ETL против ELT

Разница между ETL и ELT
В этой теме мы собираемся узнать о ETL против ELT, но давайте сначала обсудим, что означает процесс E, T, L,
ETL: процесс ETL включает извлечение данных из классифицированных источников данных, а затем преобразование и привязывание данных подходящим способом, наконец, данные загружаются в системы хранилища данных. Этот метод целесообразен до тех пор, пока многие разнородные базы данных не будут вовлечены в среду хранилища данных здесь перемещение данных из одного места в другое должно происходить в любом случае, поэтому ETL является наилучшей практикой в таких ситуациях для выполнения преобразований, поскольку передача данных в любом случае происходит здесь
ELT: Это немного другой процесс, здесь используется та же техника извлечения, затем данные загружаются непосредственно в целевые системы. На предыдущем этапе объективные системы отвечают за применение преобразований к загруженным данным. Основным недостатком здесь является то, что обычно требуется больше времени для получения данных в хранилище данных, и, следовательно, с помощью промежуточных таблиц добавляется дополнительный шаг в процессе, который требует больше дискового пространства.
ELT играет свою роль в следующих случаях,
Преимущество ELT заключается в уменьшении выдачи, происходящей в источнике, ввиду того, что преобразование не выполняется, это очень важно учитывать, если источником является система PROD. Основным недостатком здесь является то, что обычно требуется больше времени для получения данных в хранилище данных, и, следовательно, с помощью промежуточных таблиц добавляется дополнительный шаг в процессе, который требует больше дискового пространства.
Сравнение лицом к лицу между ETL и ELT (Инфографика)
Ниже приведены 7 основных различий между ETL и ELT. 
Ключевые различия между ETL и ELT
Ниже приведены основные ключевые различия между ETL и ELT:
Сравнительная таблица между ETL и ELT
Давайте обсудим топ-7 различий между ETL и ELT
| Основа сравнения ETL против ELT | ETL | ELT |
| использование | Подразумевает сложные преобразования включает в себя ETL | ELT вступает в игру, когда задействованы огромные объемы данных |
| преобразование | Преобразования выполняются в зоне подготовки | Все преобразования в целевых системах |
| Время | Поскольку этот процесс включает в себя загрузку данных сначала в системы ETL, а затем в соответствующую целевую систему, это тянет за сравнительно большее время. | Здесь, поскольку данные непосредственно загружаются в целевые системы изначально, и все преобразования выполняются в целевых системах. |
| Участие Datalake | Нет данных озера поддержки | Неструктурированные данные могут быть обработаны с озерами данных здесь. |
| техническое обслуживание | Обслуживание здесь высоко, так как этот процесс включает в себя два разных этапа | Техническое обслуживание сравнительно низкое |
| Стоимость | Выше в ценовом факторе | Сравнительно дешевле |
| вычисления | Либо нам нужно переопределить существующий столбец, либо необходимо отправить данные на целевую платформу. | Рассчитанный столбец можно легко добавить |
Вывод
Каждая компания, соблюдающая требования к хранилищу данных, будет использовать ETL (Извлечение, Преобразование, Загрузка) или ELT (Извлечение, Загрузка, Преобразование) для передачи данных в хранилище данных, получаемых из разных источников. Исходя из отраслевых и технических потребностей, одна из вышеперечисленных процедур широко применяется.
Рекомендуемые статьи
Архитектура хранилищ данных: традиционная и облачная
Привет, Хабр! На тему архитектуры хранилищ данных написано немало, но так лаконично и емко как в статье, на которую я случайно натолкнулся, еще не встречал.
Предлагаю и вам познакомиться с данной статьей в моем переводе. Комментарии и дополнения только приветствуются!

Введение
Итак, архитектура хранилищ данных меняется. В этой статье рассмотрим сравнение традиционных корпоративных хранилищ данных и облачных решений с более низкой первоначальной стоимостью, улучшенной масштабируемостью и производительностью.
Хранилище данных – это система, в которой собраны данные из различных источников внутри компании и эти данные используются для поддержки принятия управленческих решений.
Компании все чаще переходят на облачные хранилища данных вместо традиционных локальных систем. Облачные хранилища данных имеют ряд отличий от традиционных хранилищ:
Традиционная архитектура хранилища данных
Следующие концепции освещают некоторые из устоявшихся идей и принципов проектирования, используемых для создания традиционных хранилищ данных.
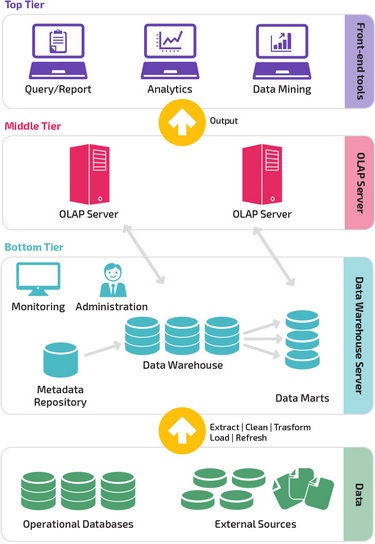
Трехуровневая архитектура
Довольно часто традиционная архитектура хранилища данных имеет трехуровневую структуру, состоящую из следующих уровней:
Kimball vs. Inmon
Два пионера хранилищ данных: Билл Инмон и Ральф Кимбалл предлагают разные подходы к проектированию.
Подход Ральфа Кимбалла основывается на важности витрин данных, которые являются хранилищами данных, принадлежащих конкретным направлениям бизнеса. Хранилище данных — это просто сочетание различных витрин данных, которые облегчают отчетность и анализ. Проект хранилища данных по принципу Кимбалла использует подход «снизу вверх».
Подход Билла Инмона основывается на том, что хранилище данных является централизованным хранилищем всех корпоративных данных. При таком подходе организация сначала создает нормализованную модель хранилища данных. Затем создаются витрины размерных данных на основе модели хранилища. Это известно как нисходящий подход к хранилищу данных.
Модели хранилищ данных
В традиционной архитектуре существует три общих модели хранилищ данных: виртуальное хранилище, витрина данных и корпоративное хранилище данных:
Звезда vs. Снежинка
Схемы «звезда» и «снежинка» — это два способа структурировать хранилище данных.
Схема типа «звезда» имеет централизованное хранилище данных, которое хранится в таблице фактов. Схема разбивает таблицу фактов на ряд денормализованных таблиц измерений. Таблица фактов содержит агрегированные данные, которые будут использоваться для составления отчетов, а таблица измерений описывает хранимые данные.
Денормализованные проекты менее сложны, потому что данные сгруппированы. Таблица фактов использует только одну ссылку для присоединения к каждой таблице измерений. Более простая конструкция звездообразной схемы значительно упрощает написание сложных запросов.
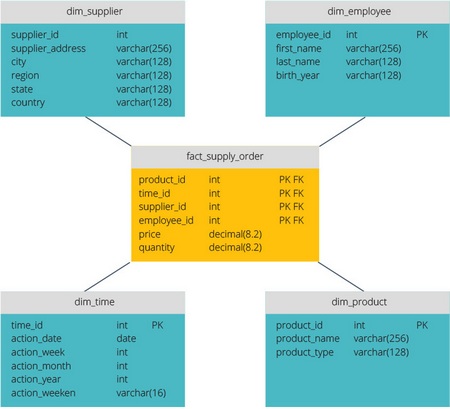
Схема типа «снежинка» отличается тем, что использует нормализованные данные. Нормализация означает эффективную организацию данных так, чтобы все зависимости данных были определены, и каждая таблица содержала минимум избыточности. Таким образом, отдельные таблицы измерений разветвляются на отдельные таблицы измерений.
Схема «снежинки» использует меньше дискового пространства и лучше сохраняет целостность данных. Основным недостатком является сложность запросов, необходимых для доступа к данным — каждый запрос должен пройти несколько соединений таблиц, чтобы получить соответствующие данные.

ETL vs. ELT
ETL и ELT — два разных способа загрузки данных в хранилище.
ETL (Extract, Transform, Load) сначала извлекают данные из пула источников данных. Данные хранятся во временной промежуточной базе данных. Затем выполняются операции преобразования, чтобы структурировать и преобразовать данные в подходящую форму для целевой системы хранилища данных. Затем структурированные данные загружаются в хранилище и готовы к анализу.
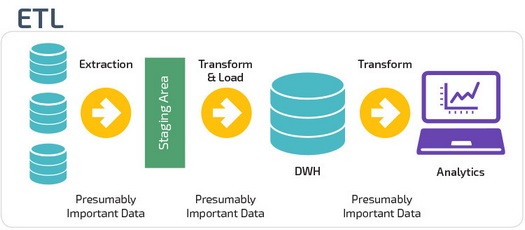
В случае ELT (Extract, Load, Transform) данные сразу же загружаются после извлечения из исходных пулов данных. Промежуточная база данных отсутствует, что означает, что данные немедленно загружаются в единый централизованный репозиторий.
Данные преобразуются в системе хранилища данных для использования с инструментами бизнес-аналитики и аналитики.

Организационная зрелость
Структура хранилища данных организации также зависит от его текущей ситуации и потребностей.
Базовая структура позволяет конечным пользователям хранилища напрямую получать доступ к сводным данным, полученным из исходных систем, создавать отчеты и анализировать эти данные. Эта структура полезна для случаев, когда источники данных происходят из одних и тех же типов систем баз данных.

Хранилище с промежуточной областью является следующим логическим шагом в организации с разнородными источниками данных с множеством различных типов и форматов данных. Промежуточная область преобразует данные в обобщенный структурированный формат, который проще запрашивать с помощью инструментов анализа и отчетности.
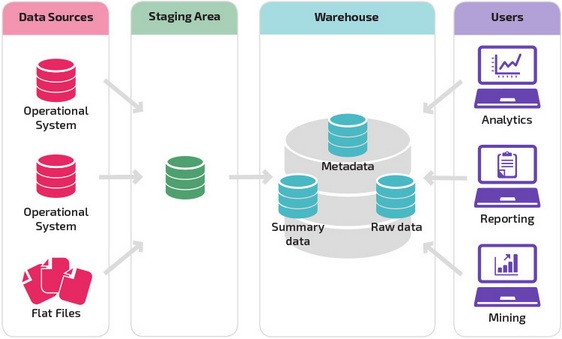
Одной из разновидностей промежуточной структуры является добавление витрин данных в хранилище данных. В витринах данных хранятся сводные данные по конкретной сфере деятельности, что делает эти данные легко доступными для конкретных форм анализа.
Например, добавление витрин данных может позволить финансовому аналитику легче выполнять подробные запросы к данным о продажах, прогнозировать поведение клиентов. Витрины данных облегчают анализ, адаптируя данные специально для удовлетворения потребностей конечного пользователя.

Новые архитектуры хранилищ данных
В последние годы хранилища данных переходят в облако. Новые облачные хранилища данных не придерживаются традиционной архитектуры и каждое из них предлагает свою уникальную архитектуру.
В этом разделе кратко описываются архитектуры, используемые двумя наиболее популярными облачными хранилищами: Amazon Redshift и Google BigQuery.
Amazon Redshift
Amazon Redshift — это облачное представление традиционного хранилища данных.
Redshift требует, чтобы вычислительные ресурсы были подготовлены и настроены в виде кластеров, которые содержат набор из одного или нескольких узлов. Каждый узел имеет свой собственный процессор, память и оперативную память. Leader Node компилирует запросы и передает их вычислительным узлам, которые выполняют запросы.
На каждом узле данные хранятся в блоках, называемых срезами. Redshift использует колоночное хранение, то есть каждый блок данных содержит значения из одного столбца в нескольких строках, а не из одной строки со значениями из нескольких столбцов.
Redshift использует архитектуру MPP (Massively Parallel Processing), разбивая большие наборы данных на куски, которые назначаются слайсам в каждом узле. Запросы выполняются быстрее, потому что вычислительные узлы обрабатывают запросы в каждом слайсе одновременно. Узел Leader Node объединяет результаты и возвращает их клиентскому приложению.
Клиентские приложения, такие как BI и аналитические инструменты, могут напрямую подключаться к Redshift с использованием драйверов PostgreSQL JDBC и ODBC с открытым исходным кодом. Таким образом, аналитики могут выполнять свои задачи непосредственно на данных Redshift.
Redshift может загружать только структурированные данные. Можно загружать данные в Redshift с использованием предварительно интегрированных систем, включая Amazon S3 и DynamoDB, путем передачи данных с любого локального хоста с подключением SSH или путем интеграции других источников данных с помощью API Redshift.
Google BigQuery
Архитектура BigQuery не требует сервера, а это означает, что Google динамически управляет распределением ресурсов компьютера. Поэтому все решения по управлению ресурсами скрыты от пользователя.
BigQuery позволяет клиентам загружать данные из Google Cloud Storage и других читаемых источников данных. Альтернативным вариантом является потоковая передача данных, что позволяет разработчикам добавлять данные в хранилище данных в режиме реального времени, строка за строкой, когда они становятся доступными.
BigQuery использует механизм выполнения запросов под названием Dremel, который может сканировать миллиарды строк данных всего за несколько секунд. Dremel использует массивно параллельные запросы для сканирования данных в базовой системе управления файлами Colossus. Colossus распределяет файлы на куски по 64 мегабайта среди множества вычислительных ресурсов, называемых узлами, которые сгруппированы в кластеры.
Dremel использует колоночную структуру данных, аналогичную Redshift. Древовидная архитектура отправляет запросы тысячам машин за считанные секунды.
Для выполнения запросов к данным используются простые команды SQL.
Panoply
Panoply обеспечивает комплексное управление данными как услуга. Его уникальная самооптимизирующаяся архитектура использует машинное обучение и обработку естественного языка (NLP) для моделирования и рационализации передачи данных от источника к анализу, сокращая время от данных до значения как можно ближе к нулю.
Интеллектуальная инфраструктура данных Panoply включает в себя следующие функции:
По ту сторону облачных хранилищ данных
Облачные хранилища данных — это большой шаг вперед по сравнению с традиционными подходами к архитектуре. Однако пользователи по-прежнему сталкиваются с рядом проблем при их настройке:
ETL и ELT: разница в том, как…
В течение последних нескольких десятилетий ETL (извлечение, преобразование, загрузка) был традиционным подходом, который использовался в хранилищах данных и аналитике. Подход ELT (извлечение, загрузка, преобразование) меняет старую парадигму. Но что на самом деле происходит, когда меняются местами буквы «T» и «L»?
ETL и ELT решают одну и ту же задачу:
Компаниям необходимо собирать, обрабатывать и анализировать гигабайты данных и событий. Данные должны быть чистыми, управляемыми и готовыми к анализу. Их нужно обогатить, формировать и трансформировать, прежде чем они станут значимыми.
Но то «как» это сделано в этих подходах отличается. Новый подход открывает новые возможности во многих современных проектах обработки данных. Есть определенные различия в том, как обрабатываются необработанные данные, когда выполняется обработка и как анализ.
В этой статье мы покажем технологические различия ETL и ELT, покажем примеры инженерии данных и анализа двух подходов и рассмотрим 10 плюсов и минусов ETL и ELT.
Технологические различия: давайте сначала разберем три ключевых этапа E, T, L:
ETL и ELT: что такое ETL?
ETL требует управления необработанными данными, включая извлечение необходимой информации и выполнение правильных преобразований, чтобы в конечном итоге удовлетворить потребности бизнеса. Каждый этап: извлечение, преобразование и загрузка, требует взаимодействия инженеров и разработчиков данных и работы с ограничениями емкости традиционных хранилищ данных. Используя ETL, аналитики и другие пользователи BI привыкли ждать, поскольку простой доступ к информации невозможен до тех пор, пока не будет завершен весь процесс ETL.
Что такое ELT?
При ELT после завершения извлечения данных вы сразу же начинаете этап загрузки – перемещение всех источников данных в единое централизованное хранилище данных. Благодаря сегодняшним инфраструктурным технологиям, в которых используются облака, системы могут поддерживать большие хранилища и масштабируемые вычисления. Следовательно, большой, расширяющийся пул данных и быстрая обработка практически бесконечны для сохранения всех извлеченных необработанных данных.
Таким образом, подход ELT представляет собой современную альтернативу ETL. Однако он все еще на этапе развития. Поэтому структуры и инструменты для поддержки процесса ELT не всегда подходят для облегчения загрузки и обработки больших объемов данных. Потенциал роста очень многообещающий – предоставление неограниченного доступа ко всем вашим данным в любое время и экономия усилий и времени разработчиков для пользователей и аналитиков BI.
Практический пример
Вот пример, который показывает технологические различия между ETL и ELT, он поможет нам вникнуть в детали.
В нашей демо-версии будут использоваться две таблицы данных: одна для покупок, а другая для валют, как показано ниже:
ТАБЛИЦА ПОКУПОК
Сумма
валюта
ТАБЛИЦА ВАЛЮТ
валюта
Курс
Чтобы разобрать основы, мы рассмотрим, как эти данные обрабатывается в ETL и ELT. Для каждого из них мы покажем, как рассчитать единую сводную таблицу с использованием этих двух таблиц, включая среднюю покупку в каждой стране (на основе предоставленного IP-адреса).
Преобразование ETL в извлеченных данных
В процессе ETL к ряду правил или функций для извлеченных данных и создания таблицы, которая будет загружена применяется этап преобразования.
Вот код, который показывает процесс предварительного преобразования данных для ETL:
Используя этот скрипт, мы сопоставляем IP-адреса с соответствующей страной. Мы выводим новое рассчитанное значение «сумма», умножая значения обеих исходных таблиц в группе на атрибут валюты. Затем мы сортируем данные по столбцу страны, объединяем данные из таблиц покупок и валют и суммируем средние значения по странам.
Это преобразование данных приводит к новой таблице со средней суммой по стране:
СРЕДНЯЯ СУММА ПО СТРАНЕ
страна
сумма
Преобразование данных ELT во время выполнения запроса
В отличие от ETL, в ELT все данные уже загружены и могут использоваться в любой момент времени.
Следовательно, преобразование выполняется во время выполнения запроса:
В запросе мы выбираем IP-адрес по стране, умножая сумму из таблицы покупок на курс из таблицы валют, чтобы вычислить среднюю сумму. Затем объединение обеих таблиц на основе общих столбцов обеих таблиц и группировка по странам.
Это приведет к той же самой выходной таблице, что и в описанном выше процессе ETL. Однако в этом случае, поскольку все необработанные данные уже загружены, нам будет проще продолжить выполнение других запросов в той же среде для тестирования и определения лучших возможных преобразований данных, соответствующих бизнес-требованиям.
Итог этого практического примера
В разработке кода ELT более эффективен, чем ETL. Кроме того, ELT более гибок, чем ETL. С помощью ELT пользователи могут запускать новые преобразования, тестировать и улучшать запросы непосредственно на необработанных данных по мере необходимости – без лишних времени и сложности, к которым мы привыкли с ETL.
Управление хранилищами данных и озерами данных
Согласно Gartner, потребности компаний в управлении данными и интеграции данных сегодня требуют как малых, так и больших, неструктурированных и структурированных объемов данных. Вот что они предлагают изменить в способе работы:
«Традиционная команда бизнес-аналитики должна продолжать разрабатывать четкие передовые практики с хорошо понятными бизнес-целями… существует второй режим бизнес-аналитики, который является более гибким и. очень итеративным, с непредвиденным обнаружением данных, допускающим быстрый сбой».
Такие мысли вызвали много разговоров о хранилищах и озерах данных. Концепция озера данных – это новый взгляд на большие объемы неструктурированных данных, предназначенный для бесконечного масштабирования с использованием таких инструментов, как Hadoop, для реализации второго режима работы бизнес-аналитики, описанного Gartner. Хотя компании по-прежнему используют хранилища данных для поддержки традиционной парадигмы, такой как ETL, масштабируемые современные хранилища данных, такие как Redshift и BigQuery, могут использоваться для реализации современной парадигмы ELT со всеми присущими ей преимуществами, упомянутыми выше.
IBM рассказывает о 5 вещах, которые требуются для современных проектов на основе больших данных, о необходимости новых концепций данных, таких как озеро данных. Это «5 V»:
ETL по-прежнему хорошо подходит для работы с устаревшими хранилищами данных, при рассмотрении более мелких подмножеств и их перемещении в хранилище данных. Но трудно предоставить решение с ETL для «5 V», когда вы идете вниз по списку – как работать с объемами? Неструктурированными данными? Скорость? и т.п.
Подход ELT открывает возможности для работы в более гибкой итеративной среде бизнес-аналитики благодаря своей эффективности и гибкости. ELT позволяет реализовать множество концепций хранилищ данных и распространяется на концепции озера данных, что позволяет включать неструктурированные данные в свое решение бизнес-аналитики.
Подводя итоги: 10 плюсов и минусов ETL и ELT
Обобщая эти два подхода, мы сгруппировали различия по 10 критериям:
1. Время – Загрузка
ETL: использует промежуточную область и систему, дополнительное время для загрузки данных
ELT: все в одной системе, загрузка только один раз
2. Время – Преобразование
ETL: нужно подождать, особенно для больших объемов данных – по мере роста данных время преобразования увеличивается
ELT: все в одной системе, скорость не зависит от размера данных
3. Время – Обслуживание
ETL: высокий уровень обслуживания – выбор данных для загрузки и преобразования; необходимо сделать все снова, если данные удалены или вы хотите улучшить основное хранилище данных.
ELT: низкие эксплуатационные расходы – все данные всегда доступны
4. Сложность реализации
ETL: на ранней стадии требует меньше места, и результат будет чистый
ELT: требует глубоких знаний инструментов и экспертного проектирования основного большого хранилища.
5. Анализ и стиль обработки
ETL: основан на нескольких сценариях для создания представлений – удаление представления означает удаление данных
ELT: создание специальных представлений – низкие затраты на создание и обслуживание
6. Ограничение данных или ограничение на поставку
ETL: предполагая и выбирая данные априори
ELT: По HW (нет) и политике хранения данных
7. Поддержка хранилищ данных
ETL: преобладающая устаревшая модель, используемая для локальных и реляционных структурированных данных.
ELT: адаптировано для использования в масштабируемой облачной инфраструктуре для поддержки структурированных и неструктурированных источников больших данных.
8. Поддержка озера данных
ETL: не является частью подхода
ELT: позволяет использовать озеро с поддержкой неструктурированных данных
9. Удобство использования
ETL: фиксированные таблицы, фиксированная временная шкала, используется в основном ИТ
ELT: ситуативность, гибкость, доступность для всех, от разработчика до гражданского интегратора
10. Рентабельность
ETL: нерентабельно для малого и среднего бизнеса
ELT: масштабируемость и доступность для бизнеса любого размера с использованием онлайн-решений SaaS
Заключительные мысли об ETL и ELT
ETL устарел. Он помог справиться с ограничениями традиционных жестких инфраструктур центров обработки данных, но сегодня это больше не является проблемой. В организациях с большими наборами данных, в масштабе нескольких терабайт, время загрузки может занять часы, в зависимости от сложности правил преобразования.
ELT – важная часть будущего хранилищ данных. С ELT компании любого размера могут извлечь выгоду из современных технологий. Анализируя большие пулы данных с большей гибкостью и меньшими затратами на обслуживание, компании получают ключевые идеи для создания реальных конкурентных преимуществ в своем бизнесе.



