Автоматическая документация для Flask с использованием OpenAPI

Техническая документация, как известно, крайне важная часть любого проекта. До недавнего времени мы прекрасно жили с таким генератором документаций как Sphinx. Но наступил момент переходить на технологии с бОльшим набором возможностей, поэтому мы приняли решение переписать нашу документацию на более современный стандарт: OpenAPI Specification. Эта статья является скромным гайдом по такому переезду. Она будет интересна Python-разработчикам, особенно тем, которые используют Flask. После ее прочтения вы узнаете, как создать статическую OpenAPI документацию для Flask приложения и развернуть ее в GitLab Pages.
apispec + marshmallow
В качестве веб-фреймворка у нас используется Flask. Документацию для API, созданного с помощью него, мы и хотим создать. Спецификация по стандарту OpenAPI описывается форматом YAML(или JSON). Чтобы преобразовать докстринги нашего API в необходимый формат, будем использовать такой инструмент, как apispec, и его плагины. Например, MarshmallowPlugin, с помощью которого (и самой библиотеки marshmallow) можно удобно — за счет возможности наследования и переиспользования — описать входные и выходные данные эндпоинтов в виде python классов, а также провалидировать их.
Используя библиотеку marshmallow, создадим класс, описывающий параметры API:
Аналогично сделаем для выходных параметров:
Для группировки запросов в OpenAPI используются теги. Создадим тег и добавим его в объект APISpec:
Далее нам нужно интегрировать параметры в докстринг так, чтобы это соответствовало OpenAPI спецификации.
Эта функция — пример реализации метода GET в нашем API.
Блок summary. Краткое описание функции. Для более подробного описания можно добавить блок description.
Блок parameters. Описание параметров запроса. У параметра указывается, откуда он берется:
Блок responses. Описание вариантов ответа команды и их структура.
Блок tags. Описание тегов, которые используются для логической группировки эндпоинтов.
Для POST запроса, например, можно указать еще requestBody, в котором описываются параметры, передаваемые в теле. Подробнее можно почитать в официальной документации.
После того, как мы описали методы API, можем загрузить их описание в объект APISpec:
Создаем метод get_apispec, который будет возвращать объект APISpec, в нем добавляем общую информацию о проекте и вызываем описанные ранее методы load_docstrings и create_tags:
Swagger UI
Swagger UI позволяет создать интерактивную страницу с документацией.
Создадим эндпоинт, который будет возвращать спецификацию в json формате, и вызываем в нем get_apispec:
Теперь, когда мы получили json спецификацию, нам нужно сформировать из неё html документ. Для этого воспользуемся пакетом flask_swagger_ui, с помощью которого можно встроить интерактивную страницу с документацией на базе Swagger UI в наше Flask приложение:
Таким образом, мы сделали эндпоинт /docs, при обращении по которому получаем документацию следующего вида:
GitLab Pages + ReDoc
Если мы не хотим формировать документацию во время обращения по эндпоинту, то можно собрать статичный документ.
Использование GitLab позволяет сгенерировать такую статическую страницу с документацией в CI/CD процессах.
Таким образом, мы один раз соберем документацию, и при обращении по заданному адресу она будет просто отображаться без какой-либо дополнительной обработки.
Для этого сохраним APISpec в YAML файл:
Теперь, когда мы получили YAML файл по спецификации OpenAPI, нужно сформировать HTML документ. Для этого будем использовать ReDoc, так как он позволяет сгенерировать документ в gitlab-ci с красивой и удобной структурой. Публиковать его будем с помощью GitLab Pages.
Добавим следующие строки в файл gitlab-ci.yml:
Стоит отметить, что index.html нужно сохранять в папку public, так как она зарезервирована GitLab’ом.
Теперь, если мы запушим изменения в репозиторий, по адресу namespace.gitlab.com/project появится документация:
Также путь до документации можно посмотреть в Settings/Pages
Пример документации с использованием ReDoc: ivi-ru.github.io/hydra
Заключение
Таким образом, мы научились собирать OpenAPI документацию с использованием ReDoc и хостить ее на GitLab Pages. В эту статью не попало еще несколько возможностей этих инструментов, например, валидация параметров с помощью marshmallow. Но основной ее целью было показать непосредственно процесс создания документации.
Flask-Marshmallow: Flask + marshmallow for beautiful APIs¶
Flask + marshmallow for beautiful APIs¶
Flask-Marshmallow is a thin integration layer for Flask (a Python web framework) and marshmallow (an object serialization/deserialization library) that adds additional features to marshmallow, including URL and Hyperlinks fields for HATEOAS-ready APIs. It also (optionally) integrates with Flask-SQLAlchemy.
Get it now¶
Define your output format with marshmallow.
Output the data in your views.
Optional Flask-SQLAlchemy Integration¶
Flask-Marshmallow includes useful extras for integrating with Flask-SQLAlchemy and marshmallow-sqlalchemy.
To enable SQLAlchemy integration, make sure that both Flask-SQLAlchemy and marshmallow-sqlalchemy are installed.
Next, initialize the SQLAlchemy and Marshmallow extensions, in that order.
Note on initialization order
Flask-SQLAlchemy must be initialized before Flask-Marshmallow.
Declare your models like normal.
You can now use your schema to dump and load your ORM objects.
SQLAlchemySchema is nearly identical in API to marshmallow_sqlalchemy.SQLAlchemySchema with the following exceptions:
By default, SQLAlchemySchema uses the scoped session created by Flask-SQLAlchemy.
Note: By default, Flask’s jsonify method sorts the list of keys and returns consistent results to ensure that external HTTP caches aren’t trashed. As a side effect, this will override ordered=True in the SQLAlchemySchema’s class Meta (if you set it). To disable this, set JSON_SORT_KEYS=False in your Flask app config. In production it’s recommended to let jsonify sort the keys and not set ordered=True in your SQLAlchemySchema in order to minimize generation time and maximize cacheability of the results.
You can also use ma.HyperlinkRelated fields if you want relationships to be represented by hyperlinks rather than primary keys.
The first argument to the HyperlinkRelated constructor is the name of the view used to generate the URL, just as you would pass it to the url_for function. If your models and views use the id attribute as a primary key, you’re done; otherwise, you must specify the name of the attribute used as the primary key.
To represent a one-to-many relationship, wrap the HyperlinkRelated instance in a marshmallow.fields.List field, like this:
flask_marshmallow¶
Integrates the marshmallow serialization/deserialization library with your Flask application.
class flask_marshmallow. Marshmallow ( app = None ) В¶
Wrapper class that integrates Marshmallow with a Flask application.
To use it, instantiate with an application:
You can declare schema like so:
app (Flask) – The Flask application object.
Initializes the application with the extension.
app (Flask) – The Flask application object.
Base serializer with which to define custom serializers.
See marshmallow.Schema for more details about the Schema API.
Return a JSON response containing the serialized data.
obj – Object to serialize.
many (bool) – Whether obj should be serialized as an instance or as a collection. If unset, defaults to the value of the many attribute on this Schema.
Deprecated since version 3.7.0: marshmallow.pprint will be removed in marshmallow 4.
flask_marshmallow.fields¶
Custom, Flask-specific fields.
See the marshmallow.fields module for the list of all fields available from the marshmallow library.
Field that outputs the absolute URL for an endpoint.
Field that outputs a dictionary of hyperlinks, given a dictionary schema with URLFor objects as values.
URLFor objects can be nested within the dictionary.
schema (dict) – A dict that maps names to URLFor fields.
Field that outputs the URL for an endpoint. Acts identically to Flask’s url_for function, except that arguments can be pulled from the object to be serialized, and **values should be passed to the values parameter.
endpoint (str) – Flask endpoint name.
values (dict) – Same keyword arguments as Flask’s url_for, except string arguments enclosed in > will be interpreted as attributes to pull from the object.
kwargs – keyword arguments to pass to marshmallow field (e.g. required ).
flask_marshmallow.sqla¶
Integration with Flask-SQLAlchemy and marshmallow-sqlalchemy. Provides SQLAlchemySchema and SQLAlchemyAutoSchema classes that use the scoped session from Flask-SQLAlchemy.
class flask_marshmallow.sqla. DummySession В¶
Placeholder session object.
Field that generates hyperlinks to indicate references between models, rather than primary keys.
endpoint (str) – Flask endpoint name for generated hyperlink.
url_key (str) – The attribute containing the reference’s primary key. Defaults to “id”.
external (bool) – Set to True if absolute URLs should be used, instead of relative URLs.
SQLAlchemyAutoSchema that automatically generates marshmallow fields from a SQLAlchemy model’s or table’s column. Uses the scoped session from Flask-SQLAlchemy by default.
Мега-Учебник Flask Глава 1: Привет, мир! ( издание 2018 )
Miguel Grinberg
Эта статья является переводом нового издания учебника Мигеля Гринберга. Прежний перевод давно утратил свою актуальность.
Автор планирует завершить его выпуск в мае 2018. Я, со своей стороны, постараюсь не отставать с переводом.
Для справки ниже приведен список статей этой серии.
Новый учебник написан в 2017 году, и, наконец, он выглядит так, как если бы он был настроен на версию Python 3. Решены проблемы с совместимостью, изменен фокус в сторону Python 3, а не Python 2 как было в 2012 году в прежней версии учебника.
К сожалению, Python 2 или 3 — это не единственное, что изменилось. Есть также несколько технологий, которые имели смысл в 2012 году, но теперь устарели. К ним относятся:
Многие вещи, которые изменились за эти пять лет, в основном означают, что нужно пересмотреть все главы, причем большинство из них претерпели довольно важные изменения.
Кроме того, у Мигеля есть еще пять лет опыта работы в качестве технического блоггера, так как продолжал создавать контент для своего блога на протяжении всех этих лет. Весь этот опыт будет отражен в обновлениях, которые он приводит в учебнике.
Более подробно читайте в блоге Мигеля
Вы собираетесь отправиться в путешествие, чтобы узнать, как создавать веб-приложения с помощью Python и микрофреймворка Flask. Видео выше даст вам обзор содержимого этого руководства. В этой первой главе вы узнаете, как настроить проект Flask. В конце этой главы у вас будет простое веб-приложение Flask, работающее на вашем компьютере!
Примечание 1: Если вы ищете старые версии данного курса, это здесь.
Примечание 2: Если вдруг Вы хотели бы выступить в поддержку моей(Мигеля) работы в этом блоге, я (Мигель Гринберг) предлагаю полную версию данного руководства упакованную электронную книгу или видео. Для получения более подробной информации посетите learn.miguelgrinberg.com.
Все примеры кода представленные в этом учебном курсе, размещены на GitHub. Загрузка кода из GitHub поможет вам сэкономить время, но я настоятельно рекомендую набирать код самостоятельно, по крайней мере, первые несколько глав. После того, как вы станете ближе знакомы с Flask можно получить доступ к коду прямо из GitHub, только в том случае, если ввод становится слишком утомительным.
В начале каждой главы, я дам вам три GitHub ссылки, которые могут быть полезны при изучении главы. Browse откроет GitHub репозиторий для микроблога в том месте, где собраны изменения к главе, которую Вы читаете, за исключением любых изменений, внесенных в будущих главах. Zip — это ссылка для загрузки zip-архива, в том числе приложения и изменений в главе. Diff — откроет графическое представление всех изменений, внесенных в главу, которую Вы собираетесь читать.
На GitHub ссылки в этой главе: Browse, Zip, Diff.
Установка Python
Если на вашем компьютере не установлен Python, установите его. Если ваша операционная система не имеет предустановленный пакет Python, вы можете скачать программу установки с официального сайта Python. Если вы используете Microsoft Windows вместе с WSL или Cygwin, обратите внимание, что вы не будете использовать родную версию Python для Windows, а версию, совместимую с Unix, которую вам нужно получить от Ubuntu (если вы используете WSL) или от Cygwin.
Чтобы убедиться, что ваша установка Python является функциональной, вы можете открыть окно терминала и ввести python3, или если это не работает, просто python. Вот что вам следует ожидать:
или так в cmd (окно командной строки Microsoft Windows) :
Интерпретатор Python теперь находится в ожидании пользовательского ввода. В будущих главах вы узнаете, для чего это интерактивное приглашение полезно. Но пока Вы подтвердили, что Python установлен в вашей системе. Чтобы выйти из интерактивного приглашения, вы можете ввести exit() и нажать Enter.
Установка Flask
Следующий шаг — установить Flask, но прежде чем я расскажу об этом, я хочу рассказать вам о лучших методах, связанных с установкой пакетов Python.
В Python пакеты, такие как Flask, доступны в общем репозитории, откуда их можно загрузить и установить. Официальный репозиторий пакетов Python называется PyPI, что означает Python Package Index (также известный, как «cheese shop»). Установка пакета из PyPI очень проста, потому что у Python есть инструмент под названием pip, который выполняет эту работу (в Python 2.7 pip не входит в комплект с Python и его нужно устанавливать отдельно).
Чтобы установить пакет на свой компьютер, вы используете pip следующим образом:
Интересно, что этот метод установки пакетов не будет работать в большинстве случаев. Если ваш интерпретатор Python был установлен глобально для всех пользователей вашего компьютера, велика вероятность того, что ваша обычная учетная запись пользователя не получит разрешения на внесение в нее изменений, поэтому единственный способ выполнить вышеприведенную команду — запустить ее от имени администратора. Но даже без этого осложнения поймите, что происходит, когда вы устанавливаете пакет, как указанным выше способом. Инструмент pip загрузит пакет из PyPI, а затем добавит его в вашу папку Python. С этого момента каждый скрипт Python, который у вас есть в вашей системе, будет иметь доступ к этому пакету. Представьте ситуацию, когда вы закончили веб-приложение с использованием версии 0.11 Flask, которая была самой последней версией Flask при запуске, но теперь она была заменена версией 0.12. Теперь вы хотите запустить второе приложение, для которого вы хотели бы использовать версию 0.12, но если вы замените установленную версию 0.11, вы рискуете сломать свое старое приложение. Вы видите проблему? Было бы идеально, если бы можно было установить Flask 0.11, который будет использоваться вашим старым приложением, а также установить Flask 0.12 для Вашего нового.
Чтобы решить проблему поддержки различных версий пакетов для разных приложений, Python использует концепцию виртуальных сред. Виртуальная среда — это полная копия интерпретатора Python. Когда вы устанавливаете пакеты в виртуальной среде, общесистемный интерпретатор Python не затрагивается, только копия. Таким образом, решение иметь полную свободу для установки любых версий ваших пакетов для каждого приложения — использовать другую виртуальную среду для каждого приложения. Виртуальные среды имеют дополнительное преимущество, они принадлежат пользователю, который их создает, поэтому им не требуется учетная запись администратора.
Начнем с создания каталога, в котором будет жить проект. Я собираюсь назвать этот каталог microblog, так как это имя приложения:
Если вы используете версию Python 3, в нее включена поддержка виртуальной среды, поэтому все, что вам нужно сделать для ее создания, это:
Обратите внимание, что в некоторых операционных системах вам может понадобиться использовать python вместо python3 в приведенной выше команде. Некоторые установки используют python для релизов Python 2.x и python3 для релизов 3.x, в то время как другие отображают python в выпусках 3.x.
Если вы используете любую версию Python старше 3.4 (включая выпуск 2.7), виртуальные среды не поддерживаются изначально. Для этих версий Python вам необходимо загрузить и установить сторонний инструмент virtualenv, прежде чем создавать виртуальные среды. После того, как virtualenv установлен, вы можете создать виртуальную среду со следующей командой:
Прим.переводчика: У меня установлено несколько версий Python. Я использую Python3.3. В моем случае пришлось вводить строку так:
В полученном сообщении видно, что установлен pip и ряд пакетов:
Независимо от метода, который вы использовали для его создания, вы создали свою виртуальную среду. Теперь вам нужно сообщить системе, что вы хотите ее использовать, активируя ее. Чтобы активировать новую виртуальную среду, используете следующую команду:
Если вы используете cmd (окно командной строки Microsoft Windows), команда активации немного отличается:
Теперь, когда вы создали и активировали виртуальную среду, вы можете, наконец, установить в нее Flask:
Если вы хотите проверить, что в вашей виртуальной среде установлен Flask, вы можете запустить интерпретатор Python и импортировать Flask в него:
Если этот импорт не дает вам никаких ошибок, вы можете поздравить себя, так как Flask установлен и готов к использованию.
Flask приложение «Привет, мир»
Если вы зайдете на сайт Flask, вас приветствует очень простое примерное приложение с пятью строками кода. Вместо того, чтобы повторять этот тривиальный пример, я покажу вам немного более сложный, который даст вам хорошую базовую структуру для написания больших приложений.
Приложение будет существовать в виде пакета.
Прим.переводчика: Пакет — это коллекция модулей.
__init__.py для пакета приложения будет содержать следующий код:
Другая особенность заключается в том, что модуль routes импортируется внизу, а не наверху скрипта, как это всегда делается. Нижний импорт является обходным путем для циклического импорта, что является общей проблемой при использовании приложений Flask. Вы увидите, что модуль routes должен импортировать переменную приложения, определенную в этом скрипте, поэтому, поместив один из взаимных импортов внизу, вы избежите ошибки, которая возникает из взаимных ссылок между этими двумя файлами.
Вот ваша первая функция просмотра, которую вам нужно написать в новом модуле с именем app/routes.py :
Эта функция просмотра на самом деле довольно проста, она просто возвращает приветствие в виде строки. Две странные строки @app.route над функцией — декораторы, уникальная особенность языка Python. Декоратор изменяет функцию, которая следует за ней. Общий шаблон с декораторами — использовать их для регистрации функций как обратных вызовов для определенных событий. В этом случае декоратор @app.route создает связь между URL-адресом, заданным как аргумент, и функцией. В этом примере есть два декоратора, которые связывают URL-адреса / и /index с этой функцией. Это означает, что когда веб-браузер запрашивает один из этих двух URL-адресов, Flask будет вызывать эту функцию и передавать возвращаемое значение обратно в браузер в качестве ответа. Если вам кажется, что это еще не имеет смысла, это будет недолго, пока вы запустите это приложение.
Чтобы завершить приложение, вам нужно создать сценарий Python на верхнем уровне, определяющий экземпляр приложения Flask. Давайте назовем этот скрипт microblog.py и определим его как одну строку, которая импортирует экземпляр приложения:
Чтобы убедиться, что вы все делаете правильно, ниже приведена диаграмма структуры проекта:
Верьте или нет, но первая версия приложения завершена! Прежде чем запускать его, Flask нужно сообщить, как его импортировать, установив переменную среды FLASK_APP :
Если вы используете Microsoft Windows, используйте команду ‘set’ вместо ‘export’ в команде выше.
Готовы ли вы быть потрясены? Вы можете запустить свое первое веб-приложение со следующей командой:
Прим.переводчика: Я был потрясен поскольку получил ошибку кодировки. Если у вас версия Python старше 3.6 вас скорее всего ждет сюрприз. Типа:
В моем случае виноваты кириллические символы ПК в имени компьютера. Заменил на PK и все заработало. Виноват модуль socket
Действительно все заработало:
Что бы написать по русски «Привет, Мир!» потребуется скорректировать
модуль routes.py
Когда вы закончите играть с сервером, вы можете просто нажать Ctrl-C, чтобы остановить его.
Поздравляем, вы совершили первый большой шаг, чтобы стать веб-разработчиком!
API REST на Python с Flask, Connexion и SQLAlchemy — урок 2
Содержание
Как отмечалось в комментариях первого урока, структура People переинициализируется каждый раз при перезапуске приложения. В этом уроке вы узнаете, как сохранить структуру People в базе данных и действия, которые предоставляет API, используя SQLAlchemy и Marshmallow.
SQLAlchemy એ предоставляет объектно-реляционную модель (ORM એ ), которая хранит объекты Python для представления данных объекта в базе данных. Это может помочь вам продолжать мыслить в стиле Python и не беспокоиться о том, как данные объекта будут представлены в базе данных.
Marshmallow обеспечивает функциональность для сериализации и десериализации объектов Python по мере их поступления в наш REST API на основе JSON. Marshmallow преобразует экземпляры класса Python в объекты, которые можно преобразовать в JSON.
Мы можете найти код Python для этой статьи здесь.
Для кого этот урок
Если вам понравился первый урок нашего мини‑курса, то здесь вы ещё больше расширите свой арсенал инструментов. Вы будете использовать SQLAlchemy એ для доступа к базе данных, что более соответствует стилю Python, чем прямой SQL. Кроме того, мы будем использовать Marshmallow для сериализации и десериализации данных, управляемых REST API. Для этого мы будем использовать основные функции объектно-ориентированного программирования, доступные в Python.
веб‑приложение, представленное в первом уроке, будет иметь небольшие изменения в файлах HTML и JavaScript для поддержки изменений. Вы можете ознакомиться с окончательной версией кода первого урока здесь.
Дополнительные пакеты
Прежде чем приступить к созданию этой новой функциональности, вам необходимо обновить virtualenv. Мы создали его для выполнения кода первого урока или для создания нового кода для этого проекта. Самый простой способ сделать это после активации virtualenv — выполнить эту команду:
Это добавляет дополнительную функциональность в нашу виртуальну среду virtualenv:
Данные People
Как уже упоминалось выше, структура данных People в предыдущем уроке является словарем Python. В этом словаре мы использовали фамилию человека в качестве ключа поиска. Структура данных выглядела примерно так:
Так как фамилия есть ключ словаря, то ограничивается её изменение — изменить можно только имя. В нашем случае перенос в базу данных позволит изменять не только имя, но и фамилию, поскольку она больше не будет использоваться в качестве ключа для поиска человека.
Концептуально, таблицу базы данных можно рассматривать как двумерный массив, в котором строки являются записями, а столбцы — полями в этих записях.
Таблицы базы данных, обычно, в качестве ключа поиска записей имеют автоинкрементное целочисленное значение. Такое поле называется первичным ключом. Каждая запись в таблице будет иметь первичный ключ, значение которого уникально во всей таблице. Наличие первичного ключа, независимого от данных, хранящихся в таблице, освобождает вас беспокойсва об уникалности значения в любом другом поле записей.
Примечание:
Автоинкрементный первичный ключ означает, что база данных берет на себя заботу:
Согласно теории, сопоставим приведенную выше структуру People единственной в нашей базе данных таблице person :
Описание столбцов таблицы:
Взаимодействие с базой данных
Мы будем использовать SQLite એ в качестве СУБД એ (Системы управления базами данных) для хранения People. SQLite встроена в дистрибутив Python по умолчанию и в мире получила широкое распространение. SQLite использует планарные файлы, что обесечивает высокую скорость обработки, и язык запросов SQL, что подходит для очень многих проектов.
В отличие от алгоритмического программирования, такого как на Python, язык запросов SQL એ не определяет, как получить данные — он определяет какие нужны данные, оставляя «как» по капотом ядра СУБД.
Получение данных таким способом не очень Python‑ническое. Список записей в порядке, но каждая отдельная запись — это просто набор данных. Программа должна знать индекс каждого поля, чтобы получить конкретное поле. Следующий код Python использует SQLite, чтобы продемонстрировать, как выполнить вышеуказанный запрос и отобразить данные:
Программа выше делает следующее:
Переменная people из строки 6 выше будет выглядеть в Python так:
Результат работы программы, записанной выше, выглядит следующим образом:
В приведенной выше программе мы должны знать, что имя человека соответствует полю с индексом 0, а фамилия человека соответствует полю с индексом 1. Хуже того, внутренняя структура person должна также быть известна заранее, всякий раз, когда мы передаём переменную итерации person в качестве параметра функции или методу.
Было бы намного лучше, если бы мы получили объект person в Python, где каждое из полей является атрибутом объекта. Это одна из вещей, которая делает SQLAlchemy.
Маленькие таблички Бобби
В приведенной выше программе оператор SQL представляет собой простую строку, передаваемую непосредственно в базу данных для выполнения. В нашем случае это не проблема, потому что SQL является строковым литералом, полностью находящимся под контролем программы. Однако сценарий использования нашего REST API будет принимать пользовательский ввод из веб‑приложения и использовать его для создания запросов SQL. Это может сделать наше приложение уязвимым для атаки.
Из первой части мы помните, что REST API для получения одного person от People выглядело так:
Приведенный выше фрагмент кода выполняет следующие действия:
Приведенный выше код, для простоты, устанавливает переменную lname в константу, но на самом деле она будет получена из пути конечной точки URL-адреса API и может быть любой, введённой пользователем. SQL запрос, сгенерированный форматированием строки, выглядит так:
Когда этот SQL выполняется базой данных, он ищет в таблице person запись, в которой фамилия равна «Farrell». Это то, что нужно, но любая программа, которая принимает пользовательский ввод, также открыта для злоумышленников. В вышеприведенной программе, где переменная lname задается введенным пользователем вводом, это открывает для нашей программы так называемую SQL‑инъекцию. Это то, что ласково называют «Маленькими табличками Бобби»:
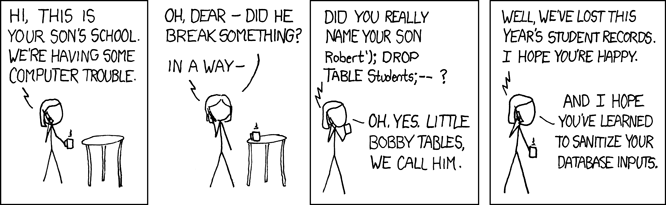
Например, представьте, что злонамеренный пользователь вызвал наш REST API следующим образом:
Приведенный выше запрос REST API устанавливает для переменной lname значение «Farrell»); DROP TABLE person; ‘, что в приведенном выше коде сгенерирует следующий оператор SQL:
Мы можем защитить свою программу, очистив все данные, которые получаем от пользователей нашего приложения. Очистка данных в этом контексте означает, что наша программа должна проверить предоставленные пользователем данные и убедиться, что они не содержат ничего опасного для программы. Это может быть сложно сделать правильно, но должно быть сделано везде, где пользовательские данные взаимодействуют с базой данных.
Есть еще один способ, который намного проще — использовать SQLAlchemy, который будет очищать пользовательские данные перед созданием операторов SQL. Это еще одно большое преимущество и мотив для использования SQLAlchemy при работе с базами данных.
Моделирование данных с SQLAlchemy
В соответствии с принципом инкапсуляции объектно-ориентированного программирования в объекте исвязывается данные с поведением, функциями, которые обработывают эти данными. Создав класс SQLAlchemy, мы можем связать поля из строк таблицы базы данных с поведением, позволяя нам взаимодействовать с данными. Вот определение класса SQLAlchemy для данных в таблице базы данных person :
Остальные определения являются атрибутами уровня класса, определенными следующим образом:
Примечание: метки времени UTC
Источником, или нулевым временем, является линия, проходящая с севера на юг от севера до южного полюса Земли через Великобританию. Это нулевой часовой пояс, от которого смещены все остальные часовые пояса. Используя его в качестве источника нулевого времени, наши временные метки будут смещены относительно этой стандартной контрольной точки.
Если к нашему приложению обращаются из разных часовых поясов, у вас есть способ выполнить вычисления даты/времени. Все, что вам нужно, это метка времени UTC и часовой пояс пункта назначения.
Если бы мы использовали местные часовые пояса в качестве источника меток времени, то мы не могли бы выполнять вычисления даты/времени без информации о смещении часовых поясов по местному времени от нуля. Без информации об источнике отметки времени мы вообще не могли бы сравнивать дату/время или выполнять математические операции.
Работа с временными метками на основе UTC является хорошим примером для подражания. Вот сайт с инструментарием для лучшего понимания и работы с датами и временем.
Но теперь, запишем небольшую программу с SQLAlchemy для выполнения этого запроса:
Использование SQLAlchemy позволяет мыслить с точки зрения объектов, обладающих некоторым поведением, а не с точки зрения простого SQL. Это становится еще более полезным, когда наши таблицы базы данных становятся больше и между ними усложняется взаимосвязь.
Сериализация/Десериализация смоделированных данных
Работа с данными, смоделированными в SQLAlchemy, внутри наших программ очень удобна. Особенно удобно в программах, где данными манипулируют, возможно, делают расчеты или используют их для создания презентаций. Наше приложение представляет собой REST API, по существу, обеспечивающее операции CRUD с данными и поэтому значительных манипуляций с данными оно не выполняет.
API REST работает с форматом JSON для данных и здесь можно столкнуться с проблемой модели SQLAlchemy. Поскольку данные, возвращаемые SQLAlchemy, являются экземплярами класса Python, Connexion не может сериализовать эти экземпляры класса в формате JSON. Помните из первого урока, что Connexion — это инструмент, который мы использовали для разработки и настройки REST API с использованием файла YAML, а так же для подключения к нему методов Python.
В этом контексте сериализация означает преобразование объектов Python, которые могут содержать другие объекты Python и сложные типы данных, в более простые структуры, преобразуемые в JSON. Здесь они перечислены:
Наш класс Person достаточно прост, поэтому получение атрибутов данных из него и создание словаря для возврата из конечных точек REST URL не составит большого труда. В более сложном приложении со многими более крупными моделями SQLAlchemy это было бы не так. Лучшее решение — использовать модуль Marshmallow, который сделает эту работу за вас.
Остальная часть определения выглядит следующим образом:
Создаём и инициализируем базу данных
SQLAlchemy обрабатывает многие взаимодействия, характерные для конкретных баз данных, и позволяет нам сосредоточиться на моделях данных, а также на том, как их использовать.
Теперь, когда мы на самом деле собираемся создать базу данных, то, как уже упоминалось ранее, будем использовать SQLite. Мы делаете это по нескольким причинам. SQLite встроен в дистрибутив Python и него не надо устанавливать, как отдельный модуль. Он сохраняет всю информацию базы данных в одном файле и поэтому прост в настройке и использовании.
Работа с отдельными серверами баз данных, такими, как MySQL или PostgreSQL, будет нормальной, но для этого потребуется установить эти системы и запустить их в работу, но это выходит за рамки нашего урока.
Поскольку SQLAlchemy управляет базой данных, во многих отношениях действительно не имеет значения, что является базовой базой данных.
Здесь мы можете найти исходный код для модулей, которые мы собираетесь создать, которые представлены здесь:
Модуль конфигурации
Хотя программа build_database.py не использует Flask, Connexion или Marshmallow, она использует SQLAlchemy для создания нашего соединения с базой данных SQLite. Вот код для модуля config.py:
Вот что делает приведенный выше код:
Модуль моделей
Модуль models.py создан для предоставления классов Person и PersonSchema в точности так, как описано в разделах выше о моделировании и сериализации данных. Вот код для этого модуля:
Вот что делает приведенный выше код:
Создание базы данных
Мы видели, как таблицы базы данных могут быть сопоставлены с классами SQLAlchemy. Теперь используйте то, что мы узнали, чтобы создать базу данных и заполнить ее данными. Мы собираетесь создать небольшую служебную программу для создания и создания базы данных с данными People. Вот программа build_database.py:
Вот что делает приведенный выше код:
Примечание. В строке 22 данные не были добавлены в базу данных. Все сохраняется в объекте сеанса. Только когда мы выполняете вызов db.session.commit () в строке 24, сеанс взаимодействует с базой данных и фиксирует действия для нее.
В SQLAlchemy сеанс является важным объектом. Он действует как канал связи между базой данных и объектами Python SQLAlchemy, созданными в программе. Сеанс помогает поддерживать согласованность между данными в программе и теми же данными, которые существуют в базе данных. Он сохраняет все действия с базой данных и соответственно обновляет базовую базу данных как явными, так и неявными действиями, предпринимаемыми программой.
Теперь мы готомы запустить программу build_database.py для создания и инициализации новой базы данных. Мы делаете это с помощью следующей команды, когда наша виртуальная среда Python активна:
Когда программа запускается, она выводит сообщения журнала SQLAlchemy на консоль. Это результат установки SQLALCHEMY_ECHO в True в файле config.py. Многое из того, что регистрирует SQLAlchemy, это команды SQL, которые он генерирует для создания и построения файла базы данных SQLite people.db. Вот пример того, что выводится при запуске программы:
Работа с базой данных
Как только база данных будет создана, мы можете изменить существующий код из первого урока, чтобы использовать ее. Все необходимые изменения связаны с созданием значения первичного ключа person_id в нашей базе данных в качестве уникального идентификатора, а не значения lname.
Обновим REST API
Ни одно из изменений не является очень существенным, и мы начнете с переопределения REST API. В приведенном ниже списке показано определение API из первого урока, но оно обновлено для использования переменной person_id в пути URL:



