тысячи применений
Трудно представить другую технологию, которая настолько разносторонняя как FPGA.
FPGA — Field-Programmable Gate Array, то есть программируемая логическая матрица (ПЛМ), программируемая логическая интегральная схема (ПЛИС). Это технология, при которой создается микросхема с набором логических элементов, триггеров, иногда оперативной памяти и программируемых электрических связей между ними. При этом программирование FPGA оказывается похоже на разработку электрической схемы, а не программы. Пользуюсь данной технологией давно и попробую описать самые полезные с моей точки зрения применения по мере их усложнения.
1. Помощь при разводке плат
Многие наверняка сталкивались, что центральный процессор, память, другие многоногие микросхемы создавали люди, редко задумывающиеся о том, как они будут соединяться на печатной плате. Протянуть шину разрядностью 32 или 64 бита — задача не решаемая без многослойной платы. Но стоит поставить между микросхемами FPGA как разводка становится на несколько порядков проще:
2. Согласование уровней сигналов
Часть микросхем имеет интерфейс 1.2В, другая 1.5, 1.8, 2.5, 3.3В, и все эти микросхемы можно подключить к одной FPGA и обеспечить двусторонний обмен за счет того, что любая FPGA имеет несколько банков ввода-вывода, каждый из которых может иметь свое опорное напряжение сигналов. Например, так:
3. Обеспечение надежности устройства
FPGA достаточно дорогие, но надежные устройства. Они начинают включаться при меньшем напряжении, чем номинальное, выдерживают импульсные наводки, часто короткое замыкание на ножках IO, быстро загружаются и могут использоваться для контроля и управления процессорами и умной периферией. Плюс могут реализовывать вспомогательные функции коммутации, задержек, моргания светодиодом и так далее. Мне очень нравится использовать FPGA (маленький PLD) как умный сторожевой таймер и схема запуска — ни разу не подводил.
4. Автоматы состояний или аппаратное программирование
Если на процессоре сначала создается «исполнитель команд», то есть процессор, а потом в него загружается последовательность команд, то на FPGA можно писать программу с командами, вшитыми в структуру прошивки. При этом отсутствует избыточность процессора, появляется малое потребление при той же скорости и функциональности, гарантированное время выполнения и высокая надежность. Пример такого автомата состояний:
5. Создание процессора внутри FPGA
Считается, что каждый программист должен написать хотя бы один компилятор, а каждый инженер должен разработать хотя бы один процессор. Это очень интересный и важный процесс, позволяющий лучше понять как работают микропроцессоры, при этом можно оптимизировать под свои задачи систему команд, встраивать большое количество одновременно работающих процессоров в одну микросхему и получать настоящую многозадачность с низким энергопотреблением. При этом структура процессора проста и легко реализуема на FPGA:
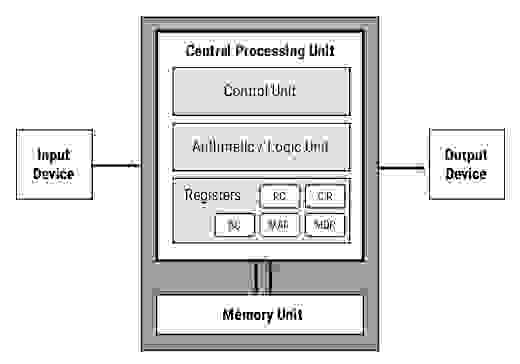
Недостатком такого процессора является отсутствие готовых компиляторов и отладчиков.
6. Использование готовых библиотек процессоров для FPGA
Библиотеки готовых процессоров есть у любого производителя FPGA (от 8086 до ARM), позволяют быстро создать процессор с определенным набором периферии и вставить его в проект FPGA. К процессору прилагается компилятор и отладчик. Быстро, удобно, но избыточно и потому ограничено по быстродействию. Пример структуры готовой библиотеки процессора:
7. Объединять процессор и периферию в одной микросхеме — SoC (System-On-Chip)
SoC — достаточно новая технология, решающая самую страшную проблему инженера, необходимость протаскивать по плате много высокоскоростных интерфейсов, которых всегда оказывается недостаточно, и которые необходимо программно поддерживать. Технология SoC позволяет в одной микросхеме иметь полноценный центральный процессор (поддерживающий операционную систему Linux, например) или микроконтроллер и большую FPGA, соединенные логическими сигналами, общей внутренней памятью и интерфейсами к внешней. То есть проблема эффективной, простой и быстрой передачи информации между FPGA и процессором успешно решена! Пример структуры SoC:
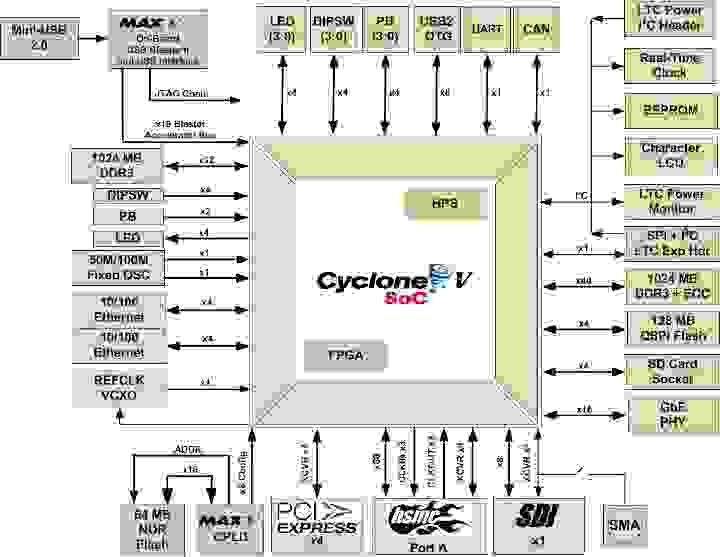
Видно, что FPGA и HPS (Host Processor System, процессор) находятся внутри одной микросхемы и окружены программируемыми ножками ввода-вывода. Действительно это многофункциональная система на кристалле.
8. Модные приложения типа crypto mining
Вспоминая, что FPGA — это набор логических ячеек и триггеров, работающих параллельно, на FPGA можно проводить много параллельных операций, что отличает от процессора, параллельность которого ограничена количеством ядер и потоков. Поэтому можно использовать FPGA как сопроцессор к центральному процессору, вынося на FPGA все самые требовательные к вычислительной мощности операции. Например, центральный процессор занимается логической обработкой задачи, а FPGA параллельно вычисляет контрольные суммы, хэши, ищет совпадения, перебирает варианты и так далее. Быстродействие FPGA ограничено только количеством параллельных блоков и временем выполнения одной операции. Отладив таким образом вычисления можно заказать ASIC, то есть заказную микросхему, выполняющую те же функции, но дешевле (при массовом производстве) и с меньшим энергопотреблением. И данная идея оказалась настолько перспективной и удобной, что гиганты разработки FPGA начали создавать специальное ПО, позволяющее интерактивно переносить части вычислений из программы на C/C++ в FPGA и контролировать быстродействие (HLS, High-Level Synthesis). Есть готовые платы с быстрыми интерфейсами для этого и средства отладки. Очень интересная и перспективная тема для использования.

9. Реализация нейронных сетей на FPGA
Нейронные сети и глубокие нейронные сети сейчас активно используются в разных областях, но реализация их на процессоре оказывается неэффективной — существует много вычислений, которые можно распараллелить (нейроны одного слоя, например, вычисляются независимо).
Поэтому перенеся нейронную сеть на FPGA удается на много порядков ускорить работу нейронной сети, остается обеспечить высокоскоростной интерфейс для загрузки исходных данных и получения результата. В качестве примера — реализация системы распознавания лиц на процессоре i7/9Gen распознает до 20 лиц за секунду с одной видеокамеры HD, реализация на FPGA — порядка 1000 лиц с нескольких камер. Структура используемой глубокой нейронной сети:



