На страже безопасности: IBM QRadar SIEM
Современные киберпреступники при атаках систем защиты компаний используют все более изощренные методы. Чтобы противодействовать им, департаменты информационной безопасности вынуждены анализировать и интерпретировать огромное количество событий в день. Компания IBM для защиты от угроз сетевой безопасности предлагает решение IBM QRadar Security Intelligence Platform, которое предоставляет единую архитектуру для интегрирования информации о безопасности и управления событиями (SIEM) и журналами, определения аномальных ситуаций, анализа инцидентов, реагирования на них, управления настройками и устранения уязвимостей.

Единая архитектура QRadar Security Intelligence Platform позволяет анализировать журналы, сетевые потоки, пакеты, уязвимости, а также данные о пользователях и ресурсах. Использование Sense Analytics дает возможность проводить анализ корреляции для выявления наиболее серьезных угроз, атак и уязвимостей в реальном времени. Это дает возможность ИТ-отделам расставить приоритеты и выделять наиболее важные инциденты из огромного потока данных. Решение автоматически реагирует на инциденты и выполняет нормативные требования за счет возможностей сбора данных, определения их корреляции и составления отчетности. Также предусмотрен прогнозный анализ имеющихся рисков, вызванных некорректной настройкой устройств и известными уязвимостями.
Анализатор угроз
IBM QRadar Security Intelligence Platform включает в себя целый ряд различных модулей. Одним из ключевых компонентов решения является инструмент IBM QRadar SIEM – система сбора и анализа событий. Он консолидирует информацию из журналов событий, поступающую от устройств, конечных точек и приложений в сети. QRadar SIEM нормализует и анализирует корреляцию для выявления угроз безопасности, а также использует передовой механизм Sense Analytics для выявления нормального поведения, обнаружения аномалий, раскрытия передовых угроз и удаления ложноположительных результатов. Этот программный модуль дает возможность собрать все связанные события в один инцидент. QRadar SIEM может включать в себя средства анализа угроз IBM X-Force Threat Intelligence со списком потенциально вредоносных IP-адресов, адресов компьютеров с вредоносным ПО, источников спама и других угроз, что позволяет внедрить упреждающий подход к обеспечению безопасности. Кроме того, для определения приоритетов продукт умеет сопоставлять угрозы для систем с событиями и данными из сети.
Возможность создавать подробные отчеты по доступу к данным и действиям пользователей обеспечивает более эффективное управление угрозами и соответствие стандартам. Стоит также упомянуть, что QRadar SIEM можно использовать в локальных и облачных средах.
Кроме того, стоит отметить, что в ближайшее время IBM планирует использовать платформу искусственного интеллекта Watson в сфере безопасности, интегрировав ее с программным обеспечением QRadar и базой данных X-Force. Это позволит повысить уровень аналитики для определения характера угроз, а также компенсировать нехватку ИТ-персонала в сфере информационной безопасности.
Вопросы функциональности
Рассмотрим указанные выше возможности IBM QRadar SIEM более детально. Обеспечение прозрачности в реальном времени позволяет обнаружить неправильное использование приложений, внутреннее мошенничество и небольшие угрозы, которые можно было бы упустить из виду среди миллионов событий, происходящих ежедневно. Решение позволяет обеспечить сбор журналов и событий из различных источников, включая устройства безопасности, операционные системы, приложения, базы данных и системы управления доступом и идентификацией. Данные сетевых потоков поступают от коммутаторов и маршрутизаторов, включая данные уровня 7 (уровень приложений). Предусмотрено получение информации от систем управления доступом и идентификацией и таких служб инфраструктуры, как протокол динамической настройки узла (DHCP), а также от сканеров уязвимости в сети и приложениях.
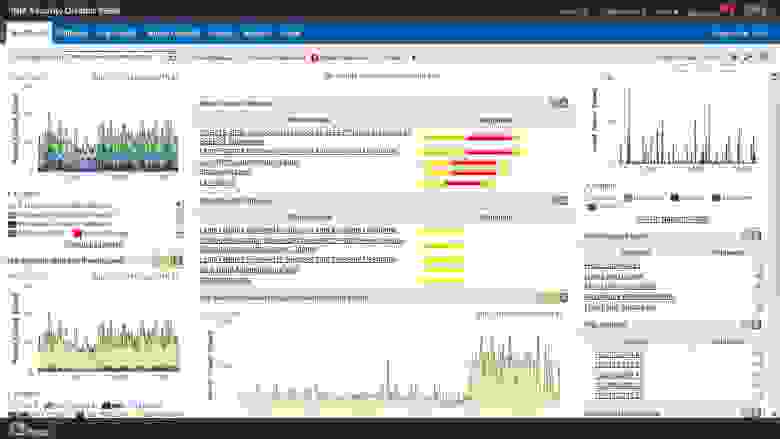
На Dashboard-панель IBM QRadar SIEM можно вывести все необходимые отчеты и графики
QRadar SIEM выполняет мгновенную нормализацию событий и сопоставление с другими данными для обнаружения угроз и создания нормативных отчетов. Решение определяет приоритеты событий, выделяя небольшое количество реальных нарушений, несущих наиболее серьезную угрозу для бизнеса. Обнаруженные аномалии дают возможность выявить изменения в поведении, связанные с приложениями, компьютерам, пользователями и сегментами сети. При использовании ПО IBM X-Force Threat Intelligence также определяются действия, связанные с подозрительными IP-адресами.
Решение дает возможность более эффективно управлять угрозами, отслеживая серьезные инциденты и предоставляя ссылки на все требуемые данные для проведения анализа. Это позволяет обнаружить действия в нерабочее время или необычное использование приложений и облачных сервисов, а также сетевую активность, не соответствующую сохраненным шаблонам использования. Для улучшения аналитики QRadar SIEM поддерживает возможность поиска в событиях и потоках данных в режиме, близком к реальному времени, а также по сохраненным данным. Возможно выполнение объединенного поиска в больших распределенных средах. Для более глубокого понимания и лучшего отображения приложений, баз данных, продуктов для совместной работы и социальных сетей можно использовать устройства IBM QRadar QFlow и IBM QRadar VFlow Collector, которые позволяют проводить детальный анализ сетевых потоков на уровне 7.
Возможность установки в облаке SoftLayer позволяет QRadar SIEM получать оперативную информацию о безопасности в облачных средах. Причем сбор событий и потоков данных от приложений выполняется как в облаке, так и на локальных ресурсах.
Решение имеет интуитивно понятный модуль отчетов, не требующий специальных баз данных или особых навыков от ИТ-администраторов. Создание отчетов о доступе к данным и активности пользователей с возможностью отслеживания информации по имени и IP-адресу гарантирует соблюдение политик безопасности, а также соответствие нормативным требованиям.
Сопутствующие компоненты
С инструментом QRadar SIEM интегрируется ряд модулей, повышающих его эффективность. Одним из наиболее важных является QRadar Risk Manager, который сопоставляет информацию об уязвимостях с данными о топологии сети и соединениях. Решение выявляет уязвимости в сети компании и работающих в ней приложениях, оценив риски и минимизировав их. Risk Manager отслеживает конфигурацию коммутаторов, маршрутизаторов, сетевых экранов и систем предотвращения вторжений (IPS), распознавая условия, представляющие угрозу безопасности. Кроме того, он позволяет моделировать сетевые атаки и другие сценарии вторжений, внося в конфигурацию сети изменения, которые дают возможность оценить масштаб угрозы.
Еще один интересный инструмент – модуль QRadar Log Manager. Он собирает и обрабатывает данные о событиях в режиме реального времени, поступающие от маршрутизаторов, коммутаторов, брандмауэров, сетей VPN, систем обнаружения и предотвращения вторжений (IDS/IPS), антивирусных программ и других источников. Log Manager дает возможность упростить ведение необходимой отчетности и контроль за соблюдением нормативно-правовых требований.
Чем полезна SIEM-система и как её внедрить?
Содержание
Компания «Пирит», российский системный интегратор и поставщик корпоративных ИТ-решений, приступила к активному развитию направления информационной безопасности (ИБ).
Не секрет, что в современном мире количество различных угроз и негативных воздействий на корпоративную инфраструктуру постоянно растет. Цена ошибки может очень дорого стоить, поэтому компаниям критически важно вовремя выявлять слабые места и оперативно реагировать на угрозы.

Как проанализировать угрозы информационной безопасности
Ключевым элементом для анализа состояния информационной безопасности компании является система SIEM (Security information and event management). Она подобно радару может заблаговременно обнаруживать атаки и слабые места в контуре защиты информационной инфраструктуры, что очень важно для немедленного реагирования на критические инциденты.
Компания «Пирит» для своих проектов выбрала SIEM-решение IBM QRadar. Оно, по мнению исследовательской компании Gartner, является одним из лидеров среди систем подобного класса.
IBM QRadar осуществляет сбор журналов и иных данных с различных компонентов ИТ-инфраструктуры: пользовательских устройств, серверов, сетевого оборудования, а также со средств обеспечения информационной безопасности – антивирусов, межсетевых экранов, систем предотвращения вторжений. Система централизованно анализирует собранные данные для выявления аномалий и оперативного реагирования на них.
QRadar позволяет выявлять корреляции между событиями, полученными из различных источников, отслеживать и анализировать ход атак на сеть компании. Детальная информация об атаке помогает специалистам по информационной безопасности оперативно принимать решения о необходимых действиях.
Для каких компаний предназначены SIEM-системы
Исторически основными потребителями SIEM-систем был финансовый сектор и телекоммуникационные компании, что было связано, прежде всего, с наличием развитых нормативов контроля за информационной безопасностью. Вместе с тем, в последнее время, потребность в подобных решениях растет и в других областях.
Однако, здесь стоит обратить внимание на один важный момент. Для успешного внедрения и использования SIEM-системы компания-заказчик должна обладать определенным уровнем зрелости в сфере ИБ с наличием профильного отдела и пониманием модели угроз, свойственной для своей сферы деятельности.
Можно ли ознакомиться с работой системы до внедрения
Компания «Пирит» предлагает заказчикам смоделировать различные варианты событий информационной безопасности и самостоятельно провести настройку системы с помощью демо-стенда Qradar. Если заказчик указывает на какой-либо приоритет, например, комплексную оценку рисков, то демо-стенд может быть легко сконфигурирован под эту задачу.
Модульный принцип решения позволяет также запускать расширения партнеров IBM: Cisco, Palo Alto Networks, Fortinet, Trend Micro, CheckPoint и многих других.
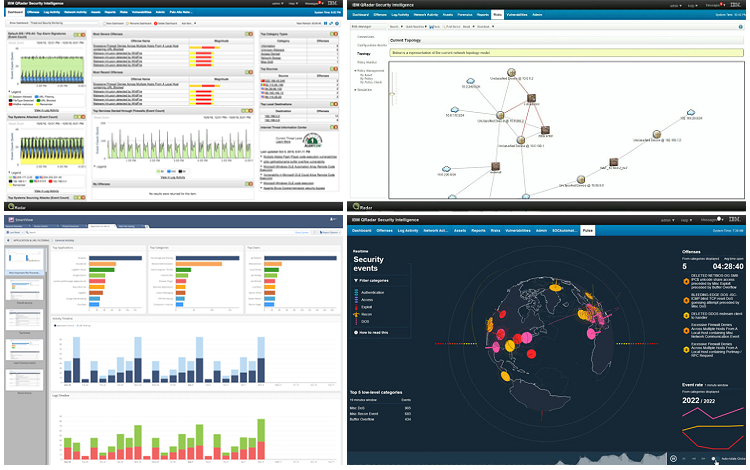
Принцип работы демо-стенда прост. Информационные системы и аппаратные решения заказчика постоянно генерируют определенные события информационной безопасности. Весь этот поток направляется на Qradar, в результате чего заказчик видит какие действия, взаимосвязи и триггеры можно настроить и какую полезную информацию получить.
Кроме того, специалисты «Пирит» проводят пилотные внедрения, где заказчик на элементах своей инфраструктуры может посмотреть систему в работе, понять какие события ИБ поступают в систему и принять решения о её дальнейшем использовании.
В какие сроки может быть внедрено решение и сколько это может стоить
Сроки внедрения существенным образом зависят от масштаба проекта, а точнее от количества источников, топологии и набора функциональности. Простая установка и подключение источников с набором базовых правил силами подготовленного специалиста делается в считанные дни. Серьезные большие проекты с обязательной стадией проектирования, затрагивающей доработку модели угроз, могут занимать несколько месяцев.
Что касается стоимости, то она рассчитывается из расчета количества событий информационной безопасности в секунду и стоимости базовых лицензий.
В таблице ниже приведено ориентировочное количество событий в секунду от стандартных элементов ИТ-инфраструктуры (значения приведены с 20% запасом).
Примерно такое количество событий в секунду поставляет каждый соответствующий компонент в ИТ-инфраструктуре заказчика. Следовательно, для определения общего количества событий необходимо умножить эти значения на количество соответствующих элементов и все сложить.
Далее для бюджетной оценки можно использовать следующую таблицу:
| Описание | Стоимость |
| Базовая лицензия, включает 100 событий и 15000 сетевых потоков, в том числе техническая поддержка на оборудование и ПО в течении 12 месяцев | $11 128,00 |
| Расширение на 100 событий в секунду, с поддержкой на 12 месяцев | $9 309,00 |
| Возможность получения в качестве виртуального сервера, с поддержкой на 12 месяцев | $1 017,00 |
И в зависимости от количества событий, которое мы получили на первом этапе, уже считаем количество необходимых лицензий.
К примеру, для базовой инфраструктуры из 100 рабочих станций, 1 Active Directory, 1 Exchange, 5 Windows Server, 1 антивируса, 2 коммутаторов, 1 прокси-сервера, получаем:
100×0,5 + 1×15 + 1×10 + 5×2 + 1×20 + 2×0,25 + 1×25 = 120,5 EPS
В любом случае, для точных расчетов лучше обращаться к авторизованным партнерам компании IBM, таким как компания «Пирит». Они помогут точно оценить затраты, подсказать возможности для оптимизации и рассчитать требуемые работы.
Требуется ли поддержка интегратора после внедрения
Система не требует специальных знаний и опыта программирования для ее развития и поддержки. Большинство эксплуатационных задач заказчик может решить самостоятельно с помощью удобного графического интерфейса.
Безусловно, определенного навыка потребует раздел управления правилами обработки событий, основанный на регулярных выражениях, однако, в целом, система очень дружелюбна и позволяет быстро овладевать необходимыми знаниями для работы с ней.
Кроме того, в ходе внедрения готовится документация пользователя и администратора, в которой отражаются особенности настройки сбора данных, возможности изменения событий и их дальнейшей обработки.
Внедрение SIEM – что нужно знать про него?
Многие уже слышали про системы класса SIM и про системы класса SEM, а что же тогда такое SIEM?
SIEM это Security Information and Event Management
Изначально, Security Information Management (SIM) и Security Event Management (SEM) были двумя различными технологиями, используемыми вместе.
В далеком 2005 году Gartner ввел понятие SIEM, чтобы охватить обе технологии.
Если погуглить отзывы по различным системам то можно получить огромное количество отзывов о каждом продукте, зачастую противоположных друг другу, что лишний раз подчеркивает необходимость понимания задач, которые ставятся перед SIEM, и уровнем квалификации тех сотрудников, которым предстоит с ним работать.
Моя основная работа связана с 3-мя такими решениями, каждый из которых имеет свои плюсы и минусы. Сравнивать демо-версии продуктов и сравнивать их после долгого использования это 2 большие разницы. Далее я попытаюсь определить основные вещи, которые вы должны знать и понимать, когда вы планируете внедрение SIEM у себя в компании.
Надеюсь, этот пост поможет вам в получении четкого представления идеи и технологиях SIEM. Я работаю с HP ArcSight, IBM QRadar и McAfee SIEM, больше всего нравится ArcSight. Если у вас есть идейные вопросы про SIEM или конкретно про ArcSight – прошу в комментариях их высказывать. В дальнейшем планирую развивать тему SIEM в части идей для правил корреляций и векторов атак, сравнения функциональных фишек продуктов и т.д.
Борьба за производительность или кто отнимал процессорное время
Началось все с «Неваляшки». О том, что это такое и для чего это было надо описано тут: http://habrahabr.ru/company/oktell/blog/108726/. То есть, мы имели четыре работающих сервера call-центра, одинаково настроенных и с примерно одинаковой конфигурацией внешних и внутренних линий, пользователей и настройкой внутренней БД. На каждый из серверов со стороны оператора связи поступала равномерная звонковая нагрузка, но сервера реагировали на это по разному!
N Конфигурация сервера и операционная система
1 T1300 @ 1.66 1 Гб ОЗУ, Windows 2003 Standard Ed. R2 SP1 32 bit
2 Intel Core Duo E8400 @ 3000 4 Гб ОЗУ, Windows 2003 Standard Ed.SP1 32 bit
3 Intel Pentium 4 3GHz 2 Гб ОЗУ, Windows 2003 Standard Ed. SP2 32 bit
4 E3400 @ 2.60 2 Гб ОЗУ, Windows 2003 Standard Ed. R2 SP2 32 bit
Столкнулись с жалобами на качество связи. Причем, жаловались не на каждый звонок, а на «некоторые». Жаловались на «кваки», очень характерные для VoIP телефонии. Довольно оперативно было выяснено, что причиной появления «кваков» было непредсказуемый рост занятости процессора на одном (первом) из серверов call-центр при возрастании нагрузки. И это при всем притом, что другие сервера такой нагрузки вообще не замечали, и никакого роста нагрузки на процессор при таком же количестве вызовов не наблюдалось. Даже, несмотря на то, что первый сервер был значительно слабее всех остальных, такой картины — роста занятости процессора до 100% — наблюдаться не должно было.
Не стоит, наверное, говорить, что мы прошли стандартный путь «протирки фар», «пинания колес» и пр. В конечном итоге пришли к мнению, что ни настройки самого call-центр, ни его СУБД, на поведение сервера не влияет. Отправной точкой для понимания сущности проблемы послужил тот факт, что в диспетчере задач в списке процессов ни один из процессов не занимал процессорного времени, вместе с тем, на мониторинге быстродействия хронология загрузки процессора показывала непрерывную загрузку процессора ядра на уровне 20%.
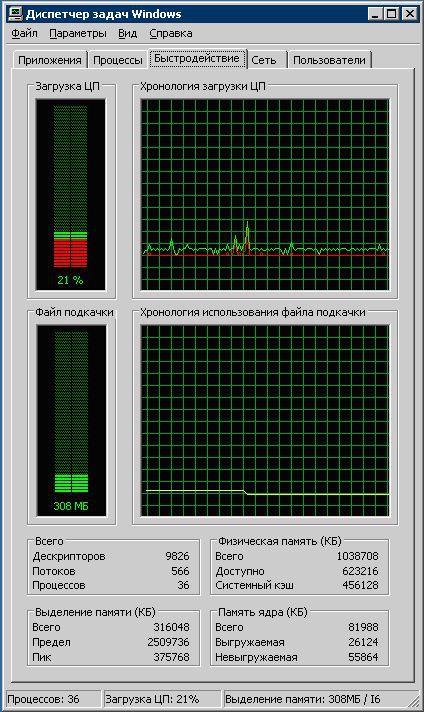

Задались целью получить ответ на вопрос чем же занято ядро в том случае, когда нагрузки на все остальные сервисы отсутствуют. Process Explorer — штатная утилита от Microsoft — подсказала, что основным потребителем ресурсов является «Hardware Interrupts». Для дальнейшего анализа причин такого потребления была скачана другая штатная утилита от Microsoft — «Kernrate View». Как и было описано в рекомендациях по использованию, в командной строке выполнили «C:\Program Files\KrView\Kernrates\Kernrate_i386_XP.exe >> log.txt» и, спустя некоторое время, нажав Ctrl-C, остановили. Получили файл log.txt, содержащий информацию вида:
/==============================\
\==============================/
Date: 2010/12/08 Time: 1:09:14
Machine Name: RESERVCC
Number of Processors: 1
PROCESSOR_ARCHITECTURE: x86
PROCESSOR_LEVEL: 6
PROCESSOR_REVISION: 0e08
Physical Memory: 1015 MB
Pagefile Total: 2450 MB
Virtual Total: 2047 MB
PageFile1: \??\C:\pagefile.sys, 1524MB
OS Version: 5.2 Build 3790 Service-Pack: 1.0
WinDir: C:\WINDOWS
Kernrate User-Specified Command Line:
Kernrate_i386_XP.exe
Kernel Profile (PID = 0): Source= Time,
Using Kernrate Default Rate of 25000 events/hit
P0 K 0:00:36.671 (28.5%) U 0:00:09.671 ( 7.5%) I 0:01:22.343 (64.0%) DPC 0:00:29.484 (22.9%) Interrupt 0:00:00.281 ( 0.2%)
Interrupts= 136809, Interrupt Rate= 1063/sec.
Total Profile Time = 128687 msec
Total Avg. Rate
Context Switches, 609407, 4736/sec.
System Calls, 5078088, 39461/sec.
Page Faults, 119817, 931/sec.
I/O Read Operations, 11671, 91/sec.
I/O Write Operations, 209479, 1628/sec.
I/O Other Operations, 229216, 1781/sec.
I/O Read Bytes, 39981700, 3426/ I/O
I/O Write Bytes, 19240135, 92/ I/O
I/O Other Bytes, 7130204725, 31107/ I/O
— Results for Kernel Mode:
— OutputResults: KernelModuleCount = 99
Percentage in the following table is based on the Total Hits for the Kernel
Time 44651 hits, 25000 events per hit — Module Hits msec %Total Events/Sec
intelppm 27457 128685 61 % 5334149
hal 12284 128685 27 % 2386447
ntkrnlpa 2868 128685 6 % 557174
win32k 525 128685 1 % 101993
alder9xp 427 128685 0 % 82954
tcpip 254 128685 0 % 49345
Ntfs 251 128685 0 % 48762
afd 120 128685 0 % 23312
RDPDD 109 128685 0 % 21175
e1e5132 109 128685 0 % 21175
iaStor 97 128685 0 % 18844
NDIS 39 128685 0 % 7576
RDPWD 31 128685 0 % 6022
fltMgr 26 128685 0 % 5051
amon 12 128685 0 % 2331
termdd 10 128685 0 % 1942
CLASSPNP 10 128685 0 % 1942
ftdisk 7 128685 0 % 1359
ipsec 3 128685 0 % 582
Npfs 2 128685 0 % 388
USBPORT 2 128685 0 % 388
volsnap 2 128685 0 % 388
TDTCP 1 128685 0 % 194
rdbss 1 128685 0 % 194
ws2ifsl 1 128685 0 % 194
netbt 1 128685 0 % 194
watchdog 1 128685 0 % 194
PartMgr 1 128685 0 % 194
Далее определяем какой именно драйвер загружает процесс «Hardware Interrupts». В списке лога «Kernrate View» он будет верхним, и рядом в процентах будет показана его доля занимания ядра. Тут стоит обратить внимание, что проценты показывают не общий процент от загрузки системы, а процент загрузки серверного ядра драйверами.
Определили, что этим драйвером является Intelppm (Intel processor power manager). Дальше — google нам в помощь. Интернет велик, могуч и безграничен. Довольно быстро поняли, что проблема с Intelppm возникает, не так уж и часто, вместе с тем, мы были не одни столкнувшиеся с такой бедой. Результат не замедлил себя обнаружить, нашлась статья, в которой не только описывается сама проблема, но и обозначается путь ее решения (Постоянный адрес оригинала статьи тут: http://www.osp.ru/text/print/302/5818429.html)
Далее следуя рекомендациям Стивена Догерти понимаем, что intelppm, является драйвером управления электропитанием процессора, который не нужен на сервере, где питание от аккумулятора и не используется вовсе. Вариантов решений было предложено несколько: переустановка, обновление или остановка неисправного драйвера. Какой варианты выберете вы — смотрите сами, вполне логично тут следовать оригинальным рекомендациям Догерти.
Мы полезли в реестр. Данные драйвера процессора Intel находятся в разделе реестра HKEY_LOCAL_MACHINE/SYSTEM/Current Control Set/Services/intelppm. Для отключения драевера intelppm изменили значение параметра Start с 1 на 4. Специалисты Microsoft, конечно, рекомендуют делать резервную копию реестра, но мы то с вами русские люди, да и что там один параметр поменять с 1 на 4. 
Рестарт помог убедиться, что загрузка процессора в среднем находится в пределах 60-70% даже при полной(!) загрузке сервера call-центр звонками.
Очень интересно выглядит при этом диспетчер устройств: 
Жалуется, ябедничает, плачет: «Драйвер для этого устройства был отключен. Возможно, необходимые функции исполняет другой драйвер. (Код 32), Нажмите кнопку „Диагностика“, чтобы запустить мастер диагностики для данного устройства.» Но на безопасность полетов это уже не влияет 😉
JSOC: как готовить инциденты
Коллеги, добрый день.
Мы чуть затянули с выпуском нашей очередной статьи. Но тем не менее она готова и я хочу представить статью нашего нового аналитика и автора — Алексея Павлова — avpavlov.
В этой статье мы рассмотрим наиболее важный аспект «жизнедеятельности» любого Security Operation Center – выявление и оперативный анализ возникающих угроз информационной безопасности. Мы расскажем, каким образом происходит настройка правил, а также выявление и регистрация инцидентов в нашем аутсорсинговом центре мониторинга и реагирования JSOC.
О том, как работает JSOC, мы говорили в наших предыдущих статьях:
JSOC: как измерить доступность Security Operation Center?
В них, в том числе, упоминалось, что ядром JSOC является SIEM-система HP ArcSight ESM. В этой статье мы сконцентрируемся на описании ее настроек и доработок, которые были реализованы для уменьшения количества false-positive-событий, оперативного подключения новых систем и СЗИ, а также увеличения скорости и повышения прозрачности процесса разбора потенциальных инцидентов для наших заказчиков.
Любая SIEM имеет «из коробки» набор предустановленных корреляционных правил, которые, сопоставляя события от источников, могут оповестить клиента о возникшей угрозе. Зачем же тогда нужна дорогостоящая настройка этой системы, а также ее поддержка силами интегратора и собственного аналитика?
Для ответа на этот вопрос необходимо рассказать, как устроен жизненный цикл событий, попадающих в JSOC из источников, каков путь от срабатывания правила до создания инцидента.
Первичная обработка событий происходит на коннекторах SIEM-системы. Обработка включает в себя фильтрацию, категоризацию, приоритизацию, агрегирование и нормализацию. Далее событие в формате CEF (Common Event Format) отправляется в ядро системы HP ArcSight, где происходят его корреляция и визуализация. Это стандартные механизмы работы с событием любой SIEM. В рамках JSOC мы доработали их, чтобы расширить возможности по мониторингу инцидентов и получению информации о конечных системах.
Фильтрация и категоризация
Одними из основных функций SIEM являются фильтрация и категоризация событий, которые происходят на коннекторах. В среднестатистической SIEM-системе нормальным потоком событий считается 6000–8000 EPS (Event per Second), при этом количество типов событий с 50–80 источников исчисляется тысячами. Для удобства обработки такого объема информации и были придуманы категории событий.
Отметим, что на оборудовании и в системах различных вендоров одинаковые события зачастую называются по-разному. Например, начало сессии в рамках подключения по протоколу TCP у Cisco имеет название «Built inbound TCP connection», у Juniper – «session created», а у Checkpoint это два события: в зависимости от успешности подключения – «accept» или «block». Во избежание модификации корреляционных правил «под нового вендора» при появлении устройств были введены категории событий, определяющие совершаемое действие.
Пример: событие с межсетевого экрана Juniper – «session start»
Category Significance: /Informational – тип сообщения – информационное
Category Device Type: Firewall – событие с фаервола
Category Behavior: /Access/Start – открытие сессии
Category Outcome: /Success – успешное
Таким образом, если нам необходимо отслеживать события успешного доступа со всех устройств в корреляционном правиле, мы просто указываем Category Behavior: /Access/Start, Category Device Type: Firewall, Category Outcome: /Success.
Помимо типовой категоризации в рамках JSOC, мы реализовали дополнительную, чтобы минимизировать возможные изменения в правилах, генерирующих инциденты. Эти правила работают для разных заказчиков, и изменение параметров под одного из них может привести к временной и\или полной неработоспособности решения для всех.
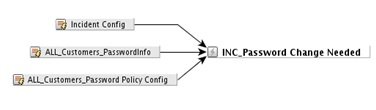
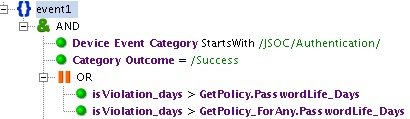
Рис. 1. Категоризация событий на примере правила «INC_Password Change Needed»
В качестве примера приведем правило «INC_Password Change Needed». Его основная задача – оповещать, если произошла аутентификация в системе под учетной записью с просроченным паролем. Период вычисляется по корпоративным правилам и разнится в зависимости от заказчика. В данном правиле используются категоризация JSOC «Device Event Category starts with /JSOC/Authentication/», которая включает в себя все события аутентификации с различных источников, и стандартная категоризация «HP Arcsight – Category Outcome =/Success» – успешное событие подключения.
Базовые и профилирующие правила
Для обработки отдельных типов событий, попадающих в ядро системы, в JSOC введены специальные профилирующие и базовые правила. Профилирующие правила для самых разных активностей играют одну из важнейших ролей. Они формируют первичные данные, записываемые в active list и в дальнейшем используемые при расчетах средних, максимальных и флуктуационных показателей. К таким правилам относятся данные по аутентификации, доступу к ресурсам, ежедневному трафику, белым спискам IP-адресов для доступа к ключевым системам и др. После того как типовые профили активностей заполнены, мы можем создать правила, которые будут фиксировать отклонение от нормальной активности.
Базовые правила хотелось бы выделить отдельным пунктом. Добавление недостающей информации в события – имени пользователя в события с файерволов, информации о владельце учетной записи из кадровой системы, дополнительное описание хостов из CMDB – реализовано в JSOC для ускорения процесса разбора инцидентов и получения всей необходимой информации в одном событии.
Ярким примером использования базовых правил является «CISCO_VPN_User Session Started». Это правило позволяет связать IP-адрес сотрудника, подключающегося по VPN, с его именем пользователя (данная информация находится в разных событиях, приходящих с Cisco ASA).
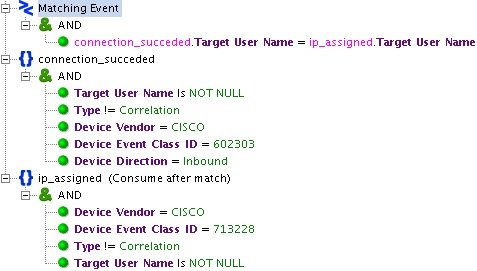
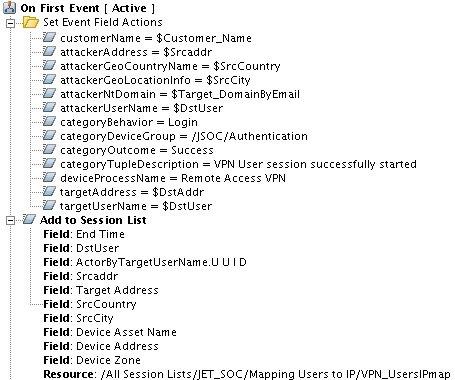
Рис. 2. Пример настроек базового правила
Создание и настройка корреляционных правил
Самый простой способ использования корреляционных правил – срабатывание по возникновению единичного события с источника. Это прекрасно работает, если SIEM-система используется в связке с настроенными СЗИ.
При остановке критичной службы на отслеживаемом сервере происходит срабатывание правила «INC_Critical Service Stopped». Это событие может говорить о злонамеренных действиях пользователя или вредоносного ПО. Но большинство направленных атак на компанию, а также внутренних инцидентов невозможно идентифицировать по одиночному событию.
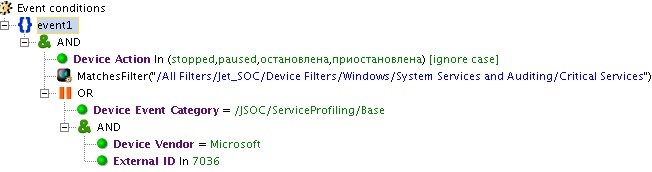
Рис. 3. Пример срабатывания правила на одиночное событие с источника
Второй способ – срабатывание корреляционных правил по нескольким последовательным событиям за период – идеально ложится в инфраструктурную безопасность.
Вход под одной учетной записью на рабочую станцию и дальнейший вход в целевую систему под другой (или такой же сценарий с VPN и информационной системой) говорит о возможней краже данных учетных записей. Подобная потенциальная угроза встречается часто, особенно в повседневной работе администраторов (domain: a.andronov, Database: oracle_admin), и вызывает большое количество ложных срабатываний, поэтому требуются создание «белых списков» и дополнительное профилирование.

Рис. 4. Пример срабатывания правила на последовательность событий с нескольких источников
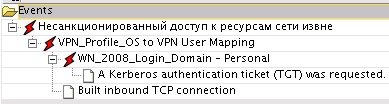
Рис. 5. Пример сопоставления событий по инциденту «несанкционированный доступ к ресурсам извне»
Третий способ настройки правил отлично подходит для выявления различных сканирований, брутфорса, эпидемий, а также DDoS.
Большое количество неуспешных попыток входа в систему может говорить о брутфорс-атаке. Правило «BF_INC_SSH_Dictionary Attack» настроено на отслеживание 20 неуспешных попыток логина на Unix-системы.
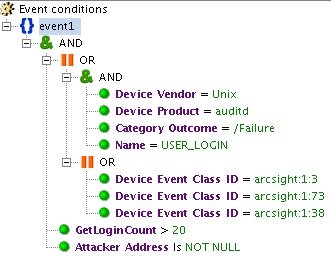
Рис. 6. Пример срабатывания правила на определенное количество событий одного типа
Наиболее сложный, в то же время эффективный и универсальный способ регистрации аномальных активностей – использование профилей.
В качестве примера можно привести корреляционное правило «INC_AV_Virus Anomaly Activity», которое отслеживает превышение среднего показателя срабатываний антивируса (вычисляется на основании профиля) за определенный период.
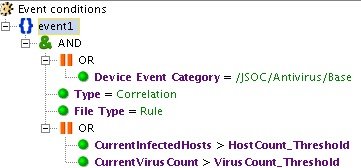
Рис. 7. Пример срабатывания правила по превышению среднего показателя



