Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
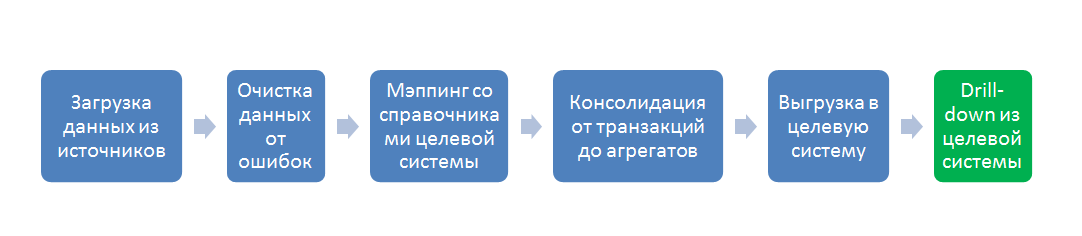
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
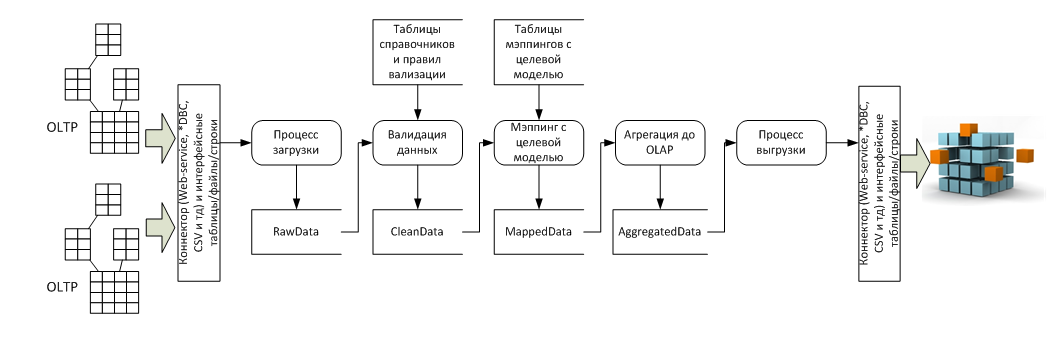
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
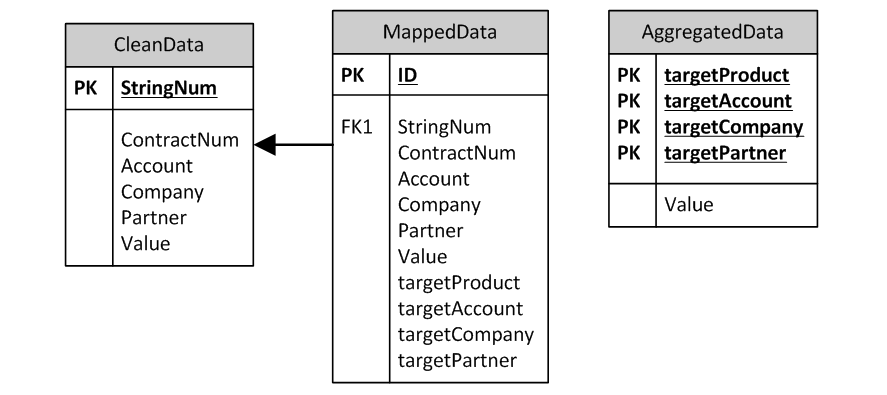
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Проектирование и разработка процесса ETL
Изучив материал настоящей лекции, вы будете знать:
Введение
Чтобы процесс преобразования данных протекал без сбоев, необходимо обеспечить наличие необходимой документации и метаданных. Процесс извлечения данных влияет на производительность других систем, поэтому его следует рассматривать в аспекте управления изменениями и конфигурацией систем – источников данных.
На рис. 15.1 показано место процесса ETL в архитектуре системы бизнес-аналитики на основе ХД.
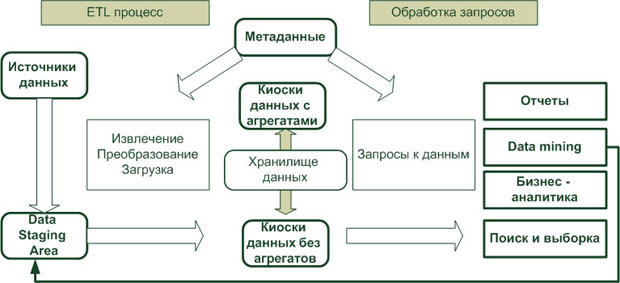
Таким образом, процесс ETL состоит из трех основных стадий.
Подходы к реализации ETL-процесса
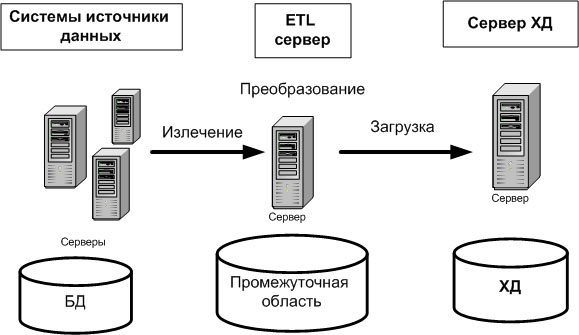
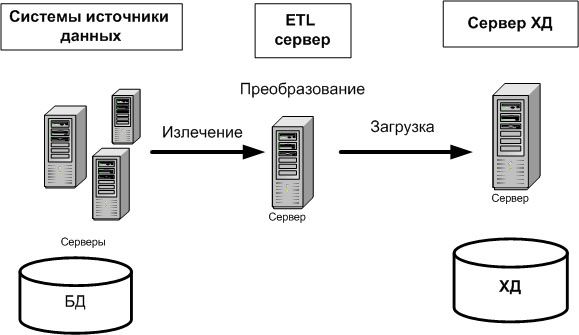
Преобразование данных в оперативной памяти выполняется быстрее, чем при размещении их предварительно на диске. Однако применение такого подхода лимитируется размером порции загружаемых данных. Если размер порции загружаемых данных достаточно большой, то необходимо использовать промежуточную область.
Разработка ETL-процесса
Как правило, при конструировании процесса ETL для ХД придерживаются следующей последовательности действий.
Планирование ETL-процесса
Процесс преобразования данных играет весьма важную роль в достижении успеха реализации проекта ХД, поэтому он должен быть хорошо спланирован. Разработка плана носит интерактивный характер.
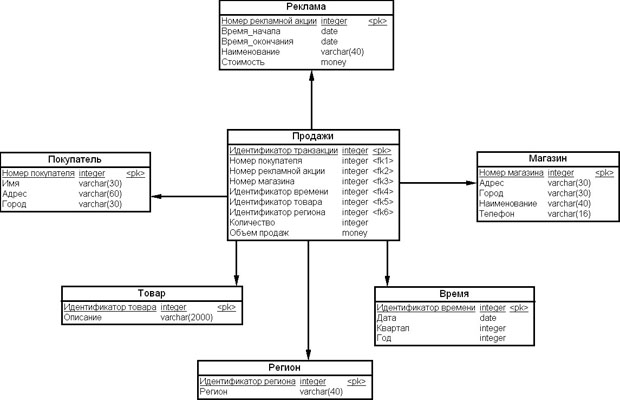
К составлению обобщенного плана лучше всего приступать, когда разработана многомерная модель ХД. Тогда для каждой таблицы многомерной схемы можно определить таблицы – источники данных.
Рассмотрим пример многомерной схемы ХД системы поддержки принятия решений на рис. 15.4.
Связи между таблицами многомерной схемы ХД и таблицами – источниками данных можно указать с помощью стрелочек, как на диаграмме на рис. 15.5.
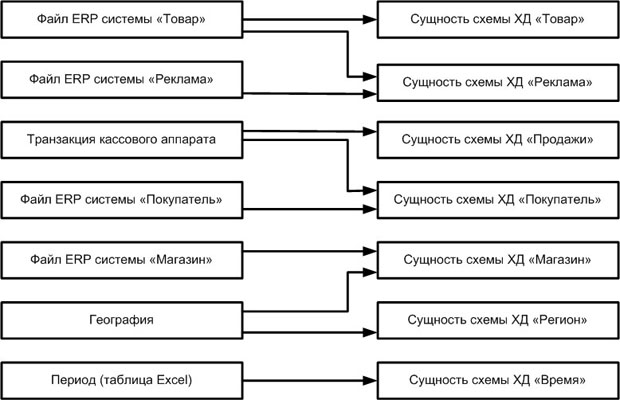
Каждую стрелочку на диаграмме следует пронумеровать и сопроводить комментарием, который должен служить напоминанием разработчикам о необходимости следить за целостностью ссылочных данных или других определенных бизнес-правилами особенностях обработки каждой таблицы источника.
На этой стадии планирования необходимо зафиксировать все обнаруженные расхождения в определениях данных и схемах кодирования.
После выполнения предварительного планирования приступают к детальному планированию.
В настоящей лекции мы не даем рекомендаций по формированию детального плана, поскольку в каждом конкретном случае детальное планирование выполняется руководителем проекта создания ХД и включает в себя учет различных факторов, связанных со спецификой предметной области ХД. Так, например, для банковских ХД, возможно, будет необходимо выполнить проверку корректности бухгалтерской базы по бизнесправилам (провести в процессе ETL подсчет остатков и оборотов по отдельным лицевым и/или балансовым счетам).
Что такое ETL: как справиться с анализом big data
Крупные предприятия собирают, хранят и обрабатывают разные типы данных из множества источников, таких как системы начисления заработной платы, записи о продажах, системы инвентаризации и других. Эта информация извлекается, преобразуется и переносится в хранилища данных с помощью ETL-систем. Расскажем, что такое ETL, а также какие платные и общедоступные решения для работы с данными есть на рынке.
ETL — что это такое и зачем?
В переводе ETL (Extract, Transform, Load) — извлечение, преобразование и загрузка. То есть процесс, с помощью которого данные из нескольких систем объединяют в единое хранилище данных.
Представьте ритейлера с розничными и интернет-магазинами. Ему нужно анализировать тенденции продаж и онлайн, и офлайн. Но бэкэнд-системы для них, скорее всего, будут отдельными. Они могут иметь разные поля или форматы полей для сбора данных, использовать системы, которые не могут «общаться» друг с другом.
И вот тогда наступает момент для ETL.
ETL-система извлекает данные из обеих систем, преобразует их в соответствии с требованиями к формату хранилища данных, а затем загружает в это хранилище.
ETL — что это на практике, а не на примере?
Современные инструменты ETL собирают, преобразуют и хранят данные из миллионов транзакций в самых разных источниках данных и потоках. Эта возможность предоставляет множество новых возможностей: анализ исторических записей для оптимизации процесса продаж, корректировка цен и запасов в реальном времени, использование машинного обучения и искусственного интеллекта для создания прогнозных моделей, разработка новых потоков доходов, переход в облако и многое другое.
Облачная миграция. Процесс переноса данных и приложений в облако называют облачной миграцией. Она помогает сэкономить деньги, сделать приложения более масштабируемыми и защитить данные. ETL в таком случае используют для перемещения данных в облако.
Хранилище данных. Хранилище данных — база данных, куда передают данные из различных источников, чтобы их можно было совместно анализировать в коммерческих целях. Здесь ETL используют для перемещения данных в хранилище данных.
Машинное обучение. Машинное обучение — метод анализа данных, который автоматизирует построение аналитических моделей. ETL может использоваться для перемещения данных в одно хранилище для машинного обучения.
Интеграция маркетинговых данных. Маркетинговая интеграция включает в себя перемещение всех маркетинговых данных — о клиентах, продажах, из социальных сетей и веб-аналитики — в одно место, чтобы вы могли проанализировать их. ETL используют для объединения маркетинговых данных.
Интеграция данных IoT. То есть данных, собранных различными датчиками, в том числе встроенными в оборудование. ETL помогает перенести данные от разных IoT в одно место, чтобы вы могли сделать их подробный анализ.
Репликация базы данных — данные из исходных баз данных копируют в облачное хранилище. Это может быть одноразовая операция или постоянный процесс, когда ваши данные обновляются в облаке сразу же после обновления в исходной базе. ETL можно использовать для осуществления процесса репликации данных.
Бизнес-аналитика. Бизнес-аналитика — процесс анализа данных, позволяющий руководителям, менеджерам и другим заинтересованным сторонам принимать обоснованные бизнес-решения. ETL можно использовать для переноса нужных данных в одно место, чтобы их можно было использовать.
Популярные ETL-системы: обзор, но коротко
Cloud Big Data — PaaS-сервис для анализа больших данных (big data) на базе Apache Hadoop, Apache Spark, ClickHouse. Легко масштабируется, позволяет заменить дорогую и неэффективную локальную инфраструктуру обработки данных на мощную облачную инфраструктуру. Помогает обрабатывать структурированные и неструктурированные данные из разных источников, в том числе в режиме реального времени. Развернуть кластер интеграции и обработки данных в облаках можно за несколько минут, управление осуществляется через веб-интерфейс, командную строку или API.
IBM InfoSphere — инструмент ETL, часть пакета решений IBM Information Platforms и IBM InfoSphere. Доступен в различных версиях (Server Edition, Enterprise Edition и MVS Edition). Помогает в очистке, мониторинге, преобразовании и доставке данных, среди преимуществ: масштабируемость, возможность интеграции почти всех типов данных в режиме реального времени.
PowerCenter — набор продуктов ETL, включающий клиентские инструменты PowerCenter, сервер и репозиторий. Данные хранятся в хранилище, где к ним получают доступ клиентские инструменты и сервер. Инструмент обеспечивает поддержку всего жизненного цикла интеграции данных: от запуска первого проекта до успешного развертывания критически важных корпоративных приложений.
iWay Software предоставляет возможность интеграции приложений и данных для удобного использования в режиме реального времени. Клиенты используют их для управления структурированной и неструктурированной информацией. В комплект входят: iWay DataMigrator, iWay Service Manager и iWay Universal Adapter Framework.
Microsoft SQL Server — платформа управления реляционными базами данных и создания высокопроизводительных решений интеграции данных, включающая пакеты ETL для хранилищ данных.
OpenText — платформа интеграции, позволяющая извлекать, улучшать, преобразовывать, интегрировать и переносить данные и контент из одного или нескольких хранилищ в любое новое место назначения. Позволяет работать со структурированными и неструктурированными данными, локальными и облачными хранилищами.
Oracle GoldenGate — комплексный программный пакет для интеграции и репликации данных в режиме реального времени в разнородных IT-средах. Обладает упрощенной настройкой и управлением, поддерживает облачные среды.
Pervasive Data Integrator — программное решение для интеграции между корпоративными данными, сторонними приложениями и пользовательским программным обеспечением. Data Integrator поддерживает сценарии интеграции в реальном времени.
Pitney Bowes предлагает большой набор инструментов и решений, нацеленных на интеграцию данных. Например, Sagent Data Flow — гибкий механизм интеграции, который собирает данные из разнородных источников и предоставляет полный набор инструментов преобразования данных для повышения их коммерческой ценности.
SAP Business Objects — централизованная платформа для интеграции данных, качества данных, профилирования данных, обработки данных и отчетности. Предлагает бизнес-аналитику в реальном времени, приложения для визуализации и аналитики, интеграцию с офисными приложениями.
Sybase включает Sybase ETL Development и Sybase ETL Server. Sybase ETL Development — инструмент с графическим интерфейсом для создания и проектирования проектов и заданий по преобразованию данных. Sybase ETL Server — масштабируемый механизм, который подключается к источникам данных, извлекает и загружает данные в хранилища.
Open source ETL-средства
Большинство инструментов ETL с открытым исходным кодом помогают в управлении пакетной обработкой данных и автоматизации потоковой передачи информации из одной системы данных в другую. Эти рабочие процессы важны при создании хранилища данных для машинного обучения.
Некоторые из бесплатных и открытых инструментов ETL принадлежат поставщикам, которые в итоге хотят продать корпоративный продукт, другие обслуживаются и управляются сообществом разработчиков, стремящихся демократизировать процесс.
Open source ETL-инструменты интеграции данных:
Apache Airflow — платформа с удобным веб-интерфейсом, где можно создавать, планировать и отслеживать рабочие процессы. Позволяет пользователям объединять задачи, которые нужно выполнить в строго определенной последовательности по заданному расписанию. Пользовательский интерфейс поддерживает визуализацию рабочих процессов, что помогает отслеживать прогресс и видеть возникающие проблемы.
Apache Kafka — распределенная потоковая платформа, которая позволяет пользователям публиковать и подписываться на потоки записей, хранить потоки записей и обрабатывать их по мере появления. Kafka используют для создания конвейеров данных в реальном времени. Он работает как кластер на одном или нескольких серверах, отказоустойчив и масштабируем.
Apache NiFi — распределенная система для быстрой параллельной загрузки и обработки данных с большим числом плагинов для источников и преобразований, широкими возможностями работы с данными. Пользовательский веб-интерфейс NiFi позволяет переключаться между дизайном, управлением, обратной связью и мониторингом.
CloverETL (теперь CloverDX) был одним из первых инструментов ETL с открытым исходным кодом. Инфраструктура интеграции данных, основанная на Java, разработана для преобразования, отображения и манипулирования данными в различных форматах. CloverETL может использоваться автономно или встраиваться и подключаться к другим инструментам: RDBMS, JMS, SOAP, LDAP, S3, HTTP, FTP, ZIP и TAR. Хотя продукт больше не предлагается поставщиком, его можно безопасно загрузить с помощью SourceForge. CloverDX по-прежнему поддерживает CloverETL в соответствии со стандартным соглашением о поддержке.
Jaspersoft ETL — один из продуктов с открытым исходным кодом TIBCO Community Edition, позволяет пользователям извлекать данные из различных источников, преобразовывать их на основе определенных бизнес-правил и загружать в централизованное хранилище данных для отчетности и аналитики. Механизм интеграции данных инструмента основан на Talend. Community Edition прост в развертывании, позволяет создавать витрины данных для отчетности и аналитики.
Apatar — кроссплатформенный инструмент интеграции данных с открытым исходным кодом, который обеспечивает подключение к различным базам данных, приложениям, протоколам, файлам. Позволяет разработчикам, администраторам баз данных и бизнес-пользователям интегрировать информацию разного формата из различных источников данных. У инструмента интуитивно понятный пользовательский интерфейс, который не требует кодирования для настройки заданий интеграции данных. Инструмент поставляется с предварительно созданным набором инструментов интеграции и позволяет пользователям повторно использовать ранее созданные схемы сопоставления.
Итак, почему стоит отказаться от локальных ETL-решений?
Традиционные локальные ETL чаще всего поставляются в комплекте с головной болью. Например, создаются собственными силами, поэтому могут быстро устареть или не иметь сложных функций и возможностей. Они дороги и требуют времени на обслуживание, а также поддерживают только пакетную обработку данных и плохо масштабируются.
Локальные платформы ETL были важнейшим компонентом инфраструктуры предприятий на протяжении десятилетий. С появлением облачных технологий, SaaS и больших данных выросло число источников информации, что вызвало рост спроса на более мощную и сложную интеграцию данных.
Побег от скуки — процессы ETL
В конце зимы и начале весны, появилась возможность поработать с новым для меня инструментом потоковой доставки данных Apache NiFi. При изучении инструмента, все время не покидало ощущение, что помимо официальной документации, нелишним были бы материалы «for dummies», с практическими примерами.
После выполнении задачи, решил попробовать облегчить вхождение в мир NiFi.
Предыстория, почти не связанная со статьей
В феврале этого года поступило предложение разработать прототип системы для обработки данных из разных источников. Источники предоставляют информацию не одновременно и в разных форматах. Нужно было данные преобразовывать в единый формат, собирать в одну структуру и передавать на обработку. Перед обработкой необходимо было провести обогащение из дополнительных справочников. Результат обработки сохраняется в две базы данных и генерируется суточный отчет.
Задача укладывалась в концепцию ETL. Поиск реализаций ETL привел на довольно большое количество ETL-систем, которые позволяют выстроить процессы обработки. В том числе opensource системы.
Система Apache NiFi была выбрана на удачу. Прототип был построен и сдан заказчику.
Первоначально заказчик хотел монолитное приложение, а использование NiFi рассматривал только как инструмент прототипирование (где-то прочитал). Но после знакомства в вблизи — NiFi остался в продукте.
А теперь собственно история
После сдачи работы заказчику, интерес к ETL не пропал. В апреле наступила самоизоляция с нерабочими днями и свободное время нужно было потратить с пользой.
Когда я начал разбираться с Apache NiFi выяснилось, что более-менее подробная информация есть только на сайте проекта. Русские статьи во многом просто переводы вводных частей официальной документации. Основной недостаток — часто не понятно в каком формате параметры вводить. Гугл спасает, но не всегда.
И появилась идея написать статью с описанием практического примера работы системы — введение для новичков. В комментариях, дорогой читатель, можно высказаться — получилось или нет.
И так, задача — получать данные о распространении вируса, обрабатывать строить графики.
Источниками данных будет сайты “стопкороновирус.рф» и «covid19.who.int». Первый сайт содержит данные по регионам России, сайт ВОЗ — данные по странам мира.
Данные на сайте «стопкороновирус.рф» находятся прямо в html-коде страницы в виде почти готового json-массива. Нужно его только обработать. Но об этом в следующей статье.
Данные ВОЗ находятся в csv-файле, который не получилось автоматически скачивать (либо я был недостаточно настойчив). Поэтому, когда нужно было, файл сохранялся из браузера в специальную папку.
Если кратко сказать о NiFi — система при выполнении процесса (pipeline), состоящего из процессоров, получает данные, модифицирует и куда-то сохраняет. Процессоры выполняют работу — читают файлы, преобразовывают один формат в другой, обогащают данные из других баз данных, загружают в хранилища и т.д. Процессоры между собой соединены очередями. У каждой очереди есть признак, по которому данные в нее загружаются из процессора. Например, в одну очередь можно загрузить данные при удачном выполнении работы процессора, в другую при сбое. Это позволяет запустить данные по разным веткам процессов. Например, берем данные, ищем подстроку — если нашли отправляем по ветке 1, если не нашли — отправляем по ветке 2.
Каждый процессор может находиться в состоянии «Running» или «Stopped». Данные накапливаются в очереди перед остановленным процессором, после старта процессора, данные будут переданы в процессор. Очень удобно, можно изменять параметры процессора, без потери данных на работающем процессе.
Данные в системе называются FlowFile, потоковый файл. Процесс начинает работать с процессора, который умеет генерировать FlowFile. Не каждый процессор умеет генерировать потоковый файл — в этом случае в начало ставится процессор «GenerateFlowFile», задача которого создать пустой потоковый файл и тем самым запустить процесс. Файл может создаваться по расписанию или событию. Файл может быть бинарным или текстовым потоком.
Файл состоит из контента и метаданных. Метаданные называются атрибутами. Например, атрибутом является имя файл, id-файла, имя схемы и т.д. Система позволяет добавлять собственные атрибуты, записывать значения. Значения атрибутов используются в работе процессоров.
Содержимое файла может быть бинарным или текстовым. Поток данных можно представить в виде массива записей. Для записи можно определить их структуру — схему данных. Схема описывает формат записи, в котором определяются имена и типы полей, валидные значения, значения по умолчанию и т.д.
В NiFi еще одна важная сущность — контроллеры. Это объекты которые знают как сделать какую-то работу. Например, процессор хочет записать в базу данных, то контроллер будет знать, как найти и подключиться к базе данных, таблице.
Контролер, который знает как читать данные на входе в контроллер называется Reader. После обработки, на выходе процессора, данные форматируются контроллеру который называется RecordSetWriter.
Итак, практическое применение вольного изложения документации — чтение данных ВОЗ и сохранение в БД. Данные будем хранить в СУБД PostgreSQL.
В таблице будет храниться дата сбора данных, код и наименование страны, код региона, суммарное количество погибших, количество погибших за сутки, суммарное количество заболевших, количество заболевших за сутки.
Источником данных будет cvs-файл с сайта https://covid19.who.int/ по кнопке “Download Map Data”. Файл содержит информацию по заболевшим и погибшим по всем странам на каждый день примерно с конца января. Оперативная информация там задерживается на 1-2 дня.
За время эксперемента, в файле менялись наименования полей (были даже наименования с пробелами), менялся формат даты.
Файл сохраняется из браузера в определенный каталог, откуда NiFi забирает его на обработку.

Общий вид визуализации процесса в интерфейсе Apache NiFI
На рисунке большие прямоугольники — процессы, прямоугольники поменьше — очереди между процессами.
Обработка начинается с верхнего процесса, отходящие от процесса стрелочки показывают направление движения FlowFile (атрибутов и контента).
На визуализации процесса показывается его статус (работает или нет), данное имя процессу, его тип, количество и общий объем прошедших файлов на входе и на выходе за период времени, в данном случае за 5 мин.
Визуализация очереди показывает ее имя, и объем данных в очереди. По умолчанию имя очереди это тип связи — success, failed и другие.
Тип первого процесса «GetFile». Этот процессор создает flowfile и запускает процесс.
В настройках процессора на вкладке Scheduling указываем расписание запуска процесса — 20 секунд. Каждые 20 секунды процессор проверяет наличие файла. Если файл найден — процесс запускается. Контентом потокового файла будет содержимое файла
Вкладка Scheduling — запуск каждые 20 сек.
Как видно из рисунка, указываем каталог и имя файла. В имени файла можно использовать символы подстановки. Например «*.csv» приведет к обработке всех csv-файлов в каталоге. Указываем также, что после обработки файл можно удалить («Keep Source File»). Также есть возможность указать максимальные и минимальные значения возраста и размера файла. Это позволяет обрабатывать, например, только не пустые файл, созданные за последний час.
На вкладке Settings указываются базовые параметры процесса, такие как имя процесса, максимальное время работы процесса, время между запусками, типы связей.
Результатом работы первого процесса «GetFile» с именем «Read WHO datafile» будет просто поток данных из файла. Поток будет передан в следующий процесс «ReplaceText».
Процессор поиска подстроки
В этом процессе обратим внимание сразу на вкладку параметров. Данный процессор ищет regex-выражение «Search Value» в входном потоке и заменяет на новое значение «Replacement Value». Обработка ведется построчно («Evaluation Mode»). В данном случае идет замена в строке даты. Во входном файле, в какой-то момент дата формата YYYY-MM-DD стала указываться как YYYY-MM-DDThh:mm:ssZ, причем время было всегда 00:00:00, а временная зона не указывалась.
Простого способа преобразования в даты уже в записи не нашел, поэтому к проблеме подошел в “лоб” — просто через процессор «ReplaceText» убрал символы T и Z. После этого строка стала конвертироваться в timestamp в avro-схеме без ошибок.
На выходе процессора будет поток текстовых данных, в которых уже поправили подстроку даты. Но пока это просто поток байтов без какой-то структуры.
Следующий процессор «Rename fields» читает поток уже как структурированные данные.
Переименование полей
Процессор содержит ссылку на Reader – специальный объект-контроллер, который умеет читать из потока структурированные данные и в таком виде уже передает процессору на обработку. В данном случае «WHO CVS Reader” просто читает поток и преобразует каждую строку cvs-файла в запись (record) которая содержит поля со значениями из строки. Имена полей берутся из заголовка cvs-файла.
Контроллер чтения записей из cvs-файла
Параметр «Schema Access Strategy» указывают, что структура записи формируется из заголовка cvs-файла. Если заголовков нет, то можно изменить стратегию доступа к схеме и в реестре схем данных создать схему, указать ее имя в параметре «Schema Name» или еще проще — указать саму схему в параметре «Schema Text».
Но так как у нас есть заголовки в файле — читаем по ним.
Итак, в процессоре данные уже структурированные — их можно представить как таблицу базы данных — поля и строки. И к этой таблице мы выполняем SQL запрос :
Поля в запросе такие же как заголовки cvs-файла. Имя таблицы служебное — FLOWFILE – обозначает чтение структурированных данных их контента файла. Язык запроса SQL довольно гибкий, есть функции преобразований, агрегаций и т.д. В данном случае запрос выводит все данные, только имена полей результата будут другие — они соответствуют полям таблицы who_outbreak в целевой БД.
Поток записей с новыми именами полей передается в контроллер RecordSetWriter, ссылка на который также указана в параметра контроллера — «WHO AvroRecordSetWriter».
Контроллер RecordSetWriter
Контролер RecordSetWriter уже использует предопределенную схему данных. Схема находится в отдельном объекте — регистре схем («Schema Registry»). В контроллере есть только ссылка на реестр схем и имя схемы.
Регистр схем
Работать с регистром схем довольно просто. Добавляем новый параметр. Его имя — будет именем схемы. Значение параметр — определение схемы.
В регистре схем создана схема who_outbreak, определение схемы:
Имена и типы атрибутов схемы соответствуют именам и типам полей записи, сформированной sql-запросом.
После выполнения контроллером sql-запроса и передачи данных на выход контроллера в формате схемы данных, структурированный поток передается в контроллер «Delete all records». Это контроллер типа «PutSQL», который может передавать на выполнение sql-команды.
Файл источник содержит полный набор данных с начала эпидемии, поэтому удаляем все строки из таблицы, чтобы загрузить данные в следующем процессоре. Это работает быстрее, чем проверка— какие данные есть в таблице, а каких нет и их нужно добавить.
delete from who_outbreak;
В параметрах контроллера указываем SQL Statement “delete from who_outbreak;” и ссылку на пул соединений «JDBC Connection Pool». Параметры JDBC стандартные. Пул содержит настройки подключения к конкретной БД, поэтому его можно использовать во всех контроллерах, которые будут работать с этой БД.
Данные или атрибуты FlowFile не обрабатываются в процессоре, поэтому вход и выход процессора идентичен.
Последний процессор «PutDatabaseRecord».
Запись в БД
В этом процессоре указываем Reader, в котором используется определенная схема who_outbreak. Так как мы удалили все записи в предыдущем процессоре, используем простой INSERT для добавления записей в таблицу. Указываем пул соединений DBCPConnectionPool, далее указываем БД и имя таблицы. Имена полей в схеме данных и БД совпадают, то больше никакой дополнительной настройки проводить не нужно.
Все процессоры, контроллеры и регистры схем нужно перевести в состояние Running (Start).
Процесс доставки данных готов. Если положить файл WHO-COVID-19-global-data.csv в каталог D:\input, то в течении 20 секунд он будет удален, а данные пройдя через процесс доставки данных будут сохранены в БД.
Сейчас вынашиваю планы на вторую часть статьи, в которой планирую описать второй процесс ETL — чтение данных с сайта, обогащение, загрузка в БД, в файлы, расщепление потока на несколько потоков и сохранение в файлы. Если тема интересна — пишите в комментарии, это мне прибавит стимула быстрее написать.
На рисунке изображение в интерфейсе Apache NiFi описанного процесса (справа) и, для затравки, процесса для второй статьи (слева).



