Feature importance в sklearn и catboost на примере классических датасетов
В данной статье будет рассмотрен пример вычисления и визуализации feature importance на классических датасетах iris и wine. Используемые ml-библиотеки: sklearn и catboost. Для визуализации будет использоваться matplotlib.
Создание классификатора на основе имеющихся данных – частая задача в практике DS-специалиста. Все помнят один из основных минусов моделей на нейронных сетях – они плохо поддаются интерпретации. При этом, чем сложнее архитектура, тем более неожиданно могут выбираться признаки для решения задачи. Однако, классические методы машинного обучения, такие как, например, деревья решений поддаются интерпретации относительно хорошо и понять, почему модель показала такой результат, а не другой — довольно просто. Более того, можно даже узнать насколько важны те или иные параметры! Это и есть feature importance. Принцип вычисления значений для признака F следующий:
Сравниваемые пары листьев имеют разные значения разделения в узле на пути к этим листьям. Если условие разделения выполнено (это условие зависит от функции F), объект переходит в левое поддерево, в противном случае он переходит в правое. Таким образом,
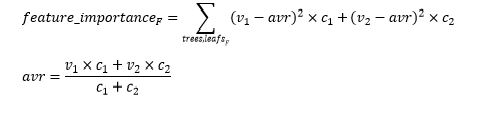
где с1 и с2 и представляют общий вес объектов в левом и правом листьях соответственно. Этот вес равен количеству объектов в каждом листе, если веса не указаны для набора данных.
v1 и v2 и представляет значение формулы в левом и правом листьях соответственно.
В данной статье будет рассмотрен пример вычисления и визуализации feature importance на классических датасетах iris и wine. Используемые ml-библиотеки: sklearn и catboost. Для визуализации будет использоваться matplotlib.
Импорт необходимых библиотек:
Загрузка датасета iris:

Рисунок 1 — Пример данных из датасета iris
Обучение sklearn RandomForest и построение гистограммы для визуализации важности признаков:
 Рисунок 2 – feature importance sklearn для iris
Рисунок 2 – feature importance sklearn для iris
Обучение catboost Classifier и построение гистограммы для визуализации важности признаков:
 Рисунок 3 — feature importance catboost для iris
Рисунок 3 — feature importance catboost для iris
Сравнение результатов feature importance для sklearn и catboost на iris:
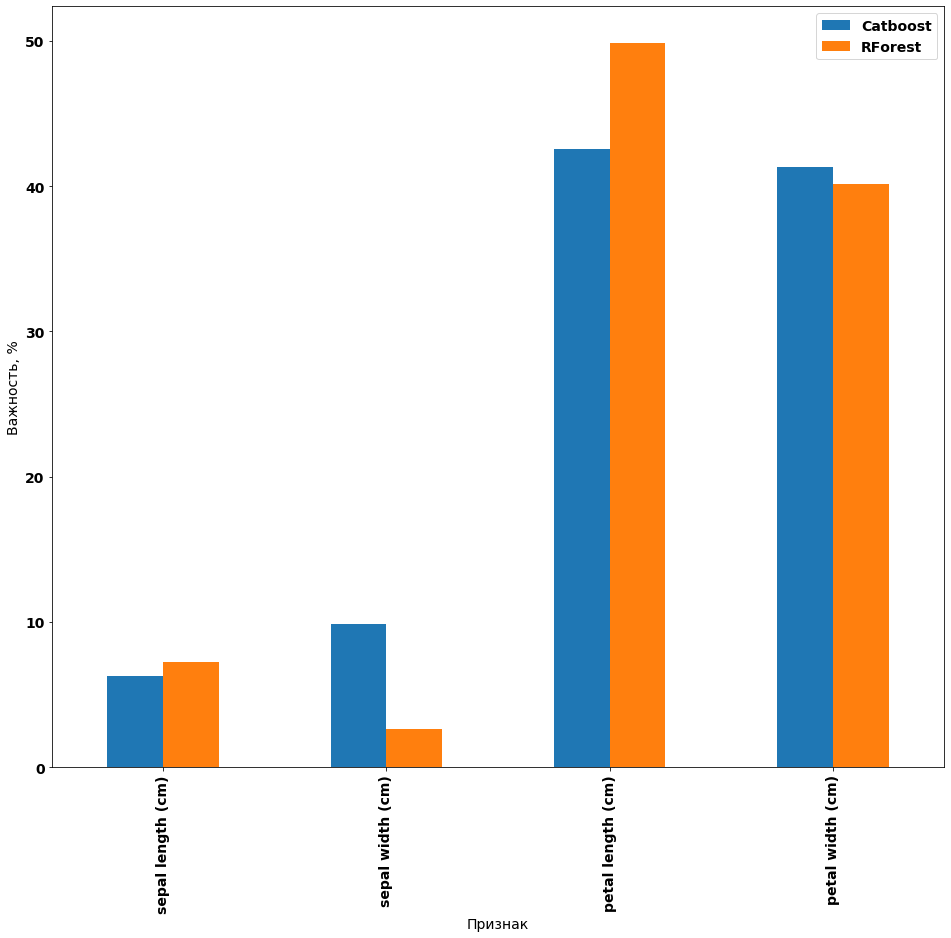 Рисунок 4 – Сравнение feature importance для iris
Рисунок 4 – Сравнение feature importance для iris
Загрузка датасета wine:
 Рисунок 5 — Пример данных из датасета wine
Рисунок 5 — Пример данных из датасета wine
Обучение sklearn RandomForest и построение гистограммы для визуализации важности признаков:
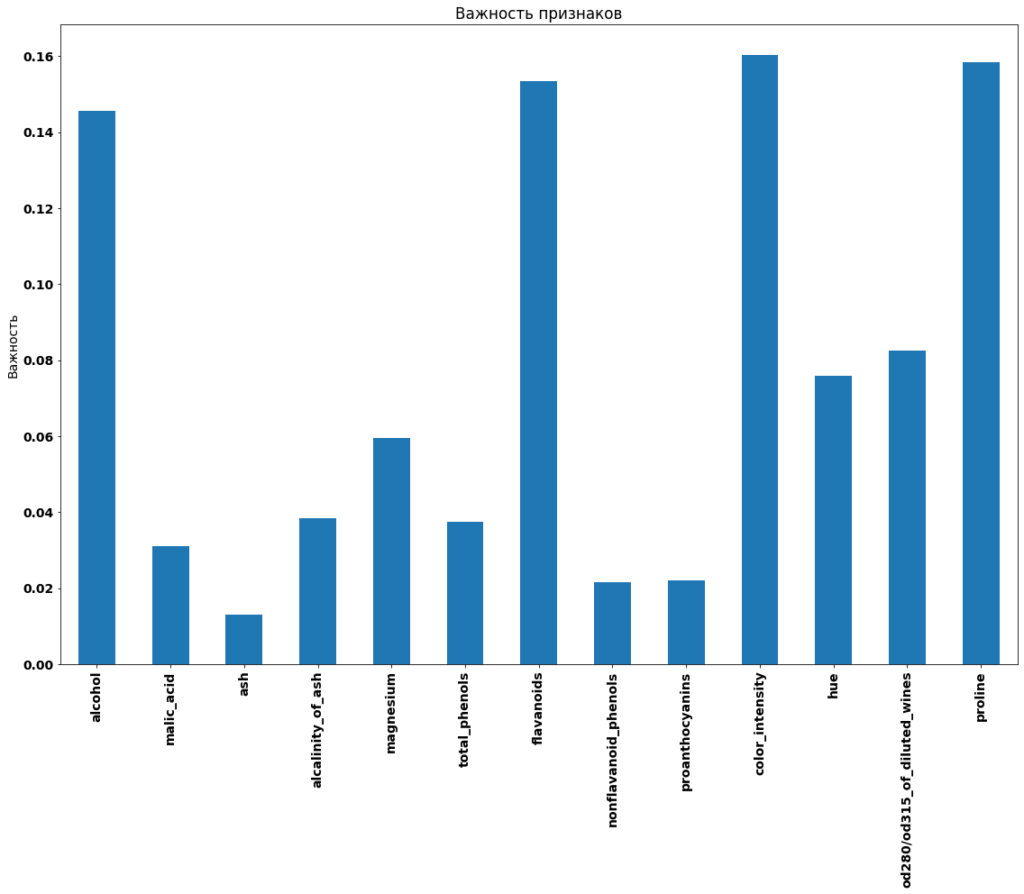 Рисунок 6 — feature importance sklearn для wine
Рисунок 6 — feature importance sklearn для wine
Обучение catboost Classifier и построение гистограммы для визуализации важности признаков:
 Рисунок 7 — feature importance catboost для wine
Рисунок 7 — feature importance catboost для wine
Сравнение результатов feature importance для sklearn и catboost на wine:
 Рисунок 8 – Сравнение feature importance для wine
Рисунок 8 – Сравнение feature importance для wine
Приведённые выше графики показывают, что на выбранных данных обе модели ведут себя схожим образом и отбирают почти одни и те же признаки, как наиболее важные.
Полученные данные можно использовать, например, для ручного сокращения размерности данных или просто наглядного представления зависимости целевой переменной от определённых признаков.
1.13. Выбор признаков ¶
Классы в sklearn.feature_selection модуле могут использоваться для выбора признаков / уменьшения размерности на выборочных наборах, либо для улучшения показателей точности оценщиков, либо для повышения их производительности на очень многомерных наборах данных.
1.13.1. Удаление функций с низкой дисперсией
VarianceThreshold это простой базовый подход к выбору функций. Он удаляет все функции, дисперсия которых не соответствует некоторому порогу. По умолчанию он удаляет все признаки с нулевой дисперсией, то есть признаки, которые имеют одинаковое значение во всех выборках.
В качестве примера предположим, что у нас есть набор данных с логическими функциями, и мы хотим удалить все функции, которые равны единице или нулю (включены или выключены) в более чем 80% выборок. Булевы функции — это случайные величины Бернулли, а дисперсия таких переменных определяется выражением
$$\mathrm[X] = p(1 — p)$$
1.13.2. Одномерный выбор функций
Одномерный выбор функций работает путем выбора лучших функций на основе одномерных статистических тестов. Это можно рассматривать как этап предварительной обработки оценщика. Scikit-learn предоставляет процедуры выбора функций как объекты, реализующие transform метод:
Эти объекты принимают в качестве входных данных функцию оценки, которая возвращает одномерные оценки и p-значения (или только оценки для SelectKBest и SelectPercentile ):
Методы, основанные на F-тесте, оценивают степень линейной зависимости между двумя случайными величинами. С другой стороны, методы взаимной информации могут фиксировать любой вид статистической зависимости, но, будучи непараметрическими, они требуют большего количества выборок для точной оценки.
Выбор функций с разреженными данными
Остерегайтесь использовать функцию оценки регрессии с проблемой классификации, вы получите бесполезные результаты.
1.13.3. Рекурсивное устранение признаков
RFECV выполняет RFE в цикле перекрестной проверки, чтобы найти оптимальное количество функций.
1.13.4. Выбор функции с помощью SelectFromModel
Примеры использования см. В разделах ниже.
1.13.4.1. Выбор функций на основе L1
Линейные модели, наказанные нормой L1, имеют разреженные решения: многие из их оценочных коэффициентов равны нулю. Когда цель состоит в том, чтобы уменьшить размерность данных для использования с другим классификатором, их можно использовать вместе с SelectFromModel для выбора ненулевых коэффициентов. В частности, для этой цели полезны разреженные оценки, используемые для Lasso регрессии, LogisticRegression а также LinearSVC для классификации:
С SVM и логистической регрессией параметр C контролирует разреженность: чем меньше C, тем меньше выбирается функций. При использовании лассо, чем выше альфа-параметр, тем меньше объектов выбирается.
L1-восстановление и сжатие
Для правильного выбора альфа-канала лассо может полностью восстановить точный набор ненулевых переменных, используя только несколько наблюдений, при соблюдении определенных конкретных условий. В частности, количество выборок должно быть «достаточно большим», иначе модели L1 будут работать случайным образом, где «достаточно большое» зависит от количества ненулевых коэффициентов, логарифма количества функций, количества шума, наименьшее абсолютное значение ненулевых коэффициентов и структура матрицы плана X. Кроме того, матрица плана должна отображать определенные специфические свойства, такие как отсутствие слишком сильной корреляции.
Не существует общего правила выбора альфа-параметра для восстановления ненулевых коэффициентов. Его можно установить путем перекрестной проверки ( LassoCV или LassoLarsCV ), хотя это может привести к модели с недостаточным количеством штрафов: включение небольшого количества нерелевантных переменных не повлияет на оценку прогноза. BIC ( LassoLarsIC ), напротив, имеет тенденцию устанавливать высокие значения альфа.
Ссылка Ричард Г. Баранюк «Compressive Sensing», журнал IEEE Signal Processing Magazine [120] июль 2007 г. http://users.isr.ist.utl.pt/
1.13.4.2. Выбор функций на основе дерева
Оценщики на основе деревьев (см. sklearn.tree Модуль и лес деревьев в sklearn.ensemble модуле) могут использоваться для вычисления значимости свойств на основе примесей, которые, в свою очередь, могут использоваться для отбрасывания нерелевантных функций (в сочетании с SelectFromModel метатрансформатором):
1.13.5. Последовательный выбор функций
Последовательный выбор функций [sfs] (SFS) доступен в SequentialFeatureSelector трансформаторе. SFS может быть как вперед, так и назад:
Forward-SFS — это жадная процедура, которая итеративно находит лучшую новую функцию для добавления к набору выбранных функций. Конкретно, мы сначала начинаем с нулевой функции и находим одну функцию, которая максимизирует перекрестно проверенный балл, когда оценщик обучается на этой единственной функции. Как только эта первая функция выбрана, мы повторяем процедуру, добавляя новую функцию к набору выбранных функций. Процедура останавливается, когда достигается желаемое количество выбранных функций, как определено n_features_to_select параметром.
Backward-SFS следует той же идее, но работает в противоположном направлении: вместо того, чтобы начинать без функции и жадно добавлять функции, мы начинаем со всех функций и жадно удаляем функции из набора. В direction параметр управляет будь то вперед или назад SFS используется.
Как правило, прямой и обратный отбор не дают одинаковых результатов. Кроме того, один может быть намного быстрее другого в зависимости от запрошенного количества выбранных функций: если у нас есть 10 функций и мы запрашиваем 7 выбранных функций, для прямого выбора потребуется выполнить 7 итераций, а для обратного выбора потребуется выполнить только 3.
1.13.6. Выбор функции как часть конвейера
Выбор функций обычно используется как этап предварительной обработки перед фактическим обучением. Рекомендуемый способ сделать это в scikit-learn — использовать Pipeline :
В этом фрагменте мы используем LinearSVC сочетание с, SelectFromModel чтобы оценить важность функций и выбрать наиболее подходящие функции. Затем a RandomForestClassifier обучается на преобразованном выходе, т. е. с использованием только релевантных функций. Вы можете выполнять аналогичные операции с другими методами выбора функций, а также с классификаторами, которые, конечно же, предоставляют способ оценки важности функций. См. Pipeline примеры для более подробной информации.
Random Forest, метод главных компонент и оптимизация гиперпараметров: пример решения задачи классификации на Python
У специалистов по обработке и анализу данных есть множество средств для создания классификационных моделей. Один из самых популярных и надёжных методов разработки таких моделей заключается в использовании алгоритма «случайный лес» (Random Forest, RF). Для того чтобы попытаться улучшить показатели модели, построенной с использованием алгоритма RF, можно воспользоваться оптимизацией гиперпараметров модели (Hyperparameter Tuning, HT).

Кроме того, распространён подход, в соответствии с которым данные, перед их передачей в модель, обрабатывают с помощью метода главных компонент (Principal Component Analysis, PCA). Но стоит ли вообще этим пользоваться? Разве основная цель алгоритма RF заключается не в том, чтобы помочь аналитику интерпретировать важность признаков?
Да, применение алгоритма PCA может привести к небольшому усложнению интерпретации каждого «признака» при анализе «важности признаков» RF-модели. Однако алгоритм PCA производит уменьшение размерности пространства признаков, что может привести к уменьшению количества признаков, которые нужно обработать RF-моделью. Обратите внимание на то, что объёмность вычислений — это один из основных минусов алгоритма «случайный лес» (то есть — выполнение модели может занять немало времени). Применение алгоритма PCA может стать весьма важной частью моделирования, особенно в тех случаях, когда работают с сотнями или даже с тысячами признаков. В результате, если самое важное — это просто создать наиболее эффективную модель, и при этом можно пожертвовать точностью определения важности признаков, тогда PCA, вполне возможно, стоит попробовать.
Теперь — к делу. Мы будем работать с набором данных по раку груди — Scikit-learn «breast cancer». Мы создадим три модели и сравним их эффективность. А именно, речь идёт о следующих моделях:
1. Импорт данных
Для начала загрузим данные и создадим датафрейм Pandas. Так как мы пользуемся предварительно очищенным «игрушечным» набором данных из Scikit-learn, то после этого мы уже сможем приступить к процессу моделирования. Но даже при использовании подобных данных рекомендуется всегда начинать работу, проведя предварительный анализ данных с использованием следующих команд, применяемых к датафрейму ( df ):

Фрагмент датафрейма с данными по раку груди. Каждая строка содержит результаты наблюдений за пациентом. Последний столбец, cancer, содержит целевую переменную, которую мы пытаемся предсказать. 0 означает «отсутствие заболевания». 1 — «наличие заболевания»
2. Разделение набора данных на учебные и проверочные данные
Например, если есть миллионы строк, можно разделить набор, выделив 90% строк на учебные данные и 10% — на проверочные. Но исследуемый набор данных содержит лишь 569 строк. А это — не так уж и много для тренировки и проверки модели. В результате для того, чтобы быть справедливыми по отношению к учебным и проверочным данным, мы разделим набор на две равные части — 50% — учебные данные и 50% — проверочные. Мы устанавливаем stratify=y для обеспечения того, чтобы и в учебном, и в проверочном наборах данных присутствовало бы то же соотношение 0 и 1, что и в исходном наборе данных.
3. Масштабирование данных
Прежде чем приступать к моделированию, нужно выполнить «центровку» и «стандартизацию» данных путём их масштабирования. Масштабирование выполняется из-за того, что разные величины выражены в разных единицах измерения. Эта процедура позволяет организовать «честную схватку» между признаками при определении их важности. Кроме того, мы конвертируем y_train из типа данных Pandas Series в массив NumPy для того чтобы позже модель смогла бы работать с соответствующими целевыми показателями.
4. Обучение базовой модели (модель №1, RF)
Сейчас создадим модель №1. В ней, напомним, применяется только алгоритм Random Forest. Она использует все признаки и настроена с использованием значений, задаваемых по умолчанию (подробности об этих настройках можно найти в документации к sklearn.ensemble.RandomForestClassifier). Сначала инициализируем модель. После этого обучим её на масштабированных данных. Точность модели можно измерить на учебных данных:
Если нам интересно узнать о том, какие признаки являются самыми важными для RF-модели в деле предсказания рака груди, мы можем визуализировать и квантифицировать показатели важности признаков, обратившись к атрибуту feature_importances_ :
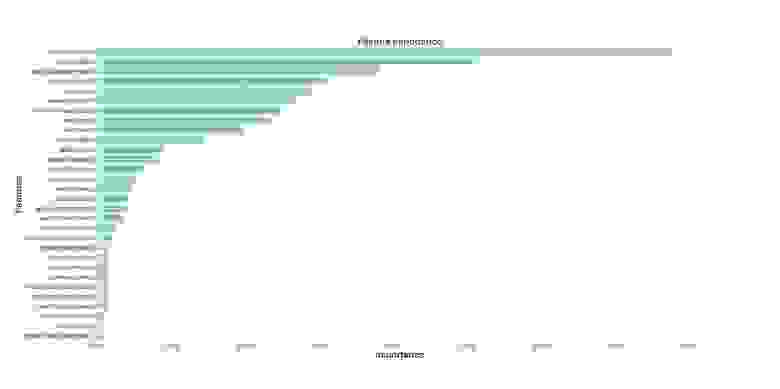
Визуализация «важности» признаков
Показатели важности признаков
5. Метод главных компонент

После того, как число используемых компонент превышает 10, рост их количества не очень сильно повышает объяснённую дисперсию
Этот датафрейм содержит такие показатели, как Cumulative Variance Ratio (кумулятивный размер объяснённой дисперсии данных) и Explained Variance Ratio (вклад каждой компоненты в общий объём объяснённой дисперсии)
Каждая компонента — это линейная комбинация исходных переменных с соответствующими «весами». Мы можем видеть эти «веса» для каждой компоненты, создав датафрейм.
Датафрейм со сведениями по компонентам
6. Обучение базовой RF-модели после применения к данным метода главных компонент (модель №2, RF + PCA)
Теперь мы можем передать в ещё одну базовую RF-модель данные X_train_scaled_pca и y_train и можем узнать о том, есть ли улучшения в точности предсказаний, выдаваемых моделью.
Модели сравним ниже.
7. Оптимизация гиперпараметров. Раунд 1: RandomizedSearchCV
После обработки данных с использованием метода главных компонент можно попытаться воспользоваться оптимизацией гиперпараметров модели для того чтобы улучшить качество предсказаний, выдаваемых RF-моделью. Гиперпараметры можно рассматривать как что-то вроде «настроек» модели. Настройки, которые отлично подходят для одного набора данных, для другого не подойдут — поэтому и нужно заниматься их оптимизацией.
Начать можно с алгоритма RandomizedSearchCV, который позволяет довольно грубо исследовать широкие диапазоны значений. Описания всех гиперпараметров для RF-моделей можно найти здесь.
Мы будем заниматься подбором следующих гиперпараметров:
Результаты работы алгоритма RandomizedSearchCV
Теперь создадим столбчатые графики, на которых, по оси Х, расположены значения гиперпараметров, а по оси Y — средние значения, показываемые моделями. Это позволит понять то, какие значения гиперпараметров, в среднем, лучше всего себя показывают.

Анализ значений гиперпараметров
Если проанализировать вышеприведённые графики, то можно заметить некоторые интересные вещи, говорящие о том, как, в среднем, каждое значение гиперпараметра влияет на модель.
8. Оптимизация гиперпараметров. Раунд 2: GridSearchCV (окончательная подготовка параметров для модели №3, RF + PCA + HT)
После применения алгоритма RandomizedSearchCV воспользуемся алгоритмом GridSearchCV для проведения более точного поиска наилучшей комбинации гиперпараметров. Здесь исследуются те же гиперпараметры, но теперь мы применяем более «обстоятельный» поиск их наилучшей комбинации. При использовании алгоритма GridSearchCV исследуется каждая комбинация гиперпараметров. Это требует гораздо больших вычислительных ресурсов, чем использование алгоритма RandomizedSearchCV, когда мы самостоятельно задаём число итераций поиска. Например, исследование 10 значений для каждого из 6 гиперпараметров с кросс-валидацией по 3 блокам потребует 10⁶ x 3, или 3000000 сеансов обучения модели. Именно поэтому мы и используем алгоритм GridSearchCV после того, как, применив RandomizedSearchCV, сузили диапазоны значений исследуемых параметров.
Итак, используя то, что мы выяснили с помощью RandomizedSearchCV, исследуем значения гиперпараметров, которые лучше всего себя показали:
Здесь мы применяем кросс-валидацию по 3 блокам для 540 (3 x 1 x 5 x 6 x 6 x 1) сеансов обучения модели, что даёт 1620 сеансов обучения модели. И уже теперь, после того, как мы воспользовались RandomizedSearchCV и GridSearchCV, мы можем обратиться к атрибуту best_params_ для того чтобы узнать о том, какие значения гиперпараметров позволяют модели наилучшим образом работать с исследуемым набором данных (эти значения можно видеть в нижней части предыдущего блока кода). Эти параметры используются при создании модели №3.
9. Оценка качества работы моделей на проверочных данных
Теперь можно оценить созданные модели на проверочных данных. А именно, речь идёт о тех трёх моделях, описанных в самом начале материала.
Проверим эти модели:
Создадим матрицы ошибок для моделей и узнаем о том, как хорошо каждая из них способна предсказывать рак груди:
Результаты работы трёх моделей
Здесь оценивается метрика «полнота» (recall). Дело в том, что мы имеем дело с диагнозом рака. Поэтому нас чрезвычайно интересует минимизация ложноотрицательных прогнозов, выдаваемых моделями.
Учитывая это, можно сделать вывод о том, что базовая RF-модель дала наилучшие результаты. Её показатель полноты составил 94.97%. В проверочном наборе данных была запись о 179 пациентах, у которых есть рак. Модель нашла 170 из них.
Итоги
Это исследование позволяет сделать важное наблюдение. Иногда RF-модель, в которой используется метод главных компонент и широкомасштабная оптимизация гиперпараметров, может работать не так хорошо, как самая обыкновенная модель со стандартными настройками. Но это — не повод для того, чтобы ограничивать себя лишь простейшими моделями. Не попробовав разные модели, нельзя сказать о том, какая из них покажет наилучший результат. А в случае с моделями, которые используются для предсказания наличия у пациентов рака, можно сказать, что чем лучше модель — тем больше жизней может быть спасено.
Уважаемые читатели! Какие задачи вы решаете, привлекая методы машинного обучения?
Feature importance — what’s in a name?


As data scientists we often focus on optimizing model performance. However, sometimes it is just as important to understand how the features in our model contribute to prediction. Unfortunately, the better performing models are also often the more opaque ones. Several methods exist to get some insight in these black box models. In this post I will discuss several feature importance methods, their interpretation, and point you to some useful resources if you need more details.
Why bother?
Before we unpack the concept ‘feature importance’, why is it even important to understand how a model works, especially if it performs well on a test set? In the real world excellent performance on a test set is just a nice start. A skeptical business manager, safety officer, or privacy compliance officer, might rightfully demand some insight into why our model is so successful.
In addition, some model biases are socially or legally unacceptable. For example, if your model works well in the real world because it implicitly profiles people based on ethnicity, you might run into conflict with your privacy compliance officer. Similarly, in the context of sensitive automated decision making the General Data Protection Regulation (GDPR) applicable in the EU stipulates the right to know what an automated decision was based on.
In short, if your model is designed to do something useful in the real world, invest some time in understanding how the features in your model contribute to model prediction.
Different types of feature importance
Now we know why it is important to understand our model’s predictions, we can start unpacking the what. Feature importance measures come in several forms.
One useful distinction is model-specific vs model-agnostic feature importance measures. As the name implies, model-agnostic feature importance measures can in principle be used for any model. Unfortunately implementations of these methods are often not completely general, so it is worth investigating in advance which importance measures are available for your model.
Another important distinction is global vs local feature importance. Local measures focus on the contribution of features for a specific prediction, whereas global measures take all predictions into account. The first relevant, for example, when we want to explain why a specific person was denied a loan from a loan assignment model.
In this post we will see examples of all four classes of feature importance: ensemble tree specific feature importance (local model-specific), permuted feature importance (global model-agnostic), LIME (local model-agnostic), and Shapley values (local model-agnostic).
Example
It is time to get our hands dirty with a concrete example. Suppose we want to classify images of breast tissue into benign and malignant. To train a model to do this we use the Wisconsin diagnosis breast cancer data available at the UCI machine learning repository. It includes diagnosis (benign vs malignant) as well as 30 descriptive cell features of 569 tissue samples. Since we are focusing on feature importance, we will train a single random forest model to keep things simple and observe its performance. In a more realistic setting using some sort of cross-validation scheme would be advisable given the small sample size.
Model training
To be able to focus on interpretation and keep this post uncluttered I have decided to only include output plots. However, I do encourage you to investigate this Jupyter notebook code hosted on Google Colab as you read along. The nice thing about Google Colab is that you can run the code even if you just have a browser available.
The notebook includes the installation of non-standard dependencies and should work out-of-the-box on Google Colab. After downloading the data and some minimal preprocessing we train a random forest model and observe a pretty good predictive capability in the test set: 99% area under the curve; 93% accuracy).

Model-specific feature importance
The first type of feature importance we compute is the one implemented by the random forest algorithm in scikit-learn. This is a tree-specific feature importance measure and computes the average reduction in impurity across all trees in the forest due to each feature. That is, features that tend to split nodes closer to the root of a tree will result in a larger importance value. When we plot the feature importance of all features below we see that the most important feature according to the built-in algorithm is maximum amount of concave points found within a tissue. Node splits based on this feature on average result in a large decrease of node impurity. The second most important feature is the standard deviation in concave points, which is by definition somewhat correlated with the first feature. After all large maximum values in number of concave points will result in larger standard deviations.

Permutation feature importance
A model-agnostic approach is permutation feature importance. The idea is simple: after evaluating the performance of your model, you permute the values of a feature of interest and reevaluate model performance. The observed mean decrease in performance — in our case area under the curve — indicates feature importance. This performance decrease can be compared on the test set as well as the training set. Only the latter will tell us something about generalizable feature importance.
For comparison with the tree-specific feature importance, we are computing feature importance on the training set. As you can see in the figure below, the differences with the previous plot are striking.

Although the top feature is the same in both methods (maximum number of concave points in a collection of cells), the second most important feature is now ‘maximum value in symmetry’ instead of ‘standard deviation in concave points’. Because maximum value and standard deviation of ‘number of concave points’ are correlated, suggesting that permutation feature importance is less likely to select two correlated top features. It more accurately reflects the added value of a feature given the presence of all other (possibly correlated) features in the model. In addition it focuses on our chosen measure of performance AUC instead of node impurity.
A second advantage of permutation is that it gives us a measure of uncertainty (95% confidence interval in the figure above) of the estimated feature importance. In our example we observe that only four of the thirty features have a significant feature importance. Note that this does not imply that only these four features are important for the model. Although non-significant features might not add much individually given the other features, removing multiple features is likely to decrease the AUC nonetheless. For example, two completely correlated important features individually contribute nothing given the other, but removing both can significantly decrease performance.
The main downside of permutation is that it can be computationally demanding if the number of features is large. Otherwise it is preferable over feature importance methods typically built into tree ensemble methods like random forests and gradient boosting. Permutation feature importance is model agnostic and can be evaluated on new data sets, and focuses on the performance measure of interest.
The two previous methods assess feature importance across individuals in a dataset. Local interpretable model-agnostic explanations (LIME) is a technique aiming to explain which features are most important in specific areas of the feature space. This can be used to assess for a specific subject which features contributed most to its prediction.
The main idea of LIME is to compute a local surrogate model. A surrogate model is an easily interpretable model such as a linear model or a decision tree trained to mimic the behavior of the more complex model of interest. In the case of LIME it fits such surrogate models locally. The procedure is as follows. For a specific prediction you want to explain, LIME slightly changes the values to create new data points that are similar. By feeding these perturbed data points to the complex model a relation between the the perturbed features and the model prediction emerges which is then captured by the surrogate model.
Below you see the output of LIME for the first subject in the test set. The fact that mean fractal dimension is larger than 0.16 seems to be major contributor in classifying this the tissue of this subject as malignant. Similarly the fact that mean compactness is larger than 0.03 actually decreased the likelihood of classifying this tissue as malignant. It is striking that maximum concave points is only the seventh feature.

Although we plotted all 30 features here, the LIME model is often restricted to just a few features since many model stakeholders prefer parsimonious explanations.
Instead of a game with players we can use the same payout mechanism for a machine learning model with features. The team score in this context is the performance measure of a (sub)model. The total payout is the difference between a base value — prediction of the null model — and an actual prediction. This difference is then divided over all features in accordance to their relative contribution.
Obviously looking at all possible subsets of features is computationally prohibitive in most realistic models with many features. Instead Shapley value approximations can be computed based on sampling. For Python the shap package has implemented Shapley values as well as a couple of (partly interactive) plots to explore Shapley values across different features and/or subjects.
The figure below shows the distribution of Shapley across subjects in the test set for each feature. Again it shows that maximum concave points is the most discriminative feature. The majority of subjects has a non-zero Shapley value. The sign shows whether the feature value moved the prediction toward malignant (positive SHAP) or benign (negative SHAP). The color reflects the order of magnitude of the feature values (low, medium, high). This way the plot immediately reveals that low (blue) values on the top ten features decrease the likelihood of a malignant tumor prediction.

The accompagnying notebook shows and explains some additional interactive plots that you may want to play with. For more information about all the plots implemented in the shap package you can read its documentation.
Conclusion
As we have seen there are many types of feature importance measures. Although many tree-based ensemble methods have conveniently implemented feature importance, be careful when interpreting them. They are biased towards the training set, typically do not focus on your performance measure of interest, and do not always reflect added value in case of correlated features. Permutation feature importance, if not computationally too demanding, can be a good alternative.
LIME and Shapley values are two local model-agnostic models. LIME’s strength is that it allows exploration of the feature space in specific neighbourhoods of interest. Shapley values are your best bet when you need to explain why specific predictions were made.
Note that although three of the four models discussed were model-agnostic in principle, their implementations in Python often are restricted to a (sometimes large) subset of models. Check out their respective documentation for more details.
There is much more to say about model feature importance and model interpretability. If you want to dive deeper, I highly recommend reading Christoff Molnar’s book Interpretable Machine Learning. It’s freely available on his GitHub page. This blogpost was largely inspired by his book.



