Размышления о «туманных вычислениях»
Доброго времени суток.
На Хабре уже мелькала статья на данную тематику. Я хочу попробовать развить эту тему, и поделиться своими мыслями — как бы оно могло быть.
Итак, что же такое «туманные вычисления», или «fog computing». Это вычисления, основанные на распределенной инфраструктуре с негарантированной доступностью. Топологически — это ячеистая (mesh) сеть с динамической маршрутизацией, узлами которой являются сравнительно однородные по вычислительной мощности компьютеры.
В идеале, в эру «туманных вычислений» компьютеры-узлы находятся буквально повсюду — под ногами, в воздухе, на улице… Они настолько миниатюрны и дешевы, что их можно носить с собой килограммами. В наше время это скорее всего будет какая-то программная среда, консолидируюшая ресурсы множества виртуализованных «капель», и позволяющая на такой параллельной машине выполняться программам, написанным под кросс-платформенные среды — платформенная зависимость в таком окружении будет убийственна. Скорей всего, речь будет идти о Java, CLR, Python, JavaScript…
Что касается аппаратной базы — вряд ли это будут микроконтроллеры в чистом виде — ресурсы микроконтроллера сильно ограничены и малодостаточны для создания разделяемой среды. А ведь скорей всего, «капли» будут обслуживать параллельно несколько потребителей. Но сама концепция исполнения таких устройств близка к концепции микроконтроллера, или SoC. По моему разумению выглядеть чип такого устройства будет следующим образом: на одном кристалле размещаются многоядерный CPU, GPU, 3-4 Гб DRAM, и 32 Гб SSD плюс периферийная логика по минимуму. Наружу выходит минимум интерфейсов — SATA и SD для «программирования» (записи ОС на SSD), HDMI+VGA+USB в случае если система используется в качестве рабочего места, LightPeak или 10GE для межсистемных коммуникаций. Если это управляющий узел — то GPIO. Возможно — какой-то локальный радиоинтерфейс. В целом такая система стремится к дизайну Atom CE или Raspberry Pi — минималистичный энергоэффективный вычислительный комплекс. Безусловно, найдется место и для аккумулятора, и для беспроводного приемника электроэнергии.
Программная основа в первую очередь, вероятно, будет включать в себя гипервизор, способный консолидировать мощность «туманной сети» и представлять их как одну многопроцессорную систему. Такой подход в свое время уже использовался в ОС OpenMosix. Запрошенные потребителем (другой «каплей») ресурсы выделятся в виде виртуальной машины, в которой запускается, например, bare-metal Java-машина. В ней развертывается пакет приложения, приложение запускается, и так далее…
Особо стоит упомянуть о роли компьютеров-каплей в качестве «пользовательского терминала» — это единственный сценарий, когда к «капле» подключается какая-то периферия. Мне это видится, как некие устройства оболочки, наподобие SmartDocks от Motorola: оболочка-смартфон, оболочка-планшет, оболочка-ноутбук, оболочка-десктоп. Оболочка-ноутбук и оболочка-десктоп вполне могут вмещать в себя несколько модулей, и таким образом нести многоузловой частный кластер, «облачко тумана». А человек превращается в реальную PAN.
При таком подходе апгрейд системы превращается в простое подключение новых узлов. Если узлы-капли будут размером с MicroSD-карточку, будущим системным блоком вполне может оказаться трехлитровая банка с пластинами беспроводного питания по торцам, и тоненькой ниточкой оптики к огромному монитору.
В такой ситуации «три килограмма контрафактных серверов» уже не выглядят бредом.
Суммируя вышесказанное, можно отметить, что нам не видать «туманных ПК» и «туманных сетей» пока не будут выполнены следующие требования:
За кадром остались вопросы аутентификации, авторизации, и разделения ресурсов «капли» несколькими «туманными сетями».
Edge-ик в тумане и другие приключения периферийных вычислений
Меня зовут Игорь Хапов. Я руководитель разработки в Научно-техническом центре IBM. И сегодня я хотел бы вам помочь окунуться в мир периферийных вычислений, или edge computing, как его ещё называют. Я расскажу о том, что же такое edge computing и как он может повлиять на наш с вами мир. Также хотелось бы пояснить различия между edge computing и fog computing, какие преимущества даёт этот подход. В статье я также описал референсную архитектуру приложения на edge computing. И под конец немного расскажу о проекте с открытым исходным кодом Open Horizon, который совсем недавно присоединился к Linux Foundation.

Что же такое edge computing
Согласно определению Гартнера, edge computing — это подвид распределенных вычислений, в котором обработка информации происходит в непосредственной близости к месту, где данные были получены и будут потребляться. Это основное отличие edge computing от облачных вычислений, при которых информация собирается и обрабатывается в публичных или частных датацентрах. Основным отличием от локальных вычислений является то, что обычно edge computing — это часть большей системы, которая включает в себя сбор статистики, централизованное управление и удаленное обновление приложений на edge устройствах.
Что же такое edge устройство? Многие считают, что edge computing — это когда приложение работает на Raspberry Pi или других микрокомпьютерах. На самом деле edge computing может быть и на мобильных устройствах, персональных ноутбуках, умных камерах и других устройствах, на которых можно запустить приложение по обработке данных.
Edge computing и IoT
Довольно часто звучит вопрос — «Чем же отличается edge computing от IoT». IoT можно назвать дедушкой edge computing. IoT — это множество устройств, связанных между собой, и способных передавать информацию друг другу. А edge computing это скорее подход к организации вычислений и управлению edge устройствами. Как вы отлично понимаете, любое приложение необходимо обновлять, мониторить и осуществлять прочие обслуживающие функции. В результате edge computing подразумевает использование определенных подходов и фреймворков, о которых я расскажу чуть позже.
edge computing vs fog computing
Когда я однажды рассказал коллеге про edge computing, он ответил — ”так это же fog computing”. Давайте попробуем разобраться, в чём же разница. С одной стороны, edge computing и fog computing часто используются как синонимы, однако fog computing, или «туманные вычисления», все-таки немного отличаются.
И edge computing, и fog computing — это вычисления, которые находятся в непосредственной близости к получаемым данным. Различие заключается в том, что при туманных вычислениях обработка осуществляется на устройствах, которые постоянно подключены к сети. В edge computing вычисления осуществляются как на сенсорах, умных устройствах – без передачи на уровень gateway, так и на уровне gateway и на микрокластерах.
Для меня было открытием, что edge computing может работать в кластерах Kubernetes или OpenShift. Оказывается, что существует достаточно много задач, где кроме оконечных устройств необходимо выполнять обработку информации в локальном кластере и передавать в централизованные дата центры только результирующие данные. И такие вычисления — тоже edge computing.
Преимущества и недостатки edge computing
При выборе технологий для своего проекта я в первую очередь основываюсь на двух критериях — «Что я от этого получу?» и «Какие проблемы я от этого получу?».
Начнём с преимуществ:
Хотя, конечно, проектируя систему с edge computing, не стоит забывать, что как и любую другую технологию её стоит использовать в зависимости от требований к системе, которую вам необходимо реализовать.
Среди недостатков edge computing можно выделить следующие:
С одной стороны, последний пункт является наиболее критичным, но, к счастью, консорциум Linux Foundation Edge (LF EDGE) включает в себя всё больше и больше проектов с открытым исходным кодом, а их зрелость стремительно растет.
Принципы компании IBM при создании платформы edge computing
Компания IBM, являясь одним из лидеров в области гибридных облаков, использует определённые принципы при разработке решений для edge computing:
IBM применяет эти принципы при декомпозиции задачи построения фреймворка edge computing.

Как вы можете видеть, всё решение разбито на 4 сегмента использования:
Помимо основных принципов и подходов, IBM разработала референсную архитектуру для решений, основанных на edge computing. Референсная архитектура — это шаблон, показывающий основные элементы системы и детализированный настолько, чтобы иметь возможность адаптировать его под конкретное решение для заказчика. Давайте рассмотрим такую архитектуру более подробно.
Референсная архитектура edge computing
Edge devices
В первую очередь, у нас есть какое-либо встроенное или дискретное edge-устройство, к которому подключены сенсоры, датчики или управляющие механизмы, например, для координации движения роборуки. Из сервисов/данных на таком устройстве могут находиться:
Hybrid multicloud
Если мы говорим об использовании ML-модели, которая будет запускаться на десятках или тысячах устройств, то нам необходимо облако, которое сможет отвечать за обучение такой модели, обработку статистики, отображение сводной информации (правая часть архитектуры).
Edge server and Edge micro data center
Как мы уже говорили, можно встретить промежуточные (близкие) кластеры обработки данных на уровне шлюзов или микро-датацентров с установленной поддержкой кластерных технологий.
Edge framework
Когда мы осознаем, что есть необходимость в управлении большим количеством сервисов на тысячах устройств и сотнями приложений в разных кластерах, наступает понимание, что надо бы использовать какой-то фреймворк для управления всем этим зоопарком и синхронизации между устройствами.
Именно наличие данного фреймворка раскрывает преимущества edge computing перед разнородными разнесёнными вычислениями.
Как мы видим, кроме центральной части по управлению сервисами и моделями в данном фреймворке присутствуют агенты, обеспечивающие контроль за управлением жизненным циклом сервисов на устройствах/кластерах на каждом из уровней использования.
Open Horizon и IBM Edge Application Manager
Именно для решения задач в области edge computing IBM разработала и выложила в open-source проект Open Horizon. Если вы помните, один из принципов, которые IBM заложила в edge computing – все компоненты должны быть основаны на open source технологиях. В мае 2020 года проект Open Horizon вошел в Linux Foundation Edge — Международный фонд open-source технологий для созданий edge-решений. Также Open Horizon является ядром нового продукта от RedHat и IBM — IBM Edge Application Manager, решения для управления приложениями на всех устройствах edge computing: от Raspberry Pi до промежуточных кластеров обработки данных.
Несмотря на то, что проект Open Horizon вошел в консорциум только в мае, он уже достаточно давно развивается как open-source проект. И мы в Научно-техническом центре IBM не только успели его попробовать, но и довести свое решение до промышленного использования. О том, как мы разрабатывали проект с использованием edge computing, и что у нас получилось — будет отдельная статья, которая выйдет в ближайшие несколько недель.
Сценарии использования
С одной стороны, edge computing framework — это специализированное решение для определённого круга задач, но оно нашло применение во многих индустриях.
В своё время, когда я изучал работу московских камер “Стрелка”, я понял, что это в чистом виде edge computing, с вычислениями «прямо на столбе» и промежуточной обработкой данных в раздельных вычислительных кластерах у различных ведомств.
Сценарии нашлись в финансовом секторе, в продажах при самообслуживании, в медицине и секторе страхования, торговле и конечно при производстве. Именно в создании решения для автоматизации и оценки качества произведённого оборудования, основанного на edge computing, мне с коллегами из Научно-технического центра IBM и посчастливилось принять участие. И на своем опыте попробовать, как создаются решения edge computing.
Если Вас заинтересовала данная тематика, следите за обновлениями в хабраблоге компании IBM и смотрите видео в разделе Ссылки. Наши зарубежные коллеги к настоящему моменту уже осветили многие технические вопросы и описали, какие сценарии уже работают и применяются в различных отраслях.
Туманные вычисления
Fog computing
Что такое туманные вычисления
и почему без них не построить никакого интернета вещей
Туманные вычисления призваны расширить облачные функции хранения, вычисления и сетевого взаимодействия. Концепция предполагает обработку данных на конечных устройствах сети (компьютерах, мобильных устройствах, датчиках, смарт-узлах и т.п.), а не в облаке, решая таким образом основные проблемы, возникающие при организации интернета вещей.
Содержание
Концепция
Развитие интернета вещей (IoT, Internet of Things) потребовало поддержки мобильности устройств IoT для различных местоположений с геолокацией и с небольшой задержкой на обработку данных. Поэтому была предложена новая платформа для удовлетворения таких требований, которая и получила название Fog computing – «туманные вычисления». Её основной особенностью является обработка данных в непосредственной близости от источников их получения, без необходимости их передачи в крупные дата-центры только для того, чтобы их там обработать и передать назад результаты.
Таким образом, становится ясным происхождение термина «туманные вычисления»: когда густое облако опускается до поверхности земли (на границу сети), мы видим туман.
Стандартизация
В 2015 году с целью выработки единых подходов к реализации Fog компаниями ARM, Cisco, Dell, Intel, Microsoft, а также Принстонским Университетом (Princeton University), в США был создан консорциум OpenFog Consortium. В дальнейшем, в консорциум OpenFog вошло много других компаний (General Electric, Hitachi, ZTE и др), а также университетов, например, ShanghaiTech University. К 2018 году в OpenFog выходят более 50 членов. Консорциум OpenFog разрабатывает стандартную архитектуру OpenFog RA [1] (OpenFog Reference Architecture).
Реализация и архитектура
Fog не является альтернативой для Cloud. Напротив, Fog плодотворно взаимодействует с Cloud, особенно в администрировании и аналитике данных, и такое взаимодействие порождает новый класс приложений.
Архитектура Fog Computing представляет собой некую «прослойку» на границе между облаком и устройствами интернета вещей с сенсорами, а также мобильными устройствами пользователей.

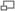
Основные архитектурные отличия Fog от Cloud:
В архитектуре Fog сетевые узлы (Fog Sites), расположенные ближе к облачным дата-центрам, обладают большей вычислительной мощностью и бóльшим объемом данных в системах хранения. Сетевые узлы, расположенные ближе к сенсорам интернета вещей и мобильным устройствам, обладают большей интерактивностью и быстрым откликом. Отличительной особенностью Fog является то, что в качестве сетевого узла могут выступать устройства пользователя, такие как персональные компьютеры, домашние шлюзы, телеприставки и мобильные устройства. Чтобы устройство пользователя могло работать как узел сети Fog, пользователь должен дать оператору связи соответствующее разрешение на использование вычислительной мощности своего гаджета в фоновом режиме, в обмен на различные льготы со стороны оператора.
Типовое применение Fog Computing



Некоторые сценарии использования

Автономные системы управления транспортом (ADS, Autonomous Driving System)

Fog-системы в электронном здравоохранении (eHealth)
Fog-проекты облачных провайдеров
Безсерверная архитектура позволяет выполнять исходный код тысяч и миллионов пользователей (в частности, fog-устройств) внутри вычислительной среды, не заботясь о масштабировании ресурсов.
Компания Microsoft анонсировала поддержку функций Azure (Azure Functions) внутри платформы разработки SDK (Software Development Kit). Функции Azure вначале были введены в семейства облачных продуктов с безсерверной архитектурой (Serverless Architecture), разработанных в Microsoft.
Компания Amazon разработала платформу Greengrass с поддержкой т.н. Lambda-функций (безсерверной архитектуры) в устройствах IoT при взаимодействии с облачной платформой AWS. Greengrass — это контейнер исполнения программного модуля, который может быть запущен непосредственно на Fog-устройстве, а не на сервере в дата-центре. Устройства с Greengrass могут обмениваться информацией между собой вне зависимости от наличия внешнего интернета, т.е. горизонтально между Fog-устройствами при помощи различных радио-протоколов интернета вещей.
Google представил платформу для интернета вещей Android Things с поддержкой микрокомпьютеров Intel Edison и Joule 570x, NXP Pico i.MX6UL и Argon i.MX6UL, а также Raspberry Pi 3. Fog-приложения разрабатываются на платформе Android Studio для любого из этих устройств. Android Things также обеспечивает интеграцию с Google Play и всей экосистемой Android, на которой сейчас работают 90% смартфонов в мире. Таким образом, система Android Things даёт возможность любому Android-смартфону или планшету работать в качестве Fog-узла.
Эти проекты показывают тенденцию «коммодитизации» устройств IoT, то есть проектирование и создание их на базе общедоступных элементов Fog Computing.
В России технологии IoT и Fog Computing используются, например, в решениях «интеллектуальный карьер» российской компании «ВИСТ Майнинг Технолоджи» (слово «майнинг» в названии российской компании используется в своём исходном значении – добыча полезных ископаемых).

Преимущества и прогнозы
Преимуществом туманных вычислений является снижение объема данных, передаваемых в облако, что уменьшает требования к пропускной способности сети, увеличивает скорость обработки данных и снижает задержки в принятии решений. Туманные вычисления решают ряд самых распространенных проблем, среди которых:
Самый большой потенциал развития технологии Fog computing имеют в следующих отраслях: энергетика, коммунальные службы, и транспорт, сельское хозяйство, торговля, а также здравоохранение и промышленное производство.
Развитие в России
2016: Кремль поручил подготовить инфраструктуру туманных вычислений
1 июля 2016 года стало известно о том, что Кремль поручил Минкомсвязи, Минпромторгу, а также другим ведомствам подготовить инфраструктуру туманных вычислений.
По данным «Коммерсанта», администрация президента направила в Минкомсвязи, Минпромторг, «Ростелеком» и Агентство стратегических инициатив (АСИ) письмо с подписью президента Владимира Путина на тему развития туманных вычислений в России.



Другой источник в одном из профильных министерств в разговоре с газетой уточнил, что результаты выполнения поручения нужно представить в октябре 2016 года. Отмечается, что инициатива по работе в данной сфере исходит от «Ростелекома» и АСИ, чью идею поддержали в администрации президента.
«Коммерсантъ» сообщает, что Минпромторг обратился к нескольким российским технологическим компаниям с просьбой предоставить экспертизу проекта. В частности, соответствующую просьбу министерство направило компании «Т-Платформы», которая занимается разработкой вычислительной техники. [9]
Fog computing

Если вам кажется, что на картинке ничего не видно, то я отвечу, на картинке отчетливейшим образом изображен туман! 😉 В связи с выходом из вынужденного захабренного молчания публикую свой небольшой футурологический очерк.
Ура! То, о чем так давно боялись спросить большевики, случилось! В след за облачными вычислениями сегодня мы открываем эпоху туманных (fog) вычислений!
Туманные вычисления — и звучит как-то туманно. Попробую в двух словах донести эту парадигму до читателя, невооруженного википедией и гуглом. Для вооруженных же придется сказать, что сие словосочетание уже было испохаблено одним из видов облачных вычислений, которые принципиально ни чем от них не отличаются.
Итак, туманные вычисления. Как нетрудно догадаться, «туман» — это, как и «облако» некоторая связанная распределенная вычислительная мощность. Применим дифференциальный подход к облаку и положим, что вместо одного дискретного узла облака (да, в настоящих облаках нет узлов и в этом кроется вся фальшивость этого термина) в составе: процессор, ОЗУ, ПЗУ, устройства ввода/вывода мы имеем скалярное поле (распределение в объеме плотности) вычислительной мощности, оперативной и постоянной памяти, а также векторное поле потоков данных.
В этой точке можно выдохнуть и дальше попробую без этих заморочек. Компьютеры становятся меньше. Компьютеры становятся дешевле. Сейчас МП3 плейер имеет вычислительную мощность на порядки больше, чем первый компьютер, созданный для решения сверх ответственных военных и научных задач. Про размер и самое главное — потребление энергии я молчу. Сейчас плотность вычислительных устройств настолько высока, что впору применять к ней статистические методы. Когда-то видел отличную статью, где приводилась суммарная выч. мощность устройств в разрезе выч. мощности одного устройства и оказалось, что вся сила не в суперкомпьютерах, а в дешевых мобильных телефонах.
Вместе с удешевлением компьютеров подешевели и системы связи. Блютус есть почти везде и я не уверен, что в моих кроссовках его нет. И вот именно сейчас не осталось преград для того, чтоб все эти маленькие слабенькие вычислительные машинки объединились в один большой сиреневый вычислительный туман.
В основе «тумана» лежит «капля» — чип микроконтроллера с памятью и интерфейсом для передачи данных на борту, и чип беспроводной связи типа Mesh (сенсорная сеть). Питание «капля» получает от маленькой батарейки, которой тем не менее хватит на пару лет работы с регулярными перерывами на сон (picoPower от Atmel рулит). К «капле» могут быть подключены устройства ввода (датчики всех мастей, от температуры и напряжения до положения в пространстве и уровня ультрафиолетового излучения) и вывода (светодиоды, жк и лед индикторы, сухие контакты и т.п.) Уже попахивает Скайнетом, не правда ли?
«И вот когда мы в двух шагах от груды сказочных богатств. » — как пел герой известного мультмюзикла, остается самое интересное — в этой сети может хранится и обрабатываться информация, непосредственно не связанная с этими самыми датчиками. Очевидно, что для большинства задач производительности современных микроконтроллеров более чем достаточно и мы получаем поле избыточной вычислительной мощности. А денег, патронов и вычислительной мощности, как известно, лишних никогда не бывает.
Для обеспечения более производительной передачи данных, в тумане будут создаваться дополнительные туннели — некоторые «капли» могут иметь высокоскоростные интерфейсы и обеспечивать лучшую связность тумана. Не пройдет и 10 лет как вычислительный туман охватит весь ареал обитания человека разумного и из коммерческих частных облаков вычисления уйдут в туман, который не имеет собственника. Программы будут паразитировать на вычислительном тумане и конкурировать между собой. Это будет экосистема, на порядок более живая, чем Интернет.
Вот такая вот у нас получается штука. Поживем увидим, был ли прав С.Лем в своем «Футурологическом конгрессе» и я в вычислительном тумане?



