Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
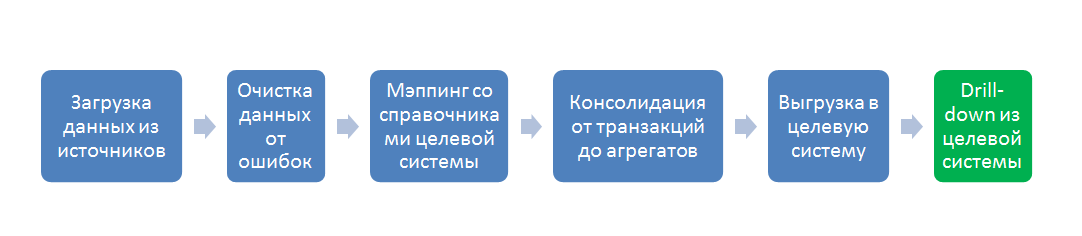
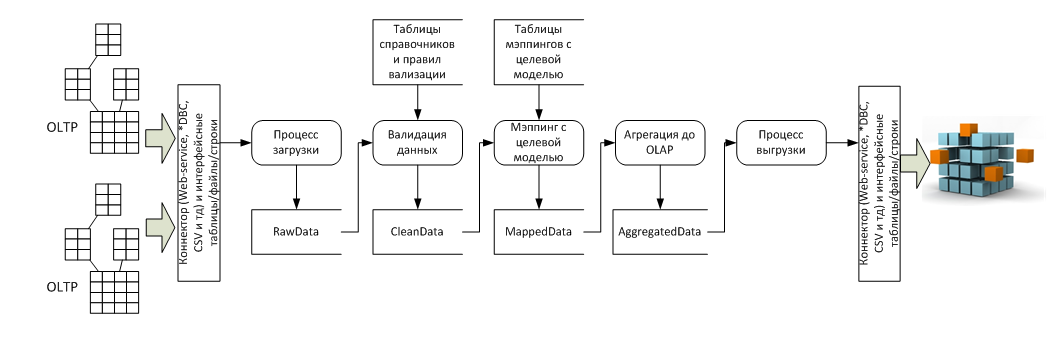
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
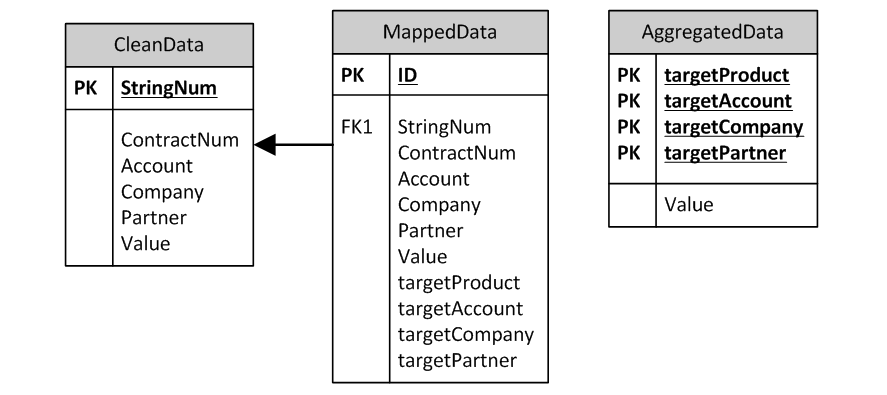
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
7 ошибок ETL-разработчика
Проекты хранилищ данных уже давно являются частью IT-инфраструктуры большинства крупных предприятий. Процессы ETL являются частью этих проектов, однако разработчики иногда совершают одни и те же ошибки при проектировании и сопровождении этих процессов. Некоторые из этих ошибок описаны в этом посте.
Я хотел бы сразу сузить рамки обсуждения и договориться о терминологии:
В целом, суть большинства ошибок ETL-разработчика можно объяснить игнорированием жизненного правила с этой картинки.

В дальнейшем будут использованы примеры для DWH на базе Oracle 11g. Итак приступим.
1. Использование системной даты (или аналогичной функции) в бизнес-логике
Одна из самых простых и частых ошибок, особенно у неопытных разработчиков. Допустим есть бизнес-правило: во время «ночного окна для загрузки» выгружать заказы, которые были закрыты за этот день (по полю close_date). Результатом иногда бывает примерно такой sql statement:
insert into target_table
select from orders
where close_date >= sysdate() — 1
Даже если забыть про то, что sysdate() может содержать не только дату, но и время, то у нас с этим скриптом возникают проблемы в тот момент, когда регулярная работа ETL процесса нарушается по вполне банальным причинам (исходная система апгрейдится на новую версию, пропала связь с исходной системой, из-за нового процесса ETL закончилось место во временном tablespace и т.д.). Т.е. в тот момент когда наш ETL процесс нужно по каким-то причинам перезапустить или же приостановить на время и потом снова запустить. Также может произойти нечто интересное, если по какой-то причине этот процесс запустят дважды за день.
Решение у этой ошибки обычно простое: параметризовать вызов данного процесса, и если нужно, то использовать sysdate() как дефолтное значение с возможностью переопределения. Хотя использование поля типа datetime для обработки дельты с точки зрения сопровождения ХД не очень оптимально, и вместо него лучше применить дельту по некоему дискретному полю (например целочисленный id сессии загрузки или нечто подобное)
2. Профилирование данных не было сделано перед началом разработки
Даже самая документированная и разработанная по всем правилам и методикам исходная система обычно содержит в себе некорректные или неконсистентные данные, несмотря на многочисленные уверения ее разработчиков или команды поддержки. И полагаться на уверения в правильности с той стороны баррикад, обычно чревато проблемами в конце разработки. Любой источник данных (таблица, файл, xml, json и т.д.) должен быть проверен на соответствие логической модели DWH. Существуют различные инструменты для профилирования данных, как встроенные в ETL инструменты, так и независимые от них. Перечислю наиболее востребованные проверки:
Проверка #1: Уникальность идентификаторов и натуральных ключей исходных данных
Различие между идентификатором и натуральным ключом состоит в том, что идентификатор — это обычно некое суррогатное значение, которое технически идентифицирует строку, а натуральный ключ — это значение или комбинация значений, которые имеют бизнес-смысл.
Таблица order_details:
| order_details_id | document_position | order_id |
| 35346346 | 10 | 1224114 |
| 35346365 | 20 | 1224114 |
| …. | …. | …. |
| 35345464 | 10 | 1224438 |
В данном примере order_details_id — это идентификатор, а комбинация document_position+order_id — это натуральный ключ.
Пример: я участвовал в проекте по загрузке данных в DWH из распределенной системы (instance-based), в которой велся учет объектов сетевой инфраструктуры. Разработчики этой системы на голубом глазу уверяли, что id этого объекта является уникальным и даже показывали в исходной системе уникальный индекс на таблице в подтверждение своих слов. Подвох выявился не сразу: оказывается уникальность этих id существовала только в рамках одного инстанса системы, и когда попробовали загрузить все данные со всех инстансов, то получилась проблема с уникальностью. В результате пришлось менять модель данных и расширять натуральный ключ сущности «сетевой объект» дополнительным полем «инстанс», чтобы обеспечить уникальность.
Проверка #2: Типы данных
Если поле называется Order_nr, то в нем необязательно содержатся только числовые значения — там вполне могут быть буквенно-цифровые последовательности. Также всегда стоит проверять длину полей. Эта проблема обычно характерна для файловых источников данных — таблицы БД обычно хорошо типизированы.
Проверка #3: Ссылочная целостность (проверка FK)
То, что разработчик показывает ER-диаграммы своей исходной системы, показывает у себя на DEV-окружении существующие FK между таблицами, и вообще мамой клянется, что у него все под контролем, не является поводом не проверить существование «повисших» записей. Т.к. он может быть не в курсе, что на продуктивном окружении DBA уже отключил эту проверку для улучшения производительности (конечно, согласовав это с менеджером разработчика, т.е. никто не виноват). Также проблемы со ссылочной целостностью очень часто встречается для файловых источников данных. Также не стоит забывать о применении сценария late-arriving-data (например, если данные приходят согласовано сегодня, далеко не факт, что так будет и через полгода).
Проверка #4: NULL значения
Основная проблема NULL значений состоит в том, что NULL<>NULL, поэтому любые запросы с джойнами по полю, которое может содержать NULL, будут возвращать непредсказуемые результаты. Поэтому все важные поля стоит обернуть конструкцией nvl(). Существует отдельный холивар по поводу грузить NULL в неключевые поля или заменять на некие значения по умолчанию. Мне ближе идея о всеобщей замене NULLов для более стандартизированного подхода к использованию DWH, но я не берусь настаивать, что так нужно делать всегда.
Проверка #5: Даты
Проверки полей с датами обычно являются самыми усложненными, т.к. помимо стандартных проверок приходится учитывать то, что не все даты, которые являются допустимыми с точки зрения БД, являются таковыми с точки зрения DWH: дата «21-07-1007» вряд ли является допустимой для даты заключения договора на оказание услуг сотовой связи. При моделировании DWH обычно существуют т.н. даты «начала времен» и «конца времен» (возможны другие названия), и любая дата, не попадающая в этот диапазон времени должна заменяться на некое значение по умолчанию.
Отдельного упоминания заслуживают случаи использования типов данных вроде varchar(8) для хранения дат (в формате например ‘20151201’), т.к. количество проверок здесь должно быть еще больше.
3. Удаление дубликатов через GROUP BY или DISTINCT
Несмотря на то, что в DWH обычно грузятся все данные, которые приходят из источника, существуют сценарии, когда на вход приходят заведомо дублирующиеся данные. Но уникальность натурального ключа требует только одну запись из дубликатов. Существует два неправильных способа удаления дубликатов:
Неправильный способ #1: GROUP BY
Допустим, мы грузим адреса клиентов и знаем, что теоретически для одного клиента может прийти несколько записей с адресной информацией (обычно они являются полными дубликатами из-за проблем, например, с синхронизацией). Поддавшись желанию решить задачу «в лоб», разработчик может написать такой запрос:
insert into customer_address
select customer_id, max(street_name), max(house_nr)
from source_table
group by customer_id
Проблемы начнутся, если на вход придут две реально отличающиеся записи для одного клиента (например, была ошибка ввода оператора, которую он исправил, но в источник данных попали оба варианта записи):
| customer_id | street_name | house_nr |
| 1321 | Moskovskaya str | 127 |
| 1321 | Pushkinskaya str | 34 |
Запрос может вернуть такой результат (в зависимости от локали):
| customer_id | street_name | house_nr |
| 1321 | Pushkinskaya str | 127 |
Такой записи в исходных данных не было, и у пользователей DWH может возникнуть резонный вопрос, что вообще это такое? На самом деле здесь нарушено 3-е требование к ETL процессу: в DWH была загружена запись, которая не может быть отслежена до исходной системы, проще говоря, которой там нет. И это однозначная ошибка ETL разработчика.
Неправильный способ #2: DISTINCT
Второй вариант «решения в лоб» в описанном выше сценарии — это использовать для удаления дублирующихся записей DISTINCT
insert into customer_address
select distinct customer_id, street_name, house_nr
from source_table
В данном случае пара дублирующихся записей с разными атрибутами будет идентифицирована раньше, поскольку вместо одной получится две записи, и будет нарушена уникальность натурального ключа и ETL-процесс упадет с ошибкой.
Один из правильных способов
Как же стоит решать проблему наличия двух записей с одинаковым натуральным ключом, но разными атрибутами? Очевидно, что если в модель данных данных изменений не внести, то из всех записей должна быть выбрана одна единственная правильная. Выбирать ее нужно согласно заранее определенному критерию: если информация является довольно критичной, то можно реализовывать различные сценарии Data Quality, если же нет, то в качестве корректной записи брать последнюю загруженную.
insert into customer_address
select customer_id, street_name, house_nr from (
select customer_id, street_name, house_nr,
row_number() over (partition by customer_id order by change_datetime desc) row_num
from source_table)
where row_num = 1
В общем следует не забывать, что любая запись в DWH должна иметь возможность быть отслеженной до источника(ов) данных в зависимости от бизнес-правила и не создавать «необъяснимые» записи.
4. Использование «статичных» скриптов из исходных систем
Очень часто бизнес-логика для сущностей DWH приходит от разработчиков или аналитиков исходных систем в виде SQL скриптов. И это большое подспорье для ETL-разработчика, но, как говорится, «бойтесь данайцев, дары приносящих»: как правило эти скрипты фиксируют некое условно «статичное» состояние исходное системы в некоторый момент времени, а ETL-разработчик обычно занимается отслеживанием динамики в данных и загрузкой только изменений («дельта»). Что же должно настораживать в этих «статичных» SQL скриптах? Вот некоторые из:
Вроде бы все логично: грузить в нашу таблицу order_from_calls все заказы, на которые есть ссылка в таблице звонков, и для которых дата последнего изменения больше даты последней загрузки. А теперь представим, что обновление таблицы calls в DWH не произошло (например, она грузится из другой исходной системы и связь с ней по какой-то причине нарушена), и этот запрос не загрузил некоторые id заказов. После этого таблица calls была дозагружена правильно, и там эти пропущенные id заказов появились, но мы их уже не загрузим в таблицу order_from_calls, т.к. в таблице orders ничего не поменялось и новые запуски этого запроса ничего не дадут. Поэтому в данном случае отслеживать дельту нужно не только по таблице orders, но и по таблице calls.
5. Разработка на небольшом объеме данных для разработки
Как правило, ETL-разработчику для разработки на DEV-окружении выгружается небольшая часть данных из продуктивной системы, на которой и предлагается вести разработку и отладку работы ETL-процессов. К сожалению, разработанные на таком малом объеме данных решения обычно приводят к различным проблемам на продуктивной системе, таким как недостаточная производительность, нехватка места для промежуточных таблиц (например, разработчик решил красиво разнести шаги бизнес-логики по набору промежуточных таблиц, последовательно перегружая из одной в другую — а вот в продуктивной системе данных оказалось слишком много, и tablespace для временных таблиц скоропостижно закончился).
К сожалению, эту ошибку ETL-разработчик не всегда может решить самостоятельно, из-за различных регламентов и инструкций, отсутствия бюджета на полноценное DEV-окружение с тем же объемом данных как на продуктиве и т.д. Таким образом, это стоит рассматривать как проектный риск.
Одним из выходов является дробление этапов проекта на более мелкие и делать релизы более часто, чтобы идентифицировать такие проблемы не в конце проекта, а хотя бы посередине.
6. Неправильное использование технических и бизнес дат
В DWH существует 2 типа дат: бизнес-даты и технические даты. Разница у них в происхождении: бизнес-дата — это та дата, которая пришла из источника данных или была создана по бизнес-правилам; техническая дата — это дата, которая была сгенерирована ETL процессом либо самим DWH. И очень часто их используют неправильно:
#1 Бизнес-даты используются как технические даты
Если сущность историзируется как SCD2 (Slowly Changing Dimension type 2) и в источнике данных есть поля «_from» и «_to», которые ETL разработчику предлагается использовать в качестве диапазонов валидности данных, то у него должны быть просто железобетонные гарантии того, все диапазоны валидности для каждого натурального ключа будут: 1) непересекающимися, 2) между диапазонами не будет разрывов, 3) объединение этих диапазонов дат будет совпадать с диапазоном даты «от начала времен» до «конца времен» установленных для вашего DWH (это могут быть например пары дат «01.01.1000» и «31.12.9999», или «11.11.1111» и «09.09.9999»). Как правило, разработчики исходных систем мало заморачиваются, и если правило «непересекающихся диапазонов дат» обычно соблюдается, то со 2-м и 3-м пунктом обычно возникают проблемы. В любом случае, общей рекомендацией является не использовать бизнес-даты для SCD2, а генерировать свои технические даты.
#2 Технические даты используются как бизнес-даты
Очень часто источники данных не поставляют поля для отслеживания каких-либо контрольных дат: например, документ имеет только статус закрытия, но не метку времени, когда это событие произошло, и в качестве решения предлагается использовать технические даты «_from» и «_to», которые были сгенерированы ETL процессом. Однако это решение работает до первого сбоя ETL процесса (например, остановки ETL процессов на пару дней): сбой произошел в понедельник, восстановление наступило в среду, и т.к. исходная система вполне себе работала все это время, все созданные документы будут загружены как созданные в среду. В общем случае, сценарий «историческая правда» не реализуем, если источник данных не поставляет всех нужных пользователям дат и может быть лишь сэмулирован (с помощью технических дат), но в таком случае этот сценарий должен быть проговорен и описан в документации, чтобы через год пользователи не удивлялись нулевому количеству закрытых документов в понедельник и вторник, а также тройному количеству их в среду.
7. «Механическая» реализация
Это одна из самых сложных для идентификации ошибок и, по правде говоря, не является ошибкой именно ETL разработчика, а скорее архитектора DWH. Но над проектом работает же команда, и коллег выручать тоже надо.
Иногда так случается, что целевая сущность в DWH была неправильно смоделирована исходя из-за расхождений в терминологии для разработчика исходной системы и архитектора. Разработчик исходной системы мыслит категориями своей исходной системы, архитектору DWH же необходимо продумывать различные интеграционные схемы, как связать в едином DWH множество объектов из разнородных исходных систем.
Опишу на примере сущности «клиент» как одной из типичных для такого рода проблем: в источнике данных есть таблица «customer», имеющая уникальный натуральный ключ, ссылочная целостность в порядке. На основе этой таблицы в DWH была создана сущность «customer». Исходя из названия, логично предположить, что одна запись в этой таблице должна соответствовать одному клиенту, но фактически выяснилось, что на самом деле один и тот же реальный клиент мог иметь несколько записей с одними и теми же атрибутами, но разными натуральными ключами. И это привело бы к неприятной коллизии для пользователей DWH, которые использовали эту сущность, например, для подсчета общего количества клиентов компании. В результате было принято решение разделить эту сущность на две: «customer_record» и «customer», связанные через FK отношением M:1.
А если бы ETL разработчик «механически» реализовал все по спецификации, то он бы конечно был бы не виноват, но у него была возможность заметить это, т.к. в любом случае он по сравнению с архитектором работает условно говоря «на земле», в отличие от «витающего в облаках» архитектора.
В целом можно упомянуть некоторые симптомы «механической» реализации:
Введение в Data Engineering. ETL, схема «звезды» и Airflow
Способность data scientist-а извлекать ценность из данных тесно связана с тем, насколько развита инфраструктура хранения и обработки данных в компании. Это значит, что аналитик должен не только уметь строить модели, но и обладать достаточными навыками в области data engineering, чтобы соответствовать потребностям компании и браться за все более амбициозные проекты.
При этом, несмотря на всю важность, образование в сфере data engineering продолжает оставаться весьма ограниченным. Мне повезло, поскольку я успел поработать со многими инженерами, которые терпеливо объясняли мне каждый аспект работы с данными, но не все обладают такой возможностью. Именно поэтому я решил написать эту статью — введение в data engineering, в которой я расскажу о том, что такое ETL, разнице между SQL- и JVM-ориентированными ETL, нормализации и партиционировании данных и, наконец, рассмотрим пример запроса в Airflow.
Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
ETL: Extract, Transform, Load
Extract, Transform и Load — это 3 концептуально важных шага, определяющих, каким образом устроены большинство современных пайплайнов данных. На сегодняшний день это базовая модель того, как сырые данные сделать готовыми для анализа.
Extract. Это шаг, на котором датчики принимают на вход данные из различных источников (логов пользователей, копии реляционной БД, внешнего набора данных и т.д.), а затем передают их дальше для последующих преобразований.
Transform. Это «сердце» любого ETL, этап, когда мы применяем бизнес-логику и делаем фильтрацию, группировку и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет. Эта процедура требует понимания бизнес задач и наличия базовых знаний в области.
Load. Наконец, мы загружаем обработанные данные и отправляем их в место конечного использования. Полученный набор данных может быть использован конечными пользователями, а может являться входным потоком к еще одному ETL.
Какой ETL-фреймворк выбрать?
В мире batch-обработки данных есть несколько платформ с открытым исходным кодом, с которыми можно попробовать поиграть. Некоторые из них: Azkaban — open-source воркфлоу менеджер от Linkedin, особенностью которого является облегченное управление зависимостями в Hadoop, Luigi — фреймворк от Spotify, базирующийся на Python и Airflow, который также основан на Python, от Airbnb.
У каждой платформы есть свои плюсы и минусы, многие эксперты пытаются их сравнивать (смотрите тут и тут). Выбирая тот или иной фреймворк, важно учитывать следующие характеристики:
Конфигурация. ETL-ы по своей природе довольно сложны, поэтому важно, как именно пользователь фреймворка будет их конструировать. Основан ли он на пользовательском интерфейсе или же запросы создаются на каком-либо языке программирования? Сегодня все большую популярность набирает именно второй способ, поскольку программирование пайплайнов делает их более гибкими, позволяя изменять любую деталь.
Мониторинг ошибок и оповещения. Объемные и долгие batch запросы рано или поздно падают с ошибкой, даже если в самой джобе багов нет. Как следствие, мониторинг и оповещения об ошибках выходят на первый план. Насколько хорошо фреймворк визуализирует прогресс запроса? Приходят ли оповещения вовремя?
Обратное заполнение данных (backfilling). Часто после построения готового пайплайна нам требуется вернуться назад и заново обработать исторические данных. В идеале нам бы не хотелось строить две независимые джобы: одну для обратного а исторических данных, а вторую для текущей деятельности. Насколько легко осуществлять backfilling c помощью данного фреймворка? Масштабируемо и эффективно ли полученное решение?
2 парадигмы: SQL против JVM
Как мы выяснили, у компаний есть огромный выбор того, какие инструменты использовать для ETL, и для начинающего data scientist-а не всегда понятно, какому именно фреймворку посвятить время. Это как раз про меня: в Washington Post Labs очередность джобов осуществлялась примитивно, с помощью Cron, в Twitter ETL джобы строились в Pig, а сейчас в Airbnb мы пишем пайплайны в Hive через Airflow. Поэтому перед тем, как пойти в ту или иную компанию, постарайтесь узнать, как именно организованы ETL в них. Упрощенно, можно выделить две основные парадигмы: SQL и JVM-ориентированные ETL.
JVM-ориентированные ETL обычно написаны на JVM-ориентированном языке (Java или Scala). Построение пайплайнов данных на таких языках означает задавать преобразования данных через пары «ключ-значение», однако писать пользовательские функции и тестировать джобы становится легче, поскольку не требуется использовать для этого другой язык программирования. Эта парадигма весьма популярна среди инженеров.
SQL-ориентированные ETL чаще всего пишутся на SQL, Presto или Hive. В них почти все крутится вокруг SQL и таблиц, что весьма удобно. В то же время написание пользовательских функций может быть проблематично, поскольку требует использования другого языка (к примеру, Java или Python). Такой подход популярен среди data scientist-ов.
Поработав с обеими парадигмами, я все-таки предпочитаю SQL-ориентированные ETL, поскольку, будучи начинающим data scientist-ом, намного легче выучить SQL, чем Java или Scala (если, конечно, вы еще с ними не знакомы) и сконцентрироваться на изучении новых практик, чем накладывать это поверх изучения нового языка.
Моделирование данных, нормализация и схема «звезды»
В процессе построения качественной аналитической платформы, главная цель дизайнера системы — сделать так, чтобы аналитические запросы было легко писать, а различные статистики считались эффективно. Для этого в первую очередь нужно определить модель данных.
В качестве одного из первых этапов моделирования данных необходимо понять, в какой степени таблицы должны быть нормализованы. В общем случае нормализованные таблицы отличаются более простыми схемами, более стандартизированными данными, а также исключают некоторые типы избыточности. В то же время использование таких таблиц приводит к тому, что для установления взаимоотношений между таблицами требуется больше аккуратности и усердия, запросы становятся сложнее (больше JOIN-ов), а также требуется поддерживать больше ETL джобов.
С другой стороны, гораздо легче писать запросы к денормализованным таблицам, поскольку все измерения и метрики уже соединены. Однако, учитывая больший размер таблиц, обработка данных становится медленнее (“Тут можно поспорить, ведь все зависит от того, как хранятся данные и какие запросы бывают. Можно, к примеру, хранить большие таблицы в Hbase и обращаться к отдельным колонкам, тогда запросы будут быстрыми” — прим. пер.).
Среди всех моделей данных, которые пытаются найти идеальный баланс между двумя подходами, одной из наиболее популярных (мы используем ее в Airbnb) является схема «звезды». Данная схема основана на построении нормализованных таблиц (таблиц фактов и таблиц измерений), из которых, в случае чего, могут быть получены денормализованные таблицы. В результате такой дизайн пытается найти баланс между легкостью аналитики и сложностью поддержки ETL.
Таблицы фактов и таблицы измерений
Чтобы лучше понять, как строить денормализованные таблицы из таблиц фактов и таблиц измерений, обсудим роли каждой из них:
Таблицы фактов чаще всего содержат транзакционные данные в определенные моменты времени. Каждая строка в таблице может быть чрезвычайно простой и чаще всего является одной транзакцией. У нас в Airbnb есть множество таблиц фактов, которые хранят данные по типу транзакций: бронирования, оформления заказов, отмены и т.д.
Таблицы измерений содержат медленно меняющиеся атрибуты определенных ключей из таблицы фактов, и их можно соединить с ней по этим ключам. Сами атрибуты могут быть организованы в рамках иерархической структуры. В Airbnb, к примеру, есть таблицы измерений с пользователями, заказами и рынками, которые помогают нам детально анализировать данные.
Ниже представлен простой пример того, как таблицы фактов и таблицы измерений (нормализованные) могут быть соединены, чтобы ответить на простой вопрос: сколько бронирований было сделано за последнюю неделю по каждому из рынков?
Партиционирование данных по временной метке
Сейчас, когда стоимость хранения данных очень мала, компании могут себе позволить хранить исторические данные в своих хранилищах, вместо того, чтобы выбрасывать. Обратная сторона такого тренда в том, что с накоплением количества данных аналитические запросы становятся неэффективными и медленными. Наряду с такими принципами SQL как «фильтровать данные чаще и раньше» и «использовать только те поля, которые нужны», можно выделить еще один, позволяющий увеличить эффективность запросов: партиционирование данных.
Основная идея партиционирования весьма проста — вместо того, чтобы хранить данные одним куском, разделим их на несколько независимых частей. Все части сохраняют первичный ключ из исходного куска, поэтому получить доступ к любым данным можно достаточно быстро.
В частности, использование временной метки в качестве ключа, по которому проходит партиционирование, имеет ряд преимуществ. Во-первых, в хранилищах типа S3 сырые данные часто сортированы по временной метке и хранятся в директориях, также отмеченных метками. Во-вторых, обычно batch-ETL джоб проходит примерно за один день, то есть новые партиции данных создаются каждый день для каждого джоба. Наконец, многие аналитические запросы включают в себя подсчет количества событий, произошедших за определенный временной промежуток, поэтому партиционирование по времени здесь очень кстати.
Обратное заполнение (backfilling) исторических данных
Еще одно важное преимущество использования временной метки в качестве ключа партиционирования — легкость обратного заполнения данных. Если ETL-пайплайн уже построен, то он рассчитывает метрики и измерения наперед, а не ретроспективно. Часто нам бы хотелось посмотреть на сложившиеся тренды путем расчета измерений в прошлом — этот процесс и называется backfilling.
Backfilling настолько распространен, что в Hive есть встроенная возможность динамического партиционирования, чтобы выполнять одни и те же SQL запросы по нескольким партициям сразу. Проиллюстрируем эту идею на примере: пусть требуется заполнить количество бронирований по каждому рынку для дашборда, начиная с earliest_ds и заканчивая latest_ds. Одно из возможных решений выглядит примерно так:
Такой запрос возможен, однако он слишком громоздкий, поскольку мы выполняем одну и ту же операцию, только над разными партициями. Используя динамическое партиционирование мы можем все упростить до одного запроса:
Отметим, что мы добавили ds в SELECT и GROUP BY выражения, расширили диапазон в операции WHERE и изменили синтаксис с PARTITION (ds= ‘<
Теперь, рассмотрим все изученные концепции на примере ETL джобы в Airflow.
Направленный ациклический граф (DAG)
Казалось бы, с точки зрения идеи ETL джобы очень просты, однако на деле они часто очень запутаны и состоят из множества комбинаций Extract, Transform и Load операций. В этом случае очень полезно бывает визуализировать весь поток данных, используя граф, в котором узел отображает операцию, а стрелка — взаимосвязь между операциями. Учитывая, что каждая операция выполняется единожды, а данные идут дальше по графу, то он является направленным и ациклическим, отсюда и название.
Одна из особенностей интерфейса Airflow — это наличие механизма, который позволяет визуализировать пайплайн данных через DAG. Автор пайплайна должен задать взаимосвязи между операциями, чтобы Airflow записал спецификацию ETL джоба в отдельный файл.
При этом помимо DAG-ов, которые определяют порядок запуска операций, в Airflow есть операторы, которые задают, что необходимо выполнить в рамках пайплайна. Обычно есть 3 вида операторов, каждый из которых имитирует один из этапов ETL-процесса:
Простой пример
Ниже представлен простой пример того, как объявить DAG-файл и определить структуру графа, используя операторы в Airflow, которые мы обсудили выше:
Когда граф будет построен, можно увидеть следующую картинку:
Итак, надеюсь, что в данной статье мне удалось максимально быстро и эффективно погрузить вас в интересную и многообразную сферу — Data Engineering. Мы изучили, что такое ETL, преимущества и недостатки различных ETL-платформ. Затем обсудили моделирование данных и схему «звезды», в частности, а также рассмотрели отличия таблиц фактов от таблиц измерений. Наконец, рассмотрев такие концепции как партиционирование данных и backfilling, мы перешли к примеру небольшого ETL джоба в Airflow. Теперь вы можете самостоятельно изучать работу с данными, наращивая багаж своих знаний. Еще увидимся!
Роберт отмечает недостаточное количество программ по data engineering в мире, однако мы таковую проводим, и уже не в первый раз. В октябре у нас стартует Data Engineer 3.0, регистрируйтесь и расширяйте свои профессиональные возможности!



