Features engineering что это
Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist их генерирует.
Признаки для Data Mining: определение и виды
Признак (фича, feature) – это переменная, которая описывает отдельную характеристику объекта. В табличном представлении выборки признаки – это столбцы таблицы, а объекты – строки [1]. Входные, независимые, переменные для модели машинного обучения называются предикторами, а выходные, зависимые, – целевыми признаками. Все признаки могут быть следующих видов [2]:
Признаки могут извлекаться из данных любого типа, в т.ч. из текста, изображений и геоданных. При обработке текстовой информации сначала выполняется ее токенизация, а затем лемматизация и цифровизация – перевод слов в числовые вектора. Этому процессу мы посвятили отдельную статью. В случае изображений зачастую анализируется не только содержание картинки как набора пикселей различного цвета, но и метаданные графического файла: дата съемки, разрешение, модель камеры и т.д. Географические данные чаще всего представлены в виде адресов (текст) или пар «широта + долгота» (числовых наборов – точек) [3].
Feature engineering: шесть шагов для создания успешной модели машинного обучения
Исследования в области машинного обучения приводят к созданию новых алгоритмов и методик. Даже такой метод, как feature engineering, существующий уже несколько десятилетий, постоянно обновляется. Команды разработчиков должны постоянно учиться и прокачивать свои навыки, генерируя новые подходы в машинном обучении. «Хайтек» перевел и дополнил статью VentureBeat, чтобы рассказать о современных методиках в feature engineering и дать советы разработчикам по созданию моделей с добавленной стоимостью.
Читайте «Хайтек» в
Метод feature engineering так же стар, как и data science. Но почему-то он становится все более забытым. Высокий спрос на машинное обучение вызвал ажиотаж среди ученых-исследователей. Сегодня у них огромный опыт создания инструментов и алгоритмов. Но у них недостаточно отраслевых знаний, требуемых для feature engineering. Исследователи пытаются компенсировать это инструментами и алгоритмами. Однако алгоритмы теперь являются лишь товаром и сами по себе не генерируют корпоративное IP-портфолио (портфель интеллектуальных прав, принадлежащих компании — «Хайтек»).

Feature engineering (с англ. «создание показателей, признаков») — техника решения задач машинного обучения, позволяющая увеличить качество разрабатываемых алгоритмов. Предусматривает превращение данных, специфических для предметной области, в понятные для модели векторы. Чтобы эффективно решить задачу с feature engineering, необходимо быть экспертом в конкретной области и понимать, что влияет на конкретную целевую переменную. Поэтому многие разработчики называют feature engineering искусством, требующим решения большого количества задач и наработки опыта.
Сегодня такие стартапы, как ContextRelevant и SparkBeyond, разрабатывают новые инструменты, которые упростят для пользователей процесс создания и отбора показателей (feature selection).
Обобщенные данные тоже становятся товаром, а облачные сервисы машинного обучения (MLaaS), такие, как Amazon ML и Google AutoML, теперь позволяют даже менее опытным членам команды запускать модели данных и получать их прогнозы в течение нескольких минут. Но в результате этого набирают обороты те компании, которые развивают организационную компетенцию в сборе или изготовлении собственных данных, создаваемых при feature engineering. Простого сбора данных и построения моделей уже недостаточно.
Корпорации многому учатся у победителей соревнований по моделированию, таких как KDD Cup и Heritage Provider Network Health Prize. Своими успехами они обязаны именно грамотному подходу к методу feature engineering.

Ян Лекун, Facebook: прогностические модели мира — решающее достижение в ИИ
Методы feature engineering
Для техники feature engineering ученые разработали ряд методов.
Контекстная трансформация. Он включает в себя преобразование отдельных функций из исходного набора в более контекстуально значимую информацию для каждой конкретной модели.
Например, при использовании категориальной функции в качестве «неизвестного» может быть специальная информация в контексте ситуации. Но внутри модели это выглядит, как просто другое значение категории. В этом случае можно ввести новую двоичную функцию has_value, чтобы отделить «неизвестное» от всех других опций. Например, функция color позволит ввести has_color для какого-то неизвестного цвета.
Команды машинного обучения часто используют биннинг для разбивания отдельных функций на несколько для лучшего понимания. Например, разделение функции «возраст» на «молодой» для 60 лет.
Биннинг, или балансировка данных — метод предварительной обработки, используемый для уменьшения влияния незначительных ошибок наблюдения. Исходные значения данных, которые попадают в небольшой интервал, заменяются значением, представляющим этот интервал, часто центральным значением. Это форма квантования.
Некоторые другие примеры преобразований:
Многофункциональная арифметика. Другой подход к feature engineering заключается в применении арифметических формул к набору существующих точек данных. Такие формулы создают производные, основанные на взаимодействии между функциями и их отношениях друг к другу.
Построение с многофункциональной арифметикой — очень выгодно, но оно требует полного понимания предмета и целей модели.
Примеры использования формул:

Джианкарло Суччи: «Попытка спроектировать программу без багов — утопия»
Feature Engineering, о чём молчат online-курсы

Sherlock by ThatsWhatSheSayd
Чтобы стать великим сыщиком, Шерлоку Холмсу было достаточно замечать то, чего не видели остальные, в вещах, которые находились у всех на виду. Мне кажется, что этим качеством должен обладать и каждый специалист по машинному обучению. Но тема Feature Engineering’а зачастую изучается в курсах по машинному обучению и анализу данных вскользь. В этом материале я хочу поделиться своим опытом обработки признаков с начинающими датасаентистами. Надеюсь, это поможет им быстрее достичь успеха в решении первых задач. Оговорюсь сразу, что в рамках этой части будут рассмотрены концептуальные методы обработки. Практическую часть по этому материалу совсем скоро опубликует моя коллега Osina_Anya.
Один из популярных источников данных для машинного обучения — логи. Практически в любой строчке лога есть время, а если это web-сервис, то там будут IP и UserAgent. Рассмотрим, какие признаки можно извлечь из этих данных.
Время
UnixTimestamp
UnixTimestamp — это количество секунд, прошедшее с 1970-01-01 00:00:00.000, популярное представление времени, натуральное число. Можно в модель добавить время в этом формате, но такой подход чаще работает в задачах регрессии. В задачах классификации он работает редко, так как в UnixTimestamp-формате сохраняется только информация о последовательности событий, а о днях недели, месяцах, часах и т. д. модель ничего знать не будет.
Год, месяц, день, часы, минуты, секунды, день недели
Часто время добавляют в модель в виде набора натуральных чисел: отдельно год, отдельно номер месяца и т. д. до нужной детализации. Например, 2017-09-08 12:07:12.997 можно преобразовать в пять признаков: 2017, 09, 08, 12, 07. Ещё можно добавить бинарный признак: выходной день или нет, время года, рабочее время или нет — и т. д., и т. п. Удачный набор таких признаков чаще всего позволяет решить задачу c высоким качеством. Иногда работает метод Создание OneHotEncoding признаков на месяцы/годы, но это скорее экзотика, нежели практика.
Отображение на круг
Представления времени в качестве набора отдельных компонентов часто достаточно, но оно имеет одну слабую сторону и может требовать добавления дополнительных признаков.
Допустим, у нас есть задача: по текущему времени определить, зачем человек взял в руки мобильный телефон — отключить звук или поставить будильник. При этом мы видим по историческим данным, что человек ставит будильник с 23.00 до 01.00, а выключает звук с 07.00 до 21.00. Если мы станем решать задачу логистической регрессией, то ей надо будет построить разделяющую плоскость для следующей картинки:

Очевидно, что она не сможет этого сделать: такое представление времени теряет информацию о том, что 23.00 и 01.00 — это очень близкие события. В данном случае можно добавить квадратичные признаки, но у меня есть способ получше! Для решения таких проблем пригодится следующий приём: берём признак, о котором мы знаем, что он меняется по циклу. Например, «час» — он меняется от 0 до 23. И превращаем его в два признака: cos(«час» 2 pi / 24 ), sin(«час» 2 pi / 24 ), т. е. мы равномерно распределили все элементы цикла по единичной окружности с центром в 0 и диаметром 1.
Для такого множества точек логистическая регрессия с лёгкостью найдёт разделяющую плоскость и поможет человеку поставить будильник. Аналогично можно поступать с днями недели, месяца, циклами работы поршня и т. д. Теоретически этот метод можно проинтерполировать и на более сложные периодические функции с помощью разложения в ряд Фурье, но я с такими случаями не сталкивался.
IP-адрес
Немного слов об IP
На первый взгляд IP-адрес — важный признак, но что с ним делать — совершенно непонятно. Наиболее распространённый сейчас вариант — это IPV4, т. е. последовательность из 4 байтов, традиционно записываемых в виде «255.0.0.1». Работать с этими числами или со всем IP как с числовыми признаками абсолютно некорректно. Если у вас есть два IP-адреса — 123.123.123.123 и 124.123.123.123, — то близость этих чисел совершенно ничего не значит (первый — это China Unicom Beijing province network, второй — Beam Telecom Pvt Ltd). Корректно было бы рассматривать IP как категориальный с выделением подсетей, но у больших сервисов таких категорий очень много. Например, если рассматривать категории по подсетям третьего уровня, то их получается 2^24 —
10^16. Чтобы обучить модель более чем с 16 миллионами признаков, нужно действительно много данных, и, скорее всего, они создадут ненужный шум.
Геолокация
На самом деле из IP достаётся гораздо больше информации, чем просто разбиение по сетям. Так, из IP-адреса с хорошей точностью извлекается страна, регион, а иногда даже город, в котором находился пользователь сервиса. Для этого можно использовать:
Внимательно обходитесь с данными, полученными об IP из подобных сервисов. Данные иногда устаревают, иногда бывают ошибочны, а IP-адреса мобильных операторов связи — вообще большая проблема, так как нередко вы можете через одного оператора с одним и тем же IP выйти как из Москвы, так и из Владивостока. Поэтому я рекомендую формировать эти дополнительные поля к логу в момент его получения, а не позже, в момент сбора признаков, так как у вас уже может не быть версии базы на тот момент, как случилось описанное в логе событие. Плюс подхода: вы сможете отследить тот факт, что какой-то IP, встречавшийся в России, перешёл в Европу, или наоборот. Но даже с этими оговорками данная функция очень полезна для анализа данных и способна значительно повысить качество модели.
Постскриптум для этого пункта
Если ваш сервис достаточно большой, то вы можете сами собирать GeoIP-базы. Если пользователь предоставит вашему сайту/приложению доступ к своей геолокации, то вы автоматически получите информацию о расположении конкретных IP-адресов. Только вам придётся придумать, как быть с некорректными геолокациями и IP-адресами, которые имеют широкую географию. Кроме того, пользуясь этим приёмом, можно предполагать, откуда заходил пользователь: из дома, с работы, находясь в дороге.
Чистота IP-адреса
Для анализа данных иногда стоит отфильтровывать действия настоящих пользователей от действий ботов, поисковых роботов и подобной «нечисти». В исходной формулировке эта задача очень сложная, используемая во многих областях, например антиспаме и антифроде. Но для задачи фильтрации данных иногда хватает и более простых методов — фильтрации по IP. Так, в интернете можно найти открытые списки IP-адресов, с которых часто проводятся фрод- и ддос-атаки, IP-адреса tor-exitnode (боты часто используют их для обхода блокировки IP за частые запросы к сервису) и IP-адреса открытых прокси-серверов (иногда применяются для тех же целей). Так, можно добавить в вектор признаков флаг «наличие IP-адреса в этих базах». Кроме того, по историческим данным вы можете считать вероятность встретить такого же провайдера, что и у IP-адреса в данной строке лога. Эта вероятность тоже может быть признаком, только у него есть гиперпараметр: как далеко смотреть историю, чтобы считать вероятность. Это важно, так как распределение пользователей и, как следствие, распределение провайдеров пользователей на сервисе меняется.
Возвращаясь к вопросу фильтрации «плохих» пользователей, отмечу: стандартная практика — фильтрация логов с IP-адресов, фигурировавших в доверенных чёрных списках. При этом пользователи, их инициировавшие, не принадлежат к списку пользователей, недавно совершавших доверенные действия. Оба этих условия одинаково важны, так как даже хорошие пользователи иногда обращаются к Tor’у и прокси-серверам, но аккаунт хорошего пользователя может быть взломан. Поэтому действие, характеризующее его как настоящего человека, должно произойти недавно.
UserAgent
Немного о UserAgent
Если мы говорим об HTTP-протоколе, то программное обеспечение, которое отправляет запрос на ваш сервер, в заголовке запроса передаёт поле User-Agent, в котором содержится информация о версии программного обеспечения и операционной системы. С помощью этого поля заголовка часто происходит перенаправление на мобильную версию сайта или на версию сайта без использования JS. Кроме версии браузера и операционной системы, в UserAgent может содержаться и другая полезная информация, но её иногда непросто достать. Дело в том, что единого утверждённого формата для строки User-Agent’а нет, и каждый пишет туда информацию так, как захочет. Есть много различных библиотек, позволяющих извлечь из строки UserAgent браузер и операционную систему, и их можно выбирать на свой вкус. Лично мне нравится https://github.com/ua-parser.
ОС, ПО, что сложного?
Браузер и операционную систему можно добавить как категориальный признак, воспользовавшись OneHotEncoding, даже тип устройства достаётся. Только для этого нужно аккуратно смотреть и на браузер, и на операционную систему. Но в UserAgent ещё можно опознать поисковых ботов, скрипты на Python, программы и кастомные сборки браузеров, использующие WebKit. Только с этим многообразием возможностей приходит и многообразие проблем. Записать в UserAgent-строку можно всё что угодно, и этим пользуются разработчики вредоносного ПО: для вашего сервера всё будет выглядеть так, будто к вам пришёл обычный пользователь с браузером Chrome и Windows 10 на компьютере. Поэтому надо относиться очень аккуратно к данным из UserAgent и следить за аномалиями в статистике версий браузеров. В ней вы можете заметить, что очень старая версия хрома гораздо популярней последней, или увидеть «вспышки» из старых андроидов. Кроме того, поможет частотный анализ, как и в случае с IP. Чаще всего разработчики роботов не знают распределения браузеров у вашей целевой аудитории и берут UserAgent из своих баз данных о распределении UserAgent среди пользователей интернета, а базы могут устаревать, не соответствовать географии, целевой аудитории вашего сервиса и т. д. Но все эти трудности — не повод не пользоваться этими данными. Это повод посмотреть на них внимательнее и извлечь ещё больше полезной информации.
Заключение
Подготовка признаков — важный этап в анализе данных. Часто начинающие датасаентисты начинают перебирать сложные модели, строить многослойные нейронные сети, делать ансамбли различных алгоритмов в тех случаях, когда можно решить задачу, аккуратно добавив хорошие признаки в логистическую регрессию. Я рассказал о кое-каких данных, которые редко рассматриваются в учебных курсах, но часто встречаются в реальной работе. Надеюсь, что информация была вам полезной.
📊 Построение и отбор признаков. Часть 1: feature engineering

Alex Maszański

Что такое признаки (features) и для чего они нужны?
Признаки могут быть следующих видов:
Стоит отметить, что для задач машинного обучения нужны только те «фичи», которые на самом деле влияют на итоговый результат. Определить и сгенерировать такие признаки вам поможет эта статья.
Что такое построение признаков?
Например, в базе данных интернет-магазина есть таблица «Покупатели», содержащая одну строку для каждого посетившего сайт клиента.

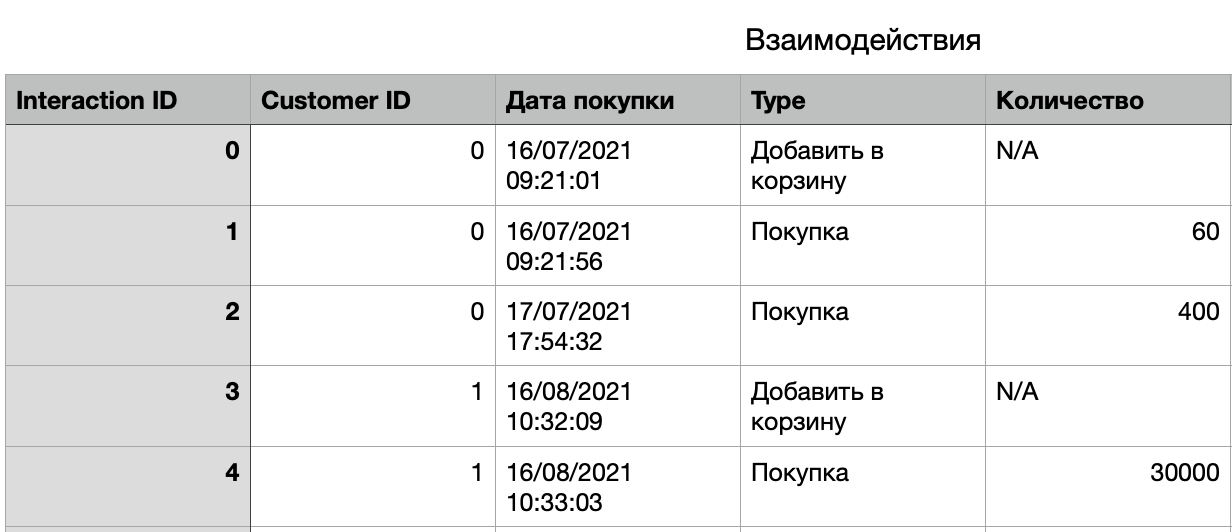
Чтобы повысить предсказательную способность, нам необходимо воспользоваться данными в таблице взаимодействий. Отбор признаков делает это возможным. Мы можем рассчитать статистику для каждого клиента, используя все значения в таблице «Взаимодействия» с идентификатором этого клиента. Вот несколько потенциально полезных признаков, или же «фич», которые помогут нам в решении задачи:
Следует обратить внимание, что данный процесс уникален для каждого случая использования и набора данных.
Этот тип инжиниринга признаков необходим для эффективного использования алгоритмов машинного обучения и построения прогностических моделей.
Построение признаков на табличных данных
Удаление пропущенных значений
Отсутствующие значения – одна из наиболее распространенных проблем, с которыми вы можете столкнуться при попытке подготовить данные. Этот фактор очень сильно влияет на производительность моделей машинного обучения.
Самое простое решение для пропущенных значений – отбросить строки или весь столбец. Оптимального порога для отбрасывания не существует, но вы можете использовать 70% в качестве значения и отбросить строки со столбцами, в которых отсутствуют значения, превышающие этот порог.
Заполнение пропущенных значений
В качестве другого примера: у вас есть столбец, который показывает количество посещений клиентов за последний месяц. Тут отсутствующие значения могут быть заменены на 0.
За исключением вышеперечисленного, лучший способ заполнения пропущенных значений – использовать медианы столбцов. Поскольку средние значения столбцов чувствительны к значениям выбросов, медианы в этом отношении будут более устойчивыми.
Замена пропущенных значений максимальными
Замена отсутствующих значений на максимальное значение в столбце будет хорошим вариантом для работы только в случае, когда мы разбираемся с категориальными признаками. В других ситуациях настоятельно рекомендуется использовать предыдущий метод.
Обнаружение выбросов
Другой математический метод обнаружения выбросов – использование процентилей. Вы принимаете определенный процент значения сверху или снизу за выброс.
Ключевым моментом здесь является повторная установка процентного значения, и это зависит от распределения ваших данных, как упоминалось ранее.
Ограничение выбросов
С другой стороны, ограничение может повлиять на распределение данных и качество модели, поэтому лучше придерживаться золотой середины.
Логарифмическое преобразование
Важное примечание: данные, которые вы применяете, должны иметь только положительные значения, иначе вы получите ошибку.
Быстрое кодирование (One-Hot encoding)
Этот метод распределяет значения в столбце по нескольким столбцам флагов и присваивает им 0 или 1. Бинарные значения выражают связь между сгруппированным и закодированным столбцом. Этот метод изменяет ваши категориальные данные, которые сложно понять алгоритмам, в числовой формат. Группировка происходит без потери какой-либо информации, например:
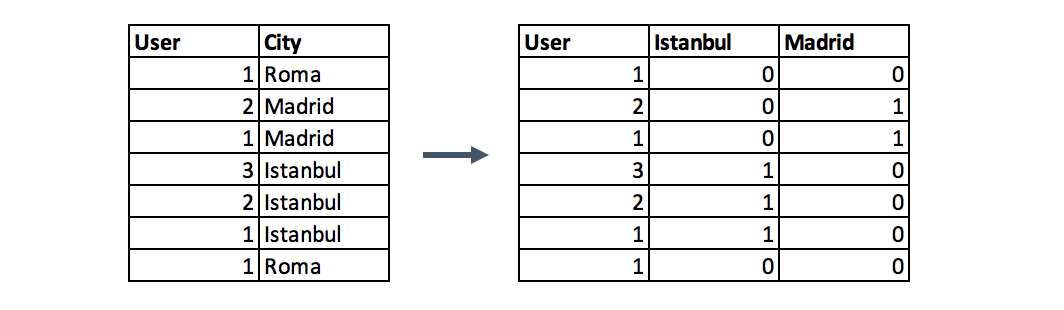
Приведенная ниже функция отражает использование метода быстрого кодирования с вашими данными.
Масштабирование признаков
В большинстве случаев числовые характеристики набора данных не имеют определенного диапазона и отличаются друг от друга.
Например, столбцы возраста и месячной зарплаты будут иметь совершенно разный диапазон.
Как сравнить эти два столбца, если это необходимо в нашей задаче? Масштабирование решает эту проблему, так как после данной операции элементы становятся идентичными по диапазону.
Существует два распространенных способа масштабирования:
В данном случае все значения будут находиться в диапазоне от 0 до 1. Дискретные бинарные значения определяются как 0 и 1.
Масштабирует значения с учетом стандартного отклонения. Если стандартное отклонение функций другое, их диапазон также будет отличаться друг от друга. Это снижает влияние выбросов в элементах. В следующей формуле стандартизации среднее значение показано как μ, а стандартное отклонение показано как σ.
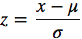
Работа с текстом
Перед тем как работать с текстом, его необходимо разбить на токены – отдельные слова. Однако делая это слишком просто, мы можем потерять часть смысла. Например, «Великие Луки» это не два токена, а один.
В коде алгоритм выглядит гораздо проще, чем на словах:
Работа с изображениями
Чтобы адаптировать ее под свою задачу, работающие в области науки о данных инженеры практикуют fine tuning (тонкую настройку). Ликвидируются последние слои нейросети, вместо них добавляются новые, подобранные под нашу конкретную задачу, и сеть дообучается на новых данных.
Пример подобного шаблона:
Заключение
На практике процесс построения фич может быть самым разнообразным: решение проблемы пропущенных значений, обнаружение выбросов, превращение текста в вектор (с помощью продвинутой обработки естественного языка, которая отображает слова в векторное пространство) – лишь некоторые примеры из этой области.
Мастерство Data Science: Автоматизированное конструирование признаков на Python

Машинное обучение все больше переходит от моделей, разработанных вручную, к автоматически оптимизированным пайплайнам с использованием таких инструментов, как H20, TPOT и auto-sklearn. Эти библиотеки, наряду с такими методами, как случайный поиск, стремятся упростить выбор модели и настройку частей машинного обучения, находя лучшую модель для набора данных без какого-либо ручного вмешательства. Однако разработка объектов, возможно, более ценный аспект пайплайнов машинного обучения, остается почти полностью человеческим трудом.
Конструирование признаков (Feature engineering), также известная как создание признаков (feature creation), представляет собой процесс создания новых признаков из существующих данных для обучения модели машинного обучения. Этот шаг может быть более важным, чем фактическая используемая модель, потому что алгоритм машинного обучения извлекает уроки только из тех данных, которые мы ему предоставляем, и создание признаков, которые имеют отношение к задаче, абсолютно необходимо (см. Превосходную статью «Несколько полезных вещей, которые необходимо знать о Машинное обучение»).
Как правило, разработка признаков — это длительный ручной процесс, основанный на знании предметной области, интуиции и манипулировании данными. Этот процесс может быть чрезвычайно утомительным, и конечные характеристики будут ограничены как субъективностью человека, так и временем. Автоматизированное проектирование признаков направлено на то, чтобы помочь специалисту по науке о данных, автоматически создавать множество объектов-кандидатов из набора данных, из которого можно выбрать лучшие и использовать для обучения.
В этой статье мы рассмотрим пример использования автоматической разработки признаков с библиотекой featuretools для Python. Мы будем использовать примерный набор данных, чтобы показать основы (следите за будущими публикациями с использованием реальных данных). Полный код из этой статьи доступен на GitHub.
Основы разработки признаков
Разработка признаков означает создание дополнительных признаков из существующих данных, которые часто распределяются по нескольким связанным таблицам. Разработка признаков требует извлечения соответствующей информации из данных и помещения ее в единую таблицу, которую затем можно использовать для обучения модели машинного обучения.
Процесс создания признаков очень трудоемкий, поскольку для создания каждой нового признака обычно требуется несколько шагов, особенно при использовании информации из нескольких таблиц. Мы можем сгруппировать операции создания признаков в две категории: преобразования и агрегации. Давайте рассмотрим несколько примеров, чтобы увидеть эти концепции в действии.
Преобразование действует на одну таблицу (в терминах Python, таблица представляет собой просто Pandas DataFrame ), создавая новые признаки из одного или нескольких существующих столбцов. Например, если у нас есть таблица клиентов ниже,
С другой стороны, агрегации выполняются по таблицам и используют отношение «один ко многим», чтобы группировать наблюдения и затем вычислять статистику. Например, если у нас есть другая таблица с информацией о кредитах клиентов, где у каждого клиента может быть несколько кредитов, мы можем рассчитать такую статистику, как среднее, максимальное и минимальное значения кредита для каждого клиента.
Этот процесс включает в себя группирование таблицы loans по клиенту, вычисление агрегации и последующее объединение полученных данных с данными клиента. Вот как мы могли бы сделать это в Python, используя язык Pandas.
Эти операции сами по себе не сложны, но если у нас есть сотни переменных, разбросанных по десяткам таблиц, этот процесс невозможно осуществить вручную. В идеале нам нужно решение, которое может автоматически выполнять преобразования и агрегации для нескольких таблиц и объединять полученные данные в одну таблицу. Несмотря на то, что Pandas — отличный ресурс, есть еще много манипуляций с данными, которые мы хотим сделать вручную! (Подробнее о ручном проектировании признаков можно найти в превосходном справочнике Python Data Science Handbook).
Featuretools
К счастью, featuretools — это именно то решение, которое мы ищем. Эта библиотека для Python с открытым исходным кодом автоматически создает множество признаков из набора связанных таблиц. Featuretools основан на методе, известном как «Deep Feature Synthesis», который звучит гораздо более впечатляюще, чем на самом деле (название происходит от объединения нескольких признаков, а не потому, что он использует глубокое обучение!).
Глубокий синтез признаков объединяет несколько операций преобразования и агрегирования (которые называются примитивами признаков в словаре FeatureTools) для создания признаков из данных, распределенных по многим таблицам. Как и большинство идей в области машинного обучения, это сложный метод, основанный на простых понятиях. Изучая один строительный блок за один раз, мы можем сформировать хорошее понимание этого мощного метода.
Во-первых, давайте посмотрим на данные из нашего примера. Мы уже видели что-то из набора данных выше, и полный набор таблиц выглядит следующим образом:
Если у нас есть задача для машинного обучения, такая как прогнозирование того, будет ли клиент погашать будущий кредит, мы захотим объединить всю информацию о клиентах в одну таблицу. Таблицы связаны (через переменные client_id и loan_id ), и мы могли бы использовать серию преобразований и агрегаций, чтобы выполнить этот процесс вручную. Однако вскоре мы увидим, что вместо этого мы можем использовать featuretools для автоматизации процесса.
Entities и EntitySets (сущности и наборы сущностей)
Мы можем создать пустой набор сущностей в featuretools, используя следующее:
Для этого фрейма данных, несмотря на то, что missed является целым числом, это не числовая переменная, так как она может принимать только 2 дискретных значения, поэтому мы говорим featuretools что следует рассматривать ее как категориальную переменную. После добавления фреймов данных в набор сущностей мы исследуем любую из них:
Типы столбцов были правильно выведены с указанной модификацией. Далее нам нужно указать, как связаны таблицы в наборе сущностей.
Связи между таблицами
Лучший способ представить отношение между двумя таблицами — это аналогия родителей и детей. Отношение один ко многим: у каждого родителя может быть несколько детей. В области таблиц родительская таблица имеет одну строку для каждого родителя, но дочерняя таблица может иметь несколько строк, соответствующих нескольким дочерним элементам одного и того же родителя.
Набор сущностей теперь содержит три сущности (таблицы) и отношения, которые связывают эти сущности вместе. После добавления сущностей и формализации отношений наш набор сущностей завершен, и мы готовы создавать признаки.
Примитивы признаков
Прежде чем мы сможем полностью перейти к глубокому синтезу признаков, нам нужно понять примитивы признаков. Мы уже знаем, что это такое, но мы просто называем их разными именами! Это просто основные операции, которые мы используем для формирования новых признаков:
Результатом является датафрейм новых признаков для каждого клиента (потому что мы сделали клиентов target_entity ). Например, у нас есть месяц, в котором присоединился каждый клиент, который является примитивом преобразования:
У нас также есть ряд примитивов агрегации, таких как средние суммы платежей для каждого клиента:
Несмотря на то, что мы указали только несколько примитивов, featuretools создал много новых признаков, комбинируя и складывая эти примитивы.
Полный фрейм данных содержит 793 столбца новых признаков!
Глубокий Синтез Признаков
Теперь у нас есть все для понимания глубокого синтеза признаков (dfs). Фактически, мы уже выполняли dfs в предыдущем вызове функции! Глубокий признак — это просто признак, состоящий из объединения нескольких примитивов, а dfs — это имя процесса, который создает эти признаки. Глубина глубокого признака — это количество примитивов, необходимых для создания признака.
Мы можем составлять признаки на любую глубину, какую захотим, но на практике я никогда не выходил за пределы глубины 2. После этого момента признаки трудно интерпретировать, но я призываю всех, кто заинтересован, попробовать «углубиться».
Featuretools создал много новых признаков для нас. Хотя этот процесс автоматически создает новые признаки, он не заменит специалиста по Data Science, потому что нам еще предстоит выяснить, что делать со всеми этими признаками. Например, если наша цель состоит в том, чтобы предсказать, будет ли клиент погашать кредит, мы могли бы искать признаки, наиболее соответствующие конкретному результату. Более того, если у нас есть знание предметной области, мы можем использовать его для выбора конкретных примитивов признаков или для глубокого синтеза признаков-кандидатов.
Следующие шаги
Автоматизированное проектирование признаков решило одну проблему, но создало другую: слишком много признаков. Хотя до подбора модели сложно сказать, какие из этих признаков будут важны, скорее всего, не все из них будут иметь отношение к задаче, на которой мы хотим обучать нашу модель. Более того, слишком большое количество признаков может привести к снижению производительности модели, поскольку менее полезные признаки вытесняют те, которые являются более важными.
Проблема слишком многих признаков известна как проклятие размерности. По мере увеличения числа признаков (размерность данных) модели становится все труднее изучать соответствие между признаками и целями. Фактически, объем данных, необходимых для хорошей работы модели, масштабируется экспоненциально с количеством признаков.
Проклятие размерности сочетается с сокращением признаков (также известным как выбор признаков): процессом удаления ненужных признаков. Это может принимать различные формы: Principal Component Analysis (PCA), SelectKBest, использование значений признаков из модели или автоматическое кодирование с использованием глубоких нейронных сетей. Однако сокращение признаков — это отдельная тема для другой статьи. На данный момент мы знаем, что мы можем использовать featuretools для создания множества признаков из множества таблиц с минимальными усилиями!
Вывод
Как и многие темы в машинном обучении, автоматизированное проектирование признаков с помощью featuretools — сложная концепция, основанная на простых идеях. Используя понятия наборов сущностей, сущностей и отношений, featuretools может выполнять глубокий синтез признаков для создания новых признаков. Глубокий синтез признаков, в свою очередь, объединяет примитивы — агрегаты, которые действуют через отношения «один ко многим» между таблицами, и преобразования, функции, применяемые к одному или нескольким столбцам в одной таблице, — для создания новых признаков из нескольких таблиц.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:



